Atención jerárquica multiescala para segmentación semántica.
ATENCIÓN JERÁRQUICA MULTIESCALA PARA LA SEGMENTACIÓN SEMÁNTICA
Resumen
La inferencia multiescala se utiliza a menudo para mejorar los resultados de la segmentación semántica. Se pasan varias escalas de imágenes a través de la red y los resultados se combinan utilizando métodos de agrupación promedio o máximo. En este artículo, proponemos un enfoque basado en la atención para combinar predicciones de múltiples escalas. Mostramos que las predicciones en ciertas escalas son más capaces de resolver modos de falla específicos y que el aprendizaje en red sesga la selección de estas escalas para generar mejores predicciones en estos casos. Nuestro mecanismo de atención es jerárquico, lo que lo hace aproximadamente 4 veces más eficiente en memoria que otros métodos de última generación. Además de hacer que el entrenamiento sea más rápido, esto también nos permite utilizar tamaños de cultivo más grandes, mejorando así la precisión del modelo. Presentamos los resultados de nuestro método en dos conjuntos de datos: Cityscapes y Mapillary Vistas. Para paisajes urbanos con una gran cantidad de imágenes mal etiquetadas, también aprovechamos la anotación automática para mejorar la generalización. Utilizando nuestro enfoque, logramos nuevos resultados de última generación en Mapillary (61.1 IOU val) y Cityscapes (85.1 IOU test).
Palabras clave : Segmentación semántica·Atención·Etiquetado automático
1. Introducción
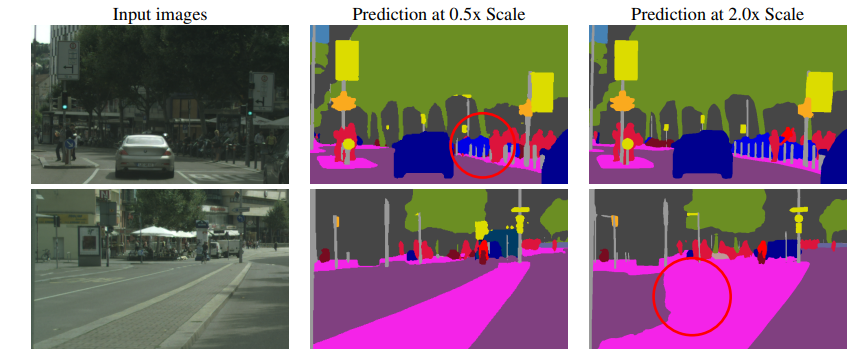
Figura 1: Demuestra un modo de falla común de la segmentación semántica en la escala de inferencia. En la primera fila, los pilares pequeños están segmentados de manera inconsistente en imágenes reducidas (0,5x), pero se predicen mejor en imágenes mejoradas (2x). En la segunda fila, las áreas de carretera/aislamiento más grandes están mejor segmentadas con una resolución más baja (0,5x).
La tarea de la segmentación semántica es etiquetar todos los píxeles de una imagen como pertenecientes a una de N categorías. En esta tarea,Existe una compensación en el sentido de que algunos tipos de predicciones se manejan mejor con resoluciones de inferencia más bajas, mientras que otros tipos de tareas se manejan mejor con resoluciones de inferencia más altas.. Por ejemplo, detalles como bordes o estructuras delgadas de objetos a menudo requieren el uso de tamaños de imagen ampliados para mejores predicciones. Al mismo tiempo, las predicciones de estructuras grandes que requieren un contexto más global a menudo funcionan mejor con tamaños de imagen reducidos porque el campo receptivo de la red puede observar una mayor parte del contexto necesario. A este último problema lo llamamos confusión de clasificación. Como se muestra en la Figura 1, se muestran ejemplos de estos casos.
El uso de inferencia de múltiples escalas es una forma común de resolver este compromiso. El uso de una variedad de escalas para hacer predicciones y la combinación de los resultados mediante una agrupación promedio o máxima a menudo mejora los resultados. La combinación de múltiples escalas utilizando el promedio a menudo mejora los resultados, pero enfrenta el problema de combinar predicciones excelentes con predicciones deficientes. Por ejemplo, si para un píxel determinado la mejor predicción proviene de la escala 2x y la predicción de la escala 0,5x es peor, entonces el promedio combinará estas predicciones para producir un resultado subóptimo. La agrupación máxima, por otro lado, elige utilizar una de N escalas para un píxel determinado, y la respuesta óptima probablemente sea una combinación ponderada de predicciones en diferentes escalas.
