Papel: https://arxiv.org/pdf/2308.00692
Código: GitHub - dvlab-research/LISA
Resumen
Aunque los sistemas de percepción han logrado un progreso notable en los últimos años, todavía se basan en instrucciones humanas explícitas para identificar objetos o categorías de destino antes de realizar tareas de reconocimiento visual. Dichos sistemas carecen de la capacidad de razonar activamente y comprender la intención implícita del usuario. En este trabajo, proponemos una nueva tarea de segmentación: la segmentación por inferencia . El objetivo de esta tarea es generar una máscara de segmentación dado un texto de consulta complejo e implícito . Además, construimos un punto de referencia que consta de más de mil pares de instrucciones de imágenes, incorporando razonamiento complejo y conocimiento del mundo con fines de evaluación . Finalmente, proponemos LISA: asistente de segmentación con instrucciones de lenguaje grande, que hereda las capacidades de generación de lenguaje de los modelos de lenguaje grande (LLM) multimodales y, al mismo tiempo, tiene la capacidad de generar máscaras de segmentación . Ampliamos el vocabulario original utilizando la etiqueta <SEG> y proponemos incrustaciones como un paradigma de enmascaramiento para desbloquear las capacidades de segmentación. En particular, LISA puede manejar las siguientes situaciones: 1 ) razonamiento complejo; 2) conocimiento del mundo; 3) respuestas interpretativas; 4) diálogo de múltiples turnos . Además, muestra una fuerte capacidad de disparo cero cuando se entrena solo en el conjunto de datos sin inferencia. Además, el ajuste fino del modelo utilizando solo 239 pares de instrucciones de imagen de segmentación de inferencia mejora aún más el rendimiento. Los experimentos muestran que el método no solo desbloquea nuevas capacidades de segmentación por inferencia, sino que también es eficaz tanto en la segmentación por inferencia compleja como en las tareas de segmentación por referencia estándar.

fondo
En este trabajo, presentamos una nueva tarea de segmentación: la segmentación por inferencia, que requiere la generación de máscaras de segmentación binarias basadas en textos de consulta implícitos que implican un razonamiento complejo.
En particular, el texto de la consulta no se limita a referencias simples (p. ej., "naranjas"), sino a descripciones más complejas que involucran razonamientos complejos o conocimiento del mundo (p. ej., "los alimentos de alta calidad contienen vitamina C"). Para llevar a cabo esta tarea, el modelo debe tener dos capacidades clave: 1) razonar sobre consultas textuales complejas e implícitas junto con imágenes y 2) generar máscaras de segmentación.
Aunque algunos estudios han integrado capacidades de razonamiento sólidas en LLM multimodales para entrada visual, la mayoría de estos modelos se centran principalmente en tareas de generación de texto y requieren tareas de formato de salida de granularidad fina, como la segmentación.
Al representar las máscaras de segmentación como incrustaciones, LISA gana capacidades de segmentación y se beneficia de la capacitación integral.
contribuir
1) Introducimos la tarea de segmentación por inferencia, que requiere un razonamiento basado en instrucciones humanas implícitas. Esta tarea destaca la importancia de la capacidad de auto-razonamiento, que es crucial para construir un sistema de percepción verdaderamente inteligente.
2) Creamos un punto de referencia de segmentación de inferencia, ReasonSeg, que contiene más de mil pares de instrucciones de imágenes. Este punto de referencia es fundamental para evaluar y alentar a la comunidad a desarrollar nuevas tecnologías.
3) Proponemos nuestro modelo - LISA, que emplea la incrustación como paradigma de enmascaramiento para incorporar nuevas funciones de segmentación. Cuando se entrena en el conjunto de datos sin inferencia, LISA demuestra una sólida capacidad de disparo cero en la tarea de segmentación de inferencia, y el rendimiento mejora aún más mediante el ajuste fino de 239 pares de instrucciones de imágenes que involucran inferencia. Creemos que LISA facilitará el desarrollo de la inteligencia perceptiva e inspirará nuevos avances en esta dirección.
trabajo relacionado
Segmentación de imágenes SEGMENTACIÓN DE IMÁGENES
El objetivo de la segmentación semántica es asignar una etiqueta de clase a cada píxel de una imagen.
