KITTI 데이터 세트 소개
기본적인 정보
KITTI독일 카를스루에 공과대학과 토요타 시카고 연구소의 오픈소스 데이터세트로, Year Month2012 호에 최초로 공개됐다.0320
해당 논문 Are we Ready for Autonomous Driving?The KITTI Vision Benchmark Suite가 에 게재되었습니다 CVPR2012.
KITTI데이터 세트는 독일 카를스루 에에서 수집되었으며 도시/교외/고속도로 등의 교통 장면을 포함합니다. 년, 월2011 , 월 일 동안 수집됩니다 .0926/28/29/301003
KITTI데이터 수집에 사용되는 플랫폼은 아래 그림과 같습니다.

위의 플랫폼에는 다음이 포함됩니다.
- 140만 화소 흑백 카메라 2개
- 140만 화소 컬러 카메라 2개
- 4 에드몬드 옵틱스
- 1 x 64라인 Velodyne 3D 레이저 스캐너
- 1 OXTS RT3003 관성 항법 시스템
위 그림에서 알 수 있듯이
- 카메라의 좌표계에서는 Z축이 앞을 향하고, Y축이 아래를 향하고 있으며, 전체 좌표계는 오른손잡이 좌표계입니다.
- 라이더의 X축은 정면을 향하고, Z축은 수직 위쪽을 향하며, Y축은 오른손 법칙에 따라 결정됩니다.
IMU/GPS시스템의 좌표계 방향은 LiDAR의 방향과 일치합니다.
정리하자면, KITTI데이터 세트는 4카메라, 1라이더, 관성항법 1시스템 으로 구성되어 있는데 IMU/GPS, 우리가 명확히 하고 싶은 것은 6센서 .
센서의 크기 매개변수는 아래 그림을 참조하십시오.

각 센서에 해당하는 수집 데이터 폴더가 [date]-drive-sync-[sqquence]디렉터리에 저장됩니다 .6
- image00
- image01
- image02
- image03
- oxts
- velodyne-points
-
Timestamp
velodyne-points폴더 아래에 3개의 타임스탬프 파일이 있습니다 .timestamps_start.txt, 레이저 스캐너가 일주일 동안 스캔을 시작하는 시간timestamps_end.txt, 레이저 스캐너가 일주일 동안 스캔하는 시간이 끝나는 시간timestamps.txt레이저가 전방을 스캔하여 카메라를 작동시켜 사진을 찍는 시간입니다.
-
이미지 데이터
- 후드와 하늘을 자른 후의 이미지입니다.
- 이미지는 왜곡 제거 후의 데이터입니다.
-
OSTX 데이터 , 각 프레임은 위도, 경도/속도/가속도를 포함한
30다양한 필드 값을 저장합니다. -
레이더 데이터
x,y,z부동 소수점 숫자의 이진 파일, 각 점은 4개의 부동 소수점 숫자, 레이더 좌표계의 좌표, 레이저의 반사 강도로 구성됩니다.r- 각 스캔에 대해 대략적인
120000포인트가 획득됩니다3D. - 라이더는 수직축을 중심으로 시계 반대 방향으로 회전합니다.
센서 교정 및 시간 동기화
전체 시스템은 LiDAR가 하나의 프레임으로 한 번 회전하도록 하며, LiDAR가 특정 위치로 회전하면 카메라가 트리거링되어 스프링 플레이트의 물리적 접촉을 통해 사진을 촬영합니다. 이 트리거링 방법으로는 데이터를 수집할 수 없지만 빈도는 데이터 수집 수가 에 도달 IMU하면 수집된 데이터의 타임 스탬프를 기록하고 카메라 수집 시간에 가장 가까운 데이터를 현재 프레임의 데이터로 선택하며 최대 시간 오류는 입니다 .IMU100HZIMU5ms
카메라 보정 , 카메라 내부 및 외부 매개변수 보정 방법은 단일 샷을 사용하여 범위 및 카메라 센서를 자동 보정하기 위한 도구 상자
입니다 . 모든 카메라 중심이 정렬됩니다. 즉, 모두 동일한 XY평면에 있으므로 이미지 보정에 편리합니다. (하늘과 후드 제거)
매일 데이터 수집을 시작하기 전에 전체 데이터 수집 시스템을 교정하여 센서 간의 위치 편차를 방지합니다.
