Detección y reconocimiento de matrículas basado en PaddleOCR
prefacio
- Debido a mi nivel limitado es inevitable que haya errores y omisiones, por favor critica y corrige.
- Para obtener contenido más interesante, haga clic para ingresar a la columna de la serie YOLO , la columna de procesamiento del lenguaje natural
o mi página de inicio personal para ver- Detección de mascarada facial basada en DETR
- YOLOv7 entrena su propio conjunto de datos (detección de máscara)
- YOLOv8 entrena su propio conjunto de datos (detección de fútbol)
- YOLOv5: TensorRT acelera el razonamiento del modelo YOLOv5
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- Jugando con Jetson Nano (5): TensorRT acelera la detección de objetivos YOLOv5
- YOLOv5: Agregar mecanismo de atención SE, CBAM, CoordAtt, ECA
- YOLOv5: interpretación del archivo de configuración yolov5s.yaml, agregando una pequeña capa de detección de objetivos
- Python convierte el conjunto de datos de segmentación de instancias en formato COCO al conjunto de datos de segmentación de instancias en formato YOLO
- YOLOv5: utilice la versión 7.0 para entrenar su propio modelo de segmentación de instancias (segmentación de instancias de vehículos, peatones, señales de tráfico, líneas de carril, etc.)
requisito previo
- Familiarizado con Python
introducción relacionada
- Python es un lenguaje de programación informática multiplataforma. Es un lenguaje de scripting de alto nivel que combina interpretabilidad, compilación, interactividad y orientación a objetos. Originalmente diseñado para escribir scripts de automatización (shell), a medida que la versión se actualiza continuamente y se agregan nuevas características del lenguaje, se utiliza cada vez más para el desarrollo de proyectos independientes y de gran escala.
- PaddleOCR (nombre completo: Paddle Optical Character Recognition) es una herramienta OCR (reconocimiento óptico de caracteres) de código abierto desarrollada en base al marco de aprendizaje profundo PaddlePaddle. OCR es una tecnología utilizada para convertir contenido de texto impreso o escrito a mano en texto electrónico editable. PaddleOCR tiene como objetivo lograr detección de texto, reconocimiento de texto y análisis de diseño de alta precisión a través de tecnología de aprendizaje profundo.
- El proyecto PaddleOCR proporciona una solución de OCR de un extremo a otro que cubre las siguientes funciones principales:
- Detección de texto : identifica regiones de texto en una imagen, generalmente representadas por un cuadro delimitador rectangular.
- Reconocimiento de texto (Reconocimiento de texto) : para el área de texto detectada, reconozca aún más los caracteres y palabras que contiene y convierta el contenido del texto de la imagen en texto editable.
- Análisis de diseño : analice la estructura de diseño del documento, incluidos párrafos, encabezados, tablas, etc., para comprender mejor la estructura organizativa del documento.
- El proyecto PaddleOCR utiliza modelos de aprendizaje profundo, como redes neuronales convolucionales (CNN) y redes neuronales recurrentes (RNN), para entrenar y optimizar modelos para la detección y el reconocimiento de texto. La ventaja de este proyecto es que puede manejar textos en múltiples idiomas y diferentes campos, al tiempo que proporciona una API y una interfaz de línea de comandos fáciles de usar, lo que permite a los desarrolladores integrar fácilmente la tecnología OCR en sus propias aplicaciones.
- En resumen, PaddleOCR es una herramienta de OCR de código abierto basada en PaddlePaddle diseñada para proporcionar funciones de detección de texto, reconocimiento de texto y análisis de diseño de alta precisión para satisfacer las necesidades de la tecnología OCR en diferentes campos de aplicación.
PaddleOCR
- Dirección del proyecto : https://github.com/PaddlePaddle/PaddleOCR.git
- Documentación del tutorial oficial de PaddleOCR : https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/README_ch.md
- Nota : Los documentos del tutorial oficial de PaddleOCR están escritos con gran detalle y aquellos que estén interesados pueden consultarlos ellos mismos. El motivo para escribir este artículo es un pequeño registro de la implementación rápida de la aplicación y el despliegue de los requisitos de mi propio proyecto después de consultar los documentos del tutorial oficial de PaddleOCR. El propósito de este artículo es implementar rápidamente la aplicación, independientemente del principio, y escribirla más tarde cuando tenga tiempo.
