Resumen
En el último artículo, resumí algunos conocimientos básicos de UNet. Si no conoce UNet, puede leer el enlace del artículo: https://wanghao.blog.csdn.net/article/details/123714994
También compilé la versión pytorch de UNet, el enlace del artículo:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwwwww/article/details/123280059
El artículo de hoy explica cómo usar UNet para lograr la clasificación binaria de imágenes.
En general, hay dos enfoques para la clasificación binaria:
La primera salida es monocanal, es decir, la salida outputde forma [batch_size, 1, height, width]. donde batch_sziees el tamaño del lote, lo que 1significa generar un canal, heighty widthes consistente con la altura y el ancho de la imagen de entrada.
Durante el entrenamiento, la cantidad de canales de salida es 1 y los valores obtenidos por outputla son números arbitrarios. Dado target, es un mapa de etiquetas de un solo canal con solo valores 0 y 1. Para hacer que la salida de la red outputcontinúe acercándose a esta etiqueta, primero outputpase una función sigmoidea para normalizar su valor a [0, 1] para obtener output1, y luego deje que esto output1y target, realicen un cálculo de entropía cruzada para obtener el valor de pérdida y retropropagar para actualizar los Pesos de la red. Eventualmente, la red aprende a output1aproximar target.
Después del entrenamiento, la red outputtiene targetla capacidad de transformar la salida en aproximadamente . Primero pase la salida outputa través función sigmoide y luego tome un umbral (generalmente establecido en 0.5), si es mayor que el umbral, tome 1, de lo contrario tome 0, para obtener el mapa de predicción predict. El seguimiento es algunos cálculos relacionados con la evaluación.
Si la última capa de la red usa sigmoid, elija BCELoss, si no, elija BCEWithLogitsLoss, por ejemplo:
Sin sigmod en la última capa
output = net(input) # net的最后一层没有使用sigmoid
loss_func1 = torch.nn.BCEWithLogitsLoss()
loss = loss_func1(output, target)
más sigmod
output = net(input) # net的最后一层没有使用sigmoid
output = F.sigmoid(output)
loss_func1 = torch.nn.BCEWithLoss()
loss = loss_func1(output, target)
Cuando se predijo:
output = net(input) # net的最后一层没有使用sigmoid
output = F.sigmoid(output)
predict=torch.where(output>0.5,torch.ones_like(output),torch.zeros_like(output))
La segunda salida es multicanal, es decir, la salida de la red outputtiene forma [batch_size, num_class, height, width]. donde batch_sziees el tamaño del lote, num_classlo que indica que el número de canales de salida es consistente con el número de clasificaciones yheight es consistente con la altura y el ancho de la imagen de entrada.width
Durante el entrenamiento, el número de canales de salida es num_class(aquí tomamos 2). Dado target, es un mapa de etiquetas de un solo canal con solo valores 0 y 1. Para que la salida de la red outputcontinúe acercándose a esta etiqueta, primero pasará outputpor una función softmax para normalizar su valor a [0, 1], output1y en cada canal, este valor sumará 1. Ya targetque es una imagen de un solo canal, primero use onehotla codificación para convertirla en num_classuna imagen de canal, y el valor en cada canal se calcula en función del valor en el canal único, por ejemplo, el primer píxel en el canal único toma el valor de 1 (0<= 1 <=num_class-1, donde num_class=2), luego onehotdespués de la codificación, en la posición del primer píxel, los valores de los dos canales son 0 y 1, respectivamente. Es decir, el valor del píxel determina que el canal correspondiente al número de serie sea 1 y los demás canales sean 0, lo cual es muy crítico. Después de realizar la operación anterior target1, permita que this output1y target1, realicen un cálculo de entropía cruzada, obtengan el valor de pérdida y actualicen el peso de la red mediante retropropagación. Eventualmente, la red aprende a output1aproximarse target1(en cada nivel de canal).
Después del entrenamiento, la red outputtiene targetla capacidad de transformar la salida en aproximadamente . outputEn cada posición de píxel de cada canal en el cálculo, se obtiene el número de canal correspondiente con el valor más grande para obtener el mapa de predicción predict.
La pérdida utilizada para la selección de entrenamiento es agregar una función de pérdida, por ejemplo:
output = net(input) # net的最后一层没有使用sigmoid
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(output, target)
al pronosticar
output = net(input) # net的最后一层没有使用sigmoid
predict = output.argmax(dim=1)
El segundo método utilizado en este combate real.
