この記事に興味があり、AI 分野の実践的なスキルについて詳しく知りたい場合は、「Technology Craze AI」公開アカウントに注目してください。ここでは、AIGC 分野の最新かつ最もホットな乾物に関する記事や事例チュートリアルをご覧いただけます。
I.はじめに
今日のデジタル時代において、大規模言語モデル (LLM) の開発は飛躍的に進んでおり、国内外で出現している大規模言語モデル (LLM) は、百輪の花と表現できます。オープンソースであろうとクローズドソースであろうと、優れたモデルは存在しますが、LLM を使用すると、アプリケーション開発中に、デプロイメント、トレーニング、微調整、API インターフェイス開発、プロンプトのプロンプトの点で、各モデルに多かれ少なかれ違いがあることがわかります。製品を別の LLM に接続する必要がある場合、またはすぐに切り替える必要がある場合 モデルがより複雑になると、使用があまり便利でなくなり、保守も容易ではなくなります。しかし、LLM は大きな進歩を遂げましたが、非常に多くの LLM に直面することで、開発者に大きな課題がもたらされています。これらの LLM モデルを呼び出すときは、大量の API インターフェイス ドキュメントを参照し、デバッグ用のテスト コードを記述する必要があります。 API 呼び出しが正しくありません。この問題を解決するために、Gorilla LLM が登場しました。これは、大規模な言語モデルを、API を通じて提供されるさまざまなサービスやアプリケーションに接続するために設計された、LLaMA ベースの微調整モデルです。
Gorilla LLM の登場により、従来の手法の欠点が補われ、API 呼び出しの記述において GPT-4 よりも優れたパフォーマンスを発揮し、テスト中のドキュメントの変更に適応できるため、柔軟な API の更新やバージョン変更が可能になります。さらに、Gorilla は、LLM を直接プロンプトするときによくある幻覚の問題を効果的に解決します。HuggingFace、TorchHub、TensorHub API で構成される包括的なデータセットである APIBench を導入することで、Gorilla LLM のパフォーマンスを評価できます。検索システムと Gorilla の統合に成功した後、LLM はツールをより正確に使用し、頻繁に更新されるドキュメントを常に把握できるようになり、その出力の信頼性と適用性が向上します。
以前紹介した「EasyLLM: 言語モデルの処理を簡素化し、OpenAI と Hugging Face クライアント間のシームレスな切り替えを実現する」 では、主に LLM の処理プロセスを簡素化し、改善することが目的です。互換性のあるクライアント API が提供されているため、ユーザーは 1 行のコードを変更するだけで、異なる LLM を簡単に切り替えることができます。その後、接続されるモデルの数が増えても、開発量自体は減りません。EasyLLM は API インターフェイスを継続的に拡張する必要があり、Gorilla LLM は、大規模な言語モデルを使用して ML API インターフェイスとドキュメントをトレーニングおよび学習することで、一歩近づいています。自然言語に基づいてインターフェイスとパラメータを自動的に識別して照合します。開発者の効率が大幅に向上すると同時に、Gorilla LLM を使用して会社の製品のインターフェイスをトレーニングし、製品の対話方法をさらにアップグレードし、自然言語を直接使用してインターフェイス呼び出しとシステム間のハードウェア対話を実現することもできます。
次に、Gorilla LLM の基本概念、そのパフォーマンス上の利点、実際のアプリケーションでの動作について詳しく紹介します。Gorilla LLM が開発者、研究者、ユーザーに、よりスマートで便利な API 呼び出しエクスペリエンスをどのように提供できるかを見てみましょう。
2. Gorilla LLM の基本的な紹介
Gorilla LLM は、自然言語クエリを解釈することで1,600 以上の API を理解し、正確に呼び出すように設計された高度な大規模言語モデル (LLM) です。自己志向型の検索手法を使用して、重複し進化する機能を持つツールを選択して活用します。Gorilla は包括的な APIBench データセットを使用して評価され、API 呼び出しの生成において GPT-4 のパフォーマンスを上回っています。
Gorilla LLM は、API 接続された大規模言語モデル (LLM) です。特定の自然言語の質問に対して、正しい入力パラメーターを含む正しい API 呼び出しを構築するために、広範な API ドキュメントに基づいてトレーニングされています。Gorilla は、以前の API 呼び出し手法よりも正確で、誤った API 呼び出しの幻覚が発生する可能性が低くなります。Gorilla は、操作の自動化や API を使用したアプリケーションの構築を検討している開発者にとって便利なツールです。同時に、自然言語処理での API の使用に興味のある研究者もそれを利用できます。
