Descarga de un modelo
2. Razonamiento modelo
Este artículo se basa en la introducción del código del proyecto chino-LLaMA-Alpaca-2 y utiliza el nativo llama2-hf.
Después de clonar el proyecto chino-LLaMA-Alpaca-2 , la implementación basada en GPU es muy simple. Después de la descarga, los parámetros del modelo (en formato Hugging Face) son los siguientes:
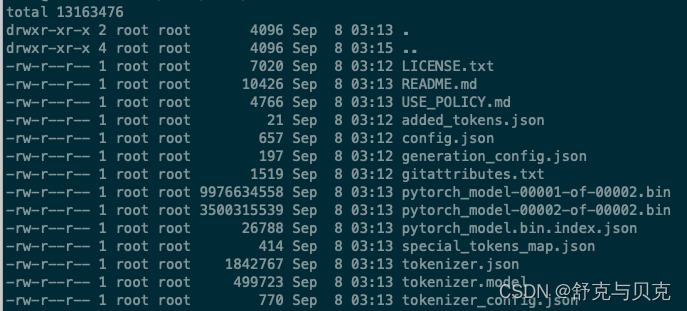
Explique brevemente la función de cada archivo.
| Nombre del archivo | ejemplo | ilustrar |
|---|---|---|
| configuración.json | { "arquitecturas": [ "LlamaForCausalLM" ], "hidden_size": 4096, ... "vocab_size": 55296 }
|
La ruta del documento del archivo de configuración de Hugging Face Transformer se encuentra en https://huggingface.co/docs/transformers/main/main_classes/configuration |
| generacion_config.json | { "_from_model_config": verdadero, "bos_token_id": 1, "eos_token_id": 2, "pad_token_id": 0, "transformers_version": "4.31.0" }
|
Esto es principalmente para proporcionar parámetros para el método de generación https://huggingface.co/docs/transformers/main_classes/text_generación |
