Introducción a este artículo:
Actualmente, los principales puntos débiles en las operaciones de comercio electrónico no solo provienen de los mercados cambiantes y las demandas de los clientes, sino también de la competencia y los desafíos que plantea el acceso fragmentado de los usuarios. Para explorar en profundidad el valor del usuario, cultivar su lealtad y lograr un crecimiento del rendimiento, Youzan ha creado un sistema de análisis OLAP integral para comerciantes, que proporciona servicios SaaS como informes de análisis fuera de línea y en tiempo real, marketing inteligente y selección de público. Este artículo presentará en detalle las prácticas de prueba de comparación de rendimiento y planificación de migración de Youzan de Clickhouse a Apache Doris , y compartirá cómo unificar la pila de tecnología OLAP basada en Apache Doris y satisfacer las necesidades de análisis en tiempo real y consultas extremadamente rápidas bajo grandes volúmenes de datos. En este escenario, la velocidad promedio de consulta aumenta en un 200% .
Autor: Li Chuangyouzan Ingeniero de I+D de datos de plataforma básica
Youzan es el proveedor de servicios SaaS de comercio electrónico líder en China. Actualmente cuenta con cinco sistemas comerciales principales: comercio electrónico social, nuevo comercio minorista, industria de la belleza, educación e internacionalización de Youzan. A través de su comercio electrónico social, gestión de tiendas, soluciones y otros Los nuevos productos de software SaaS minoristas ayudan de manera integral a los comerciantes a resolver problemas como la promoción y adquisición de clientes, la conversión de transacciones, la retención de clientes, el crecimiento de las recompras y la fisión compartida que se encuentran en la era de Internet móvil, y ayudan a todos los comerciantes que valoran los productos y servicios a realizar la privatización. de los activos de los clientes, se amplía la base de clientes de Internet y se mejora la eficiencia operativa, lo que en última instancia ayuda a los comerciantes a tener éxito.
Mientras enfrenta las necesidades de servicios personalizados de los comerciantes y desarrolladores, con el fin de brindar un mejor soporte a los comerciantes para resolver de manera efectiva problemas como la adquisición de clientes y los sistemas de distribución, Youzan ha creado un sistema de análisis OLAP para comerciantes y proporciona los siguientes escenarios de servicios SaaS:
- Informes de backend fuera de línea de los comerciantes: proporcione consultas de informes T+1 para los comerciantes del extremo B, lo que requiere alta precisión de cálculo, rendimiento de consulta y estabilidad, y también enfrentará escenarios de consulta complejos.
- Selección colectiva y marketing inteligente: obtenga datos de usuario de puntos de contacto de dominio privado y puntos de contacto fuera de línea, combínelos con datos de usuario a los que se accede desde plataformas sociales de uso común y utilice la Plataforma de datos del cliente (en lo sucesivo, CDP) y los datos de acuerdo con las necesidades comerciales. La plataforma de gestión (Plataforma de gestión de datos, en adelante denominada DMP) y el sistema de gestión de relaciones con el cliente (Gestión de relaciones con el cliente, en adelante denominado CRM) realizan un análisis exhaustivo del retrato de diferentes consumidores. Este escenario enfrentará una gran cantidad de actualizaciones de datos en tiempo real de alta frecuencia, al mismo tiempo que el volumen de consultas es grande y el QPS es alto, lo que a menudo ocurre en escenarios de consultas SQL complejas.
- Informes de análisis en tiempo real para comerciantes: proporcione análisis y consultas de informes relevantes en tiempo real para los comerciantes del lado B. Este escenario se caracteriza por un QPS relativamente alto. Los comerciantes pueden elegir diferentes combinaciones de dimensiones para la consulta, lo que requiere un alto tiempo real. y estabilidad.
- Sistema de análisis de registros Skynet: proporciona servicios de registros integrales para la recopilación, el consumo, el análisis, el almacenamiento, la indexación y la consulta de registros para todos los sistemas comerciales. Este escenario tiene un alto rendimiento de escritura, que requiere millones de escrituras de datos por segundo; y la frecuencia de consulta es baja, lo que implica consultas de registros TopN de Skynet, por lo que el sistema requiere agregación en tiempo real y capacidades de búsqueda difusa.
A medida que el volumen de datos comerciales aumenta cada vez más, las necesidades comerciales de puntualidad y análisis de consultas federadas se vuelven cada vez más urgentes. Los componentes existentes tienen ciertos puntos débiles para el desarrollo del personal comercial y el personal de operación y mantenimiento durante su uso. Por lo tanto, decidimos actualizar el Arquitectura de datos y Unificar el stack tecnológico OLAP basado en Apache Doris. Este artículo presentará en detalle la composición de la arquitectura inicial, el proceso de operación del sistema OLAP y los puntos débiles de la aplicación práctica, y compartirá la tecnología y la experiencia de ajuste en el proceso de migración de la arquitectura del sistema.
Puntos débiles de la arquitectura temprana
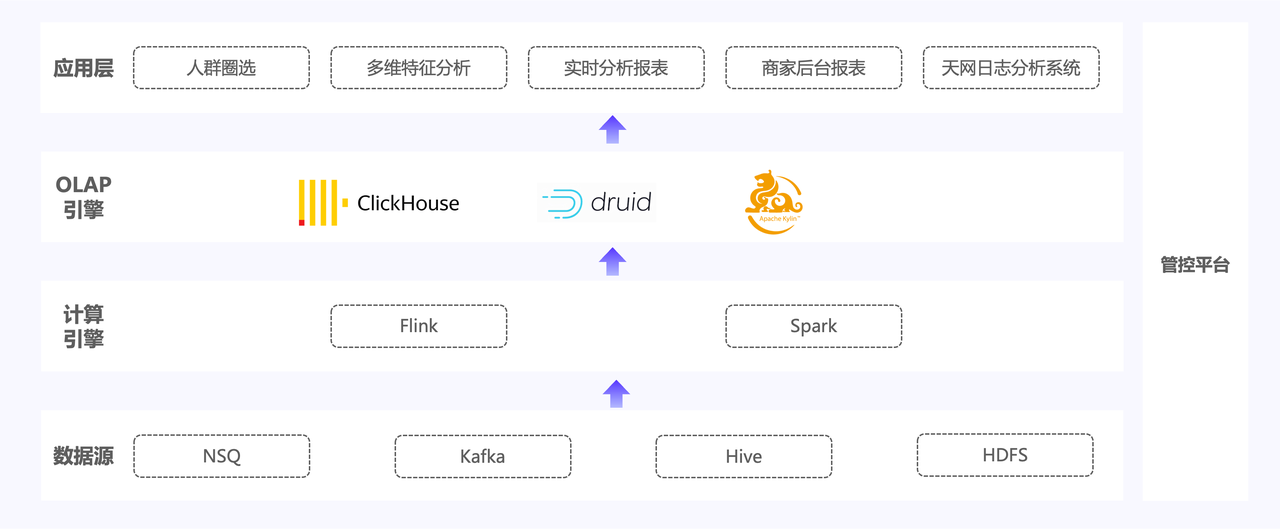
La arquitectura inicial se muestra en la figura: los datos provienen principalmente de datos originales, como la base de datos comercial Binlog y los registros de usuarios, y los datos se procesan a través de dos enlaces, en tiempo real y fuera de línea. Los datos originales se importan primero a Apache Kafka y al middleware de mensajes NSQ. Algunos de los datos se procesarán y calcularán a través de Apache Flink y se asociarán con la tabla de detalles de dimensiones almacenada en HBase. La otra parte de los datos se almacenará en Apache Hive. y HDFS como datos fuera de línea, escritos en el motor OLAP mediante el cálculo de Apache Spark.
