Este artículo es una compilación del intercambio de Pan Cheng, ingeniero de software de Netease Shufan, en ASF CommunityOverCode Asia 2023 (Beijing). El contenido de este artículo es principalmente: 1) Los beneficios y desafíos de Spark Cloud Native; 2) Cómo construir una puerta de enlace de tareas Spark unificada basada en Apache Kyuubi; 3) Cómo construir un servicio Shuffle basado en Apache Celeborn (incubación); 4 ) Soporte de NetEase para Spark en otros aspectos Mejoras en los esquemas de Kubernetes.

En los últimos años, NetEase ha realizado grandes exploraciones en el campo de los big data nativos de la nube. Este artículo se centra en cómo construir una plataforma informática fuera de línea nativa de la nube Spark en Kubernetes a nivel empresarial basada en tecnologías de código abierto como Apache Kyuubi y Celeborn, incluida la selección de tecnología, el diseño de la arquitectura, las lecciones aprendidas, la mejora de defectos, la reducción de costos y el aumento de la eficiencia. , etc. resultados de la investigación en este campo.
01 Beneficios y desafíos de Spark en Kubernetes
Apache Spark, como estándar de facto en el campo de la informática fuera de línea de big data, se utiliza ampliamente en los productos internos y comerciales de NetEase, como los centros de datos. En la actualidad, Spark on YARN es el método de uso más común y maduro en la industria, pero con la popularidad de la tecnología nativa de la nube representada por Kubernetes, Spark on K8 está siendo favorecido por cada vez más usuarios.
Netease ha estado explorando Spark en la tecnología K8 desde 2018. En comparación con Spark on YARN, Spark on K8 tiene ventajas significativas en muchos aspectos; al mismo tiempo, como tecnología relativamente nueva, no es tan completo como Spark on YARN en algunos aspectos. Hagamos una comparación simple de algunas de las partes más críticas:
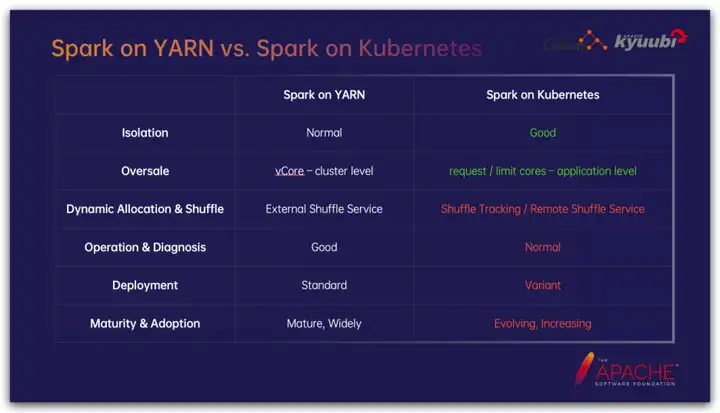
En términos de aislamiento, gracias al soporte de la tecnología de contenedores, Spark en K8 tiene ventajas significativas sobre el mecanismo de aislamiento de trabajos a nivel de proceso de YARN. Por un lado, la contenedorización simplifica enormemente la gestión de dependencias de los trabajos de Spark, especialmente el aislamiento de las dependencias de Python y las bibliotecas de enlaces dinámicos; al mismo tiempo, la contenedorización coopera con el mecanismo cgroup para restringir los recursos del trabajo de manera más estricta y precisa.
En las estrategias de gestión de recursos a nivel de clúster, las aplicaciones a menudo no utilizan el 100% de los recursos que solicitan. La sobresuscripción es una estrategia común para mejorar la utilización de los recursos del clúster. Tomando la CPU como ejemplo, YARN puede establecer la proporción de núcleo virtual a núcleo físico a nivel de clúster, es decir, la proporción de sobresuscripción de CPU, pero los K8 pueden admitir la proporción de sobresuscripción de CPU a nivel de trabajo; las tareas en el clúster tienen diferentes tasas de utilización de CPU. Para muchos trabajos con muchas E/S representados por la transmisión de datos, establecer una tasa de sobresuscripción de CPU más alta puede ahorrar en gran medida recursos de la CPU.
