Tabla de contenido
1.1 Resumen del algoritmo de interpolación (parámetro de modo)
1.2 Explicación del parámetro align_corners
2.1 Agrupación promedio y agrupación anti-promedio
2.2 Agrupación máxima y agrupación antimáxima
3. Convolución transpuesta (deconvolución)
Hay dos métodos comúnmente utilizados para reducir la resolución en el aprendizaje profundo: agrupación y convolución con un tamaño de paso de 2, y hay tres métodos comúnmente utilizados en el proceso de aumento de resolución: interpolación, desagrupación y deconvolución. Ya sea que se trate de segmentación semántica, detección de objetivos o modelos de reconstrucción 3D, es necesario ampliar las características de alto nivel extraídas y, en este momento, es necesario aumentar la muestra del mapa de características. El siguiente artículo resumirá específicamente los métodos de muestreo superior en el aprendizaje profundo.
1. Interpolación
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)
参数说明:
①size:可以用来指定输出空间的大小,默认是None;
②scale_factor:比例因子,比如scale_factor=2意味着将输入图像上采样2倍,默认是None;
③mode:用来指定上采样算法,有'nearest'、 'linear'、'bilinear'、'bicubic'、'trilinear',默认是'nearest'。上采样算法在本文中会有详细理论进行讲解;
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。此处True和False的区别本文中会有详细的理论讲解;
⑤recompute_scale_factor:如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None, antialias=False)
参数说明:
①input:输入张量;
②size:可以用来指定输出空间的大小,默认是None;
③scale_factor:比例因子,比如scale_factor=2意味着将输入图像上采样2倍,默认是None;
④mode:用来指定上采样算法,有'nearest'、 'linear'、'bilinear'、'bicubic'、'trilinear',默认是'nearest'。上采样算法在本文中会有详细理论进行讲解;
④align_corners:如果True,输入和输出张量的角像素对齐,从而保留这些像素的值,默认是False。此处True和False的区别本文中会有详细的理论讲解;
⑤recompute_scale_factor:如果recompute_scale_factor是True,则必须传入scale_factor并且scale_factor用于计算输出大小。计算出的输出大小将用于推断插值的新比例。请注意,当scale_factor为浮点数时,由于舍入和精度问题,它可能与重新计算的scale_factor不同。如果recompute_scale_factor是False,那么size或scale_factor将直接用于插值。1.1 Resumen del algoritmo de interpolación (parámetro de modo)
Los métodos comúnmente utilizados en los algoritmos de interpolación incluyen la interpolación más cercana, la interpolación lineal, la interpolación bilineal, etc. Aquí solo explicaremos los métodos de interpolación más cercana y de interpolación bilineal más utilizados.
1.1.1 Interpolación del vecino más cercano
El método de interpolación del vecino más cercano calculará directamente la distancia entre el píxel de salida asignado al punto u en el sistema de coordenadas de la imagen de entrada y los cuatro vecinos más cercanos (n1, n2, n3, n4) y asignará el valor de píxel del píxel más cercano a u a u. La velocidad de cálculo del método de interpolación del vecino más cercano es muy rápida, pero la nueva imagen destruye parcialmente la relación de gradiente de la imagen original.

1.1.2 Método de interpolación bilineal
La interpolación bilineal, también conocida como interpolación de primer orden, calcula el valor a interpolar en función de los 2 * 2 = 4 valores conocidos más cercanos al valor a interpolar. El peso de cada valor conocido está determinado por la distancia desde el valor a interpolar. Cuanto más cerca esté el peso, mayor será el peso. La interpolación bilineal consiste en calcular un total de 3 veces de interpolación lineal única en dos direcciones, como se muestra en la figura siguiente, suponiendo que los puntos rojos en la figura representan los puntos de píxeles con valores de píxeles conocidos en la imagen original, y sus Las coordenadas son punto, punto
, punto
, punto
, los valores de píxeles de estos 4 puntos rojos se expresan respectivamente
, donde
están las coordenadas del punto verde que se va a interpolar
, se requiere utilizar el método de interpolación bilineal para encontrar el valor de píxel. del punto P a interpolar.
