1. Sincronización de datos
1. clase atómica
Para la atomicidad de los datos multiproceso, además del bloqueo, Java se proporcionan una serie de clases atómicas (como, etc.) AtomicInteger para garantizar la atomicidad de los datos. El núcleo obtiene Unsafe instancias a través de la reflexión para lograr CAS operaciones, asegurando la atomicidad de los datos.
Tomando AtomicInteger una clase como ejemplo, sus métodos comunes y sus descripciones se enumeran en la siguiente tabla.
| método | efecto |
|---|---|
| colocar() | Establece un valor para un objeto. |
| conseguir() | Obtenga el valor del objeto. |
| incrementarAndGet() | Devuelve el valor del objeto incrementado en 1, de manera similar existe getAndIncrement(). |
| decrementAndGet() | Devuelve el valor del objeto después de disminuir en 1, de manera similar existe getAndDecrement(). |
También como AtomicInteger ejemplo, el código de muestra es el siguiente:
Java
copiar código
public void AtomicDemo() { AtomicInteger atomicInteger = new AtomicInteger(1); // 修改值 atomicInteger.set(2); System.out.println("get: " + atomicInteger.get()); // 等价自增 atomicInteger.incrementAndGet(); System.out.println("incrementAndGet: " + atomicInteger); // 等价自减 atomicInteger.decrementAndGet(); System.out.println("decrementAndGet: " + atomicInteger); }
(1)Referencia atómica
Además de la clase atómica equivalente incorporada AtomicInteger , AtomicReference se pueden proporcionar operaciones atómicas para clases genéricas.
AtomicReference El funcionamiento del objeto declarado AtomicInteger es similar al de la clase atómica encapsulada por otros sistemas: el valor de inicialización se puede establecer mediante palabras clave al definir new , o el valor se puede establecer mediante set() métodos posteriores, y todas sus operaciones son seguras para subprocesos.
Java
copiar código
public void referenceDemo() { AtomicReference<Integer> atomicReference = new AtomicReference<>(0); atomicReference.updateAndGet(it -> it + 1); System.out.println("Get: " + atomicReference.get()); AtomicReference<User> userAtomic = new AtomicReference<>(new User("Alex")); userAtomic.getAndUpdate(it -> new User("Beth")); System.out.println("Get: " + userAtomic.get()); } static class User { private String name; public User(String name) { this.name = name; } }
2. volátil
Antes de comprender volatile las palabras clave, debemos tener una comprensión preliminar del JVM mecanismo de funcionamiento de la memoria.
(1) Mecanismo de memoria
La memoria en JVM el medio se puede dividir aproximadamente en 主内存 y 本地内存. De forma predeterminada, todas las declaraciones de variables se almacenan en el medio 主内存 . Cuando un hilo necesita modificar el valor de una variable, debe leerlo 主内存 desde el medio al hilo en la forma de una copia 本地内存 . Una vez completado el cambio, el nuevo valor se vuelve a escribir 主内存. Sin embargo, hay un retraso en el proceso de lectura y escritura. Si los datos no se escriben a tiempo 主内存, el valor obtenido por otros procesos seguirá siendo el valor antes del cambio, lo que provocará inconsistencia en los datos.
(2) Papel volátil
Para solucionar el impacto causado por la diferencia de tiempo de lectura y escritura mencionada anteriormente, Java se proporcionan palabras clave en volatile , es decir, volatile las variables declaradas son visibles para cualquier hilo en tiempo real y, al mismo tiempo, puede evitar el reordenamiento del programa. instrucciones.
Tenga en cuenta que solo puede garantizar la variable 可见性, es decir, los datos de la memoria principal se actualizarán inmediatamente cuando la variable cambie, pero si volatile la variable se opera al mismo tiempo, el problema de atomicidad aún ocurrirá. Al mismo tiempo, debe tenerse en cuenta que volatile sólo puede modificar 类变量 y , y es ilegal 实例变量 para 方法参数 y y así sucesivamente.常量
(3) Ejemplo de demostración
El siguiente es un ejemplo para demostrar volatile el efecto: en el ejemplo, se crean dos subprocesos de lectura y escritura, uno se usa para actualizar datos y el otro se usa para monitorear el num cambio de variables e imprimir.
El código de prueba completo es el siguiente, que se ejecuta num sin volatile modificaciones y con volatile modificaciones.
Java
copiar código
public class VolatileExample { private volatile static int num = 0; public static void main(String[] args) throws InterruptedException { new Thread(() -> { int local = num; while (local < 3) { // 监控 num 值变化,记录最新值 if (num != local) { System.out.println("receive change: " + num); local = num; } } }, "Reader").start(); new Thread(() -> { int local = num; while (local < 3) { // 修改 num 值 System.out.println("change to: " + ++local); num = local; try { // 休眠使 Reader 获取变化 sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }, "Updater").start(); // 等待线程结束 TimeUnit.SECONDS.sleep(10); } }
volatile En el caso de que no se utilice, cuando el valor Updater actualizado num no se vuelve a escribir en la memoria principal inmediatamente, Reader los datos que no se pueden leer siguen siendo la variable antes del cambio, por lo que num != local siempre se juzga la condición falsey, update por lo tanto, falta la última información impresa.
TXT
copiar código
// 未使用 volatile change to: 1 receive change: 1 change to: 2 change to: 3
En el caso de uso , debido a que volatile se logra num la visibilidad de la variable en múltiples subprocesos , Reader el subproceso también puede monitorear num el estado de cambio real de la variable.
TXT
copiar código
// 使用 volatile change to: 1 receive change: 1 change to: 2 receive change: 2 change to: 3 receive change: 3
(4) modo singleton
volatile Por lo general, se usa para registros de monitoreo de estado en subprocesos múltiples y también se puede usar con bloqueos para implementar el modo singleton.