Numerosos estudios han propuesto varios diseños (por ejemplo, codificador-decodificador, convolución dilatada, módulos de agrupación piramidal, operadores no locales, etc.) para codificar información semántica de manera eficiente.
Los estudios de segmentación de instancias y la segmentación de vista completa han introducido varias innovaciones arquitectónicas para la segmentación a nivel de instancia, incluidas las estructuras basadas en DETR (Carion et al., 2020), atención de máscara y convolución dinámica .
Más recientemente, Kirillov y otros (2023) introdujeron SAM , entrenados con miles de millones de máscaras de alta calidad, que admiten cuadros delimitadores y puntos como señales, al tiempo que demuestran una excelente calidad de segmentación. X-Decoder (Zou et al., 2023a) une la visión y el lenguaje, unificando múltiples tareas en un solo modelo. SEEM (Zou et al., 2023b) admite además varios métodos de interacción humana, incluidos texto, audio y garabatos. Sin embargo, estos estudios se centran principalmente en la unificación y la compatibilidad multitarea, ignorando la inyección de nuevas funciones.
En este trabajo, proponemos LISA para resolver tareas de segmentación por inferencia y aumentar las capacidades de auto-razonamiento de los segmentadores visuales existentes .
Modelo de lenguaje grande multimodal MODELO DE LENGUAJE GRANDE MULTIMODAL
Motivados por las capacidades superiores de razonamiento de los LLM, los investigadores están explorando formas de transferir estas capacidades al dominio de la visión, desarrollando LLM multimodales.
Flamingo (Alayrac, 2022) emplea una estructura de atención que se cruza para centrarse en contextos visuales, lo que permite el aprendizaje del contexto visual.
Modelos como BLIP-2 (Li et al., 2023b) y mPLUG-OWL (Ye et al., 2023) proponen codificar características de imagen con un codificador visual, que luego se introducen en un LLM junto con incrustaciones de texto.
Otter (Li et al., 2023a) incorpora además características robustas de pocos disparos a través del ajuste de instrucciones contextuales en el conjunto de datos MIMIC-IT propuesto. LLaVA (Liu et al., 2023b) y MiniGPT-4 (Zhu et al., 2023) primero realizan la alineación de características de imagen y texto, seguida por el ajuste de instrucciones.
Además, numerosos trabajos (Wu et al., 2023; Yang et al., 2023b; Shen et al., 2023; Liu et al., 2023c; Yang et al., 2023a) utilizan ingeniería instantánea para conectar módulos independientes a través de llamadas API. , pero no Beneficios de la formación integral.
Recientemente, ha habido varios estudios que exploran la intersección entre LLM y multimodalidad en tareas de visión.
VisionLLM (Wang et al., 2023) proporciona una interfaz flexible para múltiples tareas centradas en la visión a través del ajuste de instrucciones, pero no utiliza completamente LLM para razonamiento complejo.
Kosmos-2 (Peng et al., 2023) construye datos a gran escala basados en pares de imagen y texto, inyectando la capacidad de basarse en LLM. GPT4RoI (Zhang et al., 2023) introduce cuadros espaciales como entrada y entrena el modelo en pares de región-texto
Por el contrario, nuestro trabajo pretende
1) Inyectar eficientemente capacidades de segmentación en LLM multimodales
2) Desbloquear la capacidad de auto-razonamiento del sistema de percepción actual.
Introducción a la segmentación del razonamiento

definición del problema
La tarea de segmentación de inferencia es generar una máscara de segmentación binariaM dada una imagen de entrada ximg y una instrucción de texto de consulta implícita xtxt
En lugar de frases simples (p. ej., "cubo de basura"), el texto de consulta puede contener expresiones más complejas (p. ej., "cosas que se deben tirar a la basura") u oraciones más largas (p. ej., "después de cocinar, come ¿Dónde podemos tirar el sobras y sobras?"), que implica un razonamiento complejo o conocimiento del mundo.
