El blog [ejemplo de módulo opencv dnn (3) detección de objetivos object_detection (2) detección de objetos YOLO] probó yolov3 y series de modelos anteriores, como se muestra en el blog [ejemplo de módulo opencv dnn (15) la versión opencv4.2 dnn admite aceleración cuda (excepción vs2015) Solución)] explica cómo usar el módulo dnn para la inferencia acelerada CUDA.
Este artículo explica las mejoras de red y las pruebas de yolo v4.
Directorio de artículos
1. Introducción
Joseph Redmon, autor de yolo v1~v3, anunció a principios de 2020 que detendría toda investigación de CV porque sus algoritmos de código abierto se han utilizado en cuestiones militares y de privacidad, lo que ha supuesto una gran prueba para su ética. Su retirada es una llamada de atención para la comunidad académica con respecto a la ética de la IA. saludo…
Como sucesor de la serie YOLO, el maestro ruso AlexAB lanzó YOLOv4 dos meses después de que Redmon anunciara que dejaría de actualizar Yolo. Cuando probamos el algoritmo YOLO en Windows, utilizamos la versión del proyecto de código abierto darknet de AlexAB.
Primero, revisemos la red Yolo v3. Toda la red troncal Backbone es Darkent53 y contiene 53 capas convolucionales (la capa fc completamente conectada se usa para la clasificación de imágenes y se ha eliminado aquí); el cabezal de salida contiene tres escalas. Cuando la entrada es 608*608, son 19*19, 38*38 y 76*76 respectivamente.
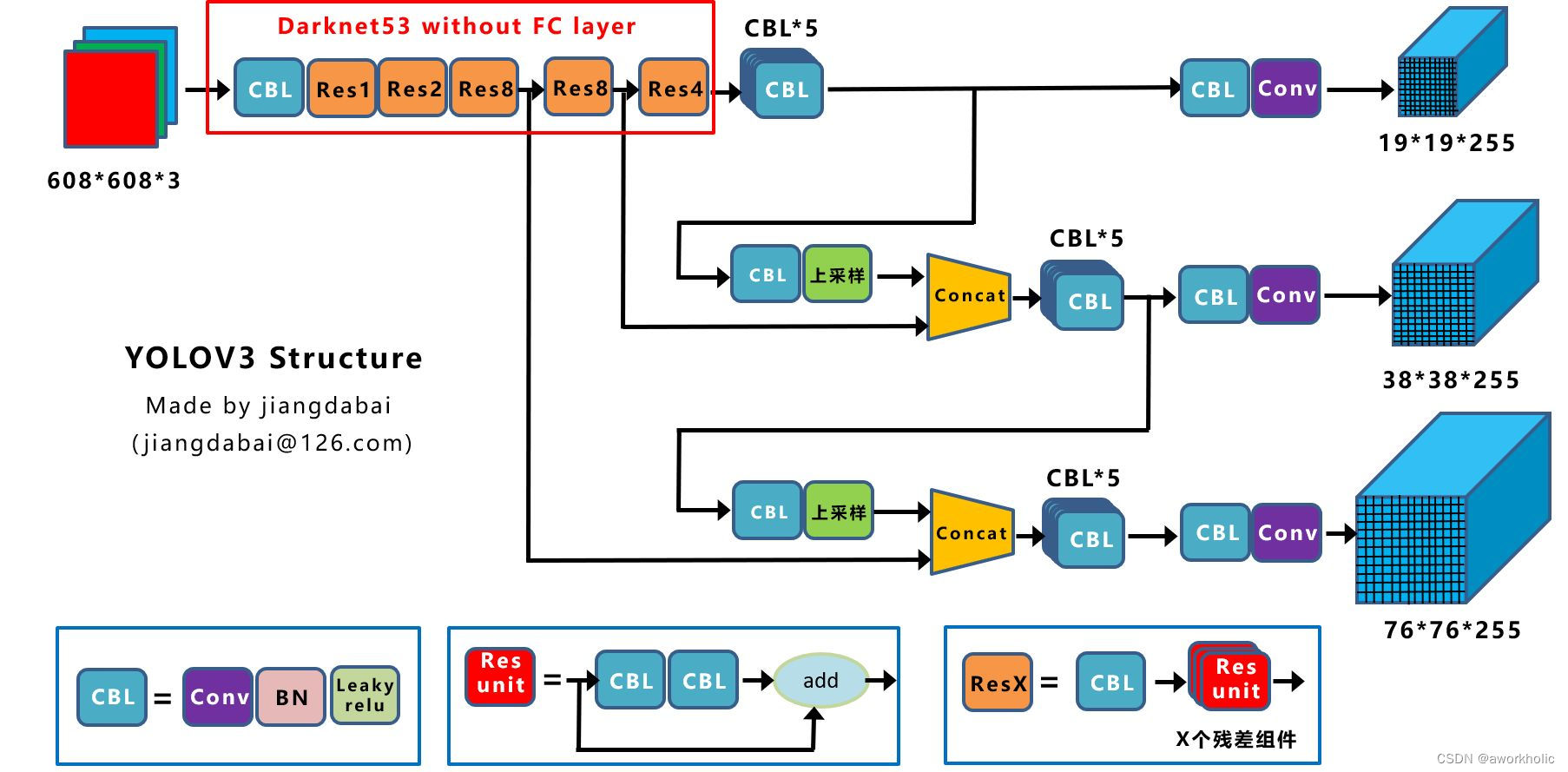
CBL es el componente más pequeño en la estructura de red de Yolov3;
Res Unit se basa en la estructura residual de Resnet para construir una red más profunda;
ResX es un componente grande de Yolov3. CBL realiza un proceso de reducción de resolución antes de cada módulo Res, ingresando una imagen de 60*608 Después de 5 veces del módulo Res, el mapa de características obtenido es 608->304->152->76->38->19.
