Tabla de contenido
contenido frontal
P1: En la programación concurrente, ¿qué tipos de tareas encontramos habitualmente?
Respuesta: Por lo general, hay: informática intensiva (intensiva en CPU), intensiva en IO
P2: ¿Cuál es la diferencia entre ellos?
respuesta:Las tareas informáticas intensivas se caracterizan por una gran cantidad de cálculos que consumen recursos de la CPU.Como calcular pi, decodificar video de alta definición, etc., todos dependen de la potencia informática de la CPU.Aunque este tipo de tarea informática intensiva también se puede completar mediante la multitarea, cuantas más tareas hay, más tiempo se dedica al cambio de tareas y menor es la eficiencia de las tareas de ejecución de la CPU., por lo tanto, para hacer el uso más eficiente de la CPU, la cantidad de tareas computacionalmente intensivas realizadas simultáneamente debe ser igual a la cantidad de núcleos de la CPU.
Dado que las tareas informáticas intensivas consumen principalmente recursos de la CPU, la eficiencia de la ejecución del código es muy importante. Los lenguajes de scripting como Python se ejecutan de manera muy ineficiente y son totalmente inadecuados para tareas computacionales intensivas. Para tareas computacionalmente intensivas, es mejor escribirlo en C.
Intensivo en IO. Las tareas que involucran IO de red y disco son todas tareas intensivas en IO. Este tipo de tarea se caracteriza por un bajo consumo de CPU y la mayor parte del tiempo de la tarea está esperando a que se completen las operaciones de IO.(Porque la velocidad de IO es mucho menor que la velocidad de la CPU y la memoria).Para tareas con uso intensivo de IO, cuantas más tareas, mayor será la eficiencia de la CPU, pero hay un límite. Las tareas más comunes son las que requieren un uso intensivo de IO, como las aplicaciones web.
Durante la ejecución de tareas intensivas de IO, el 99% del tiempo se dedica a IO y muy poco tiempo a la CPU, por lo que es completamente imposible reemplazar un lenguaje de script como Python con un lenguaje C de ejecución extremadamente rápida. Mejorar la eficiencia operativa. Para tareas intensivas en IO, el lenguaje más adecuado es el lenguaje con la mayor eficiencia de desarrollo (la menor cantidad de código), el lenguaje de secuencias de comandos es la primera opción y el lenguaje C es el peor.
Contenido del curso
1. Pensamientos desencadenados por un problema de algoritmo
1. Preguntas de algoritmos
Hay una pregunta de algoritmo titulada: [¿Cómo aprovechar al máximo el rendimiento de las CPU de múltiples núcleos para ordenar rápidamente una matriz de 20 millones de tamaño? ]
Cuando se trata de algoritmos de clasificación, supongo que todos quedarán algo impresionados; después de todo, muchas entrevistas ocasionalmente preguntarán. Por ejemplo: clasificación por burbujas, clasificación por selección, clasificación rápida, etc. Pero en este volumen de 2KW, obviamente no es aplicable. Quizás los amigos más experimentados hayan pensado en una forma, es decir, el método de clasificación por fusión.
Sí, aquí hay algo que quiero presentar [método de clasificación por fusión].
2. ¿Qué es la ordenación por combinación?
Merge Sort (Merge Sort) es un algoritmo de clasificación basado en divide y vencerás. La idea básica de la ordenación por combinación es dividir una matriz grande en
dos submatrices de igual tamaño, ordenar cada submatriz por separado y luego fusionar las dos submatrices en una matriz ordenada grande.
Debido a que a menudo se usa la implementación recursiva (determinada por la naturaleza de dividir y luego fusionar), lo llamamos clasificación por fusión.
Los pasos de la ordenación por combinación incluyen los siguientes tres pasos:
- Dividir una matriz en dos submatrices
- Ordenar cada subarreglo
- Fusionar dos subarreglos ordenados
La complejidad temporal de la ordenación por fusión es O (nlogn) y la complejidad espacial es O (n), donde n es la longitud de la matriz.
