Directorio de artículos
Uno: tipo de registro
1. gramática
TYPE record_type IS RECORD(
column1 type,
colunm2 type,
… …
Variable_name record_type;
2. Ejemplo de código
declare
type test_rec is record( --test_rec记录类型
l_name varchar2(30),
d_id number(4));
v_emp test_rec; --v_emp变量名
begin
v_emp.l_name := '张三';
v_emp.d_id := 1234;
dbms_output.put_line(v_emp.l_name || ',' || v_emp.d_id);
end;
Puede utilizar la instrucción SELECT para asignar valores a las variables de registro, siempre que se asegure de que los campos del registro coincidan con los campos de la lista de resultados de la consulta.
create table cux.employee
(last_name varchar2(20),
department_id number(4));
insert into cux.employee values('李四',1235,234);
declare
type test_rec is record( --test_rec记录类型
l_name varchar2(30),
d_id number(4));
v_emp test_rec; --v_emp变量名
begin
select last_name, department_id into v_emp
from cux.employee
where employee_id = 234;
dbms_output.put_line(v_emp.l_name || ', ' || v_emp.d_id);
end;
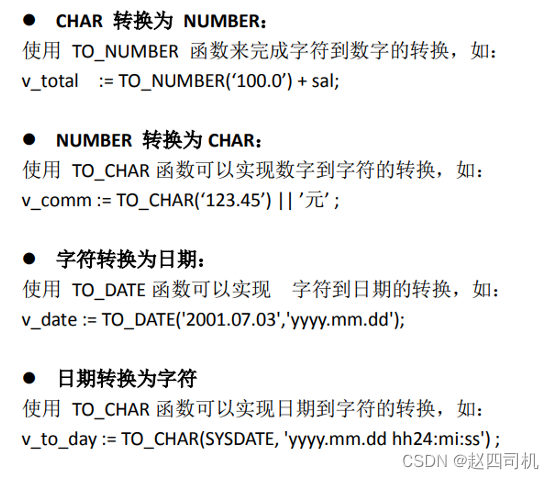
Dos: conversión de personajes
Tres: %TYPE y %ROWTYPE
1.%TIPO
Defina una variable cuyo tipo de datos sea el mismo que el de una variable de datos definida, o el tipo de datos de una columna en una tabla de base de datos, luego puede usar %TYPE
Ventajas de utilizar %TYPE:
- No es necesario conocer el tipo de datos de la columna de la base de datos a la que se hace referencia;
- El tipo de datos de la columna de la base de datos a la que se hace referencia puede cambiar en tiempo real.
declare
type test_rec is record(
l_name cux.employee.last_name%type,
d_id cux.employee.department_id%type);
v_emp test_rec;
begin
select last_name,
department_id into v_emp
from cux.employee where employee_id = 234;
dbms_output.put_line(v_emp.l_name || ', ' || v_emp.d_id);
end;
2.% TIPO DE FILA

Cuatro: bucle
1.BUCLE
LOOP
要执行的语句;
EXIT WHEN<条件语句>; --条件满足,退出
END LOOP
declare
int NUMBER(2) := 0;
begin
LOOP
int := int + 1;
dbms_output.put_line('int的当前值为:' || int);
EXIT WHEN int = 10;
END LOOP;
END;
2. MIENTRAS (recomendado)
WHILE<布尔表达式> LOOP
要执行的语句;
END LOOP;
DECLARE
x NUMBER(2) := 0;
BEGIN
WHILE x < 10 LOOP
x := x + 1;
dbms_output.put_line('x的当前值为:' || x);
END LOOP;
END;
3. Ciclo digital
FOR 循环计数器 IN[REVERSE] 下限 .. 上限 LOOP
要执行的语句
END LOOP;
En cada bucle, la variable del bucle aumenta automáticamente en 1; utilizando la palabra clave REVERSE, la variable del bucle disminuye automáticamente en 1. Los números que siguen EN REVERSO deben estar en orden ascendente y deben ser números enteros, no variables ni expresiones. Se puede salir del bucle con EXIT .