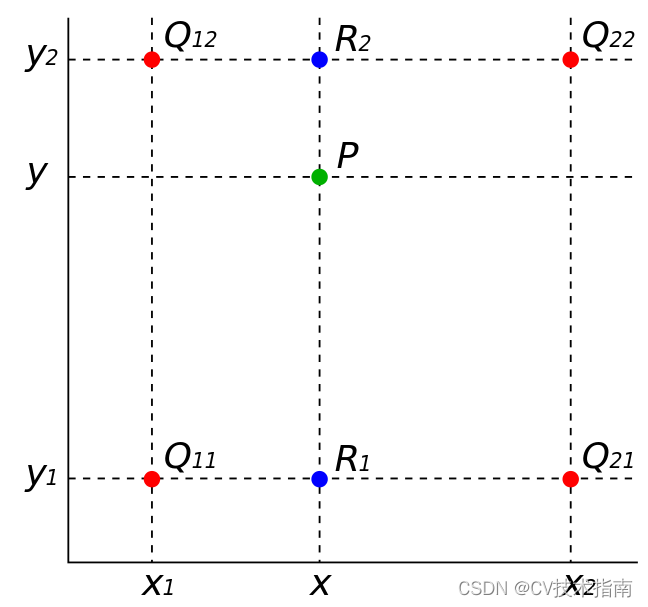
El proceso de cálculo es el siguiente:
1) Realice dos interpolaciones lineales simples en la dirección del eje x para obtener la suma de los valores de píxeles del punto azul y la suma respectivamente ;
1) Realice una única interpolación lineal en la dirección del eje y para obtener el valor de píxel del punto P.
1.2 Explicación del parámetro align_corners
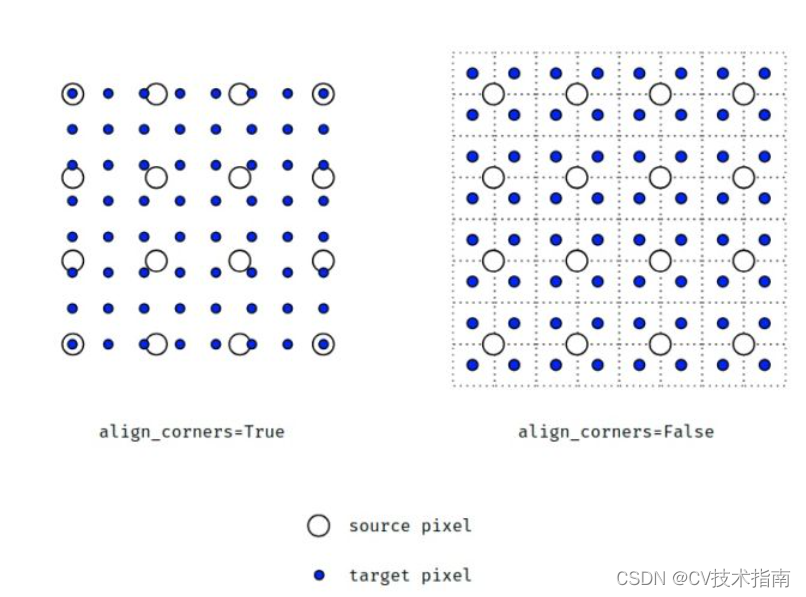
El parámetro align_corners está configurado en Verdadero y Falso, y los resultados del muestreo ascendente son diferentes, como se muestra en el siguiente código que ejecuta los resultados.
import torch
input = torch.arange(1, 10, dtype=torch.float32).view(1, 1, 3, 3)
print(input)
m = torch.nn.Upsample(scale_factor=2, mode='bilinear')
output1 = m(input)
print(output1)
n = torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
output2 = n(input)
print(output2)
La razón principal de los diferentes resultados del muestreo ascendente es la forma diferente de ver los píxeles:
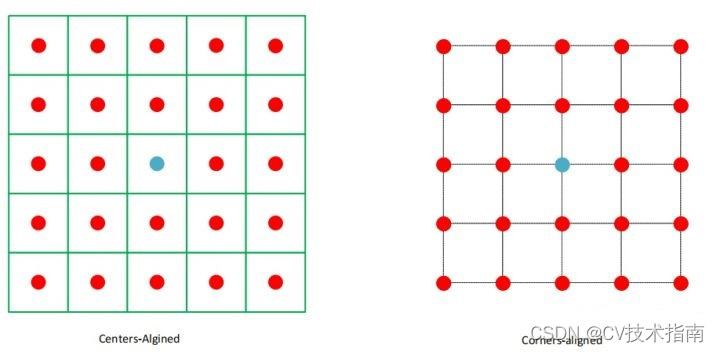
①Alineado con el centro: piense en un píxel como un cuadrado con un área, y la posición del punto central del cuadrado representa el píxel. align_corners=False trata los píxeles de esta manera. Las coordenadas de los píxeles no son los subíndices correspondientes a la matriz de la imagen, pero los subíndices deben agregarse para ser las i,jcoordenadas 0.5de cada píxel en el sistema de coordenadas en este momento (arriba a la izquierda La esquina es el origen, el eje x es positivo hacia la derecha y el eje y es positivo hacia abajo) .
