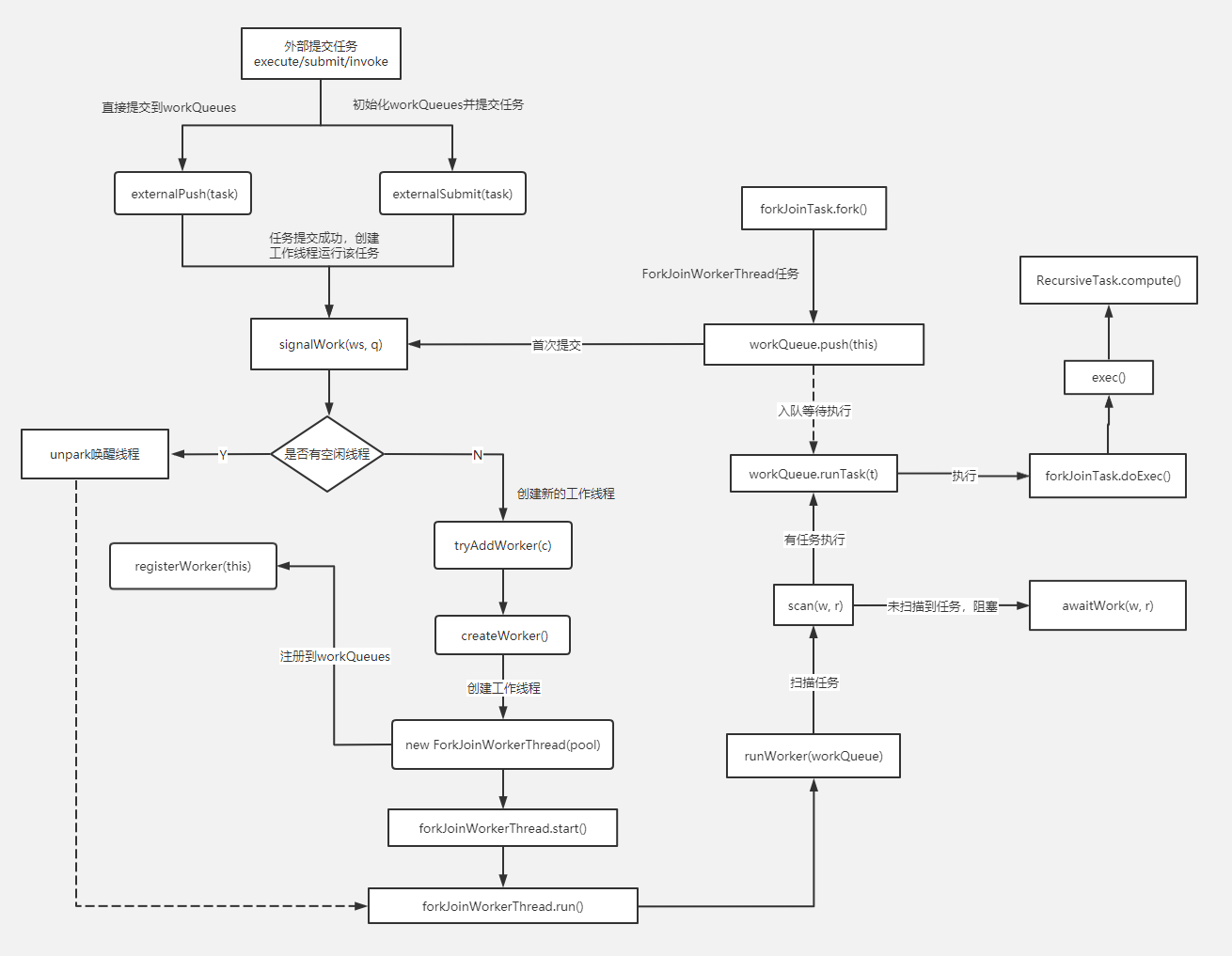
Directorio de artículos
Principio de unión en bifurcación
Tipo de tarea
Dependiente de la CPU
El uso intensivo de CPU también se denomina computacionalmente intensivo. Se refiere al rendimiento del disco duro del sistema y la memoria es mucho mejor que el de la CPU. En este momento, la mayor parte de la operación del sistema es la carga de la CPU al 100%, y la CPU necesita leer / escribir E / S (disco duro / memoria ), La E / S se puede completar en poco tiempo y la CPU aún tiene muchas operaciones por procesar y la carga de la CPU es muy alta. En un sistema multiprograma, el programa que pasa la mayor parte del tiempo haciendo cálculos, juicios lógicos y otras acciones de la CPU se llama CPUbound. Por ejemplo, un programa que calcula pi a mil dígitos por debajo del punto decimal se utiliza para el cálculo de funciones trigonométricas y raíces cuadradas la mayor parte del tiempo en el proceso de ejecución, es un programa que pertenece a la CPU vinculada. Los programas vinculados a la CPU generalmente tienen una alta tasa de uso de la CPU. Esto puede deberse a que la tarea en sí no necesita acceder al dispositivo de E / S, o puede deberse a que el programa está implementado en varios subprocesos y, por lo tanto, protege el tiempo de espera de E / S.
El número de subprocesos generalmente se establece como:
número de subprocesos = número de núcleos de CPU + 1
IO intensivo (I / O limitado)
Intensivo de E / S se refiere al hecho de que el rendimiento de la CPU del sistema es mucho mejor que el del disco duro y la memoria. En este momento, el sistema está funcionando. La mayoría de las condiciones son que la CPU está esperando operaciones de lectura / escritura de E / S (disco duro / memoria). no alto. Generalmente, cuando el programa enlazado de E / S alcanza el límite de rendimiento, el uso de la CPU sigue siendo bajo. Esto puede deberse a que la tarea en sí requiere muchas operaciones de E / S, la canalización no funciona bien y la potencia del procesador no se utiliza por completo.
El número de subprocesos generalmente se establece como:
número de subprocesos = ((tiempo de espera del subproceso + tiempo de ejecución de la CPU del subproceso) / tiempo de ejecución de la CPU del subproceso) * número de núcleo de la CPU
