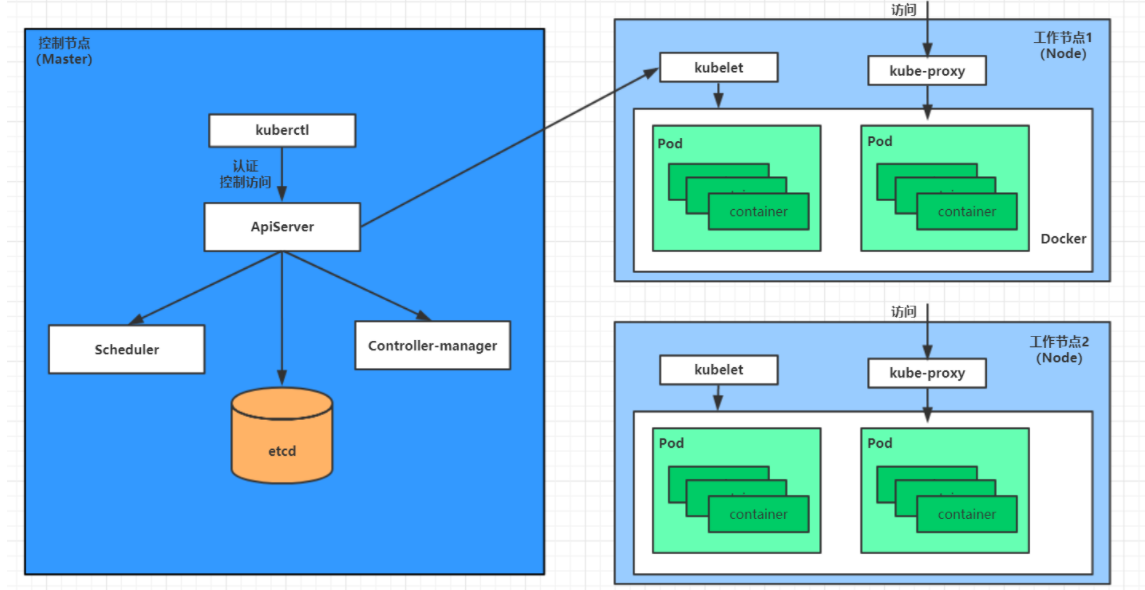
Un combate de Kubernetes
Este capítulo presentará cómo implementar un servicio nginx en un clúster de kubernetes y poder acceder a él.
1.1 Espacio de nombres
El espacio de nombres es un recurso muy importante en el sistema kubernetes. Su función principal es realizar el aislamiento de recursos de múltiples entornos o el aislamiento de recursos de múltiples inquilinos .
De forma predeterminada, todos los pods en un clúster de kubernetes son accesibles mutuamente. Pero en la práctica, es posible que no desee permitir que dos Pods se accedan entre sí, luego puede dividir los dos Pods en diferentes espacios de nombres. Kubernetes puede formar "grupos" lógicos al asignar recursos dentro del clúster a diferentes espacios de nombres, para facilitar el uso y la administración aislados de recursos en diferentes grupos.
A través del mecanismo de autorización de kubernetes, se pueden entregar diferentes espacios de nombres a diferentes inquilinos para su administración, logrando así el aislamiento de recursos de múltiples inquilinos. En este momento, el mecanismo de cuota de recursos de kubernetes también se puede combinar para limitar los recursos que pueden ocupar los diferentes inquilinos, como el uso de CPU, el uso de memoria, etc., para realizar la gestión de los recursos disponibles de los inquilinos.
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-jM5RMKPa-1640144981805)(Kubenetes.assets/image-20200407100850484.png)]](https://img-blog.csdnimg.cn/f45d363402f94e2cbb226801a75523d7.png)
Una vez que se inicia el clúster, kubernetes creará los siguientes cuatro espacios de nombres de forma predeterminada
[root@master ~]# kubectl get namespace
NAME STATUS AGE
default Active 45h # 所有未指定Namespace的对象(pod)都会被分配在default命名空间
kube-node-lease Active 45h # 集群节点之间的心跳维护,v1.13开始引入
kube-public Active 45h # 此命名空间下的资源可以被所有人访问(包括未认证用户)
kube-system Active 45h # 所有由Kubernetes系统创建的资源都处于这个命名空间
Veamos las operaciones específicas de los recursos de espacio de nombres:
Modo de comando para operar
Controlar
# 1 查看所有的ns 命令:kubectl get ns
[root@master ~]# kubectl get ns
NAME STATUS AGE
default Active 45h
kube-node-lease Active 45h
kube-public Active 45h
kube-system Active 45h
# 2 查看指定的ns 命令:kubectl get ns ns名称
[root@master ~]# kubectl get ns default
NAME STATUS AGE
default Active 45h
# 3 指定输出格式 命令:kubectl get ns ns名称 -o 格式参数
# kubernetes支持的格式有很多,比较常见的是wide、json、yaml
[root@master ~]# kubectl get ns default -o yaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: "2021-05-08T04:44:16Z"
name: default
resourceVersion: "151"
selfLink: /api/v1/namespaces/default
uid: 7405f73a-e486-43d4-9db6-145f1409f090
spec:
finalizers:
- kubernetes
status:
phase: Active
# 4 查看ns详情 命令:kubectl describe ns ns名称
[root@master ~]# kubectl describe ns default
Name: default
Labels: <none>
Annotations: <none>
Status: Active # Active:命名空间正在使用中 Terminating:正在删除命名空间
# ResourceQuota 针对namespace做的资源限制
# LimitRange针对namespace中的每个组件做的资源限制
No resource quota.
No LimitRange resource.
crear
# 创建namespace
[root@master ~]# kubectl create ns dev
namespace/dev created
borrar
# 删除namespace
[root@master ~]# kubectl delete ns dev
namespace "dev" deleted
Configurar para operar
Primero prepare un archivo yaml: ns-dev.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dev
Luego puede ejecutar los comandos de creación y eliminación correspondientes:
Crear: kubectl create -f ns-dev.yaml
Eliminar: kubectl delete -f ns-dev.yaml
1.2 vaina
Pod es la unidad más pequeña de administración de clústeres de Kubernetes. Para ejecutar un programa, debe implementarse en un contenedor (el programa se ejecuta en un contenedor) y el contenedor debe existir en un Pod.
Pod puede considerarse como el paquete de contenedores, y uno o más contenedores pueden existir en un Pod.
En la figura a continuación, el contenedor inferior es el contenedor raíz y los otros contenedores son contenedores de usuario (se explicará en detalle en el Capítulo 2)
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-hOEYHUJF-1640144981806)(Kubenetes.assets/image-20200407121501907.png)]](https://img-blog.csdnimg.cn/987244a86f5e463a88945fb466cad470.png)
Una vez que se inicia el clúster de kubernetes, cada componente del clúster también se ejecuta como un pod. Puedes verlo con el siguiente comando:
[root@master ~]# kubectl get pod -n kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-6955765f44-68g6v 1/1 Running 0 2d1h
kube-system coredns-6955765f44-cs5r8 1/1 Running 0 2d1h
kube-system etcd-master 1/1 Running 0 2d1h
kube-system kube-apiserver-master 1/1 Running 0 2d1h
kube-system kube-controller-manager-master 1/1 Running 0 2d1h
kube-system kube-flannel-ds-amd64-47r25 1/1 Running 0 2d1h
kube-system kube-flannel-ds-amd64-ls5lh 1/1 Running 0 2d1h
kube-system kube-proxy-685tk 1/1 Running 0 2d1h
kube-system kube-proxy-87spt 1/1 Running 0 2d1h
kube-system kube-scheduler-master 1/1 Running 0 2d1h
Crear y ejecutar pods
kubernetes no proporciona comandos para ejecutar Pods individualmente, todos se implementan a través de controladores de Pod
# 命令格式: kubectl run (pod控制器名称) [参数]
# --image 指定Pod的镜像
# --port 指定端口
# --namespace 指定namespace
#下边第一个nginx指的是pod名称
[root@master ~]# kubectl run nginx --image=nginx:latest --port=80 --namespace dev
deployment.apps/nginx created
Ver información de la cápsula
# 查看Pod基本信息
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 43s
# 查看Pod的详细信息,pod创建失败的话,在这个命令输出的最下边会有提示信息
[root@master ~]# kubectl describe pod nginx -n dev
Name: nginx
Namespace: dev
Priority: 0
Node: node1/192.168.5.4
Start Time: Wed, 08 May 2021 09:29:24 +0800
Labels: pod-template-hash=5ff7956ff6
run=nginx
Annotations: <none>
Status: Running
IP: 10.244.1.23
IPs:
IP: 10.244.1.23
Controlled By: ReplicaSet/nginx
Containers:
nginx:
Container ID: docker://4c62b8c0648d2512380f4ffa5da2c99d16e05634979973449c98e9b829f6253c
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:485b610fefec7ff6c463ced9623314a04ed67e3945b9c08d7e53a47f6d108dc7
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Wed, 08 May 2021 09:30:01 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-hwvvw (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-hwvvw:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-hwvvw
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned dev/nginx-5ff7956ff6-fg2db to node1
Normal Pulling 4m11s kubelet, node1 Pulling image "nginx:latest"
Normal Pulled 3m36s kubelet, node1 Successfully pulled image "nginx:latest"
Normal Created 3m36s kubelet, node1 Created container nginx
Normal Started 3m36s kubelet, node1 Started container nginx
Pods de acceso
# 获取podIP
# 下边的READY列指的是有几个容器(不包含根容器Pause),且容器里有几个是正在运行着的
# RESTARTS:重启次数
# IP:当前pod的ip(以后要用这个ip访问里边的容器下的程序),每次创建pod时,这个ip都不一样,即ip不稳定,后边会介绍怎么解决
# Node:被调到哪个node去运行了
[root@master ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ...