Puntos de referencia
En ausencia de una evaluación cuantitativa, es necesario establecer un punto de referencia para las tareas de segmentación de inferencia. Para garantizar una evaluación confiable, recopilamos un conjunto diverso de imágenes de OpenImages (Kuznetsova et al., 2020) y ScanNetv2 (Dai et al., 2017) y las emparejamos con instrucciones de texto implícitas y máscaras de objetos de alta calidad. Nuestros subtítulos incluyen dos tipos: 1) oraciones cortas; 2) oraciones largas, como se muestra en la Figura 2. El punto de referencia ReasonSeg resultante contiene un total de 1218 pares de instrucciones de imágenes. El conjunto de datos se divide además en tres partes: tren, val y prueba, que contienen 239, 200 y 779 pares de instrucciones de imágenes, respectivamente. Dado que el propósito principal del benchmark es la evaluación, los conjuntos de validación y prueba contienen más muestras de instrucciones de imágenes.
método
estructura del modelo

Incrustación como máscara
VisionLLM (Wang et al., 2023) puede admitir la representación de máscaras de segmentación como texto sin formato analizándolas en secuencias de polígonos, y permite el entrenamiento integral dentro de los marcos LLM multimodales existentes. Sin embargo, el entrenamiento de extremo a extremo de secuencias de polígonos presenta desafíos de optimización y puede afectar la generalización a menos que se utilicen muchos datos y recursos computacionales. Por ejemplo, para entrenar un modelo 7B, VisionLLM requiere 4 × 8 GPU NVIDIA 80G A100 y 50 épocas, lo que es computacionalmente prohibitivo. Por el contrario, entrenar LISA-7B requiere solo 10 000 pasos en 8 GPU NVIDIA 24G 3090 .
Con este fin, proponemos incrustaciones como un paradigma de enmascaramiento para inyectar nuevas características de segmentación en LLM multimodales.
paso 1
Texto
Primero ampliamos el vocabulario LLM original con un nuevo token, a saber, <SEG>, que representa una solicitud de salida de segmentación. Dada una instrucción de texto xtxt y una imagen de entrada ximg, las alimentamos a un LLM F multimodal, que a su vez genera una respuesta de texto ytxt.

Cuando LLM pretende generar máscaras de segmentación binaria, la salida ytxt debe contener un token <SEG>.
Luego, extraemos la incrustación de la última capa correspondiente al token <SEG> - hseg, y aplicamos la capa de proyección MLP γ para obtener hseg .
imagen
Mientras tanto, una red neuronal de columna vertebral visual extrae incrustaciones visuales de imágenes de entrada visuales. Finalmente, hseg y f se alimentan al decodificador Fdec para producir la máscara de segmentación final M. La estructura detallada del decodificador Fdec se refiere a Kirillov y otros (2023). Este proceso se puede expresar como

objetivos de entrenamiento
función de pérdida
El modelo se entrena de extremo a extremo utilizando la pérdida de generación de texto Lxt y la pérdida de máscara de segmentación Lmask . El objetivo total L es una suma ponderada de estas pérdidas, determinada por λtxt y λmask:
![]()
Específicamente, Ltxt es una pérdida de entropía cruzada autorregresiva para la generación de texto y Lmask es una pérdida de máscara, lo que impulsa al modelo a producir resultados de segmentación de alta calidad. Para calcular Lmask, empleamos una combinación de pérdida de entropía cruzada binaria (BCE) por píxel y pérdida DICE con los pesos de pérdida correspondientes λbce y λdice, respectivamente. Dados los objetivos de verdad en el terreno ytxt y m, estas pérdidas se pueden expresar como:

Formulación de datos de entrenamiento fórmula de datos de entrenamiento
Nuestros datos de entrenamiento constan de tres partes, todas derivadas de conjuntos de datos públicos ampliamente utilizados. los detalles son los siguientes

Conjunto de datos de segmentación semántica Conjunto de datos de segmentación semántica
Los conjuntos de datos de segmentación semántica generalmente consisten en imágenes y etiquetas multiclase correspondientes.