Gorilla LLM は、カリフォルニア大学バークレー校とマイクロソフトの研究者によって開発されました。API 呼び出し用に設計されており、自然言語クエリに応じて意味的および構文的に正しい API 呼び出しを生成できます。たとえば、Gorilla に「北京の天気を取得して」と頼むと、OpenWeatherMap API への呼び出しが生成され、サンフランシスコの現在の気象状況を取得します。
Gorilla LLM は、Torch Hub、TensorFlow Hub、HuggingFaceなどの大規模な機械学習ハブ データセットでトレーニングされています。Kubernetes、GCP、AWS、OpenAPIなどの新しい領域が急速に追加されています。Gorilla はGPT-4、Chat-GPT、Claudeよりも優れたパフォーマンスを発揮し、幻覚エラーが大幅に減少した信頼性を備えています。
最後に、Gorilla LLM は、MPTおよびFalconで微調整されたApache 2.0 ライセンスに基づいてライセンスされているため、Gorilla を商用目的で何の義務もなく使用できます。
2.1. 主な特徴
Gorilla LLM には次の主要な機能があります。
-
自然言語クエリを使用して 1,600 以上の API を正確に呼び出す: Gorilla LLM は、自然言語クエリを使用して 1,600 以上の API を正確に呼び出すことができます。これは、開発者が各 API のドキュメントや詳細を詳しく調べなくても、自然言語を使用してニーズを説明できることを意味します。
-
LLM で幻覚を軽減する: Gorilla LLM は、幻覚エラーに対して特に最適化されています。幻覚バグとは、間違った API または存在しない API を使用して生成されたコードです。幻覚エラーを減らすことで、Gorilla LLM はより信頼性が高く正確な API 呼び出しを提供できます。
-
ユーザーフレンドリーでさまざまなニーズやツールに適応: Gorilla LLM は、さまざまなニーズやツールに適応できるようにユーザーフレンドリーで柔軟に設計されています。ユーザーの要件や環境に応じてカスタマイズでき、さまざまな開発シナリオに適したソリューションを提供します。
-
オープンソースとコミュニティへの貢献を通じて継続的に進化する: Gorilla LLM は、コミュニティへの貢献を通じて継続的に進化および改善されるオープンソース プロジェクトです。これは、開発者がプロジェクトに参加し、一緒に開発を推進し、コミュニティからサポートやフィードバックを受けることができることを意味します。
-
他のツールとの統合: Gorilla LLM は、Langchain、ToolFormer、AutoGPT などの他の LLM ツールとシームレスに動作するように設計されています。適応性に優れており、さまざまなアプリケーションやツールチェーンに簡単に統合できるため、開発者により多くの選択肢と柔軟性が提供されます。
Gorilla LLM は、API を正確に呼び出すことで強力かつ柔軟な API 呼び出しを開発者に提供し、幻覚エラーを削減し、ユーザーフレンドリーでさまざまなニーズやツールに適応し、オープンソースでコミュニティの貢献を通じて継続的に進化し、他のツールとの統合ソリューションを生成します。
2.2. 応用シナリオ
Gorilla は次のシナリオに適用できます。
-
モバイル アプリケーション用の新しい API の作成: Gorilla を使用すると、開発者は LLM に正しいパラメータとコンテキストで新しい API を呼び出す方法を教え、それによってモバイル アプリケーション用の新しい機能とサービスを作成できます。
-
新しい機能をサポートするために既存の API を更新する: 新しい機能や変更を既存の API に追加する必要がある場合、Gorilla は、LLM に正しいパラメーターとコンテキストを教えることで、開発者が API 呼び出しを更新して新しい機能要件をサポートできるように支援します。
-
機能しない API 呼び出しのデバッグ: API 呼び出しで問題が発生した場合、Gorilla をデバッグ ツールとして使用できます。LLM に正しいパラメータとコンテキストを教えることで、開発者は機能しない API 呼び出しを分析して修正し、デバッグ効率を向上させることができます。
Gorilla は、新しい API の作成、新しい機能をサポートするための既存の API の更新、適切に動作しない API 呼び出しのデバッグなどのシナリオで役立ちます。LLM に正しいパラメータとコンテキストを教えることで、開発者が API 統合とデバッグ作業をより効率的に実行できるようにします。
2.3. 応用価値
LLM の応用価値は、API の統合とタスクの完了に関連する課題を解決することにあります。従来のソリューションは通常、ヒントベースであり、大規模で常に変化する API を処理できません。同時に、特定のタスクに適切な API とパラメータを見つけるのが難しい場合があります。これは特殊な API に限定されるものではなく、AWS、GCP、Azure などの一般的に使用されるサービスも含まれており、それぞれが多数の異なる入力パラメーターを備えた数千の API を提供しています。現在の回避策は、人間の専門家に頼るか、API ドキュメントやオンライン リソースの時間のかかる検索を必要とするため、複雑なアプリケーションを構築するプロセスが非効率的で管理が困難になります。
