Red AlexNet (propuesta en 2012)
1. Explicación detallada de la red AlexNet
- La red AlexNet es la red campeona (campeona de la competencia de clasificación) en la competencia (desafío de reconocimiento visual a gran escala) ILSVRC (ImageNet Large Scale Visual Recognition Challenge) de 2012. La tasa de precisión de clasificación se ha incrementado del tradicional 70%+ al 80%. +.
Fuente:
- Autor: Diseñado por Hinton y su alumno Alex Krizhevsky. También después de 2012, el aprendizaje profundo comenzó a desarrollarse rápidamente. La red neuronal convolucional se ha convertido en el modelo de algoritmo central en el campo de la clasificación de imágenes.
- Artículo original: Clasificación de ImageNet con redes neuronales convolucionales profundas
Oportunidades de desarrollo (beneficios de):
- Estructura de red más profunda que LeNet
- Excelente rendimiento en la supresión de problemas de sobreajuste
- El rápido desarrollo del hardware informático.
Contribuciones :
- En comparación con LeNet, la estructura de AlexNet es más compleja y las funciones de cada módulo están más cerca de las redes neuronales actuales.
- Función de activación ReLU, aumento de datos, desactivación aleatoria y otros modelos y métodos de construcción de redes de gran alcance propuestos por AlexNet
- Y a través del aprendizaje de múltiples GPU, los modelos de redes neuronales ultragrandes se hacen realidad.
Estado :
- La red AlexNet permite a las personas ver la posibilidad de utilizar el aprendizaje profundo en el campo de la visión por computadora, por lo que, hasta cierto punto, crea una era de integración del aprendizaje profundo y la visión por computadora .
- Conduciendo al estallido de la locura por la investigación de redes neuronales profundas
- Ya sea en términos de valor académico o influencia social, AlexNet puede considerarse un logro histórico en la historia del desarrollo de redes neuronales convolucionales.
Conjunto de datos ImageNet: es un conjunto de datos a gran escala con más de 22.000 categorías y 15 millones de imágenes.
Conjunto de datos ILSVRC: utiliza alrededor de 1000 tipos diferentes de objetos y más de 1 millón de imágenes de alta definición.
(Un conjunto de datos utilizado para la clasificación de imágenes, un subconjunto del conjunto de datos ImageNet)
- Conjunto de entrenamiento: 1.281.167 imágenes etiquetadas, divididas en 1.000 categorías
- Conjunto de validación: 50.000 imágenes etiquetadas
- Conjunto de prueba: 100.000 imágenes sin etiquetar
- Los aspectos más destacados de esta red son:
-
Por primera vez, se utiliza GPU para el entrenamiento de aceleración de red (la GPU es entre 20 y 50 veces más rápida que la CPU)
AlexNet utiliza múltiples GPU para entrenar redes neuronales convolucionales, lo que mejora enormemente la eficiencia y permite implementar redes más grandes y profundas.
Actualmente, el uso de múltiples GPU o incluso grupos de GPU para el entrenamiento se ha convertido en la forma básica de implementar redes neuronales a gran escala.
-
La función de activación ReLU se utiliza en lugar de la función de activación Sigmoide tradicional y la función de activación Tanh.
(Desde entonces, la función ReLU y sus variantes se han convertido en el estándar universal para las funciones de activación de redes neuronales convolucionales )
Desventajas de la función de activación sigmoidea:
- Es más problemático cuando pides orientación.
- Cuando la red es relativamente profunda, el gradiente desaparecerá.
ReLU solucionará estas dos deficiencias
-
Ventajas de la función de activación ReLU:
-
Más simple . Sin operación de exponenciación en la función de activación sigmoidea
-
Haga que el modelo sea más fácil de entrenar con diferentes métodos de inicialización de parámetros (esto se debe a que cuando la salida de la función de activación sigmoidea está muy cerca de 0 o 1, el gradiente en estas áreas es casi 0, lo que hace que la retropropagación no pueda continuar actualizando algunos parámetros del modelo). )
-
El gradiente de la función de activación ReLU en el intervalo positivo es siempre 1
(Por lo tanto, si los parámetros del modelo no se inicializan correctamente, la función sigmoidea puede obtener un gradiente de casi 0 en el intervalo positivo, lo que hace que el modelo no se pueda entrenar de manera efectiva)
-
-
Se utiliza la normalización de respuesta local LRN
Cada capa convolucional contiene la función de excitación ReLU y el procesamiento de normalización de respuesta local (LRN) , y luego es procesada por la capa de agrupación y, finalmente, el resultado de la clasificación se genera a través de la capa completamente conectada. )
El papel de LRN : Se utiliza para normalizar la salida de la capa convolucional, promover la convergencia de la red y mejorar las capacidades de generalización.