La arquitectura de datos de Youzan utiliza principalmente los siguientes tres motores OLAP. Cada componente proporciona consultas y análisis en diferentes escenarios para aplicaciones ascendentes de acuerdo con las características y necesidades del escenario empresarial:
- Apache Kylin: cree un backend de informes fuera de línea para comerciantes basado en Apache Kylin para proporcionarles consultas de informes T+1. En la actualidad, hay más de 5 millones de comerciantes en el backend. Para algunos grandes comerciantes, la cantidad de miembros de un solo punto puede llegar a decenas de millones, los SKU de productos pueden llegar a cientos de miles y la cantidad de cubos construidos en la plataforma llega a 400. +.
- Clickhouse: basado en Clickhouse, se realizan servicios de selección de público y consulta de registros TopN. La selección de público ayuda principalmente al análisis de datos de comportamiento del usuario a través de consultas detalladas en tiempo real.
- Apache Druid: con el objetivo de escenarios de informes de análisis en tiempo real para comerciantes del lado B, se crea un sistema de consulta dimensional basado en Druid para proporcionar servicios de consulta de indicadores en tiempo real para los comerciantes.
Sin embargo, debido a problemas como demasiados componentes y arquitectura redundante, ha traído una serie de desafíos en mantenimiento, desarrollo, aplicaciones comerciales, etc., de la siguiente manera:
01 Clickhouse: rendimiento de consulta insuficiente
Para escenarios de consultas de alta concurrencia y alto QPS en algunos escenarios SaaS, las capacidades de consulta de Clickhouse no son ideales. Debido a problemas de diseño del componente Clickhouse en sí, no puede admitir escenarios de consulta de unión de tablas múltiples o de tablas grandes, lo que significa que una vez que ocurre un escenario de consulta relacionado, el lado comercial necesita encontrar una nueva solución para mejorar la eficiencia general de la consulta. bajo.
02 Apache Druid: el procesamiento de reparación de datos es difícil
- La reparación de datos es difícil: cuando la propia tolerancia a fallas de Apache Flink causa la duplicación de datos, Druid depende completamente del lado de escritura para realizar operaciones idempotentes. Dado que no admite la actualización o eliminación de datos, solo puede reemplazar los datos en su totalidad, lo que resulta en datos bajos. Precisión. , difícil de reparar.
- Problema de coherencia de los datos: para Druid, después de importar datos, el segmento debe construirse antes de que pueda responder a los resultados de la consulta. Una vez que hay un retraso en los datos en el proceso de escritura de Flink ascendente en Kafka, no se pueden escribir en Druid como se esperaba, los datos del indicador fluctuarán mucho y no se puede garantizar la coherencia de los datos.
- El enlace de reparación de datos es demasiado largo y el costo es demasiado alto : para resolver algunos problemas temporales de reparación de datos, primero debemos pasar horas haciendo una copia de seguridad de los datos de Apache Kafka en HDFS. Una vez completada la copia de seguridad, también debemos volver a realizar la copia de seguridad. -importe los datos a Druid para su reparación. El enlace de reparación general es demasiado largo y el tiempo de inversión y los costos de I + D aumentarán en consecuencia.
03 Apache Kylin: T+1 baja puntualidad
Apache Kylin adopta un método de cálculo previo en el proceso de procesamiento de datos, completa los cálculos de agregación durante el proceso de construcción del cubo multidimensional y genera informes de datos T+1. Algunas empresas que operan de noche deben esperar un día para ver los datos del informe del día anterior, lo que no puede satisfacer las necesidades de puntualidad de los usuarios.
04 Arquitectura general: altos costos de operación y mantenimiento, baja eficiencia de I+D y poca flexibilidad arquitectónica
- Altos costos de I + D: las partes comerciales deben aprender a usar cada componente (Clickhouse, Druid, Apache Kylin) y los estándares de consulta SQL son diferentes, lo que aumentará los costos de aprendizaje y requerirá I + D, monitoreo, operación y mantenimiento, y periféricos en el futuro. etapas Durante el proceso de desarrollo de herramientas ecológicas y otras herramientas, es necesario invertir una gran cantidad de mano de obra y costos de acceso al desarrollo, lo que reduce la eficiencia del desarrollo.
- Cuello de botella de operación y mantenimiento: durante el período de expansión y contracción, la parte comercial debe dejar de escribir para ajustar el clúster y una sola expansión requiere migrar todas las tablas de la base de datos. No solo no se puede garantizar el costo del tiempo de operación y mantenimiento, sino que también aumentará. Costos laborales excesivos. Actualmente, Youzan tiene una gran demanda de expansión de capacidad y el costo de operación y mantenimiento de la arquitectura existente se ha convertido en un importante problema para el sistema.
- Poca flexibilidad de la arquitectura: Apache Kylin solo puede ejecutarse normalmente en escenarios donde las dimensiones y los indicadores se establecen de antemano y la estructura de la tabla es fija. Una vez que se agregan las dimensiones y los indicadores, es necesario crear un nuevo cubo y recargar los datos históricos; Clickhouse necesitará que se agregará cuando se agreguen tablas anchas. Si se vuelven a importar todos los datos, estos defectos arquitectónicos causarán un mayor uso de recursos, mayores costos de operación y mantenimiento y una menor eficiencia de I + D durante las operaciones comerciales.
Investigación técnica y evaluación costo-beneficio.
Con base en los puntos débiles arquitectónicos anteriores, llevamos a cabo una investigación y selección de arquitecturas en el mercado, con la esperanza de elegir un motor que pueda simplificar la compleja arquitectura actual y unificar la pila de tecnología OLAP. Además de analizar la ayuda que el rendimiento de OLAP aporta al negocio, también debemos evaluar la relación costo-beneficio que aporta la transformación de la arquitectura y considerar si el retorno de la inversión generado por la migración y la reconstrucción de la arquitectura cumple con las expectativas.
En términos de beneficios, debemos evaluar si el rendimiento después de la introducción de la nueva arquitectura mejora como se esperaba y comparar y evaluar Apache Doris con Clickhouse, Druid y Kylin respectivamente.
En términos de costo, primero consideraremos el costo del desarrollo de herramientas periféricas durante el proceso de reemplazo, que implica la construcción, la investigación y el desarrollo de una serie de herramientas como monitoreo, alarmas y plataformas dependientes ascendentes y descendentes; en segundo lugar, la migración empresarial. implicará mucha transformación y coordinación empresarial, cómo motivar a las partes comerciales para llevar a cabo la transformación, proporcionar herramientas de transformación más abundantes y reducir los costos de inversión tanto como sea posible son también nuestras principales consideraciones.

Después de una serie de evaluaciones, descubrimos que la iteración de la arquitectura basada en Apache Doris puede resolver eficazmente los puntos débiles de la arquitectura actual en términos de potenciación empresarial y costos, y lograr en gran medida el objetivo de reducción de costos y mejora de la eficiencia. iteración Los beneficios esperados son significativamente mayores que el costo de la transformación, por lo que decidimos construir un almacén de datos unificado en tiempo real basado en Apache Doris, la evaluación y análisis específicos son los siguientes:
- Excelente rendimiento de consultas: resuelve las deficiencias de Clickhouse en escenarios de consultas de alto QPS y consultas relacionadas con tablas grandes, y proporciona excelentes capacidades de consultas concurrentes. Además, después del lanzamiento de Apache Doris 2.0, la función de índice invertido admite la recuperación rápida en cualquier dimensión y la recuperación de texto completo por segmentación de texto. La mejora del rendimiento de las consultas en escenarios de registro es particularmente obvia.
- Actualización de datos eficiente: la clave única de Apache Doris admite actualizaciones de datos de lotes grandes y escritura en tiempo real de datos de lotes pequeños, cubriendo el 90% de nuestros escenarios comerciales. Sus modelos de clave duplicada y clave agregada también pueden admitir actualizaciones de columnas parciales y el modelo de datos general. es rico y útil.Mejora la eficiencia de la escritura y las consultas.
- Garantice la exactitud de los datos: Apache Doris admite la importación de transacciones y la función Bitmap admite la deduplicación precisa para garantizar que los datos no se pierdan ni se dupliquen; también admite la escritura precisa para garantizar una sólida coherencia entre las tablas de la base de datos y las vistas materializadas, y una sólida coherencia de los datos de copia. .
- Fácil de usar y bajo costo de desarrollo: Apache Doris es altamente compatible con MySQL, lo que reduce el umbral para un fácil desarrollo y uso. Los costos de migración y expansión de Doris son bajos y es particularmente simple en operaciones de operación y mantenimiento, como la expansión horizontal. El acceso a sus componentes periféricos y el monitoreo son relativamente simples: la comunidad Doris proporciona herramientas de acceso como Flink & Doris Connector, Spark & Doris Connector, y se puede acceder directamente a la plantilla de monitoreo sin mayor desarrollo.
- Alta actividad comunitaria: Entre las comunidades de código abierto a las que me he unido en el pasado, la comunidad Apache Doris es muy activa. Tiene muchos desarrolladores en la comunidad y itera y actualiza rápidamente. También es muy activa respondiendo preguntas en la comunidad y ha brindado mucha ayuda durante el proceso de desarrollo.
Cree un almacén de datos unificado en tiempo real basado en Apache Doris
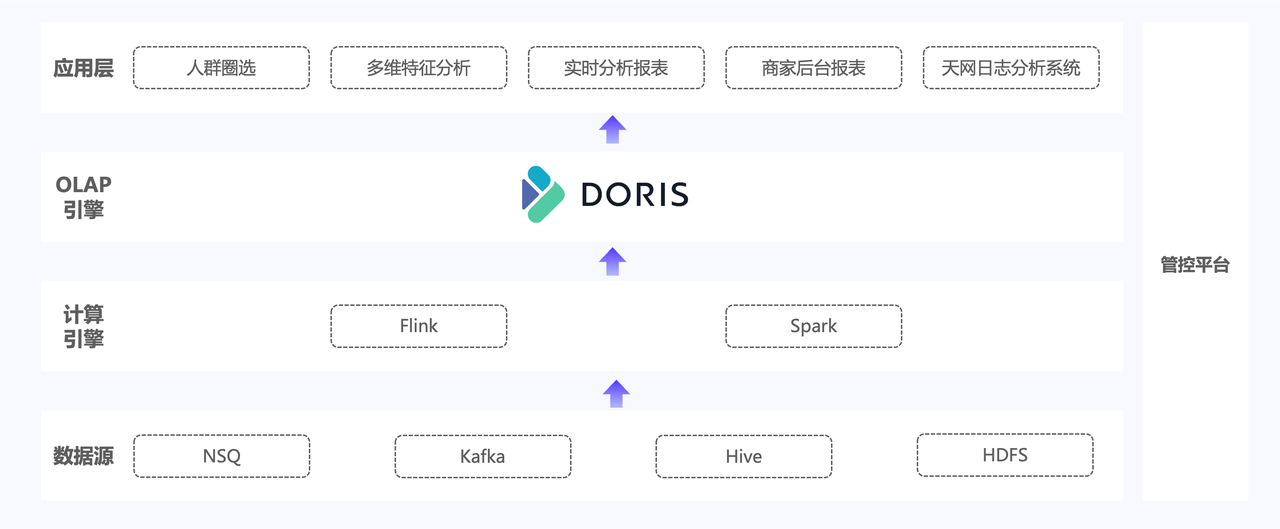
Como se muestra en la figura anterior, la nueva arquitectura construirá un almacén de datos unificado en tiempo real basado en Apache Doris, reemplazando los tres componentes OLAP en la arquitectura original y resolviendo problemas como altos costos de acceso, mayor uso de recursos y datos largos. enlaces causados por demasiados componentes, lo que en última instancia puede reducir la carga del lado comercial, reducir el costo de hardware del marco general y lograr los objetivos de unificar el motor y la pila de tecnología.
En la mayoría de los escenarios de aplicación de Youzan, la arquitectura original tiene duplicaciones de datos y retrasos en los datos que deben repararse. Después de presentar Apache Doris, utilizaremos sus funciones de modelo de clave única, clave duplicada y clave agregada para lograr actualizaciones de datos eficientes para garantizar la escritura. La eficiencia y la arquitectura Doris tienen capacidades de escalamiento elástico. Después de su introducción, puede reducir en gran medida la probabilidad de falla y la eficiencia de la recuperación de datos cuando ocurre una falla.
Además, presentaremos las siguientes características de Apache Doris:
- Índice invertido: la función de índice invertido de Apache Doris versión 2.0 optimiza el sistema de análisis de registros Skynet, logra una recuperación rápida multidimensional y acelera el rendimiento del análisis de consultas en escenarios de registros.
- Fusión - escritura del modelo de clave principal (Fusionar-en-escritura): Apache Doris proporciona una variedad de métodos de importación, que pueden importar pequeños lotes de datos a Doris en tiempo real, proporcionando consultas de informes en tiempo real para negocios posteriores en la tienda. Con la estructura de precios original, Doris puede maximizar en gran medida la puntualidad de las importaciones.
Experiencia de migración de Clickhouse a Apache Doris
Después de determinar la migración de la arquitectura, primero elegimos usar Apache Doris para reemplazar el componente Clickhouse, principalmente debido a puntos débiles como el gran cuello de botella en el rendimiento de las consultas de Clickhouse y las operaciones demasiado complejas de expansión y contracción del clúster cuando el negocio creció, lo que resultó en gran medida. aumentó la carga de trabajo del equipo de operación y mantenimiento. Además, una serie de problemas como la mala capacidad de unión de tablas grandes y el bajo rendimiento de consultas de alto QPS no pueden satisfacer las necesidades del lado comercial. Además, la función Clickhouse es similar a Apache. Doris, facilitando la migración de la parte empresarial, por lo que damos prioridad al reemplazo del componente Clickhouse.
A continuación, compartiremos el plan de migración de Doris para reemplazar Clickhouse. El ritmo general de la iteración de la arquitectura se divide en reescritura de declaraciones SQL para lograr la importación automática (incluida la reescritura de declaraciones de creación de tablas y declaraciones de consulta), pruebas de rendimiento de consultas y pruebas de estabilidad. , importe pruebas de rendimiento y optimice, y finalmente migre los datos comerciales generales después de completar una serie de pruebas.