daily date_calib.zip폴더 아래에는 3개의 텍스트 파일이 있고,
-
calib_cam_to_cam.txt

마지막 3개의 매개변수 값에 대한 설명에 따르면 sdirect ( i ) s^{(i)}_{lect}에스Rect _( 나는 )수정 후(중복된 하늘과 후드 제거) 이미지의 크기를 나타냅니다. R ect ( i ) \bold{R}^{(i)}_{lect}아르 자형Rect _( 나는 )수정에 사용되는 회전 행렬입니다. P ret ( i ) \bold{P}^{(i)}_{lect}피Rect _( 나는 )교정에 사용되는 투영 행렬입니다. 나는 ∈ { 0 , 1 , 2 , 3 } i\in\{0,1,2,3\}나∈{ 0 ,1 ,2 ,3 }은 카메라의 일련 번호를 나타내고, 0은 왼쪽 회색조 카메라, 1은 오른쪽 회색조 카메라, 2는 왼쪽 컬러 카메라, 3은 오른쪽 컬러 카메라를 나타냅니다. 왼쪽의 회색조 카메라 0은 참조 카메라 좌표계로 사용되며,3D점x = ( x , y , z , 1 ) \bold{x}=(x,y,z,1)엑스=( 엑스 ,y ,z ,1 ) , 번째i카메라 이미지로 변환하기 위해 다음 관계를 사용할 수 있습니다.y = Prect ( i ) R ect ( 0 ) x \bold{y}=\bold{P}^{(i)}_{ret }\bold{R}^{(0)}_{직사각형}\bold{x}와이=피Rect _( 나는 )아르 자형Rect _( 0 )엑스 -
calib_velo_to_cam.txt,KITTI데이터 세트 LiDAR는 왼쪽 회색조 카메라 0, 레이저에서 카메라까지의 회전 행렬 R velocam \bold{R}^{cam}_{velo} 를 기준으로 보정됩니다.아르 자형v e l o오전 _및 번역 벡터 tvelocam \bold{t}^{cam}_{velo}티v e l o오전 _동종 변환 행렬은 다음과 같이 작성할 수 있습니다.
T velocam = ( R velocamtvelocam 0 1 ) \bold{T}^{cam}_{velo}=\begin{pmatrix}R^{cam}_{velo} &t^ {cam }_{velo} \\0 &1\end{pmatrix}티v e l o오전 _=(아르 자형v e l o오전 _0티v e l o오전 _1)
이런 식으로 레이더 좌표계의 점을ii3D로i 카메라 좌표계의 공식은 다음과 같습니다. y = Prect ( i ) R ect ( 0 ) T velocamx \bold{y}=\bold{P}^{(i)}_{ect}\bold{R }^{ (0)}_{직사각형}\bold{T}^{캠}_{velo}\bold{x}와이=피Rect _( 나는 )아르 자형Rect _( 0 )티v e l o오전 _엑스 -
calib_imu_to_velo.txt, 이 파일은 좌표계에서 레이저 좌표계로imu균질 변환 행렬 T imuvelo \bold{T}_{imu}^{velo} 를 저장합니다.티나는 너야v e l o, 따라서IMU좌표계의 점을 번째 이미지의 픽셀 좌표3D로 변환하는 공식은 다음과 같이 작성할 수 있습니다 . P }^{(i)}_{직류}\bold{R}^{(0)}_{직류}\bold{T}^{cam}_{velo}\bold{T}_{imu}^ { 벨로}\bold{x}i
와이=피Rect _( 나는 )아르 자형Rect _( 0 )티v e l o오전 _티나는 너야v e l o엑스
3D 객체 감지용
초기 데이터 세트에서 지원되는 작업은 쌍안경, 광학 흐름 및 주행 거리 측정입니다. 이후 깊이 추정, 2D 타겟 탐지, 3D 타겟 탐지, BEV 타겟 탐지, 의미론적 분할, 인스턴스 분할, 다중 타겟 추적 등의 작업이 순차적으로 지원되었습니다.
표적 탐지에는 8가지 범주가 정의됩니다.
Car/Van/Truck/Pedestrian/Person_sitting/Cyclist/Tram/Misc(其他)。
3D 객체의 라벨링은 LiDAR 좌표계에서 수행되지만 이제 3D 타겟 감지는 감지 프레임 중심점의 xyz 좌표, 감지 프레임의 길이/너비/높이로만 구성된다는 점은 주목할 가치가 있습니다. 그리고 검출 프레임의 편차 항법 각도 요는 7 자유도로 구성됩니다 .