Por supuesto, hay una explicación más académica:
La idea de divide y vencerás es descomponer un problema de tamaño N en K subproblemas más pequeños,Estos subproblemas son independientes entre sí y
tienen la misma naturaleza que el problema original.. Encontrar la solución al subproblema le dará la solución al problema original.
Los pasos para dividir y conquistar el pensamiento son los siguientes:
- Descomposición: Dividir el problema a resolver en varios problemas más pequeños del mismo tipo;
- Resolución: cuando los subproblemas se dividen en lo suficientemente pequeños, utilice métodos más simples para resolverlos;
- Fusión: de acuerdo con los requisitos del problema original, las soluciones de los subproblemas se combinan capa por capa para formar la solución del problema original.
Los diez algoritmos informáticos clásicos de clasificación por combinación, clasificación rápida y búsqueda binaria son todos algoritmos implementados en base a la idea de dividir y conquistar. El
diagrama del modelo de tarea de dividir y conquistar es el siguiente:
Aquí, el algoritmo de clasificación por fusión se utiliza para implementar simplemente este problema de algoritmo. El código es el siguiente:
public class MergeSort {
private final int[] arrayToSort; //要排序的数组
private final int threshold; //拆分的阈值,低于此阈值就不再进行拆分
public MergeSort(final int[] arrayToSort, final int threshold) {
this.arrayToSort = arrayToSort;
this.threshold = threshold;
}
/**
* 排序
* @return
*/
public int[] sequentialSort() {
return sequentialSort(arrayToSort, threshold);
}
public static int[] sequentialSort(final int[] arrayToSort, int threshold) {
//拆分后的数组长度小于阈值,直接进行排序
if (arrayToSort.length < threshold) {
//调用jdk提供的排序方法
Arrays.sort(arrayToSort);
return arrayToSort;
}
int midpoint = arrayToSort.length / 2;
//对数组进行拆分
int[] leftArray = Arrays.copyOfRange(arrayToSort, 0, midpoint);
int[] rightArray = Arrays.copyOfRange(arrayToSort, midpoint, arrayToSort.length);
//递归调用
leftArray = sequentialSort(leftArray, threshold);
rightArray = sequentialSort(rightArray, threshold);
//合并排序结果
return merge(leftArray, rightArray);
}
public static int[] merge(final int[] leftArray, final int[] rightArray) {
//定义用于合并结果的数组
int[] mergedArray = new int[leftArray.length + rightArray.length];
int mergedArrayPos = 0;
int leftArrayPos = 0;
int rightArrayPos = 0;
while (leftArrayPos < leftArray.length && rightArrayPos < rightArray.length) {
if (leftArray[leftArrayPos] <= rightArray[rightArrayPos]) {
mergedArray[mergedArrayPos] = leftArray[leftArrayPos];
leftArrayPos++;
} else {
mergedArray[mergedArrayPos] = rightArray[rightArrayPos];
rightArrayPos++;
}
mergedArrayPos++;
}
while (leftArrayPos < leftArray.length) {
mergedArray[mergedArrayPos] = leftArray[leftArrayPos];
leftArrayPos++;
mergedArrayPos++;
}
while (rightArrayPos < rightArray.length) {
mergedArray[mergedArrayPos] = rightArray[rightArrayPos];
rightArrayPos++;
mergedArrayPos++;
}
return mergedArray;
}
public static void main(String[] args) {
// 初始化一个2KW的数组
Random random = new Random();
int[] arrays = new int[20000000];
for (int i = 0; i < 20000000; i++) {
arrays[i] = random.nextInt(5);
}
long start1 = System.currentTimeMillis();
// 开始拆分排序
MergeSort mergeSort = new MergeSort(arrays, 100000);
mergeSort.sequentialSort();
System.out.println("任务总耗时:wasteTime=" + (System.currentTimeMillis() - start1));
}
// 系统输出:
// 任务总耗时:wasteTime=921
}
Se puede ver que el consumo de tiempo total es: 921 ms (esto todavía es relativamente bueno para mi computadora),
creo que todos pueden ver que 921 ms aquí parece ser bueno, entonces, ¿qué pasa si la escala de datos es mayor? Puedo decirles a todos con responsabilidad que en ese momento no será una simple acumulación, puede ser un crecimiento exponencial. Y es posible que los amigos cuidadosos ya hayan visto que el código anterior se ejecuta completamente en un entorno de un solo subproceso (un núcleo está completamente cargado y los otros núcleos son silenciosos e insoportables con el paso de los años). ¿Es posible que en un entorno de subprocesos múltiples , ¿Funcionará mejor?
