Заметки по изучению Python за пятьдесят седьмой день
Очистка данных Pandas
Очистка данных — это процесс обработки бесполезных данных.
Многие наборы данных содержат недостающие данные, неправильные форматы данных, неверные данные или повторяющиеся данные. Если вы хотите сделать анализ данных более точным, вам необходимо обработать эти бесполезные данные.
В этом уроке мы будем использовать пакет Pandas для очистки данных.
Тестовые данные property-data.csv, используемые в этой статье, выглядят следующим образом:
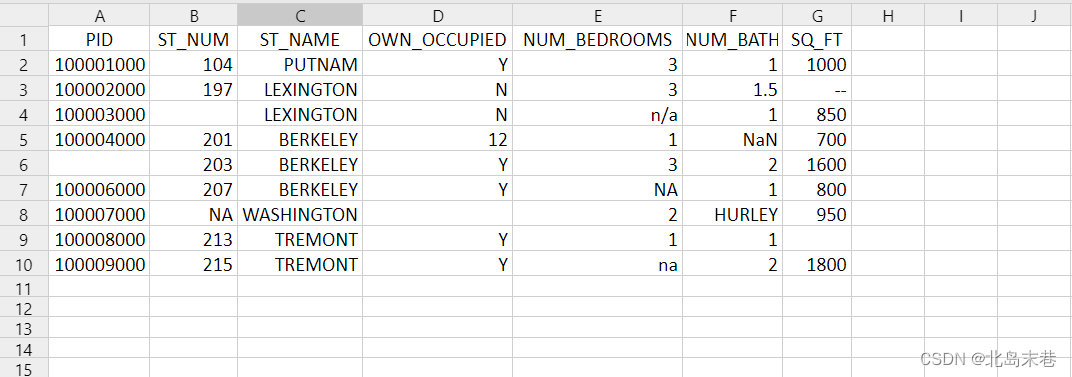
В приведенной выше таблице содержатся четыре типа пустых данных:
- н/д
- ЧТО
- —
- уже
Pandas очищает нулевые значения
Если мы хотим удалить строки, содержащие пустые поля, мы можем использовать метод dropna() со следующим синтаксисом:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
Описание параметра:
- Ось: значение по умолчанию – 0, что означает, что вся строка будет удалена, если значение пусто. Если установлен параметр axis=1, весь столбец будет удален, если значение пусто.
- как: по умолчанию установлено значение «любой». Если какие-либо данные в строке (или столбце) содержат NA, вся строка будет удалена. Если установлено значение How='all, вся строка (или столбец) будет удалена только в том случае, если Появляется NA.
- thresh: установите, сколько данных, отличных от NULL, необходимо сохранить.
- подмножество: укажите столбцы, которые вы хотите проверить. Если столбцов несколько, в качестве параметров можно использовать список имен столбцов.
- inplace: если установлено значение True, вычисленное значение напрямую перезапишет предыдущее значение и будет возвращено значение None.Исходные данные будут изменены.
нулевой()
Мы можем использовать isnull(), чтобы определить, пуста ли каждая ячейка.
# 实例 1
import pandas as pd
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
В приведенном выше примере Pandas рассматривает n/a и NA как пустые данные. na не является пустыми данными и не соответствует нашим требованиям. Мы можем указать пустой тип данных:
# 实例 2
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
Файл CSV с именем "property-data.csv" был прочитан с помощью функции pd.read_csv и сохранен в переменной df. Строка df.dropna() была удалена из исходного DataFrame (в переменной df). Если нет строк, содержащих найдены нулевые данные, преобразуйте новый DataFrame без строк нулевых данных в строки и распечатайте их.
# 实例 3
import pandas as pd
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())
Примечание. По умолчанию метод dropna() возвращает новый DataFrame и не изменяет исходные данные.
Если в вашем файле «property-data.csv» есть некоторые строки, которые содержат пустые данные (например, один или несколько столбцов имеют нулевые значения), то эти строки будут удалены, а новый DataFrame (new_df) не будет содержать этих ОК. .