Concat : La concatenación de tensores expandirá las dimensiones de dos tensores. Por ejemplo, cuando se concatenan dos tensores 26*26*256 y 26*26*512, el resultado es 26*26*768. Concat tiene la misma función que la ruta en el archivo cfg. Se aumenta el muestreo del mapa de características del campo receptivo grande para obtener el mismo tamaño que el mapa de características del campo receptivo pequeño, y las dimensiones se empalman para lograr el propósito de la fusión de características de múltiples escalas, mejorando así la capacidad de detección de objetivos pequeños. .
add : Agrega tensores. Los tensores se agregan directamente sin expandir la dimensión. Por ejemplo, si se agregan 104*104*128 y 104*104*128, el resultado sigue siendo 104*104*128. La función de agregar es la misma que el acceso directo en el archivo cfg.
2、Yolo v4
Idea central :
yolov4 ha analizado algunos trucos que se han utilizado en varios detectores desde el lanzamiento de yolov3 para mejorar la precisión de la detección y los ha combinado con algoritmos adecuadamente innovadores para lograr un equilibrio perfecto entre velocidad y precisión. Si bien existen muchos trucos para mejorar la precisión de las redes neuronales convolucionales (CNN), algunos trucos solo son adecuados para ejecutarse en ciertos modelos, o solo en ciertos problemas, o solo en pequeños conjuntos de datos.
Principales métodos de ajuste :
conexión residual ponderada (WRC), conexión parcial entre etapas (CSP), normalización entre mini lotes (CmBN), entrenamiento autoadversario (SAT), activación de Mish, mejora de datos en mosaico, CmBN, regularización DropBlock, Pérdida de CIoU, etc. Después de una serie de apilamiento, finalmente se logró el resultado experimental óptimo actual: 43,5% AP (en Tesla V100, la velocidad en tiempo real del conjunto de datos MS COCO es de aproximadamente 65 FPS).
2.1 Estructura de la red
En comparación con la red Darknet53, la red troncal de YoloV4 usa CSPDarknet53, como se muestra a continuación
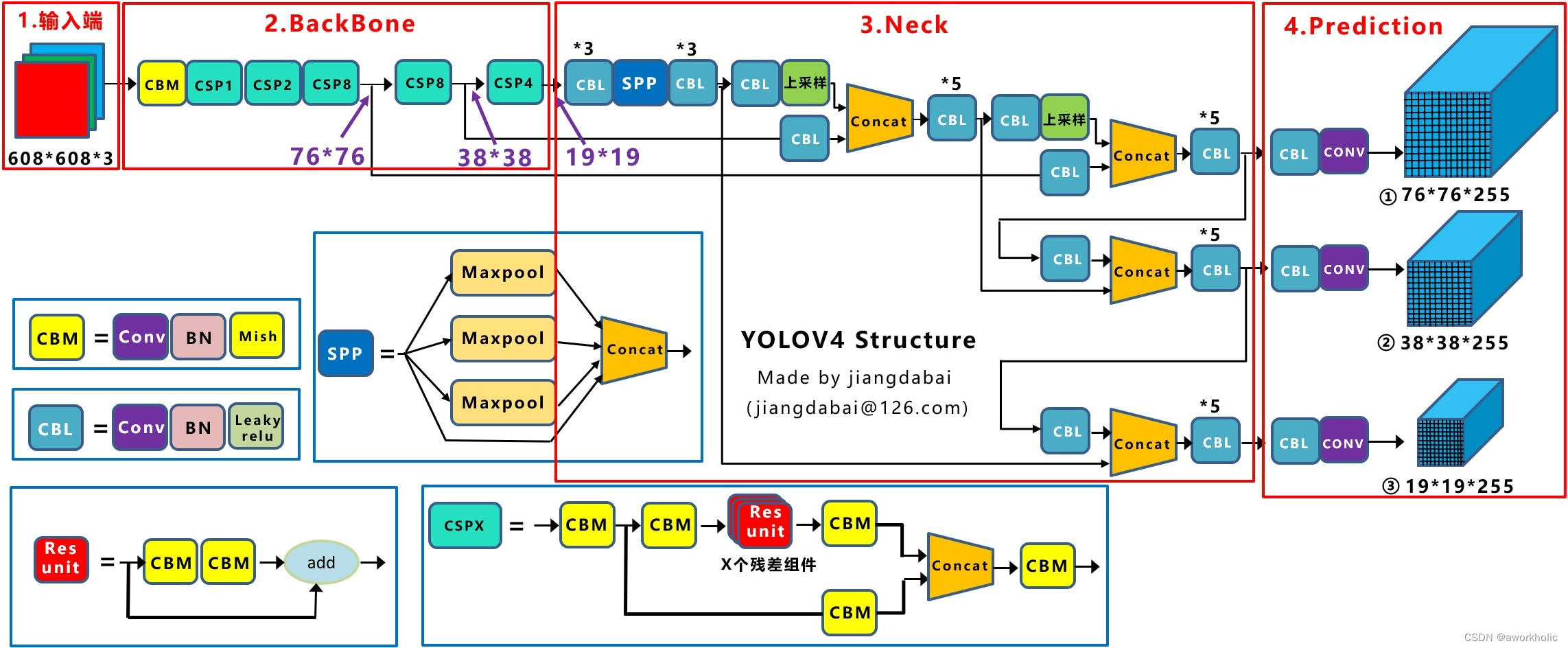
Principales diferencias:
(1) Combine el Darknet53 original con CSPNet para formar una red Backbone.
