Сяо Янхуа 丨Ключевые технологии больших моделей для предметных приложений
Опубликовано в Пекине автором Xiao Yanghua DataFunTalk 2023-08-09 12:59
Эта статья составлена на основе темы «Ключевые технологии больших моделей, ориентированных на доменные приложения» Сяо Янхуа, директора Шанхайской ключевой лаборатории науки о данных и профессора Университета Фудань на Всемирной конференции по искусственному интеллекту «Поколение ИИ и бесконечное очарование». Вертикальные широкоязычные модели» от 7 июля .
Руководство: Когда крупномасштабные генеративные модели, такие как ChatGPT, демонстрируют сильные общие интеллектуальные возможности, внимание отрасли больше обращается на тысячи отраслей. Значение большой модели может быть выделено только в том случае, если она позволяет достичь результатов в реализации сущности типа тысяч отраслей. Большие модели, такие как ChatGPT, обучаются с помощью корпуса общего назначения и обладают общими знаниями. Тогда, естественно, возникнут интересные вопросы: зачем вертикальным полям тысяч отраслей нужна общая большая модель? Способна ли существующая крупная модель общего назначения решать сложные задачи в вертикальных полях? Как оптимизировать общую большую модель, чтобы быть компетентным в решении сложных задач в полевых условиях. В настоящем отчете представлены предварительные ответы на эти вопросы.
1. Почему проблему вертикальной области необходимо решать с помощью общей большой модели?
Во-первых, возможности понимания открытого мира , обеспечиваемые универсальными генеративными большими моделями, имеют решающее значение. Эта способность позволяет большим моделям иметь определенную степень понимания вопросов естественного языка в различных открытых средах и в большинстве случаев может давать точные ответы. Хотя текущие генеративные большие модели могут иметь некоторые фактические или логические ошибки при генерации ответов. Но в целом генерируемый им контент не будет отклоняться от темы вопроса, и он сможет точно ответить на общие вопросы. Эта способность понимать проблемы открытого мира имеет решающее значение для реализации познания в вертикальной области. Идея реализации ИИ до ChatGPT склонна думать, что только позволив ему изучить возможности большинства вертикальных доменов, он сможет реализовать общую способность понимания открытого мира. Другими словами, если познание вертикальной области не может быть реализовано, достичь общего познания будет еще труднее. Однако после появления ChatGPT было доказано, что это более осуществимый путь посадки для уточнения крупномасштабной модели общего назначения для формирования общих способностей к знаниям машины , а затем для обучения когнитивных способностей вертикальной области посредством непрерывного обучение данных вертикального домена. На самом деле неизбежно и разумно основывать вертикальную когнитивную способность машины на основе общей когнитивной способности. Как может врач по-настоящему понять «болезнь», если он не понимает «здоровья». То есть, чтобы понять понятие, необходимо не только понять коннотацию и расширение самого понятия, но также понять коннотацию и расширение за пределами понятия. Следовательно, поле понимания включает в себя и вне поля понимания.Традиционное так называемое «вертикальное познание» по своей сути является ложным положением. Этот разумный путь реализации «сначала общие знания, а затем специальные знания» очень похож на процесс человеческого образования. Образование нашего человека — это, прежде всего, базовое образование, ориентированное на общее образование, а затем высшее образование, ориентированное на профессиональные знания. Разработка генеративных больших моделей освежила наше понимание пути реализации когнитивного интеллекта в предметной области, что является одним из важных вдохновений, принесенных развитием технологии больших моделей.