Dirección del código seleccionado: milesial/Pytorch-UNet: implementación de PyTorch de U-Net para la segmentación semántica de imágenes con imágenes de alta calidad (github.com)
Después de descargar el código, descomprímalo localmente, como se muestra a continuación:
conjunto de datos
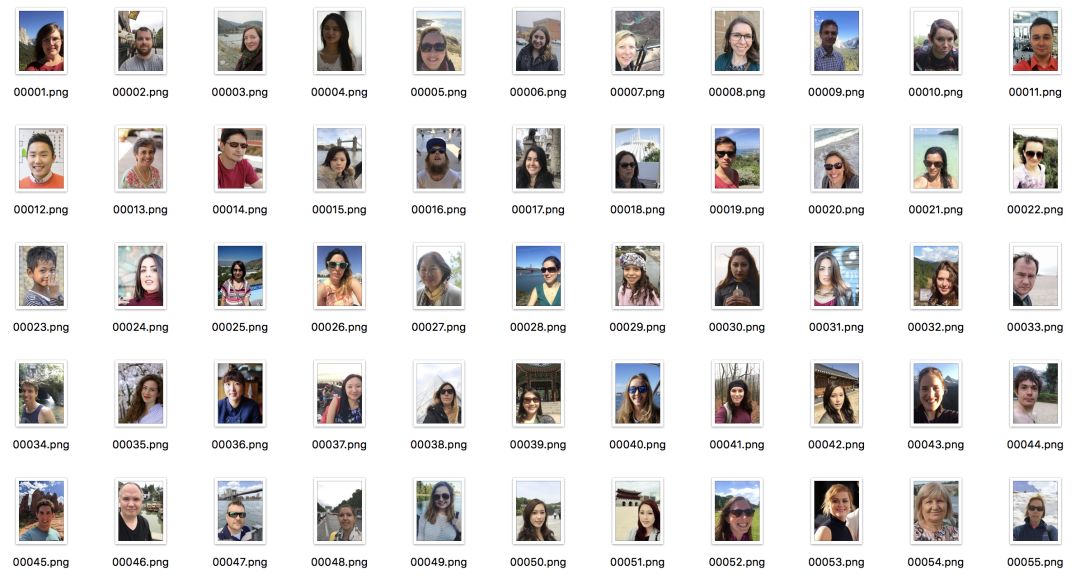
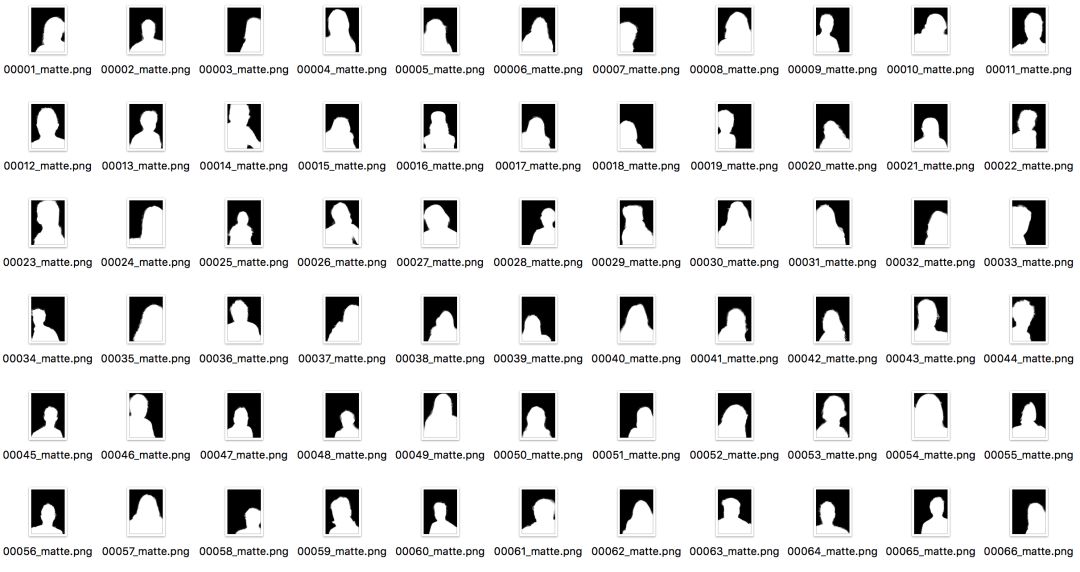
Dirección del conjunto de datos: http://www.cse.cuhk.edu.hk/~leojia/projects/automatting/, publicado en 2016.
El conjunto de datos contiene 2000 imágenes, 1700 imágenes de entrenamiento y 300 imágenes de prueba. Todos los datos son imágenes de retratos de Flickr. La resolución original de las imágenes es de 600 × 800, y la estera se genera mediante la estera de forma cerrada y la estera KNN.