| pytorch_model.bin.index.json | { "metadatos": { "total_size": 13858521088 }, "weight_map": { ... } }
|
Contiene algunos metadatos y una tabla de asignación de nombres de parámetros, incluida información de indicación de peso. |
| pytorch_model - * .bin | Dictados de estado estándar de Pytorch, cada uno de los cuales contiene una parte del modelo | |
| mapa_tokens_especial.json | { ... "pad_token": "", "unk_token": { "content": "", "lstrip": false, "normalized": true, "rstrip": false, "single_word": false } }
|
Archivo de mapeo, que contiene relaciones de mapeo de caracteres especiales como token desconocido; |
| tokenizer_config.json | { "add_bos_token": verdadero, ... "unk_token": { "__type": "AddedToken", "content": "", "lstrip": falso, "normalizado": verdadero, "rstrip": falso, "single_word" ": falso }, "use_fast": falso }
|
分词器配置文件,存储构建分词器需要的参数 |
| tokenizer.model | 标记器(Tokenizer):将文本转换为模型可以处理的数据。模型只能处理数字,因此标记器(Tokenizer)需要将我们的文本输入转换为数字数据。 |
模型推理 Chinese-LLaMA-Alpaca-2 提供了一些使用脚本,可以很方便的体验模型推理的过程 教程
aiofiles==23.1.0
fastapi==0.95.2
gradio_client==0.2.5
gradio==3.33.1
accelerate==0.22.*
colorama
datasets
