prefacio
PointNet++ es una red neuronal profunda para tareas de clasificación y segmentación de datos de nubes de puntos de forma irregular. En comparación con los métodos tradicionales de representación de datos 3D basados en cuadrículas, los datos de la nube de puntos son más fáciles de adquirir y procesar. Otra ventaja de PointNet++ es que introduce una jerarquía de múltiples escalas que puede manejar datos de nubes de puntos más complejos. En comparación con la primera versión de PointNet, el autor propuso muchas ideas nuevas y logró muy buenos resultados.
Problemas con el algoritmo PointNet
(1) Hay demasiados puntos en una imagen de nube de puntos, lo que provocará un cálculo excesivo y reducirá la velocidad del algoritmo ¿Cómo solucionarlo?
(2) ¿Cómo dividir la nube de puntos en diferentes regiones y obtener las características locales de diferentes regiones?
(3) ¿Cómo solucionar este problema cuando la nube de puntos es desigual?
Con estas preguntas en mente, comenzamos a resolver estos problemas a través de artículos y código fuente.
tarea de clasificación
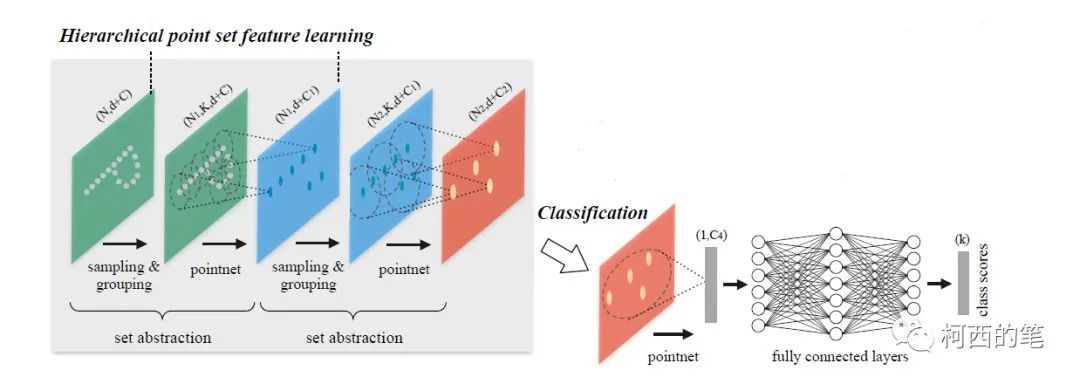
Abstracción del conjunto de características de extracción jerárquica
Este módulo consta principalmente de 3 partes:
1. Capa de muestreo (capa de muestra): algunos puntos relativamente importantes se extraen de la nube de puntos densa como el punto central, es decir, el método de muestreo del punto más lejano FPS (muestreo de punto más lejano), también para resolver el primer problema de este artículo.
2. Capa de grupo (capa de grupo): encuentre los K puntos más cercanos al punto central para formar una región de puntos locales. Esta operación es un poco como la convolución de imágenes: forma una imagen convolucional para facilitar la extracción de características. Resuelve el segundo problema.
3. Capa de extracción de características (capa de red de puntos): capa de extracción de características. Extraiga características para cada región de puntos locales.
El proceso de FPS es el siguiente:
(1) Seleccione aleatoriamente un punto como punto de muestreo inicial;
(2) Calcule la distancia entre cada punto en el conjunto de puntos de muestreo no seleccionado y el conjunto de puntos de muestreo seleccionado, y agregue el punto con la distancia más grande al conjunto de puntos de muestreo seleccionado,
(3) Calcule la distancia de acuerdo con los nuevos puntos de muestreo e itere continuamente hasta obtener el número objetivo de puntos de muestreo.
Como se muestra en la figura siguiente, se seleccionan 5 puntos de todos los puntos.

El código se implementa de la siguiente manera.