그러나 모호성을 쉽게 유발할 수 있는 질문도 있는데, length/width/height그것은 어느 축 xyz에 해당하는가? length아래 그림을 보면 해당 dx, width해당 dy, height해당을 알 수 있습니다 dz. 전체 3D상자는 LiDAR 좌표계로 표시됩니다.

KITTI 3D객체 감지 데이터 세트에는 7481Zhang 훈련 데이터와 7518Zhang 테스트 데이터가 포함됩니다. KITTI데이터 세트에는 표시된 8개체가 포함되어 있지만 Car/Pedestrian표시된 개체만으로 충분하며 KITTI공식적으로 알고리즘을 평가하는 데 사용됩니다 .BenchMark KITTI에는 3가지 유형의 탐지 상자가 있습니다 .3DCar/Pedestrian/Cyclist
다운로드한 3D표적 탐지 데이터 세트에 포함된 폴더는 다음과 같습니다.
image_02, 왼쪽 눈의png컬러 형식 이미지label_02, 왼쪽 눈 컬러 영상에 주석이 달린 객체 라벨calib, 센서 간의 좌표 변환 관계velodyne, 레이저 포인트 클라우드 데이터plane, 레이저 좌표계에서 노면의 평면 방정식
레이블 파일의 각 줄 내용은 다음과 같습니다.
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
포함된 필드는 다음과 같습니다.
type대상 유형(예:Car/Van..., 1개 필드)truncated부동 소수점 숫자 0-1, 카메라 시야를 벗어나는 대상 객체의 비율, 1 필드occluded정수0,1,2,3,0:모두 표시됨,1:부분적으로 가려짐,2:대부분 가려지지 않음,3:알 수 없음, 필드 1개alpha, 물체의 관찰 각도, 1 필드 [ − π , π ] [-\pi, \pi][ − π ,피 ]bbox,2D감지 프레임의 픽셀 좌표,x1,y1,x2,y2, 4 필드dimensions,3D물체의 크기,height,width,length, 단위는米, 3개 필드location,3D카메라 좌표계에서 물체의 중심 좌표xyz, 단위는mrotation_y,yaw각도, 요 각도, [ − π , π ] [-\pi, \pi][ − π ,피 ]scoreROC, 곡선을 계산하는 데 사용되는 대상 개체의 점수 또는MAP.
카메라 좌표계의 점은 의 calib변환 행렬을 통해 이미지 픽셀 좌표로 변환될 수 있습니다.
rotation_y와 alpha의 차이점은 alpha측정값이 카메라 중심에서 개체 중심까지의 각도라는 것입니다. 카메라 좌표계 축을 기준으로 개체의 회전 각도를 rotation_y측정합니다 . 자동차를 예로 들면, 자동차가 카메라 좌표계 축 방향 에 위치할 때 자동차가 평면의 어느 위치에 있든 각도는 0입니다. 각도는 자동차가 카메라 좌표계의 아래쪽 축에 있을 때만 각도 가 0이고, 축에서 벗어나면 각도가 0이 아닙니다.yyawxrotation_yx,zalphazalphazalpha
레이저 포인트 클라우드를 왼쪽 눈 컬러 이미지에 투영하는 데 사용할 수 있는 공식은 다음과 같습니다 X=P2*R0_rect*Tr_vel_to_cam*Y.
R0_rect는 3x3보정 행렬 이고 는 레이더를 카메라 좌표계로 변환하는 변환 행렬 Tr_vel_to_cam입니다 .3x4
코드 전투
다음을 사용하여 open3d포인트 클라우드 읽기
import numpy as np
import struct
import open3d as o3d
def convert_kitti_bin_to_pcd(binFilePath):
size_float = 4
list_pcd = []
with open(binFilePath, "rb") as f:
byte = f.read(size_float * 4)
print(byte)
while byte:
x, y, z, intensity = struct.unpack("ffff", byte)
list_pcd.append([x, y, z])
byte = f.read(size_float * 4)
np_pcd = np.asarray(list_pcd)
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(np_pcd)
return pcd
bs = "/xx/xx/data/code/mmdetection3d/demo/data/kitti/000008.bin"
pcds = convert_kitti_bin_to_pcd(bs)
o3d.visualization.draw_geometries([pcds])
# save
o3d.io.write_point_cloud('000008.pcd', pcds, write_ascii=False, compressed=False, print_progress=False)
독서를 통해 numpy,
def load_bin(bin_file):
data = np.fromfile(bin_file, np.float32).reshape((-1, 4))
data = data[:, :-1]
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(data)
return pcd
위의 코드는 포인트 클라우드 데이터를 읽고 시각화할 수 있으며 이를 pcd형식화된 포인트 클라우드로 저장할 수 있습니다.
