Tabla de contenido
Importación de conjuntos de datos
Contenido del conjunto de datos
El conjunto de datos MINST es un conjunto de datos clásico en el campo del aprendizaje automático, que incluye 70 000 muestras, incluidas 60 000 muestras de capacitación y 10 000 muestras de prueba.
Importación de conjuntos de datos
Usando tensorflowel marco, kerasobtenga el conjunto de datos MNIST por:
mnist = tf.keras.datasets.mnist
A través load_data()del método para cargar los datos en el conjunto de datos
Los datos adquiridos tuplese almacenan en el formato de:
(训练样本数据集,训练标签数据集),(测试样本数据集,测试标签数据集)
Así que usa la tupla correspondiente para recibir los datos:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
Formato del conjunto de datos
El formato de los cuatro conjuntos de datos anteriores es: numpy.ndarray, ndarray es un objeto de tipo de matriz N-dimensional, y puede imprimir los atributos relevantes del conjunto de datos para verlos:
print("训练样本的维度为:",x_train.ndim)
print("训练样本的形状为:",x_train.shape)
print("训练样本的元素数量为:",x_train.size)
print("训练样本的数据类型为:",x_train.dtype)
El resultado es el siguiente:

Se puede ver por su forma que el conjunto de datos de muestra de entrenamiento almacena 60.000 imágenes digitales de 28*28 píxeles;
Contenido del conjunto de datos
Las imágenes almacenadas en él se pueden imprimir y visualizar a través del siguiente código:
for i in range(0,28):
for j in range(0,28):
print("%.1f" % x_train[0][i][j] , end=" ")
print()
El resultado es el siguiente:
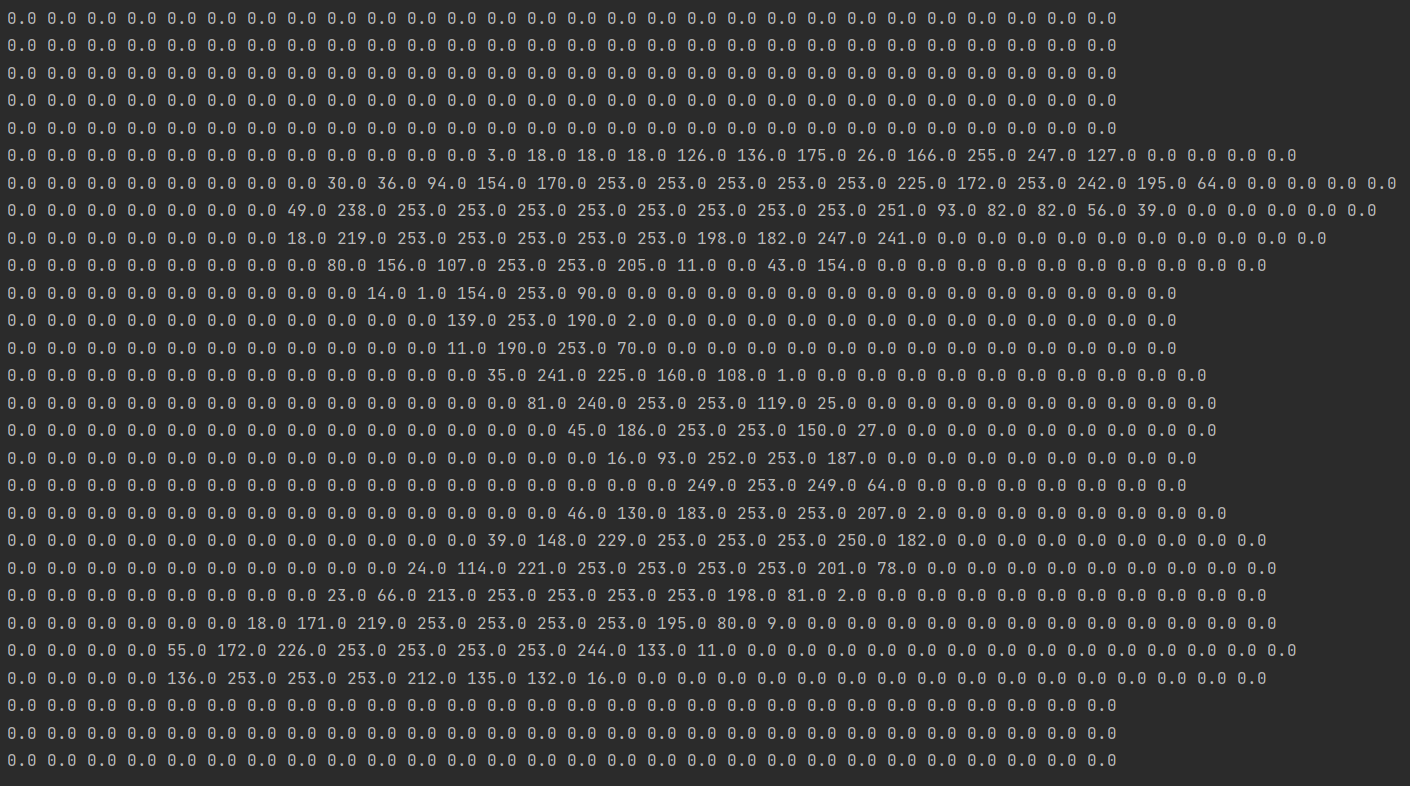
es obvio que es un numero5
Dado que el valor de cada píxel en el conjunto de datos está dentro 0-255del rango, normalizamos los datos y los convertimos en un 0-1número de punto flotante entre:
x_train, x_test = x_train / 255.0, x_test / 255.0
Como puede ver, el tipo de datos ha cambiado después del procesamiento:

Imprima la imagen almacenada nuevamente, y se puede ver vagamente que es un número 5:
