LLaMA2 de LLM: una introducción detallada a LLaMA2 (detalles técnicos), instalación, uso (código abierto gratuito para investigación y uso comercial)
Guía : ¡El 18 de julio de 2023, Meta lanzará Llama 2! Se trata de un conjunto de modelos de lenguaje grande (LLM) preentrenados y ajustados que varían en tamaño de 7 mil millones a 70 mil millones de parámetros. El LLM Meta-fine-tuned se llama Llama 2-Chat, que está optimizado para escenarios de uso conversacional. El modelo Llama 2 supera al modelo de chat de código abierto en la mayoría de los puntos de referencia que probamos y puede ser un reemplazo apropiado para el modelo de código cerrado en cuanto a confiabilidad y seguridad, según las evaluaciones humanas de Meta. Meta proporciona instrucciones detalladas sobre cómo ajustar y mejorar la seguridad de Llama 2-Chat para que la comunidad se base en el trabajo de Meta y contribuya al desarrollo responsable de LBM.
Llama 2 = Llama 1 [RoPE+RMSNorm+SwiGLU+AdamW] + 40 % de volumen de datos nuevos + tokens 2T + 4096 + SFT de alta calidad + alineación RLHF [PPO + ajuste de muestreo de rechazo] : el modelo Llama 2 está entrenado en 2 billones de tokens , y el modelo Llama-2-chat también ha entrenado más de 1 millón de nuevas anotaciones humanas. Llama 2 tiene un 40% más de datos que Llama 1 y duplica la longitud del contexto . Y Llama-2-chat utiliza el aprendizaje por refuerzo a partir de la retroalimentación humana.para ser seguro y útil. Llama 2 adopta la mayor parte de la configuración previa al entrenamiento y la arquitectura del modelo de Llama 1, incluida la arquitectura de transformador estándar, la normalización previa mediante RMSNorm, la función de activación de SwiGLU y la incorporación de posición rotada. El optimizador AdamW se utiliza para el entrenamiento, donde β_1 = 0,9, β_2 = 0,95, eps = 10^−5. Al mismo tiempo, se utilizó un programa de tasa de aprendizaje de coseno (2000 pasos de calentamiento), y la tasa de aprendizaje final se redujo al 10 % de la tasa de aprendizaje máxima. Meta entrenó previamente el modelo en su Research Super Cluster (RSC), así como en su clúster de producción interno. Tres
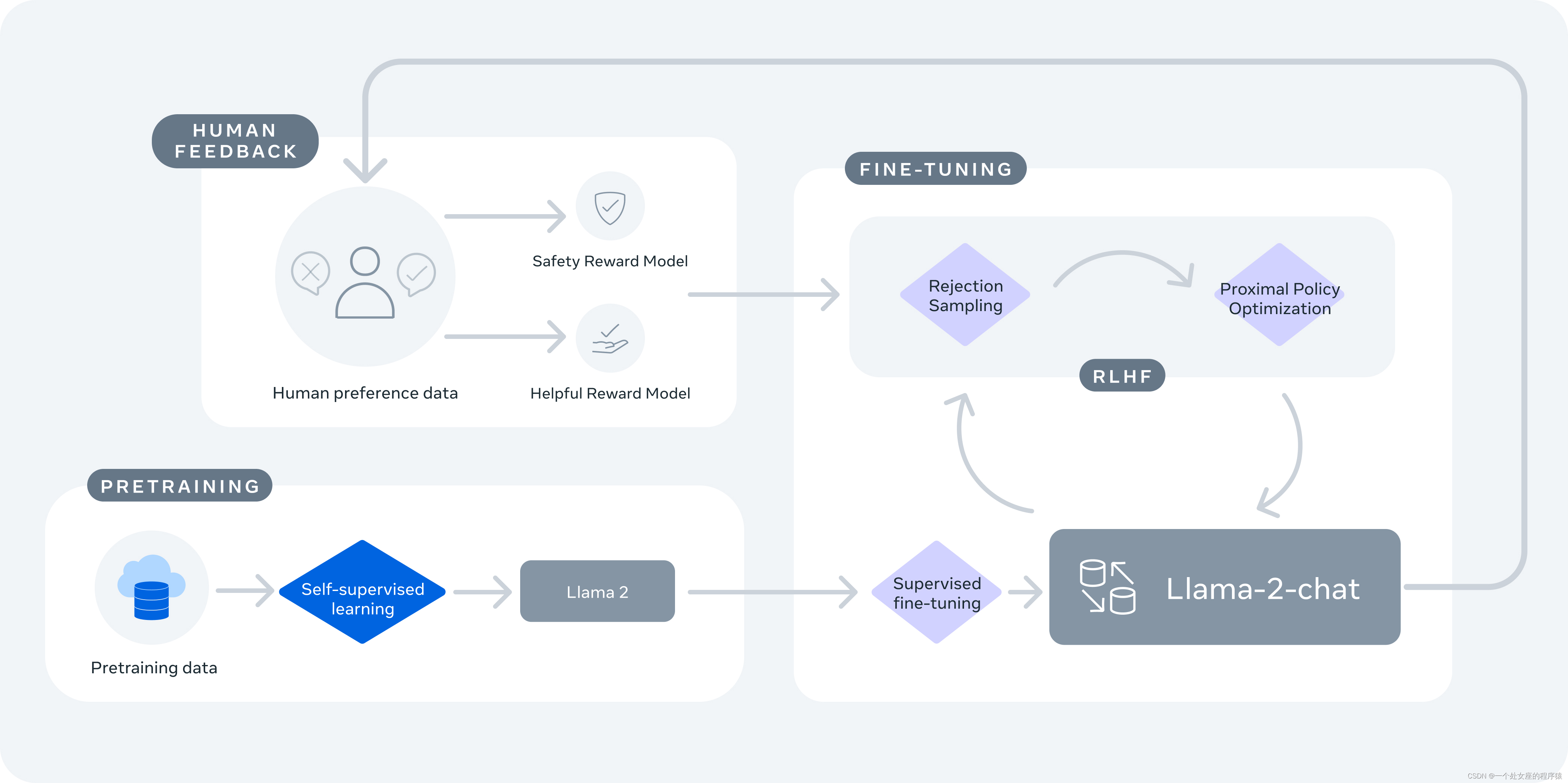