Para abordar este problema, empleamos un mecanismo de atención para predecir cómo combinar predicciones de múltiples escalas a nivel de píxeles, similar al método propuesto por Chen et al. Proponemos un mecanismo de atención jerárquico que permite a la red aprender a predecir los pesos relativos entre escalas adyacentes. En nuestro método, debido a su naturaleza jerárquica, solo necesitamos agregar una escala adicional en el proceso de capacitación, mientras que otros métodos como [1] requieren que cada escala de inferencia adicional se agregue explícitamente durante la etapa de capacitación. Por ejemplo, cuando las escalas de inferencia objetivo para la evaluación de múltiples escalas son {0,5, 1,0 y 2,0}, otros métodos de atención requieren que la red se entrene primero en todas estas escalas, lo que produce 4,25 veces (0,5 2 + 2,0 2 0,5^ 2 + 2,0^20, 52+2. 02 ) Costes adicionales de formación. Si bien nuestro método solo necesita agregar una escala adicional de 0,5x durante el entrenamiento, lo que representa solo un aumento de 0,25 veces (0,5 2 0,5^20, 52 ) Costo. Además, nuestro mecanismo jerárquico propuesto también proporciona la flexibilidad de seleccionar escalas adicionales durante la inferencia para utilizar mejor los recursos disponibles que los métodos propuestos anteriormente.
Para lograr resultados de última generación en paisajes urbanos, también adoptamos una estrategia de anotación automática de imágenes gruesas para aumentar la diversidad del conjunto de datos y así mejorar la generalización. Nuestra estrategia está inspirada en varios trabajos recientes, incluido [2, 3, 4]. A diferencia de las estrategias típicas de etiquetado suave, adoptamos el etiquetado físico para administrar el tamaño de almacenamiento de etiquetas, lo que ayuda a mejorar el rendimiento del entrenamiento al reducir los costos de E/S del disco.
1.1 Contribución a la investigación
- Un mecanismo eficiente de atención jerárquica de múltiples escalas que ayuda a resolver problemas de confusión de clases y pérdida de detalles, lo que permite a la red aprender cómo combinar de manera óptima predicciones de múltiples escalas de inferencia.
- La estrategia de anotación automática basada en umbrales estrictos utiliza imágenes sin etiquetar para mejorar el pagaré.
- Se logran resultados de última generación en los conjuntos de datos Cityscapes (85,1 IOU) y Mapillary Vistas (61,1 IOU).
2. Trabajo relacionado
Métodos de contexto multiescala . Las redes de segmentación semántica de última generación actuales utilizan troncales de red con tamaños de paso de salida más bajos, lo que permite a la red analizar mejor los detalles, pero también da como resultado un campo receptivo cada vez más reducido. El estrechamiento del campo receptivo puede dificultar que la red prediga objetos grandes en la escena. La agrupación piramidal puede compensar el campo receptivo reducido al combinar un contexto de múltiples escalas. PSPNet [5] utiliza un módulo de agrupación de pirámide espacial, que utiliza características obtenidas de la última capa del tronco de la red como entrada para combinar características de múltiples escalas a través de una serie de operaciones de agrupación y convolución. DeepLab [6] utiliza Atrous Spatial Pyramid Pooling (ASPP), que utiliza convoluciones dilatadas con diferentes tasas de expansión para crear características densas, lo cual es más ventajoso que PSPNet. Más recientemente, ZigZagNet [7] y ACNet [8] utilizan funciones intermedias en lugar de solo funciones troncales de red para crear un contexto de múltiples escalas.
Métodos de contexto asociados . Las técnicas de agrupación piramidal generalmente se centran en áreas de contexto cuadradas fijas porque la agrupación y la dilatación generalmente se aplican simétricamente. Además, dichas técnicas tienden a ser estáticas y no se pueden aprender. Sin embargo, el método del contexto asociativo crea contexto centrándose en la relación entre píxeles y no se limita a áreas cuadradas. Los métodos de contexto asociativo tienen propiedades de aprendizaje y pueden crear contexto basado en la composición de la imagen. Esta técnica crea un contexto más apropiado para áreas semánticas no cuadradas, como trenes largos o farolas altas y estrechas. OCRNet [9], DANET [10], CFNet [11], OCNet [12] y otros trabajos relacionados [13, 14, 15, 16, 17, 18, 19, 20] utilizan dichas relaciones para construir un mejor contexto.
Razonamiento multiescala . Tanto los métodos de contexto correlacionales como los de múltiples escalas [21, 22, 23, 9] utilizan la evaluación de múltiples escalas para obtener resultados óptimos. Dos formas comunes de combinar predicciones de red en múltiples escalas son el promedio y la agrupación máxima, siendo la agrupación promedio la más común. Sin embargo, la agrupación promedio requiere combinar productos de diferentes escalas con pesos iguales, lo que puede no ser ideal. Chen y otros [1, 24] utilizan cabezas de atención para combinar múltiples escalas. Entrenan una cabeza de atención en todas las escalas, que se entrena utilizando las características finales de la red neuronal. Yang y otros [24] utilizan combinaciones de características en diferentes capas de red para generar mejor información contextual. Sin embargo, ambos métodos comparten la característica de que la red y la cabeza de atención se entrenan utilizando un conjunto fijo de escalas. En tiempo de ejecución, solo se pueden utilizar estas escalas; de lo contrario, es necesario volver a entrenar la red. Este artículo propone un mecanismo de atención basado en jerárquicas que no se ve afectado por el número de escalas al inferir. Además, demostramos que nuestro mecanismo de atención jerárquica propuesto no solo mejora el rendimiento de la agrupación promedio sino que también nos permite visualizar de manera diagnóstica la importancia de diferentes escalas en categorías y escenas. Además, nuestro método es independiente de otros métodos de atención o de agrupación piramidal (por ejemplo, [22, 25, 26, 9, 27, 10, 28]) ya que estos métodos utilizan imágenes de una sola escala y prestan atención a más funciones de varios niveles. para generar predicciones de alta resolución.