La asignación dinámica de recursos es una característica muy importante para que los trabajos de Spark mejoren la utilización de recursos. En Spark en YARN, el servicio de reproducción aleatoria externo reside en cada proceso de NodeManager como un complemento para proporcionar servicios de lectura para los datos de reproducción aleatoria del nodo actual. Por lo tanto, Executor puede salga en cualquier momento sin considerar cómo la tarea de reducción posterior lee los datos aleatorios, pero en los K8 no hay un componente correspondiente, sino que hay muchas soluciones opcionales, que se discutirán en detalle más adelante.
Spark en YARN proporciona muchas funciones auxiliares, como YARN, naturalmente, tiene el concepto de Aplicación, proporciona servicios de agregación de registros, admite agentes Spark Live UI, etc., que no están disponibles de fábrica en Spark en K8.
En términos de soluciones de implementación, Spark en YARN proporciona una solución estandarizada; sin embargo, Spark en K8 tiene varias formas de jugar, como la solución aleatoria mencionada anteriormente, y tome el envío de tareas como ejemplo, representado por Spark Operador El envío yaml El esquema y el esquema nativo de envío de chispas de Spark emergen sin cesar.
Al mismo tiempo, nos enfrentamos a un desafío muy común: los usuarios tienen diferentes infraestructuras de Kubernetes. ¿Cómo podemos aprovechar sus respectivas características tanto como sea posible y maximizar los beneficios mientras admitimos varias infraestructuras?

Por ejemplo, existen diferencias significativas en la infraestructura representada por la nube pública y el despliegue privatizado: en línea con el principio de reducir costos y aumentar la eficiencia, en términos de ventajas de costos:
- Además de admitir el sistema de compra basado en el tiempo, la nube pública también proporciona un modo de pago por uso, según los diferentes tipos de recursos, generalmente cuando la tasa de uso general es inferior al 30% al 60% del total. tiempo, se puede utilizar el pago por uso. Reducir significativamente los costos; las instancias de licitación de nube pública son significativamente competitivas en precio, pero están llenas de incertidumbre y el riesgo de ser adelantadas en cualquier momento;
- El hardware implementado de forma privada, naturalmente, no es tan flexible como la nube pública y, básicamente, debe comprarse con anticipación. Para maximizar la utilización de recursos, a menudo comenzamos con la mezcla fuera de línea. Por lo general, el pico de los negocios en línea es durante el día y el pico de las tareas fuera de línea es durante la noche. Mediante la implementación híbrida y la transferencia de recursos, se mejora la tasa de utilización de los recursos del clúster y se reduce el costo general.
El almacenamiento es un objeto que necesita mucha atención en Spark en K8. En la nube pública, generalmente se pueden proporcionar discos de red de varias especificaciones para cumplir con diversos requisitos de montaje remoto; mientras que los escenarios de implementación privada a menudo están sujetos a grandes restricciones, en su mayoría discos locales vinculados a nodos físicos, en consecuencia, el mismo rendimiento de IO El hardware local tiende a ser menos costoso en términos de capacidad y capacidad.
Otro hardware, como las tarjetas de red, las CPU y la memoria, también son similares. Las nubes públicas pueden proporcionar de manera flexible varias proporciones; las implementaciones privadas se limitan en su mayoría a especificaciones y modelos específicos, pero el precio unitario suele ser más bajo.
02 Cómo construir una puerta de enlace de tareas Spark unificada basada en Apache Kyuubi
Dentro de NetEase, todos los servicios Spark están alojados. Usamos Apache Kyuubi como una puerta de enlace unificada para el envío de tareas de Spark. Kyuubi proporciona múltiples interfaces de usuario y admite varios tipos de tareas de Spark. Los escenarios de uso típicos incluyen: los usuarios pueden usar JDBC/BeeLine y varias herramientas de BI para conectarse para realizar análisis de datos interactivos; usar API RESTful para enviar trabajos por lotes SQL/Python/Scala/Jar a Kyuubi.