puntos de referencia comúnmente utilizados evaluaron la seguridad de Llama 2 : el punto de referencia TruthfulQA para la autenticidad + el punto de referencia ToxiGen para la toxicidad + el punto de referencia BOLD para el sesgo. Meta utiliza ajuste fino seguro supervisado, RLHF seguro, destilación de contexto seguro en ajuste fino seguro. RLHF comienza recopilando datos sobre las preferencias humanas por la seguridad, donde los anotadores escriben indicaciones que creen que provocan un comportamiento inseguro, luego comparan múltiples respuestas modelo a las indicaciones y seleccionan la respuesta más segura según un conjunto de pautas. Luego, los datos de preferencia humana se utilizan para entrenar un modelo de recompensa seguro, y se reutiliza un indicador adversario en la etapa RLHF para tomar muestras del modelo. Meta refina la tubería RLHF con destilación de contexto.
El rendimiento del modelo es de código abierto y el espectáculo + alto costo [ A100 ] + aún sigue la ruta abierta: Ambos metaclusters usan NVIDIA A100. Nathan Lambert, científico de aprendizaje automático de HuggingFace, estima que entrenar Llama 2 podría costar más de 25 millones de dólares. Meta publicó una gran cantidad de detalles de los datos de entrenamiento del modelo Llama 2, métodos de entrenamiento, etiquetado de datos, ajuste fino, etc. La comparación encontró que, con la misma escala de parámetros, Llama 2 es más capaz que todos los modelos grandes de código abierto. Los resultados de la evaluación publicados muestran que Llama 2 es mejor que otros modelos de lenguaje de código abierto en muchos puntos de referencia externos, incluidos el razonamiento, la codificación, la competencia y las pruebas de conocimiento.
El nacimiento de Llama 2, así como su temperamento de código abierto, insiste directamente en aquellos que dicen que quieren ser abiertos pero no lo son en absoluto, GPT-4, que ha estado construyendo una "valla técnica", y PaLM 2 de Google. Llama 2 será un hito importante para los LLM en el campo de código abierto.En el futuro, habrá una alta probabilidad de acelerar los cambios en el patrón y la ecología del mercado de modelos de lenguaje grande.
