1. Descripción general de los rastreadores web
1.1 Extracción y adquisición de datos
Definición: Un rastreador web es unalgunas reglas,automáticoProgramas y scripts que rastrean Internet en busca de información. parasimulaciónLa persona opera el navegador para abrir la página web y obtener los datos especificados en la página web.
1.2 Tipos de reptiles
| tipos de reptiles | efecto |
|---|---|
| reptil común | rastrear pagina webtododatos fuente |
| Centrarse en los reptiles | rastrear páginas webparcialdatos |
| rastreador incremental | Se utiliza para detectar la actualización de los datos del sitio web y rastrear los últimos datos del sitio web.renovarLos datos |
| rastreador distribuido | Rastreo de varias personas, mejora de los datos de rastreo de los datos del sitio web |
La primera: Clasificar según el número de rastreos:
①Rastreadores generales: normalmente se refieren a los rastreadores de motores de búsqueda.
Los rastreadores universales son una parte importante de los sistemas de rastreo de los motores de búsqueda (baidu, goole, yahoo, etc.). El objetivo principal es descargar páginas web de Internet localmente para formar una copia de seguridad espejo del contenido de Internet. (Pero un gran problema es que son muy limitados: la mayor parte del contenido es inútil: diferentes propósitos de búsqueda, ¡devuelven el mismo contenido!)
② Centrarse en los rastreadores: rastreadores para sitios web específicos.
Es un programa de rastreador web orientado a las necesidades de temas específicos. La diferencia entre este y los rastreadores generales de motores de búsqueda es que el rastreador
enfocado procesará y filtrará el contenido al rastrear páginas, y tratará de garantizar que solo la información de la página web relacionada con las necesidades sea se arrastró!
2. Concéntrese en aprender el análisis del sitio web de destino (el siguiente es un proceso fijo)
2.1 Prefacio
Rastreo de varias páginas: análisis del sitio web de destino [utilice herramientas de desarrollador] -> inicie una solicitud [marque – red Network– encabezado Agent, encuentre la URL correspondiente] -> obtenga una respuesta -> continúe iniciando una solicitud -> obtenga una respuesta y analizarlo -> Guardar datos.
2.2 ¿Qué es una cookie?
En el navegador, a menudo involucramos el intercambio de datos, como iniciar sesión en su buzón o iniciar sesión en una página. A menudo configuramos recordarme durante 30 días o las opciones de inicio de sesión automático en este punto. Entonces, ¿cómo registran la información? La respuesta son las cookies. Las cookies las establece el servidor HTTP y se almacenan en el navegador, pero el protocolo HTTP es un protocolo sin estado. Se cerrará, cada intercambio de datos debe establecer un nuevo enlace.
Una cookie es un pequeño archivo de texto almacenado en la computadora o dispositivo móvil de un usuario para rastrear la actividad y el estado del usuario en un sitio web. Cuando visita un sitio web, el sitio web envía una cookie a su computadora.
Las cookies contienen información sobre su visita, como su tipo de navegador, sistema operativo, preferencia de idioma y otra información de la visita.
Las cookies se pueden utilizar paraMantenga un registro de su estado de inicio de sesión, para que no tenga que volver a introducir su nombre de usuario y contraseña la próxima vez que visite el sitio. También se pueden utilizar pararastrea tu historial de navegación, para que el sitio pueda proporcionar contenido y publicidad más personalizados. Sin embargo, las cookies también se pueden usar para rastrear su información y actividades privadas, lo que puede generar problemas de privacidad y seguridad. Por lo tanto, la mayoría de los navegadores brindan opciones que le permiten controlar el uso de cookies y eliminarlas.