CPU intensivo vs IO intensivo
Podemos dividir las tareas en intensivas en computación e intensivas en IO.
La característica de las tareas computacionalmente intensivas es realizar una gran cantidad de cálculos y consumir recursos de la CPU, como calcular la relación pi y realizar la decodificación de videos de alta definición, etc., todo dependiendo de la potencia de cálculo de la CPU. Aunque este tipo de tarea computacionalmente intensiva también se puede completar mediante la multitarea, cuantas más tareas, más tiempo se dedica al cambio de tareas y menor es la eficiencia de la CPU para realizar las tareas. Por lo tanto, el uso más eficiente de la CPU, la computación intensiva El número de tareas simultáneas debe ser igual al número de núcleos de CPU. Las tareas informáticas consumen principalmente recursos de la CPU, por lo que la eficiencia de la operación del código es muy importante. Los lenguajes de script como Python tienen una eficiencia operativa muy baja y son completamente inadecuados para tareas de computación intensivas. Para tareas computacionalmente intensivas, es mejor escribir en lenguaje C.
El segundo tipo de tarea es intensiva en E / S. Las tareas que involucran E / S de red y disco son todas tareas intensivas en E / S. Este tipo de tarea se caracteriza por un bajo consumo de CPU y la mayor parte de la tarea es esperar a que se complete la operación de E / S (porque La velocidad de IO es mucho menor que la velocidad de la CPU y la memoria). Para tareas intensivas en E / S, cuantas más tareas, mayor será la eficiencia de la CPU, pero hay un límite. La mayoría de las tareas comunes son tareas intensivas en IO, como aplicaciones web. Durante la ejecución de tareas intensivas en IO, el 99% del tiempo se dedica a IO y muy poco tiempo a la CPU. Por lo tanto, es completamente imposible reemplazar un lenguaje de scripting como Python con un lenguaje C de ejecución muy rápida. Mejorar la eficiencia operativa. Para tareas intensivas en IO, el lenguaje más adecuado es el lenguaje con la mayor eficiencia de desarrollo (menor cantidad de código), el lenguaje de scripting es la primera opción y el lenguaje C el peor.