Sabemos que no importa qué optimización hagamos, de hecho, muchos propósitos son exprimir los recursos de la CPU tanto como sea posible. Como muchas de nuestras computadoras, el uso de la CPU en muchos casos es muy bajo, por lo que a los ojos de algunos grandes toros. , este El comportamiento de es un desperdicio de recursos (/cabeza de perro/cabeza de perro). Como se muestra en la siguiente imagen: 13% de uso de CPU, los capitalistas suspiran cuando lo ven, ¡qué desperdicio!
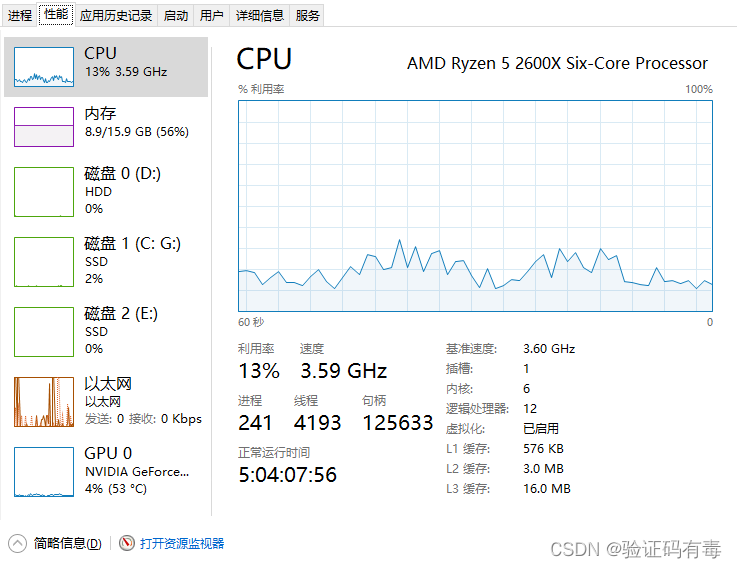
Por lo tanto, para resolver lo mencionado anteriormente [un núcleo se carga hacia adelante, los otros núcleos estarán en silencio con el tiempo] y adaptarse al [algoritmo de fusión], se propone un nuevo grupo de subprocesos ForkJoinPool.
Creo que todos tendrán preguntas: ¿grupo de subprocesos? Entonces, ¿por qué no utilizar el ThreadPoolExecutor anterior?Sólo puedo decir que realmente no funciona.! ¿por qué?
Si tiene cierto conocimiento de JVM, debe saber que por cada profundidad de llamada de función +1, el número de marcos de pila será +1 (los estudiantes interesados pueden leer mi artículo anterior [tema especial de JVM] Análisis en profundidad del modelo de memoria JVM y optimización ), por lo tanto, en este [algoritmo de fusión (recursivo)], a medida que la granularidad de la segmentación se vuelve más fina, el número de marcos de pila aumentará, lo que eventualmente resultará StackOverFlowError. O digámoslo de esta manera, en un grupo de subprocesos ordinario, si desea implementar el algoritmo de fusión, debe esperar el valor de retorno, por lo que implicará que el subproceso principal se bloquee y espere los resultados de ejecución de los subprocesos. Si las tareas se dividen en decenas de miles, incluso para cientos de miles o millones de tareas, ¿es posible que todavía necesite abrir decenas de miles, o incluso cientos de miles o millones de subprocesos? ? Incluso si lo piensas bien, es imposible que la computadora existente te lo proporcione (mira la imagen de arriba, mi computadora solo tiene más de 4000 subprocesos en funcionamiento normal).