Nota: En investigaciones posteriores, la gente descubrió gradualmente que el efecto de la capa de normalización local correspondiente no es muy bueno , por lo que básicamente ya no se usa.
-
desactivación aleatoria
La deserción se utiliza para desactivar aleatoriamente las neuronas en las dos primeras capas de la capa completamente conectada para reducir el sobreajuste .
Motivo : dado que AlexNet es una red neuronal con una gran cantidad de parámetros (60 millones de parámetros), sin una regularización adecuada, la red puede caer fácilmente en un sobreajuste grave .
Solución : la desactivación aleatoria es un método para evitar la coadaptación del mapa de características (coadatpion), es decir, en cada ciclo de entrenamiento , una cierta proporción de neuronas se selecciona aleatoriamente y sus salidas se fuerzan a 0 , de modo que estas neuronas ya no participen en propagación hacia adelante y hacia atrás.
- Dado que las neuronas se activan o desactivan aleatoriamente, estas neuronas ya no se adaptan de forma cooperativa ni aprenden funciones independientemente de otras neuronas.
- En cierto sentido, cada ciclo de formación es una estructura de red completamente nueva , lo que mejora enormemente la adaptabilidad de la red .
- Además, dado que cualquier neurona puede desactivarse, la red tiende a no depender de ninguna parte de las neuronas , lo que lleva al aprendizaje de características más robustas y universales , que pueden mejorar el rendimiento de generalización de la red .
Sobreajuste: la causa fundamental es que hay demasiadas dimensiones de características, suposiciones de modelo demasiado complejas, demasiados parámetros, muy pocos datos de entrenamiento y demasiado ruido, lo que da como resultado que la función ajustada prediga perfectamente el conjunto de entrenamiento, pero no prediga la prueba . conjunto de datos nuevos.Pobre . Sobreajustar los datos de entrenamiento sin tener en cuenta la generalización .
如图1(AlexNet ha trabajado mucho para resolver el problema de sobreajuste, por lo que tiene un rendimiento excelente en conjuntos de datos a gran escala )
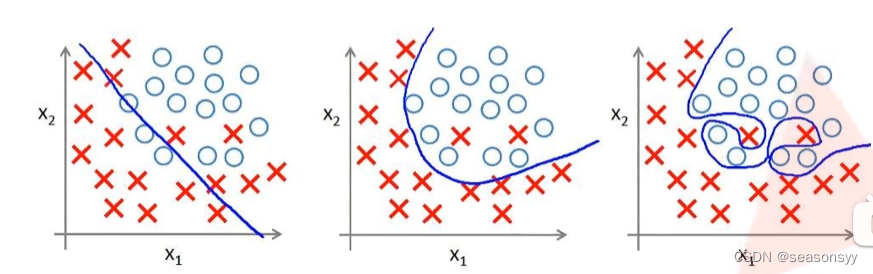
Resuelva el fenómeno de sobreajuste:
Utilice Dropout para desactivar aleatoriamente algunas neuronas durante la propagación hacia adelante de la red .
如图2
>
Figura 2Izquierda: proceso normal de propagación directa completamente conectado, cada nodo está completamente conectado con el nodo superior
Derecha: Después de usar Dropout, una parte de las neuronas se desactivan aleatoriamente en cada capa.
Se puede entender que la operación Dropout reduce los parámetros del entrenamiento de la red de forma encubierta, logrando así el efecto de reducir el fenómeno de sobreajuste de la red.
- Operación de agrupación superpuesta
A diferencia de la capa de agrupación de LeNet, se utiliza una operación de agrupación superpuesta sin parámetros que se puedan aprender .