Помимо способности понимать открытый мир, большие модели также обладают многими другими возможностями и характеристиками , на которые особенно стоит обратить внимание в предметных приложениях:
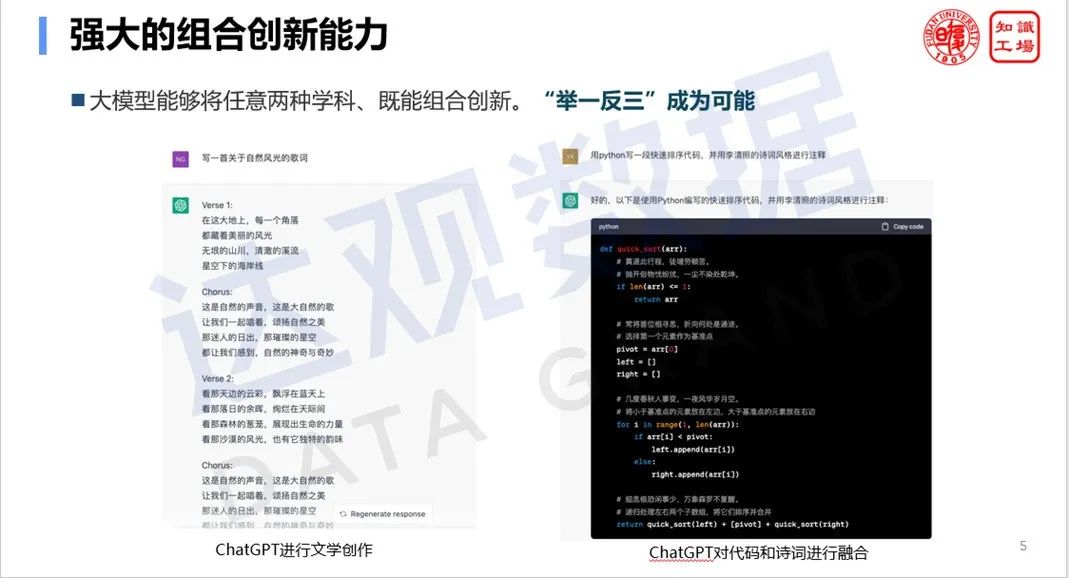
1. Комбинированные инновационные способности
Направляя большую модель на изучение нескольких различных задач на этапе обучения , комбинация больших моделей может создать возможность решать более сложные задачи . Например, мы можем позволить большой модели написать комментарий к коду Python в соответствии со стилем поэзии Ли Цинчжао, который требует, чтобы она обладала как способностью писать стихи, так и способностью писать код. Объединяя и обобщая результаты обучения инструкциям, большая модель имитирует способность людей делать выводы из одного примера, так что машина может быть компетентна для некоторых новых задач, которые никогда не изучались.
2. Оценка и способность к оценке
Общие макеты превосходны. Большая модель с определенным масштабом (особенно большая модель ) имеет отличную производительность при оценке результатов общих текстовых задач . Для традиционных текстовых задач оценка результатов часто требует ручного участия, что требует дорогостоящих трудозатрат. Теперь мы можем использовать большие модели для многих задач оценки. Например, мы можем позволить большой модели играть роль эксперта по переводу для оценки качества перевода. Разрабатывая разумные критерии оценки, предоставляя эффективные примеры оценки и предоставляя цепочки мышления процесса экспертной оценки перевода, гигантские модели (такие как GPT4) могут превосходно выполнять очень профессиональные задачи оценки, такие как перевод идиом. Возможность оценки больших моделей может значительно снизить стоимость ручной оценки в задачах предметной области, тем самым значительно уменьшив стоимость реализации интеллектуальных решений предметной области.

3. Понимание сложных инструкций и их способность выполнять
Понимание сложных инструкций и возможность их выполнения — одна из основных особенностей больших моделей. Пока для большой модели даны подробные инструкции, а ограничения или спецификации задачи четко выражены, сверхбольшая модель может выполнить задачу в соответствии с инструкциями. Эта способность быть верным инструкциям тесно связана с возможностями контекстной генерации больших моделей. При наличии разумных подсказок, а также более подробных и подробных подсказок, более крупные модели, как правило, в большей степени способны генерировать высококачественный контент. Возможность контекстной генерации больших моделей освежила наше понимание сути интеллекта.Традиционно интеллектом считались способности человека открывать и применять знания. Этот тип определения начинается с точки зрения человека, а знание является продуктом человеческого познания мира. С точки зрения большой модели, если подсказки в данной ситуации генерируются разумно, это своего рода интеллект. Такого рода способность к ситуативному генерированию, по сути, отражает своего рода способность моделировать мир и не имеет ничего общего с тем, как люди воспринимают мир.

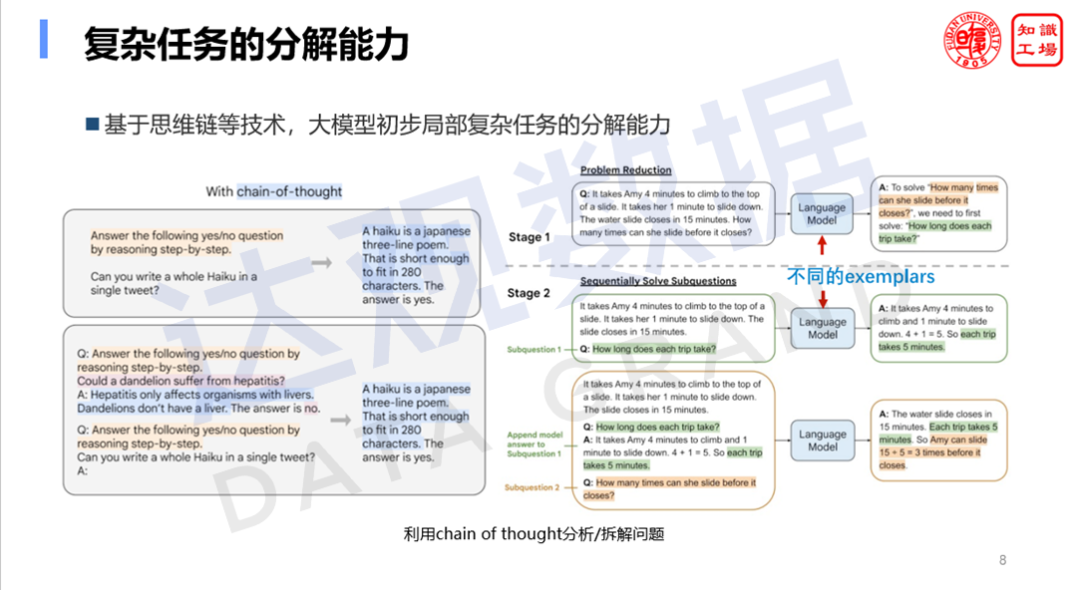
4. Умение декомпозировать и планировать сложные задачи
Возможность декомпозировать и планировать сложные задачи — еще одно преимущество больших моделей. Он может разбивать сложные задачи на несколько шагов и разумно планировать последовательность выполнения задач. Это предоставляет важную возможность для вертикальных доменных приложений, позволяя крупным моделям работать с традиционными информационными системами, эффективно объединяя базы данных, базы знаний, системы автоматизации делопроизводства, библиотеки кодов и другие системы в традиционных ИТ-системах, а также выполняя задачи, которые были трудны для традиционных интеллектуальных систем. системы в прошлом Компетентен для решения сложных задач по принятию решений, тем самым повышая уровень интеллекта всей информационной системы.
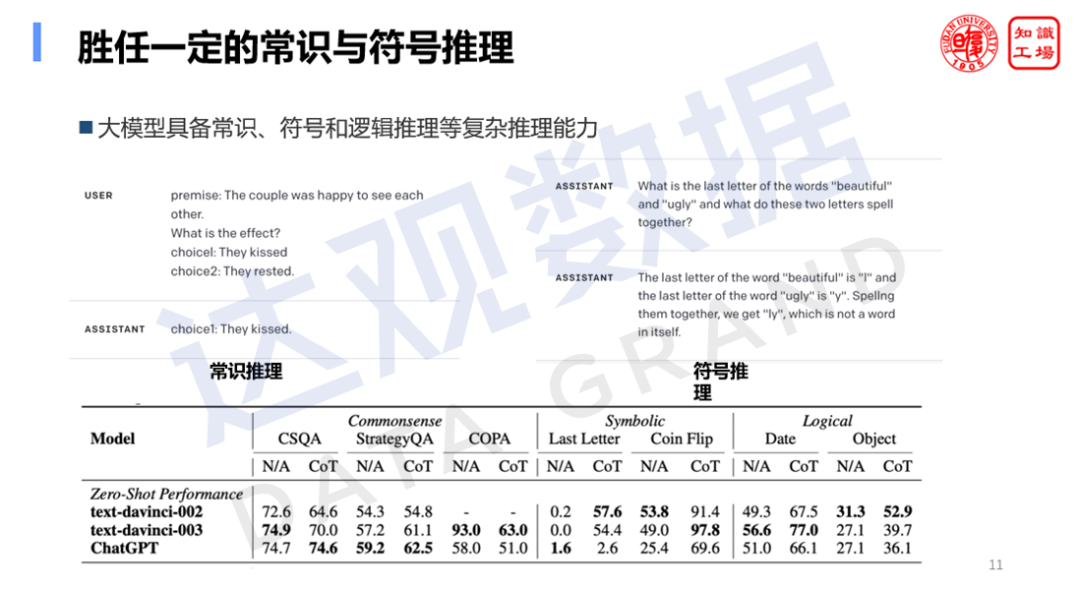
5. Способность к символическому мышлению
Кроме того, большая модель также имеет возможность символического рассуждения, которое может выполнять рассуждение на основе здравого смысла, а также определенную степень логического рассуждения и численного рассуждения. Хотя эти способности к рассуждению все еще нуждаются в дальнейшем совершенствовании перед лицом сложных текстовых задач предметной области. Кроме того, возможность согласования значений также является важной особенностью реализации больших моделей, чтобы гарантировать, что вывод больших моделей соответствует нашей человеческой этике, идеологии и ценностям.