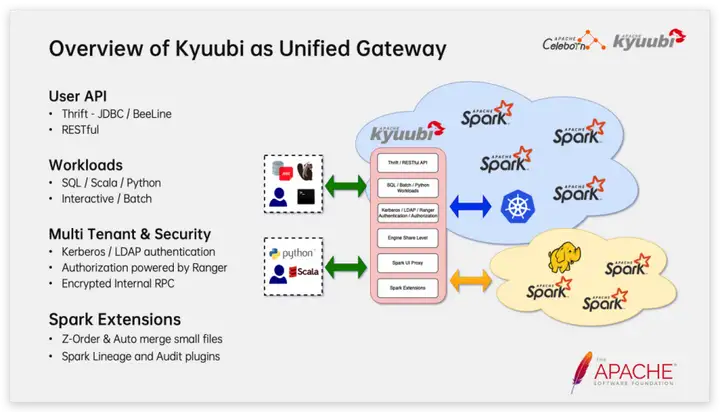
Como puerta de enlace de big data a nivel empresarial, Kyuubi también es totalmente compatible con la seguridad y el arrendamiento múltiple. Por ejemplo, Kyuubi ha realizado adaptaciones profundas en el soporte de Kerberos, como simplificar la forma en que los clientes JDBC usan la autenticación Kerberos; al admitir Kerberos/LDAP al mismo tiempo, el cliente puede elegir cualquier método de autenticación; admitir el mecanismo del agente de usuario de Hadoop, al mismo tiempo que garantiza seguridad, ahorra la gestión de una gran cantidad de tablas de claves de usuario; admite la renovación del token de delegación de Hadoop y cumple con los requisitos de autenticación de las tareas residentes de Spark, etc.
Kyuubi tiene muchos usuarios comunitarios y contribuyentes de corretajes financieros y empresas europeas y americanas. Tienen requisitos de seguridad más extremos. Por ejemplo, la comunicación interna entre los componentes del servicio también debe estar encriptada y admite control de permisos y auditoría SQL. tales escenarios También competente.
Además de la función principal como puerta de enlace, Kyuubi también proporciona una serie de complementos Spark que se pueden usar de forma independiente y que pueden proporcionar funciones de nivel empresarial como administración de archivos pequeños, orden Z, extracción de linaje SQL y limitación del cantidad de escaneo de datos de consulta.
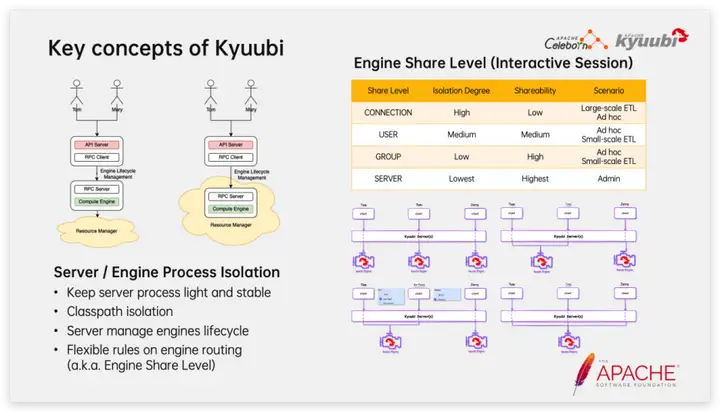
En términos de arquitectura, los dos componentes importantes de Kyuubi son el servidor y el motor. Entre ellos, Server es un servicio residente liviano y Engine es una aplicación Spark que se inicia y detiene según demanda. Después de que el cliente se conecta, el servidor Kyuubi buscará un motor adecuado de acuerdo con las reglas de enrutamiento. Si no hay resultados, llamará a Spark-Submit para abrir una nueva aplicación Spark. Cuando la aplicación Spark esté inactiva por un período de tiempo , saldrá activamente para liberar recursos. Kyuubi eligió utilizar la forma nativa de Spark para conectarse a Kubernetes en lugar del modo Spark Operador. Esta elección le permite a Kyuubi usar de manera más consistente el comando spark-submit para conectarse a diferentes sistemas de administración de recursos, como YARN, Mesos e Standalone. Este diseño es más adecuado para una transición fluida a una arquitectura de big data nativa de la nube para empresas que ya cuentan con una infraestructura de big data.
