Correo electrónico del autor del artículo: [email protected] Dirección: Huizhou, Guangdong
▲ El programa de este capítulo
⚪ Comprender el concepto MLlib de Spark;
⚪ Modelo de datos básicos MLlib de Master Spark;
⚪ Domine los conceptos básicos de las estadísticas MLlib de Spark;
1. Introducción a Spark MLlib
1. Información general
MLlib es una biblioteca de aprendizaje automático iterable para Apache Spark.
2. Fácil de usar
Disponible para lenguajes Java, Scala, Python y R.
MLlib funciona con la API de Spark e interopera con las bibliotecas NumPy (a partir de Spark 0.9) y R (a partir de Spark 1.5) en Python. Puede utilizar cualquier fuente de datos de Hadoop, como HDFS, HBase o archivos locales, lo que facilita la conexión a su flujo de trabajo de Hadoop.
Caso:
// Llama a MLib a través de Python
datos = spark.read.format("libsvm").load("hdfs://...")
modelo = KMeans(k=10).fit(datos)
3. Ejecución eficiente
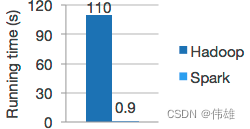
Algoritmo de alta calidad, 100 veces más rápido que MapReduce.
Spark es bueno en cálculos iterativos, lo que permite que MLlib se ejecute rápidamente. Al mismo tiempo, nos centramos en el rendimiento algorítmico: MLlib contiene algoritmos de alta calidad que utilizan iteración y pueden producir mejores resultados que la aproximación de un solo paso que a veces se utiliza en MapReduce. El modelo de datos de Hadoop y Spark se muestra en la siguiente figura.
4. Fácil de implementar
Spark se ejecuta en Hadoop, Apache Mesos, Kubernetes, de forma independiente o en la nube, y se dirige a diferentes fuentes de datos.
Puede ejecutar Spark utilizando su modo de clúster independiente, EC2, Hadoop YARN, Mesos o Kubernetes. Acceda a datos en HDFS, Apache Cassandra, Apache HBase, Apache Hive y cientos de otras fuentes de datos.
5. Algoritmo
MLlib contiene muchos algoritmos y utilidades.
Los algoritmos de ML incluyen:
1. Clasificación: regresión logística, Bayes ingenuo,….
2. Regresión: regresión lineal generalizada, regresión de supervivencia,….
3. Árboles de decisión, bosques aleatorios y árboles potenciados por gradiente.
4. Recomendación: Mínimos cuadrados alternos (ALS).
5. Agrupación: K-medias, mezcla gaussiana (GMM),….
6. Modelado de temas: Asignación Dirichlet Latente (LDA).
7. Conjuntos de elementos frecuentes, reglas de asociación y minería de patrones secuenciales.
Las herramientas de flujo de trabajo de ML incluyen:
1. Transformación de características: normalización, normalización, hash,….
2. Construcción de ML Pipeline。
3. Evaluación del modelo y ajuste de hiperparámetros.
4. Persistencia de ML: Guardar y cargar modelos y Pipelines.
Otras herramientas incluyen:
Álgebra lineal distribuida: SVD, PCA,….
Estadística: estadística resumida, prueba de hipótesis,….
6. Resumen
MLlib es una biblioteca de aprendizaje automático concurrente de alta velocidad construida en Spark, diseñada específicamente para el procesamiento de big data. Se caracteriza por el uso de cálculos de análisis de almacenamiento de memoria y iterativos más avanzados, lo que hace que la velocidad de cálculo y procesamiento de datos sea mucho mayor que la de los datos ordinarios. .motor de procesamiento.
La biblioteca de aprendizaje automático MLlib aún se está actualizando y los investigadores de Apache todavía le están agregando más algoritmos de aprendizaje automático. Actualmente, existen algoritmos de aprendizaje generales y clases de herramientas en MLlib, que incluyen estadística, clasificación, regresión, agrupación, reducción de dimensionalidad, etc.
MLlib está escrito en lenguaje Scala. El lenguaje Scala es un lenguaje de programación funcional que se ejecuta en JVM. Se caracteriza por una gran portabilidad. "Escribir una vez, ejecutar en cualquier lugar" es su característica más importante. Con la ayuda del formato de entrada unificado de datos RDD, los usuarios pueden escribir programas de procesamiento de datos en diferentes IDE y, después de pasar la prueba de localización, pueden ejecutarse directamente en el clúster después de modificar ligeramente los parámetros operativos. La obtención de resultados es más visual e intuitiva, y no habrá diferencias ni cambios en los resultados debido a diferencias en las capas subyacentes del sistema en ejecución.
2. Modelo de datos básico de MLlib
1. Información general
RDD es un formato de datos dedicado a MLlib. Se refiere a las ideas de programación funcional de Scala e introduce audazmente el concepto de análisis estadístico para convertir datos almacenados en forma de vectores y matrices para almacenamiento y cálculo. De esta manera, los datos se pueden expresar cuantitativamente. y con mayor precisión Cotejar y analizar resultados.
Múltiples tipos de datos
MLlib admite inherentemente una variedad de formatos de datos, desde el conjunto de datos Spark más básico RDD hasta vectores y matrices implementados en el clúster. Asimismo, MLlib también admite formatos localizados implementados en la máquina local.
La siguiente tabla proporciona los tipos de datos admitidos por MLlib.
| escribe un nombre |
Definición |
| vectores locales |
Conjunto de vectores locales. Proporciona principalmente a Spark un conjunto de colecciones de datos sobre las que se puede operar. |
| Punto etiquetado |
Etiquetas vectoriales. Permitir a los usuarios clasificar diferentes colecciones de datos |
| matriz local |
matriz local. Combine datos y guárdelos en forma matricial en la computadora local |
| Matriz distribuida |
Matriz distribuida. Almacenar una colección de matrices en una computadora distribuida como una matriz. |
Los anteriores son los tipos de datos admitidos por MLlib. Las matrices distribuidas se dividen en cuatro tipos diferentes según las diferentes funciones y escenarios de aplicación.
2. vectores locales
El tipo de almacenamiento localizado utilizado por MLlib es vectorial, y los vectores aquí se componen principalmente de dos tipos: conjuntos de datos dispersos (repuestos) y conjuntos de datos densos (densos) . Por ejemplo, un dato vectorial (9,5,2,7) se puede almacenar como (9,5,2,7) según el formato de datos intensivos, y el conjunto de datos se almacena como un conjunto completo. Para datos escasos, se pueden almacenar como (4, Array(0,1,2,3), Array(9,5,2,7)) según el tamaño del vector.
Caso número uno:
importar org.apache.spark.{SparkConf,SparkContext}
def principal(argumentos:Matriz[Cadena]):Unidad={
//--creamos vectores densos
//--dense puede entenderse como una forma de colección dedicada a MLlib, que es similar a Array
val vd=Vectores.denso(2,0,6)//
imprimirln(vd)
//①Referencia: talla. El método adicional consiste en descomponer los datos de matriz de datos proporcionados (9,5,2,7) en partes de tamaño específico para su procesamiento; en este caso, son 7 partes.
//③parámetro: datos de entrada. En este caso es Array(9,5,2,7)
//②Parámetro: el subíndice correspondiente a los datos de entrada debe ser incremental y el valor máximo debe ser menor o igual al tamaño
val vs = Vectores.sparse (7, Matriz (0,1,3,6), Matriz (9,5,2,7))
imprimirln(vs(6))
}
}