2. ¿Qué es el marco Fork/Join?
1. Introducción básica
El marco Fork / Join es un marco proporcionado por Java7 para ejecutar tareas en paralelo. Es un marco para dividir una tarea grande en varias tareas pequeñas y, finalmente, resumir los resultados de cada tarea pequeña para obtener los resultados de la tarea grande (dividir y conquistar el pensamiento). (Fork, el significado de cuchillo y tenedor; join, el significado de conexión. Use un tenedor para separar algo y finalmente conéctelo nuevamente) Fork
es dividir una tarea grande en varias subtareas para su ejecución en paralelo, y Join es fusionar estas subtareas El resultado de la ejecución y finalmente obtenga el resultado de esta gran tarea. Por ejemplo, la informática 1+2+ ...+20000000se puede dividir en 10 subtareas, cada una de las n subtareas suma 2.000.000 de números y finalmente resume los resultados de estas 10 subtareas. Como se muestra en la siguiente figura:
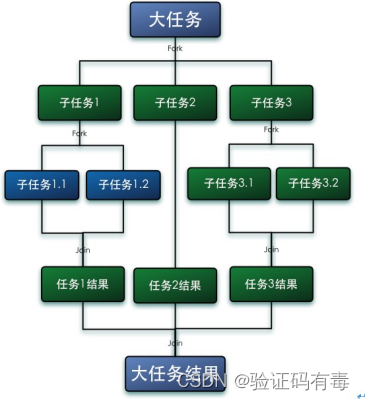
tiene los siguientes escenarios de uso clásicos:
- Tareas de descomposición recursiva
El marco Fork/Join es especialmente adecuado para tareas de descomposición recursiva, como clasificación, fusión y recorrido. Estas tareas generalmente pueden descomponer una tarea grande en varias subtareas, cada subtarea se puede ejecutar de forma independiente y los resultados de las subtareas se pueden combinar en un resultado ordenado mediante una operación de fusión. - Procesamiento de matrices
El marco Fork/Join también se puede utilizar para el procesamiento de matrices, como clasificación, búsqueda y estadísticas de matrices. Al procesar matrices grandes, el marco Fork/Join puede dividir la matriz en varios subarreglos, procesar cada subarreglo en paralelo y finalmente fusionar los subarreglos procesados en un arreglo grande ordenado. - Algoritmo paralelo
El marco Fork/Join también se puede utilizar para implementar algoritmos paralelos, como algoritmos de procesamiento de imágenes paralelos y algoritmos de aprendizaje automático paralelo. En estos algoritmos, el problema se puede descomponer en varios subproblemas, cada subproblema se resuelve en paralelo y luego los resultados de los subproblemas se combinan para obtener la solución final. - Procesamiento de big data
El marco Fork/Join también se puede utilizar para el procesamiento de big data, como el procesamiento de archivos de registro de gran tamaño, consultas de bases de datos de gran tamaño, etc. Al procesar datos grandes, los datos se pueden dividir en varios fragmentos, cada fragmento se procesa en paralelo y, finalmente, los fragmentos procesados se combinan en un resultado completo.
