Directorio de artículos
-
- @[toc]
- 1. Descripción general de etcd
- 2. Instale la herramienta etcdctl
- Tres, implementación del modo de implementación de kubeadm
-
- Cinco, copia de seguridad de implementación binaria
-
- 6. Instalar veloro
-
- 7. Implementar la aplicación de prueba.
-
- Ocho, prueba de copia de seguridad
-
- 8. Recuperación
- 9. Migración de datos del clúster
- 10. Dirección de referencia
Directorio de artículos
-
- @[toc]
- 1. Descripción general de etcd
- 2. Instale la herramienta etcdctl
- Tres, implementación del modo de implementación de kubeadm
- Cinco, copia de seguridad de implementación binaria
- 6. Instalar veloro
- 7. Implementar la aplicación de prueba.
- Ocho, prueba de copia de seguridad
- 8. Recuperación
- 9. Migración de datos del clúster
- 10. Dirección de referencia
1. Descripción general de etcd
etcd es un proyecto de código abierto iniciado por el equipo de CoreOS en junio de 2013. Su objetivo es crear una base de datos clave-valor distribuida de alta disponibilidad.
- etcd adopta internamente el protocoloraft como algoritmo de consenso, y etcd se implementa en base al lenguaje Go.
- Replicación completa: cada nodo del clúster puede utilizar el archivo completo
- Alta disponibilidad: Etcd se puede utilizar para evitar puntos únicos de falla de hardware o problemas de red.
- Consistencia: cada lectura devuelve la escritura más reciente en varios maestros
- Simple: incluye una API bien definida y orientada al usuario (gRPC)
- Seguridad: TLS automatizado implementado con autenticación de certificado de cliente opcional
- Rápido: velocidad de referencia de 10 000 escrituras por segundo
- Confiable: uso del algoritmo Raft para lograr un directorio de almacenamiento de servicios altamente consistente y de alta disponibilidad
Conocimientos básicos relacionados con la operación y mantenimiento del clúster ETCD:
- Puerto de lectura y escritura: 2379, puerto de sincronización de datos: 2380
- El clúster ETCD es un sistema distribuido que utiliza el protocolo Raft para mantener la coherencia del estado de cada nodo del clúster.
- Estado de anfitrión Líder, seguidor, candidato
- Cuando se inicializa el clúster, cada nodo tiene una función de Seguidor, que sincroniza datos con otros nodos mediante latidos.
- Leer datos a través de Follower y escribir datos a través de Leader
- Cuando un seguidor no recibe un latido del nodo maestro dentro de un cierto período de tiempo, cambiará su función a Candidato e iniciará una votación de elección maestra.
- Para configurar un cluster etcd se recomienda tener un número impar de nodos tanto como sea posible en lugar de un número par de nodos, el número recomendado es 3, 5 o 7 nodos para formar un cluster.
- Utilice las herramientas de copia de seguridad/restauración integradas de etcd para realizar copias de seguridad de datos de implementaciones de origen y restaurar datos en nuevas implementaciones. El directorio de datos debe limpiarse antes de la recuperación.
- Ajuste el directorio de datos: almacene datos de instantáneas, instantáneas configuradas por etcd para evitar demasiados archivos WAL y almacene el estado de los datos de etcd.
- En el directorio de datos wal: almacene el registro escrito previamente, la función más importante es registrar el historial completo de todos los cambios de datos. En etcd, todas las modificaciones de datos deben escribirse en WAL antes de enviarse.
- Un clúster etcd probablemente no debería tener más de siete nodos; el rendimiento de escritura se verá afectado; se recomienda ejecutar cinco nodos. Un clúster etcd de 5 miembros puede tolerar fallas de dos miembros y tres miembros pueden tolerar 1 falla.
Parámetros de configuración comunes:
- ETCD_NAME nombre de nodo, el valor predeterminado es predeterminado
- ETCD_DATA_DIR La ruta donde se guardan los datos de ejecución del servicio.
- ETCD_LISTEN_PEER_URLS La dirección de comunicación entre pares a monitorear, como http://ip:2380, si hay más de una, use comas para separarlas. Todos los nodos deben ser accesibles, así que no uses localhost
- ETCD_LISTEN_CLIENT_URLS Dirección de servicio al cliente para monitorear
- ETCD_ADVERTISE_CLIENT_URLS La dirección de escucha del cliente del nodo anunciada externamente, este valor se lo indicará a otros nodos en el clúster.
- ETCD_INITIAL_ADVERTISE_PEER_URLS La dirección de escucha del par del nodo anunciada externamente; este valor se lo indicará a otros nodos en el clúster.
- ETCD_INITIAL_CLUSTER Información de todos los nodos del cluster
- ETCD_INITIAL_CLUSTER_STATE Al crear un nuevo clúster, este valor esnuevo; si se une a un clúster existente, este valoresexistente
- ETCD_INITIAL_CLUSTER_TOKEN El ID del clúster. Cuando hay varios clústeres, el ID de cada clúster debe permanecer único
2. Instale la herramienta etcdctl
【Sitio web oficial】https://github.com/etcd-io/etcd/releases
#查看版本号
cat /etc/kubernetes/manifests/etcd.yaml |grep image
#输入版本号:v3.5.4
$ install_etcdctl.sh
#!/bin/bash
read -p "输入·etcd的版本号": VERSION
ETCD_VER=$VERSION
ETCD_DIR=etcd-download
DOWNLOAD_URL=https://ghproxy.com/github.com/coreos/etcd/releases/download
# 下载
cd /usr/local
mkdir ${ETCD_DIR}
cd ${ETCD_DIR}
rm -rf *
wget ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar -xzvf etcd-${ETCD_VER}-linux-amd64.tar.gz
# 安装etcdctl
cd etcd-${ETCD_VER}-linux-amd64
#重命名,便于识别
cp etcdctl /usr/local/bin/
#删除安装数据目录
cd /usr/local&& rm -rf ${ETCD_DIR}
#添加环境变量
echo "ETCDCTL_API=3" >>/etc/profile
#查看版本
etcdctl version
chmod o+x install_etcdctl.sh
sh install_etcdctl.sh
输入:v3.5.4
Tres, implementación del modo de implementación de kubeadm
entendimiento básico:
- K8s utiliza la base de datos etcd para almacenar datos en el clúster en tiempo real. ¡Por seguridad, se debe hacer una copia de seguridad!