この問題を解決するためにゴリラが誕生しました。LLM に正しいパラメーターとコンテキストを使用して API 呼び出しを行う方法を教えることができれば、強力な LLM 駆動のアプリケーションを構築するために必要なすべてのツールを簡単に接続できると私たちは信じています。Gorilla の目標は、LLM とさまざまなツールを統合することで、より効率的で便利なアプリケーション開発を実現することです。
Gorilla のアプリケーション価値は次の側面に反映されています。
-
API 統合の問題を解決します。Gorilla は、LLM がさまざまな API と統合できるように支援します。これにより、LLM は正しい API を呼び出し、正しいパラメーターを渡すことができ、他のツールとの共同作業を実現できます。
-
開発効率の向上: Gorilla を使用すると、開発者は人間の専門家に頼ったり、API ドキュメントやオンライン リソースの時間のかかる検索に頼る必要がなくなり、特定のタスクに適した API やパラメータをより迅速に見つけることができるため、開発効率が向上します。
-
アプリケーション構築の簡素化: Gorilla の目標は、強力な LLM 駆動アプリケーションの構築に必要なツールの統合を簡素化することです。API 呼び出しのパラメーターとコンテキストを適切に使用するように LLM に教えることで、開発者はさまざまなツールを簡単に接続し、複雑なアプリケーションの構築を実現できます。
全体として、Gorilla は API 統合とタスク完了に関連する課題を解決することで、強力な LLM 駆動アプリケーションを構築するためのより効率的かつ便利な方法を提供します。同時に、Gorilla は、テキストの作成、言語の翻訳、クエリへの応答、さまざまな種類のクリエイティブ素材の作成、さまざまなソースからの情報へのアクセスと処理など、さまざまなタスクを実行するために使用できます。
2.4. Gorilla LLM の利点
Gorilla LLM には、以前の従来の方法に比べて次の利点があります。
-
精度の向上: Gorilla LLM は、以前のメソッドよりも API 呼び出しの精度が向上しました。これは、開発者が複雑なクエリであっても、Gorilla LLM が正しい API 呼び出しを作成し、コードの精度を向上させることを信頼できることを意味します。
-
幻覚エラーの削減: 幻覚エラーとは、間違った API または存在しない API を使用して生成されたコードを指します。これにより、実行時エラーやコードが機能しなくなる可能性があります。Gorilla LLM は、大量の API 呼び出し向けに特に微調整されており、幻覚エラーの可能性が軽減されます。
-
時間と労力の節約: Gorilla LLM は、開発者が時間と労力を大幅に節約するのに役立ちます。開発者は、API ドキュメントを手動で検索したり、API 呼び出しを生成するためのコードを作成したりする必要がなくなり、その代わりに、Gorilla LLM が特定の自然言語クエリに基づいて適切な API 呼び出しを生成できるため、開発者の時間と労力を節約できます。
-
信頼性の向上: Gorilla LLM は、開発者がより信頼性の高いコードを作成し、API 呼び出しのエラーを減らすのに役立ちます。開発者が API 呼び出しを生成するコードを作成する場合、間違いが発生する可能性があります。Gorilla LLM は、意味的および構文的に正しい API 呼び出しを生成することで、これらのエラーを削減し、コードの信頼性を向上させるのに役立ちます。
-
制約付き API の処理: API 呼び出しには固有の制限や制約があることが多く、LLM は API の機能を理解するだけでなく、さまざまな制約パラメーターに従って呼び出しを分類する必要があります。これにより複雑さが増し、LLM についてより微妙な理解が必要になります。Gorilla LLM は、パラメーター サイズや最小精度などの制約を処理するなど、制約のある API 呼び出しを処理できるため、より正確な結果が得られます。たとえば、「パラメーターが 1,000 万未満で、ImageNet の精度が少なくとも 70% である画像分類モデルを呼び出します」のようなプロンプトは、LLM の正確な解釈に大きな課題をもたらします。モデルは、ユーザーの説明と、リクエストに埋め込まれた制約に関する推論を理解する必要があります。
このモデルは、API 固有のヒントを使用して文書検索システムでクエリを実行すると、他の LLM よりも優れたパフォーマンスを発揮し、その出力の信頼性と適用性が向上します。以下の図は、そのような結果を示しています。
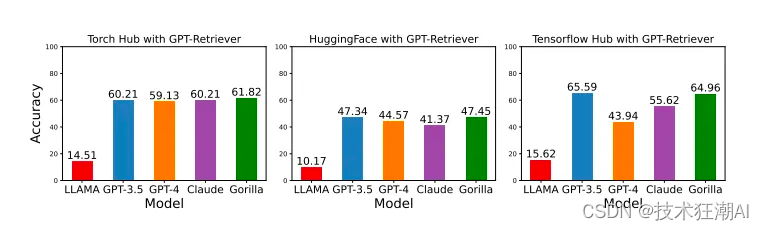
Gorilla LLM は、精度の向上、幻覚エラーの削減、時間と労力の節約、信頼性の向上、制約のある API の処理により、より効率的で正確かつ信頼性の高い API 呼び出しを生成する機能を開発者に提供します。
2.5. LLaMA に基づいて微調整する理由
現在、人気のあるオープンソース モデルは数多くありますが、Gorilla はなぜ他のモデルではなく LLaMA を選択したのでしょうか? 複数のモデルが微調整され、テストされていますか?