2.BifurcaciónJoinPool
ForkJoinPool es una clase de grupo de subprocesos en el marco Fork/Join, que se utiliza para administrar subprocesos para tareas Fork/Join. Al igual que ThreadPoolExecutoresto, también se hereda de AbstractExecutorServicela clase, por lo que tiene ThreadPoolExecutorel mismo comportamiento que enviar (), invocar (), cerrar (), awaitTermination (), etc., para enviar tareas, ejecutar tareas, cerrar grupos de subprocesos y esperar. resultado de la ejecución de la tarea. La clase ForkJoinPool también incluye algunos parámetros, como el tamaño del grupo de subprocesos, la prioridad del subproceso de trabajo, la capacidad de la cola de tareas, etc., que se pueden configurar de acuerdo con escenarios de aplicación específicos. El diagrama de clases es el siguiente:
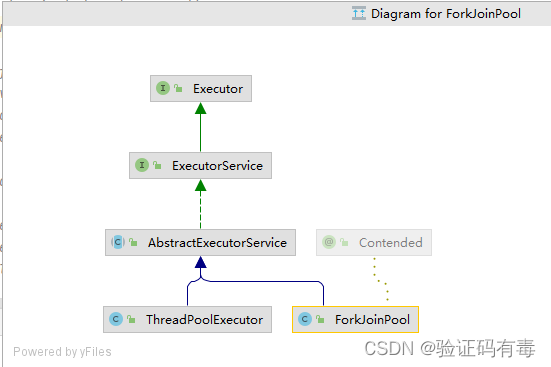
Tiene las siguientes propiedades:
- ForkJoinPool no pretende reemplazar a ExecutorService, sino complementarloEn algunos escenarios de aplicación, el rendimiento es mejor que ExecutorService;
- ForkJoinPool se utiliza principalmente para implementar el algoritmo de "divide y vencerás", especialmente las funciones llamadas recursivamente después de dividir y conquistar, como la clasificación rápida, etc.;
- ForkJoinPool es más adecuado para tareas informáticas intensivas. Si hay E / S, sincronización entre subprocesos, suspensión (), etc. que harán que los subprocesos se bloqueen durante mucho tiempo, es mejor usar ManagedBlocker.
Como se mencionó anteriormente, ForkJoinPool es un complemento de ThreadPoolExecutor: el primero es adecuado para tareas informáticas intensivas, por lo que el segundo suele ser adecuado para tareas intensivas en IO.
2. Interpretación del constructor y los parámetros de ForkJoinPool
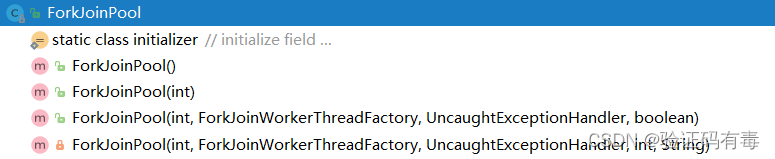
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode)
Como se muestra en el código anterior, hay 4 parámetros principales en ForkJoinPool, que se utilizan para: controlar la cantidad de subprocesos paralelos en el grupo de subprocesos, crear subprocesos de trabajo, manejar excepciones y especificar el modo de cola. Los parámetros se explican a continuación:
int parallelism: Especifica el nivel de paralelismo. ForkJoinPool determinará la cantidad de subprocesos de trabajo según esta configuración. Si no se establece, el nivel de paralelismo se establecerá mediante Runtime.getRuntime().availableProcessors();ForkJoinWorkerThreadFactory factory: Cuando ForkJoinPool crea subprocesos, se creará a través de fábrica. Tenga en cuenta que lo que debe implementarse aquí es ForkJoinWorkerThreadFactory, no ThreadFactory. Si no especifica una fábrica, la DefaultForkJoinWorkerThreadFactory predeterminada será responsable de la creación del subproceso;UncaughtExceptionHandler handler: Especifique el controlador de excepciones. Cuando la tarea cometa un error durante la ejecución, será manejada por el controlador establecido;boolean asyncMode: establece el modo de trabajo de la cola. Cuando asyncMode es verdadero, se utilizará la cola de primero en entrar, primero en salir, y cuando es falso, se utilizará el modo de último en entrar, primero en salir.