Entonces, hoy, ¿has cambiado la base de tus LLM?
Tabla de contenido
1. Descargar Descargar modelos de pesos y tokenizadores
T1 Descarga desde el sitio web oficial
T2, descarga basada en Hugging Face
(2), modelo de pre-entrenamiento
(3), afinando el modelo de chat
Artículos relacionados
LLaMA de LLMs: Traducción e Interpretación de "LLaMA: Open and Efficient Foundation Language Models"
Introducción a LLaMA2
| DIRECCIÓN |
GitHub地址:GitHub - facebookresearch/llama: Código de inferencia para modelos LLaMA Dirección del artículo: Dirección del blog: https://ai.meta.com/resources/models-and-libraries/llama/ |
| tiempo |
18 de julio de 2023 |
| autor |
Meta |
Introducción a LLaMA2
El 18 de julio de 2023, Meta lanzó en gran medida Llama 2. Como se indica en el sitio web oficial, Meta está liberando el poder de estos grandes modelos de lenguaje. Llama 2 ahora está disponible para individuos, creadores, investigadores y empresas para que puedan experimentar, innovar y escalar sus ideas de manera responsable. Esta versión incluye pesos de modelo y código de inicio para el entrenamiento previo y el ajuste fino del modelo de lenguaje Llama, que van desde los parámetros 7B a 70B.