LLaMA が開始点として選ばれたのは、LLaMA がオープンソース LLM の主力であると考えられているためです。他の多くのモデルは、特定のアプリケーション向けに派生したものです。もちろん、Gorilla は GPT-4、GPT-3.5、および Claude-v1 を使用して Gorilla のベンチマークも行っています。オープンソース モデルの商用利用を考慮して、MPT-7B と Falcon-7B をベースにした 2 つのゴリラ モデルがその後リリースされました。Gorilla モデルは Apache 2.0 ライセンスを使用するようになりました。これは、Gorilla が制限なく商業的に使用できることを意味します。
2.6. ゴリラを訓練するための基本条件
公式の紹介によると、すべてのモデルのトレーニングと評価には 8 つのA100 40GB GPUノードが使用されています。モデルと API データセットに応じて、必要な時間は大きく異なる場合があります。最短の実行では合計約 10 GPU 時間、最長の実行では合計約 120 GPU 時間でした。トレーニング プロセスでは、最先端の計算技術(効率的な注意メカニズム)とメモリの最適化(シャーディング、チェックポイント、混合精度トレーニング)もすべて使用されます。LoRA は使用されておらず、すべての Gorilla モデルはエンドツーエンドで微調整されています。
3. ゴリラの基本原理
Gorilla LLM は、API ドキュメントとコードの膨大なデータセットでトレーニングされました。データセットには、Google Cloud Platform、Amazon Web Services、Microsoft Azure などのさまざまなプラットフォームからの API 呼び出しが含まれています。Gorilla は、このデータセットを使用して API 呼び出しの構文とセマンティクスを学習します。Gorilla に API 呼び出しの生成を依頼すると、まずデータセット内で一致する API 呼び出しを見つけようとします。一致する API 呼び出しが見つかった場合は、その呼び出しを単純に返します。一致する API 呼び出しが見つからない場合は、API の構文とセマンティクスの知識に基づいて新しい API 呼び出しを生成します。
以下は、Gorilla 接続 API プロセスに関係する主要な手順です。
-
ユーザー プロンプト: ユーザーは、API を使用して達成したい特定のタスクまたは目標を説明する自然言語プロンプトを提供します。
-
取得 (オプション) : 取得モードでは、Gorilla は BM25 や GPT-Index などのドキュメント取得ツールを使用して、データベースから最新の API ドキュメントを取得します。次に、ドキュメントはユーザー プロンプトと連結され、Gorilla にそれを参照として使用するように指示するメッセージが表示されます。
-
API 呼び出しの生成: Gorilla はユーザー プロンプト (および該当する場合は取得したドキュメント) を処理して、ユーザーのタスクや目標を満たす適切な API 呼び出しを生成します。これは、API 呼び出し用に設計されたゴリラの微調整された LLaMA-7B モデルによって実現されます。
-
出力: Gorilla は生成された API 呼び出しをユーザーに返します。これを使用して、必要な API と対話し、指定されたタスクを完了できます。

特に、Gorilla は適応性が高く、ゼロショットモードと取得モードの両方で動作できるため、API ドキュメントの変更に適応し、長期にわたって精度を維持できます。
1 つ目 (そして最も人気のある) はゼロショット モードです。この場合、Gorilla はユーザーのクエリを自然言語で受け入れ、呼び出すための正しい API を返します。さて、多くのシナリオでは、時間の経過とともに API が進化することがよくあります。これはバージョン管理である可能性があり、エンドポイントが変更される可能性があり、パラメータが再シャッフルされる可能性があり、一部の API は使用が推奨されない可能性があります。
これに対してシステムを堅牢にするために、ゴリラを使用する 2 番目のモード (レトリバー対応) を導入します。この場合、Gorilla は最も関連性の高い API を選択し、それをユーザーのプロンプトに追加します。これにより、API の変更を理解できるようになります。
4. Gorilla LLM のインストール方法
Gorilla LLM を使用するには、Python 3.10 以降がインストールされている必要があります。以前のバージョンの Python はコンパイルできません。
4.1. Conda のインストール
- 新しいサーバーの場合は、初めて Conda をインストールする必要があります。ターミナルで次のコマンドを使用して、Miniconda インストール スクリプトをダウンロードします。
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 次のコマンドを使用してインストール スクリプトを実行します。
bash Miniconda3-latest-Linux-x86_64.sh
-
インストーラーの指示に従ってインストールします。インストール場所や環境変数設定などのオプションを選択できます。
-
インストールしたら、次のコマンドを使用して conda 環境をアクティブ化します。
source ~/.bashrc
- 次のコマンドを使用して、conda が正常にインストールされたことを確認します。
conda --version
conda が正常にインストールされると、conda のバージョン番号が表示されます。ここでは conda 23.5.2 をインストールしました。
4.2. ゴリラのインストール
4.2.1. 依存関係をインストールします。
- Python 3.10 を使用してゴリラという新しい Conda 環境を構築するには、次のコマンドを使用します。
conda create -n gorilla python=3.10
- ゴリラ環境をアクティブ化します。
conda activate gorilla
- required.txt という名前のファイルとその依存関係がある場合は、次のコマンドを使用して必要な Python パッケージをインストールします。
pip install -r requirements.txt
4.2.2. Gorilla Delta カウンターウェイトを取り付けます。
- 提供されたリンクから元の LLaMA 重みを取得します。