En el siguiente código de ejemplo , se implementa un modo singleton simple colaborando volatile con y . En el caso de subprocesos múltiples, se garantiza la visibilidad de la instancia y, al mismo tiempo , el objeto no se inicializa repetidamente mediante el uso de la garantía.synchronizedvolatileinstancesynchronized
Tenga en cuenta principalmente que el objeto de instancia debe juzgarse dos veces en el bloque de sincronización aquí synchronized . Suponiendo que si 线程A el bloqueo se adquiere y crea una instancia con éxito en condiciones concurrentes, otros subprocesos están en el estado de bloqueo de giro durante este proceso, cuando 线程A se completa la instanciación del objeto y Después de que volatile los datos se vuelven a escribir en la memoria principal a través de la palabra clave y se libera el bloqueo, el subproceso en el estado de giro anterior adquirirá el bloqueo y ejecutará el contenido del bloque de sincronización. Si no se realiza el segundo juicio, se generarán instancias repetidas. , y debido a que la declaración de instancia se volatile juzga así, el resultado devolverá false el objeto de la instancia completa para salir del bloque sincronizado.
Java
copiar código
public class Singleton { private volatile static Singleton instance = null; public static Singleton getInstance() { // 实例为空则获取锁 if (instance == null) { synchronized (Singleton.class) { // synchronized 防止多线程同时初始化实例 if (instance == null) instance = new Singleton(); } } return instance; } }
3. Reorganización del mando
En el punto anterior se mencionó que se Volatile puede prohibir la reordenación de instrucciones, primero permítanme presentarles qué es la reordenación de instrucciones.
Al ejecutar Java un archivo, cuando no existe una fuerte dependencia entre las líneas de código, su orden de ejecución es diferente según el orden de escritura, como se muestra en el ejemplo, la ejecución puede int b = 20 ser int a = 10 antes de la compilación real, porque los dos no están fuertemente relacionados. relacionados, lo que ocurra primero Ninguna de las definiciones afecta la correcta ejecución del programa. Pero int sum = a + b debe ejecutarse después de a y b está definido, porque sum el valor de depende en gran medida de a y b , este proceso es una reorganización de instrucciones.
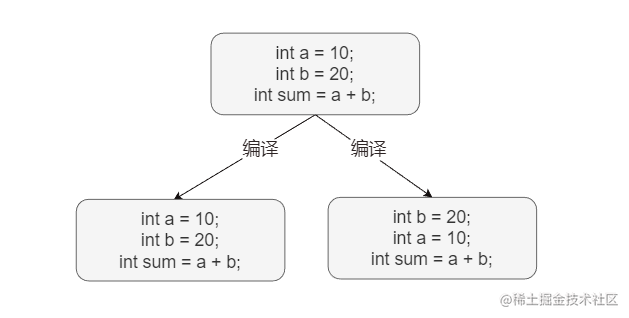
Las variables modificadas por Volatile palabras clave deben leerse antes de escribirse y deben volver a escribirse en la memoria principal inmediatamente después de que se complete la escritura. El orden de lectura y escritura es definido y no se puede cambiar, por lo que es imposible implementar la repetición de instrucciones. .
4. Hilo local
ThreadLocal Como sugiere el nombre, es un espacio de almacenamiento separado para cada subproceso, que generalmente se usa para almacenar ciertos valores de estado en el subproceso. Las variables entre diferentes subprocesos ThreadLocal existen de forma independiente y no pueden comunicarse entre sí, y los subprocesos secundarios heredarán ThreadLocal las variables del subproceso principal.
Tenga en cuenta que ThreadLocal una vez completado el uso, debe remove() reciclarse a través del método, porque ThreadLocal la variable se reciclará cuando finalice el ciclo del subproceso, pero cuando se trata del grupo de subprocesos, cada subproceso no necesariamente se destruirá después de completar el tarea y regresar al grupo de subprocesos. Entrar en el estado inactivo significa que la creación ThreadLocal siempre existirá y no se puede recolectar basura, lo que provocará pérdidas de memoria, por lo que se recomienda usarlos juntos y liberarlos en la ThreadLocal operación de configuración .try catchfinallyremove()
| método | efecto |
|---|---|
| conseguir() | Cree un objeto de almacenamiento para el hilo actual. |
| colocar() | Modifica el valor del objeto local del hilo actual. |
| eliminar() | Libera los objetos locales del hilo actual. |
(1) Ejemplo de introducción
En el siguiente ejemplo, creamos un ThreadLocal<Integer> objeto que puede almacenar Integer valores de un tipo que, cuando se pasan en diferentes subprocesos, get() inicializará una copia separada para cada subproceso. Luego creamos dos subprocesos y obtenemos y establecemos valores mediante threadLocal.get() el método AND en cada subproceso .threadLocal.set()
Al ejecutar el ejemplo, puede ver que cada subproceso tiene su propio valor independiente y no interferirá entre sí. Los dos subprocesos generan sus propios valores hash.
Java
copiar código
public class ThreadLocalExample { private static ThreadLocal<Integer> threadLocal = new ThreadLocal<>(); public static void main(String[] args) { // 创建两个子线程 Thread thread1 = new Thread(new MyRunnable()); Thread thread2 = new Thread(new MyRunnable()); // 启动子线程 thread1.start(); thread2.start(); try { // 等待子线程执行完毕 thread1.join(); thread2.join(); } catch (InterruptedException e) { e.printStackTrace(); } } static class MyRunnable implements Runnable { @Override public void run() { // 在子线程中获取值 System.out.println("Thread value: " + threadLocal.get()); // 在子线程中设置新值 threadLocal.set(Thread.currentThread().hashCode()); // 再次获取值 System.out.println("Thread value after set: " + threadLocal.get()); } } }
(2) Escenarios de aplicación
Cuando hay operaciones no seguras para subprocesos involucradas en operaciones concurrentes, generalmente se usa para ThreadLocal evitar operaciones concurrentes en objetos que no son seguros para subprocesos.
Si Java el SimpleDateFormat objeto de formato de hora no es seguro para subprocesos, se generará una excepción cuando varios subprocesos operen al mismo tiempo. En este caso, puede ThreadLocal definir un objeto separado SimpleDateFormat para cada subproceso.
En el siguiente ejemplo, se define un grupo de subprocesos con capacidad de simular concurrencia 5 y se formatea el tiempo de implementación en cada subproceso SimpleDateFormat . Si se define for un SimpleDateFormat objeto común en el paso anterior del bucle y se llama en cada subproceso secundario, se generará una excepción. ser arrojado.