Llama 2 está preentrenado en fuentes de datos en línea disponibles públicamente. El modelo perfeccionado Llama-2-chat aprovecha un conjunto de datos de instrucciones disponible públicamente con más de 1 millón de anotaciones humanas. Internamente, el modelo Llama 2 se entrena en 2 billones de tokens con el doble de la longitud de contexto de Llama 1. El modelo Llama-2-chat también se entrenó en más de 1 millón de nuevas anotaciones humanas. Llama 2 tiene un 40 % más de datos que Llama 1 y duplica la longitud del contexto. Además, Llama-2-chat utiliza el aprendizaje por refuerzo a partir de la retroalimentación humana para ser seguro y útil.
Llama-2-chat está preentrenado en Llama 2 utilizando datos en línea disponibles públicamente. A continuación, se crea una versión inicial de Llama-2-chat mediante un ajuste fino supervisado. A continuación, la optimización iterativa de Llama-2-chat se realiza mediante el aprendizaje de refuerzo a partir de la retroalimentación humana (RLHF), que incluye el muestreo de rechazo y la optimización de políticas proximales (PPO).
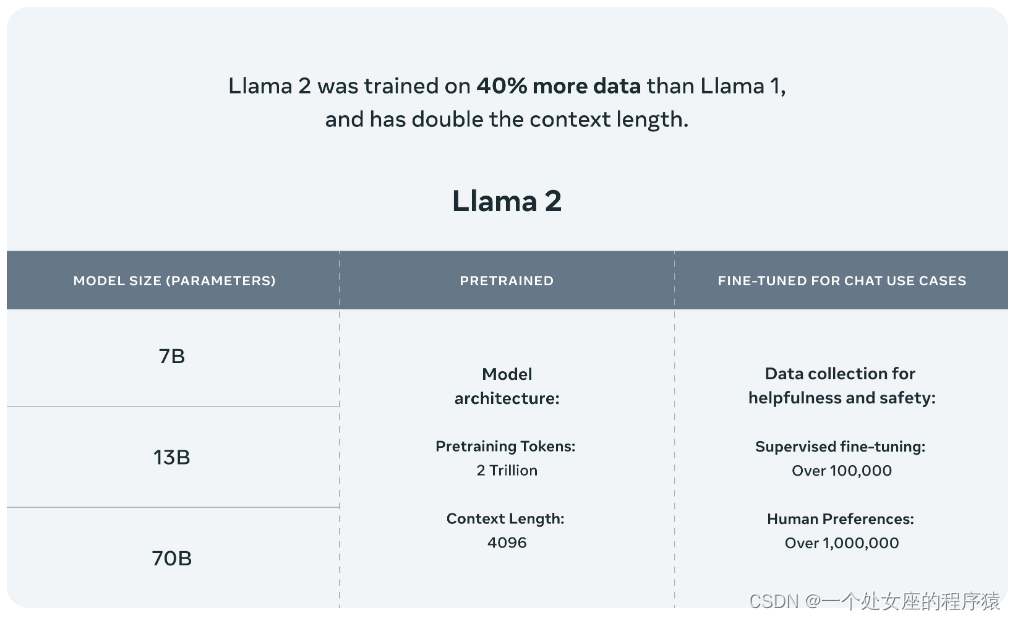
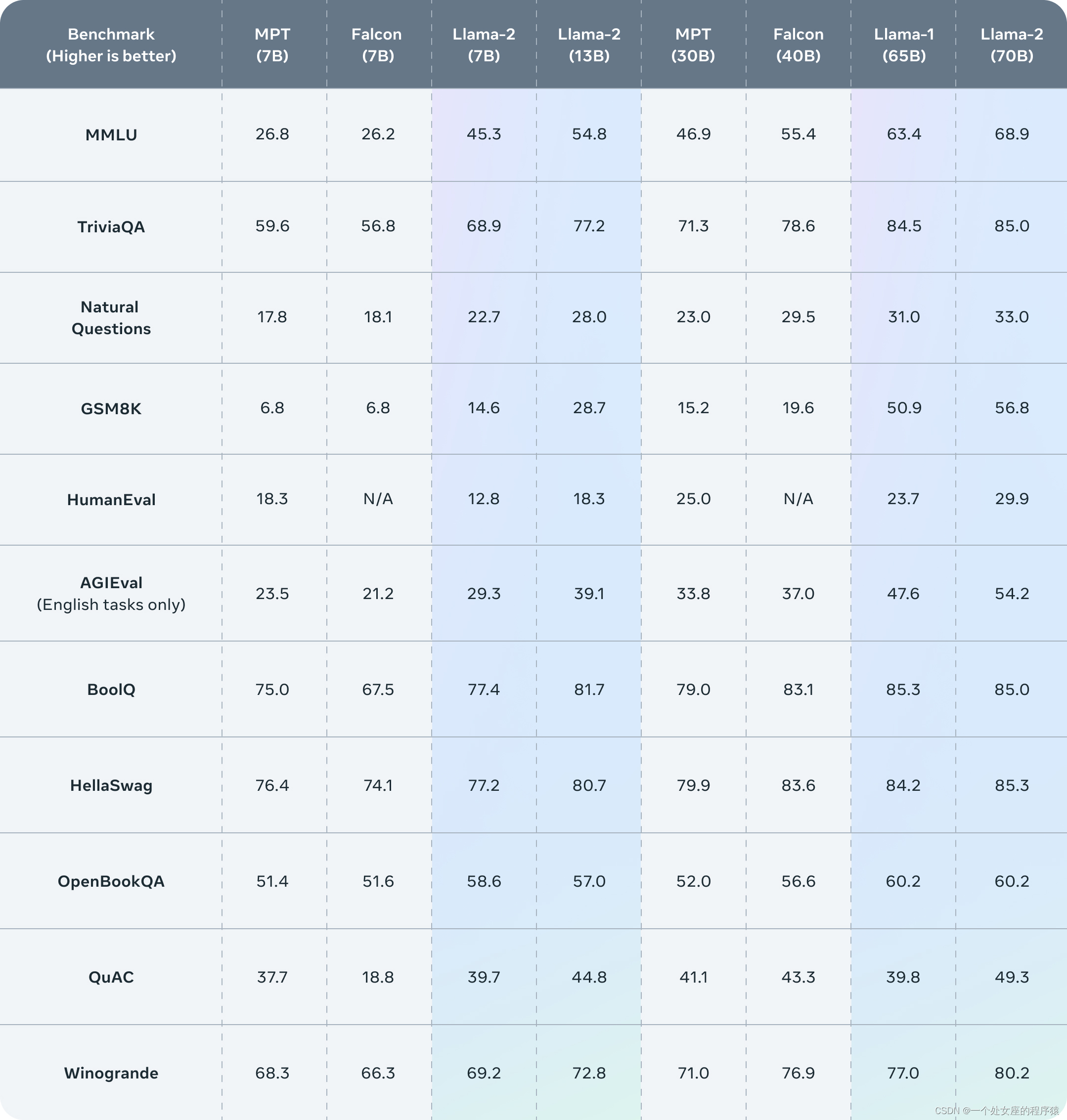
1. Prueba comparativa
Llama 2 supera a otros modelos de lenguaje de código abierto en muchos puntos de referencia externos, incluidas las pruebas de inferencia, codificación, competencia y conocimiento.