Etiquetado automático . La mayor parte del trabajo actual de segmentación semántica de última generación en paisajes urbanos, especialmente [12, 29], se entrena en su totalidad utilizando ~20 000 imágenes con anotaciones aproximadas. Sin embargo, como las etiquetas son demasiado toscas, una gran parte de cada imagen tosca no está etiquetada. Para lograr resultados de última generación en paisajes urbanos, adoptamos una estrategia de etiquetado automático inspirada en Xie et al.[2] y otros métodos de segmentación semántica autodidacta y semisupervisados [30, 31, 32, 33, 34] y pseudo-inspirados por métodos de etiquetado (por ejemplo, [4, 35, 36, 3]). Generamos etiquetas densas en imágenes bastas de paisajes urbanos. Las etiquetas que generamos casi no tienen áreas sin etiquetar, por lo que podemos explotar al máximo todo el contenido de la imagen preliminar.
La mayoría de los esfuerzos de etiquetado automático para la clasificación de imágenes utilizan etiquetas continuas o suaves, mientras que nosotros generamos etiquetas de umbral estricto para la eficiencia del almacenamiento y la velocidad de entrenamiento. Cuando se utilizan etiquetas suaves, la red de profesores proporciona probabilidades continuas para las N categorías de cada píxel, mientras que para las etiquetas duras, se utiliza un umbral para seleccionar una única categoría de nivel superior para cada píxel. De manera similar a [37, 4], generamos etiquetas densas y duras para imágenes de paisajes urbanos en bruto. Un ejemplo se muestra en la Figura 4. A diferencia de Xie et al., no realizamos mejoras iterativas de las etiquetas, sino que utilizamos imágenes con anotaciones gruesas y finas predeterminadas para una única iteración del entrenamiento completo del modelo docente. Después de esta capacitación conjunta, etiquetamos automáticamente las imágenes preliminares y las reemplazamos con imágenes de nuestra receta de capacitación docente para obtener resultados de pruebas de última generación. Al combinar nuestro algoritmo de atención jerárquica propuesto con nuestras etiquetas duras falsas, podemos obtener resultados de última generación en paisajes urbanos.
3. Mecanismo de atención jerárquico de múltiples escalas.
Nuestro mecanismo de atención es conceptualmente muy similar a [1], donde se aprende una máscara densa para cada escala, y luego la máscara es Para combinar estos resultados de predicción de múltiples escalas de una manera, consulte la Figura 2. Llamamos método explícito al método de Chen . Con nuestro enfoque jerárquico , en lugar de aprender todas las máscaras de atención para cada escala fija simultáneamente, aprendemos máscaras de atención relativas entre escalas adyacentes. Al entrenar la red, solo entrenamos pares de escalas adyacentes. Como se muestra en la Figura 2, dado un conjunto de características de imagen en una escala única (inferior), predecimos una atención relativa densa a nivel de píxeles entre dos escalas de imagen. Efectivamente, para obtener una imagen escalada por pares, reducimos una única imagen de entrada en un factor de 2, de modo que tengamos una entrada escalada 1x y una entrada escalada 0,5x, aunque se puede elegir cualquier otro factor de escala. Es importante tener en cuenta que la entrada de la red en sí es una versión reescalada de la imagen de entrenamiento original porque utilizamos el aumento de escala de imagen durante el entrenamiento, lo que permite a la red predecir la atención relativa en múltiples escalas de imagen. Al ejecutar la inferencia, podemos aplicar la atención aprendida de forma jerárquica, combinando N escalas de predicción para el cálculo. Priorizamos las escalas más bajas y aumentamos gradualmente a escalas más altas, de modo que se puedan seleccionar escalas más altas con más información contextual global para ajustar dónde las predicciones de escalas más altas pueden mejorar las predicciones.
Más específicamente, durante el entrenamiento, una imagen de entrada determinada se escala mediante un factor r, donde r = 0,5 significa reducción de resolución 2x, r = 2,0 significa aumento de resolución 2x y r = 1 significa ninguna operación. En nuestro entrenamiento, elegimos r = 0,5 y r = 1,0. Luego se envían dos imágenes con r = 1 y r = 0,5 a través de una red troncal compartida, que produce logits semánticos (L), así como máscaras de atención (α) para cada escala, que se utilizan para combinar los logits entre las máscaras (L). ). Por lo tanto, para el entrenamiento y la inferencia a dos escalas, U representa el operador de muestreo ascendente bilineal, ∗ y + son multiplicación y suma de píxeles respectivamente, entonces la ecuación se puede expresar formalmente como:
L ( r = 1 ) = U ( L ( r = 0.5 ) ∗ α ( r = 0.5 ) ) + ( ( 1 − U ( α ( r = 0.5 ) ) ) ∗ L ( r = 1 ) ) (1) L_ {(r=1) }= U(L_{(r=0.5)} ∗ α_{(r=0.5)}) + ((1 − U(α_{(r=0.5)})) ∗ L_{(r =1)}) \etiqueta{1}l( r = 1 )=y ( l( r = 0,5 )∗a( r = 0,5 ))+(( 1−U ( un( r = 0,5 )))∗l( r = 1 ))( 1 )
Hay dos ventajas al utilizar nuestra estrategia propuesta:

Figura 2: Arquitectura de red que muestra (nuestra) arquitectura explícita y en capas en los lados izquierdo y derecho, respectivamente.