01 Declaración de creación de tabla SQL y reescritura de declaración de consulta
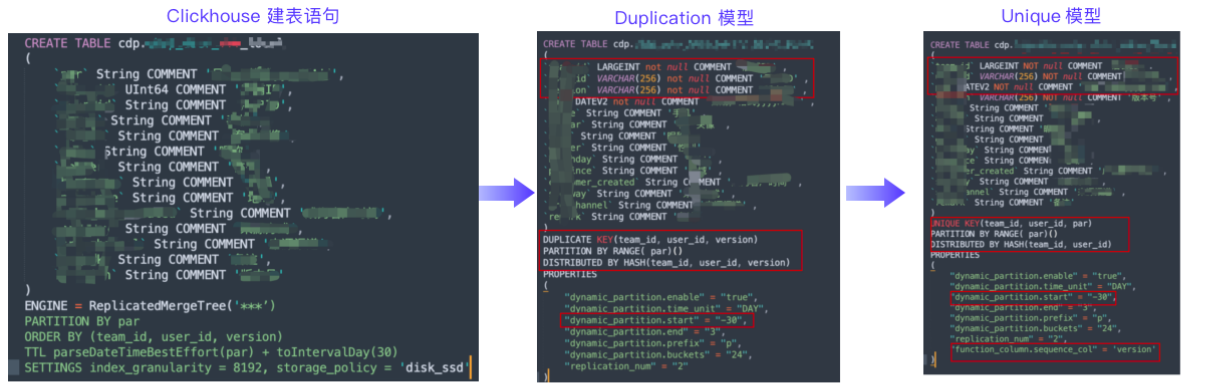
Actualmente, hemos producido una herramienta de reescritura de declaraciones de creación de tablas SQL para el modelo de clave única y el modelo de clave duplicada. Como se muestra en la figura anterior, admite la conversión automática de declaraciones de creación de tablas de Clickhouse en declaraciones de creación de tablas de Doris a través de parámetros de configuración. Las funciones principales de esta herramienta son los siguientes:
- Mapeo de tipo de campo: debido a la inconsistencia entre los campos de Doris y Clickhouse, existen algunos requisitos especiales para la conversión. Por ejemplo, el tipo de valor clave Cadena debe convertirse a Varchar y se debe establecer la longitud correspondiente, y el campo de partición Cadena necesita convertirse a Fecha V2, etc.;
- Determine la cantidad de particiones históricas de una tabla particionada dinámicamente: debido a que algunas tablas tienen particiones históricas, debe especificar la cantidad de particiones al crear la tabla; de lo contrario, se producirá una excepción sin partición al insertar datos;
- Se determina el número de depósitos: aunque la tabla de particiones históricas se puede configurar de manera uniforme, el volumen de datos de la partición histórica a menudo no es completamente consistente, por lo que podemos calcular el número de depósitos de la partición histórica en función del volumen de datos real de la partición histórica. Al mismo tiempo, para tablas no particionadas, el número de depósitos se puede calcular en función de los datos históricos. Establezca las propiedades para configurar el depósito automático;
- Determinación del ciclo TTL: puede configurar el ciclo de conversión de la tabla de particiones dinámicas y establecer el tiempo de retención antes de la conversión;
- Configuración de secuencia del modelo único: puede especificar el orden de importación de la columna Secuencia al importar, lo que resuelve el problema de que no se puede determinar el orden de importación y garantiza de manera efectiva el orden durante el proceso de importación de datos.
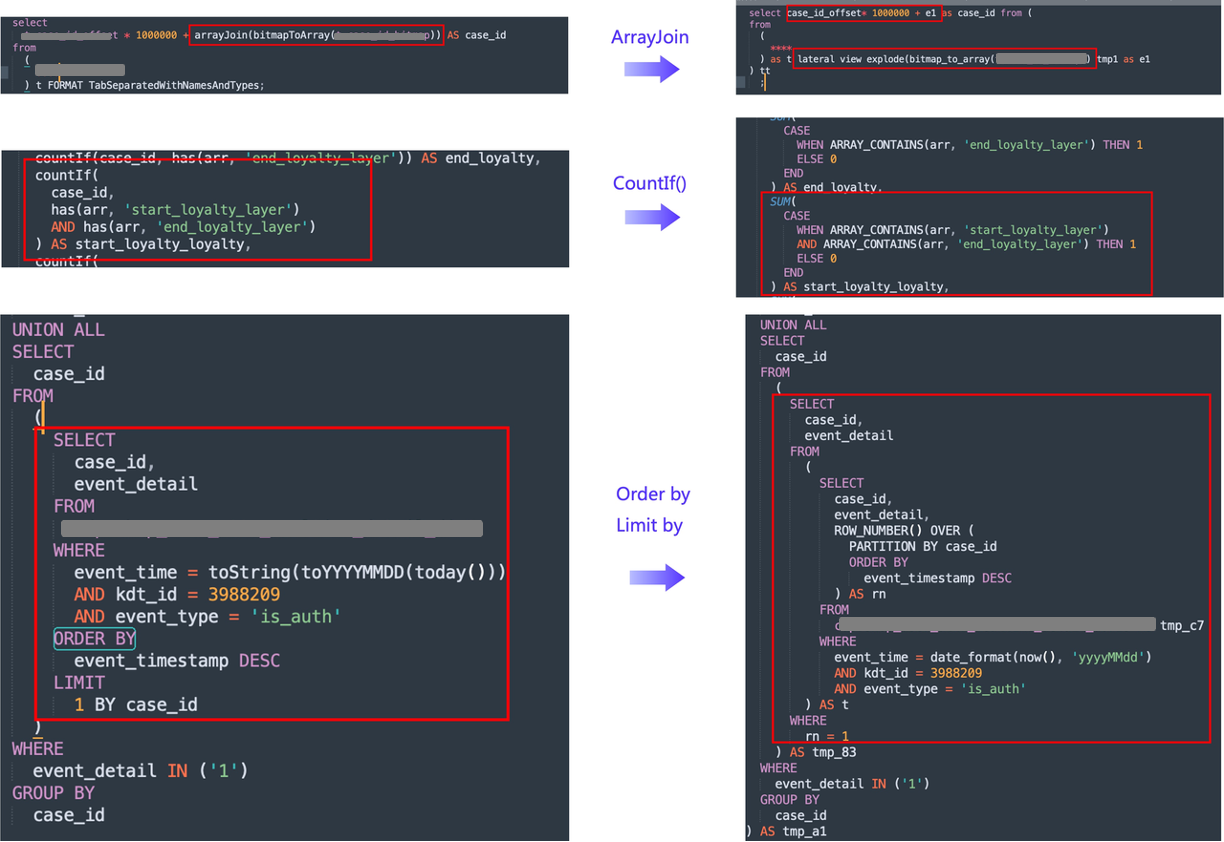
De manera similar a la herramienta de reescritura de declaraciones de creación de tablas, la reescritura de declaraciones de consulta SQL puede convertir automáticamente declaraciones de consulta de Clickhouse en declaraciones de consulta de Doris, principalmente para la verificación de doble ejecución de la precisión y estabilidad de los datos. Durante el proceso de reescritura, solucionamos las siguientes consideraciones:
- Consulta de conversión de nombres de tablas: existen ciertas reglas de mapeo durante el proceso de creación de tablas de Clickhouse y Doris. Durante la prueba de ejecución dual, podemos realizar la conversión directamente de acuerdo con las reglas de mapeo.
- Conversión de funciones: dado que las funciones utilizadas por Clickhouse y Doris son bastante diferentes, la conversión de mapeo de funciones debe realizarse en función de la relación de mapeo de funciones entre Doris y Clickhouse. Entre ellos, encontramos algunas conversiones de funciones especiales que requieren un procesamiento especial. Por ejemplo, en Clickhouse,
COUNTIF()debe convertirse paraSUM(CASE WHEN _ THEN 1 ELSE 0)lograr el mismo efectoORDER BYyGROUP BYdebe convertirse utilizando la función de ventana Doris. Además, Clickhouse utiliza paraArray Joinrealizar la conversión de columnas . transferir, y Doris necesita usarExplode,Lateral Viewpara expandirse; - Incompatibilidad a nivel de sintaxis: dado que Clickhouse no es compatible con el protocolo MySQL y Doris es altamente compatible, se requiere configuración de alias en la subconsulta. Especialmente en el escenario empresarial de selección colectiva, hay múltiples subconsultas, por lo que durante la conversión posventa, las subconsultas correspondientes deben verificarse recursivamente para
sqlparseverificar todas las subconsultas para su configuración.