Marco de unión de bifurcación
Definición y características
El marco Fork-Join es un marco para la ejecución paralela de tareas proporcionado por Java 7. Es un marco que divide una tarea grande
en varias tareas pequeñas y finalmente resume los resultados de cada tarea pequeña para obtener el resultado de la tarea grande.
Fork es dividir una tarea grande en varias subtareas para la ejecución paralela, Join es fusionar los resultados de ejecución de estas subtareas y finalmente obtener el resultado de esta gran tarea. Por ejemplo, el cálculo de 1 + 2 + ... + 10000 se puede dividir en 10 subtareas, y cada subtarea suma 1000 números y finalmente resume los resultados de estas 10 subtareas. Como se muestra abajo:
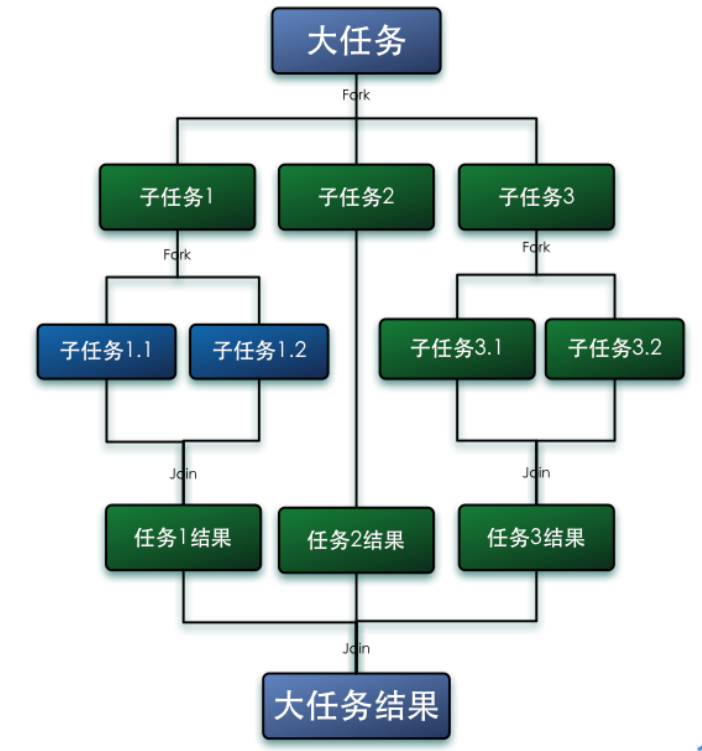
Características de Fork-Jion:
- ForkJoinPool no reemplaza a ExecutorService, sino que lo complementa, en algunos escenarios de aplicación, el rendimiento es mejor que ExecutorService.
- ForkJoinPool se usa principalmente para implementar algoritmos de dividir y conquistar , especialmente funciones llamadas recursivamente después de dividir y conquistar, como la clasificación rápida.
- ForkJoinPool es más adecuado para tareas computacionalmente intensivas. Si hay E / S, sincronización entre subprocesos, suspensión (), etc., lo que hará que los subprocesos se bloqueen durante mucho tiempo, es mejor usar ManagedBlocker.
Algoritmo de robo de trabajo
El marco principal de ForkJoin es un mecanismo de programación ligero, que utiliza la estrategia de programación básica de robo de trabajo (Work-Stealing) adoptada.
