Trazar una matriz con python-pandas
Nota: Este artículo es un artículo traducido de
Visualice datos de aprendizaje automático en Python con Pandas-Machine Learning Mastery , el título original es Visualizar datos de aprendizaje automático en Python con Pandas (el uso de pandas en Python para analizar visualmente los datos de aprendizaje automático), el autor significa que estamos utilizando algoritmos de aprendizaje automático para Al analizar los datos, primero debemos entender los datos, y la forma más rápida de comprender los datos es la visualización. Pero el método utilizado por el autor para la visualización es común a muchos datos, y se utiliza la matriz gráfica de varios gráficos, como el histograma, la matriz de gráficos de dispersión, etc. Este artículo presenta cómo usar pandas para hacer varios diagramas de matriz basados en el análisis del autor.
(1) Datos
Los datos son el conjunto de datos de PimaIndians. El código del autor contiene la URL de la fuente de datos, es decir, el conjunto de datos de diabetes de los indios Pima. El número de muestras es 768, y las variables incluyen:
Preg: tiempos de embarazo
Plas: la concentración de glucosa en plasma en la prueba oral de tolerancia a la glucosa es de 2 horas
Pres: presión arterial diastólica (mm Hg)
Piel: espesor de pliegue de tríceps (mm)
prueba: 2 horas de insulina sérica (μU / ml)
masa: índice de masa corporal (kg / (altura (m)) ^ 2)
pedi: función del linaje de la diabetes
edad: edad (años)
clase: variable de clase (0 o 1), estimada como género.
(2) Histogramas (matriz de histogramas)url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] #设置变量名
data = pandas.read_csv(url, names=names) #采用pandas读取csv数据
data.hist()
plt.show()
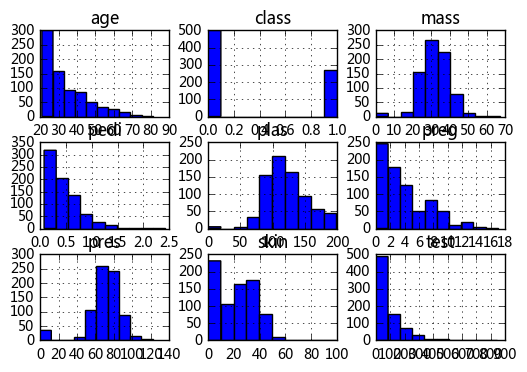
Sin embargo, vemos que los gráficos no están coordinados, y hay casos en que las variables y las coordenadas se superponen. Podemos ajustar los parámetros de hist () para resolver, incluido el ajuste de los tamaños de etiqueta del eje x y del eje y ((xlabelsize, ylabelsize), todo el diseño de los gráficos El ajuste de tamaño figsize:
data.hist(xlabelsize=7,ylabelsize=7,figsize=(8,6)) #
plt.show()
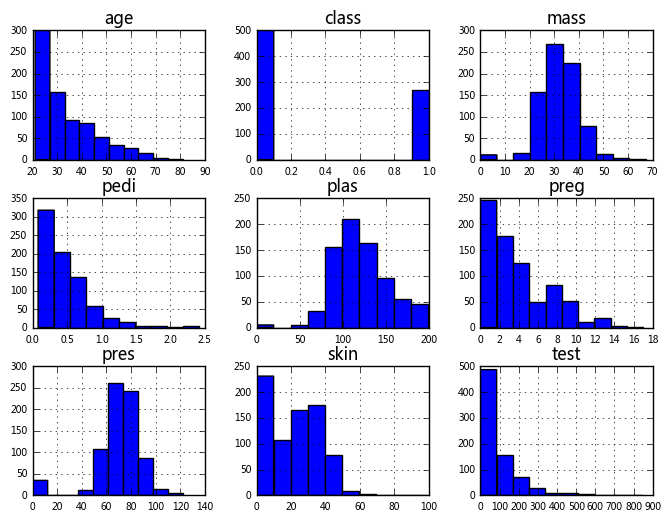
Puede ver la distribución de cada variable. Entre ellas, la masa, el plasma y la presión tienen una distribución normal determinada. Además de la clase, están básicamente sesgadas a la izquierda.