② Esquinas alineadas: considere un píxel como un punto ideal y la posición de este punto representa este píxel. align_corners=True trata los píxeles de esta manera y el subíndice de cada píxel en la matriz i,jse considera directamente como un punto de coordenadas en el sistema de coordenadas para el cálculo.
En cuanto a estos dos casos, ¿cómo se calculan los resultados respectivos después del muestreo ascendente? No sé cómo expresarlo para que todos puedan entenderlo a fondo. Todos pueden entenderlo por sí mismos. Aquí hay algunas imágenes que son útiles para la comprensión.
2. Anti-agrupación
La desagrupación es la operación inversa de la agrupación. Es imposible restaurar todos los datos originales a través del resultado de la agrupación. Hoy en día, este método rara vez se utiliza para realizar un muestreo superior de imágenes. Porque el proceso de agrupación solo retiene la información principal y descarta parte de la información. Si desea recuperar toda la información de la información principal después de la agrupación, faltará información. En este momento, la única forma de lograr el mayor grado de integridad de la información es completar los bits. Hay dos tipos de agrupación: agrupación máxima y agrupación promedio, y su antiagrupación también debe corresponder a ellos.
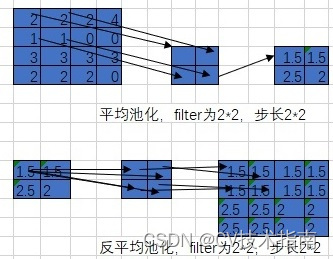
2.1 Agrupación promedio y agrupación anti-promedio
Primero restaure al tamaño original y luego complete cada valor en el resultado de la agrupación en la posición correspondiente en el área de datos original correspondiente. El proceso de agrupación promedio y agrupación antipromedio es el siguiente:
2.2 Agrupación máxima y agrupación antimáxima
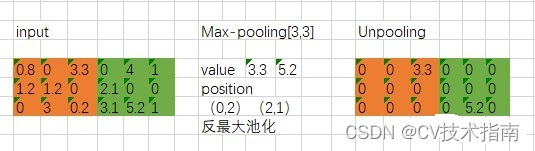
Es necesario registrar la posición de coordenadas del valor de activación máximo durante el proceso de agrupación, y luego solo activar el valor de coordenadas de la posición del valor de activación máximo durante el proceso de agrupación durante la desagrupación, y establecer los otros valores en 0. Por supuesto, este proceso es sólo aproximado. Porque en el proceso de agrupación, excepto la posición del valor máximo, otros valores no son 0.
El proceso de agrupación máxima y agrupación antimáxima es el siguiente:
3. Convolución transpuesta (deconvolución)
A continuación se explicará en detalle el principio de implementación específico del uso de la deconvolución para realizar un muestreo ascendente de imágenes. Tomando la función torch.nn.ConvTranspose2d () como ejemplo, el significado de los parámetros en esta función es básicamente el mismo que el de la antorcha. Función nn.Conv2d().
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
参数说明:
in_channels:输入的通道数
out_channels:输出的通道数
kernel_size:卷积核的大小
stride:卷积核滑动的步长,默认是1
padding:怎么填充输入图像,此参数的类型可以是int , tuple或str , optional 。默认padding=0,即不填充。
dilation:设置膨胀率,即核内元素间距,默认是1。即如果kernel_size=3,dilation=1,那么卷积核大小就是3×3;如果kernel_size=3,dilation=2,那么卷积核大小为5×5
groups:通过设置这个参数来决定分几组进行卷积,默认是1,即默认是普通卷积,此时卷积核通道数=输入通道数
bias:是否添加偏差,默认true
padding_mode:填充时,此参数决定用什么值来填充,默认是'zeros',即用0填充,可选参数有'zeros', 'reflect', 'replicate'或'circular'
La deconvolución también se conoce como convolución transpuesta y convolución en pasos fraccionarios. De hecho, el nombre más preciso para esta función debería ser convolución transpuesta. La razón está relacionada con la implementación del código subyacente de convolución y convolución transpuesta.