В целом, операции с крупными моделями общего назначения способны понимать открытый мир, объединять инновации, оценивать, точно понимать и выполнять инструкции, декомпозировать и планировать сложные задачи, символически рассуждать и согласовывать со значениями. Эти преимущества делают большие модели новой основой для искусственного интеллекта. Другими словами, любое приложение, обращающееся к большой модели, может пользоваться ее интеллектуальными возможностями. Большая модель также все чаще становится основным компонентом экологии интеллектуальных приложений, контролируя и координируя различные традиционные информационные системы и способствуя общему повышению уровня интеллекта информационной системы.
2. Может ли большая модель быть непосредственно пригодной для задач вертикальной области ?
Необходимо тщательно оценить, способна ли крупная модель общего назначения выполнять задачи вертикальной области. Текущее мнение состоит в том, что большие модели не способны напрямую решать сложные задачи принятия решений в различных областях. Поэтому на рынке корпоративных услуг мы должны не только обращать внимание на основные возможности, предоставляемые нам большой моделью, но и сохранять спокойствие и осторожность в отношении того, что ChatGPT может и чего не может делать. Имейте в виду, что нам еще предстоит проделать большую исследовательскую работу, чтобы внедрить приложение ChatGPT.
Большие модели, такие как ChatGPT, добились замечательных результатов в диалогах между человеком и машиной или в чате в открытой среде, но есть пробел в решении сложных задач по принятию решений в реальной работе. Большинство наших задач в вертикальных областях — это сложные задачи по принятию решений. Например, такие задачи, как поиск и устранение неисправностей оборудования, диагностика заболеваний, принятие инвестиционных решений и т. д., — все это серьезные и сложные сценарии принятия решений. Так называемый «серьезный» означает, что эти задачи имеют низкую устойчивость к ошибкам. Любая ошибка в вышеперечисленных сценариях принесет огромные убытки и неприемлемые затраты. Эти задачи также «сложны» и требуют обширных профессиональных знаний, сложной логики принятия решений и способности оценивать макроситуации (например, макроситуацию на фондовом рынке). Он также должен иметь возможность разбирать и планировать комплексные задачи, такие как разбивка устранения неполадок на несколько этапов; ему нужна способность находить компромиссы в сложных условиях, например, инвестиционные решения часто требуют компромиссов и компромиссов. между многими ограничениями. Также необходимо иметь способность предвидеть то, что не было замечено, и способность рассуждать и делать выводы в неопределенных сценариях, потому что быстрое развитие нашей реальной среды часто превосходит наши ожидания, и нам часто приходится принимать своевременные решения, когда информация неполная, принятие решения.

комплексное решение задач
Например, пусть машина « исследует работу о непрерывном обучении больших моделей, недавно опубликованную лабораторией фабрики знаний», что кажется простой задачей, но на самом деле требует использования упомянутых выше различных сложных решений. возможности. Например, чтобы понять, что представляет собой команда Лаборатории Фабрики Знаний и кто в нее входит, необходимо понимать коннотацию непрерывного изучения больших моделей и обладать профессиональными знаниями в области ИИ. В то же время вам также необходимо знать, как найти бумажные ресурсы (например, все мы знаем, что передовые статьи в компьютерной области часто можно загрузить с веб-сайта Arxiv), и вы можете столкнуться с некоторыми неожиданными проблемами при загрузке. документы (такие как 404 в доступе к сети, проверочный код и т. д.). Студенты бакалавриата и магистратуры в моей собственной лаборатории, очевидно, могут выполнить вышеуказанные задачи. Тем не менее, текущая большая модель все еще сложна для завершения работы во всем процессе, и необходимо улучшить возможности самой большой модели, а также необходимо устранить присущие большой модели недостатки с периферии.
В целом, большие модели все еще относительно бедны с точки зрения знания предметной области . Большая модель общего назначения имеет обширную базу знаний, с более чем достаточной шириной, но недостаточной глубиной. Однако при решении практических задач, таких как проблемы эксплуатации и обслуживания, если нет знаний об оборудовании, невозможно быть компетентным в задачах эксплуатации и обслуживания. Следовательно, большие модели должны обладать глубиной профессиональных знаний и способностью к долгосрочным рассуждениям, прежде чем их можно будет применять в вертикальных областях.
