EigenFaces, también conocido comúnmente como eigenfaces, utiliza el análisis de componentes principales (PCA) para procesar datos faciales de alta dimensión en datos de baja dimensión (reducción de dimensión) y luego realiza análisis y procesamiento de datos para obtener resultados de reconocimiento.
Fundamental
En el mundo real, la representación de mucha información es redundante. Por ejemplo, hay información redundante en los parámetros del conjunto de círculos enumerados en la Tabla 23-2.
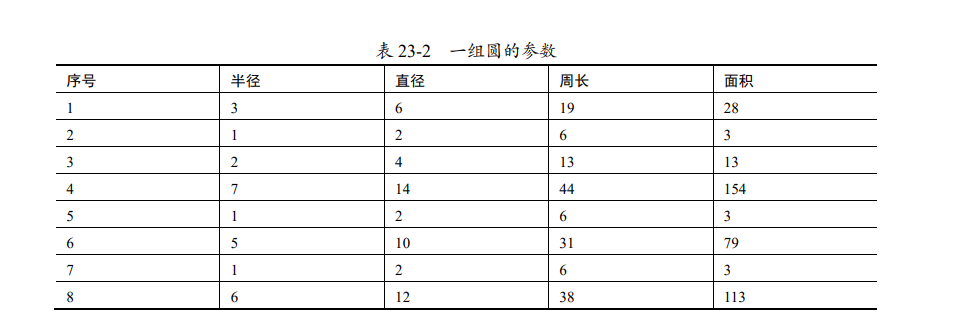
Entre los parámetros que se muestran en la Tabla 23-2, existe una correlación muy fuerte entre cada parámetro:
- diámetro = 2*radio
- Circunferencia = 2 π radio
- área = pi radio radio
Se puede ver que el diámetro, la circunferencia y el área se pueden calcular a partir del radio.
Al realizar el análisis de datos, si queremos ver los valores de estos parámetros de manera más intuitiva, necesitamos obtener los valores de todos los campos.
Sin embargo, al comparar el tamaño de los círculos, basta con utilizar sólo el radio, momento en el que otra información nos resulta "redundante".
Por lo tanto, podemos entender que el "radio" es el "componente principal" en los datos enumerados en la Tabla 23-2. Extraemos el "radio" de los datos anteriores para análisis posteriores y realizamos una "reducción de dimensiones".
Por supuesto, los datos del ejemplo anterior son muy simples y fáciles de entender, pero en la mayoría de los casos, los datos con los que tenemos que tratar son más complejos. En muchos casos, es posible que no podamos juzgar directamente qué datos son los "componentes principales" clave, por lo que debemos utilizar el método PCA para analizar los "componentes principales" en datos complejos.
EigenFaces consiste en utilizar el método PCA para reducir la dimensionalidad de los datos originales y obtener la información del componente principal en ellos, a fin de implementar el método de reconocimiento facial.
Introducción a la función
OpenCV 函数 cv2.face.EigenFaceRecognizer_create()genera un modelo de instancia de reconocedor de rostros propios, luego lo aplica cv2.face_FaceRecognizer.train()函数完成训练y finalmente usa la función cv2.face_FaceRecognizer.predict() para completar el reconocimiento de rostros.
- Función cv2.face.EigenFaceRecognizer_create()
La sintaxis de la función cv2.face.EigenFaceRecognizer_create() es:
retval = cv2.face.EigenFaceRecognizer_create( [, num_components[,
umbral]] )
Los dos parámetros de la fórmula son parámetros opcionales con los siguientes significados:
- num_components: la cantidad de componentes que se mantendrán en PCA. Por supuesto, el valor de este parámetro generalmente se
determina de acuerdo con los datos de entrada y no existe una regla determinada. Generalmente, 80 componentes son suficientes. - umbral: el umbral utilizado para el reconocimiento facial.
- La función cv2.face_FaceRecognizer.train()
función cv2.face_FaceRecognizer.train() realiza el cálculo de EigenFaces en cada imagen de referencia para obtener un vector.
Cada cara es un punto en todo el conjunto de vectores. El formato de sintaxis de esta función es:
Ninguno = cv2.face_FaceRecognizer.train( src, etiquetas )
El significado de cada parámetro en la fórmula es:
- src: imagen de entrenamiento, la imagen de la cara utilizada para el aprendizaje.
- etiquetas: Las etiquetas correspondientes a las imágenes de la cara.
Esta función no tiene valor de retorno.
- Función cv2.face_FaceRecognizer.predict()
La función cv2.face_FaceRecognizer.predict() encontrará la imagen de la cara más cercana a la imagen actual al juzgar una imagen de la cara que se va a probar. Qué imagen de cara es la más cercana, la imagen a probar se reconoce como su etiqueta correspondiente. La sintaxis de esta función es:
etiqueta, confianza = cv2.face_FaceRecognizer.predict( src )
Los significados de cada parámetro y valor de retorno en la fórmula son:
- src: La imagen de la cara a reconocer.
- etiqueta: la etiqueta del resultado del reconocimiento devuelto.
- confianza: la puntuación de confianza devuelta. La puntuación de confianza se utiliza para medir la distancia entre el resultado del reconocimiento y el modelo original.
0 significa una coincidencia exacta. El valor de este parámetro suele estar entre 0 y 20 000, siempre que sea inferior a 5000 se considera un resultado de reconocimiento bastante fiable . Tenga en cuenta que este rango es diferente del rango de valores de puntuación de confianza para LBPH.
Ejemplo: utilice el módulo EigenFaces para completar un programa simple de reconocimiento facial.
import cv2
import numpy as np
images=[]
images.append(cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
resultado de la operación:
Se informó un error

que indica que todas las imágenes deben tener el mismo tamaño para el entrenamiento.
nuevo código:
import cv2
import numpy as np
images=[]
img1= cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE);
img1.resize((240,240))
images.append(img1)
img2= cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE);
img2.resize((240,240))
images.append(img2)
img3= cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE);
img3.resize((240,240))
images.append(img3)
img4= cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE);
img4.resize((240,240))
images.append(img4)
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels)) # 识别器训练
predict_image=cv2.imread("face\\face6.png",cv2.IMREAD_GRAYSCALE)
predict_image.resize((240,240))
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
resultado de la operación:
label= 1
confidence= 11499.110301703204
Según los resultados, es un poco más preciso que la comparación de reconocimiento facial LBPH.