02 Prueba de estrés de rendimiento de Apache Doris y Clickhouse
La prueba de rendimiento de consultas compara principalmente el rendimiento de Apache Doris y los componentes de la arquitectura original de Clickhouse en tres escenarios comerciales principales (CDP, DMP, CRM). Elegimos el tamaño de clúster equivalente en línea y realizamos pruebas de estrés comparativas mediante la comparación del rendimiento de consultas SQL y el rendimiento de unión de tablas grandes , y también probamos el consumo de CPU y memoria de Doris durante la consulta. A continuación, presentaremos el proceso de prueba de estrés y compararemos los datos de rendimiento específicos en detalle. El tamaño del clúster de prueba es 3 FE + 16 BE y la configuración de nodo único BE es (32C 128 G 7T SSD).
Comparación del rendimiento de consultas SQL en escenarios principales
En la prueba de rendimiento de consultas SQL, realizamos principalmente consultas basadas en los tres sistemas principales con los escenarios de aplicación reales más actuales, es decir, la comparación de escenarios CDP, DMP y CRM. Al final, se consultaron efectivamente 16 declaraciones SQL. Las características específicas de las consultas SQL en escenarios en línea son las siguientes:
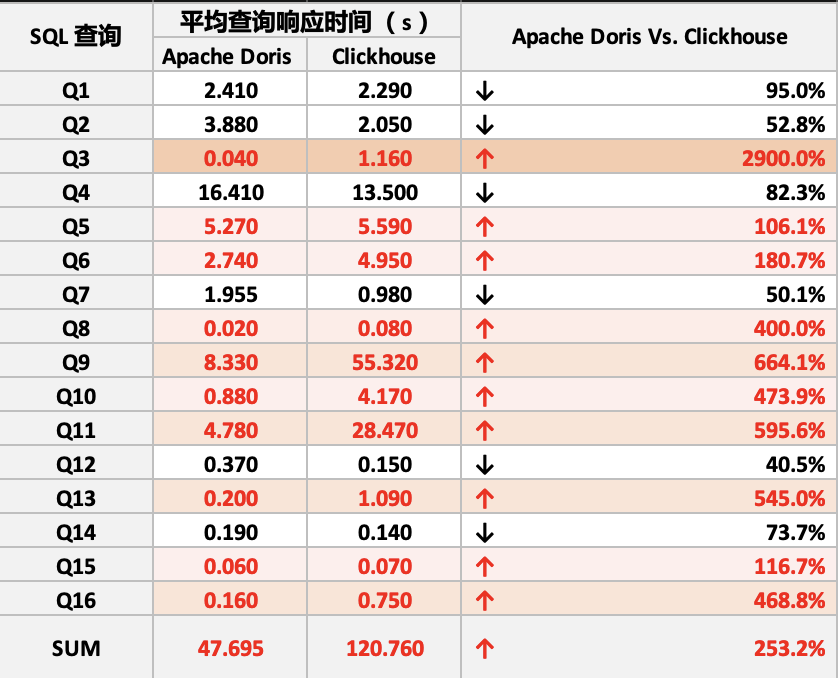
Como se muestra en la tabla, comparamos el tiempo de 16 consultas SQL entre Doris y Clickhouse, entre ellas, el rendimiento de 10 consultas SQL de Doris fue mejor que el de Clickhouse. Además, comparamos más a fondo el tiempo total de consulta de Doris y Clickhouse. Después de optimizar el diseño de la estructura de la tabla de Doris, la velocidad general de consulta de Doris es 2 o 3 veces más rápida que la de Clickhouse.
Prueba de rendimiento de consulta de unión de tabla grande
En la prueba de consulta asociada, según las tablas de datos relevantes en el escenario CDP, seleccionamos datos de la tabla principal y de la tabla de dimensiones de diferentes magnitudes de datos. Los volúmenes de datos de prueba de la tabla principal fueron 4 mil millones de tablas de comportamiento de usuario y 25 mil millones de usuarios respectivamente. tablas, 96 mil millones de tablas de atributos adicionales de usuario; las tablas de dimensiones se basan en kdt_id + user_id, y los niveles de prueba son 1 millón, 10 millones, 50 millones, 100 millones, 500 millones, 1 mil millones y 2,5 mil millones de volúmenes de datos de tablas de dimensiones respectivamente. Para realizar una prueba más completa, la prueba de consulta de asociación se divide en dos tipos: asociación completa y asociación filtrada. La asociación completa consiste en unir directamente la tabla principal y la tabla de dimensiones. La asociación filtrada consiste en unir el mismo nivel de la tabla principal y agregar condiciones para el WHEREfiltro especificado por dos ID de tienda.
El rendimiento de la prueba de consulta específica es el siguiente:
- Totalmente relacionado 4 mil millones: en la consulta totalmente relacionada de 4 mil millones de tablas principales, el rendimiento de la consulta de Doris es mejor que el de Clickhouse . A medida que aumenta el tamaño de los datos de la tabla de dimensiones, la diferencia en el tiempo de consulta entre Doris y Clickhouse se hace mayor. Doris puede alcanzar un máximo de 5 Doble mejora del rendimiento;
- Filtre la asociación de tienda especificada a 4 mil millones: en la consulta de asociación de condición de filtro,
WHERElos datos filtrados por la tabla principal de acuerdo con las condiciones son 41 millones. En comparación con Clickhouse, Doris puede lograr una mejora de rendimiento de 2 a 3 veces cuando el volumen de datos de la tabla de dimensiones es pequeño., Cuando el volumen de datos de la tabla de dimensiones es grande, el rendimiento mejora más de 10 veces . Cuando la tabla de datos de dimensiones supera los 100 millones, Doris aún puede realizar consultas de manera estable, mientras que Clickhouse provoca fallas en la consulta debido a condiciones OOM. - Totalmente relacionado 25 mil millones: cuando la tabla de 25 mil millones de 50 campos de ancho está completamente relacionada como la tabla principal, el rendimiento de consulta de Doris sigue siendo mejor que el de Clickhouse. Doris puede superar en todos los tamaños de tabla de dimensiones, mientras que Clickhouse experimentará OOM después superando los 50 millones. ;
- 25 mil millones asociados con la tienda especificada filtrada: en la consulta de asociación condicional, la tabla principal filtra los datos según la ID de la tienda a 570 millones. El tiempo de respuesta de la consulta de Doris alcanza el segundo nivel, y el tiempo de respuesta más rápido de Clickhouse también toma minutos . Es aún más imposible quedarse sin datos cuando la cantidad de datos es grande.
- La correlación completa y el filtrado especifican la correlación de la tienda 96 mil millones: ya sea una consulta de correlación de la tabla principal o una consulta de correlación condicional, Doris puede ejecutarse y responder rápidamente, mientras que Clickhouse no puede quedarse sin datos en todos los niveles de la tabla de dimensiones.
Además del rendimiento de la respuesta, también probamos el consumo de memoria y CPU de Doris y descubrimos que la carga del clúster de Doris se mantuvo estable a pesar de decenas de miles de millones de consultas relacionadas con tablas grandes. En resumen, la velocidad de respuesta de consultas de Apache Doris es más rápida que la de Clickhosue en la mayoría de los escenarios, especialmente en el escenario de unión de tablas grandes, el rendimiento de Apache Doris es completamente mejor que el de Clickhouse .
03 Prueba de estabilidad de reproducción del tráfico en línea de Clickhouse
Una vez completada la prueba de estrés de la consulta, comenzamos a ejecutar Doris y Clickhouse en línea para verificar aún más la estabilidad de Doris. Los pasos específicos son los siguientes:
- Recopile información de consulta válida de Clickhouse cuyo estado de consulta sea QueryFinish en el último minuto a través de la recopilación regular.
- Informe la información de la consulta a Kafka y luego consuma el tema de Kafka a través de Flink para obtener el SQL de consulta de Clickhouse y compilar estadísticas sobre los resultados.