(2) SPPNet se usa para adaptarse a tamaños de imágenes de entrada de diferentes tamaños y puede aumentar el campo receptivo; (
3) SAM se usa para introducir un mecanismo de atención espacial;
(4) PANet se usa para aprovechar al máximo la fusión de características;
( 5) La función de activación se reemplaza por MIsh Leaky ReLU; en yolov3, cada capa convolucional contiene una capa de normalización por lotes y un Leaky ReLU. En la red troncal CSPDarknet53 de yolov4, Mish se utiliza para reemplazar el Leak ReLU original.
2.1.1 Redes parciales entre etapas (CSPNet)
En 2019, se propuso resolver el problema de la información de gradiente repetida en la optimización de la red y obtuvo buenos resultados de prueba en el conjunto de datos ImageNet y el conjunto de datos MS COCO. Es fácil de implementar y se puede utilizar universalmente en estructuras de red ResNet, ResNeXt y DenseNet.
La estructura CSPNet logra combinaciones de gradientes más ricas y reduce la cantidad de cálculo: el mapa de características de la capa básica se divide en dos partes: (1) la parte principal continúa apilando los bloques residuales originales; (2) la parte de la rama es equivalente a a residual Los bordes se conectan directamente al final después de una pequeña cantidad de procesamiento.
Insertar descripción de la imagen aquí
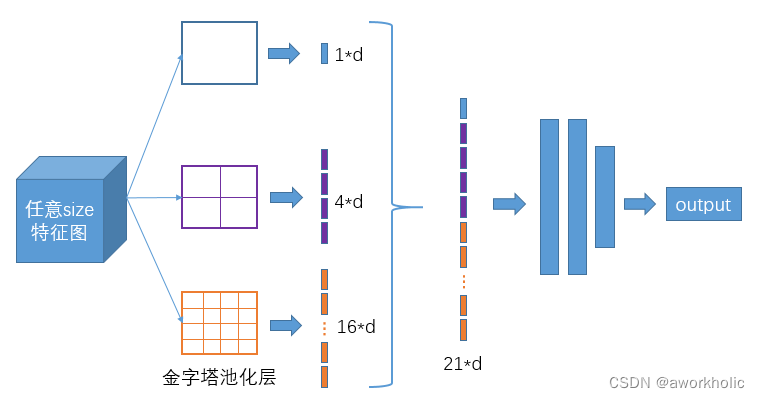
2.1.2 Red de agrupación de pirámides espaciales (SPPNet)
Fondo de Yolov1: La resolución de yolov1 durante el entrenamiento: 224×224; durante la prueba: 448×448.
Antecedentes de Yolov2: Yolov2 mantiene el funcionamiento de yolov1 sin cambios, pero agrega (10 épocas) muestras de alta resolución de 448 × 448 al entrenamiento original para un ajuste fino, de modo que las características de la red se adapten gradualmente a la resolución de 448 × 448; luego use Muestras de 448 × 448 para pruebas, lo que alivia el impacto del cambio repentino de resolución.
Propósito: La imagen de entrada del modelo de red ya no tiene un límite de tamaño fijo. La agrupación máxima se utiliza para hacer que las imágenes de entrada de diferentes tamaños sean consistentes en tamaño.
Ventajas: Mayor campo receptivo.
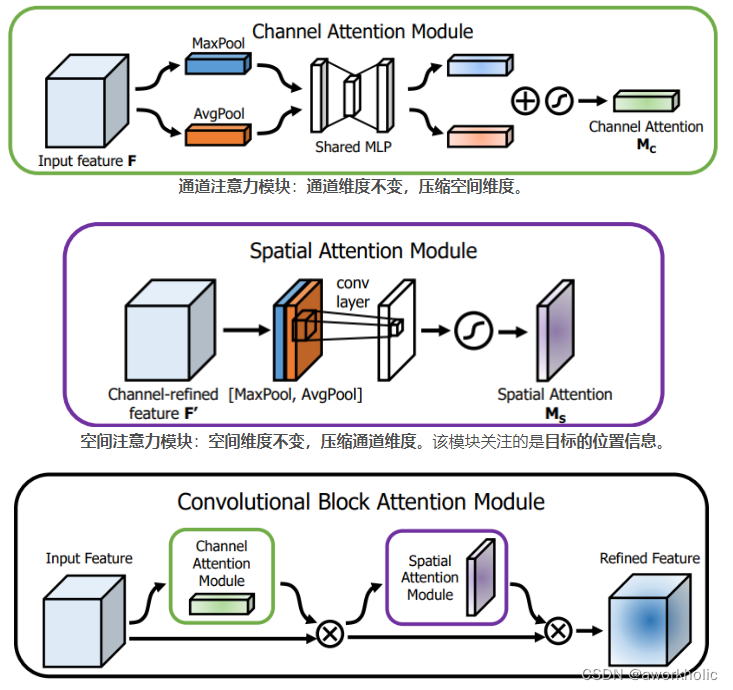
2.1.3 Módulo de Atención Espacial (SAM)
yolov4 adopta un método SAM mejorado: Módulo de atención de canal (CAM) -> SAM (Módulo de atención espacial) -> CBAM (Bloque convolucional AM) -> SAM mejorado
-
Mecanismo de atención del mapa de características (Módulo de atención del canal) : en la dimensión del canal, agregue un peso a cada mapa de características (canal), luego obtenga el valor de probabilidad correspondiente a través del sigmoide y finalmente multiplique la imagen de entrada, que es equivalente a las características del imagen de entrada El gráfico está ponderado, es decir, atención.
Por ejemplo: 32×32×256, ponderación de 256 canales. -
Mecanismo de atención espacial (Módulo de atención espacial) : en la dimensión espacial, agregue un peso a cada posición espacial (espacial), luego obtenga el valor de probabilidad correspondiente a través del sigmoide y finalmente multiplíquelo por la imagen de entrada, que es equivalente a todas las posiciones de las características de la imagen de entrada están ponderadas, es decir, atención.
Por ejemplo: 32×32×256, para cualquier posición espacial
Razones para la optimización:
(1) Dado que el cálculo de CBAM es complejo y requiere mucho tiempo, y el punto de partida de yolo es la velocidad, solo calcula el mecanismo de atención de la posición espacial.
(2) La capa de agrupación máxima y la capa de agrupación promedio SAM convencionales actúan sobre el mapa de características de entrada respectivamente para obtener dos conjuntos de mapas de características con la misma forma y luego ingresan los resultados en una capa convolucional. El proceso es demasiado complicado, por lo que yolo utiliza convolución directa para simplificarlo.
2.1.4 Red de agregación de rutas (PANet)
Antecedentes: PANet se publicó en CVPR2018, fue el campeón de la competencia de segmentación de instancias COCO2017 y el segundo lugar en la competencia de detección de objetivos.
Método específico: yolov4 adopta el método PANet mejorado
Proceso de optimización: FPNet (Feature Pyramid Networks) -> PANet (Path Aggregation Network) -> PAN mejorado
Razones para la optimización:
(1) La red FPNet adopta un enfoque de arriba hacia abajo, integrando características de alto nivel con características de nivel medio alto, nivel medio, medio inferior y nivel bajo capa por capa. La desventaja es que no se puede realizar la fusión ascendente y PANet ha optimizado esta parte. Consulte la parte (b) del diagrama esquemático para obtener más detalles.
(2) FANet adopta el método de fusión de adición de características, mientras que yolo adopta el método de fusión de empalme de características. La suma puede obtener un mapa de características mejorado, pero el peso de la característica no es mayor que 1, mientras que el empalme puede producir un mapa de características mayor que 1.
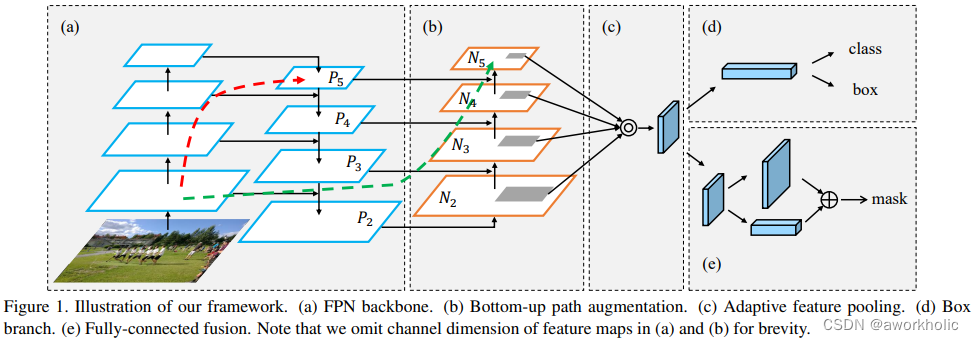
(a) FPNet: mejore el efecto de la detección de objetivos fusionando características de alto nivel.
(b) Aumento de ruta de abajo hacia arriba: mejore el efecto de detección de objetivos fusionando características de bajo nivel (formas de bordes, etc.).
(c) Agrupación de funciones adaptativas: uso de la fusión de funciones de empalme. En comparación con la suma, el empalme tiene características más obvias y puede mejorar los resultados de detección.
d) Rama de caja: Ramas de categoría y posicionamiento.
(e) Fusión totalmente conectada: se utiliza para la predicción a nivel de píxel en la segmentación.
2.1.5 Función de activación de Mish
Mish no se trunca completamente en valores negativos, lo que permite que fluyan gradientes negativos relativamente pequeños. En el experimento, a medida que aumenta la profundidad de la capa, la precisión de la función de activación ReLU disminuye rápidamente, mientras que la función de activación Mish tiene un rendimiento deficiente en términos de estabilidad del entrenamiento, precisión promedio (1% -2,8%) y precisión máxima (1,2%). - 3,6%). Hay una mejora general.
2.2 Mejoras
Estrategia de entrenamiento BackBone: mejora de datos, entrenamiento de autoconfrontación, regularización DropBlock, suavizado de etiquetas de clase, función de pérdida CIoU, DIoU-NMS, etc.