Requisitos medioambientales
- paletaocr==2.7.0.0
- remopadel==2.4.2
- paddleslim: 2.2.2
- bien proporcionado
- imagen-scikit
- imgaug
- pyclipper
- ldb
- tqdm
- engordado
- visualdl
- rapidfuzz
- opencv-python<=4.6.0.66
- opencv-contrib-python<=4.6.0.66
- citón
- lxml
- preenviador
- openpyxl
- atractivo
- PyMuPDF<1.21.0
- Almohada>=10.0.0
Detección y reconocimiento de matrículas
Preparar conjunto de datos
Aquí, el conjunto de datos de matrículas públicas CCPD2020 se utiliza como conjunto de datos principal para el entrenamiento, pero este conjunto de datos públicos no tiene el formato de conjunto de datos requerido por PaddleOCR, por lo que debe convertirse.
- El conjunto de datos se puede descargar desde https://aistudio.baidu.com/aistudio/datasetdetail/101595
- Producción de formato de datos PaddleOCR, seguimiento gratuito para escribir. Para obtener más información, consulte el documento tutorial oficial de PaddleOCR : https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/README_ch.md
detección de texto de matrícula
Descargue el modelo previamente entrenado
- Enlace de descarga : https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
Una vez completada la descarga, descomprímalo y colóquelo en el directorio PaddleOCR/models.

Conjunto de datos de detección de matrículas de ajuste y capacitación
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams Global.save_model_dir=output/CCPD/det Global.eval_batch_step="[0, 772]" Optimizer.lr.name=Const Optimizer.lr.learning_rate=0.0005 Optimizer.lr.warmup_epoch=0 Train.dataset.data_dir=../../datasets/CCPD2020/ccpd_green Train.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/train/det.txt] Eval.dataset.data_dir=../../datasets/CCPD2020/ccpd_green Eval.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/test/det.txt]
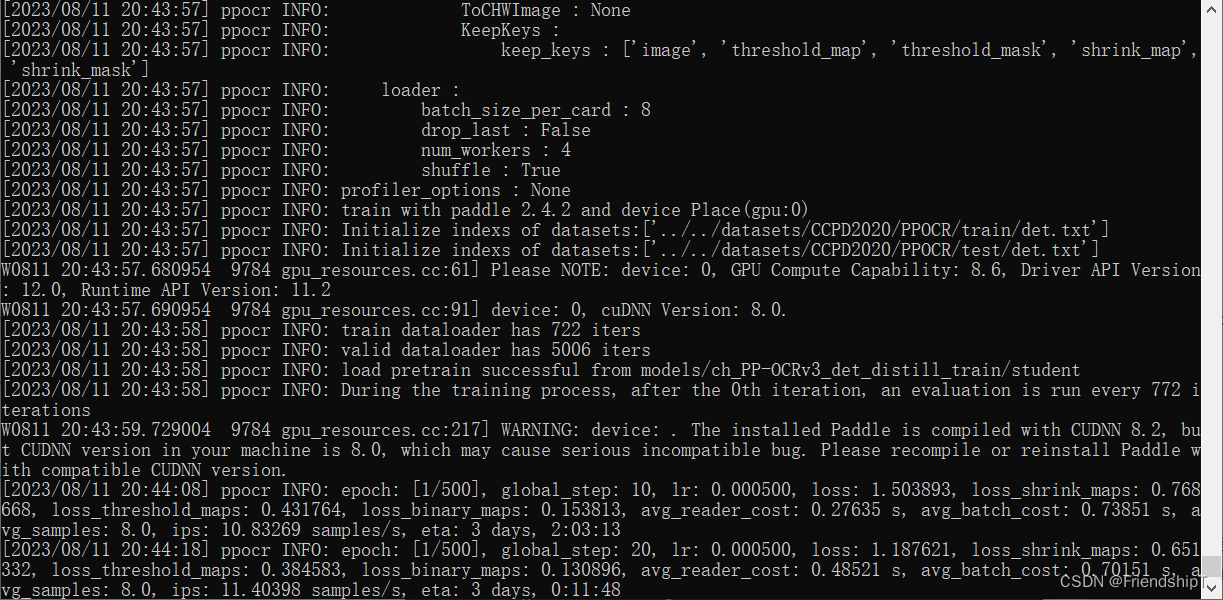
Evaluar el modelo entrenado.