Durante el entrenamiento, seleccionamos aleatoriamente varias categorías para cada imagen. Para generar datos que coincidan con el formato de la pregunta y respuesta visual, utilizamos la siguiente plantilla de pregunta y respuesta
" USUARIO: <IMAGEN> ¿Puede segmentar {NOMBRE DE CLASE} en esta imagen?" Asistente: Sí <SEG>, donde {NOMBRE DE CLASE} es la categoría seleccionada y <IMAGEN> representa el marcador de posición para el token de parches de imagen.
La supervisión de pérdida de máscara se proporciona utilizando la máscara de segmentación binaria correspondiente como verdad de campo. Durante la capacitación, también usamos otras plantillas para generar datos de control de calidad para garantizar la diversidad de datos. Empleamos conjuntos de datos de segmentación de piezas ADE20K , COCO-Stuff y LVIS-PACO .
Conjunto de datos de segmentación de referencia Vanilla Conjunto de datos de segmentación de referencia
Los conjuntos de datos de segmentación de referencia proporcionan descripciones breves y explícitas de las imágenes de entrada y los objetos de destino.
Por lo tanto, es fácil convertirlos en pares de preguntas y respuestas usando una plantilla como "¿Puede USUARIO: <IMAGEN> dividir {descripción} en esta imagen?" Asistente: Por supuesto, <SEG>, donde {descripción} es la descripción explícita dada. Esta sección utiliza los conjuntos de datos refCOCO , refCOCO+ , refCOCOg y refCLEF .
Conjunto de datos de respuestas de preguntas visuales Conjunto de datos de respuestas de preguntas de imagen
Para mantener la capacidad original de respuesta visual a preguntas (VQA) de LLM multimodal, también incluimos el conjunto de datos de VQA durante el entrenamiento. Usamos directamente los datos llava-instruction-150k generados por GPT-4 (Liu et al., 2023b).
parámetros entrenables
Para preservar la capacidad de generalización del LLM F multimodal preentrenado (es decir, LLaVA en nuestros experimentos), aprovechamos LoRA (Hu et al., 2021) para un ajuste fino eficiente y congelamos completamente la columna vertebral visual. El decodificador Fdec está totalmente ajustado. Además, la palabra incrustación y la capa de proyección γ de LLM también se pueden entrenar.
experimento
configuración del experimento
estructura de red
A menos que se indique lo contrario, adoptamos LLaVA-7B-v1-1 o LLaVA-13B-v1-1 como LLM F multimodal
La red troncal ViT-H SAM se utiliza como red troncal visual.
La capa de proyección de γ es un MLP con canales [256, 4096, 4096] .
detalles de implementacion
8 GPU NVIDIA 24G 3090
El guión de entrenamiento se basa en el motor de velocidad profunda (Rasley et al., 2020). Usamos el optimizador AdamW (Loshchilov & Hutter, 2017) con tasa de aprendizaje y caída de peso establecida en 0.0003 y 0, respectivamente .
También adoptamos WarmupDecayLR como programador de tasa de aprendizaje , donde las iteraciones de calentamiento se establecen en 100.
Los pesos de pérdida de generación de texto λtxt gen y pérdida de máscara λmask se establecen en 1,0 y 1,0 respectivamente,
Los pesos de pérdida bce λbce y pérdida de dados λdice se establecen en 2,0 y 0,5 respectivamente.
Además, el tamaño de lote de cada dispositivo se establece en 2 y el paso de acumulación de gradiente se establece en 10. Durante el entrenamiento, elegimos hasta 3 categorías para cada imagen en el conjunto de datos de segmentación semántica.
conjunto de datos
Para conjuntos de datos de segmentación semántica, usamos ADE20K (Zhou et al., 2017) y COCO-Stuff (Caesar et al., 2018). Además, para mejorar los resultados de segmentación de ciertas partes de los objetos, también utilizamos conjuntos de datos de segmentación semántica parcial, incluidos PACO-LVIS (Ramanathan et al., 2023), PartImageNet (He et al., 2022) y PASCAL-Part (Chen et al. Personas, 2014);
Para los conjuntos de datos de segmentación de referencia, usamos refCLEF , refCOCO , refCOCO+ (Kazemzadeh et al., 2014) y refCOCOg (Mao et al., 2016).