Debido al alto valor comercial del conjunto de datos de segmentación de retratos, hay pocos conjuntos de datos públicos a gran escala. Este conjunto de datos es uno de los primeros publicados y ampliamente utilizado. Tiene varias características importantes:
(1) La resolución de la imagen es uniforme, el disparo es claro y la calidad es muy alta.
(2) Todas las imágenes son retratos de la parte superior del cuerpo y el área del retrato ocupa al menos 2/3 de la imagen tanto en largo como en ancho.
(3) Las poses de los personajes cambian muy poco, y todas son vistas frontales desde un ángulo pequeño, y el fondo es relativamente simple.

[1] Shen X, Tao X, Gao H, et al. Retrato mate automático profundo[M]// ComputerVision – ECCV 2016. Springer International Publishing, 2016:92-107.
Después de descargar el conjunto de datos, coloque el conjunto de entrenamiento en la carpeta de datos, donde las imágenes se colocan en la carpeta imgs, la máscara se coloca en la carpeta de máscaras y el conjunto de prueba se coloca en la carpeta de prueba:
Dado que el programa original se usa para el Desafío de enmascaramiento de imágenes de Carvana , debemos modificar la lógica de carga del conjunto de datos y abrir el archivo utils/data_loading.py:
class CarvanaDataset(BasicDataset):
def __init__(self, images_dir, masks_dir, scale=1):
super().__init__(images_dir, masks_dir, scale, mask_suffix='_matte')
Cambie mask_suffix a "_matte"
tren
Abra train.py y verifique primero los parámetros globales:
def get_args():
parser = argparse.ArgumentParser(description='Train the UNet on images and target masks')
parser.add_argument('--epochs', '-e', metavar='E', type=int, default=300, help='Number of epochs')
parser.add_argument('--batch-size', '-b', dest='batch_size', metavar='B', type=int, default=16, help='Batch size')
parser.add_argument('--learning-rate', '-l', metavar='LR', type=float, default=0.001,
help='Learning rate', dest='lr')
parser.add_argument('--load', '-f', type=str, default=False, help='Load model from a .pth file')
parser.add_argument('--scale', '-s', type=float, default=0.5, help='Downscaling factor of the images')
parser.add_argument('--validation', '-v', dest='val', type=float, default=10.0,
help='Percent of the data that is used as validation (0-100)')
parser.add_argument('--amp', action='store_true', default=False, help='Use mixed precision')
return parser.parse_args()
épocas: el número de épocas, generalmente establecido en 300.
tamaño de lote: el tamaño del lote, establecido de acuerdo con el tamaño de la memoria de video.
tasa de aprendizaje: la tasa de aprendizaje, generalmente establecida en 0.001, si el optimizador es diferente, la tasa de aprendizaje inicial también debe ajustarse en consecuencia.
carga: La ruta para cargar el modelo. Si continúa con el último entrenamiento, debe configurar la ruta del archivo de peso del último entrenamiento. Si hay peso previo al entrenamiento, configure la ruta del peso previo al entrenamiento.
escala: el factor de ampliación, que aquí se establece en 0,5, y el tamaño de la imagen se cambia a la mitad del tamaño original.
validación: Porcentaje de validación del conjunto de validación.
amp: ¿Está utilizando precisión mixta?
Los parámetros más importantes son las épocas, el tamaño del lote y la tasa de aprendizaje, que se pueden ajustar repetidamente para lograr la mejor precisión.
Lo siguiente es configurar el modelo:
net = UNet(n_channels=3, n_classes=2, bilinear=True)
logging.info(f'Network:\n'
f'\t{net.n_channels} input channels\n'
f'\t{net.n_classes} output channels (classes)\n'
f'\t{"Bilinear" if net.bilinear else "Transposed conv"} upscaling')
if args.load:
net.load_state_dict(torch.load(args.load, map_location=device))
logging.info(f'Model loaded from {args.load}')
Configure el parámetro UNet, n_channels es el número de canal de la imagen imgs, si es rgb, es 3, si es una imagen en blanco y negro, es 1, n_classes se establece en 2, y el fondo también se considera como un categoría aquí, por lo que hay dos clases.
Si se establece un archivo de peso, cargue el archivo de peso. Cargar el archivo de peso para el aprendizaje de transferencia puede acelerar el entrenamiento y reducir el número de iteraciones, por lo que, si hay alguna, intente cargar los pesos previos al entrenamiento.