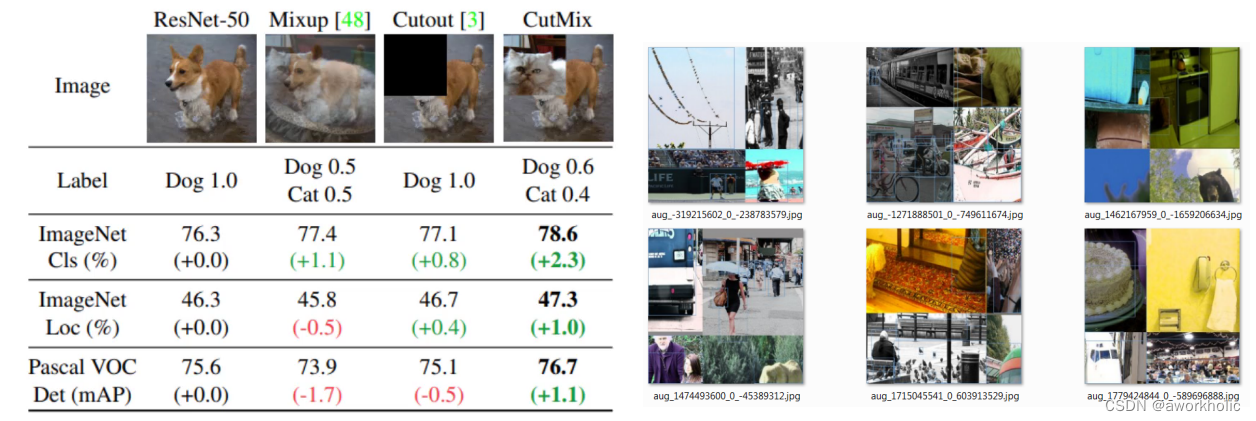
2.2.1 Mejora de datos de mosaico + mejora de datos de CutMix
La característica más importante: yolov4 puede completar el entrenamiento con una sola CPU, sin tener que preocuparse por problemas del equipo.
Métodos específicos:
11. Utilice métodos de mejora de datos comúnmente utilizados (como brillo, saturación, contraste; escala aleatoria, rotación, volteo, etc.) para realizar la mejora de datos en todas las imágenes 22. Utilice el método de mejora de datos CutMix
. Vea los detalles abajo.
33. Adopte el método de mejora de datos en mosaico, es decir, seleccione cuatro imágenes al azar y empalme en una sola.
2.2.2 Entrenamiento de autoadversidad (SAT)
En la primera etapa: sobre la base de la imagen original, se agrega ruido y se establecen umbrales de peso, lo que permite que la red neuronal se entrene para ataques adversarios.
En la segunda etapa: entrene la red neuronal para detectar el objetivo utilizando métodos normales.
Nota: Para obtener más información, consulte el Método de símbolo de gradiente rápido (FGSM) contra ataques adversarios.
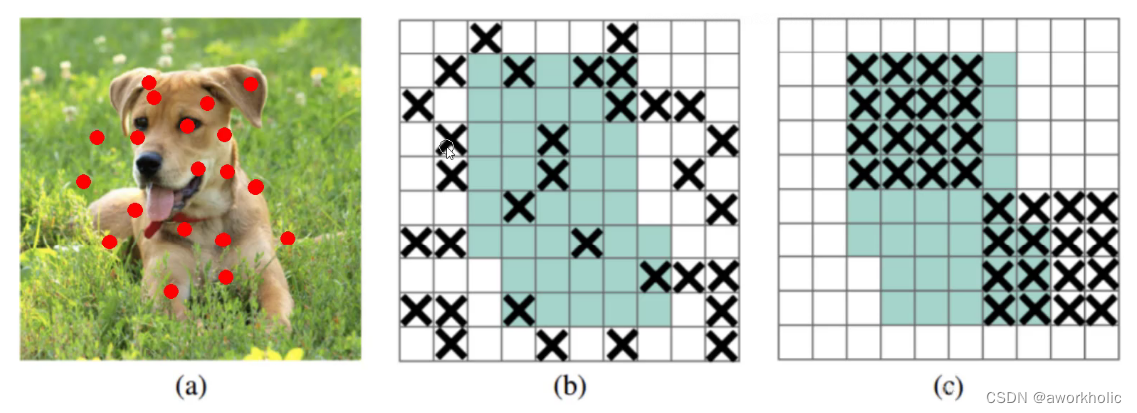
2.2.3 Abandono mejorado (DropBlock)
El abandono anterior era eliminar algunos puntos al azar, pero ahora es eliminar todo el bloque.
Imagen b: la eliminación elimina aleatoriamente algunas neuronas (como los puntos rojos en la imagen a), pero para toda la imagen, el efecto no es obvio. Por ejemplo: si se eliminan los ojos, todavía podemos aproximarnos al reconocimiento a través de las características periféricas de los ojos (esquinas de los ojos, ojeras, etc.).
Imagen c: DropBlock elimina aleatoriamente un gran bloque de neuronas. Por ejemplo: elimina toda la oreja izquierda de la cabeza del perro.
2.2.4 Suavizado de etiquetas
Problema: Las etiquetas son absolutas: 0 o 1. Este fenómeno hará que la red neuronal se sobreadapte durante el proceso de entrenamiento.