Para sesiones interactivas, Kyuubi propuso creativamente el concepto de nivel de uso compartido del motor. Hay cuatro opciones integradas: CONEXIÓN, USUARIO, GRUPO y SERVIDOR. El aislamiento se reduce a su vez y el grado de uso compartido aumenta a su vez. Pueden Se pueden usar juntos para cumplir con varios escenarios de carga. Por ejemplo, el nivel de uso compartido CONNECTION genera una aplicación Spark separada para cada sesión, lo que garantiza de manera efectiva el aislamiento entre sesiones, y generalmente se usa para tareas de programación ETL a gran escala; el nivel de uso compartido USER permite que el mismo usuario reutilice la misma aplicación Spark. , Esto acelera el inicio de nuevas sesiones y garantiza que otras no se verán afectadas cuando la aplicación Spark se cierra inesperadamente (como OOM causado por consultas de conjuntos de resultados grandes). Para tareas por lotes, solo se admite la semántica similar al nivel de uso compartido CONNECTION, y Kyuubi se comporta más como un sistema de programación de tareas en este momento.
Kyuubi Server está diseñado como una puerta de enlace liviana. En contraste, la estabilidad de Kyuubi Engine es ligeramente menor. Es muy probable que se produzca OOM debido a que la consulta devuelve un gran conjunto de resultados. Estabilidad, al mismo tiempo, el diseño del El nivel de uso compartido del motor controla bien el rango de impacto del choque del motor.
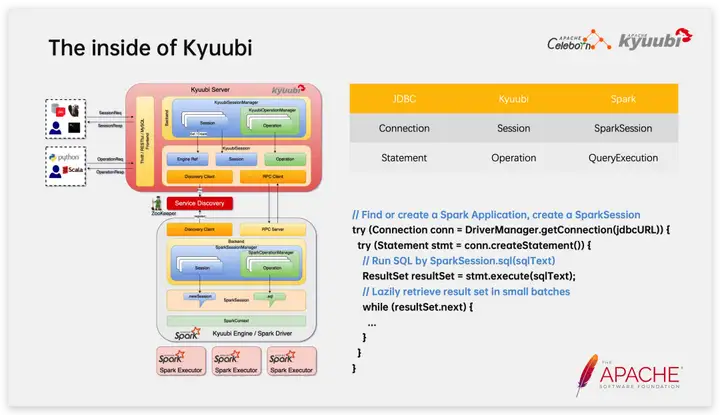
En términos de implementación interna específica, hay dos conceptos importantes en la sesión interactiva de Kyuubi: Sesión y Operación, que corresponden a Conexión y Declaración en JDBC, y SparkSession y QueryExecution en Spark respectivamente.
Lo anterior es un código típico para conectarse a Kyuubi para ejecutar Spark SQL a través del controlador JDBC, y puede ver claramente la correspondencia entre la llamada JDBC del cliente y el lado del motor Spark. En particular, al extraer el conjunto de resultados, el conjunto de resultados se devolverá al cliente desde Spark Driver a través del servidor Kyuubi en forma de microlote, lo que reduce efectivamente la presión de la memoria del servidor Kyuubi y garantiza la estabilidad del servidor Kyuubi; en la última versión 1.7, Kyuubi admite el método de serialización de conjuntos de resultados basado en Apache Arrow, lo que mejora en gran medida la eficiencia de transmisión de escenarios de conjuntos de resultados grandes.
03 Cómo construir un servicio aleatorio basado en Apache Celeborn (en incubación)
Como se mencionó anteriormente, el esquema de reproducción aleatoria juega un papel vital en la asignación dinámica de recursos de Spark en K8, y el Executor solo se puede lanzar bajo la premisa de garantizar que los datos de lectura aleatoria descendentes no se vean afectados. En los últimos años, la comunidad y las principales empresas han surgido sin cesar en la solución aleatoria. A continuación se presenta una breve introducción a varios de los métodos más convencionales.