El lado izquierdo muestra la arquitectura de [1], donde la atención en cada escala se aprende explícitamente. El lado derecho muestra nuestra arquitectura jerárquica de atención. Arriba a la derecha hay una ilustración de nuestro proceso de capacitación, donde la red aprende a predecir la atención entre pares de escalas adyacentes. La inferencia en la parte inferior derecha se realiza de manera jerárquica/jerárquica para combinar múltiples escalas de predicción. La atención en una escala inferior determina la contribución de la siguiente escala superior.
- En el momento de la inferencia, ahora tenemos flexibilidad para elegir escalas, por lo que es factible agregar nuevas escalas, como 0,25x o 2,0x, a modelos ya entrenados con 0,5x y 1,0x con la ayuda de nuestro mecanismo de atención jerárquico propuesto encadenados. de. Esto difiere de los métodos propuestos anteriormente, que se limitaban a utilizar la misma escala utilizada durante el entrenamiento del modelo.
- Esta estructura en capas nos permite aumentar la eficiencia del entrenamiento, mejorando en comparación con los métodos explícitos. Cuando se utiliza el método explícito, si se utilizan tres proporciones de 0,5, 1,0 y 2,0, el coste de formación será 0,5 2 + 1,0 2 + 2,0 2 = 5,25 0,5^2 + 1,0^2 + 2,0^ 2 = 5,250, 52+1. 02+2. 02=5,25 , en relación con el entrenamiento utilizando una sola escala. Al adoptar nuestro método jerárquico propuesto, el costo de capacitación es solo0,5 2 + 1,0 2 = 1,25 0,5^2 + 1,0^2 = 1,250, 52+1. 02=1,25 .
3.1 Arquitectura
Backbone : en los estudios de creación de perfiles de esta sección, utilizamos ResNet-50 [38] (configurado con un paso de salida de 8) como la columna vertebral de la red. Para lograr resultados de última generación, utilizamos una columna vertebral más grande y potente: HRNet-OCR [9].
Cabeza semántica : una cabeza totalmente convolucional especialmente diseñada para la predicción semántica, que consta de (3x3 conv) → (BN) → (ReLU) → (3x3 conv) → (BN) → (ReLU) → (1x1 conv). La convolución final genera num_classes canales.
Cabezal de atención : utiliza un cabezal separado similar a la estructura del cabezal semántico para la predicción de atención, que genera un único canal además de la salida de convolución final. Cuando se utiliza ResNet-50 como andamio, los cabezales semánticos y de atención se utilizan con las características de la última etapa de ResNet-50. Cuando se utiliza HRNet-OCR, los cabezales semánticos y de atención se utilizan con las características de los bloques OCR. Para HRNet-OCR, también hay un encabezado semántico auxiliar , que obtiene sus características directamente del marco HRNet antes del OCR. Este encabezado incluye (1x1 conv) → (BN) → (ReLU) → (1x1 conv). Después de prestar atención a los logits semánticos, se utiliza un muestreo ascendente bilineal para reducir las predicciones al tamaño de la imagen objetivo.
3.2 Análisis
Para evaluar la efectividad de nuestro método de atención multiescala, entrenamos la red utilizando la arquitectura DeepLab V3+ y la columna vertebral ResNet50. En la Tabla 1, mostramos que nuestro método de atención jerárquica logra una mayor precisión (51,6) en relación con el método promedio de referencia (49,4) o el método explícito (51,4). También observamos que nuestro método logra resultados significativamente mejores que el método explícito al agregar una escala de 0,25x. A diferencia de los métodos explícitos, nuestro método no requiere volver a entrenar la red cuando se utiliza la escala adicional de 0,25x. Esta flexibilidad en el tiempo de inferencia es una ventaja clave de nuestro enfoque. Podemos realizar una sesión de entrenamiento pero tenemos la flexibilidad de evaluarla en una variedad de escalas diferentes.

Tabla 1: Comparación de nuestro método de atención jerárquica de múltiples escalas con otros métodos en el conjunto de validación Mapillary. La arquitectura de red es una combinación de troncales DeepLab V3+ y ResNet-50. Escalas de evaluación: Escalas para evaluación multiescala. FLOPS: el número relativo de operaciones de punto flotante consumidas por la red durante el entrenamiento. Tiempo de minibatch: tiempo de minibatch de entrenamiento medido en la GPU Nvidia Tesla V100.