- La implementación de UDF en Flink convierte la consulta SQL de Clickhouse en la consulta SQL de Doris y la ejecuta mediante JDBC.
- Obtenga resultados de ejecución y resultados estadísticos, compárelos con la información de ejecución de Clcikhouse y finalmente guárdelos en RDS.
- Finalmente, a través de las estadísticas de reproducción del tráfico de consultas en línea de Clickhouse, se analiza el rendimiento de las consultas de Doris y la precisión de los datos de las consultas.

04 Pruebas y optimización del rendimiento de importación de datos de Apache Doris
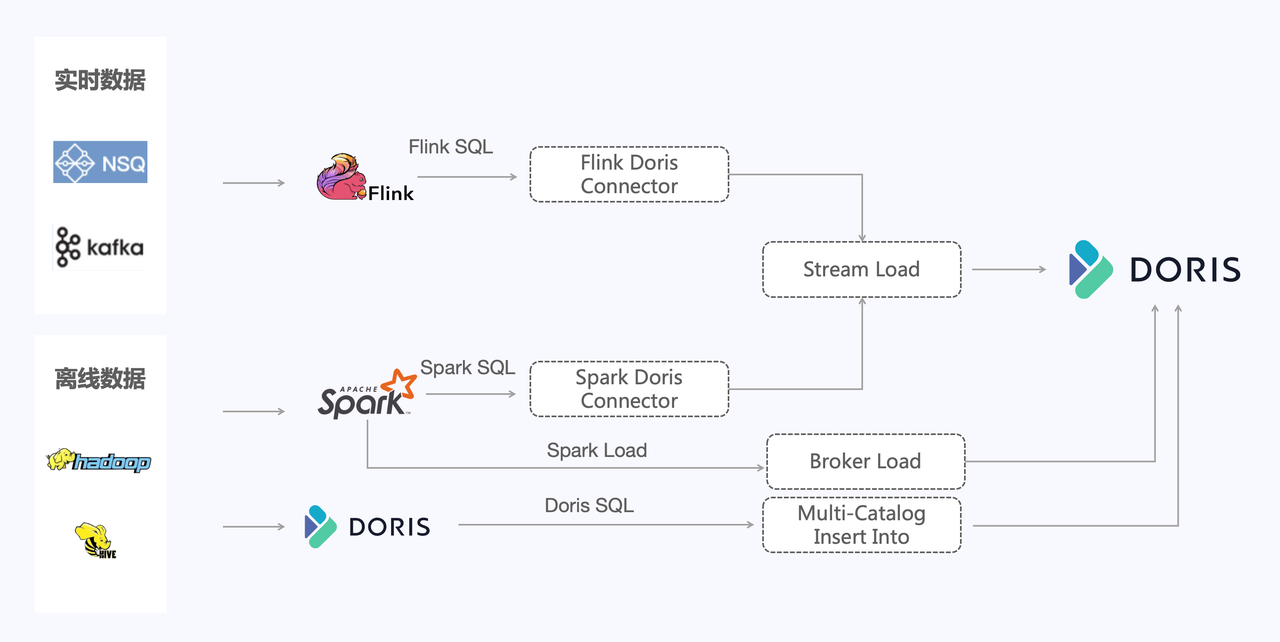
Las pruebas de rendimiento de importación de datos son una de nuestras áreas importantes de preocupación. El propio Apache Doris proporciona un método de importación relativamente rico para la importación de datos en tiempo real y datos fuera de línea. El método de importación de datos en tiempo real consiste principalmente en utilizar Apache Flink para importar NSQ. y datos de Apache Kafka en tiempo real. Escriba en Apache Doris a través del método Stream Load. Doris proporciona múltiples métodos de importación para datos sin conexión:
- Admite la lectura de datos externos a través de Spark SQL y la escritura en Apache Doris a través de Stream Load;
- Admite el método Spark Load , utiliza recursos del clúster Spark para completar la operación de clasificación de datos en HDFS y luego escribe los datos en Doris a través de Broker Load;
- Admite la función Doris Multi-Catalog para leer directamente fuentes de datos externas y escribir en Doris mediante Insert Into.
Debido a la gran cantidad de datos fuera de línea, realizamos pruebas de rendimiento y comparaciones de varios métodos de importación de datos para este tipo de datos, y probamos el tiempo de importación comparando varios niveles de datos detallados. Tamaño del clúster de prueba 3 FE + 16 BE, la configuración de nodo único BE es (32C 128 G 7T SSD) resultados de la prueba:
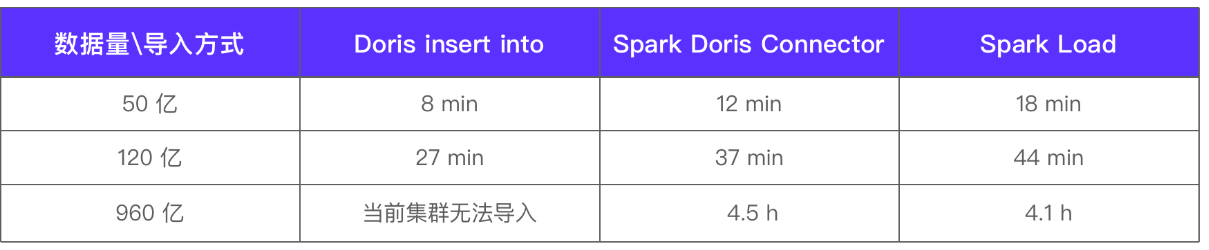
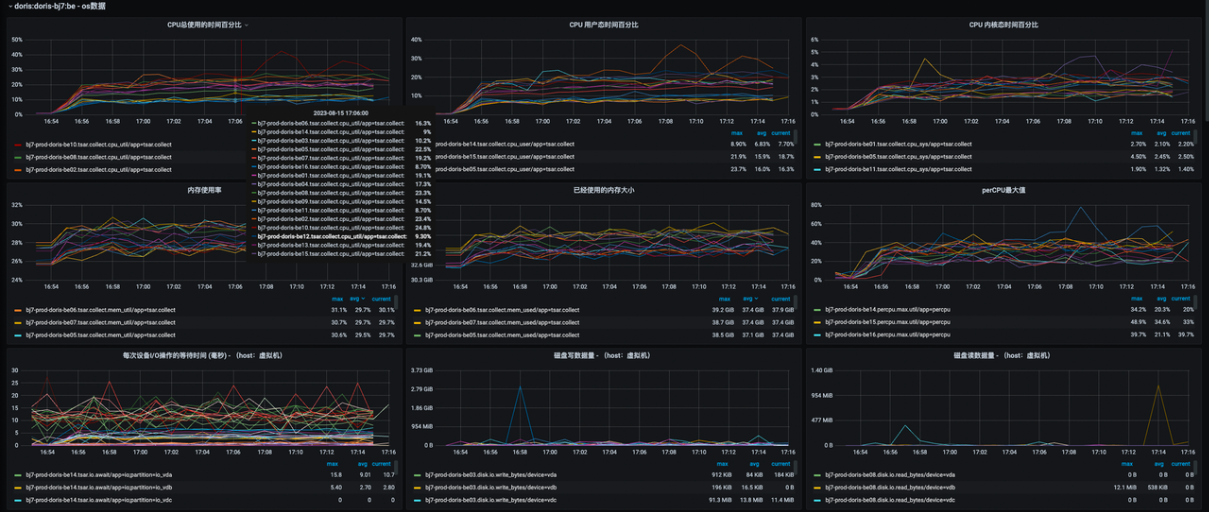
El grado de paralelismo de la importación del formato Spark Doris Connector es 80 y el lote único es 1 millón. La carga del clúster es la siguiente:
Con base en los resultados de las pruebas anteriores, analizamos más a fondo las ventajas de varios métodos de importación y las soluciones de ajuste posteriores. Esperamos que las siguientes prácticas de ajuste puedan ayudar a los desarrolladores con necesidades similares:
Doris Insertar En
El método Insert Into puede proporcionar un rendimiento derivado rápido y es relativamente simple de usar. Actualmente, el rendimiento de importación de este método es suficiente para satisfacer nuestras necesidades comerciales.
