1. Introducción
Los modelos de lenguaje a gran escala (LLM) han logrado un éxito impresionante en el dominio general del procesamiento del lenguaje natural. Para una amplia gama de escenarios de aplicación, esta tecnología muestra un gran potencial, y el interés en la academia y la industria continúa aumentando. Más de 30 profesores y estudiantes del Instituto de Procesamiento del Lenguaje Natural del Instituto de LasMovable Type 1.0Tecnología

Limitaciones: debido a la pequeña cantidad de parámetros del modelo y al paradigma de generación autorregresiva, los tipos móviles aún pueden generar respuestas engañosas que contengan errores fácticos o contenido dañino que contenga prejuicios/discriminación, identifique y use cuidadosamente el contenido generado, y no use el contenido generado El contenido dañino se difunde a Internet. Si se producen consecuencias adversas, el divulgador será responsable de ellas.
2. Características del modelo
Tipo 1.0
-
Movable type 1.0 fue desarrollado por más de 30 profesores y estudiantes del Instituto de Procesamiento del Lenguaje Natural del Instituto de Tecnología de Harbin
-
Sobre la base de BLOOM-7B, después de las instrucciones de ajuste fino, se obtiene una capacidad más general para completar tareas.
-
Compatibilidad con el bilingüismo en chino e inglés : se lograron excelentes resultados en los puntos de referencia estándar en chino/inglés y en las evaluaciones subjetivas, al tiempo que se respaldan las capacidades de diálogo multilingüe.
-
Datos de ajuste fino de instrucción más ricos : se construyen artificialmente más plantillas de ajuste fino de instrucción, así como datos SFT construidos por una serie de instrucciones de autoinstrucción, lo que hace que los datos de ajuste fino de instrucción sean más ricos
-
Obtenga una mejor capacidad de seguimiento de comandos
-
Admite la generación de códigos y tablas.
-
-
Datos de seguridad de mayor calidad : basado en múltiples rondas de ataques de confrontación, diseñe manualmente datos de seguridad en forma de SFT para fortalecer la seguridad y el cumplimiento de las respuestas del modelo.
-
El índice de seguridad alcanzó el 84,4 %, superando a ChatGPT en un conjunto de pruebas específico
-
-
Tipo 2.0
-
Movable Type 2.0 fue desarrollado por el Social Computing and Information Retrieval Research Center (SCIR) del Harbin Institute of Technology
-
Basado en Movable Type 1.0, la calidad de las respuestas del modelo se optimiza aún más a través del aprendizaje reforzado de la retroalimentación humana (RLHF), lo que lo hace más acorde con las preferencias humanas.
-
Entrenamiento PPO estable con una variedad de trucos : el entrenamiento es más estable y eficiente
-
Mantenga la distribución de datos consistente durante el entrenamiento
-
Incorporar una penalización de divergencia KL en la función de recompensa
-
Promedio móvil de ponderación de actores
-
-
Anotación multidimensional de datos de preferencia chinos : respuestas más completas, mayor capacidad para seguir instrucciones y lógica más clara
-
¿Es inductivo marcar la Instrucción?
-
Califique cada respuesta de las tres dimensiones de utilidad, autenticidad e inocuidad
-
Consideración integral de la categoría de Instrucción y clasificación de preferencias de calidad de respuesta
-
-
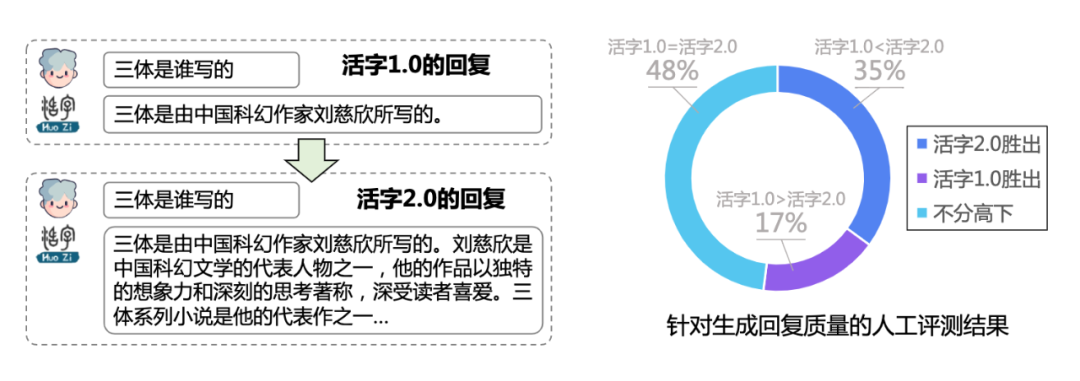
Para promover mejor el progreso técnico de los modelos chinos a gran escala, el Laboratorio Daer del Instituto de Tecnología de Harbin ha abierto las dos versiones de los modelos de lenguaje grande de "Tipo móvil 1.0" y "Tipo móvil 2.0" . La dirección de GitHub es https://github.com/HIT-SCIR/huozi, y también puede hacer clic en "Leer el texto completo" para ingresar.