python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams Eval.dataset.data_dir=../../datasets/CCPD2020/ccpd_green Eval.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/test/det.txt]
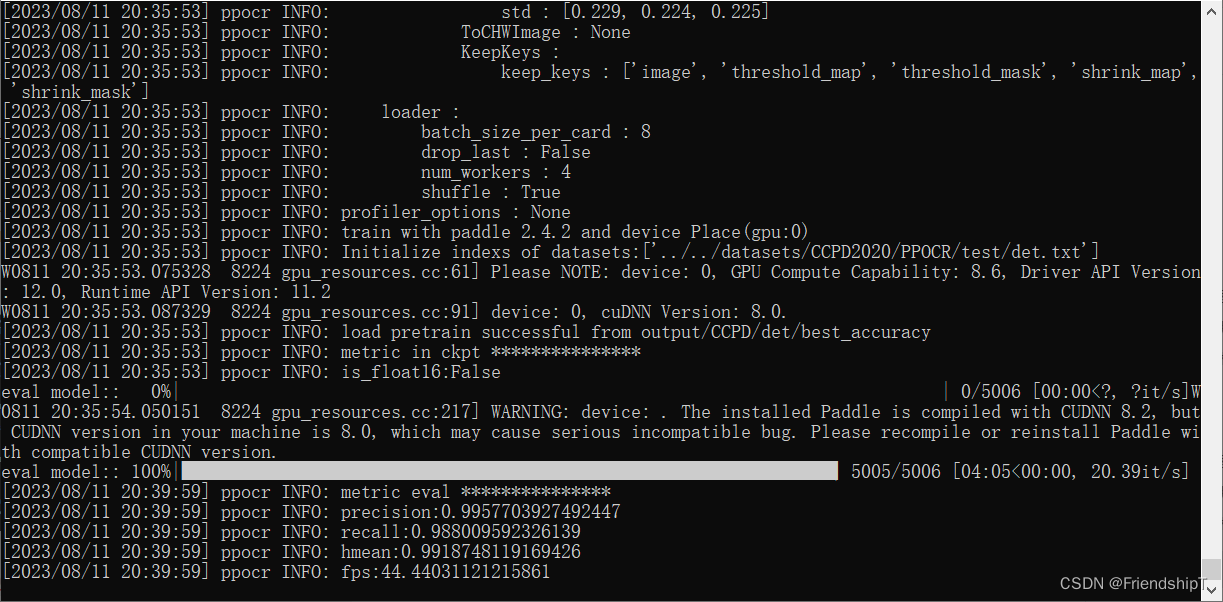
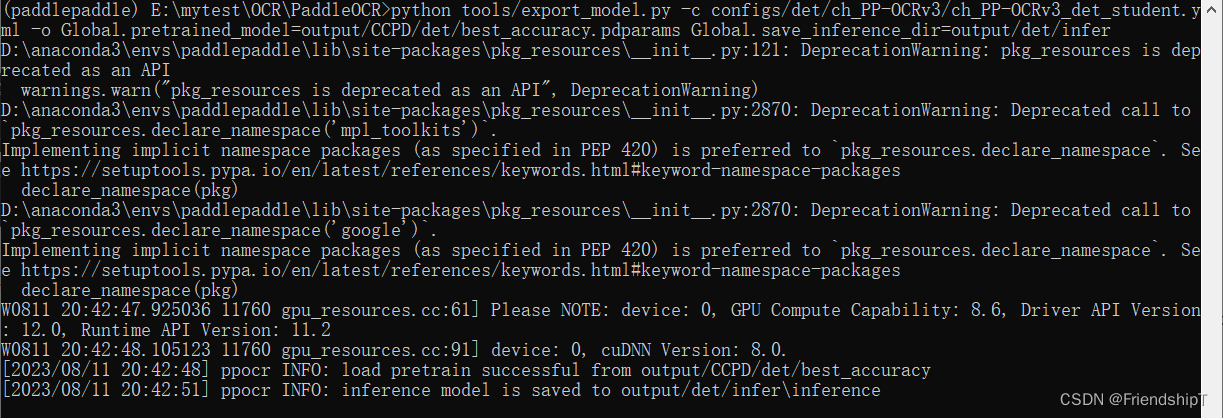
modelo de exportación
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams Global.save_inference_dir=output/det/infer
Reconocimiento de texto de matrícula
Descargue el modelo previamente entrenado
- Dirección de descarga : https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
Una vez completada la descarga, descomprímalo y colóquelo en el directorio PaddleOCR/models.