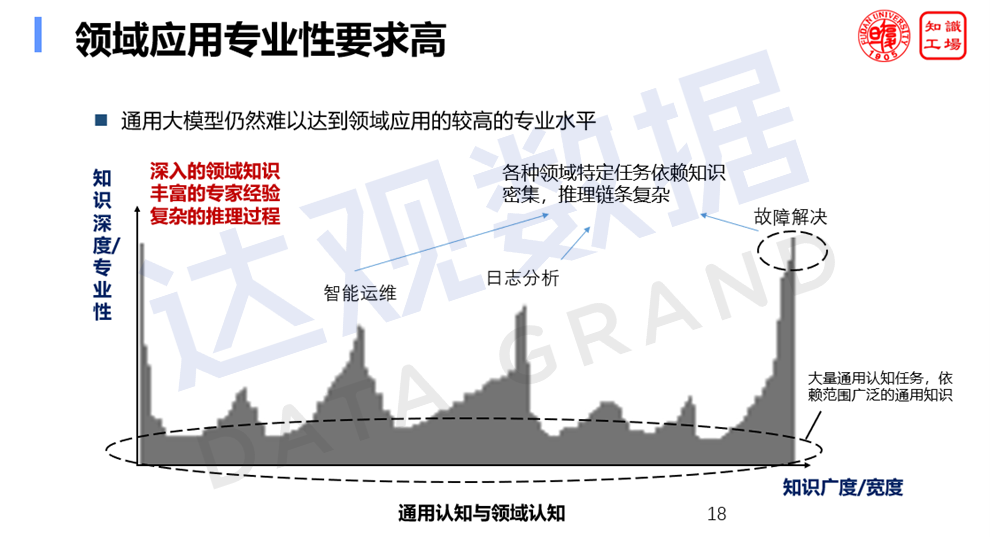
широкая база знаний
Другая неизбежная проблема — это проблема «иллюзии» больших моделей, т. е. проблема серьезной чепухи. Когда мы спрашиваем о девизе Фуданьского университета, большая модель вполне может придумать, казалось бы, строгий ответ. Но после тщательного изучения вы обнаружите, что в некоторых основных фактах (например, он сфабриковал источник девиза школы Фудань) ответ большой модели подвержен ошибкам. Тот факт, что большая модель фабрикует ответы в «серьезном» текстовом стиле, создаст большие трудности при ее применении. Поскольку кажущиеся строгими ответы часто скрывают некоторые основные фактические ошибки, нам все равно приходится платить большую цену, чтобы судить о достоверности информации при ее применении. Это на самом деле приводит к дополнительным затратам для приложений с большими моделями. Можно ли решить проблему галлюцинаций большой модели после ее собственной оптимизации? Например, используйте больше обучающих данных и тренируйтесь с большей вычислительной мощностью. Теоретически большие модели, такие как ChatGPT, являются вероятностными генеративными большими моделями, и они все же допускают ошибки с определенной вероятностью. В каком-то смысле иллюзия — это цена, которую приходится платить за творчество больших моделей, а иметь и то, и другое сложно. Таким образом, проблема галлюцинаций является неизбежной проблемой при вертикальном применении больших моделей.

Проблема «иллюзии» больших моделей
Кроме того, в больших моделях отсутствует «верность» данной информации. В задачах предметной области нам нужны большие модели, чтобы отвечать в соответствии с нормами предметной области, системами, процессами и знаниями. Однако, если они не настроены должным образом, большие модели, как правило, выбрасывают предоставленные документы или информацию и имеют тенденцию свободно играть с полученными общими знаниями. Элегантная творческая игра и верная констатация фактов — пара противоречий, которые трудно примирить. На данный вопрос, следует ли отвечать общими знаниями или специальными знаниями. Наше человеческое знание адаптируется к проблемам часто интуитивно, но машинам очень сложно гибко взаимодействовать между общими и специальными знаниями. Хотя гигантские модели (такие как GPT4) могут в определенной степени смягчить проблему недостаточной точности больших моделей, даже после тонкой настройки и оптимизации ответы больших моделей могут по-прежнему выходить за заданный диапазон, что приводит к ошибкам. Это серьезная проблема, с которой сталкиваются современные большие модели общего назначения.

«достоверность» информации
Поэтому мое основное суждение состоит в том, что полагаться исключительно на существующие универсальные большие модели недостаточно для решения многих задач . Нам необходимо разрабатывать большие вертикальные модели предметной области, активно разрабатывать периферийные плагины и реализовывать стратегию объединения больших моделей с графами знаний и традиционными базами знаний, чтобы облегчить проблемы больших моделей и улучшить эффект приземления больших моделей.