nginx 1/1 Running 0 190s 10.244.1.23 node1 ...
#访问POD
[root@master ~]# curl http://10.244.1.23:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Eliminar el Pod especificado
# 删除指定Pod
[root@master ~]# kubectl delete pod nginx -n dev
pod "nginx" deleted
# 此时,显示删除Pod成功,但是再查询,发现又新产生了一个
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 21s
# 这是因为当前Pod是由Pod控制器创建的(因为我们使用的是kubectl run创建的),控制器会监控Pod状况,一旦发现Pod死亡,会立即重建
# 此时要想删除Pod,必须删除Pod控制器
# 先来查询一下当前namespace下的Pod控制器
[root@master ~]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 9m7s
# 接下来,删除此PodPod控制器
[root@master ~]# kubectl delete deploy nginx -n dev
deployment.apps "nginx" deleted
# 稍等片刻,再查询Pod,发现Pod被删除了
[root@master ~]# kubectl get pods -n dev
No resources found in dev namespace.
operación de configuración
Cree un pod-nginx.yaml con el siguiente contenido:
# 注意,此时起的是单独的pod,不是pod控制器
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: dev
spec:
containers:
- image: nginx:latest # -指的是数组
name: pod
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
Luego puede ejecutar los comandos de creación y eliminación correspondientes:
Crear: kubectl create -f pod-nginx.yaml
Eliminar: kubectl delete -f pod-nginx.yaml
1.3 Etiqueta
La etiqueta es un concepto importante en el sistema kubernetes. Su función es agregar identificación a los recursos para distinguirlos y seleccionarlos.
Características de la etiqueta:
- Se adjuntará una etiqueta a varios objetos en forma de pares clave-valor clave/valor, como nodo, pod, servicio, etc.
- Un objeto de recurso puede definir cualquier cantidad de Etiquetas, y la misma Etiqueta también se puede agregar a cualquier cantidad de objetos de recurso
- La etiqueta generalmente se determina cuando se define el objeto de recurso, por supuesto, también se puede agregar o eliminar dinámicamente después de que se crea el objeto.
La agrupación multidimensional de recursos se puede realizar a través de Label, de modo que la asignación de recursos, la programación, la configuración, la implementación y otros trabajos de administración se pueden realizar de manera flexible y conveniente.
Algunos ejemplos de etiquetas de uso común son los siguientes:
- Etiquetas de versión: "versión": "lanzamiento", "versión": "estable"...
- Etiquetas de entorno: "entorno": "dev", "entorno": "prueba", "entorno": "pro"
- Etiquetas de esquema: "tier": "frontend" (primer plano), "tier": "backend" (backend)
Después de definida la etiqueta, también se debe considerar la selección de la etiqueta, lo que requiere el uso del Selector de etiquetas, a saber:
La etiqueta se utiliza para definir un identificador para un objeto de recurso
Label Selector se utiliza para consultar y filtrar objetos de recursos con ciertas etiquetas
Actualmente hay dos selectores de etiquetas:
-
Selector de etiquetas basado en ecuaciones
nombre = esclavo: Seleccione todos los objetos que contengan clave="nombre" y valor="esclavo" en Etiqueta
env != producción: seleccione todos los objetos, incluida la clave = "env" en la etiqueta y el valor no es igual a "producción"
-
Selector de etiquetas basado en conjuntos
nombre en (maestro, esclavo): Seleccione todos los objetos que contengan clave="nombre" y valor="maestro" o "esclavo" en Etiqueta
el nombre no está en (frontend): seleccione todos los objetos que contengan la clave = "nombre" en la etiqueta y el valor no sea igual a "frontend"
Se pueden utilizar varios criterios de selección de etiquetas. En este caso, se pueden combinar varios selectores de etiquetas y separarlos con comas ",". Por ejemplo:
nombre=esclavo,env!=producción
nombre no en (frontend), env! = producción
modo de comando
# 为pod资源打标签 标签名字是:version=1.0
[root@master ~]# kubectl label pod nginx-pod version=1.0 -n dev
pod/nginx-pod labeled
# 为pod资源更新标签
[root@master ~]# kubectl label pod nginx-pod version=2.0 -n dev --overwrite
pod/nginx-pod labeled
# 查看标签
[root@master ~]# kubectl get pod nginx-pod -n dev --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 10m version=2.0
# 筛选标签
[root@master ~]# kubectl get pod -n dev -l version=2.0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 17m version=2.0
[root@master ~]# kubectl get pod -n dev -l version!=2.0 --show-labels
No resources found in dev namespace.
#删除标签 version-: 代表删除version标签
[root@master ~]# kubectl label pod nginx-pod version- -n dev
pod/nginx-pod labeled
método de configuración
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: dev
labels:
version: "3.0"
env: "test"
spec:
containers:
- image: nginx:latest
name: pod
ports:
- name: nginx-port
containerPort: 80
protocol: TCP
Luego puede ejecutar el comando de actualización correspondiente: kubectl apply -f pod-nginx.yaml
1.4 Despliegue
En kubernetes, pod es la unidad de control más pequeña, pero kubernetes rara vez controla directamente los pods, generalmente a través del controlador de pods. El controlador de pod se usa para la administración de pods para garantizar que los recursos de pod cumplan con el estado esperado. Cuando los recursos de pod fallan, intentará reiniciar o reconstruir el pod. .
Hay muchos tipos de controladores de Pod en kubernetes, y este capítulo solo presenta uno: Implementación.