- La copia de seguridad solo necesita copia de seguridad en un nodo (para evitar daños al nodo de copia de seguridad, se recomienda hacer una copia de seguridad de dos nodos), los datos en cada nodo están sincronizados, pero la recuperación de datos debe realizarse en cada nodo .
- El contenedor ectd se comparte en red con la máquina host. Utilizando el método hostNetwork, el puerto de datos 2379 se puede ver en la máquina host (ss -ntlp|grep 2379).
[root@k8s-master-01 etcd_backup]# ss -ntlp|grep 2379
LISTEN 0 128 192.168.4.114:2379 *:* users:(("etcd",pid=1841,fd=9))
LISTEN 0 128 127.0.0.1:2379 *:* users:(("etcd",pid=1841,fd=8))
- El clúster implementado en modo kubeadm, en el que etcd se implementa y se inicia mediante un pod estático, tiene su archivo yaml en el directorio /etc/kubernetes/manifests, que registra la imagen de inicio, la versión, la ruta del certificado, el directorio de datos, etc.
[root@k8s-master-01 ~]# cat /etc/kubernetes/manifests/etcd.yaml |grep -A 10 volumes:
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /data/k8s/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
Preste atención a si se reemplaza el directorio de datos etcd, el valor predeterminado es /var/lib/etcd/ donde el directorio de datos etcd es /data/k8s/etcd; de lo contrario, el clúster no podrá recuperarse.
1) copia de seguridad
- Es mejor realizar una copia de seguridad de dos nodos para evitar solo el fallo de la máquina de copia de seguridad.
#创建命名空间
kubectl create ns test
#部署
cat > nginx-deployment.yaml<<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: test
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
EOF
#部署
kubectl apply -f nginx-deployment.yaml
#创建备份目录
mkdir -p /data/etcd_backup
cd /data/etcd_backup
#备份
ETCDCTL_API=3 etcdctl \
snapshot save snap.db_$(date +%F) \
--endpoints=https://192.168.4.114:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
#检查
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --write-out=table snapshot status /opt/etcd_backup/snap.db_2023-08-24
Deprecated: Use `etcdutl snapshot status` instead.
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 4c5447a8 | 2333766 | 1308 | 6.9 MB |
+----------+----------+------------+------------+
#集群节点状态
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" member list -w table
+------------------+---------+---------------+----------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+---------------+----------------------------+----------------------------+------------+
| c3509e57d5f53562 | started | k8s-master-01 | https://192.168.4.114:2380 | https://192.168.4.114:2379 | false |
+------------------+---------+---------------+----------------------------+----------------------------+------------+
#任意节点查看 etcd 集群信息
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.4.114:2379 | c3509e57d5f53562 | 3.5.4 | 6.9 MB | true | false | 10 | 2649811 | 2649811 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
- Hay nginx antes de la implementación, elimine nginx, restaure, etc. para confirmar la existencia de nginx.
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6774dc6-7mm2j 1/1 Running 0 11s
nginx-deployment-ff6774dc6-hdvbf 1/1 Running 0 11s
nginx-deployment-ff6774dc6-zcf8m 1/1 Running 0 11s
[root@k8s-master-01 ~]#kubectl delete -f nginx-deployment.yaml
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
2) recuperación
kubeadm
- El etcd en el clúster implementado por kubeadm se ejecuta como un contenedor estático y el directorio de almacenamiento del archivo de configuración del contenedor estático es /etc/kubernetes/manifests/.
- El proceso principal es: detener los servicios api-server y etcd -> ejecutar restauración -> reiniciar api-server y los servicios etcd
#先停止api server和etcd服务。因为是静态Pod部署,监控这个目录下的yaml文件,当把目录备份后就直接相当于停服
mkdir -p /tmp/etcd/manifests/
mv /etc/kubernetes/manifests/{kube-apiserver.yaml,etcd.yaml} /tmp/etcd/manifests/
mv /data/k8s/etcd /data/k8s/etcd.`date +%Y%m%d`
#查看api-server是否停止
[root@k8s-master-01 ~]# kubectl get pod
The connection to the server 192.168.4.114:6443 was refused - did you specify the right host or port?
#使用snap.db文件恢复数据到/var/lib/etcd目录。
ETCDCTL_API=3 etcdctl snapshot restore snap.db_2023-08-24 --endpoints=https://192.168.4.114:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --data-dir=/data/k8s/etcd
#启动kube-apiserver和etcd容器
mv /tmp/etcd/manifests/{kube-apiserver.yaml,etcd.yaml} /etc/kubernetes/manifests/
#查看结果,数据恢复
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6774dc6-ch9p2 1/1 Running 0 2m3s
nginx-deployment-ff6774dc6-cklzj 1/1 Running 0 2m3s
nginx-deployment-ff6774dc6-fb6wb 1/1 Running 0 2m3s
#检查集群是否正常
[root@k8s-master-01 etcd_backup]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
4. Copia de seguridad de tiempo
- Es mejor realizar una copia de seguridad de dos nodos para evitar solo el fallo de la máquina de copia de seguridad.
#创建etcd脚本存放目录
mkdir -p /opt/etcd_backup
#创建etcd数据备份目录
mkdir -p /data/etcd_backup
#创建定时备份脚本
[root@master etcd]# cat /opt/etcd_backup/etcd_backup.sh
#!/bin/bash
CACERT="/etc/kubernetes/pki/etcd/ca.crt "
CERT="/etc/kubernetes/pki/etcd/server.crt"
EKY="/etc/kubernetes/pki/etcd/server.key"
ENDPOINTS="192.168.4.114:2379"
ETCDCTL_API=3 etcdctl \
--cacert="${CACERT}" \
--cert="${CERT}" \
--key="${EKY}" \
--endpoints=${ENDPOINTS} \
snapshot save /data/etcd_backup/etcd-snapshot-`date +%Y-%m-%d_%H:%M:%S`.db
# 备份保留30天
find /data/etcd_backup/ -name *.db -mtime +30 -exec rm -f {} \;
#设置定时任务
crontab -e
#每天凌晨2点执行
0 2 * * * sh /opt/etcd_backup/etcd_backup.sh
#停止apisever和etcd
mkdir -p /tmp/etcd/manifests/
mv /etc/kubernetes/manifests/{kube-apiserver.yaml,etcd.yaml} /tmp/etcd/manifests/
mv /data/k8s/etcd /data/k8s/etcd.`date +%Y-%m-%d_%H:%M:%S`
#恢复命令
ETCDCTL_API=3 etcdctl snapshot restore /data/etcd_backup/etcd-snapshot-20230825.db \
--endpoints=https://192.168.4.114:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--data-dir=/data/k8s/etcd
#启动kube-apiserver和etcd容器
mv /tmp/etcd/manifests/{kube-apiserver.yaml,etcd.yaml} /etc/kubernetes/manifests/
#查看集群
kubectl get cs
Cinco, copia de seguridad de implementación binaria
| nodo | IP |
|---|---|
| etdc_1 | 192.168.4.114 |
| etdc_2 | 192.168.4.115 |
| etdc_3 | 192.168.4.116 |
1) copia de seguridad
- Es mejor realizar una copia de seguridad de dos nodos para evitar solo el fallo de la máquina de copia de seguridad.