Java
copiar código
public class SafeDateFormatTest { private static final ThreadLocal<DateFormat> dateFormatThreadLocal = ThreadLocal.withInitial(() -> { return new SimpleDateFormat("yyyy-MM-dd"); }); public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService threadPool = Executors.newFixedThreadPool(5); List<Future<Date>> results = new ArrayList<Future<Date>>(); // perform 10 date conversions for (int i = 0; i < 10; i++) { results.add(threadPool.submit(() -> { Date date; try { date = dateFormatThreadLocal.get().parse("2023-01-01"); } catch (ParseException e) { throw new RuntimeException(e); } return date; })); } threadPool.shutdown(); // look at the results for (Future<Date> result : results) { System.out.println(result.get()); } } }
Dos, la introducción de la cerradura.
1. Categorías básicas
Java Hay muchas clasificaciones de bloqueos de subprocesos si se subdividen. Aquí solo presentamos brevemente algunas clasificaciones que se encuentran comúnmente. Tenga en cuenta que las siguientes clasificaciones no son mutuamente excluyentes.
-
bloqueo optimista
El bloqueo optimista, como su nombre lo indica, es bloquear de una manera más relajada. Se cree que otros subprocesos no cambian el valor, sino que solo leen cuando se mantiene el bloqueo, por lo que se permite que varios objetos mantengan el bloqueo al mismo tiempo. y el mecanismo del número de versión del par se controla para lograr coherencia.
-
cerradura pesimista
El bloqueo pesimista es todo lo contrario del bloqueo optimista: cualquier proceso de una tarea puede cambiar las variables mientras mantiene un bloqueo, por lo que otros procesos no pueden adquirir la misma instancia de bloqueo durante el período de retención del bloqueo.
-
bloqueo de giro
Un bloqueo de giro se produce cuando otro proceso adquiere la instancia de bloqueo y el proceso actual intenta repetidamente adquirir el bloqueo (bloqueo), entonces dicho comportamiento se denomina bloqueo de giro.
-
cerradura justa
Un bloqueo justo significa que cuando el bloqueo está ocupado por un proceso, otros procesos ingresarán a la cola y esperarán si necesitan adquirir el bloqueo. Se adopta un mecanismo de asignación por orden de llegada. Si se crea el bloqueo
new ReentrantLock(true), es un candado justo. -
bloqueo injusto
Un bloqueo injusto significa que después de que el proceso mantiene el bloqueo, otros procesos lo asignarán aleatoriamente si necesitan adquirir el bloqueo. Este mecanismo puede provocar la inanición del subproceso, es decir, el proceso que solicitó el primero no ha podido adquirir el bloqueo. candado Común
synchronizedyReentrantLocktodo candado injusto. -
cerradura reentrante
Un bloqueo reentrante significa que una instancia de bloqueo se puede adquirir repetidamente mediante el mismo proceso. Por ejemplo, un
ReentrantLockbloqueo reentrante típico generalmente necesita usarse con un contador. Cuando el contador vuelve a cero, el bloqueo se libera. -
cerradura no reentrante
Un bloqueo no reentrante significa que la instancia de bloqueo no se puede adquirir repetidamente mediante el mismo proceso.
synchronizedEs un bloqueo reentrante en sí mismo, pero puede lograr un efecto no reentrante con un contador.
2. El significado de la cerradura
En un solo hilo sabemos claramente qué hilo está manipulando variables, pero obviamente todo esto no está tan claro en multiproceso, porque hay un problema obvio, es decir, los conflictos de variables.
count Para dar un ejemplo simple, hay dos subprocesos en el programa, cada uno de los cuales necesita realizar un autoincremento y una autodisminución en la variable 1000 . En teoría, el valor del resultado después de ejecutar el programa count debería ser 0 . El código de muestra es el siguiente :
Java
copiar código
private int count = 0; public void demo() throws InterruptedException { Thread thread1 = new Thread(() -> { for (int i = 0; i < 10000; i++) { count += 1; } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 10000; i++) { count -= 1; } }); thread1.start(); thread2.start(); thread1.join(); thread2.join(); // 输出结果未知 System.out.println(count); }
Sin embargo, cuando se ejecuta el programa anterior, se descubre que los resultados obtenidos para cada salida son diferentes y 0 los resultados son diferentes cada vez, esto en realidad se debe a que Java los pasos correspondientes de suma, resta, multiplicación y división en la compilación subyacente son más de un paso.
Por ejemplo, el autoincremento más comúnmente utilizado i = i + 1 corresponde a tres pasos en la implementación de compilación subyacente: 读取 -> 增加 -> 写入 , y cualquier problema en cualquiera de estos tres pasos hará que el resultado final sea anormal. Volviendo al código anterior, cuando 线程 1 se realiza la operación de incremento automático, en realidad solo se puede hacer 读取 增加 . Antes de completar la escritura, 线程 2 se obtiene la instancia de la variable para completar el auto-decremento 写入 , lo que conduce a la falla del incremento automático -1 .
3. Bloqueo jerárquico
En JDK1.8 , el bloqueo JVM se actualizará según el uso synchronized y, por lo general, puede seguir la siguiente ruta: 偏向锁 -> 轻量级锁 -> 重量级锁. Los bloqueos solo se pueden actualizar y no se pueden degradar, por lo que una vez que se actualizan a bloqueos pesados, solo el sistema operativo puede programarlos.
Lo más importante en el proceso de actualización de bloqueo es el encabezado del objeto MarkWord , que contiene cuatro partes Thread ID: , Age, Biased, Tag . Entre ellos, Biased están 1bit size y Tag yes 2bit , y la actualización del bloqueo se realiza de acuerdo con los tres valores variables de Thread Id, Biasedy .Tag
-
Bloqueo de polarización
En el caso de que solo un subproceso utilice el bloqueo, los bloqueos sesgados pueden garantizar una mayor eficiencia.