La relación entre pod y Deployment se establece a través de la etiqueta;
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-dNqPbEEE-1640144981807)(Kubenetes.assets/image-20200408193950807.png)]](https://img-blog.csdnimg.cn/a675295f62fc4f0ca2783da05d1c1902.png)
operación de comando
# 创建deployment,名称为nginx,并且创建deployment下的pod
# 命令格式: kubectl create deployment 名称 [参数]
# --image 指定pod的镜像
# --port 指定端口
# --replicas 指定创建pod数量,默认1个
# --namespace 指定namespace
[root@master ~]# kubectl create deploy nginx --image=nginx:latest --port=80 --replicas=3 -n dev
deployment.apps/nginx created
# 查看创建的Pod
[root@master ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
nginx-5ff7956ff6-6k8cb 1/1 Running 0 19s
nginx-5ff7956ff6-jxfjt 1/1 Running 0 19s
nginx-5ff7956ff6-v6jqw 1/1 Running 0 19s
# 查看deployment的信息
[root@master ~]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/3 3 3 2m42s
# UP-TO-DATE:成功升级的副本数量
# AVAILABLE:可用副本的数量
[root@master ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 3/3 3 3 2m51s nginx nginx:latest run=nginx
# 查看deployment的详细信息
[root@master ~]# kubectl describe deploy nginx -n dev
Name: nginx
Namespace: dev
CreationTimestamp: Wed, 08 May 2021 11:14:14 +0800
Labels: run=nginx
Annotations: deployment.kubernetes.io/revision: 1
Selector: run=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: run=nginx
Containers:
nginx:
Image: nginx:latest
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-5ff7956ff6 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m43s deployment-controller Scaled up replicaset nginx-5ff7956ff6 to 3
# 删除
[root@master ~]# kubectl delete deploy nginx -n dev
deployment.apps "nginx" deleted
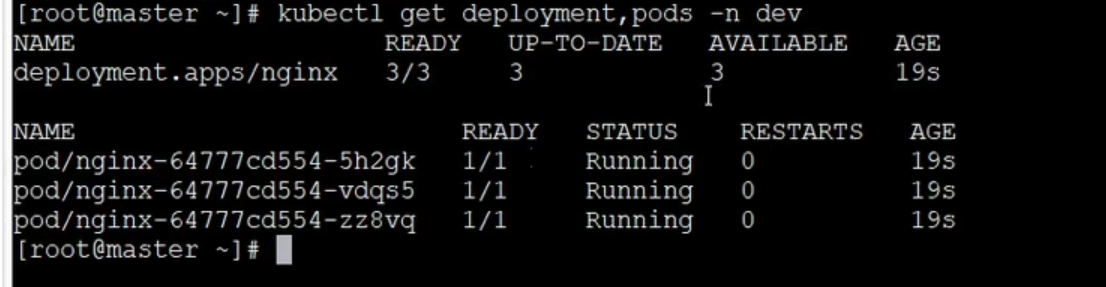
Verifique que el nombre del espacio de nombres sea la implementación y el pod en desarrollo
kubectl get deployment,pods -n dev
operación de configuración
Cree un deployment-nginx.yaml con el siguiente contenido:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
replicas: 3 # pod个数
selector:
matchLabels:
run: nginx #标签名,与下边pod的的labels一致时,Deployment才能与下边的pod挂钩
template: #pod模版,下边就是pod信息
metadata:
labels:
run: nginx
spec:
containers:
- image: nginx:latest
name: nginx
ports:
- containerPort: 80
protocol: TCP
Luego puede ejecutar los comandos de creación y eliminación correspondientes:
Crear: kubectl create -f deployment-nginx.yaml
Eliminar: kubectl delete -f deployment-nginx.yaml
1.5 Servicio
A través del estudio del capítulo anterior, ha podido utilizar la implementación para crear un conjunto de pods para brindar servicios con alta disponibilidad.
Aunque a cada Pod se le asignará una IP de Pod separada, hay dos problemas de la siguiente manera:
- La IP del pod cambiará a medida que se reconstruya el pod (el pod se reconstruirá automáticamente después de que se cuelgue, y la IP del pod cambiará después de la reconstrucción)
- La IP del pod es solo una IP virtual visible en el clúster y no se puede acceder a ella desde el exterior
Esto dificulta el acceso al servicio. Por lo tanto, Kubernetes diseñó Service para resolver este problema.
El servicio puede considerarse como una interfaz de acceso externo para un grupo de Pods del mismo tipo . Con Service, las aplicaciones pueden implementar fácilmente el descubrimiento de servicios y el equilibrio de carga.
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-NAr8AEPV-1640144981807)(Kubenetes.assets/image-20200408194716912.png)]](https://img-blog.csdnimg.cn/36223bf37ee94f70bbb713e7ba7e84d5.png)
Operación 1: crear un servicio accesible dentro del clúster
# 暴露Service service的80端口与pod的80端口做映射 --name:service名称 --type:类型有很多,后边会讲
[root@master ~]# kubectl expose deploy nginx --name=svc-nginx1 --type=ClusterIP --port=80 --target-port=80 -n dev
service/svc-nginx1 exposed
# 查看service 查看所有srvice:kubectl get svc -n dev
[root@master ~]# kubectl get svc svc-nginx1 -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
svc-nginx1 ClusterIP 10.109.179.231 <none> 80/TCP 3m51s run=nginx
# 这里产生了一个CLUSTER-IP,这就是service的IP,在Service的生命周期中,这个地址是不会变动的
# 可以通过这个IP访问当前service对应的POD
[root@master ~]# curl 10.109.179.231:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
.......
</body>
</html>
Operación 2: crear un servicio al que también se pueda acceder fuera del clúster
# 上面创建的Service的type类型为ClusterIP,这个ip地址只用集群内部可访问
# 如果需要创建外部也可以访问的Service,需要修改type为NodePort
[root@master ~]# kubectl expose deploy nginx --name=svc-nginx2 --type=NodePort --port=80 --target-port=80 -n dev
service/svc-nginx2 exposed
# 此时查看,会发现出现了NodePort类型的Service,而且有一对Port(80:31928/TC)
[root@master ~]# kubectl get svc svc-nginx2 -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
svc-nginx2 NodePort 10.100.94.0 <none> 80:31928/TCP 9s run=nginx
# 接下来就可以通过集群外的主机访问 节点IP:31928访问服务了
# 例如在的电脑主机上通过浏览器访问下面的地址
http://192.168.5.4:31928/
Eliminar servicio
[root@master ~]# kubectl delete svc svc-nginx-1 -n dev service "svc-nginx-1" deleted
método de configuración
Cree un svc-nginx.yaml con el siguiente contenido:
apiVersion: v1
kind: Service
metadata:
name: svc-nginx
namespace: dev
spec:
clusterIP: 10.109.179.231 #固定svc的内网ip
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: ClusterIP
Luego puede ejecutar los comandos de creación y eliminación correspondientes:
Crear: kubectl create -f svc-nginx.yaml
Eliminar: kubectl delete -f svc-nginx.yaml
resumen
Hasta ahora, ha dominado las operaciones básicas de los recursos de espacio de nombres, pod, implementación y servicio. Con estas operaciones, puede implementar una implementación simple y acceder a un servicio en un clúster de kubernetes, pero si desea utilizar mejor kubernetes, necesita Conoce en profundidad los detalles y la razón de ser de cada uno de estos recursos.
Explicación detallada de Two Pod
2.1 Introducción a la cápsula
2.1.1 Estructura de la cápsula
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-wYmYRjwK-1640144981808)(Kubenetes.assets/image-20200407121501907-1626781151898.png)]](https://img-blog.csdnimg.cn/999d5de5a0e449ea8e1ffb15a5f4a7b2.png)
Cada Pod puede contener uno o más contenedores, que se pueden dividir en dos categorías:
-
El número de contenedores donde residen los programas de usuario puede ser grande o pequeño
-
El contenedor Pause, que es un contenedor raíz que tendrá cada Pod , tiene dos funciones:
-
Se puede utilizar como base para evaluar el estado de salud de todo el Pod.
-
Puede configurar la dirección IP en el contenedor raíz, y otros contenedores comparten esta IP (IP del Pod) para realizar la comunicación de red dentro del Pod (el mundo exterior también puede acceder a cada contenedor en el pod a través de esta IP más diferentes puertos)
这里是Pod内部的通讯,Pod的之间的通讯采用虚拟二层网络技术来实现,我们当前环境用的是Flannel
-
2.1.2 Definición de pod
La siguiente es la lista de recursos de Pod:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,资源类型,例如 Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认为"default"
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {
} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
#小提示:
# 在这里,可通过一个命令来查看每种资源的可配置项
# kubectl explain 资源类型 查看某种资源可以配置的一级属性
# kubectl explain 资源类型.属性 查看属性的子属性
[root@k8s-master01 ~]# kubectl explain pod
KIND: Pod
VERSION: v1
FIELDS:
apiVersion <string>
kind <string>
metadata <Object>
spec <Object>
status <Object>
[root@k8s-master01 ~]# kubectl explain pod.metadata
KIND: Pod
VERSION: v1
RESOURCE: metadata <Object>
FIELDS:
annotations <map[string]string>
clusterName <string>
creationTimestamp <string>
deletionGracePeriodSeconds <integer>
deletionTimestamp <string>
finalizers <[]string>
generateName <string>
generation <integer>
labels <map[string]string>
managedFields <[]Object>
name <string>
namespace <string>
ownerReferences <[]Object>
resourceVersion <string>
selfLink <string>
uid <string>
En kubernetes, los atributos de primer nivel de básicamente todos los recursos son los mismos, e incluyen principalmente 5 partes:
- versión de apiVersion, definida internamente por kubernetes, el número de versión debe consultarse con kubectl api-versions
- kind type, definido internamente por kubernetes, el número de versión debe consultarse con kubectl api-resources
- metadatos Los metadatos, principalmente la identificación y descripción de recursos, comúnmente utilizados son nombre, espacio de nombres, etiquetas, etc.
- La descripción detallada de la especificación, que es la parte más importante de la configuración, contiene descripciones detalladas de varias configuraciones de recursos
- estado información de estado, el contenido interno no necesita ser definido, es generado automáticamente por kubernetes
Entre los atributos anteriores, la especificación es el foco de la próxima investigación, continúe observando sus subatributos comunes:
- contenedores <[]Objeto> lista de contenedores, utilizada para definir los detalles del contenedor
- nodeName envía el pod al nodo Node especificado de acuerdo con el valor de nodeName
- nodeSelector <map[]> De acuerdo con la información definida en NodeSelector, seleccione para programar el Pod al Nodo que contiene estas etiquetas
- hostNetwork Ya sea para usar el modo de red de host, el valor predeterminado es falso, si se establece en verdadero, significa usar la red de host
- volumes <[]Object> Volumen de almacenamiento, utilizado para definir la información de almacenamiento montada en el Pod
- restartPolicy Estrategia de reinicio, que indica la estrategia de procesamiento del Pod cuando encuentra una falla
2.2 Configuración de módulos
Esta sección estudia principalmente pod.spec.containerslos atributos, que también es la configuración más crítica en la configuración de pod.
[root@k8s-master01 ~]# kubectl explain pod.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object> # 数组,代表可以有多个容器
FIELDS:
name <string> # 容器名称
image <string> # 容器需要的镜像地址
imagePullPolicy <string> # 镜像拉取策略
command <[]string> # 容器的启动命令列表,如不指定,使用打包时使用的启动命令
args <[]string> # 容器的启动命令需要的参数列表
env <[]Object> # 容器环境变量的配置
ports <[]Object> # 容器需要暴露的端口号列表
resources <Object> # 资源限制和资源请求的设置
2.2.1 Configuración básica
Cree un archivo pod-base.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labels:
user: heima
spec:
containers: #定义两个容器,一个是nginx,一个是busybox
- name: nginx # 前边有-,代表下边有相同的配置
image: nginx:1.17.1 # 本地没有该镜像的话,会自动去远程仓库下载(具体下载策略下边会讲)
- name: busybox # 一个小的linux命令集合工具
image: busybox:1.30
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-eTE5oSNI-1640144981809)(Kubenetes.assets/image-20210617223823675-1626781695411.png)]](https://img-blog.csdnimg.cn/beebbf3f7d2e476d99fbd9ab992a549d.png)
La configuración de un Pod relativamente simple se define arriba, que contiene dos contenedores:
- nginx: Creado con la imagen nginx de la versión 1.17.1, (nginx es un contenedor web ligero)
- busybox: Creado con la imagen de busybox versión 1.30, (busybox es una pequeña colección de comandos de Linux)
# 创建Pod
[root@k8s-master01 pod]# kubectl apply -f pod-base.yaml
pod/pod-base created
# 查看Pod状况
# READY 1/2 : 表示当前Pod中有2个容器,其中1个准备就绪,1个未就绪
# RESTARTS : 重启次数,因为有1个容器故障了,Pod一直在重启试图恢复它(下边的重启次数是4了)
[root@k8s-master01 pod]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pod-base 1/2 Running 4 95s
# 可以通过describe查看内部的详情
# 此时已经运行起来了一个基本的Pod,虽然它暂时有问题
[root@k8s-master01 pod]# kubectl describe pod pod-base -n dev
2.2.2 Extracción de imágenes
Cree un archivo pod-imagepullpolicy.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-imagepullpolicy #不能有大写字母
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
imagePullPolicy: Never # 用于设置镜像拉取策略(never:一直用本地镜像)
- name: busybox
image: busybox:1.30
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-QP6BM4hG-1640144981809)(Kubenetes.assets/image-20210617223923659.png)]](https://img-blog.csdnimg.cn/77d64be8a6434758bfb7023d9aebe261.png)
imagePullPolicy, utilizada para establecer la política de extracción de imágenes, kubernetes admite la configuración de tres políticas de extracción:
- Siempre: Extraiga siempre la imagen del almacén remoto (siempre descargue de forma remota; incluso si es local, debe descargarse de forma remota)
- IfNotPresent: use la imagen local si está disponible localmente y extraiga la imagen del almacén remoto si no está disponible localmente (si la imagen está disponible localmente, no se descargará de forma remota si la imagen tiene un número de versión específico)
- Nunca: solo use la imagen local, nunca vaya al almacén remoto para extraer, si no hay una imagen local, se informará un error (siempre use la imagen local)
Descripción de los valores predeterminados:
Si la etiqueta de imagen es un número de versión específico, la política predeterminada es: IfNotPresent
Si la etiqueta de la imagen es: más reciente (versión final), la política predeterminada siempre es
# 创建Pod
[root@k8s-master01 pod]# kubectl create -f pod-imagepullpolicy.yaml
pod/pod-imagepullpolicy created
# 查看Pod详情
# 此时明显可以看到nginx镜像有一步Pulling image "nginx:1.17.1"的过程
[root@k8s-master01 pod]# kubectl describe pod pod-imagepullpolicy -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1
Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1"
Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1"
Normal Created 26s kubelet, node1 Created container nginx
Normal Started 25s kubelet, node1 Started container nginx
Normal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 7s (x3 over 25s) kubelet, node1 Created container busybox
Normal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
2.2.3 Comando de inicio
En el caso anterior, siempre ha habido un problema que no se ha resuelto, es decir, el contenedor de busybox no se ha ejecutado con éxito, entonces, ¿qué causó la falla de este contenedor?
Resulta que busybox no es un programa, sino una colección de herramientas. Después de iniciar y administrar el clúster de kubernetes, se cerrará automáticamente. La solución es mantenerlo en ejecución (bucle infinito), que utiliza la configuración del comando.
Cree un archivo pod-command.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-pKDMBF1C-1640144981810)(Kubenetes.assets/image-20210617224457945.png)]](https://img-blog.csdnimg.cn/358d9750c6ce4c378374b799774200b4.png)
comando, que se usa para ejecutar un comando después de inicializar el contenedor en el pod.
Explique un poco el significado del comando anterior:
"/bin/sh", "-c", use sh para ejecutar el comando
toque /tmp/hello.txt, cree un archivo /tmp/hello.txt
while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done; Escribe la hora actual en el archivo cada 3 segundos
# 创建Pod
[root@k8s-master01 pod]# kubectl create -f pod-command.yaml
pod/pod-command created
# 查看Pod状态
# 此时发现两个pod都正常运行了
[root@k8s-master01 pod]# kubectl get pods pod-command -n dev
NAME READY STATUS RESTARTS AGE
pod-command 2/2 Runing 0 2s
# 进入pod中的busybox容器,查看文件内容
# 补充一个命令: kubectl exec pod名称 -n 命名空间 -it -c 容器名称 /bin/sh 在容器内部执行命令
# 使用这个命令就可以进入某个容器的内部,然后进行相关操作了
# 比如,可以查看txt文件的内容
[root@k8s-master01 pod]# kubectl exec pod-command -n dev -it -c busybox /bin/sh
/ # tail -f /tmp/hello.txt
14:44:19
14:44:22
14:44:25
特别说明:
通过上面发现command已经可以完成启动命令和传递参数的功能,为什么这里还要提供一个args选项,用于传递参数呢?这其实跟docker有点关系,kubernetes中的command、args两项其实是实现覆盖Dockerfile中ENTRYPOINT的功能。
1 如果command和args均没有写,那么用Dockerfile的配置。
2 如果command写了,但args没有写,那么Dockerfile默认的配置会被忽略,执行输入的command
3 如果command没写,但args写了,那么Dockerfile中配置的ENTRYPOINT的命令会被执行,使用当前args的参数
4 如果command和args都写了,那么Dockerfile的配置被忽略,执行command并追加上args参数
2.2.4 Variables de entorno
Cree un archivo pod-env.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-env
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do /bin/echo $(date +%T);sleep 60; done;"]
env: # 设置环境变量列表(下边设置了两个环境变量)
- name: "username"
value: "admin"
- name: "password"
value: "123456"
env: variables de entorno, utilizadas para establecer variables de entorno en los contenedores del pod.
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-env.yaml
pod/pod-env created
# 进入容器,输出环境变量
[root@k8s-master01 ~]# kubectl exec pod-env -n dev -c busybox -it /bin/sh
/ # echo $username
admin
/ # echo $password
123456
Este método no es muy recomendable, se recomienda almacenar estas configuraciones por separado en el archivo de configuración, que se presentará más adelante.
2.2.5 Configuración del puerto
Esta sección presenta la configuración de puertos del contenedor, es decir, la opción de puertos de los contenedores.