El tamaño del paso de la operación de agrupación ordinaria es consistente con el tamaño del kernel, por lo que las áreas calculadas en dos pasos cualesquiera no se superponen.
La operación de agrupación superpuesta significa que habrá partes superpuestas en el proceso de agrupación, es decir, el tamaño del paso de agrupación es menor que el tamaño del núcleo de agrupación .
El uso de este enfoque en AlexNet reduce la tasa de error
- Aumento de datos
AlexNet introduce una gran cantidad de aumentos de imágenes , como voltear, recortar y cambiar de color, expandiendo así aún más el conjunto de datos para aliviar el sobreajuste ).
Definición : Se refiere a un método para obtener nuevas muestras y aumentar la capacidad del conjunto de datos mediante el procesamiento de datos existentes.
Función : el aumento de datos puede enriquecer la diversidad de muestras y mejorar la solidez de la red ante los cambios anteriores mediante métodos como recortar, desplazar, escalar, voltear y ajustar el color y el brillo.
Operación :
- AlexNet recorta una imagen de 256 × 256 píxeles en varias imágenes de 224 × 224 píxeles, con posiciones de recorte aleatorias .
- Voltea la imagen horizontalmente para producir una nueva imagen. Al recortar aleatoriamente y voltear horizontalmente, la cantidad de muestras de entrenamiento aumenta considerablemente .
- Al cambiar los valores de los píxeles en los tres canales RGB de la muestra para generar nuevas muestras, el conjunto de datos de entrenamiento aumenta aún más y se mejora la robustez del modelo ante los cambios de color y brillo.
Resultados : Los experimentos muestran que esto ayuda a resolver el problema del sobreajuste. Actualmente, el aumento de datos se ha convertido en un paso estándar en el proceso de aplicación de redes neuronales convolucionales .
2. Estructura de la red AlexNet
如图3Como se muestra en el diagrama de estructura de red.
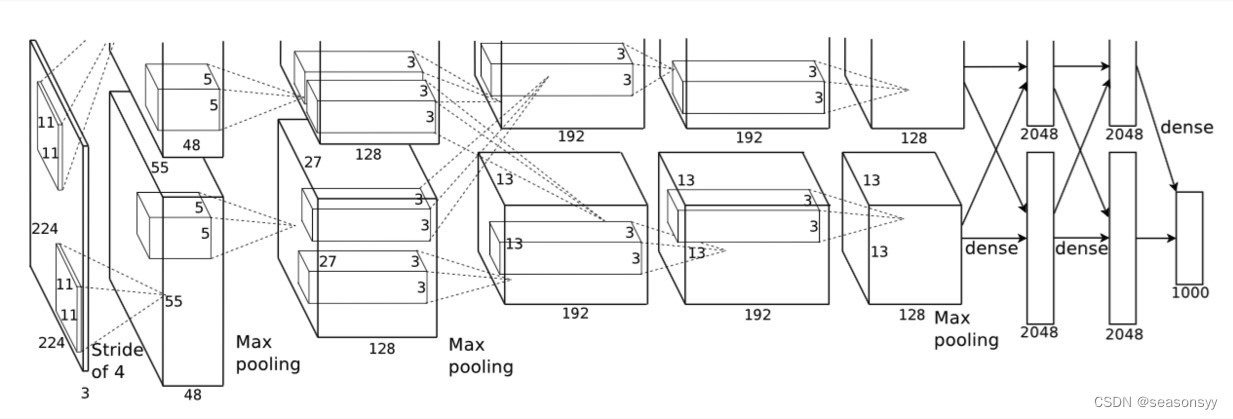
imagen 3
AlexNet contiene 8 capas de transformación, incluidas 5 capas convolucionales, 3 capas completamente conectadas (2 capas ocultas completamente conectadas, 1 capa de salida completamente conectada), con un total de aproximadamente 60 millones de parámetros.
Cada capa convolucional contiene la función de excitación ReLU y el procesamiento de normalización de respuesta local (LRN) , y luego es procesada por la capa de agrupación y, finalmente, el resultado de la clasificación se genera a través de la capa completamente conectada. )
El papel de LRN : Se utiliza para normalizar la salida de la capa convolucional, promover la convergencia de la red y mejorar las capacidades de generalización.