Cuando el primer hilo accede al bloque de sincronización por primera vez, primero verificará si
Mark Wordel indicador en el encabezado del objeto es para juzgar si el bloqueo del objeto está en el estado sin bloqueo o en el estado de bloqueo sesgado (bloqueo sesgado anónimo). ). También es el estado predeterminado del bloqueo. Una vez que el hilo adquiere el bloqueo, escribirá su propio hilo en él . Antes de que otros subprocesos adquieran el bloqueo, el bloqueo se encuentra en un estado de bloqueo sesgado.Tag0101IDMarkWord -
cerradura ligera
Cuando el siguiente hilo participe en la competencia de bloqueo sesgado, primero juzgará si
MarkWordel hilo guardado en el bloqueo es igualIDa este hiloID. De lo contrario, el bloqueo sesgado se revocará inmediatamente y se actualizará a un bloqueo ligero.Cada hilo que participa en la competencia generará uno en su propia pila de hilos
LockRecord(LR), y luego cada hilo establecerá el encabezado del objeto de bloqueo como un puntero hacia sí mismo(CAS)girando (es decir, tratando constantemente de adquirir el bloqueo) , lo que significa que la configuración exitosa del hilo significa cuál El hilo adquiere el bloqueo.MarkWordLRCuando la cerradura está en el estado de una cerradura liviana, ya no se puede juzgar por un simple
Tagvalor de comparación: cada vez que se adquiere la cerradura, es necesario girarla. Por supuesto, el giro también es para escenarios donde no hay competencia de bloqueos. Por ejemplo, después de que un hilo termina de ejecutarse, otro hilo adquiere el bloqueo. Sin embargo, si el giro falla un cierto número de veces, el bloqueo se expandirá hasta convertirse en un peso pesado. cerrar con llave. -
cerradura pesada
Los bloqueos pesados son nuestra
synchronizedcomprensión intuitiva: en este caso, el hilo se bloqueará, ingresará al estado del kernel del sistema operativo, esperará la programación del sistema operativo y luego volverá al estado del usuario. Las llamadas al sistema son caras, de ahí el nombre de cerraduras pesadas.Si las variables compartidas del sistema son altamente competitivas, las cerraduras se expandirán rápidamente a cerraduras pesadas y estas optimizaciones existirán solo de nombre. Si la concurrencia es muy grave, puede
-XX:-UseBiasedLockingdesactivar el bloqueo sesgado a través de parámetros. En teoría, habrá alguna mejora en el rendimiento, pero no es seguro en la práctica.
3. Cerraduras de uso común
En subprocesos múltiples, a menudo es necesario bloquear variables u operaciones compartidas para garantizar que solo un subproceso pueda operar en variables al mismo tiempo y lograr la atomicidad de las variables. El siguiente es el objeto de bloqueo comúnmente utilizado en introducción Java .
1. sincronizado
synchronized Es uno de los objetos de bloqueo más básicos. Al agregar una palabra clave synchronized implícitamente bloqueable this antes del método, otros procesos no pueden obtenerla cuando quieren acceder a la variable. Solo finaliza el bloqueo que se libera automáticamente después de la ejecución del código del bloque de sincronización. Se pueden adquirir otros procesos nuevamente, para lograr el propósito de la atomicidad.
Podemos obtener el resultado deseado modificando el código de muestra mencionado anteriormente.
Java
copiar código
private int count = 0; public void demo() throws InterruptedException { Thread thread1 = new Thread(() -> { for (int i = 0; i < 10000; i++) { synchronized(this) { // 加锁 synCount += 1; } } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 10000; i++) { synchronized(this) { // 加锁 synCount -= 1; } } }); thread1.start(); thread2.start(); thread1.join(); thread2.join(); System.out.println(count); }
2. Bloqueo reentrante
Java Se proporciona ReentrantLock una operación de bloqueo más ligera .
Sabemos que un bloqueo solo puede ser adquirido por un subproceso al mismo tiempo, por lo que cuando otros subprocesos mantienen un bloqueo, el usuario synchronized siempre intentará adquirir el bloqueo hasta que se adquiera el objeto de bloqueo. Una vez que la lógica es anormal, Es fácil tener un bucle infinito. Además ReentrantLock del bloqueo básico, tryLock() se proporciona un método para establecer el período de tiempo de espera de la adquisición del bloqueo. Si el bloqueo no se adquiere después de la expiración, el bloqueo se bloqueará y se ejecutará el código restante.
(1)bloquear()
La operación de bloqueo se puede realizar pasándola lock() . El mismo objeto de hilo solo puede contener un bloqueo. Tenga en cuenta que lock() si la operación de bloqueo falla, siempre intentará adquirir el bloqueo, lo que provocará que el programa se bloquee y no pueda ejecutar códigos posteriores.
Al usarlo, se recomienda colocar el bloque de código try catch y liberar el bloqueo finally para unlock() evitar que la anomalía del programa haga que el bloqueo no se libere normalmente y provoque problemas de interbloqueo.
Java
copiar código
public void demo1() throws Exception { Lock lock = new ReentrantLock(); Thread thread1 = new Thread(() -> { // 加锁 lock.lock(); try { sleep(10 * 1000); } finally { // 一定要释放锁 lock.unlock(); } }); Thread thread2 = new Thread(() -> { // 锁被线程 1 持有无法获取 lock.lock(); System.out.println("get lock"); }); thread1.start(); Thread.sleep(500); thread2.start(); thread1.join(); thread2.join(); }
(2) intentar bloquear()
tryLock() La función es lock() similar a, pero puede establecer el período de tiempo de espera del bloqueo. Si el bloqueo no se adquiere dentro del tiempo especificado, continuará regresando false y ejecutando el código restante.
Por ejemplo, en el siguiente ejemplo, thread2 después de intentar bloquear durante dos segundos, si no se bloquea correctamente, regresará false y continuará ejecutando el código posterior. Si se reemplaza con lock() un método, ingresará a un ciclo de interbloqueo, lo que resultará en un desperdicio de recursos del programa.