Primero mire las subopciones compatibles con los puertos:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:
name <string> # 端口名称,如果指定,必须保证name在pod中是唯一的
containerPort<integer> # 容器要监听的端口(0<x<65536),重点掌握,使用pod的ip加这个端口来访问
hostPort <integer> # 容器要在主机上公开的端口,如果设置,主机上只能运行容器的一个副本(一般省略)
hostIP <string> # 要将外部端口绑定到的主机IP(一般省略)
protocol <string> # 端口协议。必须是UDP、TCP或SCTP。默认为“TCP”。
Luego, escriba un caso de prueba, cree pod-ports.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports: # 设置容器暴露的端口列表
- name: nginx-port
containerPort: 80 #以后使用pod的ip加这个端口来访问容器里的程序
protocol: TCP
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-ports.yaml
pod/pod-ports created
# 查看pod
# 在下面可以明显看到配置信息
[root@k8s-master01 ~]# kubectl get pod pod-ports -n dev -o yaml
......
spec:
containers:
- image: nginx:1.17.1
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: nginx-port
protocol: TCP
......
Para acceder al programa en el contenedor, necesita usar elPodip:containerPort
2.2.6 Cuotas de recursos
Para ejecutar un programa en un contenedor, debe ocupar ciertos recursos, como CPU y memoria. Si los recursos de un contenedor no están limitados, puede consumir una gran cantidad de recursos, lo que hace que otros contenedores no se ejecuten. En respuesta a esta situación, kubernetes proporciona un mecanismo para cuotas de recursos de memoria y cpu.Este mecanismo se implementa principalmente a través de la opción de recursos, que tiene dos subopciones:
- límites: se utiliza para limitar el uso máximo de recursos del contenedor de tiempo de ejecución. Cuando el uso de recursos del contenedor supera los límites, se terminará y se reiniciará
- solicitudes: se utiliza para establecer los recursos mínimos requeridos por el contenedor.Si los recursos del entorno no son suficientes, el contenedor no podrá iniciarse.
Los límites superior e inferior de los recursos se pueden establecer a través de las dos opciones anteriores.
Luego, escriba un caso de prueba, cree pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # 资源配额
limits: # 限制资源(上限)
cpu: "2" # CPU限制,单位是core数
memory: "10Gi" # 内存限制
requests: # 请求资源(下限)
cpu: "1" # CPU限制,单位是core数
memory: "10Mi" # 内存限制
Aquí hay una descripción de las unidades de CPU y memoria:
- cpu: número de núcleo, puede ser entero o decimal
- memoria: tamaño de la memoria, puede usar Gi, Mi, G, M, etc.
# 运行Pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# 查看发现pod运行正常
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev
NAME READY STATUS RESTARTS AGE
pod-resources 1/1 Running 0 39s
# 接下来,停止Pod
[root@k8s-master01 ~]# kubectl delete -f pod-resources.yaml
pod "pod-resources" deleted
# 编辑pod,修改resources.requests.memory的值为10Gi
[root@k8s-master01 ~]# vim pod-resources.yaml
# 再次启动pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# 查看Pod状态,发现Pod启动失败
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev -o wide
NAME READY STATUS RESTARTS AGE
pod-resources 0/1 Pending 0 20s
# 查看pod详情会发现,如下提示
[root@k8s-master01 ~]# kubectl describe pod pod-resources -n dev
......
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had taint {
node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.(内存不足)
2.3 Ciclo de vida de la vaina
Generalmente nos referimos al período de tiempo desde la creación del objeto pod hasta el final como el ciclo de vida del pod, que incluye principalmente los siguientes procesos:
- proceso de creación de cápsulas
- Ejecute el proceso de contenedor de inicio
- Ejecutar el contenedor principal (contenedor principal)
- Enganche después del inicio del contenedor (después del inicio), enganche antes de la terminación del contenedor (antes de la parada)
- Sonda de actividad del contenedor (sonda de actividad), sonda de preparación (sonda de preparación)
- proceso de terminación de pod

A lo largo del ciclo de vida, el Pod aparecerá en cinco estados ( fases ), de la siguiente manera:
- Pendiente: el servidor ap ha creado el objeto de recurso del pod, pero no se ha programado o aún está en proceso de descargar la imagen.
- En ejecución (En ejecución): el pod se programó para un nodo y el kubelet creó todos los contenedores.
- Correcto: todos los contenedores del pod terminaron correctamente y no se reiniciarán
- Error: todos los contenedores terminaron, pero al menos un contenedor no pudo terminar, es decir, el contenedor devolvió un estado de salida distinto de cero
- Desconocido (Unknown): el servidor ap normalmente no puede obtener la información de estado del objeto pod, generalmente causado por una falla en la comunicación de la red
2.3.1 Creación y Terminación
proceso de creación de cápsulas
-
El usuario envía la información del pod que se creará a apiServer a través de kubectl u otros clientes api
-
apiServer comienza a generar la información del objeto pod, almacena la información en etcd y luego devuelve un mensaje de confirmación al cliente (el mensaje no se devuelve cuando la creación es exitosa, pero se devuelve cuando se inicia la creación)
-
El apiServer comienza a reflejar los cambios del objeto pod en etcd, y otros componentes usan el mecanismo de observación para rastrear y verificar los cambios en el apiServer.
-
El programador encuentra que hay un nuevo objeto de pod para crear, comienza a asignar hosts al pod y actualiza la información de resultados a apiServer
-
El kubelet en el nodo del nodo encuentra que se envió un pod, intenta llamar a la ventana acoplable para iniciar el contenedor y envía el resultado de regreso a apiServer
-
apiServer almacena la información de estado del pod recibido en etcd
proceso de terminación de pod
- El usuario envía un comando a apiServer para eliminar el objeto pod
- La información del objeto pod en apiServer se actualizará con el tiempo. Durante el período de gracia (predeterminado 30 s), el pod se considera inactivo.
- Marcar el pod como terminado
- El kubelet inicia el proceso de apagado del pod mientras supervisa que el objeto del pod cambie al estado de terminación
- Cuando el controlador de puntos finales supervisa el comportamiento de apagado del objeto pod, se eliminará de la lista de puntos finales de todos los recursos de servicio que coincidan con este punto final.
- Si el objeto de pod actual define un procesador de enlace preStop, comenzará a ejecutarse de forma síncrona después de que se marque como de terminación
- El proceso contenedor en el objeto pod recibió una señal de parada
- Una vez que finaliza el período de gracia, si todavía hay procesos en ejecución en el pod, el objeto del pod recibirá una señal de terminación inmediata.
- Kubelet solicita a apiServer que establezca el período de gracia de este recurso de pod en 0 para completar la operación de eliminación. En este momento, el pod ya no es visible para el usuario.
2.3.2 Inicializar el contenedor
El contenedor de inicialización es un contenedor que se ejecutará antes de que se inicie el contenedor principal del pod. Principalmente realiza un trabajo previo para el contenedor principal. Tiene dos características:
- El contenedor de inicialización debe ejecutarse hasta el final. Si un contenedor de inicialización no se ejecuta, entonces kubernetes debe reiniciarlo hasta que se complete correctamente.
- Los contenedores de inicialización deben ejecutarse en el orden definido, y el siguiente puede ejecutarse solo después de que el anterior tenga éxito
Hay muchos escenarios de aplicación para inicializar contenedores, los más comunes se enumeran a continuación:
- Proporcione utilidades o código personalizado que no están presentes en la imagen del contenedor principal
- El contenedor de inicialización se inicia y ejecuta en serie antes que el contenedor de la aplicación, por lo que se puede usar para retrasar el inicio del contenedor de la aplicación hasta que se cumplan las condiciones de las que depende.
A continuación, haga un caso para simular el siguiente requisito:
Suponga que desea ejecutar nginx como contenedor principal, pero debe poder conectarse al servidor donde se encuentran mysql y redis antes de ejecutar nginx.
Para simplificar la prueba, las direcciones de los servidores mysql (192.168.5.4)y redis se especifican de antemano(192.168.5.5)
Cree pod-initcontainer.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers:
- name: test-mysql
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.5.14 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.5.15 -c 1 ; do echo waiting for reids...; sleep 2; done;']
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created
# 查看pod状态
# 发现pod卡在启动第一个初始化容器过程中,后面的容器不会运行
root@k8s-master01 ~]# kubectl describe pod pod-initcontainer -n dev
........