A continuación, modifique la lógica de la función train_net.
try:
dataset = CarvanaDataset(dir_img, dir_mask, img_scale)
except (AssertionError, RuntimeError):
dataset = BasicDataset(dir_img, dir_mask, img_scale)
# 2. Split into train / validation partitions
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train_set, val_set = random_split(dataset, [n_train, n_val], generator=torch.Generator().manual_seed(0))
# 3. Create data loaders
loader_args = dict(batch_size=batch_size, num_workers=4, pin_memory=True)
train_loader = DataLoader(train_set, shuffle=True, **loader_args)
val_loader = DataLoader(val_set, shuffle=False, drop_last=True, **loader_args)
1. Cargue el conjunto de datos.
2. Dividir el conjunto de entrenamiento y el conjunto de validación según la proporción.
3. Coloque el conjunto de entrenamiento y el conjunto de validación en el DataLoader.
# (Initialize logging)
experiment = wandb.init(project='U-Net', resume='allow', anonymous='must')
experiment.config.update(dict(epochs=epochs, batch_size=batch_size, learning_rate=learning_rate,
val_percent=val_percent, save_checkpoint=save_checkpoint, img_scale=img_scale,
amp=amp))
Configuración de wandb, wandb es una herramienta de visualización muy útil. Para conocer los métodos de instalación y uso, consulte: https://blog.csdn.net/hhhhhhhhhhwwwwwwwwwwww/article/details/116124285.
# 4. Set up the optimizer, the loss, the learning rate scheduler and the loss scaling for AMP
optimizer = optim.RMSprop(net.parameters(), lr=learning_rate, weight_decay=1e-8, momentum=0.9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2) # goal: maximize Dice score
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp)
criterion = nn.CrossEntropyLoss()
global_step = 0
1. Establezca el optimizador en RMSprop. También intenté cambiarlo a SGD. Por lo general, SGD funciona mejor. Sin embargo, durante el entrenamiento, se encontró que los resultados finales de los dos eran similares.
2. Estrategia de ajuste de la tasa de aprendizaje ReduceLROnPlateau, similar a keras. Esta vez, se utiliza la puntuación de Dice, por lo que el modo se establece en el máximo y, cuando la puntuación ya no aumenta, la tasa de aprendizaje se reduce.
3. Establezca la pérdida en nn.CrossEntropyLoss(). Entropía cruzada, una pérdida de uso común para la clasificación múltiple.
Lo siguiente es la lógica de la parte del tren, que debe modificarse de la siguiente manera:
masks_pred = net(images)
true_masks = F.one_hot(true_masks.squeeze_(1), net.n_classes).permute(0, 3, 1, 2).float()
print(masks_pred.shape)
print(true_masks.shape)
El resultado calculado por masks_pred = net(images) es: [batch, 2, 400, 300], donde 2 representa dos categorías.
true_masks.shape es [lote, 1, 400, 300], así que haga un procesamiento en caliente en true_masks. Si realiza un procesamiento onehot directamente en true_masks, encontrará que la forma procesada es [batch, 1, 400, 300, 2], que es incompatible con masks_pred, por lo que antes de realizar onehot, primero cree la segunda dimensión (también La dimensión de 1), de modo que la forma después de onehot sea [batch, 400, 300, 2], y luego ajuste el orden para que coincida con la dimensión de masks_pred.
El siguiente paso es calcular la pérdida. La pérdida se divide en dos partes, una parte es entropía cruzada y la otra parte es pérdida de dados. Estas dos pérdidas tienen sus propias ventajas y el efecto combinado es mejor. dice_loss está en el archivo utils/dice_sorce.py, el código es el siguiente:
import torch
from torch import Tensor
def dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon=1e-6):
# Average of Dice coefficient for all batches, or for a single mask
assert input.size() == target.size()
if input.dim() == 2 and reduce_batch_first:
raise ValueError(f'Dice: asked to reduce batch but got tensor without batch dimension (shape {
input.shape})')
if input.dim() == 2 or reduce_batch_first:
inter = torch.dot(input.reshape(-1), target.reshape(-1))
sets_sum = torch.sum(input) + torch.sum(target)
if sets_sum.item() == 0:
sets_sum = 2 * inter
return (2 * inter + epsilon) / (sets_sum + epsilon)
else:
# compute and average metric for each batch element
dice = 0
for i in range(input.shape[0]):
dice += dice_coeff(input[i, ...], target[i, ...])
return dice / input.shape[0]
def dice_coeff_1(pred, target):
smooth = 1.