Además, también observamos que en el método de múltiples escalas promedio de referencia, agregar solo una escala de 0,25x afecta negativamente la precisión ya que el pagaré disminuye en 0,7, mientras que nuestro método con la escala adicional de 0,25x mejora la precisión en 0,6 pagaré. En el método de promediación de referencia, las predicciones de 0,25x son tan aproximadas que cuando se promedian a otras escalas, observamos categorías como marcas de carriles, alcantarillas, cabinas telefónicas, farolas, semáforos y señales de semáforo (delanteras y traseras), portabicicletas. , etc., Reducido en 1,5 pagarés. La rugosidad prevista daña los bordes y los detalles. Sin embargo, agregar una escala de 0,25x mejora los resultados en 0,6 cuando se utiliza nuestro método de atención propuesto, ya que nuestra red puede aplicar la predicción de 0,25x de la manera más adecuada y evitar su uso en los bordes. Esto se puede observar en la imagen izquierda de los pilares delgados en la Figura 3. La predicción de 0,5x cubre solo una cantidad muy pequeña de los pilares delgados, pero hay una señal muy fuerte de preocupación en la escala de 2,0x. A su vez, en la región muy grande de la derecha, el mecanismo de atención aprende a hacer pleno uso de la escala inferior (0,5x) y tiene poco uso para las predicciones erróneas de 2,0x.
3.2.1 Funciones de escala única frente a funciones de escala dual
Si bien la arquitectura que adoptamos solo utiliza características de las dos escalas de imagen adyacentes inferiores para proporcionar información al cabezal de atención (consulte la Figura 2), intentamos entrenar el cabezal de atención según las características obtenidas de las dos escalas adyacentes. No observamos diferencias significativas en la precisión, por lo que seleccionamos un conjunto de características.
4 Etiquetado automático en paisaje urbano
Inspirándonos en trabajos recientes de [2] y [39] sobre anotaciones automáticas para tareas de clasificación de imágenes, mejoramos los paisajes urbanos con una estrategia de anotación automática para mejorar el tamaño efectivo del conjunto de datos y la calidad de las etiquetas. En Cityscapes, se utilizan 20.000 imágenes con etiquetas aproximadas junto con 3.500 imágenes con etiquetas finas. La imagen aproximada tiene una calidad de etiqueta muy moderada y contiene una gran cantidad de píxeles sin etiquetar, como se muestra en la Figura 4. Al utilizar nuestro método de etiquetado automático, podemos mejorar la calidad de la etiqueta, contribuyendo así al modelo de pagaré.
En el etiquetado automático para la clasificación de imágenes, una técnica común es utilizar etiquetas suaves o continuas, donde la red de profesores proporciona una probabilidad objetivo (suave) para cada N clase de cada píxel. El desafío con este enfoque es el espacio en disco y la velocidad de entrenamiento: almacenar estas etiquetas requiere alrededor de 3,2 TB de espacio en disco: 20000 imágenes * 2048w * 1024 h * 19 categorías * 4B = 3,2 TB. Incluso si optamos por almacenar estas etiquetas, ralentizará significativamente el entrenamiento durante el entrenamiento. Por lo tanto, adoptamos una estrategia de etiquetado estricto para seleccionar la predicción de clase superior de la red de profesores dado un píxel. Etiquetas de umbral basadas en un umbral de probabilidades de salida de la red de docentes. Las predicciones de los profesores que superan el umbral se convierten en etiquetas de verdad fundamental; de lo contrario, los píxeles se etiquetan como categorías ignoradas. En la práctica, utilizamos un umbral de 0,9.
5 resultados
5.1 Implementación del protocolo
En esta sección detallamos nuestro protocolo de implementación.
Detalles de entrenamiento: Nuestros modelos se entrenan en servidores Nvidia DGX usando Pytorch [40] con 8 GPU por nodo, usando entrenamiento paralelo de datos distribuidos de precisión mixta y normalización por lotes simultánea. Usamos el descenso de gradiente estocástico (SGD) como optimizador, entrenamos con un tamaño de lote 1, un impulso de 0,9 y una caída de peso de 5e-4 en cada GPU.
Adoptamos una estrategia de tasa de aprendizaje "polinómica" [41]. Usamos RMI [42] con la configuración predeterminada como función de pérdida principal y entropía cruzada como función de pérdida auxiliar. Para paisajes urbanos, utilizamos un exponente polinómico de 2,0, una tasa de aprendizaje inicial de 0,01 y entrenamos durante 175 épocas en 2 nodos DGX. Para Mapillary, utilizamos un exponente polinómico de 1,0, una tasa de aprendizaje inicial de 0,02 y entrenamos durante 200 épocas en 4 nodos DGX. De manera similar a [29], utilizamos muestreo uniforme de clases en el cargador de datos para muestrear cada clase por igual, lo que ayuda a mejorar los resultados cuando los datos están desequilibrados.
Aumento de datos: aplicamos desenfoque gaussiano, mejora de color, volteo horizontal aleatorio y escalado aleatorio (0,5x-2,0x) a las imágenes de entrada para aumentar el proceso de entrenamiento del conjunto de datos. Usamos un tamaño de recorte de 2048x1024 para paisajes urbanos y un tamaño de recorte de 1856x1024 para Mapillary.