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1
Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 48s kubelet, node1 Created container test-mysql
Normal Started 48s kubelet, node1 Started container test-mysql
# 动态查看pod
[root@k8s-master01 ~]# kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
pod-initcontainer 0/1 Init:1/2 0 52s
pod-initcontainer 0/1 Init:1/2 0 53s
pod-initcontainer 0/1 PodInitializing 0 89s
pod-initcontainer 1/1 Running 0 90s
# 接下来新开一个shell,为当前服务器新增两个ip,观察pod的变化
[root@k8s-master01 ~]# ifconfig ens33:1 192.168.5.14 netmask 255.255.255.0 up
[root@k8s-master01 ~]# ifconfig ens33:2 192.168.5.15 netmask 255.255.255.0 up
2.3.3 Función de gancho
La función gancho puede percibir los eventos en su propio ciclo de vida y ejecutar el código del programa especificado por el usuario cuando llegue el momento correspondiente.
Kubernetes proporciona dos funciones de enlace después de iniciar y antes de detener el contenedor principal:
- post inicio: se ejecuta después de que se crea el contenedor, si falla, el contenedor se reiniciará
- pre stop: ejecutado antes de que finalice el contenedor, el contenedor finalizará correctamente después de que se complete la ejecución, y la operación de eliminación del contenedor se bloqueará antes de que se complete
El controlador de gancho admite las siguientes tres formas de definir acciones:
-
Comando Exec: Ejecutar un comando en el contenedor (usado más)
…… lifecycle: postStart: exec: command: - cat - /tmp/healthy …… -
TCPSocket: intenta acceder al socket especificado en el contenedor actual
…… lifecycle: postStart: tcpSocket: port: 8080 …… -
HTTPGet: inicie una solicitud http a una URL en el contenedor actual
…… lifecycle: postStart: httpGet: path: / #URI地址 port: 80 #端口号 host: 192.168.5.3 #主机地址 scheme: HTTP #支持的协议,http或者https ……
A continuación, tome el método exec como ejemplo para demostrar el uso de la función de gancho y cree un archivo pod-hook-exec.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # 在容器启动的时候执行一个命令,修改掉nginx的默认首页内容
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # 在容器停止之前停止nginx服务
command: ["/usr/sbin/nginx","-s","quit"]
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-hook-exec.yaml
pod/pod-hook-exec created
# 查看pod
[root@k8s-master01 ~]# kubectl get pods pod-hook-exec -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2
# 访问pod
[root@k8s-master01 ~]# curl 10.244.2.48
postStart...
2.3.4 Detección de contenedores
La detección de contenedores se utiliza para detectar si la instancia de la aplicación en el contenedor funciona con normalidad y es un mecanismo tradicional para garantizar la disponibilidad comercial. Si después de la detección, el estado de la instancia no cumple con las expectativas, Kubernetes "eliminará" la instancia problemática y no soportará el tráfico comercial. Kubernetes proporciona dos sondas para implementar la detección de contenedores, a saber:
- sondas de actividad: sondas de actividad, utilizadas para detectar si la instancia de la aplicación se está ejecutando actualmente con normalidad; si no, k8s reiniciará el contenedor
- Sondeos de preparación: sondeos de preparación, utilizados para detectar si la instancia de la aplicación puede recibir solicitudes actualmente; si no, k8s no reenviará el tráfico
livenessProbe decide si reiniciar el contenedor y readinessProbe decide si reenvía la solicitud al contenedor.
Las dos sondas anteriores actualmente admiten tres métodos de detección:
-
Comando Exec: Ejecuta un comando en el contenedor, si el código de salida de la ejecución del comando es 0, el programa se considera normal, de lo contrario es anormal
…… livenessProbe: exec: command: - cat - /tmp/healthy …… -
TCPSocket: Intentará acceder al puerto de un contenedor de usuarios, si se puede establecer esta conexión, el programa se considera normal, de lo contrario no es normal
…… livenessProbe: tcpSocket: port: 8080 …… -
HTTPGet: llama a la URL de la aplicación web en el contenedor. Si el código de estado devuelto está entre 200 y 399, el programa se considera normal, de lo contrario es anormal.
…… livenessProbe: httpGet: path: / #URI地址 port: 80 #端口号 host: 127.0.0.1 #主机地址 scheme: HTTP #支持的协议,http或者https ……
Tomemos las sondas de vida como ejemplo para hacer algunas demostraciones:
Método 1: Ejecutivo
Crear pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # 执行一个查看文件的命令
Crea una cápsula y observa el efecto.
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created
# 查看Pod详情
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-exec -n dev
......
Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx
Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx
Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted
Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory
# 观察上面的信息就会发现nginx容器启动之后就进行了健康检查
# 检查失败之后,容器被kill掉,然后尝试进行重启(这是重启策略的作用,后面讲解)
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~]# kubectl get pods pod-liveness-exec -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个存在的文件,比如/tmp/hello.txt,再试,结果就正常了......
Método 2: TCPSocket
Crear pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # 尝试访问8080端口
Crea una cápsula y observa el efecto.
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created
# 查看Pod详情
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-tcpsocket -n dev
......
Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2
Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machine
Normal Created <invalid> kubelet, node2 Created container nginx
Normal Started <invalid> kubelet, node2 Started container nginx
Warning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused
# 观察上面的信息,发现尝试访问8080端口,但是失败了
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~]# kubectl get pods pod-liveness-tcpsocket -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个可以访问的端口,比如80,再试,结果就正常了......
Método 3: HTTPObtener
Crear pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet: # 其实就是访问http://127.0.0.1:80/hello
scheme: HTTP #支持的协议,http或者https
port: 80 #端口号
path: /hello #URI地址
Crea una cápsula y observa el efecto.
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created
# 查看Pod详情
[root@k8s-master01 ~]# kubectl describe pod pod-liveness-httpget -n dev
.......
Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine
Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx
Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx
Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted
# 观察上面信息,尝试访问路径,但是未找到,出现404错误
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@k8s-master01 ~]# kubectl get pod pod-liveness-httpget -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 1/1 Running 5 3m17s
# 当然接下来,可以修改成一个可以访问的路径path,比如/,再试,结果就正常了......
Hasta ahora, liveness Probe se ha utilizado para demostrar tres métodos de detección, pero al observar las subpropiedades de livenessProbe, encontrará que, además de estos tres métodos, existen otras configuraciones, que se explican aquí:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.livenessProbe
FIELDS:
exec <Object>
tcpSocket <Object>
httpGet <Object>
initialDelaySeconds <integer> # 容器启动后等待多少秒执行第一次探测
timeoutSeconds <integer> # 探测超时时间。默认1秒,最小1秒
periodSeconds <integer> # 执行探测的频率。默认是10秒,最小1秒
failureThreshold <integer> # 连续探测失败多少次才被认定为失败。默认是3。最小值是1
successThreshold <integer> # 连续探测成功多少次才被认定为成功。默认是1
Configuremos dos ligeramente a continuación para demostrar el efecto:
[root@k8s-master01 ~]# more pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /
initialDelaySeconds: 30 # 容器启动后30s开始探测
timeoutSeconds: 5 # 探测超时时间为5s
2.3.5 Estrategia de reinicio
En la sección anterior, una vez que haya un problema con la detección del contenedor, Kubernetes reiniciará el Pod donde se encuentra el contenedor. De hecho, esto está determinado por la estrategia de reinicio del pod. Hay tres estrategias de reinicio para el pod, de la siguiente manera :
- Siempre: cuando el contenedor falla, el contenedor se reinicia automáticamente, que también es el valor predeterminado.
- OnFailure: reiniciar cuando el contenedor termina y el código de salida no es 0 (no 0: terminación anormal)
- Nunca: no reinicie el contenedor independientemente del estado.
La política de reinicio se aplica a todos los contenedores en el objeto pod. El contenedor que debe reiniciarse por primera vez se reiniciará inmediatamente cuando deba reiniciarse, y kubelet retrasará la operación que debe reiniciarse por un período de tiempo, y el tiempo de retraso de las operaciones de reinicio repetido se basa en este 10s, 20s, 40s, 80s, 160s y 300s, 300s es el tiempo de retraso máximo.
Crea pod-restartpolicy.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-restartpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # 设置重启策略为Never
ejecutar prueba de vaina
# 创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created
# 查看Pod详情,发现nginx容器失败
[root@k8s-master01 ~]# kubectl describe pods pod-restartpolicy -n dev
......
Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 15s kubelet, node1 Container nginx failed liveness probe
# 多等一会,再观察pod的重启次数,发现一直是0,并未重启
[root@k8s-master01 ~]# kubectl get pods pod-restartpolicy -n dev
NAME READY STATUS RESTARTS AGE
pod-restartpolicy 0/1 Running 0 5min42s
2.4 Programación de pods
De forma predeterminada, el componente Programador calcula en qué nodo se ejecuta un Pod mediante el algoritmo correspondiente, y este proceso no está sujeto a control manual. Pero en el uso real, esto no satisface las necesidades, porque en muchos casos, queremos controlar ciertos Pods para llegar a ciertos nodos, entonces, ¿cómo debemos hacerlo? Esto requiere comprender las reglas de programación de kubernetes para pods. kubernetes proporciona cuatro tipos de métodos de programación:
- Programación automática: el programador calcula completamente el nodo en el que se ejecutará a través de una serie de algoritmos
- Programación dirigida: NodeName, NodeSelector
- Programación de afinidad: NodeAffinity, PodAffinity, PodAntiAffinity
- Programación de corrupción (tolerancia): corrupción, tolerancia
2.4.1 Programación dirigida
La programación dirigida se refiere a programar el pod en el nodo deseado declarando nodeName o nodeSelector en el pod. Tenga en cuenta que la programación aquí es obligatoria, lo que significa que incluso si el nodo de destino que se va a programar no existe, se programará para él, pero el pod no se ejecutará.
Nombre del nodo
NodeName se usa para aplicar restricciones para programar pods en el nodo Node del nombre especificado. De esta forma, la lógica de programación del Programador se omite directamente y el Pod se programa directamente en el nodo con el nombre especificado.
A continuación, experimente: cree un archivo pod-nodename.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 把当前pod,指定调度到node1节点上
#创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 1/1 Running 0 56s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeName的值为node3(并没有node3节点)
[root@k8s-master01 ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@k8s-master01 ~]# vim pod-nodename.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在node3节点,所以pod无法正常运行
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 0/1 Pending 0 6s <none> node3 ......
Selector de nodos
NodeSelector se usa para programar pods para nodos de nodos con etiquetas específicas. Se implementa a través del mecanismo de selección de etiquetas de kubernetes, es decir, antes de que se cree el pod, el programador utilizará la estrategia de programación MatchNodeSelector para realizar la coincidencia de etiquetas, encontrar el nodo de destino y luego programar el pod para el destino. Esta regla de coincidencia es una restricción obligatoria.
A continuación, experimente:
1 Primero agregue etiquetas a los nodos de nodo respectivamente
[root@k8s-master01 ~]# kubectl label nodes node1 nodeenv=pro
node/node2 labeled
[root@k8s-master01 ~]# kubectl label nodes node2 nodeenv=test
node/node2 labeled
2 Cree un archivo pod-nodeselector.yaml y utilícelo para crear Pods
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # 指定调度到具有nodeenv=pro标签的节点上
#创建Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@k8s-master01 ~]# kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeselector 1/1 Running 0 47s 10.244.1.87 node1 ......
# 接下来,删除pod,修改nodeSelector的值为nodeenv: xxxx(不存在打有此标签的节点)
[root@k8s-master01 ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@k8s-master01 ~]# vim pod-nodeselector.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#再次查看,发现pod无法正常运行,Node的值为none
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none>
# 查看详情,发现node selector匹配失败的提示
[root@k8s-master01 ~]# kubectl describe pods pod-nodeselector -n dev
.......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
2.4.2 Programación de afinidad
En la sección anterior, se introdujeron dos métodos de programación direccional, que son muy convenientes de usar, pero hay ciertos problemas, es decir, si no hay un Nodo que cumpla con las condiciones, el Pod no se ejecutará, incluso si hay un lista de Nodos disponibles en el clúster No, esto limita sus escenarios de uso.
Basado en los problemas anteriores, kubernetes también proporciona una programación de afinidad (Afinidad). Se ha ampliado en base a NodeSelector, mediante el formulario de configuración se puede seleccionar preferentemente para programación el Nodo que cumpla las condiciones, en caso contrario también se podrá programar a los nodos que no cumplan las condiciones, haciendo la programación mas flexible.
La afinidad se divide principalmente en tres categorías:
- nodeAffinity (afinidad de nodo): apunte al nodo para resolver el problema de a qué nodos se puede programar el pod
- podAffinity (afinidad de pod): con pod como objetivo, resuelva el problema de qué pods se pueden implementar en el mismo dominio de topología que los pods existentes
- podAntiAffinity (anti-afinidad de pod): Apunte a los pods para resolver el problema de que los pods no se pueden implementar en el mismo dominio de topología que los pods existentes
Explicación de los escenarios de uso de afinidad (antiafinidad):
Afinidad : si dos aplicaciones interactúan con frecuencia, es necesario usar la afinidad para que las dos aplicaciones estén lo más cerca posible, lo que puede reducir la pérdida de rendimiento causada por la comunicación de red.
Antiafinidad : cuando la aplicación se implementa con múltiples copias, es necesario usar antiafinidad para distribuir cada instancia de la aplicación en cada nodo, lo que puede mejorar la alta disponibilidad del servicio.
NodoAfinidad
Primero mire NodeAffinitylos elementos configurables:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可以,相当于硬限制
nodeSelectorTerms 节点选择列表
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当于软限制 (倾向)
preference 一个节点选择器项,与相应的权重相关联
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
关系符的使用说明:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"
A continuación, demostremos primero requiredDuringSchedulingIgnoredDuringExecution,
Crear pod-nodeaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
nodeAffinity: #设置node亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
nodeSelectorTerms:
- matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 查看pod状态 (运行失败)
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ......
# 查看Pod的详情
# 发现调度失败,提示node选择失败
[root@k8s-master01 ~]# kubectl describe pod pod-nodeaffinity-required -n dev
......
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
#接下来,停止pod
[root@k8s-master01 ~]# kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted
# 修改文件,将values: ["xxx","yyy"]------> ["pro","yyy"]
[root@k8s-master01 ~]# vim pod-nodeaffinity-required.yaml
# 再次启动
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 此时查看,发现调度成功,已经将pod调度到了node1上
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 11s 10.244.1.89 node1 ......
A continuación, demostremos de nuevo requiredDuringSchedulingIgnoredDuringExecution,
Crear pod-nodeaffinity-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-preferred
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
nodeAffinity: #设置node亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软限制
- weight: 1
preference:
matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签(当前环境没有)
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-preferred.yaml
pod/pod-nodeaffinity-preferred created
# 查看pod状态 (运行成功)
[root@k8s-master01 ~]# kubectl get pod pod-nodeaffinity-preferred -n dev
NAME READY STATUS RESTARTS AGE
pod-nodeaffinity-preferred 1/1 Running 0 40s
NodeAffinity规则设置的注意事项:
1 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能运行在指定的Node上
2 如果nodeAffinity指定了多个nodeSelectorTerms,那么只需要其中一个能够匹配成功即可
3 如果一个nodeSelectorTerms中有多个matchExpressions ,则一个节点必须满足所有的才能匹配成功
4 如果一个pod所在的Node在Pod运行期间其标签发生了改变,不再符合该Pod的节点亲和性需求,则系统将忽略此变化
Pod Affinity
PodAffinity implementa principalmente la función de usar el Pod en ejecución como referencia para hacer que el Pod recién creado y el Pod de referencia estén en la misma área.
Primero mire PodAffinitylos elementos configurables:
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬限制
namespaces 指定参照pod的namespace
topologyKey 指定调度作用域
labelSelector 标签选择器
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist.
matchLabels 指多个matchExpressions映射的内容
preferredDuringSchedulingIgnoredDuringExecution 软限制
podAffinityTerm 选项
namespaces
topologyKey
labelSelector
matchExpressions
key 键
values 值
operator
matchLabels
weight 倾向权重,在范围1-100
topologyKey用于指定调度时作用域,例如:
如果指定为kubernetes.io/hostname,那就是以Node节点为区分范围
如果指定为beta.kubernetes.io/os,则以Node节点的操作系统类型来区分
A continuación, demostración requiredDuringSchedulingIgnoredDuringExecution,
1) Primero crea un Pod de referencia, pod-podaffinity-target.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: dev
labels:
podenv: pro #设置标签
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 将目标pod名确指定到node1上
# 启动目标pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# 查看pod状况
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s
2) Cree pod-podaffinity-required.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: podenv
operator: In
values: ["xxx","yyy"]
topologyKey: kubernetes.io/hostname
La configuración anterior significa que el nuevo pod debe estar en el mismo nodo que el pod con la etiqueta nodeenv=xxx o nodeenv=yyy. Obviamente, no existe tal pod ahora. A continuación, ejecute la prueba.
