Fuente | Identificación del corazón de la máquina | casihumano2014
Recientemente, un dron autónomo derrotó a los mejores jugadores humanos en una competencia de drones.
Este dron controlado de forma autónoma es un sistema Swift diseñado y desarrollado por un equipo de investigación de la Universidad de Zurich, cuyos resultados aparecen en la portada del último número de la revista Nature.

Contenido de la investigación: https://www.nature.com/articles/s41586-023-06419-4
En esta carrera de drones, el operador humano controla el dron a través de una pista 3D a través de una cámara a bordo, lo que le permite observar el entorno desde la perspectiva del dron. Es un gran desafío para los drones autónomos alcanzar el nivel de los drones controlados por humanos porque el dron necesita estimar su velocidad y posición en la pista utilizando únicamente sensores a bordo.
Swift derrotó a los jugadores humanos campeones del mundo: el campeón mundial de la Drone Racing League 2019 Alex Vanover, el dos veces campeón del MultiGP International Open Thomas Bitmatta y el tres veces campeón nacional suizo Marvin Schaepper.
La Figura 1a a continuación es la pista de esta competencia. Swift no solo ganó la carrera contra el campeón humano, sino que también estableció el récord de carrera más rápido. Este trabajo supone un hito en el campo de la robótica móvil y la inteligencia artificial.

Figura 1
Echemos un vistazo a los métodos técnicos del dron autónomo Swift.
Introducción rápida a la tecnología
Swift es un cuadricóptero que se controla de forma autónoma utilizando únicamente sensores e informática a bordo y consta de dos módulos clave:
-
Sistema de percepción, que convierte información visual e inercial de alta dimensión en representaciones de baja dimensión;
-
La estrategia de control ingiere la representación de baja dimensión generada por el sistema de detección y genera comandos de control.
Entre ellos, la política de control está representada por una red neuronal de retroalimentación y entrenada mediante aprendizaje de refuerzo profundo (RL) basado en políticas sin modelos.
Dado que existen diferencias en la detección y la dinámica entre la simulación y el mundo real, optimizar las estrategias solo en la simulación conducirá a un rendimiento deficiente de los UAV en el mundo real, por lo que el equipo de investigación utilizó datos recopilados del sistema físico para estimar un ruido empírico no paramétrico. modelo (modelo de ruido empírico no paramétrico). Los experimentos muestran que estos modelos empíricos de ruido ayudan a transferir con éxito las estrategias de control de la simulación a la realidad.
Específicamente, Swift mapea las lecturas de los sensores a bordo en comandos de control. Este mapeo consta de dos partes: (1) una estrategia de observación que refina la información visual e inercial de alta dimensión en codificaciones de baja dimensión específicas de la tarea; (2) una estrategia de control que convierte codificación en comandos de drones. La descripción general del sistema Swift se muestra en la Figura 2 a continuación:
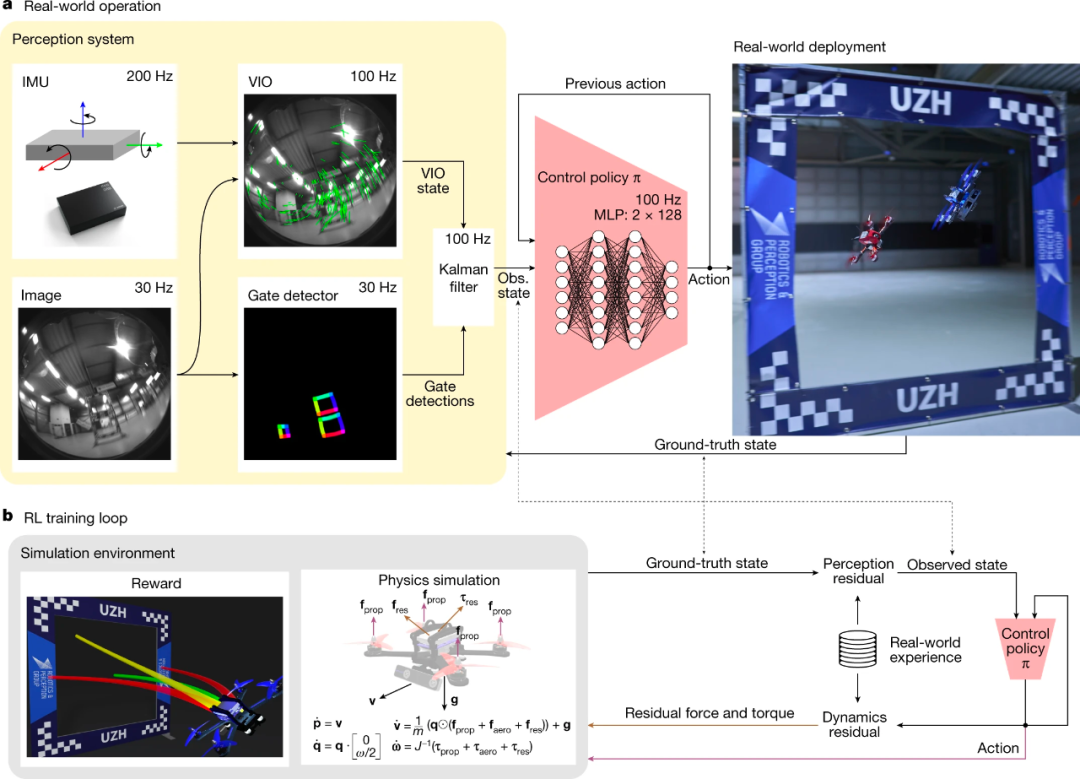
Figura 2
Como en el escenario que se muestra en la Figura 1, la estrategia de observación de Swift requiere ejecutar un estimador visual-inercial y un detector de puertas. Entre ellos, el detector de puertas es una red neuronal convolucional que se utiliza para detectar puertas de carrera en imágenes aéreas y luego utiliza las puertas detectadas para estimar la posición global y la dirección de vuelo del dron en la pista. Esto se hace utilizando un algoritmo de resección de cámara, combinado con un mapa de seguimiento. Finalmente, Swift utiliza un filtro de Kalman para combinar la estimación de pose global (obtenida del detector de puerta) con la estimación visual-inercial para caracterizar con mayor precisión el estado del robot.
La estrategia de control (representada por un perceptrón de dos capas) es responsable de mapear la salida del filtro de Kalman en los comandos de control del UAV. La política de control se entrena en simulación utilizando el aprendizaje por refuerzo profundo (RL) sobre políticas sin modelos. Durante el entrenamiento, la política considera información sobre la siguiente puerta de competencia dentro del campo de visión de la cámara, maximizando la recompensa para mejorar la precisión de la estimación de la pose.
Experimentos y resultados
Para evaluar el desempeño de Swift, el estudio realizó una serie de experimentos de competencia y los comparó con la planificación de trayectorias y el control predictivo del modelo (MPC).
Como se muestra en la Figura 3b a continuación, Swift ganó 5 de 9 juegos contra A. Vanover, Swift ganó 4 de 7 juegos contra T. Bitmatta y Swift ganó 4 de 9 juegos contra M. Schaepper. Swift ganó 6 juegos. De las 10 pérdidas registradas por Swift, el 40% se debió a colisiones con oponentes, el 40% a colisiones con puertas de competencia y el 20% a ser más lento que los drones controlados por humanos. En general, Swift ganó la mayor cantidad de carreras contra drones controlados por humanos y también estableció el récord de carrera más rápido, superando el mejor tiempo de un drone controlado por humanos (A. Vanover) por media docena de segundos.