Figura 3: Predicciones semánticas y atencionales en cada nivel de escala para dos escenas diferentes. La escena de la izquierda ilustra el problema de los detalles finos, mientras que la escena de la derecha ilustra el problema de la segmentación de áreas grandes. El color blanco de atención indica valores elevados (cercanos a 1,0). La suma de los valores de atención para un píxel determinado en todas las escalas es 1,0. Izquierda: el pilar delgado de la acera se resuelve mejor en una escala de 2x, y la atención se enfoca más con éxito en esa escala, lo que demuestra la representación en blanco del pilar en la imagen de atención de 2x. Derecha: Las áreas de carreteras/aisladas más grandes se predicen mejor a una escala de 0,5x, y la atención se centra realmente en esta área a una escala de 0,5x.

Figura 4: Ejemplo de nuestras etiquetas de imágenes aproximadas generadas automáticamente. Las etiquetas aproximadas generadas automáticamente (derecha) proporcionan información de anotación más detallada que las etiquetas aproximadas originales (centro). Esta información de anotación más granular mejora la distribución de las etiquetas porque ahora se representan tanto objetos pequeños como grandes, en lugar de solo objetos grandes.
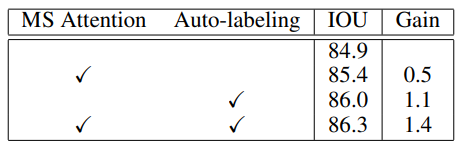
Tabla 2: Experimentos de ablación en el conjunto de validación de paisajes urbanos. El método de referencia utiliza HRNet-OCR como arquitectura. MS Attention es nuestro método de atención multiescala propuesto. El etiquetado automático significa que utilizamos etiquetas aproximadas generadas automáticamente o reales durante la capacitación. La combinación de ambas tecnologías produce los mejores resultados.
5.1.1 Resultados de paisajes urbanos
Paisajes urbanos [43] es un gran conjunto de datos que cubre 19 categorías semánticas etiquetadas en 5000 imágenes de alta resolución. Para paisajes urbanos, utilizamos HRNet-OCR como red troncal mientras empleamos nuestro método de atención multiescala propuesto. Usamos RMI como función de pérdida para el cabezal de segmentación principal, pero para el cabezal de segmentación auxiliar, usamos entropía cruzada porque descubrimos que el uso de la pérdida de RMI da como resultado una precisión del entrenamiento reducida a medida que el entrenamiento es más profundo. Logramos los mejores resultados entrenando primero en el conjunto de datos Mapillary más grande y luego entrenando en paisajes urbanos. Para las tareas previas al entrenamiento de Mapillary, no utilizamos la atención para el entrenamiento. Tomamos muestras con un 50% de probabilidad de imágenes train+val y etiquetamos automáticamente conjuntos de imágenes gruesas en función del uso de anotaciones a nivel de subpíxeles. Al realizar pruebas, usamos escala = {0.5,1.0,2.0} y cambio de imagen.
Como se muestra en la Tabla 2, realizamos estudios de ablación en el conjunto de validación Cityscapes. La atención multiescala mejora el IOU en un 0,5 % en comparación con la arquitectura HRNet-OCR según la agrupación promedio. La anotación automática mejora la línea base del pagaré en un 1,1 %. La combinación de las dos técnicas da como resultado una ganancia total de un 1,4% menos de pagaré.
Finalmente, en la Tabla 3, mostramos los resultados de nuestro método en comparación con otros métodos de mejor rendimiento en el conjunto de pruebas de Paisajes urbanos. Nuestro método logra una puntuación de 85,1, la puntuación más alta en la prueba de paisajes urbanos reportada entre todos los métodos, superando la mejor puntuación anterior en 0,6 IOU. Además, nuestro método tiene las puntuaciones más altas dentro de la clase en todas las clases menos en tres. Algunos resultados se presentan visualmente en la Figura 5.

Tabla 3: Comparación con otros métodos en el conjunto de pruebas de Paisajes urbanos. Los mejores resultados en cada categoría están en negrita.
5.1.2 Resultados de Vistas Mapillares
Mapillary Vistas [45] es un gran conjunto de datos que contiene 25.000 imágenes de alta resolución anotadas en 66 categorías de objetos. Para Mapillary, utilizamos HRNet-OCR como red troncal y adoptamos nuestro método de atención multiescala propuesto. Dado que las imágenes de Mapillary pueden tener resoluciones muy altas y diferentes, cambiamos el tamaño de las imágenes para que su lado largo sea 2177, como se hace en [23]. Usamos pesos de la parte HRNet entrenada en la clasificación ImageNet para la inicialización del modelo. Dado que el requisito de memoria de 66 categorías es mayor en Mapillary, reducimos el tamaño del recorte a 1856x1024.
En la Tabla 4, mostramos los resultados de nuestro método en el conjunto de validación Mapillary. Nuestro enfoque de modelo único logró una puntuación de 61,1, que es 2,4 puntos más que el siguiente enfoque más cercano, Panoptic Deeplab [23], que logró una puntuación de 58,7 utilizando una combinación de múltiples modelos.

Tabla 4: Comparación de resultados en el conjunto de validación Mapillary. Los mejores resultados en cada categoría están en negrita.