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) #[b,npoint] #npoint是要从很多的点中筛选出那么多
distance = torch.ones(B, N).to(device) * 1e10 #[b,N] #N指原来有N个点
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) #[b] 在0-N中随机生成了B个点(随机选了个点作为初始点,并且用的索引
batch_indices = torch.arange(B, dtype=torch.long).to(device) #[b] 0-b
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) #获得索引对应的位置的坐标
dist = torch.sum((xyz - centroid) ** 2, -1) #计算所有坐标和目前这个点的距离
mask = dist < distance #距离符合要求的
distance[mask] = dist[mask] #将符合要求的距离都放入
farthest = torch.max(distance, -1)[1] #最远距离对应的索引 [b]
return centroids #最终输出筛选的[n,npoint]个点的位置El flujo de la capa de paquetes es el siguiente:
(1) Obtenga el punto central correspondiente después de la detección según FPS
(2) Utilice cada punto central en el conjunto de origen para filtrar la cantidad de puntos necesarios cerca según la distancia y forme un nuevo conjunto de puntos centrado en cada punto FPS
(3) El nuevo conjunto de puntos realizará una operación similar a la normalización de coordenadas para formar 3 características nuevas y luego se combinará con las características originales de cada punto para formar nuevas características antes de la extracción de características.
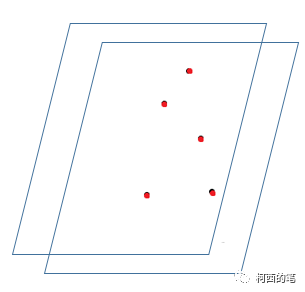
El diagrama simplificado es el siguiente:
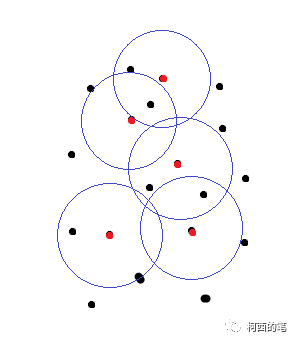
Figura 1
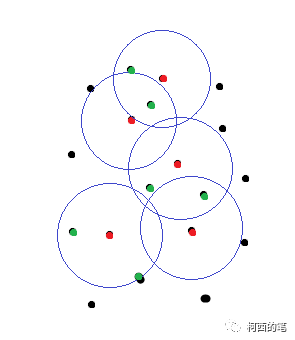
Figura II
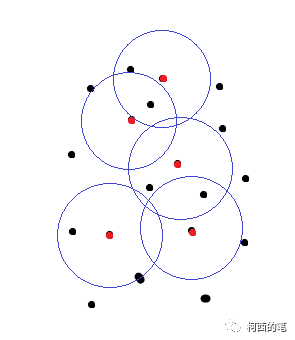
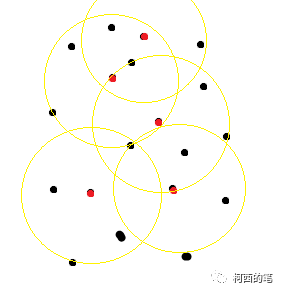
En la Figura 1, el punto rojo es el punto central del resultado de FPS y los puntos negros son algunos puntos iniciales. Los puntos verdes en la Figura 2 son los puntos filtrados según la distancia, y estos puntos y los puntos rojos formarán una serie de conjuntos de puntos.
En la capa de agrupación, el autor propone tres esquemas: SSG (agrupación de escala única), MSG (agrupación de múltiples escalas) multiescala y MRG (agrupación de múltiples resoluciones) multiresolución. De hecho, se realizan múltiples grupos de muestreo con diferentes radios o diferentes resoluciones. También es para resolver el tercer problema de este artículo.
SSG: Equivale al muestreo grupal con un solo radio
MSG: equivale a muestrear múltiples grupos de radios con la misma resolución y luego combinar los conjuntos de puntos.
resonancia magnética
El código se implementa de la siguiente manera.