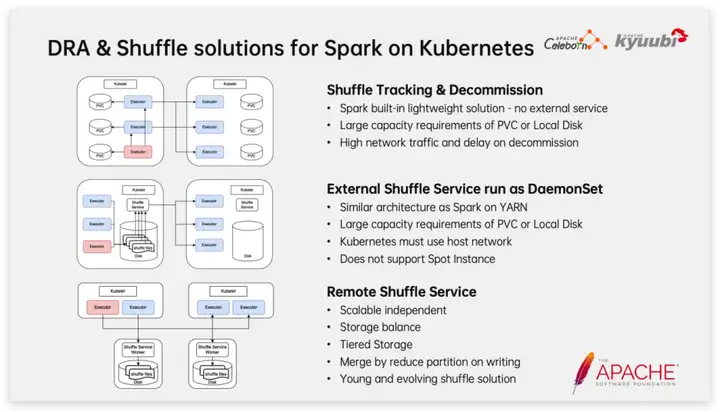
El primero es Shuffle Tracking combinado con desmantelamiento, que es una solución liviana integrada en Spark y no requiere mantenimiento de servicios adicionales. El seguimiento aleatorio consiste en analizar qué datos aleatorios se pueden consumir en sentido descendente mediante el seguimiento del linaje de RDD y luego evitar que estos Ejecutores salgan para garantizar la prestación de servicios de lectura de datos aleatorios. Obviamente, la salida retrasada provocará un cierto desperdicio de recursos y no podrá manejar el Ejecutor OOM. El desmantelamiento es un medio complementario. Cuando el Ejecutor está inactivo durante un período de tiempo, los datos aleatorios se mueven al Ejecutor que no ha agotado el tiempo de espera antes de salir. Según nuestra práctica, esta solución no funciona bien cuando la cantidad de datos es grande y la carga del clúster es alta.
Otra idea natural es reproducir la solución en YARN en K8, es decir, iniciar un proceso de servicio aleatorio externo en cada nodo K8 a través de DaemonSet para proporcionar un servicio de lectura aleatoria. Esta solución es completamente consistente con Spark on YARN en términos de rendimiento y confiabilidad, y se aplicó en cierta escala en los primeros días de Netease. Pero al mismo tiempo, existen ciertas desventajas, como que no se aplica a instancias de licitación (solo se pueden usar Pods y no se permite iniciar DaemonSets en Nodos) y se requiere Host Network.
En los últimos uno o dos años, la solución Remote Shuffle Service ha sido favorecida por cada vez más usuarios. Con el desarrollo de la tecnología de tarjetas de red, la diferencia de eficiencia entre la lectura y escritura en red y la lectura y escritura en disco se ha reducido gradualmente. En teoría, convertir la lectura y escritura en disco local de la reproducción aleatoria nativa de Spark en lectura y escritura en red no necesariamente causará desventajas en actuación. Lo más importante es que al implementar Shuffle Service como un servicio separado, el escalado bajo demanda está más en línea con el concepto nativo de la nube; al mismo tiempo, también podemos tener más espacio operativo, como mejorar la utilización al equilibrar el espacio de almacenamiento entre nodos. y el almacenamiento garantiza el rendimiento al tiempo que reduce la demanda de capacidad de disco de alto rendimiento. Sin embargo, debemos dejar claro que desde el nacimiento del proyecto Spark, la reproducción aleatoria se ha mejorado continuamente como característica principal; como tecnología relativamente nueva, el Servicio de reproducción aleatoria remota tendrá un largo camino por recorrer en términos de estabilidad, corrección y rendimiento. .Camina.