3. Método de envío de tareas
El envío de tareas es una de las capacidades principales de ForkJoinPool. Hay tres formas de enviar tareas:

4. Diagrama de principio de funcionamiento
Recuerde la imagen a continuación, el diagrama del principio de funcionamiento de ThreadPoolExecutor:
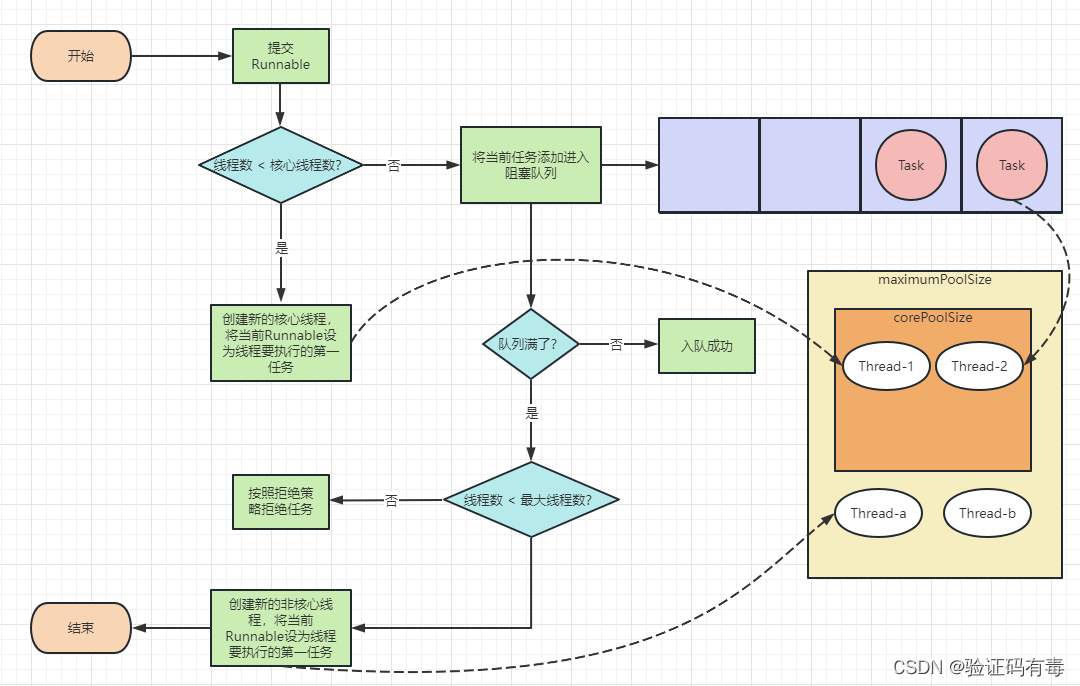
ForkJoinPool es diferente de ThreadPoolExecutor, para adaptarse a un mayor paralelismo, ha modificado el diseño de la cola de trabajo. Su diagrama esquemático es el siguiente:
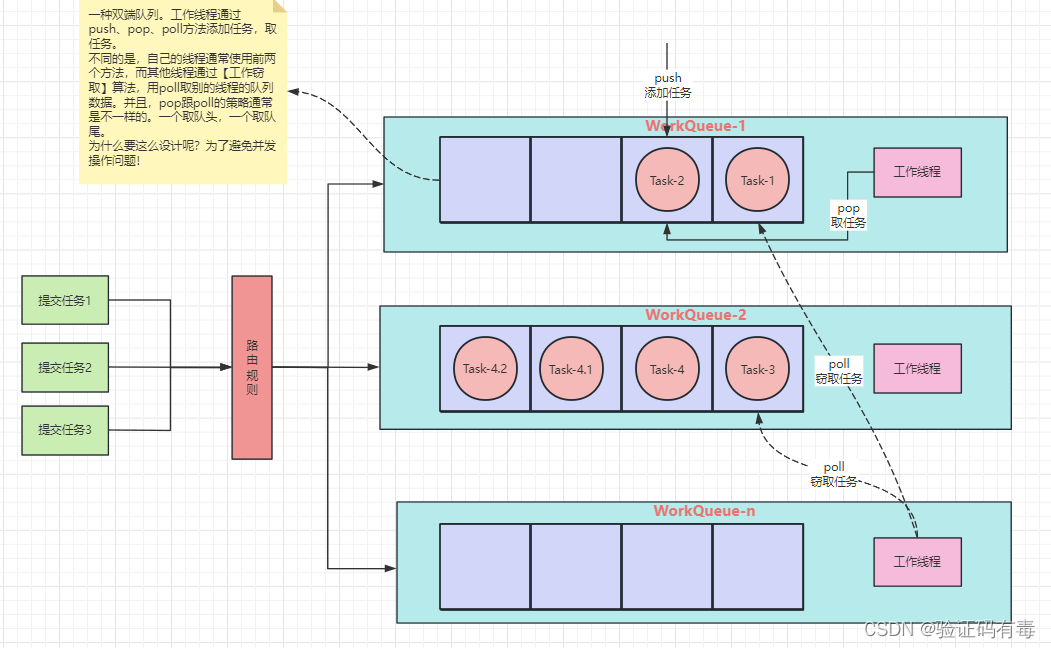
Hay múltiples colas de tareas dentro de ForkJoinPool. Cuando enviamos tareas a través del método invoke() o submit() de ForkJoinPool, ForkJoinPool envía tareas a una cola de tareas de acuerdo con ciertas reglas de enrutamiento, luego la subtarea se enviará a la cola de tareas. correspondiente al hilo de trabajo ( como en la Tarea-4 en la figura anterior, la Tarea-4.1 y la Tarea-4.2 se separan aún más mediante el método fork ).
Si la cola de tareas correspondiente al hilo de trabajo está vacía, ¿no hay trabajo que hacer? No,ForkJoinPool admite un mecanismo llamado [robo de tareas]. Si el hilo de trabajo está inactivo, puede "robar" tareas en otras colas de tareas de trabajadores.. De esta forma, todos los subprocesos de trabajo no estarán inactivos.
5. Robo de empleo