begin
FOR i in reverse 2 .. 10 LOOP
DBMS_OUTPUT.PUT_LINE('i的值为' || i);
END LOOP;
end;
Cinco: Cursor
1. Definición y lectura del cursor.
--游标FOR读取
declare
cursor c_emp(dep_id number default 1236) is
select last_name,employee_id epid
from cux.employee
where department_id = dep_id;
begin
for v_emp in c_emp loop
DBMS_OUTPUT.PUT_LINE(v_emp.last_name || ', ' || v_emp.epid);
end loop;
end;
2. Propiedades del cursor
- % ENCONTRADO: atributo de tipo booleano, cuando el último registro leído se devuelve correctamente, el valor es VERDADERO;
- %NOTFOUND: atributo de tipo booleano, opuesto a %FOUND;
- %ISOPEN: atributo booleano, devuelve VERDADERO cuando el cursor está abierto;
- %ROWCOUNT: un atributo numérico que devuelve el número de registros que se han leído desde el cursor.
3. La diferencia entre NO_DATA_FOUND y %NOTFOUND
Las declaraciones SELECT... INTO activan NO_DATA_FOUND;
Activar %NOTFOUND cuando no se encuentra la cláusula WHERE de un cursor de visualización; activa SQL%NOTFOUND cuando no se encuentra la cláusula WHERE de la instrucción UPATE o DELETE; utiliza %NOTFOUND o %FOUND para determinar la condición de salida del bucle en el bucle de extracción, no utilice NO_DATA_FOUND.
Seis: error anormal
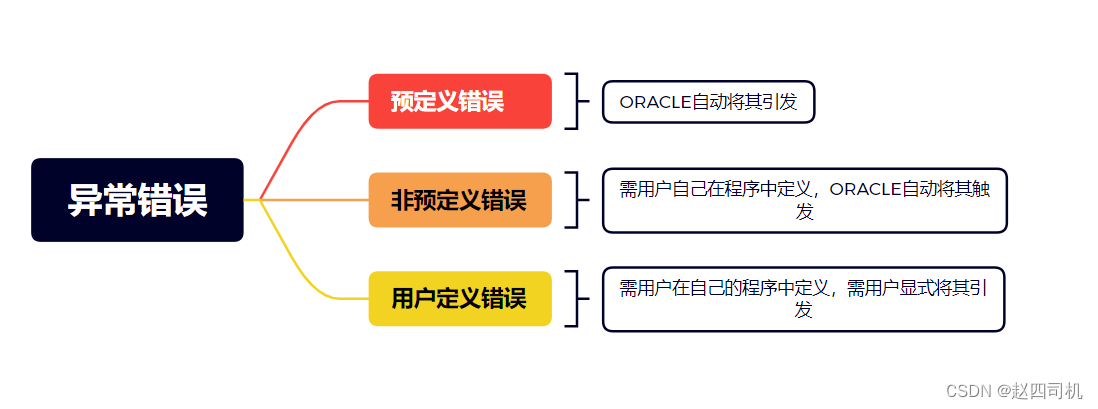
1. Manejo de excepciones
EXCEPTION
WHEN first_exception THEN <code to handle first exception>
WHEN second_exception THEN <code to handle second exception>
WHEN OTHERS THEN <code to handle others exception>
END;
El manejo de excepciones se puede organizar en cualquier orden, pero OTROS deben colocarse al final.
declare
-- Local variables here
v_empid cux.employee.employee_id%type := &v_empid;
v_sal cux.employee.salary%type;
/* 预定义异常处理 */
begin
-- Test statements here
select salary into v_sal
from cux.employee
where employee_id = v_empid
for update;
if v_sal <= 3000 then
update cux.employee set salary = salary+1000
where employee_id = v_empid;
DBMS_OUTPUT.PUT_LINE('编号为:'|| v_empid || '工资已更新');
else
DBMS_OUTPUT.PUT_LINE('编号为:'|| v_empid || '工资不需更新');
end if;
exception
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('编号为:'|| v_empid || '员工不存在');
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE('数据行数太多,请使用游标');
WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('其他错误');
end;
2. Manejo de excepciones no predefinidas
-
Defina la condición de excepción <condición de excepción> EXCEPCIÓN en la sección de definición de bloque PL/SQL
-
Conecte sus excepciones definidas con errores estándar de ORACLE y utilice la declaración PRAGMA EXCEPTION_INIT;
EXCEPCIÓN DE PRAGMA (<situación anormal>,<código de error>);
-
En la parte de procesamiento de situaciones anormales de PL/SQL, la situación anormal se trata en consecuencia.