einops
markdown
numpy==1.24
optimum==1.12.0
pandas
peft==0.5.*
transformers==4.33.1
Pillow>=9.5.0
pyyaml
requests
safetensors==0.3.2
scipy
sentencepiece==0.1.99
tensorboard
tqdm
wandb
# bitsandbytes
bitsandbytes==0.41.1启动运行环境(使用docker):
docker run -it -v `pwd`:/home/work --gpus 1 pytorch:2.0.1-transformers /bin/bash
python scripts/inference/inference_hf.py --base_mode /home/work/llama2/ --with_prompt --interactive
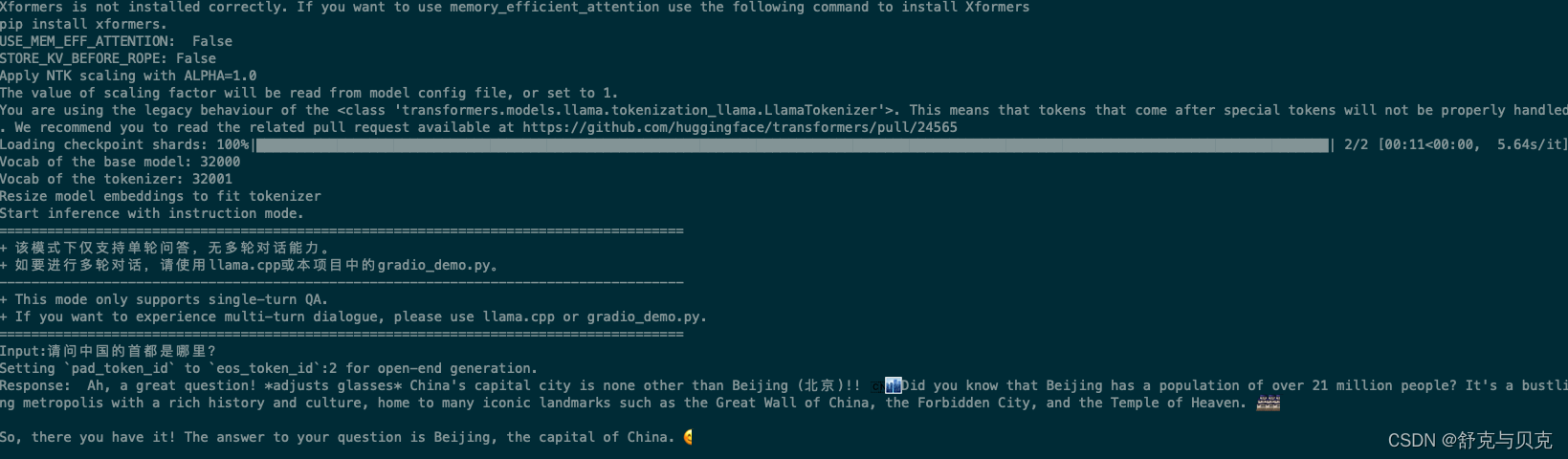

可以看出原生的LLAMA2模型对中文支持不好,回答的答案基本都是英文
三、搭建text-generation-webui
text-generation-webui是github上的一个开源项目,也是目前运行开源模型最广泛使用的软件之一。如果你之前用过第一代LLama,应该对这个项目比较熟悉。
text-generation-webui的安装方式相当简单,同样需要从github上克隆项目:https://github.com/oobabooga/text-generation-webui。克隆完成后,我们把刚才转换好的huggingface格式的模型文件夹整个放入models中,目录结构如下:
我们将刚才生成好huggingface格式的模型文件夹整个放入models中,文件结构如下图:

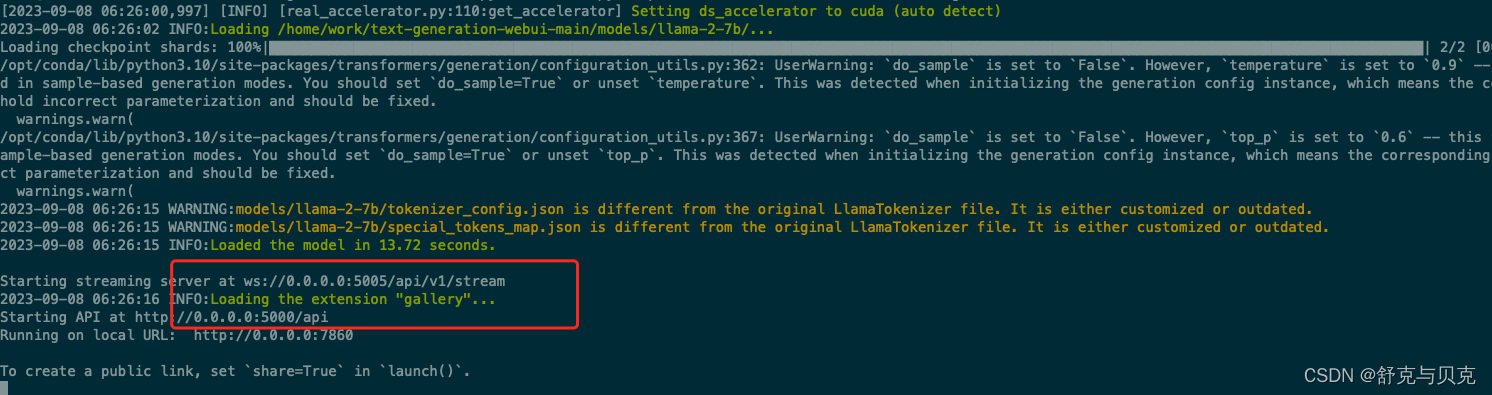
如果这一步做完了,模型部署这块就大功告成啦。现在我们运行text-generation-webui就可以和llama2模型对话了,具体的命令如下:
python server.py --api --listen --model /home/work/text-generation-webui-main/models/llama-2-7b/
四、使用模型
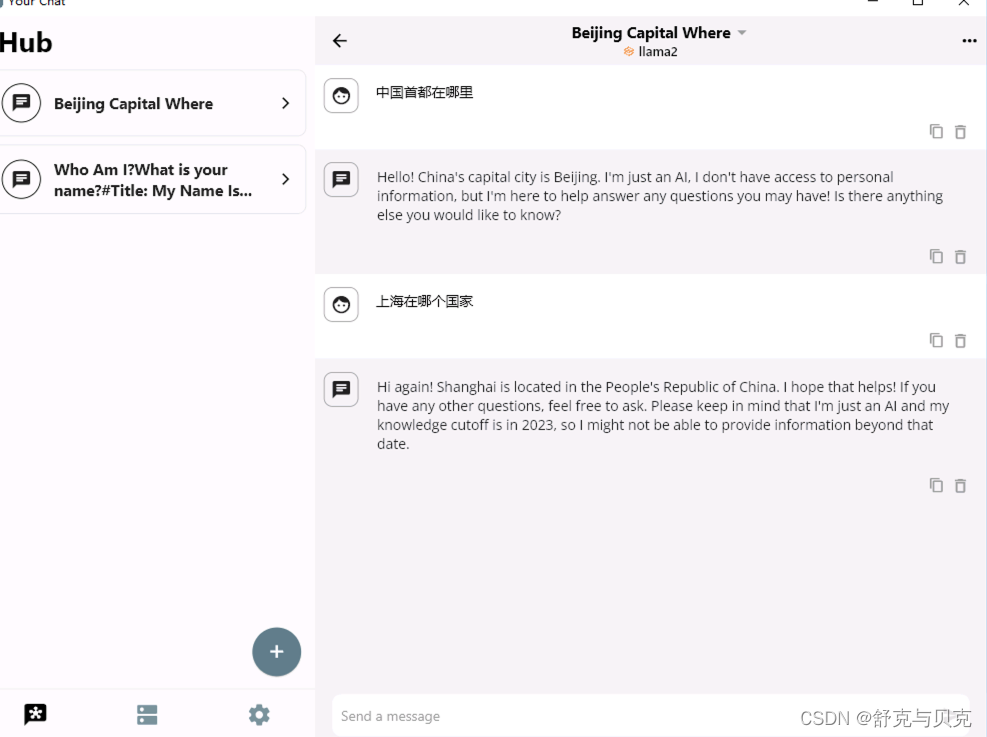
现在,LLama2模型已经搭建好了,怎么样把它分享给你的朋友或同事使用呢?