F12Abra las herramientas de desarrollo del navegador y siga los pasos que se muestran en la figura Cookies:
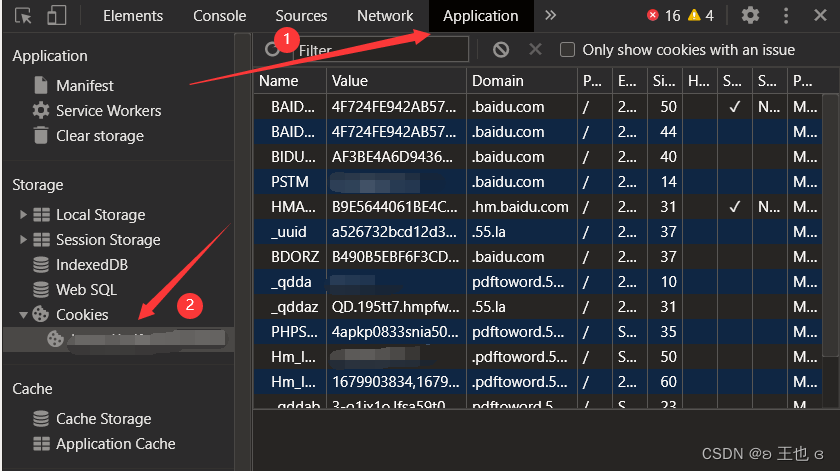
2.3 ¿Qué es Request Heders?
Request headers(Encabezado de solicitud) son los metadatos incluidos en la solicitud cuando el cliente envía una solicitud HTTP al servidor. Estos metadatos contienen información sobre la solicitud, comoEl tipo de solicitud (GET, POST, etc.), la fuente de la solicitud, el tipo de contenido de la solicitud, la marca de tiempo de la solicitud, etc.。
Los encabezados de solicitud generalmente se incluyen en el encabezado de una solicitud HTTP, expresados en forma de pares clave-valor . Por ejemplo, User-Agent indica el tipo y la versión del navegador, Accept indica el tipo MIME admitido por el cliente, Referer indica la dirección URL de la página de origen de la solicitud, etc.
Los encabezados de solicitud son una parte muy importante del protocolo HTTP. Proporcionan información adicional sobre la solicitud, lo que ayuda al servidor a comprender el propósito y el contenido de la solicitud y responder en consecuencia. Al mismo tiempo, los encabezados de solicitud también se pueden usar para controlar las operaciones de almacenamiento en caché, autenticación y seguridad.
2.4 ¿Qué es el agente de usuario?
User-AgentEs un campo de encabezado de solicitud HTTP, que contiene información sobre el cliente (generalmente un navegador) que envía la solicitud, como el tipo de navegador, el número de versión, el sistema operativo, el tipo de dispositivo, etc.
El servidor web puede utilizar el encabezado User-Agent para determinar el entorno de software y hardware utilizado por el cliente y proporcionar una respuesta más adecuada. Por ejemplo, un sitio web puede usar el encabezado User-Agent para determinar cómo mostrar páginas, brindar contenido apropiado o responder a diferentes tipos de dispositivos.
Nota: la información del encabezado del agente de usuario se puede obtener a través de JavaScript o código back-end, por lo que algunos sitios web pueden usar esta información para analizar el comportamiento de los visitantes, las estadísticas de la participación en el mercado del navegador y otra información. Así que esto también nos da una oportunidad para los reptiles.
Los usuarios también pueden ocultar su identidad o engañar al servidor modificando el encabezado User-Agent, por lo que el User-Agent no puede determinar completamente la identidad real del visitante.
Por lo general, cuando practicamos el código del rastreador, necesitamos usar el agente de usuario que realmente visitamos y podemos usar el agente más adelante.
2.5 ¿Qué es el referente?
ReferrerSe refiere a la dirección URL desde la cual la página está vinculada a la página actual y generalmente se usa para rastrear y analizar la fuente de tráfico del sitio web. Cuando un usuario hace clic en un enlace o visita un sitio web a través de un motor de búsqueda, el campo de referencia contendrá la dirección URL de la página de origen.
La información de referencia generalmente la envían los navegadores web,Le dice al servidor web desde qué página el visitante se vinculó a la página actual。
Esta información es útil para los webmasters, ya que les da una idea de las fuentes de tráfico y el comportamiento de los usuarios del sitio web.
Sin embargo, dado que la información de referencia puede contener información confidencial, comoBuscar palabras clave o la dirección URL de la última página visitada, por lo que algunos navegadores y software de seguridad de red pueden prohibir el envío de información de referencia, o filtrarla o anonimizarla al enviarla.