ETCDCTL_API=3 etcdctl \
snapshot save snap.db \
--endpoints=https://192.168.4.114:2379 \ #备份节点IP
--cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem
2) recuperación
- El clúster etcd se ejecuta en varios servidores en forma de servicio. La única diferencia con el método contenedor son los puntos finales del servicio. La copia de seguridad es la misma que kubeadm.
- Secuencia de recuperación: detener kube-apiserver -> detener ETCD -> restaurar datos -> iniciar ETCD -> iniciar kube-apiserve
1. Detener apiserver y etcd.
#每个etcd节点需要先手动停止kube-apiserver和etcd服务
systmectl stop kube-apiserver
systemctl stop etcd
mv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.`date +%Y-%m-%d_%H:%M:%S`
2. recuperación etcd_1
- La recuperación debe realizarse en cada nodo etcd.
# 每个etcd依次恢复,需要修改 name, initialadvertise-peer-urls等参数
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_1 \ # 每台节点name不一样,根据当前节点etcd配置文件即可
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \ #描述集群节点信息
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.114:2380 \ # 修改为当前节点ip
--data-dir=/vaf/lib/default.etcd #注意数据目录
3. recuperación etcd_2
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_2 \
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.115:2380 \
--data-dir=/vaf/lib/default.etcd
4. recuperación etcd_3
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_3 \
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.116:2380 \
--data-dir=/vaf/lib/default.etcd
5. Inicie etcd y apiserver
#启动 kube-apiserver和etcd 服务
systemctl start kube-apiserver
systemctl start etcd
6. Verifique el clúster
#查看集群状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl \
--cacert=/opt/etcd/ssl/etcd-ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem \
--endpoints="https://192.168.4.114:2379,https://192.168.4.115:2379,https://192.168.4.116:2379" endpoint health \
--write-out=table
#查看集群
[root@k8s-master-01 k8s]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
pista:
- Una vez restaurada la copia de seguridad, el clúster no estará disponible temporalmente porque se reinician los servicios apiserver y etcd.
- etcdctl es una copia de seguridad instantánea y no registra los datos escritos más recientes, por lo que la restauración desde la copia de seguridad puede perder los datos más recientes.
- etcd no puede realizar copias de seguridad de los datos comerciales almacenados en volúmenes de datos fotovoltaicos.
- etcd es una copia de seguridad global y no se puede realizar una copia de seguridad ni restaurarla para un determinado espacio de nombres.
6. Instalar veloro
Dirección de Velero: https://github.com/vmware-tanzu/velero
Dirección del complemento ACK: https://github.com/AliyunContainerService/velero-plugin
1) Introducción a Velero
Velero utiliza un sistema de almacenamiento de objetos como respaldo, por lo que antes de instalar Velero, debe instalar un sistema de almacenamiento de objetos, como Ceph o Minio. La instalación de Minio es relativamente sencilla y también se recomienda utilizar Minio como sistema de almacenamiento de respaldo de Velero.
Los usuarios de velero pueden realizar copias de seguridad, restaurar y migrar de forma segura los recursos del clúster y los volúmenes persistentes de Kubernetes. Su principio básico es realizar una copia de seguridad de los datos del clúster, como los recursos del clúster y los volúmenes de datos persistentes, en el almacenamiento de objetos y extraer los datos del almacenamiento de objetos durante la recuperación. Además de la recuperación ante desastres, también puede realizar la migración de recursos y admitir la migración de aplicaciones de contenedores de un clúster a otro, lo que también es un escenario de uso muy exitoso para velero.
Velero incluye principalmente dos componentes principales, a saber, servidor y cliente. El servidor se ejecuta en un clúster de Kubernetes específico y el cliente es una herramienta de línea de comandos que se ejecuta localmente y se puede utilizar siempre que se configuren kubectl y kubeconfig, lo cual es muy simple.
Con base en su capacidad de copia de seguridad de recursos de Kubernetes, Velero puede realizar fácilmente copias de seguridad y recuperación de datos de clústeres de Kubernetes, copiar recursos del clúster de Kubernetes a otros clústeres de Kubernetes o copiar rápidamente el entorno de producción al entorno de prueba y otras funciones.
En términos de copia de seguridad de recursos, velero admite la copia de seguridad de datos en numerosos almacenamientos en la nube, como AWS S3 o sistemas de almacenamiento compatibles con S3, Azure Blob, Google Cloud Storage, Aliyun OSS, etc. En comparación con etcd, el motor de almacenamiento de datos que hace una copia de seguridad de todo Kubernetes, el control de velero es más detallado: puede hacer una copia de seguridad del nivel de objeto en el clúster de Kubernetes y también puede hacer una copia de seguridad o restaurar objetos como Tipo, Espacio de nombres y Etiqueta por clasificación. .