Nota: En investigaciones posteriores, la gente descubrió gradualmente que el efecto de la capa de normalización local correspondiente no es muy bueno , por lo que básicamente ya no se usa.
Debido a las limitaciones de la memoria gráfica inicial, la primera AlexNet utilizó un diseño de flujo de datos dual, de modo que una GPU solo necesitaba procesar la mitad del modelo.
Afortunadamente, los gráficos han avanzado mucho en los últimos años y ahora generalmente no requieren un diseño tan especial.
Esta red puede verse como dos partes porque el autor utilizó dos GPU para operaciones paralelas.
Sólo necesitamos fijarnos en una pieza porque la parte superior e inferior son iguales.
Entrada : Como se puede ver en la Figura 3, el tamaño de la capa de entrada es 224 × 224 × 3, pero sería más razonable establecer el tamaño en 227 × 227 × 3. Por lo tanto, 227×227×3 prevalecerá más adelante.
Nota: La estructura de red que se muestra en la Figura 3 en realidad se basa en la estructura de dos GPU, por lo que todos los parámetros están separados por la mitad; mientras que la siguiente tabla muestra la estructura de red como un todo.
| nombre_capa | aporte | tamaño_del_núcleo | paso | relleno | producción | Cantidad de parámetros |
|---|---|---|---|---|---|---|
| Aporte | 227×227×3 | 227×227×3 | ||||
| Conv1 | 227×227×3 | 11×11×96 | 4 | 0 | (227-11+0)/4+1=55 55×55×96 | (11×11 ×3+1) ×96 |
| MaxPooling1 | 55×55×96 | 3×3 | 2 | 0 | (55-3+0)/2+1=27 27×27×96 | |
| Conv2 (Misma convolución) | 27×27×96 | 5×5×256 | 1 | 2 | (27-5+2×2)/1+1=27 27×27×256 | (5×5×96+1)×256 |
| MaxPooling2 | 27×27×256 | 3×3 | 2 | 0 | (27-3+0)/2+1=13 13×13×256 | |
| Conv3 (Misma convolución) | 13×13×256 | 3×3×384 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×384 | (13×13×256+1)×384 |
| Conv4 (Misma convolución) | 13×13×384 | 3×3×384 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×384 | (13×13×384+1)×384 |
| Conv5 | 13×13×384 | 3×3×256 | 1 | 1 | (13-3+2×1)/1+1=13 13×13×256 | (3×3×384+1)×256 |
| MaxPooling3 | 13×13×256 | 3×3 | 2 | 0 | (13-3+0)/2+1=6 6×6×256 | |
| FC6 | 6×6×256=9216 | 4096 | 6×6×256×4096+1 | |||
| FC7 | 4096 | 4096 | 4096×4096+1 | |||
| FC8(Softmax) | 4096 | 1000 | 4096×1000+1 |
El tamaño de la ventana de la primera capa convolucional de AlexNet es 11 × 11. Debido a que la altura y el ancho de la mayoría de las imágenes en ImageNet son más de 10 veces la altura y el ancho de la imagen MNIST, los objetos en las imágenes de ImageNet ocupan más píxeles, por lo que se necesita una ventana de convolución más grande para capturar los objetos.
La cantidad de canales de convolución utilizados por AlexNet también es decenas de veces mayor que la de LeNet.
AlexNet controla la complejidad del modelo de la capa completamente conectada mediante el método de abandono, mientras que LeNet no utiliza el método de abandono.
Misma convolución : Realice la misma convolución. Lo mismo es una convolución en la que el tamaño del mapa de características permanece sin cambios después del procesamiento (el número de canales puede cambiar)
Misma convolución:
En esencia, sigue siendo una convolución ordinaria, y la fórmula de cálculo sigue siendo
salida = [(entrada − tamaño del filtro + 2 ∗ relleno) / paso] + 1 salida=[(tamaño del filtro de entrada+2*padding)/ paso] +1fuera u t _ _=[ ( en entrada _−Tamaño del filtro _ _ _ _+2∗relleno ) / paso ] _ _ _ _ _ _ _ _ _+1
Beneficio: el tamaño de la imagen no se reduce después de la convolución y no se pierde ninguna información de la imagen original durante la convolución, por lo que elmapa de características extraído será más completo.Inspiración: al construir una red neuronal convolucional de su propia red, adoptar el mismo método de convolución en el momento adecuado puede brindar un buen rendimiento y el código es muy simple: solo necesita configurar la respuesta de acuerdo con los requisitos de los parámetros de Misma convolución. .