3. Как общую большую модель можно квалифицировать для задач вертикальной предметной области?
Применение больших моделей общего назначения к конкретным областям по-прежнему требует большой оптимизации, чтобы перейти от «ничего не делать, кроме дела», от контейнера знаний к мощному инструменту для решения проблем и высвободить огромный потенциал больших модели. Я считаю, что модель «Цао Чжи» Daguan Data также выполняет аналогичную оптимизацию. Я возьму в качестве примера предметно-ориентированный процесс оптимизации собственной большой модели KW-CuteGPT моей лаборатории, чтобы показать, как большие модели могут быть компетентны для задач вертикальной предметной области. Существует два основных пути оптимизации: один — это оптимизация самой большой модели, а другой — взаимодействие между большой моделью и периферийными технологиями.
Сначала обсудите, как оптимизировать возможности самой большой модели. Во-первых, улучшить способность больших моделей понимать длинные тексты. Например, использование большой модели для суммирования записей о звонках в службу поддержки является очень распространенным сценарием приложения Многие клиенты часто тратят пять или шесть минут на выражение своих намерений с помощью длинных записей разговоров. И он может содержать только один или два важных информационных пункта. Обобщение диалогов с большими моделями должно поддерживать способность понимать длинные тексты. Некоторые крупные модели, имеющиеся в настоящее время в продаже, такие как GPT-4, уже могут поддерживать длину входных данных до 32 КБ, что эквивалентно десяткам тысяч слов, что является очень замечательной возможностью. Однако большинство моделей с открытым исходным кодом поддерживают только входные данные длиной 2–4 КБ, что по-прежнему недостаточно для понимания длинных текстов. Поэтому в процессе разработки больших вертикальных моделей предметной области первостепенной задачей является улучшение понимания и возможностей обработки ввода длинного текста. Длинные тексты сложны, потому что существуют глобальные семантические ограничения, многие из которых включают несколько предложений или даже несколько абзацев, и для больших моделей по-прежнему сложно понять этот глобальный контекст.

Улучшить понимание длинных текстов
Во-вторых, нам необходимо еще больше улучшить возможности планирования и совместной работы больших моделей для решения сложных задач. Вот также реальный случай в системе ответов на вопросы Мы часто сталкиваемся с путаницей: для определенного вопроса на естественном языке, должны ли мы использовать знание графа знаний, чтобы ответить на него, или позволить большой модели ответить на него? Мы надеемся, что большая модель сможет принимать независимые решения, планировать, решать, следует ли использовать внешние знания, и решать, какие внешние знания необходимо использовать. Для разных источников или разных типов знаний свои знания можно получить через вызовы API. Это также требует, чтобы большая модель понимала API и соответствующие правила использования, взаимосвязь вызовов, конфигурацию параметров, а также форматы ввода и вывода, чтобы реализовать взаимодействие между моделью и инструментами внешней базы знаний. Однако, объективно говоря, существует много внешних инструментов для больших моделей, и среда, в которой находятся инструменты, также очень сложна.Необходимо постоянно оптимизировать масштаб и возможности совместной работы больших моделей, чтобы гарантировать, что большие модели могут решать сложные задачи в сотрудничестве с различными инструментами.Идеальный эффект.

Возможности планирования и совместной работы для сложных задач
В-третьих, необходимо дополнительно оптимизировать структурную интерпретацию и стиль текста. В практических приложениях у пользователей есть особые требования к стилям, и большая модель должна иметь возможность понимать и своевременно реагировать на корректировки выходного формата. Комплексная добыча в отрасли по-прежнему пользуется большим спросом. В прошлом нам обычно требовалось предоставлять справочную информацию об отрасли (например, схему домена) в приглашении, чтобы большая модель могла извлекать ключевые элементы. После оптимизации способность большой модели к фоновому пониманию в различных областях была значительно улучшена, и она может адаптивно понимать предысторию различных областей, не полагаясь на конкретные отраслевые фоновые подсказки, и может проводить структурный анализ высокопрофессиональных текстов и разбор.