Java
copiar código
public void demo2() throws Exception { Lock lock = new ReentrantLock(); Thread thread1 = new Thread(() -> { // 加锁, 但不释放锁 lock.lock(); }); Thread thread2 = new Thread(() -> { try { // 尝试加锁,两秒后未取锁继续执行后续内容 boolean isLock = lock.tryLock(2, TimeUnit.SECONDS); System.out.println("carry on..."); } catch (InterruptedException e) { e.printStackTrace(); } }); thread1.start(); Thread.sleep(500); thread2.start(); thread1.join(); thread2.join(); }
3. Bloqueo de lectura y escritura
Aunque los dos tipos de bloqueos anteriores pueden lograr atomicidad, un bloqueo de talla única obviamente tendrá una ligera reducción en la eficiencia, por lo que se Java proporciona una serie de bloqueos de lectura y escritura, ReadWriteLock que es uno de ellos.
En los negocios donde las necesidades de visualización son mayores que las modificaciones, por ejemplo, para funciones como foros, a varios usuarios se les permite ver al mismo tiempo pero se les prohíbe a varios usuarios modificar al mismo tiempo. La lógica de exclusión mutua se elimina a través de la lectura. -Bloqueo de escritura para lograr un control de concurrencia más detallado y garantizar la seguridad de los subprocesos, logrando un buen rendimiento en el caso de.
(1) Características
ReadWriteLock Dividido en 读锁 y 写锁 , sus características son las siguientes:
读锁No son mutuamente excluyentes读锁y pueden estar retenidos por varios subprocesos al mismo tiempo.写锁También son mutuamente excluyentes y como máximo un hilo puede contenerlos al mismo tiempo写锁.读锁y写锁son mutuamente excluyentes, es decir,读锁no写锁pueden celebrarse al mismo tiempo, y sólo uno de los dos está en estado de celebración.
(2) Inicialización
ReadWriteLock El método de inicialización es el siguiente:
Java
copiar código
public void init() { // 声明一个读写锁 ReadWriteLock rwLock = new ReentrantReadWriteLock(); // 读锁,允许多线程持有 Lock rLock = rwLock.readLock(); // 写锁,仅允许单线程持有 Lock wLock = rwLock.writeLock(); }
(3) Ejemplo de sincronización
Después de comprender el concepto básico de bloqueo de lectura y escritura, podemos comprender su función más profundamente a través de ejemplos simples.
Para facilitar las pruebas de seguimiento, aquí se define un 读线程 AND 写线程 y el programa de simulación que requiere mucho tiempo se simula mediante la operación de suspensión.
Java
copiar código
class ReadThread extends Thread { private String name; public ReadThread(String name){ this.name = name; } @Override public void run() { rLock.lock(); try { System.out.println(name + " do read."); // Simulate program timing TimeUnit.SECONDS.sleep(3); System.out.println(name + " sleep over."); } catch (InterruptedException e) { e.printStackTrace(); } finally { rLock.unlock(); } } } class WriteThread extends Thread { private String name; public WriteThread(String name){ this.name = name; } @Override public void run() { wLock.lock(); try { System.out.println(name + " do write."); // Simulate program timing TimeUnit.SECONDS.sleep(3); System.out.println(name + " sleep over."); } catch (InterruptedException e) { e.printStackTrace(); } finally { wLock.unlock(); } } }
Según los subprocesos de lectura y escritura declarados anteriormente, a continuación se proporcionan tres ejemplos de 双读锁 , 一读一写 y , respectivamente .双写锁
El código de prueba específico es el siguiente:
Java
copiar código
/** * 双读锁示例,不互斥 */ public void demo1() throws InterruptedException { Thread reader1 = new ReadThread("Reader-1"); Thread reader2 = new ReadThread("Reader-2"); // Start thread reader1.start(); TimeUnit.MILLISECONDS.sleep(200); reader2.start(); // waiting for finish. reader1.join(); reader2.join(); } /** * 一读一写,互斥 */ public void demo2() throws InterruptedException { Thread reader1 = new ReadThread("Reader-1"); Thread writer1 = new WriteThread("Writer-1"); // Start thread reader1.start(); TimeUnit.MILLISECONDS.sleep(200); writer1.start(); // waiting for finish. reader1.join(); writer1.join(); } /** * 双写锁,互斥 */ public void demo3() throws InterruptedException { Thread writer1 = new WriteThread("Writer-1"); Thread writer2 = new WriteThread("Writer-2"); // Start thread writer1.start(); TimeUnit.MILLISECONDS.sleep(200); writer2.start(); // waiting for finish. writer1.join(); writer2.join(); }
Al ejecutar el programa anterior, puede ver que demo1 la operación de lectura de los dos subprocesos en el bloqueo de lectura se activa básicamente al mismo tiempo, mientras que el demo2 subproceso de escritura no puede adquirir el bloqueo mientras se ejecuta el subproceso de lectura, y el subproceso de escritura solo se activa. después de que el hilo de lectura sale y libera el bloqueo. De la misma demo3 manera, el segundo hilo de escritura se activa después de que el hilo de escritura libera el bloqueo.
Según los resultados, también se verifican las conclusiones anteriores: se permite que los bloqueos de lectura coexistan, pero los bloqueos de lectura y los bloqueos de escritura son mutuamente excluyentes, y los bloqueos de escritura también se excluyen mutuamente antes.
TXT
copiar código
// demo1 Reader-1 do read. Reader-2 do read. Reader-1 sleep over. Reader-2 sleep over. // demo2 Reader-1 do read. Reader-1 sleep over. Writer-1 do write. Writer-1 sleep over. // demo3 Writer-1 do write. Writer-1 sleep over. Writer-2 do write. Writer-2 sleep over.
4. Bloqueo estampado
StampedLock También se divide en bloqueo de lectura y escritura, pero es un tipo de bloqueo optimista y las diferentes operaciones se distinguen proporcionando un número de versión para el bloqueo.