Conjunto de datos de reconocimiento de matrículas de ajuste y capacitación
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams Global.save_model_dir=output/CCPD/rec/ Global.eval_batch_step="[0, 90]" Optimizer.lr.name=Const Optimizer.lr.learning_rate=0.0005 Optimizer.lr.warmup_epoch=0 Train.dataset.data_dir=../../datasets/CCPD2020/PPOCR Train.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/train/rec.txt] Eval.dataset.data_dir=../../datasets/CCPD2020/PPOCR Eval.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/test/rec.txt]


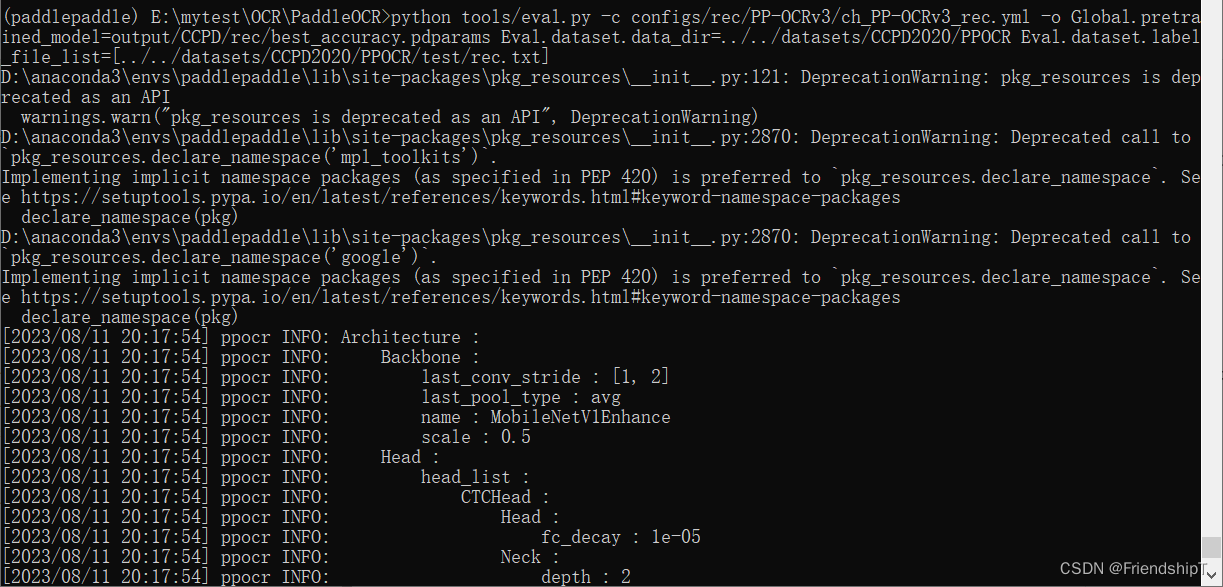
Evaluar el modelo entrenado.