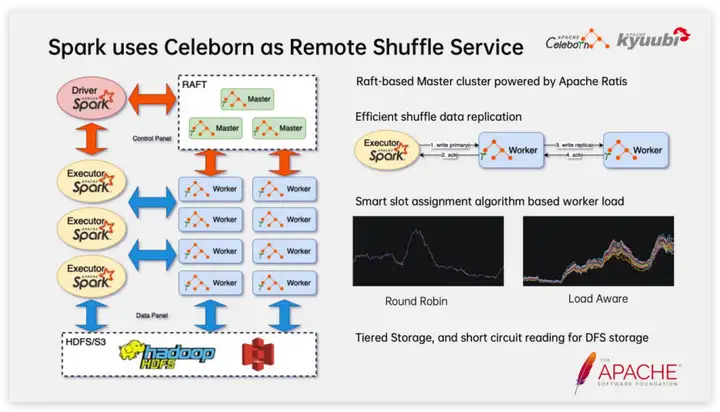
En la selección de tecnología específica del Servicio aleatorio remoto, NetEase optó por crear una plataforma interna del Servicio aleatorio basada en Apache Celeborn (Incubating). Las características principales en las que nos centramos incluyen:
- El servidor Celeborn incluye dos roles, Maestro y Trabajador. Entre ellos, Master desempeña un papel de coordinación y es un clúster Raft con buenas capacidades de recuperación ante desastres y admite actualizaciones continuas; los trabajadores sirven como nodos de datos para proporcionar servicios de lectura y escritura de datos aleatorios y pueden expandirse y reducirse en cualquier momento según la carga. y el latido entre componentes, el mecanismo de verificación de estado puede descubrir y eliminar rápidamente nodos trabajadores defectuosos;
- Celeborn proporciona un mecanismo de copia asincrónico y eficiente, que tiene poco impacto en el rendimiento después de que se enciende. El Cliente solo necesita escribir datos en el nodo de trabajo principal con éxito para regresar, y el nodo de trabajo principal copiará de forma asincrónica los datos aleatorios al nodo trabajador de respaldo;
- Según la carga del trabajador, la partición aleatoria se puede asignar de forma inteligente para hacer que la carga del clúster sea más equilibrada. Esto es muy importante para implementar trabajadores en nodos heterogéneos. Por ejemplo, algunos nodos usan SSD, mientras que otros usan HDD; otro ejemplo es la diferencia en el rendimiento de diferentes discos de trabajo causada por el uso mixto de servidores nuevos y antiguos y el envejecimiento del hardware;
- Se admite el almacenamiento jerárquico y, para el almacenamiento distribuido, el Cliente puede leer datos directamente del sistema de almacenamiento, lo que reduce la presión sobre el Trabajador.
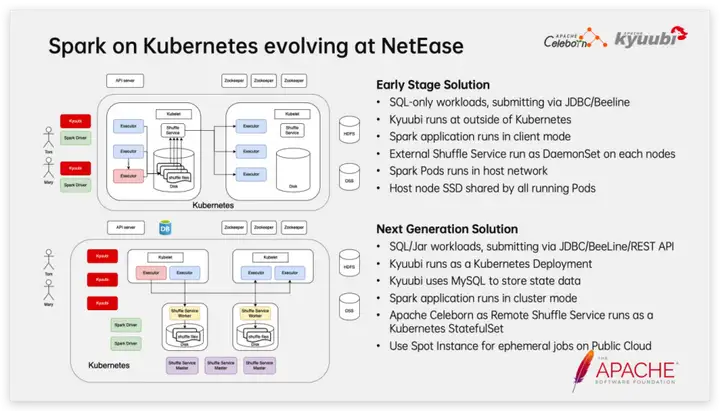
Resuma el proceso de evolución de Spark en Kubernetes en Netease:
Planes iniciales:
1. Solo admite el envío de tareas SQL a través de JDBC y BeeLine 2. El clúster Kyuubi se implementa en nodos de máquinas físicas fuera del clúster K8s
3. El trabajo de Spark se ejecuta en modo Cliente.
4. Inicie el servicio aleatorio externo como DaemonSet en cada nodo
5. Los trabajos de Spark, ESS, etc. se ejecutan en modo Host Network 6. Instale SSD en cada nodo y móntelo en el Pod en modo hostPath
Plan mejorado:
1. Admite el envío de tareas SQL/Jar a través de JDBC, BeeLine y RESTful 2. Kyuubi se implementa en el clúster K8 en forma de StatefulSet
3. Kyuubi usa MySQL para almacenar datos de estado 4. Los trabajos de Spark se ejecutan en modo Clúster 5. Implemente Celeborn en forma de StatefulSet en el clúster K8 como servicio aleatorio remoto
6. En la nube pública, utilice Pods de instancias puntuales para proporcionar recursos informáticos para trabajos de Spark. En particular, las instancias puntuales tienen una ventaja de costo extremadamente baja, lo que desempeña un papel vital en la reducción de costos y el aumento de la eficiencia.
04 Mejoras de NetEase a Spark en Kubernetes en otros aspectos
Como se mencionó anteriormente, Spark en Kubernetes no proporciona de forma nativa servicios de agregación de registros como YARN, lo cual es muy hostil para el análisis de trabajos y la resolución de problemas de Spark.

Permitimos que Spark en Kubernetes obtenga una experiencia de salto de registro similar a Spark en YARN mediante los siguientes métodos:
1. Utilice Grafana Loki para crear un servicio de consulta y almacenamiento de registros y configure Grafana como un servicio de visualización de registros.