# 利用nn包构建采用Same卷积的卷积层 self.conv1=nn.Sequential( nn.Conv2d ( in_channels=1, out_channels=6, kernel_size=3, stride=1, # 步长一定要设置为1 padding=1 # padding设置成1就实现了加边界 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2) )La capa de salida utiliza un clasificador softmax y finalmente genera las posibles probabilidades de cada una de las 1000 categorías. Debido a las ventajas del clasificador Softmax y las buenas características de la red, el modelo AlexNet entrenado no solo puede distinguir si el contenido de la imagen es un gato, sino que incluso puede distinguir la raza del gato .
(Las últimas 1000 categorías se generan en AlexNet, incluso si el tamaño de cada salida es diferente, después de pasar por el clasificador Softmax, el rango de salida vuelve a 0 ~ 1 , lo cual también es uno de los beneficios de usar Softmax)Softmax es una extensión de la clasificación binaria Sigmoide, solo necesita dos pasos para procesar los datos:
- Primero use la función exponencial para asignar los resultados de la clasificación múltiple de cero a infinito positivo
- Luego tome el método de normalización para obtener la probabilidad correspondiente del mapeo de resultados.
Suponiendo que la salida debe clasificarse en n tipos ahora, la salida obtendrá n probabilidades después de pasar por el clasificador Softmax, de la siguiente manera:
La fórmula anterior refleja la esencia del clasificador Softmax :
- El primer paso en el procesamiento de representaciones moleculares: usar la función exponencial para mapear los resultados de la clasificación múltiple desde cero hasta infinito positivo
- Denominador: representa sumar todos los resultados y normalizar el numerador
Ejemplo : supongamos que la red necesita generar un resultado de tres categorías. Durante un proceso de entrenamiento, la red genera un vector de fila como [12 26 -9]. El proceso de cálculo del clasificador Softmax es el siguiente:
P2 es el más cercano a 1, lo que significa que la posibilidad de la segunda clasificación es extremadamente alta, que está cerca del 100%, por lo que pensamos que el resultado de clasificación generado por la red es la segunda clasificación.
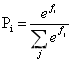

3. Código AlexNet
referencia:
Blogger de la estación B @霹雳巴拉Wz : https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62
github : https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
Ejemplo :\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\pytorch_classification\Test2_alexnet
Descripción: Esta parte es para ejecutar el código AlexNet
El conjunto de datos requerido para esta capacitación: conjunto de datos de clasificación de flores
Este conjunto de datos tiene un total de 5 categorías:
- margarita margarita
- diente de león diente de león
- rosasrosas:
- girasol girasol
- tulipanestulipanes
Los pasos para descargar el conjunto de datos de clasificación de flores son los siguientes:
- (1) Cree una nueva carpeta "flower_data" en la carpeta data_set
- (2) Haga clic en el enlace para descargar el conjunto de datos de clasificación de flores https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
- (3) Descomprima el conjunto de datos en la carpeta flower_data
- (4) Ejecute el script "split_data.py" para dividir automáticamente el conjunto de datos en un tren de conjunto de entrenamiento y un valor de conjunto de validación.
├── flower_data
├── flower_photos(解压的数据集文件夹,3670个样本)
├── train(生成的训练集,3306个样本) 9 :
└── val(生成的验证集,364个样本) 1
Ingrese el comando powershell en el directorio deep-learning-for-image-processing-master\data_set (mantenga presionada la tecla Mayús y haga clic derecho en este directorio para ingresar la opción)
Luego ingrese "python split_data.py" y haga clic en Entrar, este script se ejecutará y el conjunto de entrenamiento se dividirá en un conjunto de entrenamiento y un conjunto de verificación de acuerdo con 9:1.