(3) Gráficos de densidad (matriz de gráficos de densidad)
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False,fontsize=8,figsize=(8,6))
plt.show()
Después de que se emite el código original, todavía hay cierta superposición, aquí se agrega el tamaño de fuente del texto de coordenadas en la figura y el tamaño de diseño general.

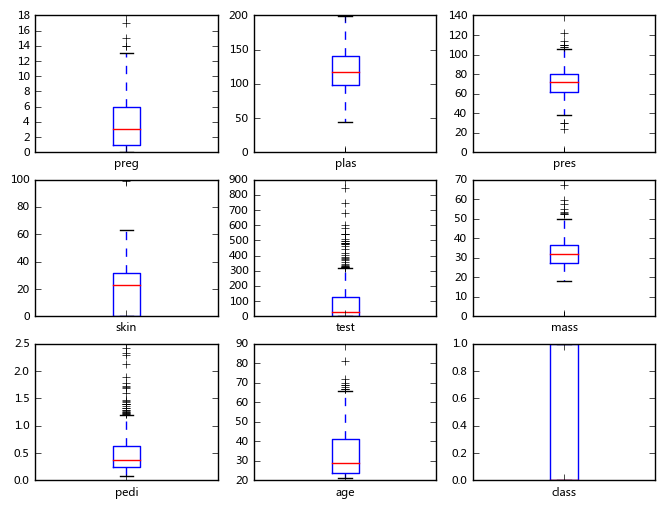
(4) Parcelas de caja y bigotes
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False, sharey=False, fontsize=8,figsize=(8,6))
plt.show()
Similar a (3), observe aquí que el eje xy el eje y se pueden compartir, utilizando los comandos sharex = False, sharey = False.
(5) Gráfico de matriz de correlación
import numpy
correlations = data.corr() #计算变量之间的相关系数矩阵
# plot correlation matrix
fig = plt.figure() #调用figure创建一个绘图对象
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1) #绘制热力图,从-1到1
fig.colorbar(cax) #将matshow生成热力图设置为颜色渐变条
ticks = numpy.arange(0,9,1) #生成0-9,步长为1
ax.set_xticks(ticks) #生成刻度
ax.set_yticks(ticks)
ax.set_xticklabels(names) #生成x轴标签
ax.set_yticklabels(names)
plt.show()
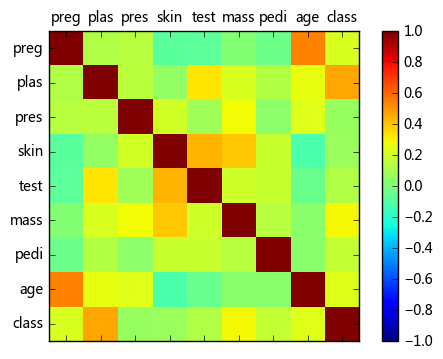 Cuanto más oscuro es el color, más fuerte es la correlación entre los dos.
Cuanto más oscuro es el color, más fuerte es la correlación entre los dos.
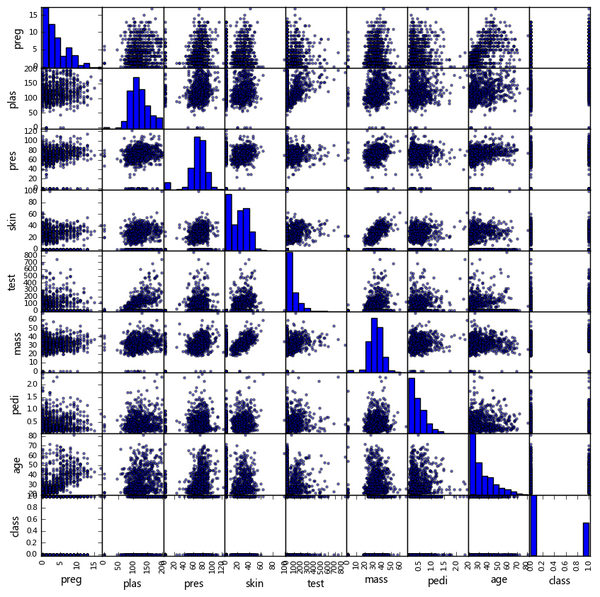
(6) Matriz de diagrama de dispersión
from pandas.tools.plotting import scatter_matrix
scatter_matrix(data,figsize=(10,10))
plt.show()