El algoritmo de robo de trabajo se refiere a un hilo que roba tareas de otras colas para su ejecución. Necesitamos hacer una tarea relativamente grande. Podemos dividir esta tarea en varias subtareas independientes. Para reducir la competencia entre subprocesos, colocamos estas subtareas en diferentes colas y las creamos para cada cola Un subproceso independiente ejecuta las tareas en la cola y el subproceso corresponde a la cola uno a uno. Por ejemplo, el subproceso A es responsable de procesar las tareas en la cola A. Sin embargo, algunos subprocesos terminarán las tareas en sus propias colas primero, mientras que todavía hay tareas esperando ser procesadas en las colas correspondientes a otros subprocesos. En lugar de esperar, el hilo que terminó su trabajo también podría ayudar a otros hilos a funcionar, por lo que fue a la cola de otros hilos para robar una tarea para su ejecución. En este momento, accederán a la misma cola, por lo que para reducir la competencia entre el subproceso de tarea robado y el subproceso de tarea robado, generalmente se usa una cola de dos extremos. El subproceso de tarea robado siempre ejecuta la tarea desde la parte superior de la cola de dos extremos. El hilo que roba la tarea siempre ejecuta la tarea desde la base del deque.
El proceso de ejecución de robo de trabajo se muestra en la siguiente figura:
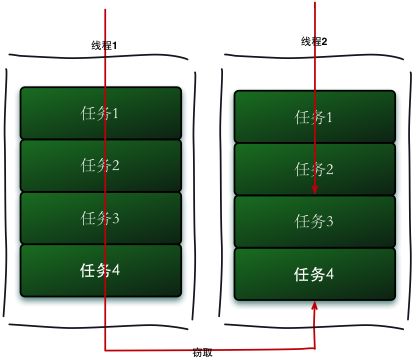
-
La ventaja del algoritmo de robo de trabajo es hacer un uso completo de los subprocesos para la computación paralela y reducir la competencia entre subprocesos.
-
La desventaja del algoritmo de robo de trabajo es que todavía hay competencia en algunos casos, como cuando solo hay una tarea en el deque. Y consume más recursos del sistema, como la creación de múltiples subprocesos y múltiples deques.
principio de funcionamiento
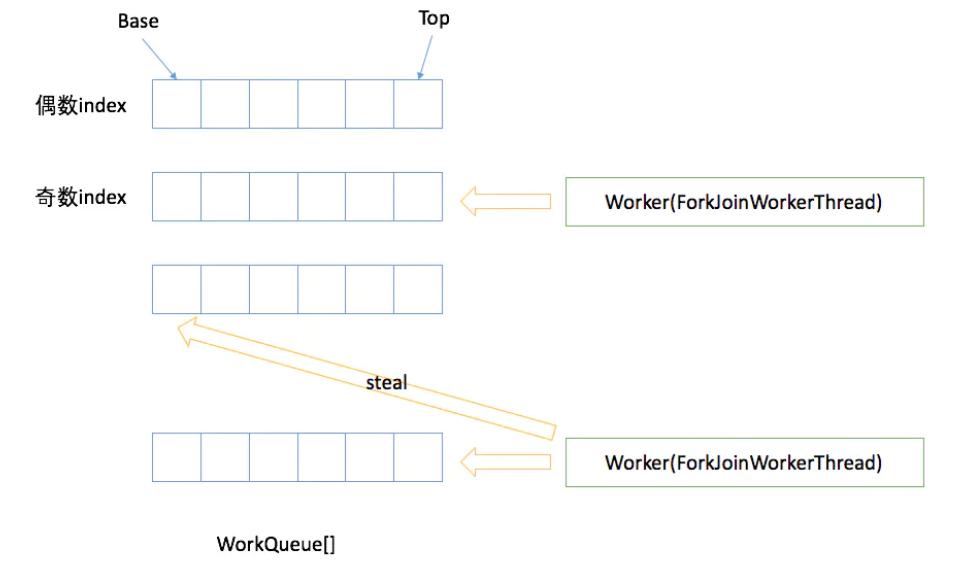
- Cada subproceso de trabajo de ForkJoinPool mantiene una cola de trabajo (WorkQueue), que es una deque, y el objeto almacenado en ella es una tarea (ForkJoinTask).
