Einführung in Omnidata-Hive-Connector
Der Omnidata-Hive-Connector ist ein Dienst, der die Betreiber der Big-Data-Komponente Hive auf die Speicherknoten drängt, wodurch datennahes Computing realisiert, die Netzwerkbandbreite reduziert und die Abfrageleistung von Hive verbessert wird. Unterstützt derzeit Hive auf Tez. omnidata-hive-connector wurde in der openEuler-Community als Open Source bereitgestellt.
OmniData-Architektur
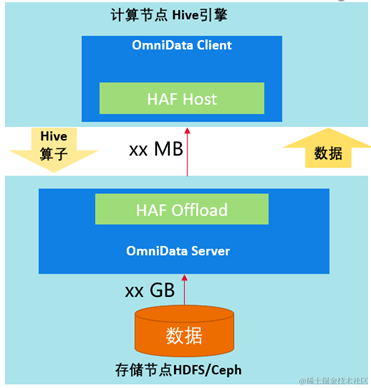
OmniData ist der allgemeine Begriff für Operator-Pushdown. OmniData besteht im Wesentlichen aus den folgenden vier Teilen:
1. OmniData Client ist ein Open-Source-Teil und stellt entsprechende Plug-Ins für verschiedene Engines bereit. Für die Hive-Engine dient der Omnidata-Hive-Connector als OmniData-Client und nutzt HAF-Annotationen und kompilierte Plug-in-Funktionen, um Aufgaben automatisch an den OmniData-Server des Speicherknotens zu übertragen.
2. Haf Host ist eine Bibliothek, die auf Rechenknoten bereitgestellt wird und Funktionen zum Auslagern externer Aufgaben bereitstellt und Aufgaben an Haf Offload weiterleitet.
3. Haf Offload ist eine Bibliothek, die auf dem Speicherknoten bereitgestellt wird, um Aufgabenausführungsfunktionen bereitzustellen und zum Ausführen von OmniData Server-Jobs verwendet wird.
4. OmniData Server bietet die Möglichkeit zur Ausführung von Operator-Pushdowns und empfängt von Haf Host übertragene Aufgaben.
Omnidata-Hive-Connector-Funktion
1. Implementieren Sie die Filter-, Aggregations- und Limit-Operatoren von Hive, um sie zur Berechnung an die Speicherknoten weiterzuleiten, Daten im Voraus zu filtern, die Menge der Netzwerkübertragungsdaten zu reduzieren und die Leistung zu verbessern.
2. Registrieren Sie sich per Plug-in bei Hive, implementieren Sie den Operator-Pushdown lose gekoppelt und aktivieren oder aktivieren Sie ihn über den Funktionsschalter.
3. Implementieren Sie das Pushdown des HDFS/Ceph-Dateisystems.
4. Implementieren Sie das Pushdown des Orc/Parquet-Dateispeicherformats.
5. Implementieren Sie den Pushdown der integrierten UDF von Hive (Cast, Instr, Länge, Lower, Replacement, Substr und Upper).
Anwendungsszenarien für den Omnidata-Hive-Connector
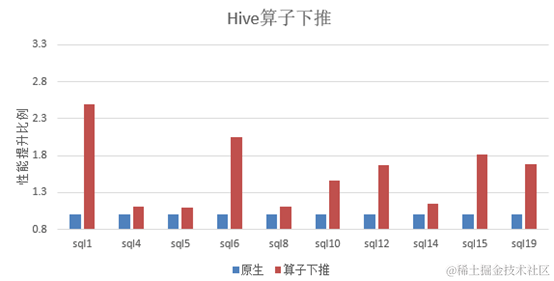
Führen Sie im Szenario der Speicher- und Berechnungstrennung der typischen Hardwarekonfiguration der Big-Data-Komponente Hive die Standardtestfälle TPC-H bzw. Omnidata-Hive-Connector aus.