Следует отметить, что dropna() по умолчанию удалит строки, содержащие хотя бы одно значение NaN. Если вы хотите отбросить все значения NaN и сохранить только строки без пропущенных значений, вы можете использовать dropna(how='all').
Кроме того, вы можете указать, следует ли удалять строки или столбцы, задав параметр оси. Например, df.dropna(axis=1) удалит столбцы, содержащие нулевые данные.
Если вы хотите изменить исходные данные DataFrame, вы можете использовать параметр inplace = True.
# 实例 4
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())
Вы также можете удалить строки с нулевыми значениями в указанных столбцах.
# 实例 5
import pandas as pd
df = pd.read_csv('property-data.csv')
# 移除 ST_NUM 列中字段值为空的行
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
Вы также можете использовать метод fillna() для замены некоторых пустых полей.
# 实例 6
import pandas as pd
df = pd.read_csv('property-data.csv')
# 使用 12345 替换空字段
df.fillna(12345, inplace = True)
print(df.to_string())
Вы также можете указать столбец для замены данных:
# 实例 7
import pandas as pd
df = pd.read_csv('property-data.csv')
# 使用 12345 替换 PID 为空数据:
df['PID'].fillna(12345, inplace = True)
print(df.to_string())
Панды заменяют клетки
Распространенный способ замены пустых ячеек — вычисление среднего значения, медианы или моды столбца.
Pandas использует методыmean(), median() и mode() для вычисления среднего значения (среднего значения всех значений), медианы (числа в середине после сортировки) и режима (числа с самой высокой частотой) столбец. .
иметь в виду()
Используйте методmean(), чтобы вычислить среднее значение столбца и заменить пустые ячейки.
# 实例 8
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
медиана()
Используйте метод median() для вычисления медианы столбца и замены пустых ячеек.
# 实例 9
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].median()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
режим()
Используйте метод mode(), чтобы вычислить режим столбца и заменить пустые ячейки.
# 实例 10
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mode()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
Pandas очищает искаженные данные
Ячейки с искаженными данными могут затруднить анализ данных, если не сделать его невозможным.
Мы можем передавать строки, содержащие пустые ячейки, или конвертировать все ячейки в столбце в один и тот же формат данных.
В следующем примере форматируется дата:
# 实例 11
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
Pandas очищает ошибочные данные
Ошибки данных также распространены, и мы можем заменить или удалить ошибочные данные.
В следующем примере данные заменяются неправильным возрастом:
# 实例 12
import pandas as pd
person = {
"name": ['Google', 'Baidu' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
Вы также можете установить условный оператор, чтобы установить возраст от 120 до 120.
# 实例 13
import pandas as pd
person = {
"name": ['Google', 'Baidu' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())
Вы также можете удалить строки с неверными данными и строки с возрастом больше 120.
# 实例 14
import pandas as pd
person = {
"name": ['Google', 'Baidu' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())
Pandas очищает повторяющиеся данные
Если мы хотим очистить повторяющиеся данные, мы можем использовать методы Duplied() и drop_duplications().
дублировано()
Если соответствующие данные дублируются, функция Duplied() вернет True, в противном случае — False.
# 实例 15
import pandas as pd
person = {
"name": ['Google', 'Baidu', 'Baidu', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
drop_duplications()
Чтобы удалить повторяющиеся данные, вы можете напрямую использовать метод drop_duplications().
# 实例 16
import pandas as pd
persons = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(persons)
df.drop_duplicates(inplace = True)
print(df)
постскриптум
Сегодня вы изучаете очистку данных Python Pandas. Вы изучили это? Краткое содержание сегодняшнего учебного материала:
- Очистка данных Pandas
- Pandas очищает нулевые значения
- Панды заменяют клетки
- Pandas очищает искаженные данные
- Pandas очищает ошибочные данные
- Pandas очищает повторяющиеся данные