Spark Doris Connector admite el bloqueo de escrituras
El método de importación Spark Doris Connector es más versátil y puede resolver el problema de la importación de grandes cantidades de datos. El rendimiento de la importación es relativamente estable. Durante el proceso de importación, necesitamos controlar razonablemente la tasa de importación y el paralelismo de la importación. Teniendo en cuenta que nuestro escenario empresarial implica cientos de miles de millones de datos cada día y su importación tarda entre 5 y 6 horas, si la importación de datos de tablas tan grandes falla porque se rechazan las escrituras BE, provocará retrasos en la salida de datos posteriores y otros problemas. Además, en la versión 2.0, errores como -235 y -238 se han solucionado en el nivel del kernel de Apache Doris, eliminando la necesidad de que los usuarios solucionen dichos problemas manualmente.
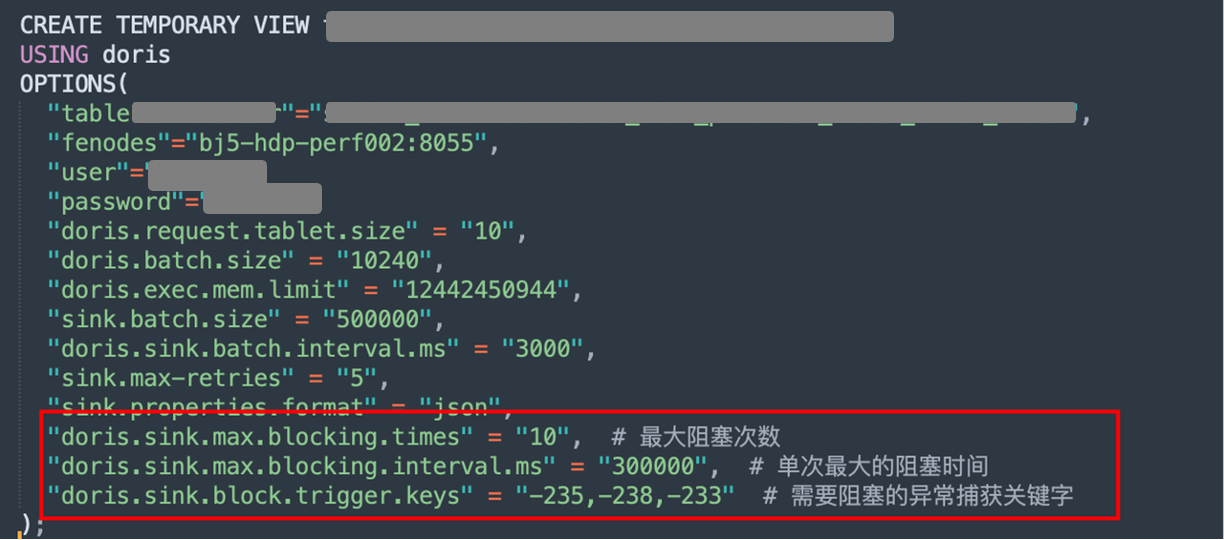
Comenzamos principalmente controlando la velocidad de escritura. El principio general de transformación es retrasar el bloqueo mediante escritura de retroceso exponencial y usar parámetros de configuración para esperar el reintento cuando ocurre una excepción de importación en grandes cantidades de datos, para evitar que la tarea falle. Los tres parámetros de tiempos máximos de bloqueo, tiempo máximo de bloqueo único y palabras clave de captura de excepciones de bloqueo se utilizan para capturar excepciones de bloqueo e implementar la función de retroceso de bloqueo. Finalmente, bajo esta configuración, nuestra tasa de éxito en la importación de datos en tablas grandes alcanzó más del 95%.
[1] Relaciones públicas relacionadas: https://github.com/apache/doris-spark-connector/pull/117
Spark Doris Connector admite la importación de datos de mapa de bits
Al leer la documentación oficial de Apache Doris, descubrimos que el método Spark Load puede importar datos de mapa de bits y, al mismo tiempo, el cálculo de los datos de mapa de bits se puede colocar en el clúster de Spark para su cálculo. En la práctica empresarial, utilizamos Spark Doris Connector con más frecuencia, por lo que comenzamos a explorar la importación de datos de mapa de bits a través de Spark Doris Connector.
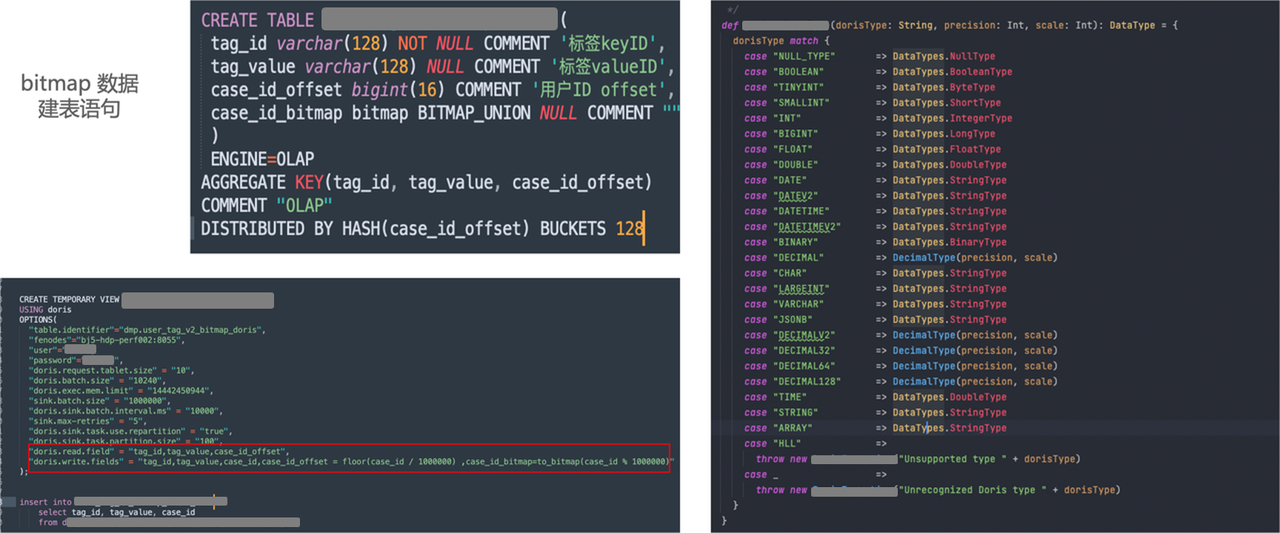
Como se muestra en la figura anterior, la declaración de creación de la tabla de mapa de bits se divide principalmente en tres campos, de los cuales el último campo es el cálculo del mapa de bits de CASE_ID. Después de comunicarnos con los miembros de la comunidad, ofrecemos una opción para configurar Doris Read Field, escribir otras columnas excepto las columnas de mapa de bits y realizar el procesamiento de mapeo en Doris Write Field. La implementación final es como se muestra en la figura anterior, importando directamente datos detallados de Apache Hive a los datos de mapa de bits de Apache Doris a través de Spark Doris Connect.
Optimización de importación de formato CSV de Spark Doris Connector
En nuestro proceso de importación, ya sea Spark Doris Connector o Flink Doris Connector, finalmente se importan mediante Stream Load. Los archivos de importación CSV y JSON tienen dos formatos de importación, y la selección de diferentes formatos provocará una pérdida en el rendimiento de la importación. También es diferente de la tasa.