(1) Bloqueo pesimista
StampedLockreadLock() Los y en writeLock() son bloqueos pesimistas, el efecto específico es ReentrantReadWriteLock similar a y, y no se presentará en detalle aquí. Para conocer métodos específicos, consulte la siguiente tabla.
| método | efecto |
|---|---|
| leerBloqueo() | Obtenga un bloqueo de lectura y devuelva el número de versión para liberar o actualizar el bloqueo. |
| estáReadLocked() | Determine si actualmente existe un bloqueo de lectura. |
| obtenerReadLockCount() | Obtenga la cantidad de bloqueos de lectura actualmente activos. |
| desbloquearLeer() | Libere el bloqueo de lectura correspondiente según el número de versión ingresado. |
| escribirBloqueo() | Obtenga un bloqueo de escritura y devuelva el número de versión para liberar o actualizar el bloqueo. |
| está escrito bloqueado() | Determine si actualmente existe un bloqueo de escritura. |
| desbloquearEscribir() | Libere el bloqueo de escritura correspondiente según el número de versión ingresado. |
(2) Bloqueo optimista
Se puede devolver un número de versión pasando tryOptimisticRead() . Tenga en cuenta que no hay un estado libre de bloqueo en este momento. El validate(stamp) método se puede utilizar para verificar si hay una escritura en este momento, es decir, si hay un bloqueo de escritura en el Estado de retención Se pueden diseñar diferentes lógicas de procesamiento según el resultado.
Los métodos de interfaz más utilizados y su correspondiente información de descripción se refieren a la siguiente tabla.
| método | efecto |
|---|---|
| probarOptimisticRead() | Lectura optimista, devuelve un número de versión. |
| validar() | Determine si el bloqueo de escritura se ha adquirido después de adquirir la versión correspondiente. |
| intentarConvertToReadLock() | Intenta actualizar el bloqueo actual a un bloqueo de lectura y devuelve 0 para indicar un error. |
| intenteConvertToWriteLock() | Intenta actualizar el bloqueo actual a un bloqueo de escritura y devuelve 0 para indicar un error. |
| desbloquear() | Libere todos los bloqueos (bloqueos de lectura y bloqueos de escritura) correspondientes al número de versión. |
El siguiente es un ejemplo de actualización de un bloqueo optimista a un bloqueo pesimista. Aquí se omite el contenido específico WriteThread para la operación de adquirir un bloqueo de escritura .writeLock
Java
copiar código
public class RwTest { private static long stamp = 1L; private static final StampedLock stampedLock = new StampedLock(); @Test public void optimisticDemo() throws InterruptedException { // Start write thread Thread write = new WriteThread(); write.setName("Writer-1"); write.start(); TimeUnit.MILLISECONDS.sleep(100); // Optimistic read stamp = stampedLock.tryOptimisticRead(); try { // 验证是否发生写操作 if (stampedLock.validate(stamp)) { // 若是从乐观读升级为悲观读 stamp = stampedLock.tryConvertToReadLock(stamp); if (stamp != 0L) { // convert success System.out.println("Is read lock: " + stampedLock.isReadLocked()); System.out.println("Convert read success, do read."); } } } catch (Exception e) { e.printStackTrace(); } finally { stampedLock.unlock(stamp); } } }
5. Cerradura distribuida
En la producción y el desarrollo reales, para lograr una alta disponibilidad, implementamos servicios en diferentes nodos a través del clúster. En este momento, varios nodos del clúster pueden ejecutar repetidamente una sola operación de usuario. Para esta situación, los dos tipos de bloqueos anteriores obviamente no son adecuados, porque ambos son para servicios de un solo nodo, por lo que en este momento se necesitan bloqueos distribuidos.
En términos más simples, todo el entorno del clúster puede considerarse como un subproceso principal y cada nodo es un subproceso. Los bloqueos distribuidos se utilizan para controlar la atomicidad de las operaciones entre diferentes nodos.
1. RedissonLock
RedissonLock Es un Redis bloqueo distribuido basado en implementación, su uso se describe en detalle a continuación.
(1) Conexión de Redis
Debido a que se basa en Redis la implementación, la conexión del servicio debe crearse con anticipación.
Java
copiar código
public void connect() { Config config = new Config(); config.useSingleServer() // Redis 服务地址 .setAddress("redis://127.0.0.1:6379") // 设置密码 .setPassword("123456") // 设置存储数据库 .setDatabase(2); // 创建连接 redissonClient = Redisson.create(config); }
(2) Uso básico
RedissonLock El método de uso es ReentrantLock básicamente el mismo que el actual, la diferencia es que el primero almacenará el objeto de bloqueo en Redis la memoria, por lo que no daré ejemplos específicos aquí, solo presentaré sus métodos comunes.
Cabe señalar que si no se establece el tiempo de vencimiento al bloquear, será el predeterminado 30s .
Java
copiar código
public void infoDemo() throws InterruptedException { RLock lock = redissonClient.getLock("test"); // 加锁 lock.lock(); // 加锁,并指定超时时间 lock.lock(6000, TimeUnit.MILLISECONDS); // 异步加锁 RFuture<Void> future = lock.lockAsync(); // 异步加锁, 指定锁超时时长 future = lock.lockAsync(6000, TimeUnit.MILLISECONDS); // tryLock() 可以设置等待时间 boolean isL1 = lock.tryLock(); System.out.println("tryLock: " + isL1); // 尝试获取锁 waitTime: 等待时间; leaseTime: 锁过期时间 // 在 5 秒内未取到锁返回 false, 取到锁则设置锁过期为 6 秒 boolean isL2 = lock.tryLock(5 * 1000, 6 * 1000, TimeUnit.MILLISECONDS); System.out.println("tryLock: " + isL2); // 解锁 lock.unlock(); // 是否加锁 System.out.println("is locked: " + lock.isLocked()); // 加锁次数 System.out.println("lock count: " + lock.getHoldCount()); }
(3) Mecanismo de vigilancia
RedissonLock El tiempo de vencimiento del bloqueo predeterminado es 30s , si la tarea demora más de lo que 30s el bloqueo se liberará por adelantado, pero si el tiempo de vencimiento se establece manualmente, a veces es imposible estimar con precisión el consumo de tiempo de la tarea y puede haber un desperdicio de recursos. causado por mantener la cerradura por demasiado tiempo Condición. En respuesta a esta situación, RedissonLock se introduce un mecanismo de vigilancia watchDog . El programa de vigilancia mantendrá el bloqueo a intervalos fijos. Si el bloqueo aún se mantiene, renovará automáticamente el tiempo de bloqueo para realizar el tiempo de bloqueo dinámico.