https://huggingface.co/docs/transformers/main/model_doc/llama
- ゴリラ デルタ ウェイトを Hugging Face リポジトリからダウンロードします。
https://huggingface.co/gorilla-llm/gorilla-7b-hf-delta-v1
4.2.3. 増分重みを使用する:
次の Python コマンドのプレースホルダーを正しいファイル パスに置き換えます。
python3 apply_delta.py
--base-model-path path/to/hf_llama/
--target-model-path path/to/gorilla-falcon-7b-hf-v0
--delta-path path/to/models--gorilla-llm--gorilla-7b-hf-delta-v1
このコマンドを使用して、LLaMA モデルに増分重みを適用します。
4.2.4. CLI を使用した推論:
- コマンド ライン インターフェイス (CLI) を使用してゴリラ モデルとの対話を開始するには、次のコマンドを使用します。
python3 serve/gorilla_falcon_cli.py --model-path path/to/gorilla-falcon-7b-hf-v0
# 如果您在使用 Apple 芯片(M1、M2 等)的 Mac 上运行,请添加 “--device mps”
path/to/gorilla-7b-hf,th,tf-v0Gorilla モデルへの実際のパスに置き換える必要があります。
4.3、ゴリラのコード構造
4.3.1. データフォルダーには、コミュニティによって提供された API ドキュメントや APIBench データセットなど、さまざまなデータセットが含まれています。
-
apiサブディレクトリ内の各ファイルは、 というタイトルの API を表します{api_name}_api.jsonl。 -
apibenchサブフォルダーには、LLM モデルのトレーニングと評価のデータセットが含まれています。ファイル{api_name}_train.jsonlと が含まれています{api_name}_eval.jsonl。 -
コミュニティによって提供される API は
apizooサブディレクトリにあります。
4.3.2. eval フォルダーには、評価コードと出力が含まれています。
-
README.mdファイルには、評価プロセスに関する指示またはデータが含まれています。 -
LLM モデルから応答を受信するには、
get_llm_responses.pyスクリプトを使用します。 -
サブディレクトリ
eval-scriptsには、各 API の評価スクリプトが含まれていますast_eval_{api_name}.py。 -
eval-data サブディレクトリには、評価の質問と回答が含まれています。
-
questionsサブフォルダー内の質問ファイルは、API 名と評価指標ごとに整理されます。- 各 API フォルダーには、サブディレクトリ
questionsにファイルというタイトルのファイルがありますquestions_{api_name}_{eval_metric}.jsonl。
- 各 API フォルダーには、サブディレクトリ
-
応答ファイルは、API 名と評価メトリックごとに
responsesサブフォルダーにも整理されます。- サブフォルダーへの応答として、各 API フォルダーには.jsonl
responses_{api_name}Gorilla_FT{eval_metric}.jsonlというタイトルのresponses_{api_name}Gorilla_RT{eval_metric}ファイルが含まれています。
- サブフォルダーへの応答として、各 API フォルダーには.jsonl
4.3.3.推論フォルダーには、Gorilla をローカルで実行するためのコードが含まれています。
-
このフォルダー内のファイルには
README.md、推論コードを実行するための命令が含まれている可能性があります。 -
serveサブディレクトリには、Gorilla コマンド ライン インターフェイス (CLI) スクリプトとチャット テンプレートが含まれています。 -
trainこのフォルダーには「Coming Soon!」とマークされており、おそらくゴリラ モデルのトレーニング コードが含まれているはずです。ただし、そのフォルダーは現在利用できないようです。
提供されたコードとデータセットの使用に関する具体的な手順と情報については、各フォルダー内の README ファイルを参照してください。
5. Gorilla LLM の使用方法
まず、pipを使用してOpenAIをインストールします
pip install openai
APIキーとAPIベースを次のように設定します
import openai
openai.api_key = "EMPTY" # key可以忽略
openai.api_base = "http://34.132.127.197:8000/v1" #http://zanino.millennium.berkeley.edu:8000/v1
5.1. テキスト翻訳
OpenAI ライブラリを使用して、Gorilla の結果を取得する関数を作成する
def get_gorilla_response(prompt="我想把英语翻译成中文。", model="gorilla-falcon-7b-hf-v0"):
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content
プロンプトと使用するモデルを送信する関数を実装します (この場合はGorilla-falcon-7b-hf-v0 )。
prompt = "我想从英语翻译成中文。"
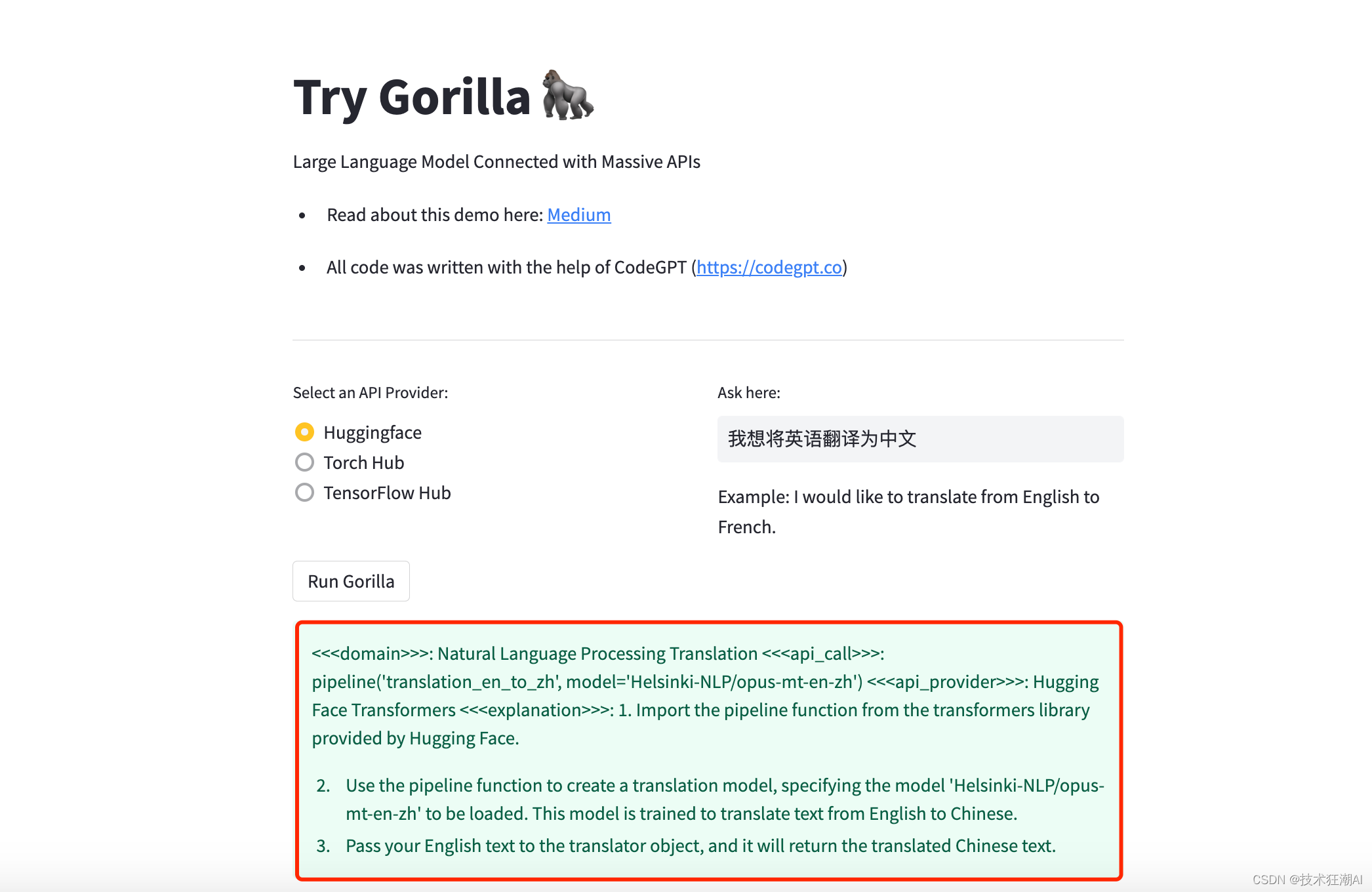
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0" ))
それでおしまい。その後、Huggingface API から完全な情報と、リクエストの実行方法に関する指示を受け取ります。
<<<domain>>>: Natural Language Processing Translation
<<<api_call>>>: pipeline('translation_en_to_zh', model='Helsinki-NLP/opus-mt-en-zh') <<<api_provider>>>: Hugging Face Transformers
<<<explanation>>>:
1. Import the pipeline function from the transformers library provided by Hugging Face.
2. Use the pipeline function to create a translation model, specifying the model 'Helsinki-NLP/opus-mt-en-zh' to be loaded. This model is trained to translate text from English to Chinese.
3. Pass your English text to the translator object, and it will return the translated Chinese text.
ゴリラハグフェイスデモ:
https://huggingface.co/spaces/davila7/try-gorilla?source=post_page
5.2、物体の検出
# 对象检测
prompt = "我想构建一个可以检测图像“cat.jpeg”中对象的机器人。输入:['cat.jpeg']"
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0"))
出力結果:
<<<domain>>>: Computer Vision Object Detection
<<<api_call>>>: model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101-dc5')
<<<api_provider>>>: Hugging Face Transformers
<<<explanation>>>: 1. Import the necessary components from the Hugging Face Transformers library, torch, and PIL (Python Imaging Library).
2. Open the image using PIL's Image.open() function with the provided image path.
3. Initialize the pretrained DETR (DEtection TRansformer) model and the image processor.
4. Generate inputs for the model using the image processor.
5. Pass the inputs to the model, which returns object detection results.
<<<code>>>:
from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
from PIL import Image
import torch
def load_model():
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/detr-resnet-101-dc5')
model = AutoModelForObjectDetection.from_pretrained('facebook/detr-resnet-101-dc5')
return feature_extractor, model
def process_data(image_path, feature_extractor, model):
image = Image.open(image_path)
inputs = feature_extractor(images=image, return_tensors='pt')
outputs = model(**inputs)
results = feature_extractor.post_process(outputs, threshold=0.6)[0]
response = [model.config.id2label[label.item()] for label in results['labels']]
return response
image_path = 'cat.jpeg'
# Load the model and feature extractor
feature_extractor, model = load_model()
# Process the data
response = process_data(image_path, feature_extractor, model)
print(response)
5.3. トーチハブから API を呼び出す
# Torch Hub 翻译
prompt = "我想把英语翻译成汉语。"
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0"))
出力結果:
{'domain': 'Machine Translation', 'api_call': \"model = torch.hub.load('pytorch/fairseq', 'transformer.wmt14.en-fr', tokenizer='moses', bpe='subword_nmt')\", 'api_provider': 'PyTorch', 'explanation': 'Load the Transformer model from PyTorch Hub, which is specifically trained on the WMT 2014 English-French translation task.', 'code': 'import torch\nmodel = torch.hub.load('pytorch/fairseq', 'transformer.wmt14.en-fr', tokenizer='moses', bpe='subword_nmt')'}"
6. Gorrilla API に基づいた ChatGPT-3.5 の微調整
Gorilla API データセットで ChatGPT-3.5 を微調整してパフォーマンスの向上を試みます。OpenAI ChatGPT-3.5 の微調整ドキュメントはここからアクセスできます。
https://platform.openai.com/docs/guides/fine-tuning
注: この微調整スクリプトは OpenAI 上で 720 万個のトークンをトレーニングします。これには一定の料金がかかります。続行する前に、この料金を支払う意思があるかどうかを検討してください。
6.1. インストールの依存関係
pip install openai tiktoken
必要なモジュールをインポートする
import re
import os
import json
import openai
from pprint import pprint
OpenAI APIキーの設定
openai_api_key = "OPENAI API KEY"
openai.api_key = openai_api_key
6.2、データセットの準備
ゴリラ ハギングフェイス API トレーニング データをダウンロードします。すべてのゴリラ トレーニング データはここにあります:
https://github.com/ShishirPatil/gorilla/tree/main/data/apibench
wget https://raw.githubusercontent.com/ShishirPatil/gorilla/cab053ba7fdf4a3286c0e75aa2bf7abc4053812f/data/apibench/huggingface_train.json
6.2.1. データのロード
data = []
with open("huggingface_train.json", "r") as file:
# data = json.load(file)
for line in file:
item = json.loads(line.strip())
data.append(item)
# 这是与训练有关的数据
data[0]["code"]
6.2.2. データ分析
トレーニングデータの解析手順
def parse_instructions_and_outputs(code_section):
sections = code_section.split('###')
for section in sections:
if "Instruction:" in section:
instruction = section.split("Instruction:", 1)[1].strip()
break
domain = re.search(r'<<<domain>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
api_call = re.search(r'<<<api_call>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
api_provider = re.search(r'<<<api_provider>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
if "<<<explanation>>>" in code_section:
explanation_pattern = r'<<<explanation>>>(.*?)(?:\n<<<code>>>|```|$)'
explanation = re.search(explanation_pattern, code_section, re.DOTALL).group(1).lstrip(': ')