# 启动pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 查看pod状态,发现未运行
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s
# 查看详细信息
[root@k8s-master01 ~]# kubectl describe pods pod-podaffinity-required -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"]
# 意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@k8s-master01 ~]# vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果
[root@k8s-master01 ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" deleted
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 发现此时Pod运行正常
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>
Sobre PodAffinity, preferredDuringSchedulingIgnoredDuringExecutionno se demostrará aquí.
PodAntiAffinity antiafinidad
PodAntiAffinity implementa principalmente la función de usar el Pod en ejecución como referencia, de modo que el Pod recién creado y el Pod de referencia no estén en la misma área.
Su método de configuración y sus opciones son las mismas que las de PodAffinty, por lo que no lo explicaré en detalle aquí, solo haré un caso de prueba.
1) Continúe usando el módulo de destino en el caso anterior
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE LABELS
pod-podaffinity-required 1/1 Running 0 3m29s 10.244.1.38 node1 <none>
pod-podaffinity-target 1/1 Running 0 9m25s 10.244.1.37 node1 podenv=pro
2) Cree pod-podantiaffinity-required.yaml con el siguiente contenido:
apiVersion: v1
kind: Pod
metadata:
name: pod-podantiaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAntiAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配podenv的值在["pro"]中的标签
- key: podenv
operator: In
values: ["pro"]
topologyKey: kubernetes.io/hostname
La configuración anterior significa que el nuevo pod no debe estar en el mismo nodo que el pod con la etiqueta nodeenv=pro. Ejecute la prueba.
# 创建pod
[root@k8s-master01 ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created
# 查看pod
# 发现调度到了node2上
[root@k8s-master01 ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96 node2 ..
2.4.3 Corrupciones y tolerancias
Manchas
Los métodos de programación anteriores son todos desde la perspectiva del Pod, agregando atributos al Pod para determinar si el Pod debe programarse para el Nodo especificado; de hecho, también podemos pararnos en la perspectiva del Nodo, agregando la mancha atributo al Nodo , para decidir si permitir la programación de Pod.
Después de que el Nodo está contaminado, hay una relación repulsiva con el Pod, y luego se niega a programar el Pod, e incluso el Pod existente puede ser expulsado.
El formato de la corrupción es: key=value:effect, la clave y el valor son las etiquetas de la corrupción, y el efecto describe el efecto de la corrupción. Se admiten las siguientes tres opciones:
- PreferNoSchedule: kubernetes intentará evitar programar pods en nodos con esta contaminación a menos que no haya otros nodos para programar
- NoSchedule: kubernetes no programará pods en nodos con esta mancha, pero no afectará a los pods existentes en el nodo actual.
- NoExecute: kubernetes no programará pods en nodos con esta contaminación y también eliminará los pods existentes en los nodos.

Los siguientes son ejemplos de comandos para establecer y eliminar contaminaciones con kubectl:
# 设置污点
kubectl taint nodes node1 key=value:effect
# 去除污点
kubectl taint nodes node1 key:effect-
# 去除所有污点
kubectl taint nodes node1 key-
A continuación, demuestre el efecto de la mancha:
- Prepare el nodo nodo1 (para que el efecto de demostración sea más evidente, detenga temporalmente el nodo nodo2)
- Establezca una mancha para el nodo node1:
tag=heima:PreferNoScheduleluego cree pod1 (pod1 está bien) - Modifique para establecer una contaminación para el nodo node1:
tag=heima:NoScheduleluego cree pod2 (pod1 normal pod2 falla) - Modifique para establecer una contaminación para el nodo node1:
tag=heima:NoExecuteluego cree pod3 (los 3 pods fallan)
# 为node1设置污点(PreferNoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:PreferNoSchedule
# 创建pod1
[root@k8s-master01 ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
# 为node1设置污点(取消PreferNoSchedule,设置NoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:PreferNoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoSchedule
# 创建pod2
[root@k8s-master01 ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods taint2 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
taint2-544694789-6zmlf 0/1 Pending 0 21s <none> <none>
# 为node1设置污点(取消NoSchedule,设置NoExecute)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:NoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoExecute
# 创建pod3
[root@k8s-master01 ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
taint1-7665f7fd85-htkmp 0/1 Pending 0 35s <none> <none> <none>
taint2-544694789-bn7wb 0/1 Pending 0 35s <none> <none> <none>
taint3-6d78dbd749-tktkq 0/1 Pending 0 6s <none> <none> <none>
Sugerencia:
un clúster creado con kubeadm agregará una marca de contaminación al nodo principal de forma predeterminada, por lo que los pods no se programarán en el nodo principal.
kubectl describe node master
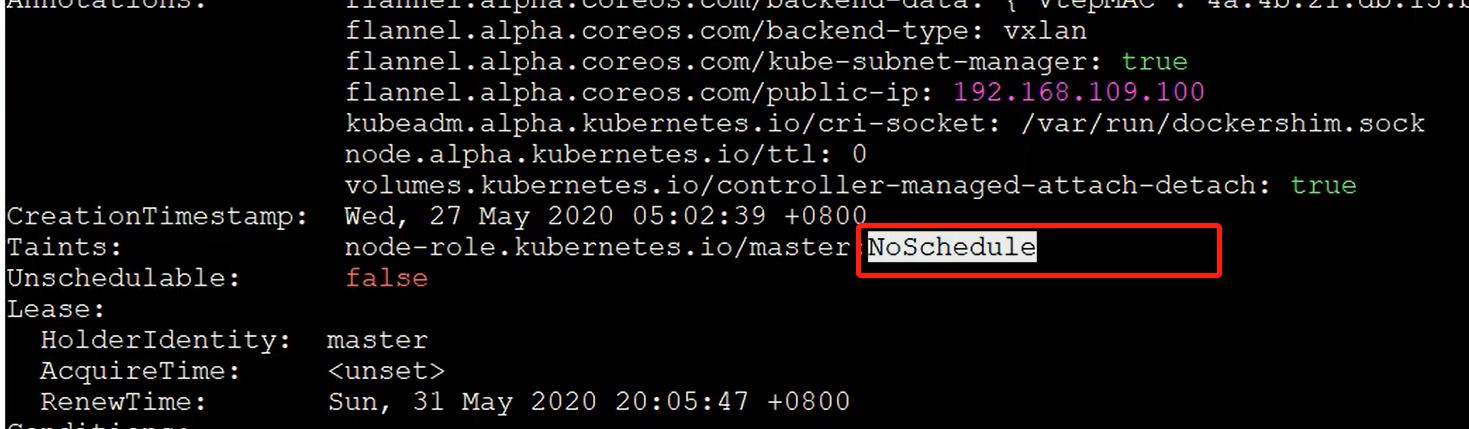
Tolerancia
La función de taint se presentó anteriormente. Podemos agregar taint al nodo para rechazar la programación del pod. Pero si solo queremos programar un pod en un nodo con taint, ¿qué debemos hacer en este momento? Aquí es donde se utiliza la tolerancia . (El lado izquierdo de abajo es la tolerancia)
![[Falló la transferencia de la imagen del enlace externo, el sitio de origen puede tener un mecanismo anti-leeching, se recomienda guardar la imagen y cargarla directamente (img-9WS3UtrQ-1640144981812)(Kubenetes.assets/image-20200514095913741.png)]](https://img-blog.csdnimg.cn/ebfd107361b74081bed57ed9358d7ced.png)
Stain significa rechazo y tolerancia significa ignorar. El nodo rechaza la programación del pod a través de la corrupción, y el Pod rechaza a través de la tolerancia y la ignorancia.
Echemos un vistazo al efecto a través de un caso:
- En la sección anterior, la mancha se ha marcado en el nodo nodo 1.
NoExecuteEn este momento, el pod no se puede programar. - En esta sección, puede agregar tolerancia al pod y luego programarlo
Cree pod-toleration.yaml con el siguiente contenido
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
tolerations: # 添加容忍
- key: "tag" # 要容忍的污点的key
operator: "Equal" # 操作符
value: "heima" # 容忍的污点的value
effect: "NoExecute" # 添加容忍的规则,这里必须和标记的污点规则相同
# 添加容忍之前的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 0/1 Pending 0 3s <none> <none> <none>
# 添加容忍之后的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 1/1 Running 0 3s 10.244.1.62 node1 <none>
Echemos un vistazo a la configuración detallada de la tolerancia:
[root@k8s-master01 ~]# kubectl explain pod.spec.tolerations
......
FIELDS:
key # 对应着要容忍的污点的键,空意味着匹配所有的键
value # 对应着要容忍的污点的值
operator # key-value的运算符,支持Equal和Exists(默认)
effect # 对应污点的effect,空意味着匹配所有影响
tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间