6. Conclusión
Este artículo propone un método de atención jerárquico de múltiples escalas para la segmentación semántica. Nuestro método mejora la precisión de la segmentación semántica y al mismo tiempo es eficiente en términos de memoria y computación, los cuales son problemas prácticos. La eficiencia del entrenamiento limita la velocidad de la investigación y la eficiencia de la memoria de la GPU limita el tamaño de la red que se puede entrenar simultáneamente, lo que puede limitar la precisión de la red. Demostramos experimentalmente que nuestro método propuesto puede lograr mejoras consistentes en conjuntos de datos de paisajes urbanos y mapas.
Agradecimientos: Nos gustaría agradecer a Sanja Fidler, Kevin Shih, Tommi Koivisto y Timo Roman por sus útiles debates.

Referencias
[1] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu y Alan L. Yuille. Atención a la escala: segmentación de imágenes semánticas conscientes de la escala
, 2015.
[2] Qizhe Xie, Minh-Thang Luong, Eduard Hovy y Quoc V. Le. La autoformación con estudiante ruidoso mejora
la clasificación de imagenet, 2019.
[3] Eric Arazo, Diego Ortego, Paul Albert, Noel E O'Connor y Kevin McGuinness. Pseudoetiquetado y sesgo de confirmación en el aprendizaje profundo semisupervisado. Preimpresión de arXiv arXiv:1908.02983, 2019.
[4] Dong-Hyun Lee. Pseudoetiqueta: el método de aprendizaje semisupervisado simple y eficiente para
redes neuronales profundas. 2013.
[5] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang y Jiaya Jia. Red de análisis de escenas piramidales. En
Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 2881–2890, 2017.
[6] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff y Hartwig Adam. Codificador-decodificador con
atroz convolución separable para segmentación semántica de imágenes. En ECCV, 2018.
[7] Di Lin, Dingguo Shen, Siting Shen, Yuanfeng Ji, Dani Lischinski, Daniel Cohen-Or y Hui Huang. Zigzagnet:
fusión de contexto de arriba hacia abajo y de abajo hacia arriba para la segmentación de objetos. En CVPR, 2019.
[8] Jun Fu, Jing Liu, Yuhang Wang, Yong Li, Yongjun Bao, Jinhui Tang y Hanqing Lu. Red de contexto adaptativo
para el análisis de escenas, 2019.
[9] Yuhui Yuan, Xilin Chen y Jingdong Wang. Representaciones contextuales de objetos para segmentación semántica, 2019.
[10] Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang y Hanqing Lu. Red de atención dual para segmentación de
escenas, 2018.
[11] Hang Zhang, Han Zhang, Chenguang Wang y Junyuan Xie. Características co-ocurrentes en la segmentación semántica.
En CVPR, 2019.
[12] Yuhui Yuan y Jingdong Wang. Ocnet: Red de contexto de objetos para análisis de escenas, 2018. [
13] Yunpeng Chen, Yannis Kalantidis, Jianshu Li, Shuicheng Yan, y Jiashi Feng. A2-nets: Redes de atención doble
. En NIPS, 2018.
[14] Fan Zhang, Yanqin Chen, Zhihang Li, Zhibin Hong, Jingtuo Liu, Feifei Ma, Junyu Han y Errui Ding. Acfnet:
clase atencional Red de características para segmentación semántica.En ICCV, 2019.
[15] Yunpeng Chen, Marcus Rohrbach, Zhicheng Yan, Shuicheng Yan, Jiashi Feng y Yannis Kalantidis.
Redes de razonamiento global basadas en gráficos. arXiv:1811.12814, 2018.
[16] Xiaodan Liang, Zhiting Hu, Hao Zhang, Liang Lin, y Eric P Xing. El razonamiento gráfico simbólico se encuentra con las convoluciones.
En NIPS, 2018.
[17] Yin Li y Abhinav Gupta. Más allá de las cuadrículas: aprendizaje de representaciones gráficas para el reconocimiento visual. En NIPS, 2018. [
18] Kaiyu Yue, Ming Sun, Yuchen Yuan, Feng Zhou, Errui Ding y Fuxin Xu. Red compacta generalizada no local
. En NIPS. 2018.
[19] Xia Li, Zhisheng Zhong, Jianlong Wu, Yibo Yang, Zhouchen Lin y Hong Liu.
Atención a la maximización de expectativas. Redes para segmentación semántica.En ICCV, 2019.
[20] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei y Wenyu Liu. Ccnet: Atención cruzada
para segmentación semántica. arXiv:1811.11721, 2018.
[21] Liang-Chieh Chen, George Papandreou, Florian Schroff y Hartwig Adam. Repensar la convolución atroz para
la segmentación de imágenes semánticas. arXiv:1706.05587, 2017.
[22] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff y Hartwig Adam. Codificador-decodificador con
atroz convolución separable para segmentación de imágenes semánticas, 2018.
[23] Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam y Liang-Chieh
Chen. Panoptic-deeplab: una base simple, sólida y rápida para la segmentación panóptica ascendente, 2019.