Antes de la optimización, realizamos una prueba de rendimiento de importación en una tabla de negocios con miles de millones de escala de datos y 26 campos. Descubrimos que el formato CSV es casi un 40% más rápido que JSON en velocidad de importación y su consumo de memoria es menor. Apache Doris recomienda oficialmente utilizar el formato CSV.
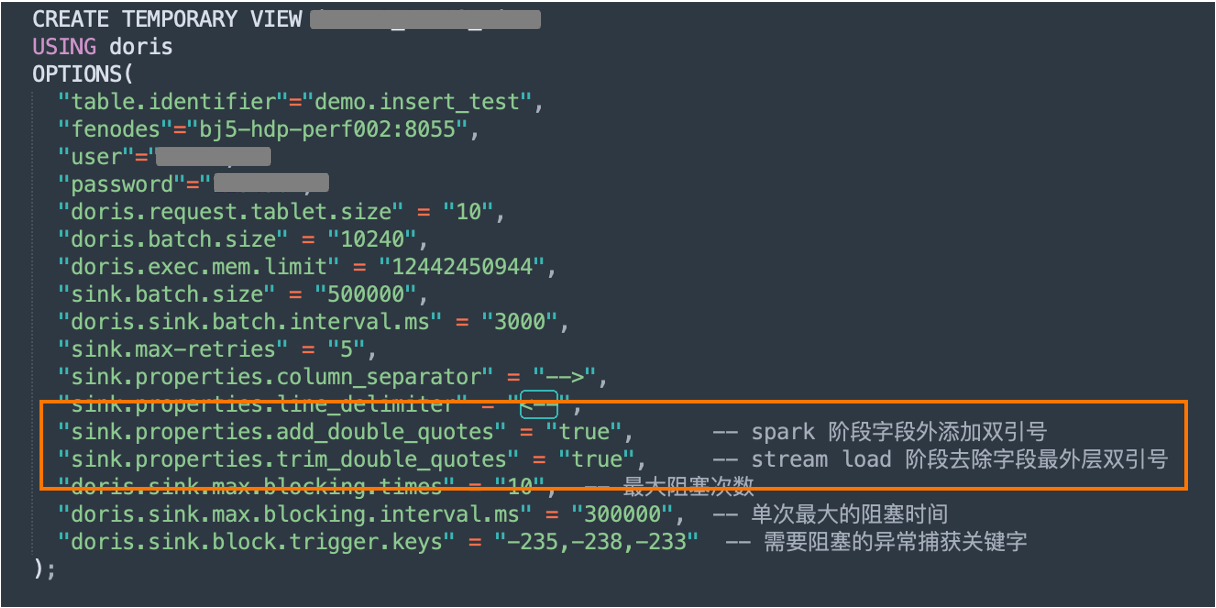
Vale la pena señalar que al importar en formato CSV, establecer delimitadores de campo y saltos de línea razonables es crucial para la eficiencia del reconocimiento de CSV Reader. Al mismo tiempo, el delimitador no se reconoce.
A través de las indicaciones de la documentación oficial, descubrimos que Stream Load puede admitir la configuración de parámetros para eliminar las comillas dobles más externas del campo. En base a esto, decidimos agregar la configuración de configuración del usuario durante la fase de escritura de Spark Doris Connector y unir comillas dobles. en la capa exterior del campo para garantizar que no se utilicen. Los caracteres especiales seleccionados aún se pueden separar de manera efectiva y se agrega una configuración para eliminar las comillas dobles más externas durante la fase de escritura de Stream Load. A través de la configuración en ambos extremos, se puede garantizar que incluso si los datos comerciales son muy complejos, no hay necesidad de preocuparse por la identificación de los símbolos de campo, lo que garantiza de manera efectiva que los campos se puedan segmentar normalmente.
[2] Relaciones públicas relacionadas: https://github.com/apache/doris-spark-connector/pull/119
Carga de chispa
La característica del método de importación Spark Load es realizar barajar, ordenar y otras tareas basadas en los recursos de Spark y generar los archivos en HDFS. Después de eso, el nodo BE puede leer directamente los archivos en HDFS y escribirlos en formato Doris. Con base en este método, durante el proceso de prueba, descubrimos que cuando la cantidad de datos es mayor, la velocidad de importación es más rápida y los recursos del clúster de Doris se pueden guardar sin causar grandes pérdidas de rendimiento.
Dado que Spark Load se usa con frecuencia en escenarios de datos de reparación temporal, también lo optimizamos aún más según las pruebas. A través de la documentación del sitio web oficial y la ayuda de la comunidad, descubrimos que la tasa de importación en la etapa Spark Load se ve afectada principalmente por dos parámetros: concurrencia de importación única y volumen de procesamiento de datos de importación de BE único, y ambos parámetros están estrechamente relacionados con la fuente. Tamaño del archivo y nodo BE. Al controlar otras variables, cuanto más pequeño sea el archivo fuente, más lenta será la velocidad de importación, por lo que creemos que hacer un uso completo de los recursos operativos de Spark y establecer razonablemente el número de depósitos durante la etapa ETL puede acelerar efectivamente la velocidad de importación.
Planificación y perspectivas futuras
En el proceso de prueba general, se completó la prueba de rendimiento basada en la versión oficial de Apache Doris 2.0. Estamos muy satisfechos con el rendimiento de las consultas de Doris. Además, para el rendimiento de importación, utilizamos por primera vez la versión Doris 2.0-Alpha durante las pruebas y descubrimos que había cuellos de botella de CPU ocasionales durante el proceso de importación. Por ejemplo, cuando usamos Spark Doris Connector, Spark usó recursos y Doris para importar datos de CPU. Hay ciertos obstáculos. Al mismo tiempo, también informamos el problema a la comunidad. Después de la optimización de la comunidad y el lanzamiento de la versión 2.0-Beta, se mejoró la estabilidad.
Actualmente, estamos trabajando con Clickhouse para verificar aún más la estabilidad de Doris a través de la doble ejecución en línea. Al mismo tiempo, estamos optimizando el rendimiento del método de importación Spark Doris Connector y desarrollando herramientas de importación de periféricos para completar el reemplazo de componentes y otros trabajos de implementación. . Después de completar gradualmente la migración comercial de Clickhouse, con base en la experiencia de migración de Clickhouse, completamos gradualmente la migración de los dos componentes de Druid y Kylin para el negocio de acciones no migradas, y finalmente construimos un análisis extremadamente rápido y un almacén de datos unificado en tiempo real basado en Apache Doris.
Estoy muy agradecido con el equipo técnico de SelectDB por su respuesta positiva y profesional para acelerar el proceso de migración de Youzan Business. También espero que este artículo pueda proporcionar experiencia práctica relevante y referencia de selección de OLAP para las empresas que se preparan para migrar su arquitectura. Finalmente, continuaremos participando en actividades comunitarias y contribuyendo con resultados relevantes a la comunidad. ¡Esperamos que Apache Doris se desarrolle rápidamente y mejore cada vez más!
Referencia de relaciones públicas de GitHub:
[1] Spark Doris Connector admite el bloqueo de escrituras
https://github.com/apache/doris-spark-connector/pull/117
[2] Optimización de importación de formato CSV de Spark Doris Connector
https://github.com/apache/doris-spark-connector/pull/119
[3] Spark Load crea la apariencia de Hive para admitir la configuración de la versión de Hive
https://github.com/apache/doris/pull/20622
[4] Optimización de adquisición de variables de entorno del sistema Spark Load
https://github.com/apache/doris/pull/21837
[5] Los atributos de apariencia de Hive no tienen efecto en la optimización de Spark Load