Para el conjunto de datos de Visual Question Answering (VQA), usamos el conjunto de datos llava-instruction-150k (Liu et al., 2023b). Para evitar la fuga de datos, excluimos las muestras de COCO cuyas imágenes aparecen en el conjunto de validación refCOCO(+/g) durante el entrenamiento.
Además, sorprendentemente descubrimos que el rendimiento del modelo se puede mejorar aún más ajustando el modelo en 239 muestras de pares de instrucciones de imagen ReasonSeg.
Índice de evaluación
Seguimos la mayoría de los trabajos anteriores sobre la segmentación de referencia (Kazemzadeh et al., 2014;) gIoU se define por la media de todas las intersecciones-uniones (iou) por imagen, mientras que cIoU se define por las intersecciones-uniones acumulativas. Dado que cIoU tiene un gran sesgo para los objetos de área grande y fluctúa mucho, se prefiere gIoU .
Resultados experimentales
SEGMENTACIÓN DE RAZONAMIENTO

Un modelo solo puede hacer un buen trabajo si realmente comprende la consulta. Los trabajos existentes se limitan a citas explícitas sin métodos adecuados para comprender las consultas implícitas, mientras que nuestro modelo aprovecha un LLM multimodal para lograrlo.
El rendimiento de LISA-13B es mucho mejor que el de 7B, especialmente en el escenario de consultas largas, lo que sugiere que el cuello de botella de rendimiento actual aún puede estar en la comprensión del texto de la consulta, y un LLM multimodal más potente puede conducir a mejores resultados.
SEGMENTACIÓN DE REFERENCIA DE VAINILLA
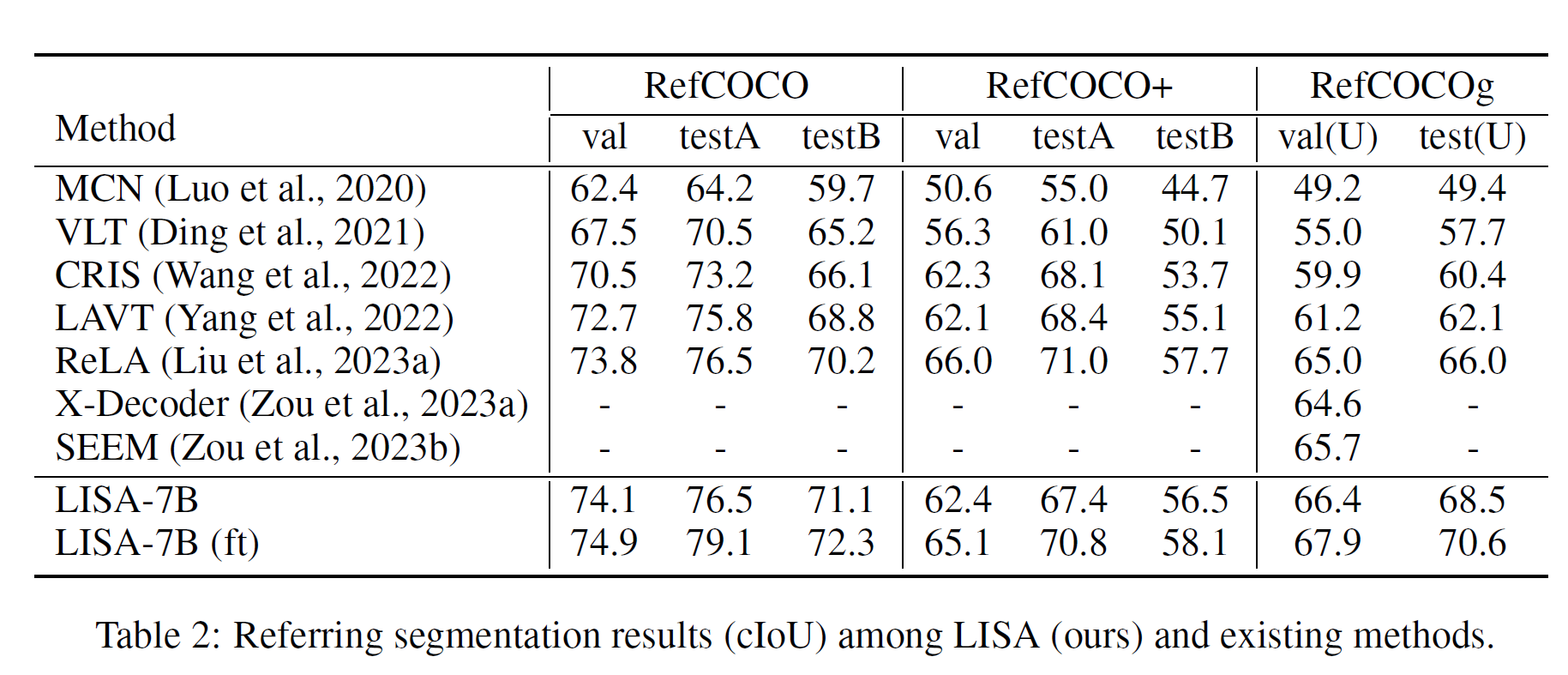
experimento de ablación
A menos que se indique lo contrario, informamos las métricas gIoU y cIoU para LISA-7B en el conjunto de validación.