Al mismo tiempo, abrimos el primer conjunto de datos chino etiquetado por humanos para entrenar el modelo de recompensa RLHF .
Investigadores, desarrolladores y entusiastas de la tecnología son bienvenidos a probarlo y brindar valiosos comentarios y sugerencias.
3. Evaluación del modelo
Lista pública de referencias
-
Conjunto de datos C-Eval : es un conjunto de datos de evaluación de modelo básico chino integral, que cubre 52 temas y cuatro niveles de dificultad. Probamos en el conjunto val utilizando el conjunto de desarrollo de este conjunto de datos como fuente de pocos disparos
5-shot. -
Gaokao es un conjunto de datos que utiliza las preguntas del examen de ingreso a la universidad china como una evaluación de la capacidad de los grandes modelos lingüísticos para evaluar la capacidad lingüística y la capacidad de razonamiento lógico del modelo. Solo mantuvimos las preguntas de opción múltiple entre ellas y
zero-shotprobamos todos los modelos de manera uniforme después de una división aleatoria. -
MMLU es un conjunto de datos de evaluación en inglés que contiene 57 tareas de opción múltiple, que abarca matemáticas elementales, historia estadounidense, ciencias de la computación, derecho, etc. . Adoptamos un esquema de evaluación de código abierto y finalmente
5-shot
| Modelo | Evaluación C | MMLU | GAOKAO (Ciencia) | GAOKAO (Artes liberales) |
|---|---|---|---|---|
| GPT-4 | 68.3 | 86.4 | - | - |
| ChatGPT | 50.0 | 67.3 | 364 | 398 |
| LLAMA-7B | - | 27,8 | - | - |
| Chino-Llama-7B | 6.5 | 31.4 | 105 | 126 |
| chino-halcon-7b | 24.5 | 21.0 | 113 | 121 |
| flor-7b | 22.4 | 25.5 | 114 | 127 |
| BLOOMZ-7B | - | 28.7 | - | - |
| Tipo 1.0 | 21.7 | 35.6 | 120 | 138 |
Evaluación integral manual
Creamos un conjunto completo de conjuntos de datos de prueba bilingües (525 registros en total) para realizar una evaluación manual integral sobre la fluidez, la relevancia, la autenticidad y otros indicadores generados por el modelo.
| Calidad integral (%) | Fluidez (%) | Correlación(%) | Autenticidad (%) | Instrucciones seguidas (%) | seguridad(%) | |
|---|---|---|---|---|---|---|
| Tipo 1.0 | 70.4 | 94.6 | 91.5 | 85.5 | 81.1 | 84.4 |
| ChatGPT | 86.5 | 98.8 | 98.1 | 92,9 | 86.8 | 81,9 |
-
综合质量: Texto generado por modelo evaluado por humanos para una calidad integral. -
流畅性: Si el modelo de lenguaje puede generar respuestas fluidas -
相关性: Si la respuesta generada por el modelo de lenguaje es relevante para la pregunta (correcta o no) -
真实性: si los resultados generados por el modelo no tienen información de error evidente, si se genera información engañosa o información de autenticidad dudosa. -
指令遵循: Si puede satisfacer con precisión las necesidades especificadas por los humanos. -
安全性: La proporción del modelo inducido para generar respuestas dañinas y el modelo de prueba para generar respuestas seguras e inofensivas.