如图4
Figura 4

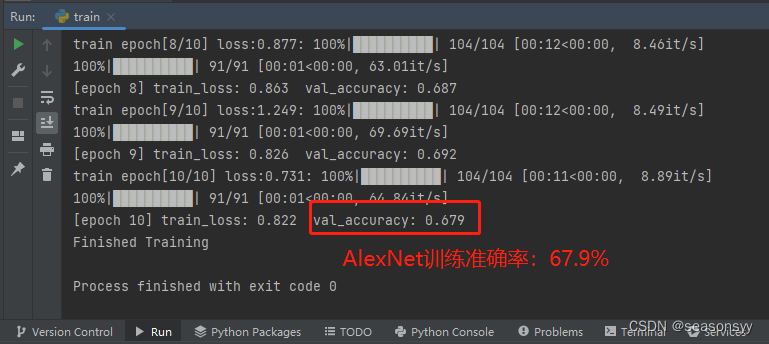
Resultados de carrera :
Después de ejecutar train.py, el mejor resultado se guardará como Alex.pyh
Verificación: coloque una imagen en esta carpeta y luego preste atención a la ruta de la imagen.
Luego ejecute el archivo predict.py
Precisión del entrenamiento AlexNet: 67,9%
error de ejecución :
OMP: Error n.º 15: Inicializando libiomp5md.dll, pero encontré que libiomp5md.dll ya estaba inicializado.
OMP: Sugerencia Esto significa que se han vinculado varias copias del tiempo de ejecución de OpenMP al programa. Esto es peligroso, ya que puede degradar el rendimiento o provocar resultados incorrectos. Lo mejor que puede hacer es asegurarse de que sólo un tiempo de ejecución de OpenMP esté vinculado al proceso, por ejemplo, evitando la vinculación estática del tiempo de ejecución de OpenMP en cualquier biblioteca. Como solución alternativa insegura, no compatible y no documentada, puede configurar la variable de entorno KMP_DUPLICATE_LIB_OK=TRUE para permitir que el programa continúe ejecutándose, pero eso puede causar fallas o producir resultados incorrectos de manera silenciosa. Para obtener más información, consulte http://www.intel.com/software/products/support/.
ReferenciaChatGPT
Motivo del error :
Este error se produce porque varias bibliotecas de tiempo de ejecución de OpenMP están vinculadas en el programa , lo que puede reducir el rendimiento o generar resultados incorrectos.
Solución :
La mejor solución es asegurarse de que solo una biblioteca de tiempo de ejecución de OpenMP esté vinculada al proceso , verificar las opciones de compilación y vincular la configuración de la biblioteca para asegurarse de que no haya bibliotecas OpenMP duplicadas vinculadas. Por ejemplo, evite vincular estáticamente el tiempo de ejecución de OpenMP en cualquier biblioteca. Como solución alternativa insegura, no compatible y no documentada, puede configurar la variable de entorno KMP_DUPLICATE_LIB_OK=TRUE para permitir que el programa continúe con la ejecución, pero esto puede causar un bloqueo o producir resultados incorrectos. Consulte http://www.intel.com/software/products/support/ para obtener más información.
Pasos de la solución :
-
Si está utilizando el compilador de Visual Studio, puede configurar "Compatibilidad con Open MP" en "Sí" en "C/C++" -> "Generación de código" en las propiedades del proyecto.
-
Si está utilizando otro compilador, consulte la documentación de ese compilador para encontrar opciones de configuración para OpenMP y asegúrese de vincular solo una biblioteca de tiempo de ejecución de OpenMP.
-
Si los pasos anteriores no resuelven el problema, puede intentar configurar la variable de entorno KMP_DUPLICATE_LIB_OK=TRUE. Tenga en cuenta que esta es una solución alternativa y puede causar otros problemas.
Estoy usando el compilador pycharm.
En el compilador PyCharm, puede intentar los siguientes pasos para resolver este problema:
-
Abra PyCharm y acceda a su proyecto.
-
Seleccione "Ejecutar" -> "Editar configuraciones" en la barra de menú superior.