Opciones de diseño para la columna vertebral visual

Las opciones de diseño para la columna vertebral visual son flexibles y no se limitan a SAM
Ajuste fino de SAM LoRA
Nos dimos cuenta de que la red troncal SAM sintonizada con LoRA no funcionaba tan bien como la red troncal congelada. Una posible razón es que el ajuste fino debilita la capacidad de generalización del modelo SAM original.
Pesos preentrenados SAM
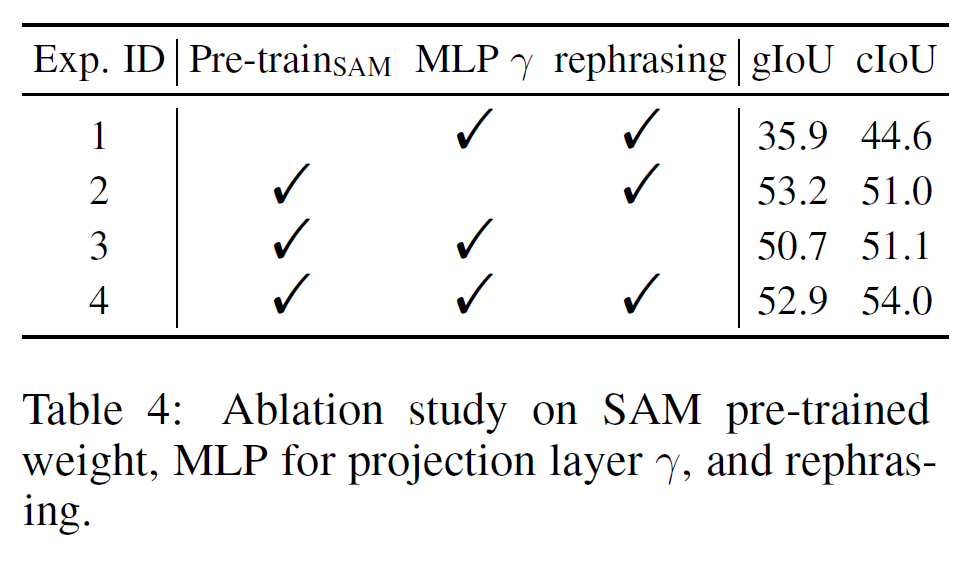
¡Sin pesas previas al entrenamiento, el rendimiento cae drásticamente!