- Cuando cada subproceso de trabajo genera una nueva tarea durante la operación (generalmente porque se llama a fork ()), se coloca en la parte superior de la cola de trabajo y el subproceso de trabajo usa el método LIFO al procesar su propia cola de trabajo, es decir Diga cada vez que se saca una tarea desde arriba para ejecutarla.
- Mientras procesa su propia cola de trabajo, cada hilo de trabajo intentará robar una tarea (ya sea de la tarea que se acaba de enviar al grupo o de la cola de trabajo de otros hilos de trabajo), y la tarea robada se ubica en la cola de trabajo de otros hilos El líder del equipo, lo que significa que el subproceso trabajador utiliza el método FIFO al robar las tareas de otros subprocesos trabajadores.
- Al encontrar join (), si la tarea que necesita unirse no se ha completado, otras tareas se procesarán primero y esperarán a que se complete.
- Cuando no hay tarea propia ni tarea que robar, entra en sueño.
HorquillaUnirsePiscina
ForkJoinPool es el grupo de ejecución utilizado para ejecutar las tareas de ForkJoinTask. Ya no es una combinación del grupo de ejecución tradicional Worker + Queue, sino que mantiene una matriz de cola WorkQueue (WorkQueue []), lo que reduce en gran medida el tiempo de envío de tareas y subprocesos. colisión.
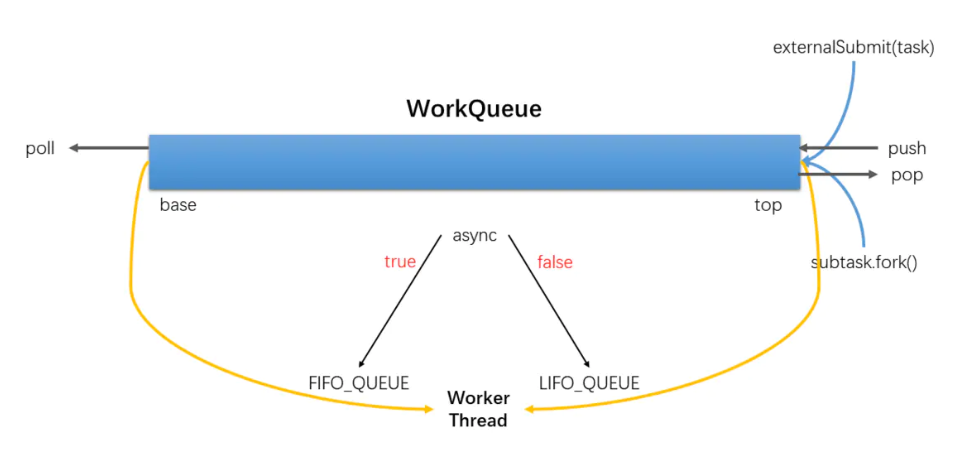
WorkQueue
- WorkQueue es una lista bidireccional, utilizada para la ejecución ordenada de tareas. Si WorkQueue se utiliza para su propio subproceso de ejecución Thread, el subproceso seleccionará tareas desde el final para ejecutar LIFO por defecto.
- Cada ForkJoinWorkThread tiene su propio WorkQueue, pero no todos los WorkQueue tienen un ForkJoinWorkThread correspondiente.
- ForkJoinWorkThread WorkQueue sin preservación es el envío, envío desde el exterior, el subíndice WorkQueue [] es un número par de bits.