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
"""
1.预设搜索区域的半径R与子区域的点数K
2.上面提取出来了 s 个点,作为 s个centriods。以这 s个点为球心,画半径为R的球体(叫做query ball,也就是搜索区域)。
3.在每个以centriods的球心的球体内搜索离centriods最近的的点(按照距离从小到大排序,找到K个点)。
如果query ball的点数量大于规模nsample,那么直接取前nsample个作为子区域;如果小于,那么直接对某个点重采样(此处直接复制了第一个点),凑够规模nsample
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1]) #[2,512,1024]
sqrdists = square_distance(new_xyz, xyz) #获得采样后点集与原先点集的距离[2,512,1024]
group_idx[sqrdists > radius ** 2] = N #将距离比半径大的,将此处置为1024
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample] #因为是0-1023的索引,不符合要求的变味了1024,再对索引排序,获得前nsample个 [b,s,nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample]) #拿了符合要求的第一个索引点索引,也就是中心点,并且复制了nsample次 [b,s,nsample]
mask = group_idx == N #查看那前nsample中有没有不符合要求的
group_idx[mask] = group_first[mask] #其中将不符合要求的点,全部换成符合要求的第一个点
return group_idx
def sample_and_group(npoint, radius, nsample, xyz, points, returnfps=False):
"""
Input:
npoint:
radius:
nsample:
xyz: input points position data, [B, N, 3]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, npoint, nsample, 3]
new_points: sampled points data, [B, npoint, nsample, 3+D]
"""
B, N, C = xyz.shape
S = npoint
fps_idx = farthest_point_sample(xyz, npoint) # [B, npoint] #FPS最远点采样算法 获得需要点的索引
new_xyz = index_points(xyz, fps_idx) # [B, npoint,c] #将对应索引的点拿出来
idx = query_ball_point(radius, nsample, xyz, new_xyz) #[b,npoint,nsample] #进行query_ball处理,类似于卷积操作,找到new_xyz附近原xyz的nsample个点,返回对应的索引[b,npoint,nsample]
grouped_xyz = index_points(xyz, idx) # [B, npoint, nsample, C] #将对应索引的点拿出来
grouped_xyz_norm = grouped_xyz - new_xyz.view(B, S, 1, C) #每个点减去自己半径内中心的那个点进行归一化[B, npoint, nsample, C]
if points is not None: #points即原来点就存才的一些特征
grouped_points = index_points(points, idx) #将每个区域原先的特征拿出来 [b,npoint,nsample,D]
new_points = torch.cat([grouped_xyz_norm, grouped_points], dim=-1) # [B, npoint, nsample, C+D] #将归一化数据和原先的特征结合
else:
new_points = grouped_xyz_norm #如果原先没有特征的,那么数据就是归一化后的点
if returnfps:
return new_xyz, new_points, grouped_xyz, fps_idx
else:
return new_xyz, new_pointscapa de extracción de características
Esta capa son algunas operaciones básicas de agrupación convolucional. Al final, las características de puntos seleccionadas por FPS aumentarán.

Repita la capa de abstracción establecida varias veces y finalmente conecte algunas redes completamente conectadas para clasificar la nube de puntos.