3. Manejo de excepciones definido por el usuario
Los errores de excepción definidos por el usuario se desencadenan mediante el uso explícito de la instrucción RAISE. Cuando se genera un error de excepción, el control se transfiere a la parte de error de excepción del bloque EXCEPCIÓN y se ejecuta el código de manejo de errores.
paso:
-
Defina excepciones en la parte de definición del bloque PL/SQL;
-
<situación anormal> EXCEPCIÓN
LEVANTAR<condición anormal>;
En la situación anormal que maneja parte del bloque PL/SQL, la situación anormal se trata en consecuencia.
Siete: procedimientos o funciones almacenados
Almacene el programa PL/SQL en la base de datos y ejecútelo en cualquier lugar. La única diferencia entre procedimientos y funciones es que las funciones siempre devuelven datos a la persona que llama, mientras que los procedimientos no devuelven datos.
1. Función
La marca del parámetro IN indica que el valor pasado a la función no cambia durante la ejecución de la función; la marca OUT indica que un valor se calcula en la función y se pasa a la declaración de llamada a través del parámetro; la marca IN OUT indica que el valor pasado a la función se puede cambiar y pasar a la declaración de llamada. Si se omite el indicador, el parámetro está implícitamente IN. Debido a que la función espera un valor de retorno, RETURN contiene el tipo de datos del resultado devuelto.
create or replace function get_salary(
dep_id cux.employee.department_id%type (default 1235),
emp_count out number)
return number
is
v_sum number;
begin
select sum(salary), count(*) into v_sum, emp_count
from cux.employee
where department_id = dep_id;
return v_sum;
exception
when no_data_found then
DBMS_OUTPUT.PUT_LINE('查询的数据不存在');
when others then
DBMS_OUTPUT.PUT_LINE(sqlcode || '--' || sqlerrm);
end;
Proceso de llamada de función:
1. Representación del cargo;
declare
v_num number;
v_sum number;
begin
v_sum := get_salary(1237, v_num);
DBMS_OUTPUT.PUT_LINE('1237号部门的工资总和:' || v_sum || ' 人数:' || v_num);
end;
2. Notación de nombre
El parámetro formal debe tener el mismo nombre que el parámetro formal declarado cuando se define la función, y el orden se puede organizar en cualquier orden.
v_sum := get_salary(dep_id => 1237, emp_count => v_num);
3. Representación híbrida
Los argumentos pasados utilizando notación posicional deben preceder a los argumentos pasados en notación nombrada. Es decir, no importa cuántos parámetros tenga la función, siempre que uno de los parámetros use notación de nombre, todos los parámetros posteriores deben usar notación de nombre.
v_sum := get_salary(1237, emp_count => v_num);
Ocho: Paquete
1. Creación de paquetes
create or replace package demo_pack is
-- Author : 11313321
-- Created : 2023/8/22 8:45:06
-- Purpose : 练习测试
-- Public type declarations
EmpRec cux.employee%ROWTYPE;
-- Public function and procedure declarations
function add_emp(
last_name VARCHAR2, dept_id number, emp_id NUMBER, salary number)
return number;
function remove_emp(emp_id number)
return number;
procedure query_empl(emp_id number);
end demo_pack;
El método de creación del cuerpo del paquete, que implementa la definición del paquete declarada anteriormente:
create or replace package body demo_pack is
function add_emp(last_name VARCHAR2, dept_id number, emp_id NUMBER, salary number)
return number
is
empno_remaining exception;
pragma exception_init(empno_remaining, -1);
begin
insert into cux.employee values(last_name, dept_id, emp_id, salary,TO_DATE('2023,5,20','yyyy-mm-dd'));
if sql%found then
return 1;
end if;
exception
when empno_remaining then
return 0;
when others then
return -1;
end add_emp;
function remove_emp(emp_id number)
return number
is
begin
delete from cux.employee where employee_id = emp_id;
if sql%found then
return 1;
else
return 0;
end if;
exception
when others then
return -1;
end remove_emp;
procedure query_empl(emp_id number)
is
begin
select * into EmpRec from cux.employee where employee_id = emp_id;
exception
when no_data_found then
DBMS_OUTPUT.PUT_LINE('数据库中没有该员工');
when too_many_rows then
DBMS_OUTPUT.PUT_LINE('程序运行错误!请使用游标');
when others then
DBMS_OUTPUT.PUT_LINE(sqlcode || '--' || sqlerrm);
end query_empl;
begin
-- Initialization
null;
end demo_pack;
2. Llamada de paquete
El formato de llamada para elementos comunes en el paquete es: registro.nombre del elemento
declare
var number;
begin
var := demo_pack.add_emp('老马', 1476, 789, 3800);
if var=-1 then
DBMS_OUTPUT.PUT_LINE(sqlcode || '--' || sqlerrm);
elsif var=0 then
DBMS_OUTPUT.PUT_LINE('该记录已存在');
else
DBMS_OUTPUT.PUT_LINE('添加记录成功');
demo_pack.query_empl(789);
DBMS_OUTPUT.PUT_LINE(demo_pack.EmpRec.employee_id||'--'||
demo_pack.EmpRec.last_name||'--'||demo_pack.EmpRec.department_id);
var := demo_pack.remove_emp(788);
if var=-1 then
DBMS_OUTPUT.PUT_LINE(sqlcode || '--' || sqlerrm);
elsif var=0 then
DBMS_OUTPUT.PUT_LINE('该记录不存在');
else
DBMS_OUTPUT.PUT_LINE('删除记录成功');
end if;
end if;
end;