我们用YourChat来完成这个工作。YourChat是一个聊天客户端,它支持text_generation_webui的API,适配了Android、iOS、Windows和MacOS,以下我们以Windows版本为例,当然其他平台也大同小异。 下载地址:https://yourchat.app/download
在上一步,我们在启动text_generation_webui的时候添加了一个--api参数,这就让text_generation_webui支持了API调用。如果你想要使用YourChat,那这个API功能就必须要打开。
首先,让我们把刚刚搭建的text_generation_webui添加到YourChat的服务里面。如果是第一次使用YourChat,它会弹出一个新手教程。如果text-generation-webui参数没有动过,那就按照教程的指引,填入服务的IP地址就可以了。
如果之前已经下载过YourChat,那就在YourChat的"服务"界面,点击右下角的"+"按钮,添加一个新的服务。在"名称"栏中,输入你的服务名称,比如模型名字"llama-2-7b"。在"Host"栏中,填写你的模型服务器的地址,例如"192.168.1.100"。
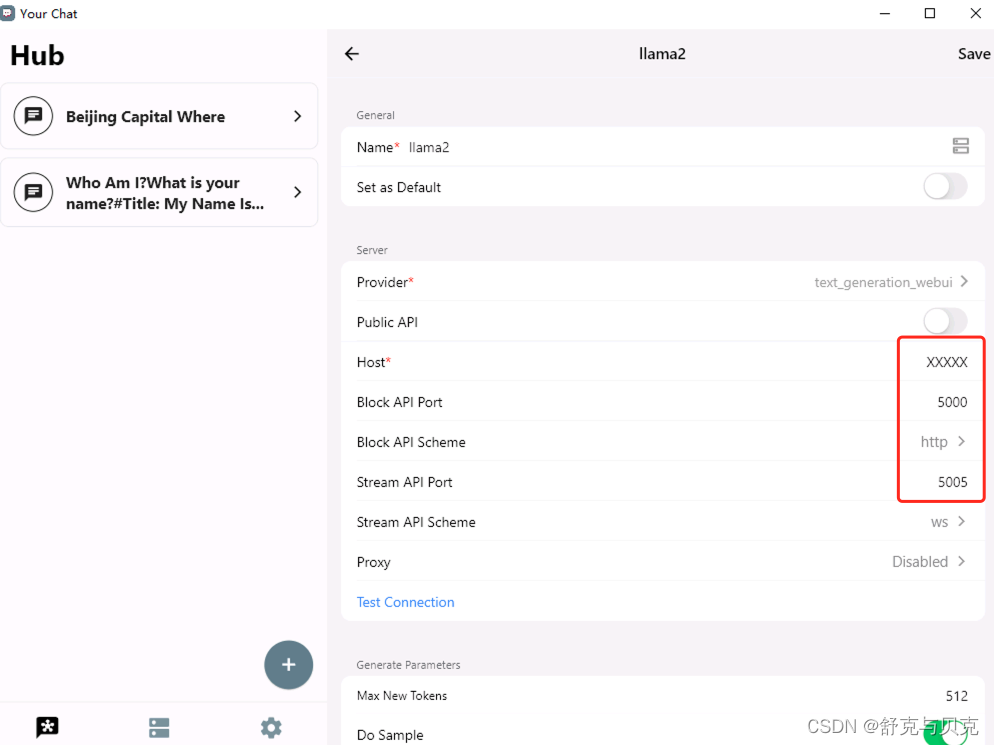
然后点击右上角的保存按钮,你的Llama2模型就成功地被添加到了YourChat中,你现在可以开始和LLama2进行聊天了。
LLama 2干货部署教程+模型分发 - 知乎 (zhihu.com)
Ajuste de la serie LLama2 desde cero (2): Ejecute llama2 - Zhihu (zhihu.com)