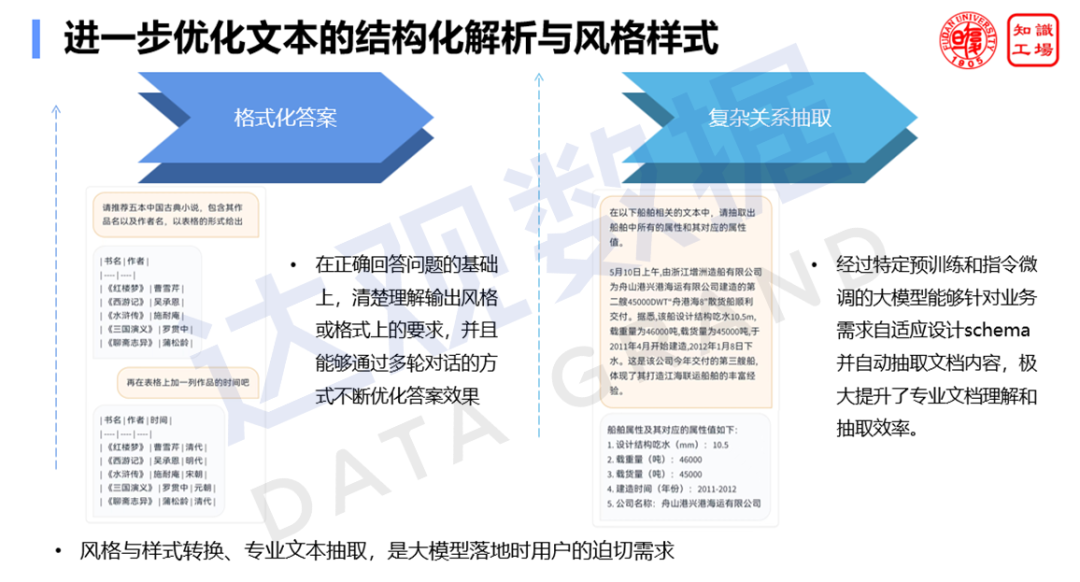
Оптимизация текста для структурированной интерпретации и стилистического оформления
В-четвертых, необходимо постоянно улучшать способность большой модели отвечать на вопросы в области вопроса и ответа, в том числе способность отвечать прямо, не ходить по кругу, верно отвечать на заданный документ, твердо верить в правильные убеждения. Общая большая модель склонна к кругам и мутным ответам в процессе вопросов и ответов. В процессе разговора с большой моделью она, скорее всего, ответит: «Я большая модель, мой ответ только для справки...», не желая давать ответ с четким суждением (главным образом потому, что общая модель предназначена для безопасность, первоначальный замысел освобождения от ответственности), который долго ставит в замешательство, но не может получить желаемого ответа. В вертикальных доменных приложениях мы не хотим, чтобы он ходил по кругу, мы надеемся, что он может давать ответы напрямую, чтобы помочь нам в принятии решений. В то же время мы требуем, чтобы большая модель не превышала заданный диапазон содержимого при формировании ответа на основе данного документа. Он должен сочетать заданный контент и собственную способность генерации языка, чтобы дать разумный ответ, а не играть сам по себе. В вертикальных доменных приложениях мы не хотим, чтобы большая модель играла бессистемно, она должна быть верна вовлеченной области. Кроме того, необходимо улучшить способность большой модели сохранять правильные убеждения. Модели со слабыми убеждениями будут иметь ответ «трава на стене», то есть без четкой позиции, вы говорите ей «вы не правы», и она тут же меняет слова. неправильно, он скажет: «Да, я был неправ, 2+2 должно равняться 5». У крупной модели со слишком твердыми убеждениями будет проблема «пасть мертвой утки», то есть ясно указано, что она ответила неправильно, но она по-прежнему настаивает на том, чтобы не меняться. Оба случая ложны. При применении вертикальной области мы надеемся, что большая модель сможет осознать свои собственные ошибки, не поколебать своих правильных убеждений, а также избежать проблемы знания ошибок и их неисправления.

Улучшение способности больших моделей отвечать на вопросы предметной области
С точки зрения синергии между большими моделями и периферийными технологиями в первую очередь необходимо дополнительно оптимизировать диагностику и оценку приложений больших моделей. Лаборатория фабрики знаний недавно выпустила несколько междисциплинарных систем оценки, которые предназначены для оценки с двух точек зрения: диагностика процесса обучения большой модели и эффект применения большой модели. В настоящее время многие оценки ориентированы на применение, но на самом деле оценки для диагностики также очень важны. Нам необходимо установить эталон оценки для наборов данных, необходимых для обучения больших моделей, и нам необходимо создать систему передового опыта для ключевых параметров, архитектуры модели и соотношений данных в процессе обучения больших моделей посредством оценки. Кроме того, оценка больших моделей должна развиваться от единственной цели «высокий балл» по текущему наиболее стандартному набору данных оценки к двойной цели «высокая энергия», которая учитывает решение практических задач. Это означает, что оценка не только фокусируется на оценке различных экзаменационных вопросов, которые сосредоточены на способности осваивать точки знаний, но также обращает внимание на способность больших моделей решать практические и сложные проблемы принятия решений. Система оценки больших моделей, ориентированная на «высокий балл и высокую энергию», является основным направлением развития оценки больших моделей.