2. Llama-2-chat utiliza el aprendizaje por refuerzo a partir de comentarios humanos para ser seguro y útil
Instalación de LLaMA2
1. Descargar Descargar modelos de pesos y tokenizadores
T1 Descarga desde el sitio web oficial
Si descarga pesos de modelo y tokenizadores, debe visitar el sitio web de Meta AI y aceptar la licencia de Meta. Una vez que se apruebe su solicitud, recibirá una URL firmada por correo electrónico. Luego ejecute el script download.sh, pasando la URL proporcionada cuando se le solicite iniciar la descarga. Asegúrese de copiar solo el texto de la URL y no use la opción "Copiar dirección de enlace" cuando haga clic con el botón derecho en la URL. Si el texto de la URL copiada comienza con https://download.llamameta.net ↗, entonces lo copió correctamente. Si el texto de la URL copiada comienza con https://l.facebook.com ↗, lo copió mal.
Asegúrese de que wget y md5sum estén instalados. Luego ejecute el script:
./download.shT2, descarga basada en Hugging Face
También ofrecemos descargas en Hugging Face. Primero debe solicitar la descarga desde el sitio web de Meta AI usando la misma dirección de correo electrónico que su cuenta de Hugging Face. Después de hacerlo, puede solicitar acceso a cualquier modelo en Hugging Face y dentro de 1-2 días su cuenta tendrá acceso a todas las versiones.
2. Instalación
En un entorno conda con PyTorch/CUDA, clone el repositorio y ejecútelo en el directorio de nivel superior
pip install -e Cómo usar LLaMA2
1. Uso básico
(1), modelo de razonamiento
Diferentes modelos requieren diferentes valores de paralelismo de modelo (MP)
| Modelo | parlamentario |
|---|---|
| 7b | 1 |
| 13b | 2 |
| 70b | 8 |
Todos los modelos admiten longitudes de secuencia de hasta 4096 tokens , pero asignamos previamente los búfer en función de los valores max_seq_len y max_batch_size. Así que configura estos valores de acuerdo a tu hardware.
(2), modelo de pre-entrenamiento
Estos modelos no fueron ajustados para el chat o la respuesta a preguntas. Se les debe pedir que la respuesta esperada sea una continuación natural de la pista.
Consulte example_text_completion.py para ver algunos ejemplos. Para ilustrar esto, vea el siguiente comando para ejecutarlo con el modelo llama-2-7b (nproc_per_node debe establecerse en el valor MP):
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4(3), afinando el modelo de chat
Estos modelos ajustados están entrenados para aplicaciones conversacionales. Para las funciones y el rendimiento esperados, se debe seguir un formato específico definido en chat_completion, incluidas las etiquetas INST y <<SYS>>, etiquetas BOS y EOS, y espacios y líneas nuevas entre ellas (recomendamos llamar a strip() en la entrada para evitar espacios dobles).
También puede implementar clasificadores adicionales para filtrar las entradas y salidas que se consideran inseguras. Consulte el repositorio llama-recipes para ver ejemplos de cómo agregar verificadores de seguridad a la entrada y salida de su código de inferencia.
Ejemplo usando llama-2-7b-chat:
torchrun --nproc_per_node 1 example_chat_completion.py
--ckpt_dir llama-2-7b-chat/
--tokenizer_path tokenizer.model
--max_seq_len 512 --max_batch_size 4Llama 2 es una nueva tecnología y su uso es potencialmente riesgoso . Las pruebas realizadas hasta ahora no cubren todas las situaciones . Para ayudar a los desarrolladores a abordar estos riesgos, hemos creado Pautas de uso responsable. Se pueden encontrar más detalles en nuestro trabajo de investigación.