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return 1 - (2. * intersection + smooth) / (m1.sum() + m2.sum() + smooth)
def multiclass_dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon=1e-6):
# Average of Dice coefficient for all classes
assert input.size() == target.size()
dice = 0
for channel in range(input.shape[1]):
dice += dice_coeff(input[:, channel, ...], target[:, channel, ...], reduce_batch_first, epsilon)
return dice / input.shape[1]
def dice_loss(input: Tensor, target: Tensor, multiclass: bool = False):
# Dice loss (objective to minimize) between 0 and 1
assert input.size() == target.size()
fn = multiclass_dice_coeff if multiclass else dice_coeff
return 1 - fn(input, target, reduce_batch_first=True)
Importarlo a train.py y luego combinarlo con entropía cruzada como la pérdida de este proyecto.
loss = criterion(masks_pred, true_masks) \
+ dice_loss(F.softmax(masks_pred, dim=1).float(),
true_masks,
multiclass=True)
El siguiente paso es modificar la lógica de la función de evaluación.
mask_true = mask_true.to(device=device, dtype=torch.long)
mask_true = F.one_hot(mask_true.squeeze_(1), net.n_classes).permute(0, 3, 1, 2).float()
Se agregó lógica onehot a mask_true.
Después de modificar la lógica anterior, puede comenzar a entrenar.
prueba
Después del entrenamiento, puedes probarlo. Abra predict.py y modifique los parámetros globales:
def get_args():
parser = argparse.ArgumentParser(description='Predict masks from input images')
parser.add_argument('--model', '-m', default='checkpoints/checkpoint_epoch7.pth', metavar='FILE',
help='Specify the file in which the model is stored')
parser.add_argument('--input', '-i', metavar='INPUT',default='test/00002.png', nargs='+', help='Filenames of input images')
parser.add_argument('--output', '-o', metavar='INPUT',default='00001.png', nargs='+', help='Filenames of output images')
parser.add_argument('--viz', '-v', action='store_true',
help='Visualize the images as they are processed')
parser.add_argument('--no-save', '-n', action='store_true',default=False, help='Do not save the output masks')
parser.add_argument('--mask-threshold', '-t', type=float, default=0.5,
help='Minimum probability value to consider a mask pixel white')
parser.add_argument('--scale', '-s', type=float, default=0.5,
help='Scale factor for the input images')
modelo: establezca la ruta del archivo de peso. Esto se modifica al archivo de peso entrenado por usted mismo.
escala: 0,5, correspondiente a los parámetros de entrenamiento.
Otros parámetros se ingresan a través del comando.
def mask_to_image(mask: np.ndarray):
if mask.ndim == 2:
return Image.fromarray((mask * 255).astype(np.uint8))
elif mask.ndim == 3:
img_np=(np.argmax(mask, axis=0) * 255 / (mask.shape[0]-1)).astype(np.uint8)
print(img_np.shape)
print(np.max(img_np))
return Image.fromarray(img_np)
img_np=(np.argmax(mask, axis=0) * 255 / (mask.shape[0]-1)).astype(np.uint8) La lógica aquí debe modificarse.
Código fuente:
return Image.fromarray((np.argmax(mask, axis=0) * 255 / mask.shape[0]).astype(np.uint8))
Agregamos una clase de fondo, por lo que mask.shape[0] es 2, y el fondo debe restarse.
También es necesario modificar el método de presentación de los resultados;
def plot_img_and_mask(img, mask):
print(mask.shape)
classes = mask.shape[0] if len(mask.shape) > 2 else 1
fig, ax = plt.subplots(1, classes + 1)
ax[0].set_title('Input image')
ax[0].imshow(img)
if classes > 1:
for i in range(classes):
ax[i + 1].set_title(f'Output mask (class {
i + 1})')
ax[i + 1].imshow(mask[i, :, :])
else:
ax[1].set_title(f'Output mask')
ax[1].imshow(mask)
plt.xticks([]), plt.yticks([])
plt.show()
Cambie el ax[i + 1] original.imshow(mask[:, :, i]) a: ax[i + 1].imshow(mask[i, :, :]).
Ejecutando una orden:
python predict.py -i test/00002.png -o output.png -v
Resultado de salida:

¡En este punto, hemos logrado el recorte completo del personaje de la imagen de fondo!
Resumir
Este artículo implementa la segmentación de imágenes con Unet, a través de este artículo puedes aprender:
1. Cómo usar Unet para la segmentación semántica de la clasificación de pares de imágenes en dos.
2. Cómo usar la visualización wandb.
3. Cómo usar la combinación de entropía cruzada y dice_loss.
4. Cómo realizar la predicción de la segmentación semántica de dos categorías.
Código completo:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwwwww/85083165