Оптимизация диагностики и оценки применения больших моделей
Кроме того, необходимо дополнительно улучшить возможности управления данными больших моделей. Многие проблемы практического применения больших моделей, такие как предвзятость ответов, утечка конфиденциальной информации, нарушение авторских прав, нарушения содержания, неправильные представления и т. д., в конечном итоге могут быть отнесены к источнику данных. Текущее основное мышление по-прежнему связано с пост-событийной оптимизацией после уточнения возможностей больших моделей. Здесь необходимо отметить, что вышеупомянутые проблемы больших моделей из исходного кода сложно решить с помощью апостериорной оптимизации. Например, утечки конфиденциальности, нарушения авторских прав и идеологические ошибки больших моделей, мы не можем гарантировать соответствующую безопасность на 100% на уровне результата. В крупных моделях по-прежнему существует определенная вероятность ошибок или непредсказуемых ошибок, которые приведут к нарушению соответствующих законов и правил и приведут к непоправимым последствиям. Следовательно, необходимо усилить управление данными от источника данных и выполнять такие работы, как очистка данных, идентификация конфиденциальности, исправление выборки и очистка от незаконного контента. Соответствующие отделы должны активно продвигать стандарты и нормы наборов данных для обучения больших моделей, проводить сертификацию соответствия наборов данных для обучения больших моделей и обеспечивать здоровое развитие индустрии больших моделей из источника данных.
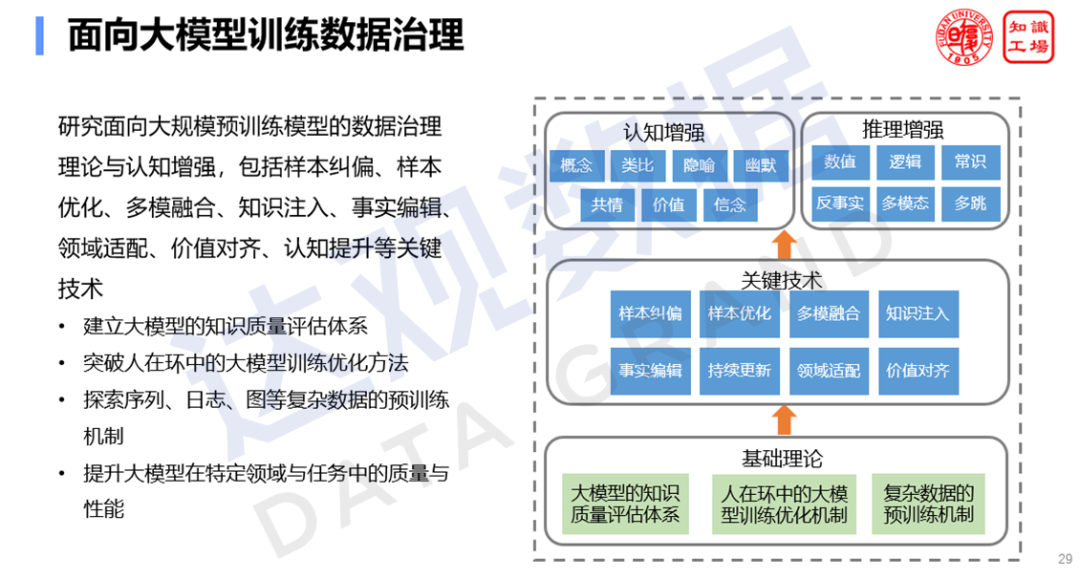
Улучшите возможности управления данными больших моделей
В целом, основными проблемами в исследованиях и разработках отечественных крупномасштабных моделей по-прежнему являются отсутствие систем и возможностей управления данными, а также отклонение оценки от требований приложения. Интенсификация исследований в этих двух аспектах и содействие решению этих двух проблем являются ключевыми мерами по содействию развитию индустрии крупномасштабных моделей в моей стране в ближайшем будущем.
Наконец, я все же хочу подчеркнуть, что крупная модель общего назначения не должна оставаться на стадии открытого чата, как ChatGPT. повышенная производительность, которая помогает качественному развитию и цифровой трансформации различных отраслей в нашей стране.