Una gran diferencia entre ForkJoinPool y ThreadPoolExecutor es que la existencia de ForkJoinPool introduce un diseño de robo de trabajo, que es una de las claves de su garantía de rendimiento. El robo de trabajo consiste en permitir que subprocesos inactivos roben tareas de la cola de doble extremo de subprocesos ocupados. De forma predeterminada, un subproceso de trabajo obtiene tareas del encabezado de su propio deque. Sin embargo, cuando su propia tarea está vacía, el subproceso obtendrá la tarea del final de la cola de otros subprocesos ocupados. Este enfoque minimiza la posibilidad de que los subprocesos compitan por las tareas.
La mayoría de las operaciones de ForkJoinPool tienen lugar en colas de robo de trabajo, que se implementan mediante la clase interna WorkQueue. Es una forma especial de Deques, pero solo admite tres operaciones: push, pop y poll (también conocido como robo). En ForkJoinPool, la lectura de la cola tiene restricciones estrictas: push y pop solo se pueden llamar desde el hilo al que pertenecen, mientras que poll se puede llamar desde otros hilos.
A través del robo de trabajo, el marco Fork/Join puedeLogre el equilibrio de carga automático de las tareas para aprovechar al máximo la potencia informática de las CPU de múltiples núcleos y, al mismo tiempo, evitar problemas de retraso y falta de subprocesos.