Es ist ersichtlich, dass nach der Ausführung von Omnidata-Hive-Connector die Leistung von 10 SQLs im Durchschnitt um mehr als 40 % verbessert wird .
Hauptoptimierungsmethoden des Omnidata-Hive-Connectors
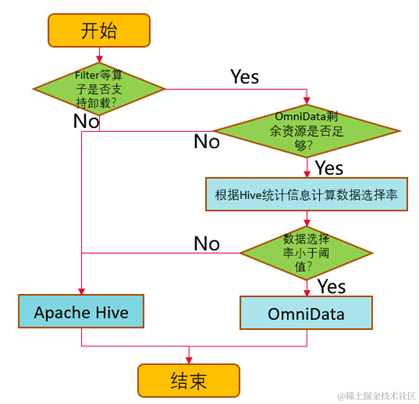
1. Erzielen Sie einen dynamischen Pushdown basierend auf der Datenauswahlrate.
Omnidata-Hive-Connector berechnet die Datenauswahlrate anhand statistischer Hive-Informationen (je niedriger die Auswahlrate, desto mehr Daten werden gefiltert). Durch Festlegen des Schwellenwerts für die Push-Down-Auswahlrate über Parameter kann Omnidata-Hive-Connector die Auswahl dynamisch reduzieren Rate zu niedrig Operatoren, die größer als der Schwellenwert sind, werden zur Ausführung an den Speicherknoten weitergeleitet, sodass der Speicherknoten Daten lokal zur Berechnung lesen und dann den berechneten und gefilterten Datensatz über das Netzwerk an den Rechenknoten zurücksenden kann, wodurch die Netzwerkübertragungseffizienz verbessert wird Optimierung der Leistung. Zusätzlich zur Datenauswahlrate wird die Beurteilung auch darauf basieren, ob der Betreiber unterstützt wird und ob die verbleibenden Ressourcen ausreichend sind.
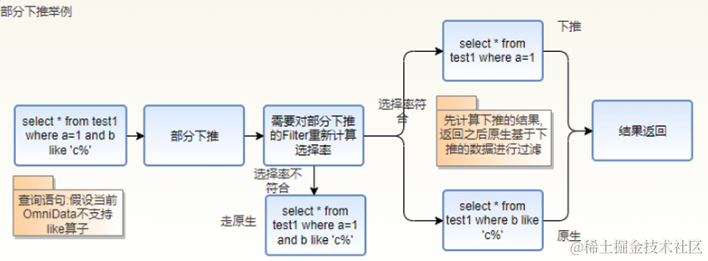
2. Drücken Sie den Filterteil nach unten.
Wenn in einem Filter sowohl Operatoren vorhanden sind, die Pushdown unterstützen, als auch Operatoren, die Pushdown nicht unterstützen, erstellt der Omnidata-Hive-Connector einen neuen Filter für den nicht unterstützten Operator, verwendet den nativen Hive-Berechnungsprozess und berechnet den Operator, der Pushdown unterstützt, neu Wählen Sie die Auswahlrate aus und bestimmen Sie, ob basierend auf der neuen Auswahlrate nach unten gedrückt werden soll.
3. Speicher- und Computerzusammenarbeit, rationelle Nutzung von Computerressourcen.
Der Omnidata-Hive-Connector drängt Bediener zur Durchführung von Berechnungen zu den Speicherknoten, wodurch die CPU-Auslastung der Rechenknoten effektiv reduziert und die CPU der Speicherknoten genutzt werden kann, um die Recheneffizienz insgesamt zu verbessern. Am Beispiel von TPC-Hs SQL lag die durchschnittliche CPU-Auslastung des Rechenknotens vor der Optimierung bei über 60 %. Nach der Optimierung lag die durchschnittliche CPU-Auslastung des Rechenknotens bei etwa 40 %.