선택된 3D표적 탐지 작업 데이터 세트 training/image_02/000008.png,
해당 태그 파일 000008.txt,
Car 0.88 3 -0.69 0.00 192.37 402.31 374.00 1.60 1.57 3.23 -2.70 1.74 3.68 -1.29
Car 0.00 1 2.04 334.85 178.94 624.50 372.04 1.57 1.50 3.68 -1.17 1.65 7.86 1.90
Car 0.34 3 -1.84 937.29 197.39 1241.00 374.00 1.39 1.44 3.08 3.81 1.64 6.15 -1.31
Car 0.00 1 -1.33 597.59 176.18 720.90 261.14 1.47 1.60 3.66 1.07 1.55 14.44 -1.25
Car 0.00 0 1.74 741.18 168.83 792.25 208.43 1.70 1.63 4.08 7.24 1.55 33.20 1.95
Car 0.00 0 -1.65 884.52 178.31 956.41 240.18 1.59 1.59 2.47 8.48 1.75 19.96 -1.25
000008.png위와 같이 그려보세요 .
import cv2
img = cv2.imread(img_s)
with open(label_s) as f:
lines = f.read().split("\n")[:-1]
for item in lines:
boxes = item.split()[4:8]
boxes = [float(x) for x in boxes]
bb = np.array(boxes, dtype=np.int32)
cv2.rectangle(img, bb[:2], bb[-2:], (0,0,255), 1)
cv2.imwrite("/xx/xx/data/code/mmdetection3d/demo/data/kitti/08_res.png", img)

왼쪽 하단에 있는 두 개의 감지 상자를 보면 가장자리가 잘 표시되지 않습니다.
해당 포인트 클라우드 데이터는 다음과 같습니다.
KITTI3D 객체 감지 데이터 라벨이 제공하는 중심점 좌표는 3D왼쪽 눈 컬러 카메라 좌표계입니다.
시각적 감지 프레임을 사용하기 위한 코드는 Open3D다음과 같다.
"""
from https://github.com/dtczhl/dtc-KITTI-For-
Beginners.git
"""
import matplotlib.pyplot as plt
import matplotlib.image as mping
import numpy as np
import os
import open3d as o3d
import open3d.visualization as o3d_vis
from shapely.geometry import Point
from shapely.geometry.polygon import Polygon
MARKER_COLOR = {
'Car': [1, 0, 0], # red
'DontCare': [0, 0, 0], # black
'Pedestrian': [0, 0, 1], # blue
'Van': [1, 1, 0], # yellow
'Cyclist': [1, 0, 1], # magenta
'Truck': [0, 1, 1], # cyan
'Misc': [0.5, 0, 0], # maroon
'Tram': [0, 0.5, 0], # green
'Person_sitting': [0, 0, 0.5]} # navy
# image border width
BOX_BORDER_WIDTH = 5
# point size
POINT_SIZE = 0.005
def show_object_in_image(img_filename, label_filename):
img = mping.imread(img_filename)
with open(label_filename) as f_label:
lines = f_label.readlines()
for line in lines:
line = line.strip('\n').split()
left_pixel, top_pixel, right_pixel, bottom_pixel = [int(float(line[i])) for i in range(4, 8)]
box_border_color = MARKER_COLOR[line[0]]
for i in range(BOX_BORDER_WIDTH):
img[top_pixel+i, left_pixel:right_pixel, :] = box_border_color
img[bottom_pixel-i, left_pixel:right_pixel, :] = box_border_color
img[top_pixel:bottom_pixel, left_pixel+i, :] = box_border_color
img[top_pixel:bottom_pixel, right_pixel-i, :] = box_border_color
plt.imshow(img)
plt.show()
def show_object_in_point_cloud(point_cloud_filename, label_filename, calib_filename):
pc_data = np.fromfile(point_cloud_filename, '<f4') # little-endian float32
pc_data = np.reshape(pc_data, (-1, 4))
cloud = o3d.geometry.PointCloud()
cloud.points = o3d.utility.Vector3dVector(pc_data[:,:-1])
pc_color = np.ones((len(pc_data), 3))
calib = load_kitti_calib(calib_filename)
rot_axis = 2
with open(label_filename) as f_label:
lines = f_label.readlines()
bboxes_3d = []
for line in lines:
line = line.strip('\n').split()
point_color = MARKER_COLOR[line[0]]
veloc, dims, rz, box3d_corner = camera_coordinate_to_point_cloud(line[8:15], calib['Tr_velo_to_cam'])
bboxes_3d.append(np.concatenate((veloc, dims, np.array([rz]))))
bboxes_3d = np.array(bboxes_3d)
print(bboxes_3d.shape)
lines = []
for i in range(len(bboxes_3d)):
center = bboxes_3d[i, 0:3]
dim = bboxes_3d[i, 3:6]
yaw = np.zeros(3)
yaw[rot_axis] = bboxes_3d[i, 6]
rot_mat = o3d.geometry.get_rotation_matrix_from_xyz(yaw)
# bottom center to gravity center
center[rot_axis] += dim[rot_axis] / 2
box3d = o3d.geometry.OrientedBoundingBox(center, rot_mat, dim)
line_set = o3d.geometry.LineSet.create_from_oriented_bounding_box(
box3d)
line_set.paint_uniform_color(np.array(point_color) / 255.)
lines.append(line_set)
for i, v in enumerate(pc_data):
if point_in_cube(v[:3], box3d_corner) is True:
pc_color[i, :] = point_color
cloud.colors = o3d.utility.Vector3dVector(pc_color)
o3d_vis.draw([*lines, cloud])
def point_in_cube(point, cube):
z_min = np.amin(cube[:, 2], 0)
z_max = np.amax(cube[:, 2], 0)
if point[2] > z_max or point[2] < z_min:
return False
point = Point(point[:2])
polygon = Polygon(cube[:4, :2])
return polygon.contains(point)
def load_kitti_calib(calib_file):
"""
This script is copied from https://github.com/AI-liu/Complex-YOLO
"""
with open(calib_file) as f_calib:
lines = f_calib.readlines()
P0 = np.array(lines[0].strip('\n').split()[1:], dtype=np.float32)
P1 = np.array(lines[1].strip('\n').split()[1:], dtype=np.float32)
P2 = np.array(lines[2].strip('\n').split()[1:], dtype=np.float32)
P3 = np.array(lines[3].strip('\n').split()[1:], dtype=np.float32)
R0_rect = np.array(lines[4].strip('\n').split()[1:], dtype=np.float32)
Tr_velo_to_cam = np.array(lines[5].strip('\n').split()[1:], dtype=np.float32)
Tr_imu_to_velo = np.array(lines[6].strip('\n').split()[1:], dtype=np.float32)
return {
'P0': P0, 'P1': P1, 'P2': P2, 'P3': P3, 'R0_rect': R0_rect,
'Tr_velo_to_cam': Tr_velo_to_cam.reshape(3, 4),
'Tr_imu_to_velo': Tr_imu_to_velo}
def camera_coordinate_to_point_cloud(box3d, Tr):
"""
This script is copied from https://github.com/AI-liu/Complex-YOLO
"""
def project_cam2velo(cam, Tr):
T = np.zeros([4, 4], dtype=np.float32)
T[:3, :] = Tr
T[3, 3] = 1
T_inv = np.linalg.inv(T)
lidar_loc_ = np.dot(T_inv, cam)
lidar_loc = lidar_loc_[:3]
return lidar_loc.reshape(1, 3)
def ry_to_rz(ry):
angle = -ry - np.pi / 2
if angle >= np.pi:
angle -= np.pi
if angle < -np.pi:
angle = 2 * np.pi + angle
return angle
h, w, l, tx, ty, tz, ry = [float(i) for i in box3d]
cam = np.ones([4, 1])
cam[0] = tx
cam[1] = ty
cam[2] = tz
t_lidar = project_cam2velo(cam, Tr)
Box = np.array([[-l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2],
[w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2],
[0, 0, 0, 0, h, h, h, h]])
rz = ry_to_rz(ry)
rotMat = np.array([
[np.cos(rz), -np.sin(rz), 0.0],
[np.sin(rz), np.cos(rz), 0.0],
[0.0, 0.0, 1.0]])
velo_box = np.dot(rotMat, Box)
cornerPosInVelo = velo_box + np.tile(t_lidar, (8, 1)).T
box3d_corner = cornerPosInVelo.transpose()
dims = np.array([l, w, h])
# t_lidar: the x, y coordinator of the center of the object
# box3d_corner: the 8 corners
print(t_lidar.shape)
return t_lidar.reshape(-1), dims, rz, box3d_corner.astype(np.float32)
if __name__ == '__main__':
# updates
ROOT = "/media/lx/data/code/mmdetection3d/demo/data/kitti"
IMG_DIR = f'{
ROOT}/image_2'
LABEL_DIR = f'{
ROOT}/label_2'
POINT_CLOUD_DIR = f'{
ROOT}/velo'
CALIB_DIR = f'{
ROOT}/calib'
# id for viewing
file_id = 8
img_filename = os.path.join(IMG_DIR, '{0:06d}.png'.format(file_id))
label_filename = os.path.join(LABEL_DIR, '{0:06d}.txt'.format(file_id))
pc_filename = os.path.join(POINT_CLOUD_DIR, '{0:06d}.bin'.format(file_id))
calib_filename = os.path.join(CALIB_DIR, '{0:06d}.txt'.format(file_id))
# show object in image
show_object_in_image(img_filename, label_filename)
# show object in point cloud
show_object_in_point_cloud(pc_filename, label_filename, calib_filename)
시각화된 결과는 다음과 같습니다.
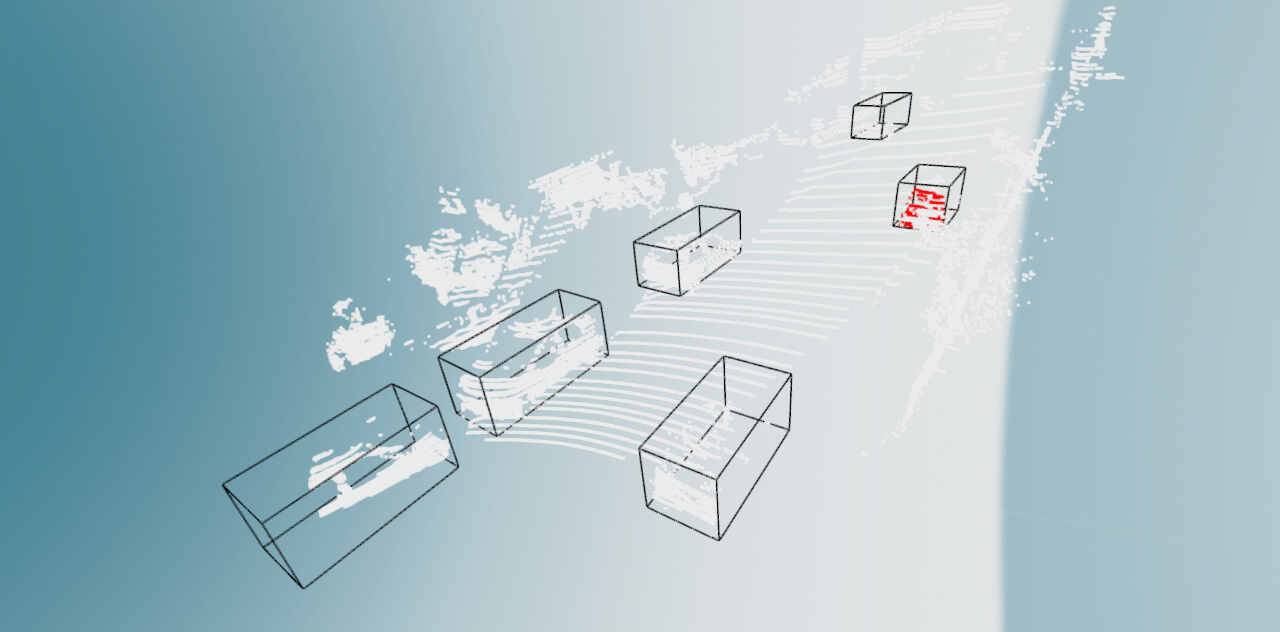
이상으로 KITTI데이터 세트가 3D표적 탐지 작업에 사용되는 상황에 대한 기본적인 이해를 가질 수 있으며, 나중에 다중 양식을 사용할 때 2D탐지 프레임을 결합하여 표적을 식별하고 위치를 찾는 방법을 추가하게 됩니다.