2) flujo de trabajo
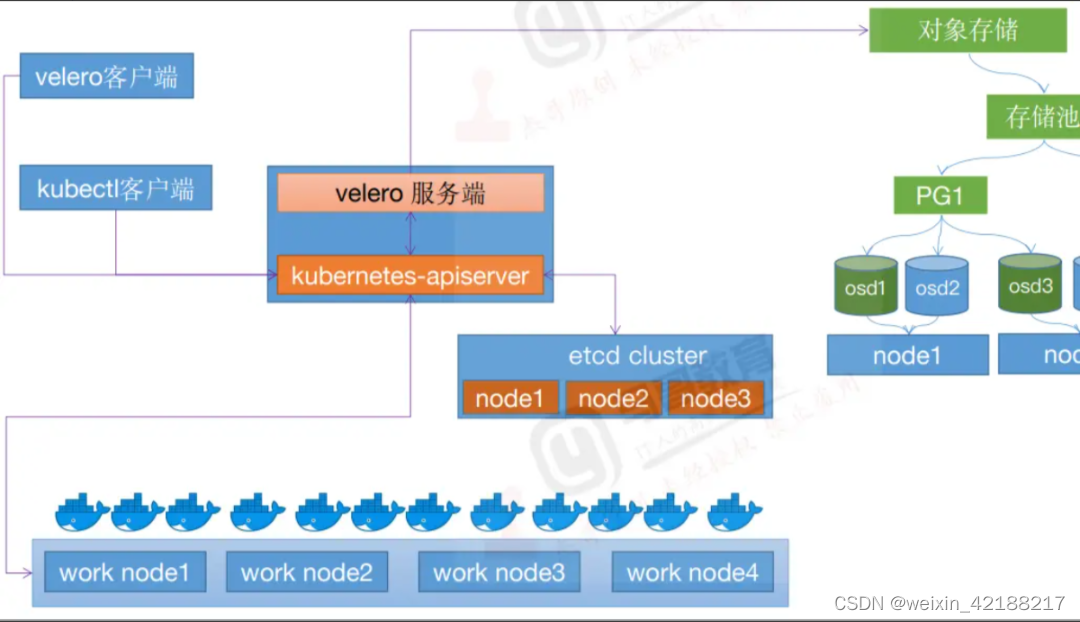
Tome la copia de seguridad de datos centrales como ejemplo; al ejecutar la copia de seguridad de velero, cree mi copia de seguridad:
- El cliente Velero primero llama al servidor API de Kubernetes para crear un objeto de respaldo;
- BackupController será notificado de que se ha creado un nuevo objeto de Backup y realizará la validación;
- BackupController inicia el proceso de copia de seguridad, recopila datos para la copia de seguridad consultando recursos al servidor API;
- BackupController llamará al servicio de almacenamiento de objetos, por ejemplo, AWS S3, para cargar el archivo de copia de seguridad. De forma predeterminada, Velero Backup Create admite instantáneas de disco de cualquier volumen persistente. Las instantáneas se pueden ajustar especificando indicadores adicionales. Ejecute Velero Backup Create --help para ver los indicadores disponibles. También puede desactivar las instantáneas con la opción --snapshot-volumes=false .
Con respecto a la ubicación de almacenamiento de respaldo y las instantáneas de volumen, Velero tiene dos recursos personalizados, BackupStorageLocation y VolumeSnapshotLocation, que se utilizan para configurar la ubicación de almacenamiento de las copias de seguridad de Velero y sus instantáneas de volumen persistentes asociadas.
El almacenamiento de backend principal admitido por BackupStorageLocation es el almacenamiento compatible con S3, un prefijo en el depósito donde se almacenan todos los datos de Velero y un conjunto de otros campos específicos del proveedor. Por ejemplo: Minio y Alibaba Cloud OSS, etc.;
VolumeSnapshotLocation (datos pv), que se utiliza principalmente para tomar instantáneas de PV, requiere que los proveedores de la nube proporcionen complementos y está completamente definido por campos específicos proporcionados por el proveedor (como la región de AWS, el grupo de recursos de Azure, el tipo de instantánea de Portworx, etc.). ). Tomando como ejemplo la base de datos y el middleware que son más sensibles a la coherencia de los datos, el complemento de almacenamiento de código abierto Carina pronto proporcionará una función de instantánea de volumen velero con reconocimiento de base de datos, que puede realizar copias de seguridad y recuperación rápidas de datos de middleware.
3) Proceso general
Los siguientes son los pasos generales para implementar Kubernetes Velero:
| paso | describir |
|---|
- Instalar Velero | Instalar Velero en un clúster de Kubernetes
- Crear almacenamiento backend de Velero | Configurar el almacenamiento en la nube o el almacenamiento local utilizado por Velero
- Crear certificados y autenticación de Velero | Generar certificados y claves TLS y crear Kubernetes Secret
- Configurar Velero | Crear un archivo de configuración para Velero
- Crear y configurar depósitos de Velero | Crear depósitos en el almacenamiento backend de Velero
- Configuración de complementos de Velero | Instalación y configuración de complementos de Velero
- Crear programación de Velero | Configurar Velero para crear una programación de respaldo
4) volumen persistente nfs
[root@k8s-master ~]# vim nfs.sh
#!/bin/bash
IPADDR=$(ip a|grep brd|grep ens160|awk '{print $2}'|grep -o -E "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}")
read -p "请输入本机IP:" -t 30 HOST_IP
yum install -y nfs-utils
mkdir -p /data/nfs
chmod -R 777 /data/nfs
#增加配置文件
echo "/data/nfs s $IPADDR/24(rw,sync,no_subtree_check,no_root_squash)" >>/etc/exports
#查看配置文件
cat /etc/exports
#授权(chown 修改文件和文件夹的用户和用户组属性)
chown nfsnobody:nfsnobody /data/nfs
#启动和增加开启自启动
systemctl restart nfs-server.service
systemctl enable nfs-server.service
systemctl status nfs-server.service
#创建数据目录
mkdir -p /opt/nfs-storageclass
cd /opt/nfs-storageclass
cat >nfs-client-provisioner.yaml<<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: nfs # 存储分配器的默认名称 ,根据自己的名称来修改,与 storageclass.yaml 中的 provisioner 名字一致
- name: NFS_SERVER
value: $HOST_IP # NFS服务器所在的 ip
- name: NFS_PATH
value: /data/nfs # 共享存储目录
volumes:
- name: nfs-client-root
nfs:
server: $HOST_IP # NFS服务器所在的 ip
path: /data/nfs # 共享存储目录
EOF
sed -i 's#gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.1# dyrnq/nfs-subdir-external-provisioner:v4.0.1#g' nfs-client-provisioner.yaml
cat >rbac.yaml<<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
EOF
cat >storageclass.yaml<<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: nfs # 或者选择其他名称,必须匹配部署变量 PROVISIONER_NAME'
parameters:
archiveOnDelete: "false" #当设置为“false”时,在删除PVC时,您的pv将不会被配置程序存档。
EOF
kubectl apply -f /opt/nfs-storageclass/.