else:
explanation = None
# 考虑两种情况提取代码片段
code_pattern = r'(?:<<<code>>>|```) (.*)' # 匹配 <<<code>>> 或 ```
code_snippet_match = re.search(code_pattern, code_section, re.DOTALL)
code_snippet = code_snippet_match.group(1).lstrip(': ') if code_snippet_match else None
return instruction, domain, api_call, api_provider, explanation, code_snippet
def encode_train_sample(data, api_name):
"""将多个提示指令编码为单个字符串。"""
code_section = data['code']
if "<<<api_call>>>" in code_section:
instruction, domain, api_call, api_provider, explanation, code = parse_instructions_and_outputs(code_section)
prompts = []
#prompt = instruction + "\nWrite a python program in 1 to 2 lines to call API in " + api_name + ".\n\nThe answer should follow the format: <<<domain>>> $DOMAIN, <<<api_call>>>: $API_CALL, <<<api_provider>>>: $API_PROVIDER, <<<explanation>>>: $EXPLANATION, <<<code>>>: $CODE}. Here are the requirements:\n" + domains + "\n2. The $API_CALL should have only 1 line of code that calls api.\n3. The $API_PROVIDER should be the programming framework used.\n4. $EXPLANATION should be a step-by-step explanation.\n5. The $CODE is the python code.\n6. Do not repeat the format in your answer."
prompts.append({"role": "system", "content": "你是一个有厉害的API开发人员,可以根据需求编写API。"})
prompts.append({"role": "user", "content": instruction})
prompts.append({"role": "assistant", "content": f"<<<domain>>> {domain},\
<<<api_call>>>: {api_call}, <<<api_provider>>>: {api_provider}, <<<explanation>>>: {explanation}, <<<code>>>: {code}"})
return prompts
else:
return None
ゴリラの論文を反映する正しい形式でトレーニング サンプルをフォーマットします。
encoded_data = []
none_count = 0
for d in data:
res = encode_train_sample(d, "huggingface")
if res is not None:
encoded_data.append({"messages":res})
else:
none_count += 1
print(f"{none_count} samples out of {len(data)} ignored")
微調整のために OpenAI に渡される印刷サンプル
encoded_data[3]
出力結果:
{'messages': [{'role': 'system',
'content': 'You are a helpful API writer who can write APIs based on requirements.'},
{'role': 'user',
'content': 'I run an online art store and I want to classify the art pieces uploaded by the users into different categories like abstract, landscape, portrait etc.'},
{'role': 'assistant',
'content': "<<<domain>>> Computer Vision Image Classification,<<<api_call>>>: ViTModel.from_pretrained('facebook/dino-vits8'), <<<api_provider>>>: Hugging Face Transformers, <<<explanation>>>: 1. We first import the necessary classes from the transformers and PIL packages. This includes ViTModel for the image classification model and Image for processing image data.\n2. We then use the from_pretrained method of the ViTModel class to load the pre-trained model 'facebook/dino-vits8'. This model has been trained using the DINO method which is particularly useful for getting good features for image classification tasks.\n3. We load the image data from an uploaded image file by the user.\n4. This model can then be used to classify the image into different art categories like 'abstract', 'landscape', 'portrait' etc., <<<code>>>: None"}]}
トレーニングデータを保存する
encoded_file_path = 'encoded_data.jsonl'
with open(encoded_file_path, 'w') as file:
for item in encoded_data:
line = json.dumps(item)
file.write(line + '\n')
6.3. OpenAI データ検証スクリプト
# 我们从导入所需的包开始
import json
import os
import tiktoken
import numpy as np
from collections import defaultdict
# 接下来,我们指定数据通路并打开JSONL文件
data_path = encoded_file_path
# 加载数据集
with open(data_path) as f:
dataset = [json.loads(line) for line in f]
# 我们可以通过检查示例数量和第一项来快速检查数据
# 初始数据集统计信息
print("Num examples:", len(dataset))
print("First example:")
for message in dataset[0]["messages"]:
print(message)
# 现在我们对数据有了了解,我们需要遍历所有不同的示例并检查以确保格式正确并与Chat完成消息结构匹配
# 格式错误检查
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
if not content or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
# 除了消息的结构之外,我们还需要确保长度不超过4096令牌限制。
# Token 计数功能
encoding = tiktoken.get_encoding("cl100k_base")
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
def print_distribution(values, name):
print(f"\n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.1)}, {np.quantile(values, 0.9)}")
# 最后,在继续创建微调作业之前,我们可以查看不同格式化操作的结果:
# 警告和token计数
n_missing_system = 0
n_missing_user = 0
n_messages = []
convo_lens = []
assistant_message_lens = []
for ex in dataset:
messages = ex["messages"]