imagen 3
Para realizar un análisis más detallado del rendimiento de Swift, el estudio comparó las velocidades de vuelo más rápidas de una sola vuelta de Swift y los drones controlados por humanos. Los resultados se muestran en la Figura 4 y la Tabla 1 a continuación.
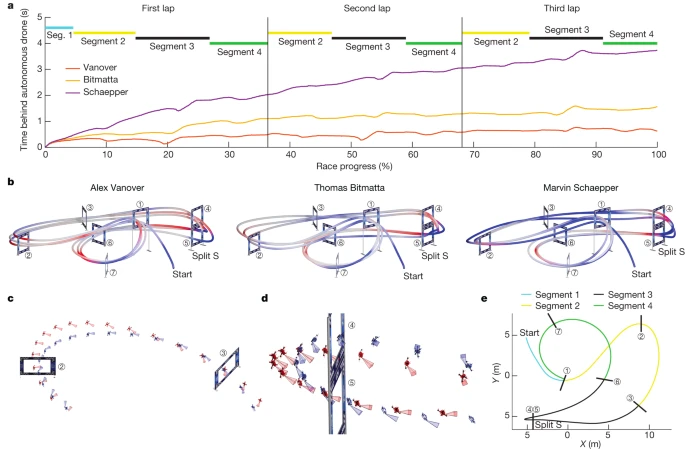
Figura 4
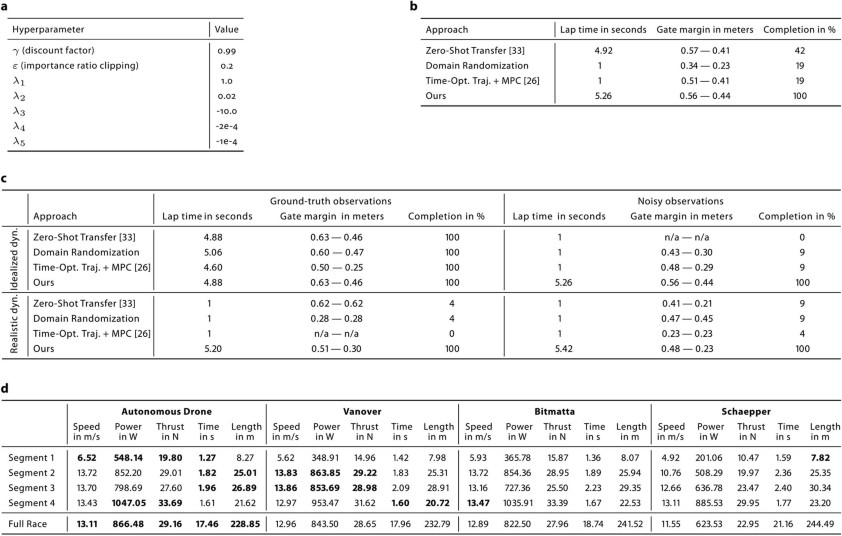
tabla 1
Si bien Swift fue más rápido que todos los drones controlados por humanos en general, no fue más rápido en cada segmento de la pista, como se muestra en la Tabla 1.
Un análisis cuidadoso realizado por el equipo de investigación encontró que: al despegar, Swift tiene un tiempo de reacción más corto y despega 120 milisegundos antes que los pilotos humanos en promedio; Swift también acelera más rápido y entra a la primera puerta de competencia a mayor velocidad. Durante los giros cerrados, como se muestra en la Figura 4cd, los movimientos de Swift son más compactos.
El equipo de investigación también planteó la hipótesis de que Swift optimiza las trayectorias en escalas de tiempo más largas que los operadores humanos. Es bien sabido que la RL sin modelos puede optimizar la recompensa a largo plazo a través de la función de valor. Por el contrario, los operadores humanos planifican los movimientos en escalas de tiempo más cortas y como máximo solo pueden predecir una puerta de carrera hacia el futuro.