chmod o+x nfs.sh
sh nfs.sh
输入nfs的节点IP
kubectl get pods -n kube-system|grep fs-client-provisioner-
5) Instalar Velero
【Documento oficial】
- https://velero.io/docs/v1.9/
- https://github.com/vmware-tanzu/velero/
[Compatibilidad entre la versión Velero y la versión k8s]
- https://github.com/vmware-tanzu/velero
| Velero version | Probado en la versión de Kubernetes |
|---|---|
| 1.12 | 1.25.7, 1.26.5, 1.26.7 y 1.27.3 |
| 1.11 | 1.23.10, 1.24.9, 1.25.5 y 1.26.1 |
| 1.10 | 1.22.5, 1.23.8, 1.24.6 y 1.25.1 |
| 1.9 | 1.20.5, 1.21.2, 1.22.5, 1.23 y 1.24 |
- Velero admite entornos IPv4, IPv6 y de doble pila
#查看k8s版本,选择Velero版本kubeadm version
[root@k8s-master1 ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.0", GitCommit:"a866cbe2e5bbaa01cfd5e969aa3e033f3282a8a2", GitTreeState:"clean", BuildDate:"2022-08-23T17:43:25Z", GoVersion:"go1.19", Compiler:"gc", Platform:"linux/amd64"}
cd /opt/
wget -c https://ghproxy.com/github.com/vmware-tanzu/velero/releases/download/v1.10.0/velero-v1.10.0-linux-amd64.tar.gz
tar -zxvf velero-v1.10.0-linux-amd64.tar.gz
cd velero-v1.10.0-linux-amd64
mv velero /usr/local/bin
chmod +x /usr/local/bin/velero
velero version
6) Instalar minio
1. Dirección oficial
【Dirección oficial】
- https://github.com/minio/mc
- https://min.io/docs/minio/linux/index.html?ref=docs-redirect
- https://zhuanlan.zhihu.com/p/557868296
【Versión de espejo especificada】
- https://github.com/minio/mc/tree/RELEASE.2023-08-18T21-57-55Z
2. Implementar yaml
Aquí podemos usar minio para reemplazar el almacenamiento de objetos del entorno de nube. El paquete comprimido descomprimido anterior contiene un archivo de lista de recursos de ejemplos/minio/00-minio-deployment.yaml. Para facilitar las pruebas, el Servicio se puede cambiar a el tipo NodePort. , podemos configurar una dirección de consola para proporcionar una entrada de acceso a la página de la consola, el archivo de lista de recursos completo es el siguiente:
#配置一个 console-address 来提供一个 console 页面的访问入口
args:
- server
- /storage
- --config-dir=/config
- --console-address=:9001 #添加
。。。。。。
ports:
- containerPort: 9000
- containerPort: 9001 #添加
#暴露端口
# type: ClusterIP
# ports:
# - port: 9000
# targetPort: 9000
# protocol: TCP
type: NodePort
ports:
- name: api
port: 9000
targetPort: 9000
- name: console
port: 9001
targetPort: 9001
nodePort: 30009
#修改minio部署yaml
cd /opt/velero-v1.10.0-linux-amd64/examples/minio
#查看
[root@k8s-master1 minio]# cat 00-minio-deployment.yaml
# Copyright 2017 the Velero contributors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
---
apiVersion: v1
kind: Namespace
metadata:
name: velero
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: velero
name: minio
labels:
component: minio
spec:
strategy:
type: Recreate
selector:
matchLabels:
component: minio
template:
metadata:
labels:
component: minio
spec:
volumes:
- name: storage
emptyDir: {}
- name: config
emptyDir: {}
containers:
- name: minio
image: minio/minio:edge
imagePullPolicy: IfNotPresent
args:
- server
- /storage
- --config-dir=/config
- --console-address=:9001
env:
- name: MINIO_ACCESS_KEY
value: "minio"
- name: MINIO_SECRET_KEY
value: "minio123"
ports:
- containerPort: 9000
- containerPort: 9001
volumeMounts:
- name: storage
mountPath: "/storage"
- name: config
mountPath: "/config"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage
namespace: velero
spec:
storageClassName: "managed-nfs-storage"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
namespace: velero
name: minio
labels:
component: minio
spec:
# ClusterIP is recommended for production environments.
# Change to NodePort if needed per documentation,
# but only if you run Minio in a test/trial environment, for example with Minikube.
type: NodePort
ports:
# - port: 9000
# targetPort: 9000
# protocol: TCP
- name: api
port: 9000
targetPort: 9000
- name: console
port: 9001
targetPort: 9001
nodePort: 30009
selector:
component: minio
---
apiVersion: batch/v1
kind: Job
metadata:
namespace: velero
name: minio-setup
labels:
component: minio
spec:
template:
metadata:
name: minio-setup
spec:
restartPolicy: OnFailure
volumes:
- name: config
emptyDir: {}
containers:
- name: mc
image: minio/mc:edge
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- "mc --config-dir=/config config host add velero http://minio:9000 minio minio123 && mc --config-dir=/config mb -p velero/velero"
volumeMounts:
- name: config
mountPath: "/config"
Acceso: http://192.168.4.115:30009/login
- Nombre de usuario: minio
- Contraseña: minio123
Los datos y la configuración de minio se pueden conservar con, por ejemplo, cephfs.
Generalmente se recomienda implementar fuera del clúster.