El método específico: suavizar las etiquetas absolutas (como: [0, 0] ~ [0.05, 0.95]), es decir, los resultados de la clasificación tienen un cierto grado de borrosidad, lo que mejora la capacidad anti-sobreajuste de la red.
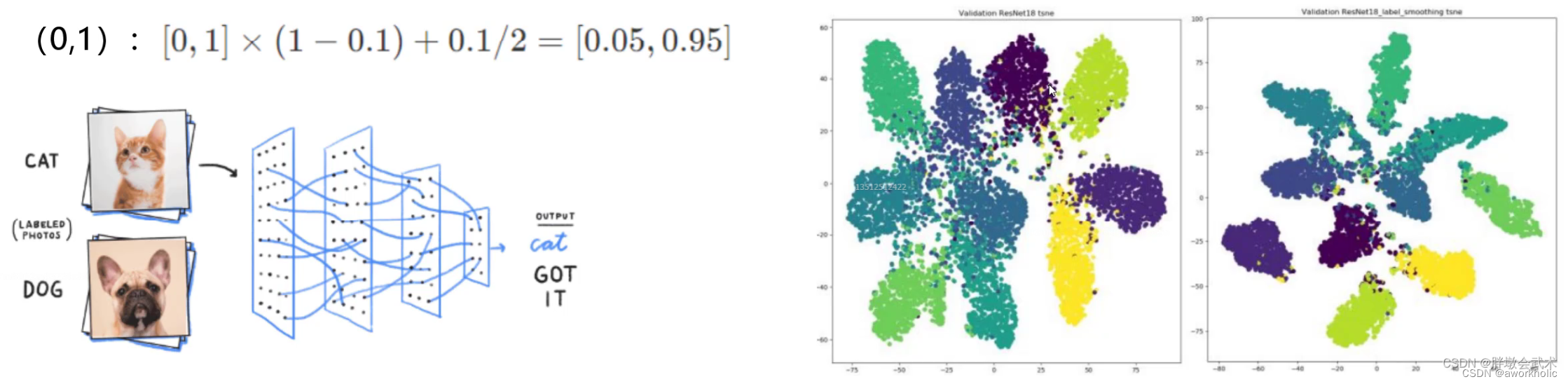
Antes de su uso, los resultados de clasificación son relativamente buenos, pero hay un cierto error entre cada categoría; después del uso, los resultados de clasificación son mejores, la distancia dentro del grupo se vuelve más pequeña y la distancia entre los grupos se hace mayor.
2.2.5, función de pérdida de pérdida de CIoU
Efecto: el uso de la función de pérdida CIoU Loss hace que la regresión del cuadro de predicción sea más rápida y precisa.
Proceso de optimización de pérdidas: pérdida de IOU clásica -> pérdida de GIOU (IoU generalizada) -> pérdida de DIOU (IoU de distancia) -> pérdida de CIOU.
Iou solo considera el área de superposición de los cuadros de destino y las intersecciones. GIou considera el problema de los cuadros delimitadores que no se superponen y puede continuar entrenando sin intersecciones. DIou considera la distancia euclidiana del punto central del cuadro delimitador en función de los anteriores. CIou Considere más a fondo la información de la escala de relación de aspecto.
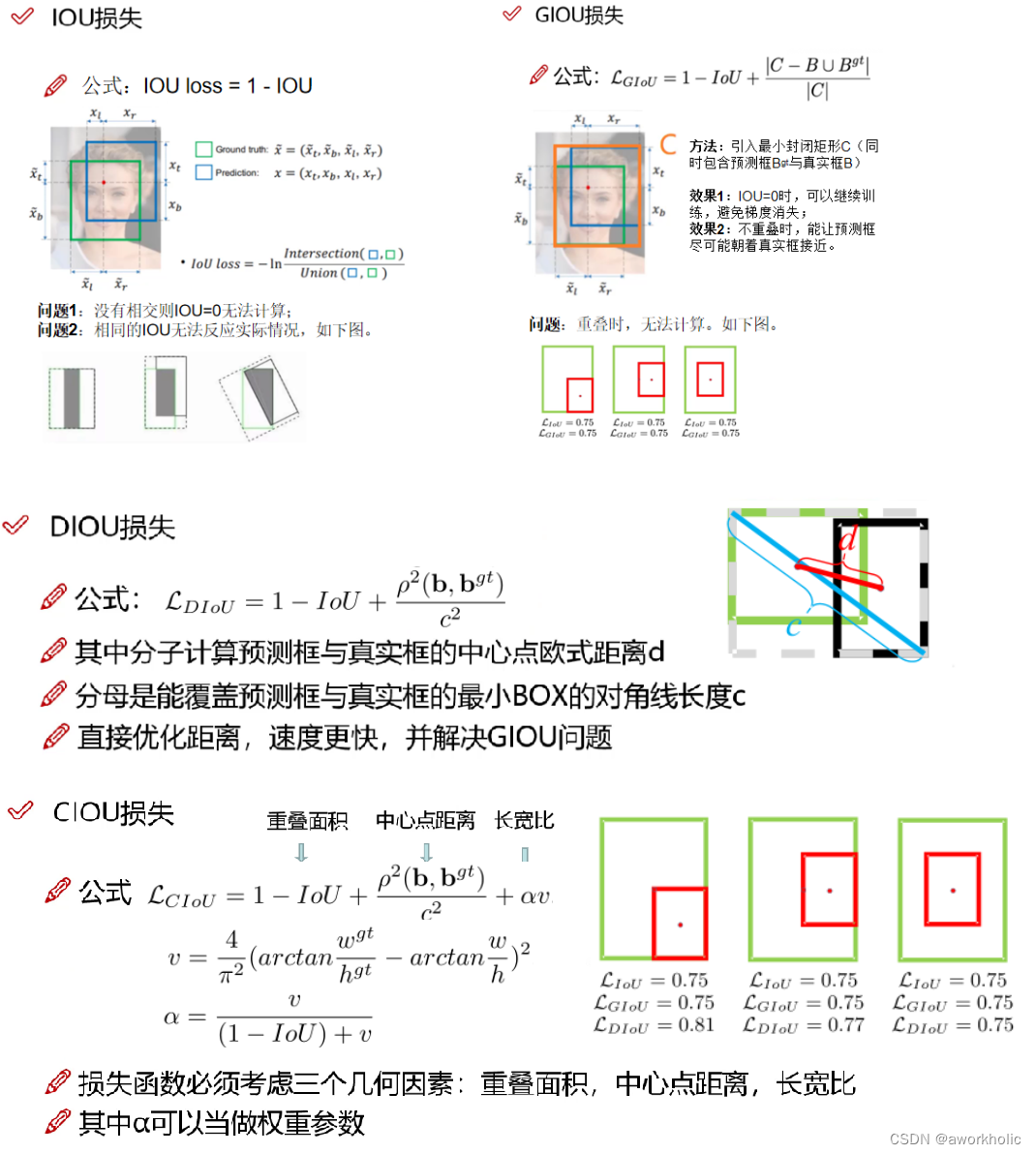
2.2.6、DIoU-NMS