if not any(message["role"] == "system" for message in messages):
n_missing_system += 1
if not any(message["role"] == "user" for message in messages):
n_missing_user += 1
n_messages.append(len(messages))
convo_lens.append(num_tokens_from_messages(messages))
assistant_message_lens.append(num_assistant_tokens_from_messages(messages))
print("缺少系统消息的示例数:", n_missing_system)
print("缺少用户消息的数字示例:", n_missing_user)
print_distribution(n_messages, "num_messages_per_example")
print_distribution(convo_lens, "num_total_tokens_per_example")
print_distribution(assistant_message_lens, "num_assistant_tokens_per_example")
n_too_long = sum(l > 4096 for l in convo_lens)
print(f"\n{n_too_long} 示例可能超过4096令牌限制,它们将在微调期间被截断")
# 定价和违约n_epochs估计
MAX_TOKENS_PER_EXAMPLE = 4096
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
TARGET_EPOCHS = 3
MIN_EPOCHS = 1
MAX_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"数据集有~{n_billing_tokens_in_dataset}个令牌,在训练期间将收取费用")
print(f"默认情况下,您将在此数据集上训练{n_epochs}个纪元")
print(f"默认情况下,您将收取~{n_epochs*n_billing_tokens_in_dataset}代币的费用")
print("请参阅定价页面以估算总成本")
6.4. GPT-3.5の微調整を開始する
OpenAI トレーニング ファイルを作成する
openai.File.create(
file=open(encoded_file_path, "rb"),
purpose='fine-tune'
)
微調整タスクを作成する
openai.api_key = openai_api_key
openai.FineTuningJob.create(
training_file="file-OrxAP7HcvoSUmu9MtAbWo5s4",
model="gpt-3.5-turbo"
)
# 列出 10 个微调任务
openai.FineTuningJob.list(limit=10)
# 查询微调的状态
state = openai.FineTuningJob.retrieve("ftjob-qhg4yswil15TCqD4SNHn0V1D")
state["status"], state["trained_tokens"], state["finished_at"]
# 列出微调作业中最多 10 个事件
openai.FineTuningJob.list_events(id="ftjob-qhg4yswil15TCqD4SNHn0V1D", limit=10)
6.5. 微調整モデルの使用
openai.api_key = openai_api_key
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "How can i load a NER model?"}
]
)
print(completion.choices[0].message)
print(completion.choices[0].message["content"])
出力結果:
('To load a Named Entity Recognition (NER) model in Python, you can use the '
"Hugging Face Transformers library. Here's a step-by-step guide to loading "
'and using a NER model:\n'
'\n'
'1. Install the required Hugging Face Transformers library using "pip install '
'transformers".\n'
'2. Import the AutoModelForTokenClassification class from the transformers '
'library.\n'
'3. Import the necessary tokenizer as well, which is AutoTokenizer in this '
'case.\n'
'4. Use the from_pretrained method to load the pre-trained model with its '
'respective model name or identifier.\n'
'5. Then, use the load_tokenizer method to load the tokenizer.\n'
'6. Encode your text using the loaded tokenizer, specifying the '
"'return_tensors' parameter as 'pt'.\n"
'7. Pass the input tensor to the model and it will return the predictions, '
'describing the Named Entities in the text.\n'
'\n'
'Please keep in mind that you should download the model first, replace '
"'YOUR_MODEL_NAME' with an appropriate model identifier, and make sure to "
'execute this code on a suitable device (e.g., CPU or GPU).\n'
'\n'
'Here is how the code looks:\n'
'```python\n'
'from transformers import AutoModelForTokenClassification, AutoTokenizer\n'
'import torch\n'
'\n'
"model = AutoModelForTokenClassification.from_pretrained('YOUR_MODEL_NAME')\n"
"tokenizer = AutoTokenizer.from_pretrained('YOUR_MODEL_NAME')\n"
'\n'
'# Encode your text using the loaded tokenizer\n'
"inputs = tokenizer(text, return_tensors='pt')\n"
'\n'
'# Pass the input tensor to the model and obtain NER predictions\n'
'predictions = model(**inputs)\n'
'```\n'
'\n'
"Remember to replace 'YOUR_MODEL_NAME' with an appropriate BERT NER-trained "
"model such as 'dslim/bert-base-NER'.")
7. まとめ
Gorilla LLM は、正確な API 呼び出しを生成し、ドキュメントのリアルタイムの変更に適応する画期的な LLM です。このモデルは、将来の LLM がツールやシステムと対話する際に、より信頼性が高く、多用途になる道を切り開きます。
Gorilla LLM は、開発者にとって強力な新しいツールです。開発者の時間と労力を節約し、より信頼性の高いコードを作成するのに役立ちます。あなたが開発者であれば、Gorilla LLM について学ぶことをお勧めします。
LLM の今後の進歩は、幻覚エラーのさらなる削減、さまざまな API への適応性の向上、複雑なタスクの処理能力の拡張に焦点を当てることができます。潜在的なアプリケーションには、コンピューティング インフラストラクチャへの主要なインターフェイスとしての機能、休暇の予約などのプロセスの自動化、さまざまな Web API 間のシームレスな通信の促進などが含まれます。
8. 参考文献
-
ゴリラのウェブサイト
https://shishirpatil.github.io/gorilla/
-
ゴリラのGitHub
https://github.com/ShishirPatil/gorilla
-
ゴリラのポケベル
https://arxiv.org/abs/2305.15334
この記事に興味があり、AI 分野の実践的なスキルについて詳しく知りたい場合は、「Technology Craze AI」公開アカウントに注目してください。ここでは、AIGC 分野の最新かつ最もホットな辛口記事と実践的なチュートリアルをご覧いただけます。