HorquillaUnirseTrabajo
ForkJoinWorkThread es un hilo que se utiliza para ejecutar tareas. Se utiliza para distinguir entre el uso de hilos que no son de ForkJoinWorkThread para enviar tareas. El inicio de un Thread, se registra automáticamente en un WorkQueue Pool, hace que Thread of WorkQueue solo aparezca en WorkQueue [] de bits impares .
ForkJoinTask
ForkJoinTask es una tarea. Es más liviana que las tareas tradicionales y ya no es una subclase de Runnable. Proporciona métodos Fork / Join para dividir tareas y agregar resultados.
método de horquilla
fork()El único trabajo realizado es enviar la tarea a la cola de trabajo del hilo de trabajo actual.
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
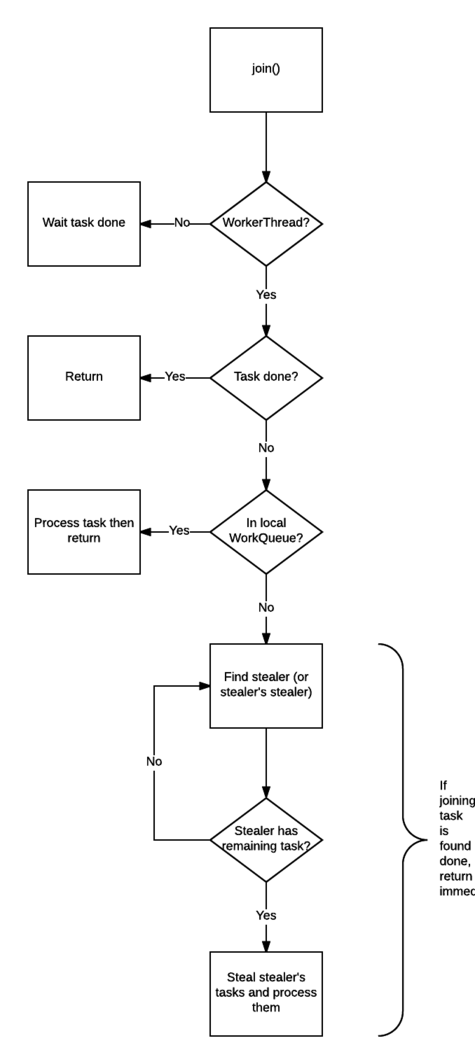
método de unión
join() El trabajo de es mucho más complicado, por lo que puede evitar que se bloqueen los hilos.
Compruebe la llamada join()si el hilo es ForkJoinThread. Si no es así (como el hilo principal), bloquee el hilo actual y espere a que se complete la tarea. Si es así, no bloquea.
Verifique el estado de finalización de la tarea, si se ha completado, devuelva el resultado directamente.
Si la tarea no se ha completado pero está en su propia cola de trabajo, complétela.
Si la tarea ha sido robada por otros subprocesos de trabajo, robe la tarea en la cola de trabajo del ladrón (en modo FIFO) y ejecútela para ayudarlo a completar la tarea previa a la unión lo antes posible.
Si el ladrón que robó la tarea ha completado todas sus tareas y está esperando la tarea que necesita unirse, encuentra al ladrón del ladrón y ayúdalo a completar su tarea.
Realice el paso 5 de forma recursiva.
Además de las colas de trabajo propiedad de cada subproceso de trabajo, ForkJoinPool también tiene colas de trabajo. La función de estas colas de trabajo es recibir tareas enviadas por subprocesos externos (no subprocesos de ForkJoinThread). Estas colas de trabajo se denominan Para enviar cola.
submit()Y, fork()de hecho, no hay una diferencia esencial, pero la confirmación se convirtió en cola de envío solo (y se inicia alguna operación de sincronización). La cola de envío, como otras colas de trabajo, es el objeto "robado" por el hilo de trabajo. Por lo tanto, cuando una tarea en ella es robada con éxito por un hilo de trabajo, significa que la tarea enviada realmente comienza a entrar en la etapa de ejecución.
Esquema de ForkJoin