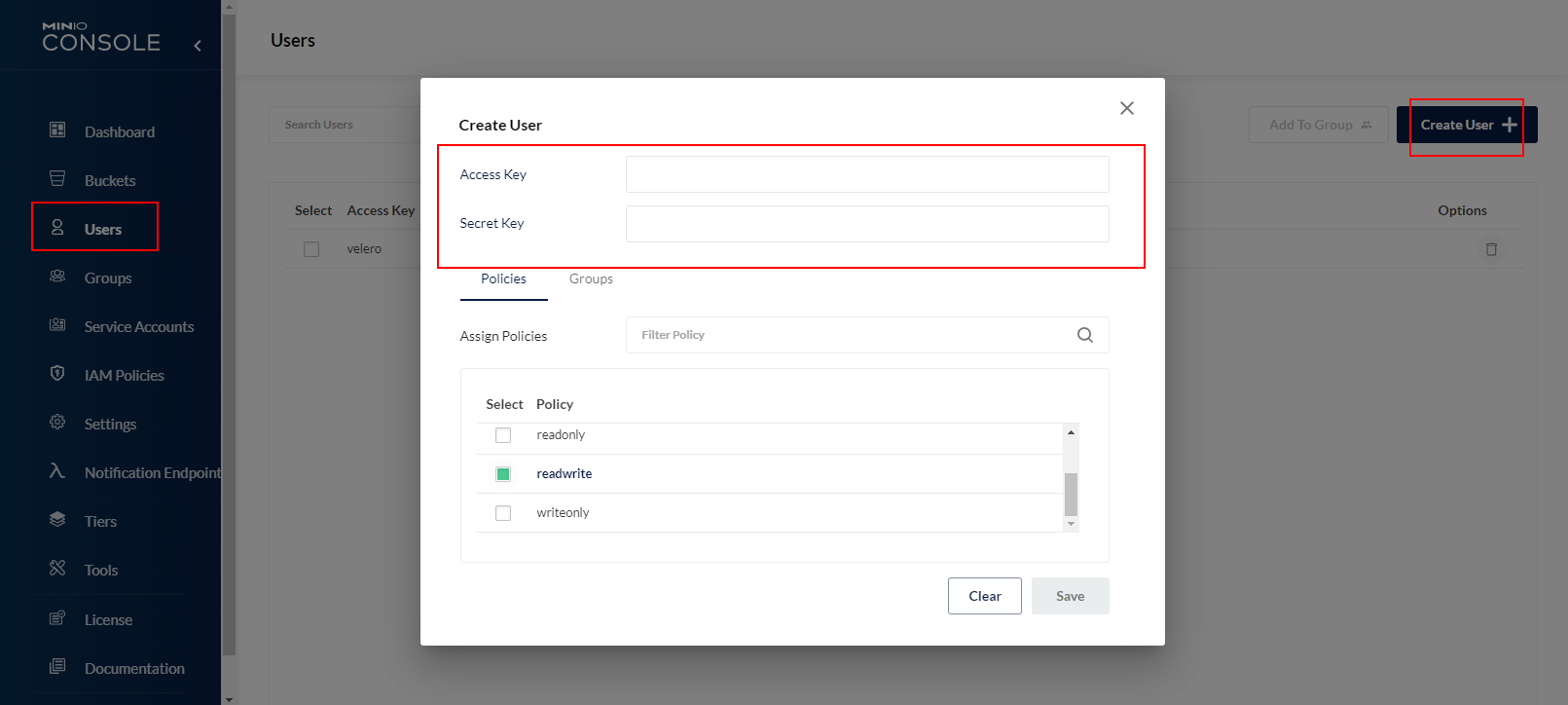
3. Cree una identificación y una clave
Puede elegir crear un depósito y luego debe crear un usuario (recuerde la identificación y la clave) para autorizar al depósito correspondiente a cargar normalmente.
- Seleccionar usuarios: seleccione crear usuario.
- Clave de acceso: copia de seguridad
- Clave secreta: Abcd123456
- seleccionar política: leer escribir
4. Cree un depósito de respaldo
- Seleccione "Depósitos" para crear un depósito de respaldo llamado velerodata.
- Seleccione "Crear depósito" para crear, y el resto son predeterminados
5. Acceso de prueba
Acceda a la cuenta de respaldo: http://192.168.4.115:30009/login
- Nombre de usuario: minioadmin
- Contraseña: minioadmin
7) Instalar el servidor velero
Cree un archivo de autenticación minio, utilizando el usuario con permiso de lectura y escritura creado anteriormente:
cd /opt/velero-v1.10.0-linux-amd64/
cat >velero-auth.txt << EOF
[default]
aws_access_key_id = minioadmin
aws_secret_access_key = minioadmin
EOF
velero --kubeconfig /root/.kube/config install \
--use-node-agent \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.7.0 \
--bucket velerodata --secret-file ./velero-auth.txt \
--use-volume-snapshots=false \
--namespace velero default-volumes-to-restic \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://minio.velero.svc:9000
Si la dirección s3URL no usa la dirección de resolución interna de k8s, use la dirección expuesta del puerto de datos 9000 (nodo IP+30008)
【Descripción de parámetros】
- –kubeconfig encuentra el archivo de autenticación creado por la variable de entorno KUBECONFIG de forma predeterminada
- –bucket minio crear nombre de almacenamiento
- --archivo de autenticación de contraseña de archivo secreto
- –namespace tiene como valor predeterminado el espacio de nombres velero; al especificar este parámetro se especifica la creación de un espacio de nombres
【Descripción de parámetros importantes】
| parámetros de instalación | Descripción de parámetros |
|---|---|
| -proveedor | Declara el uso de tipos de complementos proporcionados por aws. |
| –complementos | Utilice el complemento API compatible con AWS S3 "velero-plugin-for-aws". |
| -balde | Nombre del depósito creado en COS. |
| –archivo-secreto | El archivo de credenciales de acceso para acceder a COS. Para obtener más información, consulte el archivo de credenciales "credentials-velero" creado anteriormente. |
| –uso-restic | Velero admite el uso de la herramienta de copia de seguridad gratuita de código abierto Restic para realizar una copia de seguridad y restaurar los datos del volumen de almacenamiento de Kubernetes (los volúmenes hostPath no son compatibles, consulte Restricciones de Restic para obtener más detalles). Esta integración es un complemento a la función de copia de seguridad de Velero y se recomienda habilitarla. él. |
| –volúmenes-predeterminados-a-restic | Habilite el uso de Restic para realizar copias de seguridad de todos los volúmenes del Pod, siempre que sea necesario habilitar el parámetro --use-restic. |
| –backup-ubicación-config | Configuraciones relacionadas con el acceso al depósito de respaldo, incluida la región, s3ForcePathStyle, s3Url, etc. |
| región | La región del depósito COS de almacenamiento de objetos es compatible con la API de S3, por ejemplo, la región de creación es Guangzhou y el valor del parámetro de región es "ap-guangzhou". |
| s3ForcePathStyle | Utilice el formato de ruta de archivo S3. |
| s3URL | Dirección de acceso a la API S3 compatible con COS de almacenamiento de objetos. Tenga en cuenta que el nombre de dominio en la dirección de acceso no es el nombre de dominio de acceso a la red pública para crear el depósito de almacenamiento COS mencionado anteriormente, y se debe utilizar el formato de URL es https://cos..myqcloud.com. Por ejemplo, si la región es Guangzhou, el valor del parámetro es https://cos.ap-guangzhou.myqcloud.com. |
- Otros parámetros de instalación se pueden ver con el comando velero install --help. Por ejemplo, en lugar de realizar una copia de seguridad de los datos del volumen de almacenamiento, puede configurar --use-volume-snapshots=false para desactivar la copia de seguridad de instantáneas del volumen de almacenamiento.