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams Eval.dataset.data_dir=../../datasets/CCPD2020/PPOCR Eval.dataset.label_file_list=[../../datasets/CCPD2020/PPOCR/test/rec.txt]

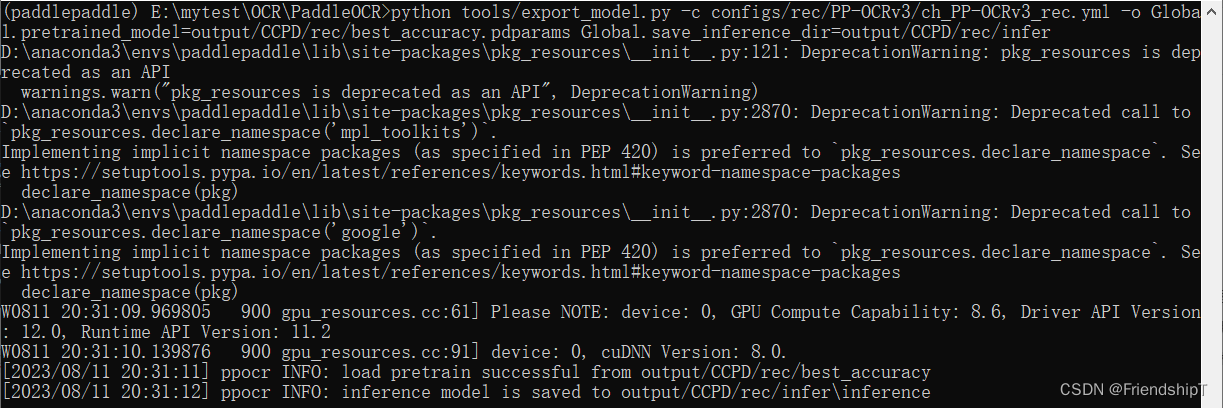
modelo de exportación
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams Global.save_inference_dir=output/CCPD/rec/infer
hacer predicciones

python tools/infer/predict_system.py --det_model_dir=output/CCPD/det/infer/ --rec_model_dir=output/CCPD/rec/infer/ --image_dir="test.jpg"
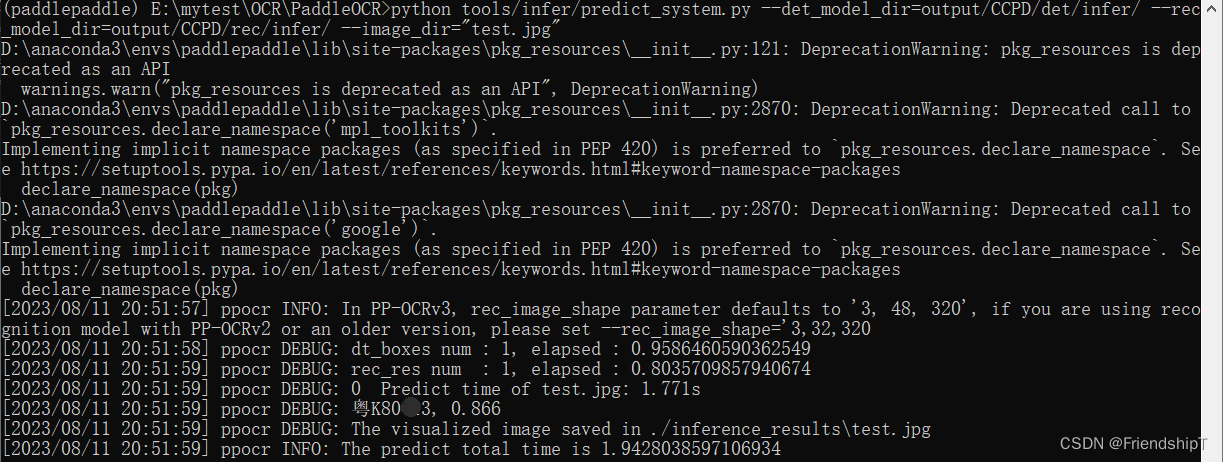
Gráfico de resultados de la prueba

referencia
[1] https://github.com/PaddlePaddle/PaddleOCR.git
[2] https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/README_ch.md
[3] https://github.com /detectRecog/CCPD
- Debido a mi nivel limitado es inevitable que haya errores y omisiones, por favor critica y corrige.
- Para obtener contenido más interesante, haga clic para ingresar a la columna de la serie YOLO , la columna de procesamiento del lenguaje natural
o mi página de inicio personal para ver- YOLOv5: Agregar mecanismo de atención SE, CBAM, CoordAtt, ECA
- YOLOv5: interpretación del archivo de configuración yolov5s.yaml, agregando una pequeña capa de detección de objetivos
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7 entrena su propio conjunto de datos (detección de máscara)
- YOLOv8 entrena su propio conjunto de datos (detección de fútbol)
- Jugando con Jetson Nano (5): TensorRT acelera la detección de objetivos YOLOv5
- YOLOv5: utilice la versión 7.0 para entrenar su propio modelo de segmentación de instancias (segmentación de instancias de vehículos, peatones, señales de tráfico, líneas de carril, etc.)
- Python convierte el conjunto de datos de segmentación de instancias en formato COCO al conjunto de datos de segmentación de instancias en formato YOLO
- Detección de mascarada facial basada en DETR
- Utilice los recursos de Kaggle GPU para experimentar el proyecto de código abierto Stable Diffusion de forma gratuita
- YOLOv5: TensorRT acelera el razonamiento del modelo YOLOv5