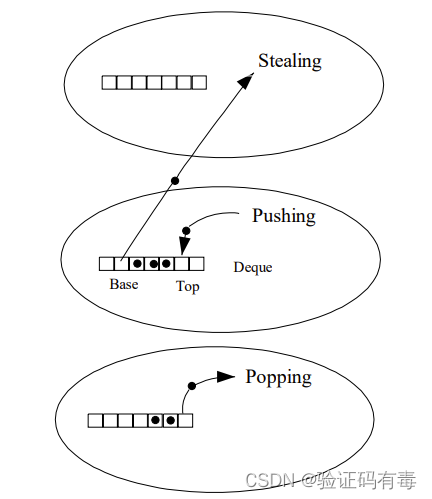
6. La diferencia entre el grupo de subprocesos comunes y
- algoritmo de robo de trabajo
ForkJoinPool utiliza colas multitarea y algoritmos de robo de trabajo para mejorar la utilización de subprocesos, mientras que el grupo de subprocesos ordinario utiliza una cola de tareas de bloqueo compartida para administrar las tareas. En el algoritmo de robo de trabajo, cuando un subproceso completa su propia tarea, puede obtener una tarea de la cola de otros subprocesos para ejecutarla, a fin de mejorar la tasa de utilización del subproceso. - Descomposición y fusión de tareas
ForkJoinPool puede descomponer una tarea grande en varias tareas pequeñas, ejecutar estas pequeñas tareas en paralelo y finalmente combinar sus resultados para obtener el resultado final. El grupo de subprocesos ordinario solo puede ejecutar tareas una por una en el orden de las tareas enviadas. - La cantidad de subprocesos de trabajo
ForkJoinPool establecerá automáticamente la cantidad de subprocesos de trabajo de acuerdo con la cantidad de núcleos de CPU en el sistema actual para maximizar la ventaja de rendimiento de la CPU. El grupo de subprocesos ordinario necesita establecer manualmente el tamaño del grupo de subprocesos. Si la configuración no es razonable, puede causar demasiados o muy pocos subprocesos, lo que afectará el rendimiento del programa. - tipo de tarea
ForkJoinPool es adecuado para realizar paralelización de tareas a gran escala, mientras que los grupos de subprocesos ordinarios son adecuados para realizar algunas tareas breves, como procesar solicitudes.
7.Tarea de unión de horquilla
ForkJoinTask es una clase abstracta en el marco Fork/Join, que define la interfaz básica para ejecutar tareas. Los usuarios pueden implementar su propia clase de tarea heredando la clase ForkJoinTask y reescribir el método compute() para definir la lógica de ejecución de la tarea. Normalmente, no necesitamos heredar directamente la clase ForkJoinTask, solo necesitamos heredar sus subclases. El marco Fork/Join proporciona las siguientes tres subclases:
RecursiveAction: para tareas que se ejecutan de forma recursiva pero que no necesitan devolver resultados.
RecursiveTask: se utiliza para ejecutar de forma recursiva tareas que necesitan devolver resultados.
CountedCompleter: se activará una función de enlace personalizada para ejecutarse después de que se complete la tarea
El núcleo de ForkJoinTask es el método fork() y el método join(), que llevan a cabo la función principal de coordinación de tareas, una para el envío de tareas y otra para la adquisición de resultados.
fork()——enviar tareas
El método fork() se utiliza para enviar tareas al grupo de subprocesos donde se está ejecutando la tarea actual. Si el subproceso actual es del tipo ForkJoinWorkerThread, se colocará en la cola de trabajo del subproceso; de lo contrario, se colocará en la cola de trabajo del grupo de subprocesos comunes.
join()——Obtener el resultado de la ejecución de la tarea
El método join() se utiliza para obtener el resultado de la ejecución de la tarea. Al llamar a join(), el hilo actual se bloqueará hasta que la subtarea correspondiente termine de ejecutarse y devuelva el resultado.
resumir
- Aprendí ForkJoinPool, su principio y diseño de cola de trabajo.
- Aprendí la diferencia entre ForkJoinPool y ThreadPoolExecutor