#查看
[root@k8s-master1 velero-v1.10.0-linux-amd64]# kubectl get backupstoragelocation -A -oyaml
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-09-05T06:08:12Z"
generation: 15
labels:
component: velero
name: default
namespace: velero
resourceVersion: "1116179"
uid: 3eb2e6ef-f95e-4674-92c7-8b296f864d57
spec:
config:
region: minio
s3ForcePathStyle: "true"
s3Url: http://minio.velero.svc:9000
default: true
objectStorage:
bucket: velerodata
provider: aws
status:
lastSyncedTime: "2023-09-05T06:14:21Z"
lastValidationTime: "2023-09-05T06:14:21Z"
phase: Available
kind: List
metadata:
resourceVersion: ""
#删除
kubectl delete -n velero backupstoragelocations.velero.io default
kubectl delete deployments.apps -n velero velero
#卸载
velero uninstall
#查看安装状态
[root@k8s-master1 ~]# kubectl get pod -n velero
NAME READY STATUS RESTARTS AGE
minio-597fcfdb94-cksx2 1/1 Running 0 18m
minio-setup-76r5g 0/1 Completed 0 18m
node-agent-frqjq 1/1 Running 0 12m
node-agent-mtb96 1/1 Running 0 12m
node-agent-nlsg7 1/1 Running 0 12m
velero-5bb5bd6699-f8z9q 1/1 Running 0 12m
[root@k8s-master1 ~]# kubectl get crd | grep velero
backuprepositories.velero.io 2023-09-05T06:08:09Z
backups.velero.io 2023-09-05T06:08:09Z
backupstoragelocations.velero.io 2023-09-05T06:08:09Z
deletebackuprequests.velero.io 2023-09-05T06:08:09Z
downloadrequests.velero.io 2023-09-05T06:08:09Z
podvolumebackups.velero.io 2023-09-05T06:08:09Z
podvolumerestores.velero.io 2023-09-05T06:08:09Z
restores.velero.io 2023-09-05T06:08:10Z
schedules.velero.io 2023-09-05T06:08:10Z
serverstatusrequests.velero.io 2023-09-05T06:08:10Z
volumesnapshotlocations.velero.io 2023-09-05T06:08:10Z
#查看安装状态
[root@k8s-master1 ~]# kubectl get backupstoragelocations -A
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT
velero default Available 45s 13m true
[velero instalado a través del timón]
- http://www.1024sky.cn/blog/article/77733
7. Implementar la aplicación de prueba.
1) Implementar el servicio de prueba
Implemente dos aplicaciones de prueba para probar los resultados de la copia de seguridad y la recuperación, y utilice minio para almacenar los datos de la copia de seguridad.
- mysql 5.7
cd /opt/velero-v1.10.0-linux-amd64/
cat >mysql5.7.yaml<<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1 #版本
kind: Deployment #创建资源的类型
metadata: #资源的元数据
name: mysql-dep #资源的名称,是元数据必填项
spec: #期望状态
replicas: 1 #创建的副本数量(pod数量),不填默认为1
selector: #
matchLabels:
app: mysql-pod
template: #定义pod的模板
metadata: #pod的元数据
labels: #labels标签,必填一个
app: mysql-pod
spec: #pod的期望状态
containers: #容器
- name: mysql #容器名称
image: mysql:5.7 #镜像
imagePullPolicy: IfNotPresent
ports: #容器的端口
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "root"
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
---
apiVersion: v1 #版本
kind: Service #创建资源的类型
metadata: #资源的元数据
name: mysql-svc #资源的名称,是元数据必填项
labels: #labels标签
app: mysql-svc
spec: #期望状态
type: NodePort #服务类型
ports: #端口
- port: 3306
targetPort: 3306 #与containerPort一样
protocol: TCP
nodePort: 30306
selector:
app: mysql-pod
EOF
- archivo de implementación nginx
cat >nginx.yaml<<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-nfs-storage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: my-pvc
containers:
- name: nginx
image: nginx
volumeMounts:
- name: data-volume
mountPath: /var/www/html
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
EOF
#创建
kubectl apply -f mysql5.7.yaml
kubectl apply -f nginx.yaml
2) Escribir contenido de prueba
kubectl exec -it -n default mysql-dep-58cb9d765f-4sd58 /bin/bash
mysql -uroot -proot
-- 创建测试数据库
CREATE DATABASE testdb;
-- 使用测试数据库
USE testdb;
-- 创建测试表
CREATE TABLE test_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
email VARCHAR(100)
);
-- 插入测试数据
INSERT INTO test_table (name, age, email) VALUES
('John Doe', 25, '[email protected]'),
('Jane Smith', 30, '[email protected]'),
('Mike Johnson', 35, '[email protected]');
select * from test_table;
+----+--------------+------+--------------------------+
| id | name | age | email |
+----+--------------+------+--------------------------+
| 1 | John Doe | 25 | [email protected] |
| 2 | Jane Smith | 30 | [email protected] |
| 3 | Mike Johnson | 35 | [email protected] |
+----+--------------+------+--------------------------+
#退出MySQL和容器
mysql> exit
Bye
bash-4.2# exit
exit
Ocho, prueba de copia de seguridad
1) Resumen de copia de seguridad
1. Clasificación de respaldo
velero tiene dos formas de hacer una copia de seguridad de los datos con estado, la comparación es la siguiente
| Considere las dimensiones | Basado en una instantánea de CSI | Copia de archivo |
|---|---|---|
| impacto en el rendimiento de la aplicación | Bajo, la interfaz CSI llama a la instantánea del sistema de almacenamiento. | Dependiendo de la cantidad de datos, consume recursos adicionales. |
| Disponibilidad de datos | Dependiendo del sistema de almacenamiento, deberá utilizar un CSI que admita instantáneas. | Almacenamiento de objetos y aislamiento del entorno de producción, disponibilidad independiente, soporte de disponibilidad entre sitios |
| consistencia de los datos | Apoye la consistencia de choques, coopere con el mecanismo de gancho para lograr consistencia | Sin garantía, basado en gancho. |
⋓La copia de archivos se cifrará, comprimirá y se realizará una copia de seguridad incremental. La relación de compresión es de aproximadamente el 60%. Los archivos de copia de seguridad son todos archivos binarios cifrados, que están confusos.