MLP frente a capa de proyección lineal
Notamos que hacer γ MLP tiene una pequeña caída de rendimiento en gIoU, pero un rendimiento relativamente alto en cIoU↑
Aportación de todo tipo de datos de entrenamiento
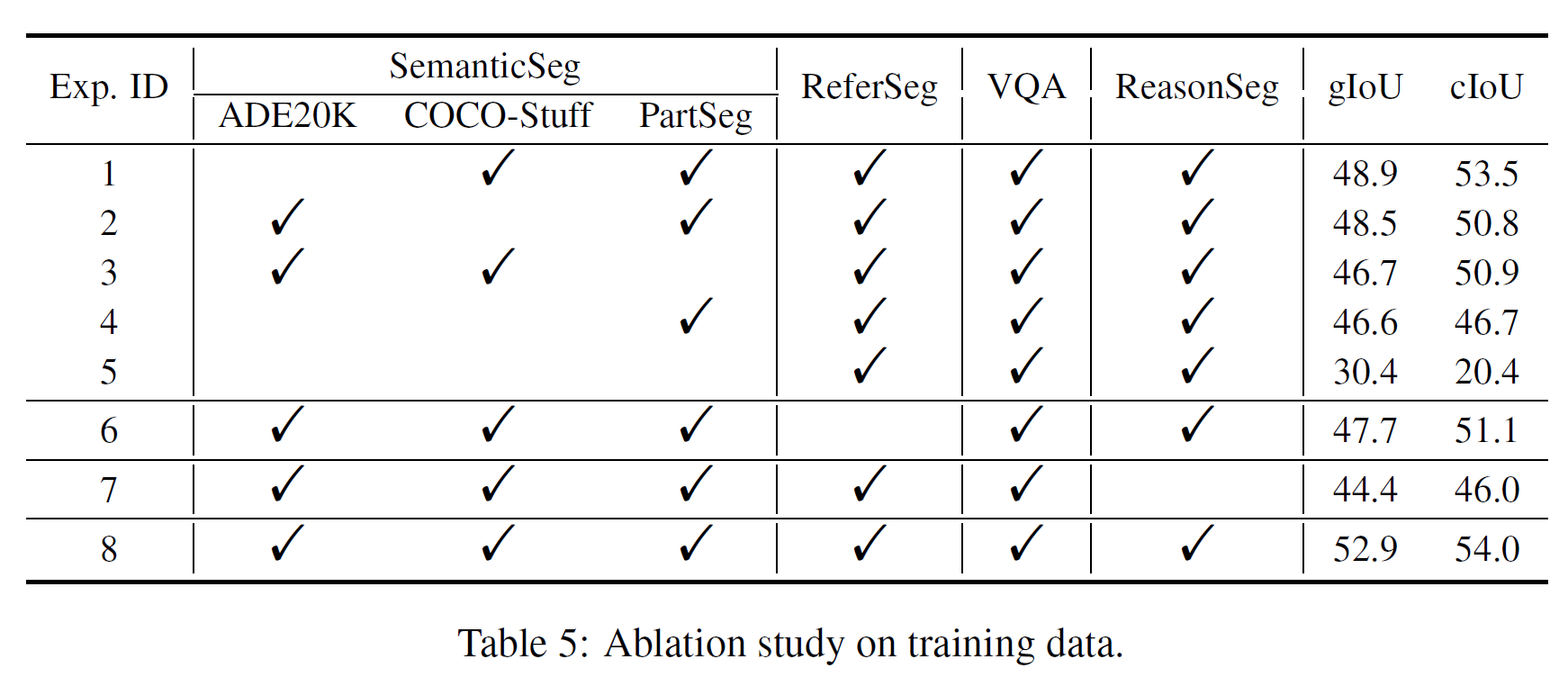
Vale la pena señalar que en Exp. 4, no usamos ningún conjunto de datos de segmentación semántica y el rendimiento disminuyó mucho. Suponemos que el conjunto de datos de segmentación semántica proporciona una gran cantidad de máscaras binarias reales para el entrenamiento, ya que una etiqueta multiclase puede producir varias máscaras binarias. Esto muestra que los conjuntos de datos de segmentación semántica son cruciales en el entrenamiento.
Resumen de comandos GPT-3.5
En el proceso de ajuste fino del par de instrucciones de imagen para la segmentación de inferencias, usamos GPT-3.5 para reescribir la instrucción de texto y seleccionar una al azar. La comparación del Experimento 3 y el Experimento 4 en la Tabla 4 muestra que el rendimiento mejora en un 2,2 % y un 2,9 % cIoU respectivamente. Este resultado verifica la efectividad de este método de aumento de datos.
APÉNDICE - ALGUNOS RESULTADOS EXPERIMENTALES