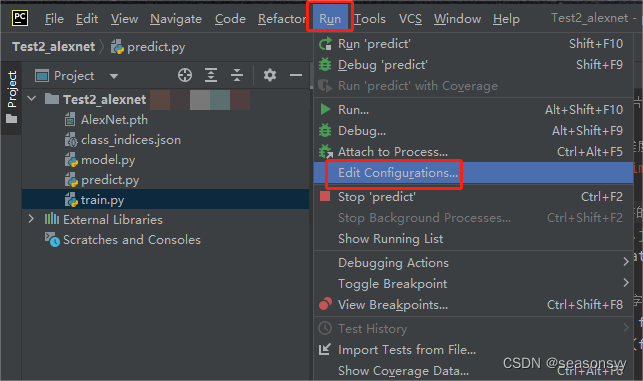
Figura 5
-
En el cuadro de diálogo que aparece, busque el perfil que desea ejecutar y selecciónelo.
-
En la sección "Variables de entorno" en el panel derecho, agregue una nueva variable de entorno.
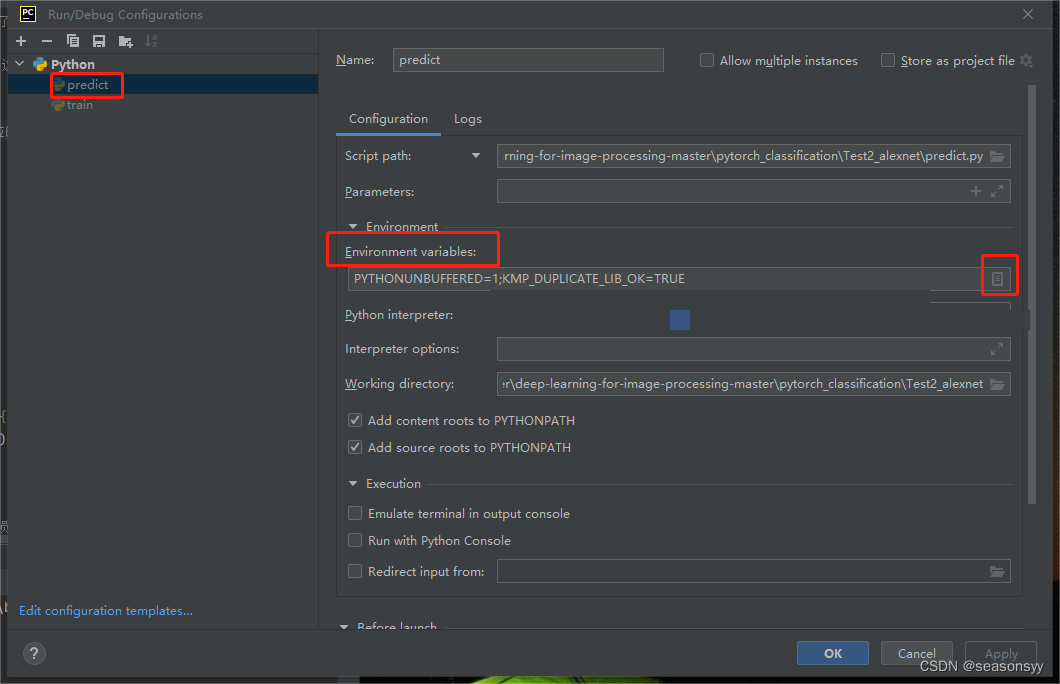
Figura 6
- Establezca el nombre de la variable en
KMP_DUPLICATE_LIB_OKy establezca el valor de la variable enTRUE.
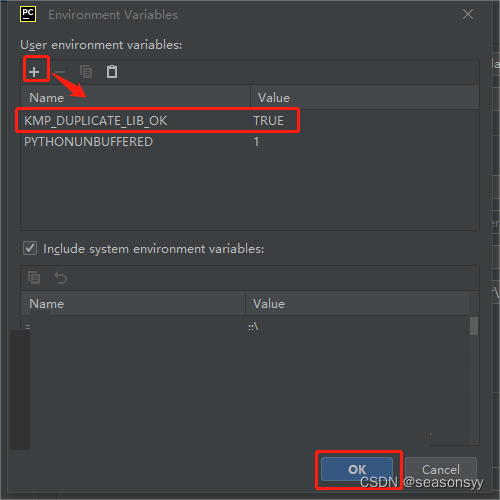
Figura 7
-
Haga clic en "Aceptar" para guardar los cambios.
-
Ahora intenta ejecutar tu programa nuevamente y comprueba si sigues apareciendo el mismo error. Establecer esta variable de entorno en "VERDADERO" puede permitir que continúe la ejecución del programa, pero tenga en cuenta que esto puede provocar un bloqueo o producir resultados erróneos.
Si el problema aún no se puede resolver mediante los pasos anteriores, consulte la documentación de PyCharm o comuníquese con el equipo de soporte de PyCharm para obtener ayuda y orientación más precisa.
Resultado de la solución : éxito
Los resultados de la predicción se muestran en la figura: ( 图8-图9)
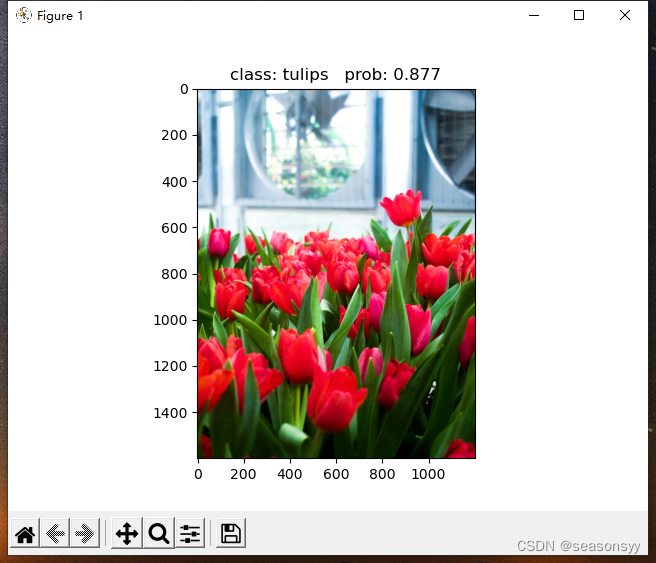
Figura 8
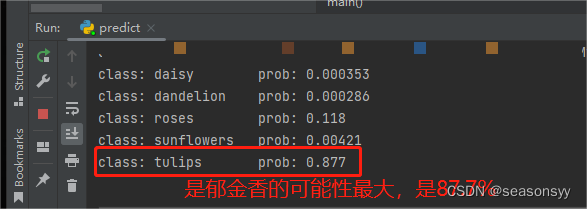
Figura 9
4. Cómo utilizar la red AlexNet para entrenar su propio conjunto de datos
referencia:
Blogger de la estación B @霹雳巴拉Wz: https://www.bilibili.com/video/BV1W7411T7qc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62
github:https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
El código AlexNet que acabamos de ejecutar utiliza el conjunto de datos de flores. Podemos eliminar las cinco categorías en la carpeta flower_photos en la siguiente dirección, luego reemplazarlas con nuestro propio conjunto de datos, llamar a la página split.py y seguir 9: La proporción de 1 se divide en conjunto de entrenamiento y conjunto de prueba, y luego usa train.py para el entrenamiento.
conjunto de datos de flores:
aprendizaje profundo para el procesamiento de imágenes maestro\aprendizaje profundo para el procesamiento de imágenes maestro\data_set\flower_data\flower_photos
Qué es necesario modificar:
en tren.py:图10

Figura 10
predecir.py:图11

Figura 11
5. Referencias
- "Aprendizaje profundo y redes neuronales" editado por Zhao Muguang
Editorial: Electronic Industry Press, primera edición en enero de 2023
ISBN: 978-7-121-44429-6
- "Principios y práctica de redes neuronales convolucionales profundas" editado por Zhou Pucheng, Li Congli, Wang Yong y Wei Zhe
Editorial: Beijing: Electronic Industry Press, 2020.10
ISBN: 978-7-121-39663-2
- "Introducción y práctica de la red neuronal Python" editado por Wang Kai
Editorial: Prensa de la Universidad de Pekín
ISBN: 9787301316290
- Blogger de la estación B @霹雳巴拉Wz: https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=647760d93691c99109dee33aad004b62