En los resultados de la detección, si hay múltiples cuadros de detección con IOU superiores al umbral de confianza
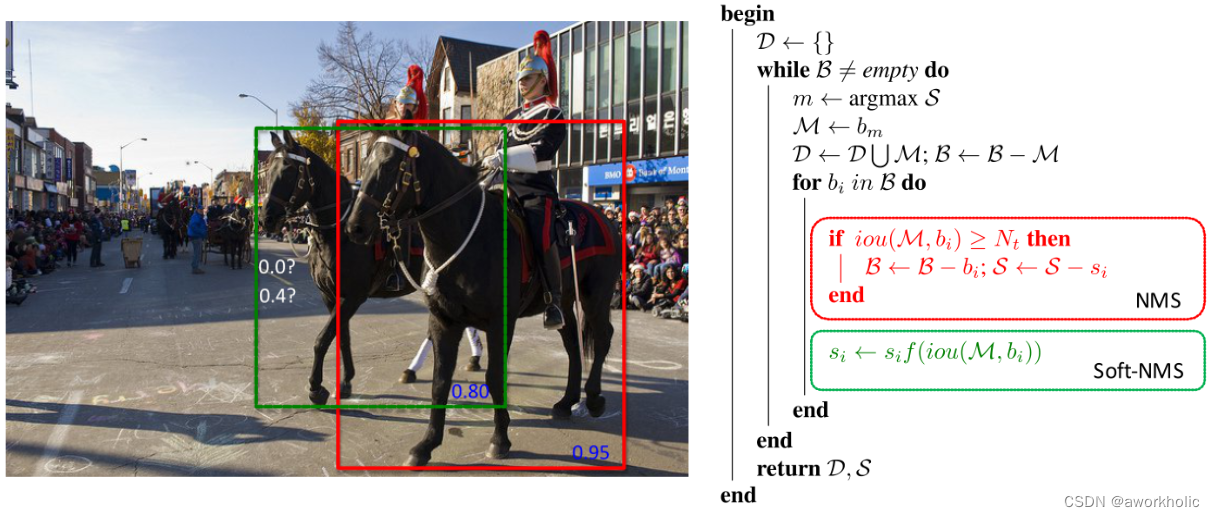
(1) Supresión no máxima de NMS: solo tome el cuadro correspondiente al valor máximo de IoU.
(2) DIoU-NMS: Tome únicamente la casilla correspondiente al valor máximo calculado por la fórmula. Tome el IoU con la mayor confianza y calcule la distancia del punto central entre el cuadro candidato de mayor confianza (M) y todos los demás cuadros (Bi). Ventajas: El efecto de reconocimiento es mejor cuando hay oclusión.
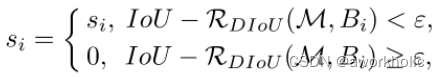
(3) SOFT-NMS: para los cuadros de detección que no cumplen con los requisitos y se superponen en gran medida con el cuadro de detección correspondiente al nivel de confianza máximo, el cuadro de detección no se elimina directamente, pero se reduce el nivel de confianza. Ventajas: mayor tasa de recuperación
3. Prueba
Yolov3 y yolov4 se pueden probar usando el mismo código. Puede consultar [ejemplo de módulo opencv dnn (3) detección de objetivos object_detection (2) detección de objetos YOLO] .
Dirección de introducción y descarga del proyecto https://github.com/AlexeyAB/darknet#pre-trained-models
3.1 Formación
Yolo v4 también utiliza el marco darknet y la capacitación se puede realizar directamente utilizando el script del programa oficial (igual que yolov3).