dividir tarea
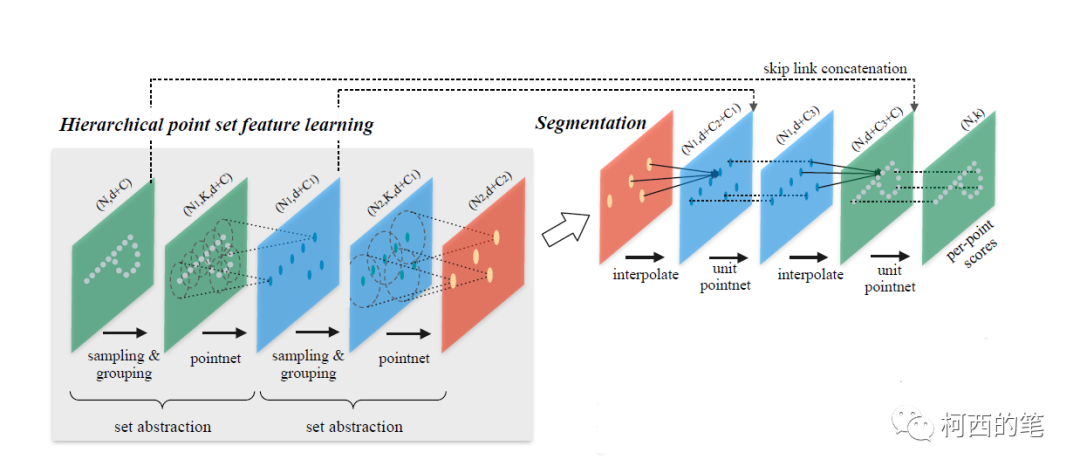
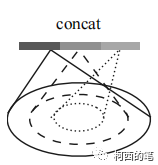
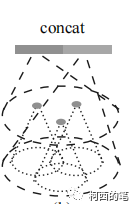
El extractor de características de la tarea de segmentación es el mismo que el de la tarea de clasificación, a continuación hablaremos principalmente del enlace de muestreo ascendente. El autor propone una estrategia de propagación de características jerárquica basada en la interpolación de distancia.
El proceso general es el siguiente:
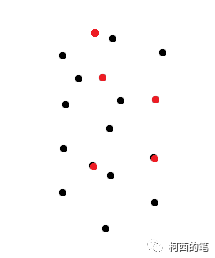
(1) Calcule el peso del promedio ponderado de distancia inversa, como se muestra en la siguiente figura: el punto rojo es el punto después de la extracción de características de FPS; de hecho, la cantidad de características del punto rojo será mayor que la del punto negro. punto. Y el muestreo ascendente consiste en hacer que estos puntos negros también produzcan características coincidentes.
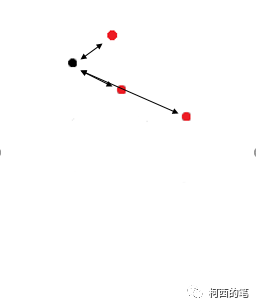
Cálculo de peso: para cada punto negro, busque los 3 puntos rojos más cercanos y luego asigne características al punto negro de acuerdo con el peso de la distancia en cada punto rojo. Entonces cada punto negro generará nuevas características. El punto rojo también debe hacer lo mismo. Es decir, todos los puntos de la figura anterior generarán nuevas funciones.


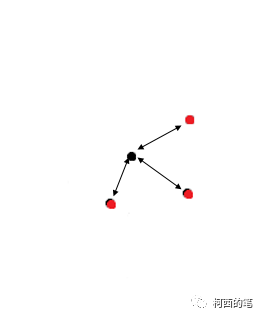
(2) Las nuevas características generadas son operadas por cat con las características de la capa anterior, y luego la fusión de características se completa mediante convolución. Finaliza el muestreo ascendente en un solo paso.
El código se implementa de la siguiente manera.
class PointNetFeaturePropagation(nn.Module): #上采样
def __init__(self, in_channel, mlp):
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N] 上一层的
xyz2: sampled input points position data, [B, C, S] 现在层的
points1: input points data, [B, D1, N] 上一层的
points2: input points data, [B, D2, S] 现在层的
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2) #计算两点集各点之间距离[b,N,S]
dists, idx = dists.sort(dim=-1) #排序
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3] 获得距离最近的3点
dist_recip = 1.0 / (dists + 1e-8)
norm = torch.sum(dist_recip, dim=2, keepdim=True)
weight = dist_recip / norm #根据距离设置权重
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2) #[B,N,D2]
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1) #上采样cat [B,N,D1+D2]
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1) #[B,D1+D2,N]
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points #[B, D', N]¡Hasta ahora, el análisis del artículo sobre PointNet ++ ha terminado! Si hay alguna mala interpretación, bienvenido a criticar y corregir, ¡progresemos juntos!