2. Utilice log4j-loki-appender para escribir registros de la aplicación Spark en el servicio de registro remoto
3. En SPARK-40887, mejoramos Spark para admitir la adición de enlaces de salto a servicios de registro externos en la interfaz de usuario de Spark de manera configurable; los enlaces pueden ser plantillas, por ejemplo, variables como POD_NAME se pueden usar como consultas en los enlaces de salto La estrategia de asignación de Pod condicional es otro tema interesante. Por ejemplo, en los dos escenarios siguientes, necesitamos utilizar diferentes estrategias de asignación.

En un escenario de implementación privada, para algunas tareas de red y de E/S intensas, si se programa una gran cantidad de ejecutores en el mismo nodo, es probable que se forme un punto de acceso y provoque un cuello de botella en el rendimiento del hardware. En este caso, podemos usar antiafinidad para que los ExecutorPods puedan distribuirse en todos los nodos tanto como sea posible durante la asignación.
En el escenario de implementación mixta fuera de línea, preferimos utilizar la estrategia de asignación de pods de embalaje bin para concentrar los pods ejecutores en una pequeña cantidad de nodos tanto como sea posible, de modo que cuando los nodos se transfieran, las máquinas puedan quedar libres rápidamente y el impacto en las tareas de Spark se puede reducir.

Los desarrolladores de Netease y la comunidad Kyuubi también han realizado muchas mejoras importantes en Spark en K8, que no se pueden describir en detalle debido a limitaciones de tiempo y espacio. Puede buscar en la comunidad la solicitud de extracción correspondiente de acuerdo con la orden de trabajo de JIRA. ¡Aquí también estamos muy agradecidos con los desarrolladores de la comunidad Spark por su ayuda en la revisión del código y otros aspectos!
Preguntas y respuestas en vivo
P : Hemos implementado Kyuubi en K8 para enviar tareas de Spark a K8. A continuación, planeamos usar Kyuubi para enviar tareas de Spark y Flink a YARN. En este escenario, ¿se recomienda implementar un conjunto separado de servicios Kyuubi para cada carga o utilizar el mismo conjunto de servicios Kyuubi?
R : Lo primero que debe quedar claro es que una sola instancia o clúster de Kyuubi admite la administración de múltiples versiones de Spark, el uso de múltiples motores informáticos y el envío de tareas a diferentes sistemas de administración de recursos. Como se mencionó anteriormente, Kyuubi Server es un servicio liviano y estable. En escenarios reales, también recomendamos usar un solo clúster de Kyuubi Server para administrar múltiples motores tanto como sea posible para implementar Unified Gateway. Recomendamos que los clústeres de Kyuubi se implementen de forma independiente solo en escenarios donde los usuarios tienen requisitos de SLA extremadamente altos o deben estar físicamente aislados por razones de seguridad y cumplimiento.
P : Como se mencionó en el intercambio, Celeborn admite actualizaciones continuas. De hecho, he medido que después de reiniciar el nodo trabajador de Celeborn, la tarea fallará. ¿Cuál podría ser el problema?
R : Celeborn está diseñado para admitir reinicios continuos. El nodo maestro es un clúster Raft que naturalmente admite actualizaciones continuas. En Celeborn 0.3.0, Celeborn agregó una función de apagado elegante para que los nodos trabajadores admitan actualizaciones continuas. Específicamente, al enviar una señal de cierre elegante al nodo trabajador: el cliente de escritura recibirá la información devuelta y percibirá que el trabajador se está cerrando, suspenderá la escritura de la partición actual y utilizará el mecanismo de reactivación para solicitar una nueva ranura para escritura. datos posteriores; después de que se desconecten todas las solicitudes de escritura, el propio trabajador descargará los datos y el estado en la memoria al disco y luego saldrá; el cliente que está leyendo cambiará automáticamente al nodo de réplica para leer los datos; el trabajador se reinicia Después de eso, el estado se recupera del disco y se pueden seguir proporcionando servicios de lectura de datos. En resumen, para admitir la actualización continua de Worker, debe cumplir con: versión 0.3.0 o superior; habilitar la copia de datos; habilitar el cierre ordenado.