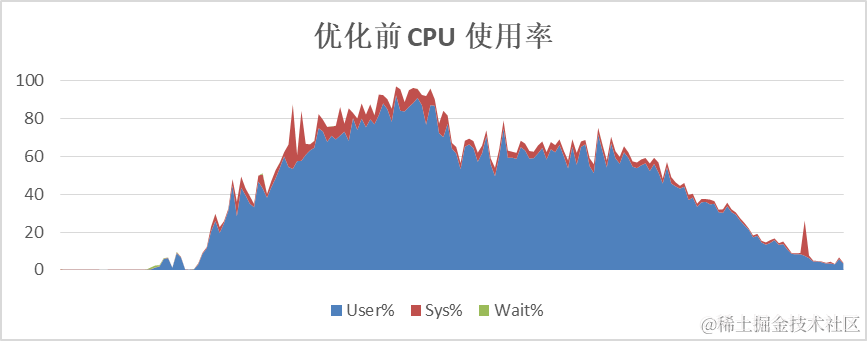
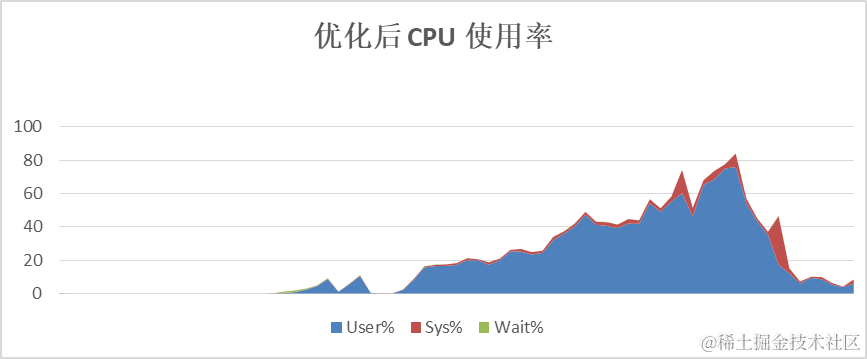
4. Filtern Sie Daten im Voraus, um die Netzwerkübertragung zu reduzieren.
Die Vorfilterung von Daten ist die Hauptquelle für Leistungssteigerungen bei Omnidata-Hive-Connectoren. Sie filtert Daten an Speicherknoten, reduziert die Netzwerkübertragung und reduziert die von Rechenknoten verarbeitete Datenmenge.
Nehmen Sie als Beispiel TPC-Hs SQL. SQL enthält mehrere Filter. Vor der Optimierung muss der Bediener fast 6 Milliarden Datenzeilen von Remote-Speicherknoten im gesamten Netzwerk lesen; nach der Optimierung müssen nur 40 Millionen Zeilen gefilterter gültiger Daten sein übermittelt. OK. Die Ausführungseffizienz stieg um mehr als 60 %.
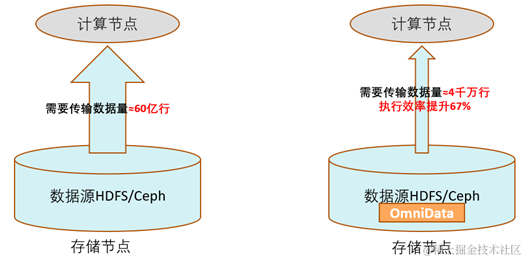
Omnidata-Hive-Connector-Folgeplanung
Dieses Projekt wurde in der openEuler-Community als Open Source bereitgestellt. Die Omnidata-Hive-Connector-Funktion wird aktiv neue Funktionen unterstützen. Der Folgeplan sieht wie folgt aus:
1. Unterstützt Zeitstempel- und Dezimaldatenformate.
2. Unterstützt Pushdown des BloomFilter-Operators.
3. Unterstützen Sie das Pushdown benutzerdefinierter Funktionen.
Codeadresse:
https://gitee.com/openeuler/omnidata-hive-connector
Interessierte Freunde sind herzlich willkommen, der openEuler Bigdata SIG beizutreten und über Technologien im Bereich Big Data zu diskutieren.