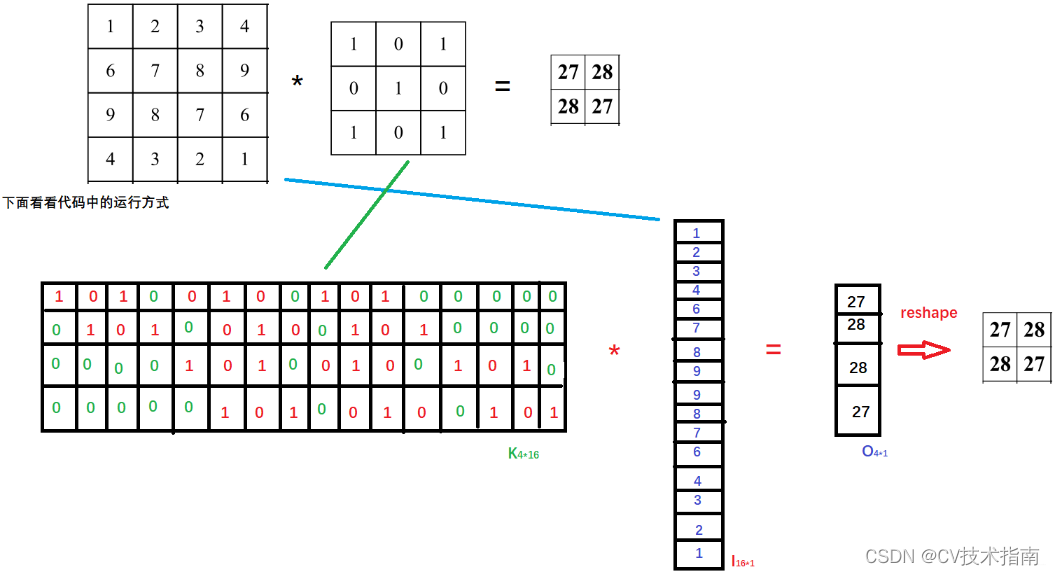
Antes de explicar esto, debemos echar un vistazo a una operación específica de convolución normal en el proceso de implementación del código. Para una convolución normal, necesitamos implementar una gran cantidad de operaciones de multiplicación y suma, y esta forma de multiplicar y sumar resulta ser en lo que la multiplicación de matrices es buena. Entonces, cuando se implementa el código, la operación de convolución generalmente se implementa rápidamente con la ayuda de la multiplicación de matrices, entonces, ¿cómo se hace esto? Supongamos que el tamaño de la imagen de entrada es 4 × 4, el núcleo de convolución es 3 × 3, relleno = 0, paso = 1, se puede saber mediante cálculo que el tamaño de la imagen de salida después de la convolución es 2 × 2, como se muestra en la siguiente figura:
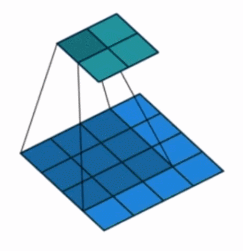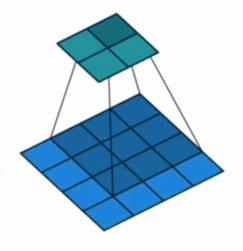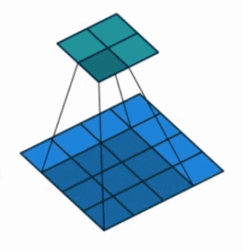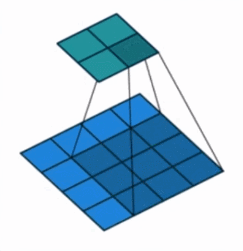
El proceso específico de convolución convencional en la implementación del código es: primero convertir la matriz de 4 × 4 que representa la imagen de entrada en un vector de columna de 16 × 1. Dado que el cálculo muestra que la imagen de salida es una matriz de 2 × 2, también se convierte en una matriz de 4 × 2. Vector de 1 columna, entonces se puede saber por la multiplicación de matrices que la matriz de parámetros debe ser 4 × 16, entonces, ¿de dónde viene esta matriz de parámetros de 4 × 16? De la figura anterior se desprende claramente que 4 significa que la ventana del núcleo de convolución se desliza 4 veces para atravesar toda la imagen de entrada. Este 16 es colocar primero los 9 pesos de 3 × 3 en una fila y luego deslizar la imagen de entrada de acuerdo con a la ventana. La posición se complementa con 7 0 para formar 16 parámetros. Estos 16 parámetros son los parámetros de peso correspondientes a los 16 píxeles de la imagen de entrada, a saber:
Genere la remodelación del vector 4 × 1 para representar la matriz de 2 × 2 de la imagen de salida. La siguiente figura es un ejemplo de multiplicación de matrices para convolución convencional:
Ahora veamos cómo se implementa la convolución transpuesta en el código. La convolución transpuesta es un método de muestreo ascendente. El tamaño de la imagen de entrada es relativamente pequeño. Después de la convolución transpuesta, se generará una imagen más grande. Supongamos que el tamaño de la imagen de entrada es 2 × 2, el núcleo de convolución es 3 × 3, relleno = 0, zancada = 1 y la imagen de salida de 4 × 4 se obtendrá transponiendo la convolución, como se muestra en la siguiente figura:

El proceso específico de convolución transpuesta en la implementación del código es: primero convertir la matriz de 2 × 2 que representa la imagen de entrada en un vector de columna de 4 × 1, dado que la imagen de salida después de la convolución transpuesta es una matriz de 4 × 4, también se convierte en una Vector de columna de 16 × 1, entonces se puede saber por la multiplicación de matrices que la matriz de parámetros debe ser 16 × 4, entonces, ¿de dónde proviene esta matriz de parámetros de 16 × 4? De la figura anterior se puede ver que 16 significa que la ventana del núcleo de convolución se ha deslizado 16 veces para atravesar toda la imagen de entrada. Aunque el núcleo de convolución aquí tiene 9 pesos, solo hay cuatro como máximo que se pueden multiplicar por la imagen ( es decir, cuando el núcleo de convolución está en el medio), este es el significado de 4 en la matriz de parámetros, a saber:
Genere la remodelación del vector de 16 × 1 para representar la matriz de 4 × 4 de la imagen de salida. La siguiente figura es un ejemplo de multiplicación de matrices para convolución transpuesta: 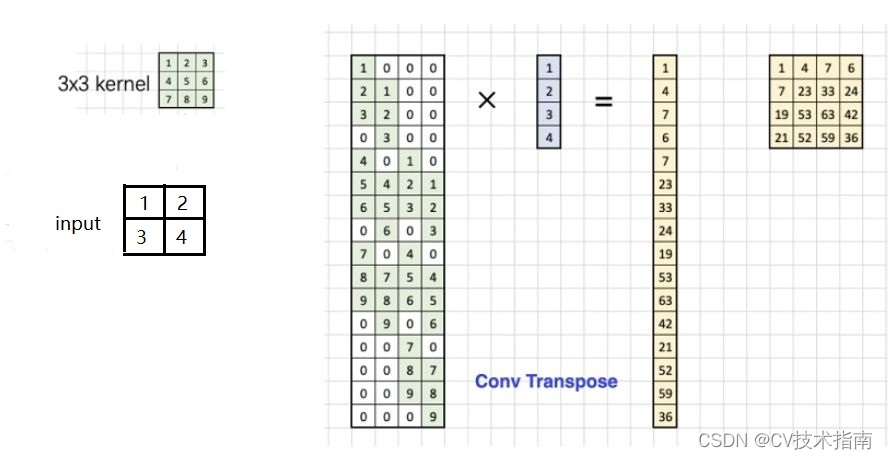
A través del proceso de implementación del código de convolución convencional y convolución transpuesta, no es difícil encontrar que la matriz de convolución utilizada en estas dos operaciones de convolución
es precisamente la relación de transposición en forma, que es el origen de la convolución transpuesta. Tenga en cuenta que lo que se menciona aquí es la forma y el valor específico debe ser diferente.