3. HTTP
3.1 ¿Por qué necesitas saber HTTP?
Al aprender sobre el rastreo, es muy importante comprender HTTP, porque HTTP es el protocolo básico utilizado por las aplicaciones web. HTTP (Protocolo de transferencia de hipertexto) es un protocolo de capa de aplicación para transferir hipertexto (incluidos archivos HTML, imágenes, audio, video, hojas de estilo, etc.).
Cuando se utiliza un rastreador para rastrear datos de sitios web, el rastreador primero debe enviar una solicitud HTTP y luego recibir una respuesta HTTP del servidor. Los rastreadores se comunican con los servidores web mediante HTTP, que dicta cómo se transmiten y presentan los datos. Por lo tanto, comprender los conceptos básicos del protocolo HTTP es crucial para aprender a rastrear.
3.2 Código de estado de respuesta HTTP: (¡hay un 404 familiar aquí!)
El primer dígito del código de estado HTTP define el tipo de código de estado, generalmente en los siguientes cinco tipos:
| código de estado | explicar |
|---|---|
| 1xx | Un código de estado informativo que indica que la solicitud ha sido recibida y el procesamiento continúa. |
| 2xx | Código de estado de éxito, que indica que el servidor ha recibido, entendido y aceptado correctamente la solicitud. |
| 3xx | Código de estado de redirección, que indica que se requieren más operaciones del cliente para completar la solicitud. |
| 4xx | El código de estado de error del cliente indica que hay un problema con la solicitud iniciada por el cliente y el servidor no puede entender o aceptar la solicitud. |
| 5xx | Código de estado de error del servidor, que indica que el servidor encontró un error al procesar la solicitud. |
4. Adquisición de datos web
4.1 La biblioteca más básica: el uso de la biblioteca de solicitudes
es una forma concisa y simple de manejar solicitudes HTTPbiblioteca de terceros, su mayor ventaja es que el proceso de programación es más cercano al proceso normal de acceso a URL.
Los documentos oficiales de enseñanza son los siguientes:
https://requests.readthedocs.io/projects/cn/zh_CN/latest/
Descarga de bibliotecas de terceros: Open , importación de bibliotecas de terceros: solicita construcciones y devuelve el objetopython Solicitud :cmdpip install + 第三方库名
import
r = requests.get(url)
El objeto Respuesta contiene toda la información devuelta por el servidor, así como la información de Solicitud solicitada.
Las propiedades son las siguientes:
| Atributos | ilustrar |
|---|---|
| r.status_code | El estado devuelto por la solicitud HTTP, 200 significa éxito, 404 significa falla |
| r.texto | La forma de la respuesta HTTP 字符串, el contenido de la página correspondiente a la url |
| r.content | La forma del contenido de la respuesta HTTP 二进制(imagen, video, audio) |
Aviso:
- Si el archivo de imagen se almacena en js, la decodificación debe importarse a la biblioteca json y luego
json.loads()decodificarse para formar el marco de datos requerido. De lo contrario, el código fuente es una cadena de cadenas y las operaciones posteriores no se pueden realizar.- Funciones utilizadas para codificar: importar
from urllib import parse,parse.quote()codificar usando
4.2 Obtener información del encabezado
- obtener
cookies:
import requests
from fake_useragent import UserAgent
r = requests.get(url,headers = headers)
# 方法一,items打印出列表形式,遍历后依次打印
for key,value in r.cookies.items():
print(key + "=" + value)
# 方法二,转换为字典形式
cookie = requests.utils.dict_from_cookiejar(r.cookies)
print(cookie)
-
obtener
headers, puede usarr.headers -
Para obtener la respuesta después de enviar la solicitud
url, puede usarr.url
4.3 Explicación detallada de los parámetros .get
requests.get()y requests.post() son dos bibliotecas de solicitudes HTTP comúnmente utilizadas en Python, que se pueden usar para enviar solicitudes GET y POST. Ambas funciones pueden aceptar múltiples parámetros, la siguiente es una explicación detallada de sus parámetros de uso común:
Para requests.get(url, params=None, **kwargs) la función :
- url: dirección URL de la solicitud.