[24] Shiqi Yang y Gang Peng. Atención al refinamiento a través de múltiples escalas para la segmentación semántica. En
Conferencia de la Cuenca del Pacífico sobre multimedia, páginas 232–241. Springer, 2018.
[25] Ashish Sinha y José Dolz. Atención autoguiada a múltiples escalas para la segmentación de imágenes médicas, 2019.
[26] Guosheng Lin, Anton Milan, Chunhua Shen e Ian Reid. Refinenet: redes de refinamiento de rutas múltiples para
segmentación semántica de alta resolución, 2016.
[27] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei y Wenyu Liu. Ccnet: Atención cruzada
para segmentación semántica. En la Conferencia Internacional IEEE sobre Visión por Computadora (ICCV), octubre de
2019.
[28] Hanchao Li, Pengfei Xiong, Jie An y Lingxue Wang. Red de atención piramidal para segmentación semántica.
Preimpresión de arXiv arXiv:1805.10180, 2018.
[29] Yi* Zhu, Karan* Sapra, Fitsum A Reda, Kevin J Shih, Shawn Newsam, Andrew Tao y Bryan Catanzaro.
Mejora de la segmentación semántica mediante la propagación de vídeos y la relajación de etiquetas. En Actas de la
Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 8856–8865, 2019.
[30] Qing Lian, Fengmao Lv, Lixin Duan y Boqing Gong. Construcción de planes de estudio piramidales automotivados para
la segmentación semántica entre dominios: un enfoque no conflictivo. En la Conferencia Internacional IEEE sobre
Visión por Computadora (ICCV), 2019.
[31] Yunsheng Li, Lu Yuan y Nuno Vasconcelos. Aprendizaje bidireccional para la adaptación de dominios de la
segmentación semántica. En Conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2019.
[32] Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek y Yann LeCun. Predecir más profundamente el
futuro de la segmentación semántica. En la Conferencia Internacional IEEE sobre Visión por Computadora (ICCV), 2017.
[33] Yang Zou, Zhiding Yu, BVK Vijaya Kumar y Jinsong Wang. Adaptación de dominio para segmentación semántica
mediante autoformación con equilibrio de clases. En Conferencia europea sobre visión por computadora (ECCV), 2018.
[34] Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Vijaya Kumar y Jinsong Wang. Confianza Regularizada
Auto-entrenamiento. En Conferencia Internacional IEEE sobre Visión por Computadora (ICCV), 2019.
[35] Ahmet Iscen, Giorgos Tolias, Yannis Avrithis y Ondrej Chum. Propagación de etiquetas para un aprendizaje profundo semisupervisado
. En Actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 5070–5079,
2019.
[36] Weiwei Shi, Yihong Gong, Chris Ding, Zhiheng MaXiaoyu Tao y Nanning Zheng. Aprendizaje profundo transductivo semisupervisado que utiliza funciones min-max. En Actas de la Conferencia Europea sobre
Visión por Computador (ECCV), páginas 299–315, 2018.
[37] Yiting Li, Lu Liu y Robby T Tan. Pérdida de coherencia desacoplada impulsada por la certeza para el aprendizaje semisupervisado.
arXiv, páginas arXiv–1901, 2019.
[38] Kaiming He, Xiangyu Zhang, Shaoqing Ren y Jian Sun. Aprendizaje residual profundo para el reconocimiento de imágenes. En
Actas de la conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 770–778, 2016.
[39] Antti Tarvainen y Harri Valpola. Los profesores malos son mejores modelos a seguir: los objetivos de coherencia ponderados promediados
mejoran los resultados del aprendizaje profundo semisupervisado, 2017.
[40] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen,
Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: una biblioteca de aprendizaje profundo de alto rendimiento y estilo imperativo
. En Avances en sistemas de procesamiento de información neuronal, páginas 8024–8035, 2019.
[41] Wei Liu, Andrew Rabinovich y Alexander C. Berg. Parsenet: Mirar más amplio para ver mejor, 2015.
[42] Zheng Yang Deng Cai Shuai Zhao, Yang Wang. Pérdida de información mutua de regiones para segmentación semántica. En
NeurIPS, 2019.
[43] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth y Bernt Schiele. El conjunto de datos de paisajes urbanos para la comprensión semántica de la escena urbana. En Proc.
de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2016.
[44] Yuan Yuhui, Xie Jingyi, Chen Xilin y Wang Jingdong. Segfix: refinamiento de límites independiente del modelo para
la segmentación. Preimpresión de arXiv, 2020.
[45] Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulò y Peter Kontschieder. El conjunto de datos de vistas cartográficas para
la comprensión semántica de escenas callejeras. En Conferencia Internacional sobre Visión por Computador (ICCV), 2017.
[46] Lorenzo Porzi, Samuel Rota Bulo, Aleksander Colovic y Peter Kontschieder. Segmentación de escenas perfecta. En
la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), junio de 2019.
[47] Tien-Ju Yang, Maxwell D Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, Xiao Zhang, Vivienne Sze, George Papandreou
y Liang-Chieh Chen. Deeperlab: analizador de imágenes de un solo disparo. Preimpresión de arXiv arXiv:1902.05093,
2019.