Nueve: gatillo
1. La composición del desencadenante.
- Evento desencadenante: en qué circunstancias se activa el DISPARADOR, por ejemplo: INSERTAR, ACTUALIZAR, ELIMINAR
- Tiempo de disparo: antes del disparo (ANTES), después (DESPUÉS)
- El desencadenante en sí: propósito e intención después del desencadenante
- Frecuencia de activación: activadores a nivel de declaración (STATEMENT) y activadores a nivel de fila (ROW).
- Nivel de declaración: cuando se activa un evento, el activador se ejecuta solo una vez
- Nivel de fila: cuando ocurre un evento, el disparador se ejecuta una vez por cada fila de datos afectados por la operación.
- La diferencia entre un disparador de fila y un disparador de declaración es la siguiente: un disparador de fila requiere que cuando una operación de declaración DML afecta varias filas de datos en la base de datos, para cada una de las filas de datos, siempre que cumplan con las restricciones del disparador, se El disparador está activado El disparador de declaración toma toda la operación de declaración como un evento desencadenante y lo activa una vez cuando cumple las condiciones de restricción.
2. gramática
CREATE [OR REPLACE] TRIGGER trigger_name
{BEFORE | AFTER}
{INSERT|DELETE|UPDATE[OF column[,column...]]}
ON [schema.] table_name
[FOR EACH ROW]
[WHEN condition]
trigger body;
La opción PARA CADA FILA indica que el disparador es un disparador de varias filas. Cuando se omite la opción PARA CADA FILA, los activadores ANTES y DESPUÉS son activadores de declaración, y los activadores EN LUGAR DE son activadores de fila.
3. Limitaciones de los desencadenantes
- La instrucción SELECT en el cuerpo del disparador solo puede ser una estructura SELECT...INTO... o una instrucción SELECT utilizada para definir un cursor.
- La declaración de control de transacciones de la base de datos COMMIT; ROLLBACK; SAVEPOINT no se puede utilizar en el desencadenador.
- Los procedimientos o funciones llamados por desencadenadores tampoco pueden utilizar declaraciones de control de transacciones de la base de datos.
Cuando se activa el disparador, use el valor de la columna en el registro que se insertó, actualizó o eliminó y, a veces, use el valor de la columna antes y después de la operación.
- El modificador :NEW accede al valor de la columna una vez completada la operación.
- El modificador :OLD accede al valor de la columna antes de que se complete la operación.
4. Ejemplos
--创建表
create table cux.emp_his as
select * from cux.employee
where 1 = 2;
--创建触发器
create or replace trigger del_emp_trigger
before delete on cux.employee for each row
begin
insert into cux.emp_his(last_name, department_id, employee_id, salary)
values(:old.last_name, :old.department_id, :old.employee_id, :old.salary);
end;
5. Cree un disparador EN LUGAR DE
CREATE [OR REPLACE] TRIGGER trigger_name
INSTEAD OF
{INSERT | DELETE | UPDATE [OF column [, column …]]}
ON [schema.] view_name
[FOR EACH ROW ]
[WHEN condition]
trigger_body;
EN LUGAR DE se utiliza para activadores DML en vistas.