- params: diccionario opcional o secuencia de bytes para pasar parámetros de solicitud.
- **kwargs: argumentos de palabra clave opcionales, que incluyen:
- encabezados: tipo de diccionario, información de encabezado de solicitud HTTP.
- tiempo de espera: establece el período de tiempo de espera.
- proxies: tipo de diccionario, dirección del servidor proxy.
1. Configuración cookie, el método de obtención se ha mencionado anteriormente.
2. Establecer proxyproxies
Sugerencia: si conoce la dirección del servidor se usa como criterio para juzgar: si la conoce, es un proxy de reenvío, si no la conoce, es un proxy inverso.
¿Por qué usamos proxies?
(1) Dejar que el servidor piense que el mismo cliente no está solicitando;
(2) Evitar que se filtre nuestra dirección real y ser responsable.
Uso:
Cuando necesitamos usar un proxy, lo mismoConstruir diccionario proxy, pasado al parámetro proxies.
3. Prohibición de verificación de certificados vertify
A veces usamos una herramienta de captura de paquetes. En este momento, dado que el certificado proporcionado por la herramienta de captura de paquetes no es emitido por una autoridad de certificación digital confiable, la verificación del certificado fallará. En este momento, necesita cerrar el certificado Verificar falso.
(3) Configuración timeout
De hecho, en la mayoría de los desarrollos de rastreadores, el parámetro de tiempo de espera se usa junto con el módulo de reintento (actualización).
El código se reproduce de un gran dios: haga clic aquí para saltar
import requests
from retrying import retry
headers = {
"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/532.2 (KHTML, like Gecko) Chrome/4.0.222.3 "}
@retry(stop_max_attempt_number=3) # stop_max_attempt_number=3最大执行3次,还不成功就报错
def _parse_url(url): # 前面加_代表此函数,其他地方不可调用
print("*"*100)
response = requests.get(url, headers=headers, timeout=3) # timeout=3超时参数,3s内
assert response.status_code == 200 # assert断言,此处断言状态码是200,不是则报错
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except Exception as e:
print(e)
html_str = None
return html_str
if __name__ == '__main__':
# url = "www.baidu.com" # 这样是会报错的!
url = "http://www.baidu.com"
print(parse_url(url))
4.4 Explicación detallada de los parámetros .post
Para la función request.post(url, data=None, json=None, **kwargs):
- url: dirección URL de la solicitud.
- datos: un diccionario, lista de tuplas o secuencia de bytes para enviar datos de formulario al servidor.
- json: datos en formato JSON, utilizados para enviar datos JSON.
- **kwargs: argumentos de palabra clave opcionales, que incluyen:
- encabezados: tipo de diccionario, información de encabezado de solicitud HTTP.
- tiempo de espera: establece el período de tiempo de espera.
- proxies: tipo de diccionario, dirección del servidor proxy.
Content-TypeEn el cuerpo de la solicitud HTTP, la relación con el método de envío de datos POST es la siguiente:
| Tipo de contenido | Cómo enviar datos |
|---|---|
| application/x-www-form-urlencoded | datos del formulario |
| multiparte/datos de formulario | Carga de archivo de formulario |
| aplicación/json | Serializar datos JSON |
| texto/xml | datos XML |
Al rastrear el código, asegúrese de encontrar la solicitud HTTP y cree la solicitud POST correcta; de lo contrario, no se podrá devolver el contenido correspondiente.
Se puede ver información más detallada y más parámetros en la documentación oficial:
- solicitudes.get(): https://docs.python-requests.org/en/latest/api/#requests.get
- solicitudes.post(): https://docs.python-requests.org/en/latest/api/#requests.post
4.5 La diferencia entre datos y parámetros
En la biblioteca de solicitudes de Python, datay paramsson parámetros utilizados para enviar solicitudes al servidor, pero sus funciones y escenarios de uso son ligeramente diferentes.