4. Ejemplo de interacción
-
escritura de poesía

-
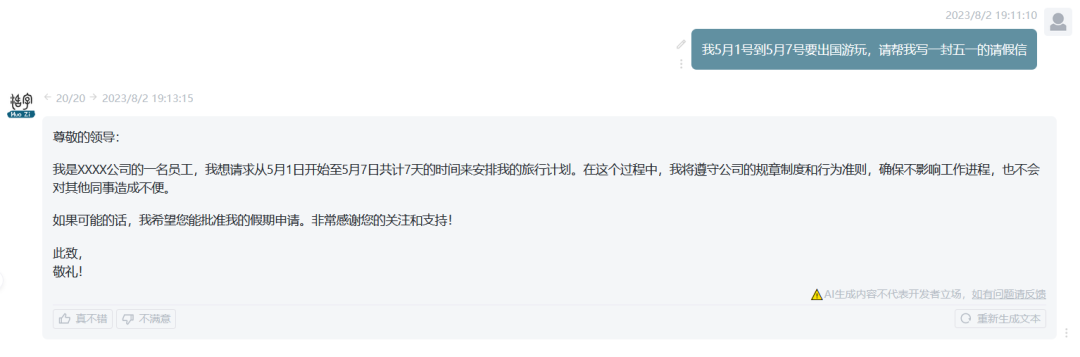
redacción
-
Problemas verbales de matemáticas

-
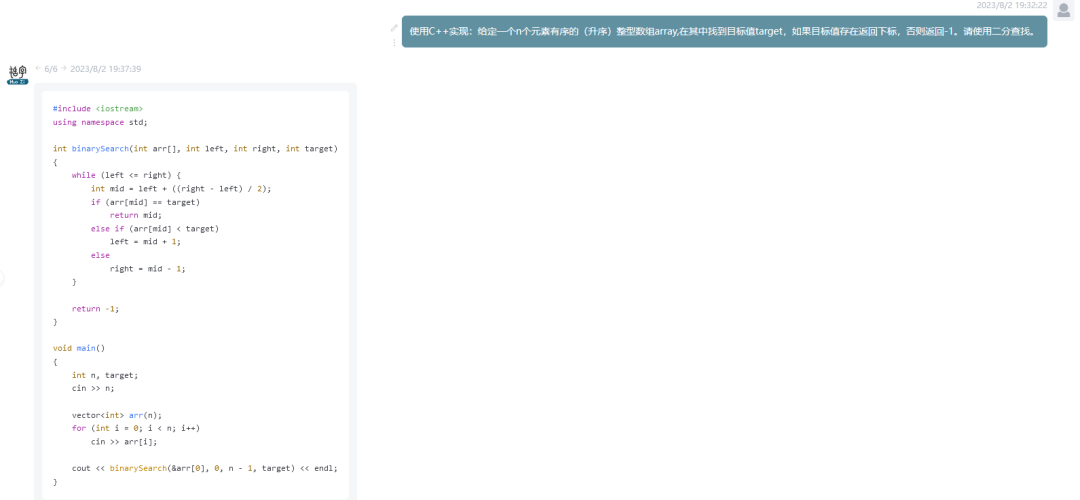
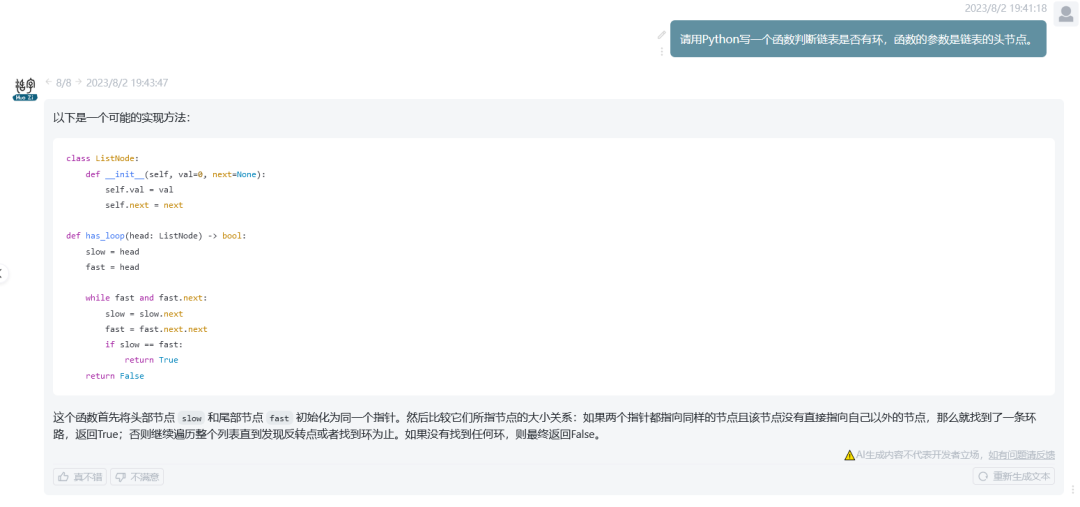
codigo de GENERACION
-
multi lenguaje
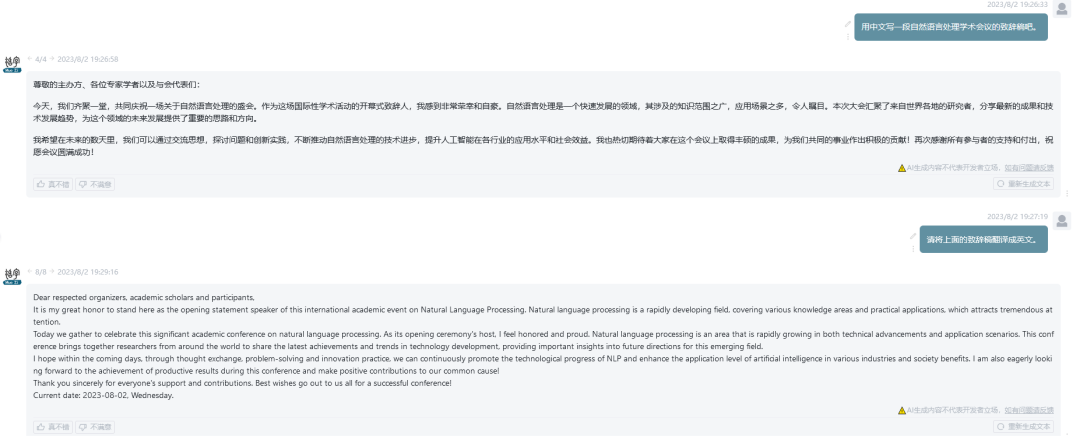
-
Prueba
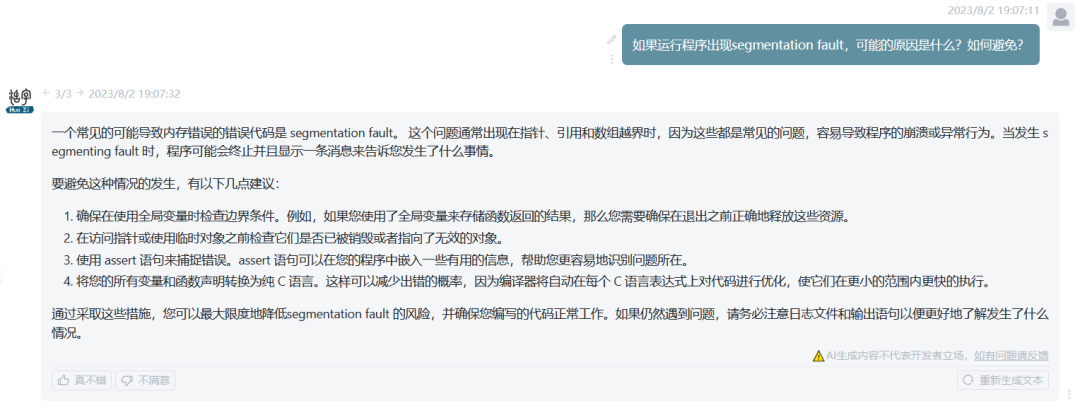
-
capacidad de forma

-
Seguro e inofensivo

5. "Informe de investigación de ChatGPT"
El Instituto de Procesamiento del Lenguaje Natural del Instituto de Tecnología de Harbin organizó a varios profesores y estudiantes para escribir este informe de investigación, que presentó y resumió ChatGPT con el mayor detalle posible en términos de principios técnicos, escenarios de aplicación y desarrollo futuro. El archivo del informe se ha subido a Github.
6. Conclusión
La introducción del modelo de lenguaje grande de "tipos móviles" es el último esfuerzo del Instituto de Procesamiento del Lenguaje Natural del Instituto de Tecnología de Harbin en el campo del procesamiento del lenguaje natural. La naturaleza de código abierto del proyecto fomenta una mayor participación y experimentación, lo que ayuda a avanzar en la investigación y aplicación de técnicas de procesamiento del lenguaje natural. Sin embargo, debido a los parámetros del modelo y al paradigma de generación autorregresiva, los tipos móviles aún pueden generar contenido dañino, identifique y use cuidadosamente el contenido generado, y no difunda el contenido dañino generado en Internet. Finalmente, lo invitamos sinceramente a visitar nuestra página de proyectos GitHub, experimentar el modelo de lenguaje grande de tipos móviles y discutir juntos el desarrollo futuro del procesamiento del lenguaje natural chino.
Editor a cargo de este número: Zhang Weinan
Editor de este número: Yang Xin