El tiempo de vigilancia predeterminado es , es decir , el estado del bloqueo actual se leerá 30scada dos veces . Si el bloqueo aún se mantiene, el tiempo de bloqueo se extenderá automáticamente . Por supuesto, también puede especificar el tiempo del programa de vigilancia al crear una conexión . Si está configurado, verificará el estado del bloqueo cada dos veces . Si el bloqueo no se libera, se extenderá .10s30ssetLockWatchdogTimeout()60s60/3=20s60s
Veamos un ejemplo específico: 线程 1 el tiempo de vencimiento no se especifica al crear un bloqueo, por lo que el tiempo de vencimiento predeterminado es 30s , pero debido a que el mecanismo de vigilancia 10s leerá el estado del bloqueo cada dos veces, sleep() lleva tiempo simular la tarea 60s , por lo que cuando 30s el candado está bloqueado. El tiempo de vencimiento se renovará automáticamente nuevamente 30s, por lo que 线程 2 no se adquirirá el candado. El bloqueo sólo se puede adquirir después de que el mecanismo de vigilancia de liberación de bloqueo expire una vez finalizado el modo de suspensión 线程 2 .
Java
copiar código
public void watchDogDemo() throws InterruptedException { RLock lock = redissonClient.getLock("test"); Thread thread1 = new Thread(() -> { // 不指定时间,默认 30s 过期 lock.lock(); try { // 模拟任务耗时,看门狗会自动给续期 Thread.sleep(60 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 任务结束释放锁 lock.unlock(); } }).start(); // 间隔启动第二个线程 Thread.sleep(500); Thread thread2 = new Thread(() -> { // 无法拿到锁 lock.lock(); try { System.out.println("get lock"); } finally { // 任务结束释放锁 lock.unlock(); } }).start(); }
6. Herramienta de hilo
1. Cuenta atrás
CountDownLatch Puede entenderse como un contador y podemos controlar el flujo de hilos aplicándolo inteligentemente.
(1) Inicialización
El await() método del contador juzgará si el valor del contador actual es 0 ; de lo contrario, entrará en el estado de bloqueo.
Java
copiar código
public void demo() { // 初始化值为 1 的计数器 CountDownLatch latch = new CountDownLatch(1); // 计数器减 1 latch.countDown(); // 获取计数器大小 latch.getCount() try { // 等待计数器归零, 进入阻塞 latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("end"); }
(2) Simulación concurrente
La simulación de tareas de eventos concurrentes se puede realizar rápidamente a través de CountDownLatch. Los ejemplos específicos son los siguientes:
Java
copiar código
public void concurrentDemo() throws InterruptedException { CountDownLatch latch = new CountDownLatch(3); for (int i = 0; i < 3; i++) { int finalI = i; new Thread(() -> { try { // 阻塞,等待计数器归 0 模拟并发 latch.await(); // 需进行的并发操作 System.out.println(finalI); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); // 计数器递减 latch.countDown(); TimeUnit.SECONDS.sleep(1); } }
2. Barrera cíclica
CyclicBarrier También se traduce como una valla, es decir, se puede realizar el control de subprocesos por lotes y se activa cuando un grupo de subprocesos alcanza el estado crítico.
(1) Inicialización
El efecto del bloqueo de subprocesos se logra a través await() del método. Cuando el número especificado de subprocesos ingresa al estado de bloqueo, CyclicBarrier se activará el evento definido en. Tenga en cuenta que cuando el evento genera una excepción, se generará una excepción await() aquí BrokenBarrierException .
Java
copiar código
public void demo1() { // 当指定数量的线程到达 await 状态则触发事件 CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> { // 定义事件 System.out.println("\nAll threads have reached the barrier!\n"); }); for (int i = 0; i <= 3; i++) { new Thread(() -> { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " has reached the barrier."); try { // 进入阻塞,等待其它线程到达 await 状态 cyclicBarrier.await(); } catch (Exception e) { // 若 CyclicBarrier 事件抛出异常则会抛到此处 e.printStackTrace(); } System.out.println(threadName + " has continued executing."); }, "Thread-" + i).start(); } }
(2) Ejemplo de sincronización
Después de comprender el uso básico, veamos un caso más práctico.
Se generan cien mil números aleatorios a través Random de la simulación de la biblioteca y se logra el propósito de la suma. Para lograr propósitos más eficientes, el conjunto de matrices se divide en 3 submatrices y se suma por separado, y finalmente 3 se suman los resultados de la tarea. Una vez completado el cálculo de cada subtarea, await() ingresa al bloque y espera a que otras subtareas completen el cálculo. Cuando 3 se calculan todas las subtareas y ingresan al bloque, CyclicBarrier se activa la acumulación final y los resultados de las tres tareas se agregan a obtener el resultado final.
Java
copiar código
public void demo2() throws InterruptedException { List<Integer> list = new ArrayList<>(); for (int i = 1; i < 100000; i++) { list.add(new Random().nextInt(100)); } // 将数组拆分为 3 个子任务 List<List<Integer>> subLists = new ArrayList<>(); subLists.add(list.subList(0, 30000)); subLists.add(list.subList(30000, 70000)); subLists.add(list.subList(70000, 99999)); // 设置栅栏触发事件 List<Integer> result = new ArrayList<>(); CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> { AtomicInteger total = new AtomicInteger(0); result.forEach(it -> { total.getAndUpdate(i -> i + it); }); System.out.println("\nAll task finish, result is : " + total); }); // 提交计算子任务 for (int i = 0; i < 3; i++) { int batch = i; new Thread(() -> { AtomicInteger sum = new AtomicInteger(0); subLists.get(batch).forEach(sum::getAndAdd); result.add(sum.get()); try { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " calculate finish, wait other task done."); cyclicBarrier.await(); } catch (Exception e) { e.printStackTrace(); } }, "Thread-" + i).start(); } TimeUnit.SECONDS.sleep(5); }
3. Semáforo
Semaphore Puede lograr el efecto de limitar el número de accesos de subprocesos, que puede entenderse aproximadamente como una cola de subprocesos bloqueados: solo un número específico de subprocesos puede acceder a los recursos al mismo tiempo y se bloqueará después de alcanzar el umbral.
Semaphore El efecto es similar al de los bloqueos de subprocesos ordinarios, que se utilizan para limitar el acceso concurrente, pero la diferencia es que pueden Semaphore retenerse en varios subprocesos al mismo tiempo.
(1) Inicialización
Semaphore También proporciona acceso a los recursos acquire() de tryAcquire() dos maneras.
Java
copiar código
public void demo1() throws InterruptedException { // 初始化并指定并发大小 Semaphore semaphore = new Semaphore(3); // 请求访问,并发数满则阻塞 semaphore.acquire(); // 请求访问,失败不会阻塞 boolean b1 = semaphore.tryAcquire(); boolean b2 = semaphore.tryAcquire(3, TimeUnit.SECONDS); try { System.out.println(UUID.randomUUID()); } finally { // 释放资源 semaphore.release(); } }
(2) Ejemplo de sincronización
IO Sabemos que el bloqueo es común, por lo que en escenarios comerciales como la descarga de archivos, se deben utilizar subprocesos múltiples para lograr descargas de múltiples tareas, pero si la cantidad de concurrencia no es razonablemente limitada, los recursos del sistema estarán muy ocupados . IO Esta situación se puede lograr creando un recurso de grupo de subprocesos dedicado de un tamaño específico, pero a menudo hay otros servicios en un sistema que necesitan usar subprocesos. Obviamente, crear un grupo de subprocesos separado para cada módulo es inapropiado y consume recursos .
Semaphore Resuelve perfectamente este problema, mediante el cual se puede limitar el número de subprocesos concurrentes del mismo recurso. Veamos un ejemplo a continuación para que entendamos mejor:
Java
copiar código
/** * 初始化大小为 3,即只能同时 3 个任务并发 */ private static final Semaphore semaphore = new Semaphore(3); public void demo2() throws InterruptedException { for (int i = 0; i < 5; i++) { new MyThread().start(); } // 等待主线程中子任务结束 TimeUnit.SECONDS.sleep(25); } static class MyThread extends Thread { @Override public void run() { try { // 达到指定数量访问将阻塞 semaphore.acquire(); try { System.out.println(UUID.randomUUID()); // 模拟耗时 TimeUnit.SECONDS.sleep(3); } finally { // 一定要释放! semaphore.release(); } } catch (InterruptedException e) { e.printStackTrace(); } } }
Siete, punto muerto del hilo
1. Introducción al punto muerto
El punto muerto de subprocesos, como su nombre lo indica, significa que dos subprocesos esperan entre sí para liberar el objeto de bloqueo, lo que hace que ambos subprocesos entren en un bucle infinito de espera. En tareas de subprocesos múltiples, si la adquisición y liberación de bloqueos no están diseñadas correctamente , es muy probable que se produzcan problemas de punto muerto.
Para dar un ejemplo simple, user-1 para user-2 garantizar la coherencia de los datos, es decir, si una parte deduce el dinero pero la otra parte no lo recibe, para garantizar la coherencia de los datos, es necesario bloquear el dos objetos al mismo tiempo durante la operación de transferencia, es decir, después user-1 de bloquearlo user-2 , bloqueelo y luego realice operaciones comerciales de transferencia específicas.
Después de convertir la lógica del texto anterior al código correspondiente, queda de la siguiente manera:
Java
copiar código
public void transfer(User fromUser, User toUser, double amount) { synchronized(toUser) { synchronized(fromUser) { // 扣除来源用户余额 fromUser.debit(amount); // 增加目标用户余额 toUser.credit(amount) } } }
En el ejemplo anterior, cuando hay dos subprocesos de transferencia user-1 a user-2 cuenta y user-2 transferencia a user-1 cuenta al mismo tiempo, debido al orden de acción opuesto, el primero de los dos subprocesos en el código anterior se synchronized bloquea con éxito user-1 y user-2 ambos ingresarán el estado bloqueado en este momento. Cuando llega la segunda synchronized vez, el bloqueo retenido por el hilo uno user-2 está esperando el bloqueo liberado por el hilo dos user-1 , y el bloqueo retenido user-1 por el hilo dos está esperando el bloqueo liberado por el hilo uno user-2 . Ambos están esperando a que la otra parte se desbloquee. , lo que resulta en un estado de punto muerto.
2. Soluciones
Hay dos formas comunes de evitar el problema del interbloqueo: la primera es determinar el orden de ejecución de los bloqueos y la segunda es esperar el bloqueo ReentrantLock sin tryLock() bloqueo.
El segundo método es relativamente simple y el problema del punto muerto se puede evitar implementando un tiempo de espera de salida a través tryLock() del método. Por supuesto, la desventaja es que una de las tareas no se ejecutará.
Lo siguiente se centra en el análisis de las ideas de implementación del primer método.
El núcleo del método 1 es determinar la secuencia de bloqueo del proceso y garantizar la coherencia de la secuencia de bloqueo para el mismo grupo de operaciones. Como en el ejemplo anterior de transferencia user-1 user-2 a user-2 2 user-1 , porque se garantiza que no importa cómo se active, se garantiza bloquear user-1 el par primero y luego user-2 bloquear el par, o el orden se invierte, pero el punto clave es para garantizar que la aplicación utilice este orden cada vez que se llame.
Modifique ligeramente el ejemplo anterior calculando el valor hash del objeto para compararlo para garantizar la coherencia de la secuencia de bloqueo e introduciendo un tercer objeto de bloqueo para evitar que los dos objetos sean consistentes. El ejemplo de código correspondiente es el siguiente hashCode() :
Java
copiar código
public final Object obj = new Object(); public void transfer(User fromUser, User toUser, double amount) { int fromId = fromUser.hashCode(); int toId = toUser.hashCode(); if(fromId < toId) { synchronized(toUser) { synchronized(fromUser) { fromUser.debit(amount); toUser.credit(amount) } } } else if (fromId > toId) { synchronized(fromUser) { synchronized(toUser) { fromUser.debit(amount); toUser.credit(amount) } } } else { synchronized(obj) { synchronized(fromUser) { synchronized(toUser) { fromUser.debit(amount); toUser.credit(amount) } } } } }