paramsPor lo general, se usa para pasar parámetros de cadena de consulta al enviar solicitudes GET. La cadena de consulta es un par clave-valor que aparece en la URL. Se incluyen después del signo de interrogación (?) en la URL, y varios pares clave-valor están separados por un símbolo &. Por ejemplo, supongamos que queremos enviar una solicitud GET a https://example.com/search y la cadena de consulta q contiene pagedos parámetros, podemos escribir así:
import requests
params = {
'q': 'python', 'page': '2'}
response = requests.get('https://example.com/search', params=params)
Después de enviar una solicitud, la biblioteca de solicitudesautomáticoCodifique los parámetros en params en la cadena de consulta de la URL,Obtener la URL completaes https://example.com/search?q=python&page=2.
dataPor lo general, se usa para enviar parámetros del cuerpo de la solicitud, como datos de formulario y datos JSON al enviar solicitudes POST. Se pasan al parámetro de datos como un diccionario, que luego la biblioteca de solicitudes codificará en el formato apropiado para enviar al servidor. Por ejemplo, supongamos que queremos enviar una solicitud POST a https://example.com/login que contienenombre de usuario y contraseñaDos campos de formulario se pueden escribir así:
import requests
data = {
'username': 'alice', 'password': 'secret'}
response = requests.post('https://example.com/login', data=data)
Después de enviar la solicitud, la biblioteca de solicitudes codificará automáticamente los parámetros en los datos en el formato application/x-www-form-urlencoded o multipart/form-data, y lo enviará al servidor como el cuerpo de la solicitud.
Cabe señalar que,
paramsaunquedatatienen funciones y escenarios de uso ligeramente diferentes, todos son parámetros opcionales y puede optar por usarlos o no según la situación real.
4.6 Obtener la respuesta
r.text, para obtener el contenido devuelto por la url.
r.josnSi los datos que obtenemos después de acceder están en formato JSON, entonces podemos usar el método json() para obtener directamente los datos convertidos en formato de diccionario. Después de eso, use json.loads()para decodificar.
4.7 Poco conocimiento
Punto de conocimiento 1:
a veces nos encontramos con el mismo nombre de parámetro de URL, pero con diferentes valores, y el diccionario de Python no admite el mismo nombre de la clave, entonces podemos representar el valor de la clave como una lista:
import requests
params = {
'key': 'value1', 'key2': ['value2', 'value3']}
resp = requests.get("http://httpbin.org/get", params=params)
print(resp.url)
Punto de conocimiento dos:
Nota: solo uno de json y datos pueden existir al mismo tiempo
5. Aplicación técnica de visualización de datos (framework, componentes, etc.) 【actualización continua】
Suplemento: Dificultades en el desarrollo de rastreadores (avanzado)
Dificultades de los reptiles.
La dificultad de los reptiles se divide principalmente en dos direcciones:
- Todos los recursos públicos de la red de adquisición de datos
están preparados para los usuarios. Para evitar que los rastreadores los recopilen, el servidor configurará muchas pruebas de Turing para evitar el rastreo malicioso de los rastreadores, es decir,Medidas anti-escalada. En el proceso de desarrollo de rastreadores, gran parte de nuestro trabajo consiste en abordar estas medidas anti-rastreo. - La velocidad de recopilación
En la era de los grandes datos, se requiere una gran cantidad de datos, a menudo al nivel de decenas de millones o incluso cientos de millones. Si la velocidad de recolección no puede mantenerse y toma demasiado tiempo, no cumplirá con los requisitos comerciales. Generalmente, adoptaremos concurrencia y distribución para resolver el problema de la velocidad. Este es otro enfoque en el proceso de desarrollo del rastreador.
Nota: El nombre de dominio puede determinar qué computadora; y el número de puerto es para determinar qué aplicación de esa computadora
expresión regular
re.findall(b"From Inner Cluster \r\n\r\n(.*?)",first_data,re.s)Qué significa este código
Explicación:
1. La función de esta expresión regular es first_dataencontrar todas las subcadenas que comienzan con "From Inner Cluster" de la cadena, seguido de dos retornos de carro (\r\n\r\n), y luego cualquier carácter, y devuelve un lista.
2. re.sLa bandera se usa en el tercer parámetro del método re.findall() para indicar que el .en el patrón de expresión regular puede coincidirincluyendo saltos de líneacualquier carácter en el .