Dos complementos de copia de archivos:
- Restic (predeterminado) https://restic.readthedocs.io/en/latest/100_references.html#terminology
- Copiar https://kopia.io/docs/advanced/architecture
2. Mejores prácticas de copia de seguridad
- Si su almacenamiento admite instantáneas, instantáneas locales de alta frecuencia + copia de seguridad restic de baja frecuencia en s3
- Seleccione la granularidad de respaldo y la estrategia de respaldo adecuadas desde el punto de vista de la aplicación.
- Evite conflictos al compartir el mismo almacén de objetos en un entorno de múltiples clústeres
3. Mecanismo de sincronización
- Dado que velero backup cargará la metainformación de esta tarea de respaldo en s3, cuando la tarea de respaldo se elimina en el clúster, pero los datos en s3 se eliminan, velero sincronizará periódicamente la tarea de respaldo de s3 con el clúster.
4. hoyo
- Eliminar tareas de copia de seguridad o recuperación que no se han completado durante mucho tiempo hará que velero se bloquee y no pueda procesar tareas posteriores
- Cuando se utiliza el método de copia de seguridad de archivos, es muy probable que las aplicaciones con sistemas de archivos de copia de seguridad que cambian rápidamente, como Es y Ck, no realicen copias de seguridad.
2) copia de seguridad
- La copia de seguridad admite copia de seguridad completa, copia de seguridad del espacio de nombres especificado, copia de seguridad del selector especificado, etc. Para obtener más información, puede ver la ayuda a través de velero backup create -h.
#创建单次的备份任务,备份数据库与nginx
velero backup create test3 --include-namespaces=default --default-volumes-to-fs-backup
Parámetros comunes:
- --include-namespaces: especifique los espacios de nombres para realizar la copia de seguridad, separados por varias comas
- –include-resources: especifique el tipo de recurso para realizar la copia de seguridad, separado por varias comas, como configmap, secret
- --include-cluster-resources: se establece en verdadero para indicar que la copia de seguridad incluye recursos a nivel de clúster, separados por varias comas.
- –exclude-namespaces: excluye espacios de nombres especificados, separados por varias comas
- excluir recursos: excluir tipos de recursos específicos
- copia de seguridad de velero obtener vista de copia de seguridad
- velero backup describe --details Ver lista de datos de respaldo
3) Copia de seguridad de tiempo
#这里我们为了测试将备份周期调整成了每分钟一次
[root@master1 yaml]# velero schedule create schedule-backup --schedule="* * * * *" --include-namespaces=default --default-volumes-to-fs-backup Schedule "schedule-backup" created successfully.
[root@master1 yaml]# kubectl get schedule -A
NAMESPACE NAME STATUS SCHEDULE LASTBACKUP AGE PAUSED
velero schedule-backup Enabled * * * * * 15s
8. Recuperación
- Primero elimine mysql y nginx. Aquí eliminamos manualmente nginx y mysql para simular la pérdida de datos.
#删除
cd /opt/velero-v1.10.0-linux-amd64/
kubectl delete -f mysql5.7.yaml
kubectl delete -f nginx.yaml
#查看
kubectl get pod -n default
kubectl get all -n default
-Iniciar la recuperación, crear una estrategia de recuperación, restaurar desde una tarea de copia de seguridad de la que hemos realizado una copia de seguridad previamente.
#查看备份
[root@k8s-master1 ~]# kubectl get backup -A
NAMESPACE NAME AGE
velero test3 5m47s
#恢复
[root@k8s-master1 ~]# velero restore create --from-backup test3
Restore request "test3-20230905145431" submitted successfully.
Run `velero restore describe test3-20230905145431` or `velero restore logs test3-20230905145431` for more details.
#查看恢复记录
[root@k8s-master1 ~]# kubectl get restore -A
NAMESPACE NAME AGE
velero test3-20230905145431 26s
#查看恢复的数据
[root@k8s-master1 ~]# kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
mysql-dep-58cb9d765f-4sd58 0/1 PodInitializing 0 64s
nginx-deployment-7bb559659f-w6tpw 1/1 Running 0 64s
- Después de esperar un rato, se descubre que todos los pods se están ejecutando y se comprueba si hay datos en MySQL.
[root@k8s-master1 ~]# kubectl exec -it -n default mysql-dep-58cb9d765f-4sd58 /bin/bash
bash-4.2# mysql -uroot -proot
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb |
+--------------------+
5 rows in set (0.00 sec)
mysql> use testdb;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test_table;
+----+--------------+------+--------------------------+
| id | name | age | email |
+----+--------------+------+--------------------------+
| 1 | John Doe | 25 | [email protected] |
| 2 | Jane Smith | 30 | [email protected] |
| 3 | Mike Johnson | 35 | [email protected] |
+----+--------------+------+--------------------------+
3 rows in set (0.00 sec)
9. Migración de datos del clúster
#首先,在集群 1 中创建备份(默认 TTL 是 30 天,你可以使用 --ttl 来修改):
velero backup create <BACKUP-NAME>
#然后,为集群 2 配置 BackupStorageLocations 和 VolumeSnapshotLocations,指向与集群 1 相同的备份和快照路径,并确保 BackupStorageLocations 是只读的(使用 --access-mode=ReadOnly)。接下来,稍微等一会(默认的同步时间为 1 分钟),等待 Backup 对象创建成功。
velero backup describe <BACKUP-NAME>
#最后,执行数据恢复:
velero restore create --from-backup <BACKUP-NAME>
velero restore get
velero restore describe <RESTORE-NAME-FROM-GET-COMMAND>
10. Dirección de referencia
【kubeadm】
- http://wed.xjx100.cn/news/186281.html?action=onClick
- http://www.inspinia.net/a/216380.html?action=onClick
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
- https://cloud.tencent.com/developer/article/2098673
[Guión]
- https://www.cnblogs.com/zhangmingcheng/p/13892140.html
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
[Referencia de implementación binaria]
- https://www.yii666.com/blog/509712.html
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
【Herramientas Velero】
- https://github.com/vmware-tanzu/velero
[referencia clave]
- https://www.jb51.cc/k8s/3812803.html
- https://blog.51cto.com/u_16175439/6627299
- http://yunxue521.top/archives/velero
【Documentación de Tencent Cloud】
- https://www.tencentcloud.com/zh/document/product/457/38939
【Contenedor de herramientas de respaldo】
- https://zhuanlan.zhihu.com/p/391732609
【Excelente blog】
- https://www.hi-linux.com/posts/60858.html