3.2 Código de prueba
#include <fstream>
#include <sstream>
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace dnn;
float confThreshold, nmsThreshold;
std::vector<std::string> classes;
void postprocess(Mat& frame, const std::vector<Mat>& out, Net& net);
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);
void callback(int pos, void* userdata);
int main(int argc, char** argv)
{
// 根据选择的检测模型文件进行配置
confThreshold = 0.5;
nmsThreshold = 0.4;
float scale = 0.00392;
Scalar mean = {
0,0,0};
bool swapRB = true;
int inpWidth = 416; // 416, 608 ...
int inpHeight = 416;
String modelPath = "../../data/testdata/dnn/yolov4.weights";
String configPath = "../../data/testdata/dnn/yolov4.cfg";
String framework = "";
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_CPU;
int backendId = cv::dnn::DNN_BACKEND_CUDA;
int targetId = cv::dnn::DNN_TARGET_CUDA;
String classesFile = "../../data/dnn/object_detection_classes_yolov4.txt";
// Open file with classes names.
if (!classesFile.empty()) {
const std::string& file = classesFile;
std::ifstream ifs(file.c_str());
if (!ifs.is_open())
CV_Error(Error::StsError, "File " + file + " not found");
std::string line;
while (std::getline(ifs, line)) {
classes.push_back(line);
}
}
// Load a model.
Net net = readNet(modelPath, configPath, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);
std::vector<String> outNames = net.getUnconnectedOutLayersNames();
// Create a window
static const std::string kWinName = "Deep learning object detection in OpenCV";
// Open a video file or an image file or a camera stream.
VideoCapture cap;
cap.open(0);
// Process frames.
Mat frame, blob;
while (waitKey(1) < 0) {
cap >> frame;
if (frame.empty()) {
waitKey();
break;
}
// Create a 4D blob from a frame.
Size inpSize(inpWidth > 0 ? inpWidth : frame.cols,
inpHeight > 0 ? inpHeight : frame.rows);
blobFromImage(frame, blob, scale, inpSize, mean, swapRB, false);
// Run a model.
net.setInput(blob);
if (net.getLayer(0)->outputNameToIndex("im_info") != -1) // Faster-RCNN or R-FCN
{
resize(frame, frame, inpSize);
Mat imInfo = (Mat_<float>(1, 3) << inpSize.height, inpSize.width, 1.6f);
net.setInput(imInfo, "im_info");
}
std::vector<Mat> outs;
net.forward(outs, outNames);
postprocess(frame, outs, net);
// Put efficiency information.
std::vector<double> layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
std::string label = format("Inference time: %.2f ms", t);
putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
imshow(kWinName, frame);
}
return 0;
}
void postprocess(Mat& frame, const std::vector<Mat>& outs, Net& net)
{
static std::vector<int> outLayers = net.getUnconnectedOutLayers();
static std::string outLayerType = net.getLayer(outLayers[0])->type;
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<Rect> boxes;
if (net.getLayer(0)->outputNameToIndex("im_info") != -1) // Faster-RCNN or R-FCN
{
// Network produces output blob with a shape 1x1xNx7 where N is a number of
// detections and an every detection is a vector of values
// [batchId, classId, confidence, left, top, right, bottom]
CV_Assert(outs.size() == 1);
float* data = (float*)outs[0].data;
for (size_t i = 0; i < outs[0].total(); i += 7) {
float confidence = data[i + 2];
if (confidence > confThreshold) {
int left = (int)data[i + 3];
int top = (int)data[i + 4];
int right = (int)data[i + 5];
int bottom = (int)data[i + 6];
int width = right - left + 1;
int height = bottom - top + 1;
classIds.push_back((int)(data[i + 1]) - 1); // Skip 0th background class id.
boxes.push_back(Rect(left, top, width, height));
confidences.push_back(confidence);
}
}
}
else if (outLayerType == "DetectionOutput") {
// Network produces output blob with a shape 1x1xNx7 where N is a number of
// detections and an every detection is a vector of values
// [batchId, classId, confidence, left, top, right, bottom]
CV_Assert(outs.size() == 1);
float* data = (float*)outs[0].data;
for (size_t i = 0; i < outs[0].total(); i += 7) {
float confidence = data[i + 2];
if (confidence > confThreshold) {
int left = (int)(data[i + 3] * frame.cols);
int top = (int)(data[i + 4] * frame.rows);
int right = (int)(data[i + 5] * frame.cols);
int bottom = (int)(data[i + 6] * frame.rows);
int width = right - left + 1;
int height = bottom - top + 1;
classIds.push_back((int)(data[i + 1]) - 1); // Skip 0th background class id.
boxes.push_back(Rect(left, top, width, height));
confidences.push_back(confidence);
}
}
}
else if (outLayerType == "Region") {
for (size_t i = 0; i < outs.size(); ++i) {
// Network produces output blob with a shape NxC where N is a number of
// detected objects and C is a number of classes + 4 where the first 4
// numbers are [center_x, center_y, width, height]
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols) {
Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
Point classIdPoint;
double confidence;
minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold) {
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.cols);
int height = (int)(data[3] * frame.rows);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(Rect(left, top, width, height));
}
}
}
}
else
CV_Error(Error::StsNotImplemented, "Unknown output layer type: " + outLayerType);
std::vector<int> indices;
NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));
std::string label = format("%.2f", conf);
if (!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
}
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine), Scalar::all(255), FILLED);
putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}