
Análisis de las preguntas de disertación y diseño del CDGP en junio de 2023
( Agregue gzh "big data iron eater", responda "2023 cdgp " para obtener la versión completa)
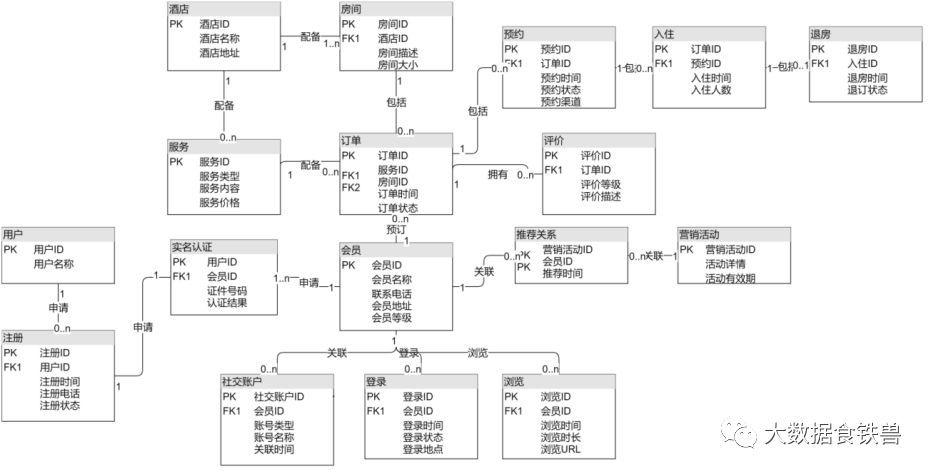
- Modelado de miembros del hotel
- Combinado con leyes y regulaciones de seguridad de datos nacionales y extranjeras, hable sobre la construcción de un sistema de gestión de seguridad de transmisión de datos en el extranjero
Nacional: "Ley de seguridad de datos", "Ley de seguridad cibernética", "Medidas de evaluación de seguridad de exportación de datos" que se implementarán en septiembre de 2022 En el extranjero: Reglamento de protección de datos de la UE, Ley de seguridad nacional de EE. UU. y Ley Patriota de EE. UU., Ley federal de gestión de seguridad de la información , Ley 198 de Canadá y otras involucran información personal: "Ley de protección de información personal" ● Construya la gestión de seguridad de datos a partir de los siguientes aspectos: (1) Seguridad de la información, que incluye: vulnerabilidad, amenaza, riesgo, encriptación, ofuscación/desensibilización (2) Seguridad de red, incluidos: puertas traseras, bots/cadáveres, cortafuegos, DMZ, registradores de pulsaciones de teclas, pruebas de penetración, redes privadas virtuales (VPN) (3) seguridad de datos, incluidos: seguridad de instalaciones, seguridad de dispositivos, seguridad de credenciales, seguridad de comunicaciones electrónicas ● Gestión y construcción a lo largo del ciclo de vida de los datos: el ciclo de vida completo de los datos incluye planificación-diseño/activación-creación/adquisición-almacenamiento/mantenimiento-uso-mejora y eliminación. Planificación: Asociación de datos con requisitos de seguridad y privacidad Diseño y Habilitación: "Establecer medidas de seguridad y protección de datos en el sistema Creación/Adquisición: Clasificar nuevos datos para que los datos estén debidamente protegidos Almacenamiento/Mantenimiento: Garantizar que el almacenamiento de datos cumpla con las políticas y regulaciones Uso: Administre los derechos de acceso para garantizar el uso adecuado de los datos y evitar el uso indebido Mejora: Manténgase a la vanguardia de los requisitos reglamentarios e identifique nuevas amenazas de seguridad Disposición: Procese los datos de conformidad con las políticas y los requisitos reglamentarios pertinentes
- (1) ¿Desafíos de la gestión de datos maestros? (2) ¿Cuáles son los objetivos de la gestión de datos maestros? (3) ¿Cómo identificar los datos maestros? (4) ¿Pasos de implementación de la gestión de datos maestros?
(1) Desafío: resolución de entidades (gestión de identidades), que es el proceso de identificación y gestión de asociaciones entre datos de diferentes sistemas y procesos. Este proceso debe gestionarse de forma continua para mantener la coherencia de estas entidades, instancias e identidades de datos maestros. (2) Meta : Asegurar que la organización tenga datos maestros completos, consistentes, actualizados y fidedignos en cada proceso, y alentar a las empresas a compartir datos maestros entre unidades de negocios y sistemas de aplicación. (3) Los datos maestros son datos sobre entidades comerciales, que incluyen principalmente datos de referencia, datos de estructura empresarial y datos de estructura de transacciones. Los pasos de identificación/análisis de entidades de datos maestros son los siguientes: 1) Coincidencia, 2) Análisis estándar, 3) Coincidencia de flujo de trabajo y tipo de conciliación, 4) Gestión de ID de datos, 5) Gestión de subordinados (4) Pasos: Identificar factores impulsores y necesidades y evaluar Evaluar fuentes de datos, definir métodos arquitectónicos, modelar datos maestros, definir responsabilidades de gestión y mantenimiento VI, establecer un sistema de gobierno para promover el uso de datos maestros .
- (1) ¿Cómo construir un almacén de datos? (2) ¿Cuáles son las características de la arquitectura de datos moderna? (3) ¿Cuáles son las similitudes y diferencias entre los almacenes de datos y los lagos de datos? (4) ¿Cómo resolver el problema SCD?
(1) El proceso principal de construcción del almacén de datos: 1) Comprender los requisitos 2) Definir y mantener la arquitectura del almacén de datos/inteligencia empresarial 3) Desarrollar el almacén de datos y el data mart 4) Cargar el almacén de datos 5) Implementar la cartera de productos de inteligencia empresarial 6) Mantener los datos productos (2) Características de la arquitectura de datos moderna: características de big data: 3V (gran cantidad, muchos tipos, cambios rápidos) + densidad de bajo valor, características de alto valor de la arquitectura de datos: integración de lagos y almacenes, integración de flujos y lotes. Los representantes típicos son la arquitectura Lambda y la arquitectura Kappa. Aquí se puede hablar de ello en función de la puntuación. (3) Similitudes y diferencias entre los almacenes de datos y los lagos de datos: ● Similitudes: ambos se pueden usar para el almacenamiento y análisis de big data, y están orientados a aplicaciones de nivel empresarial. Todos tienen una capacidad de almacenamiento muy grande y una velocidad de acceso a datos eficiente. Ambos admiten el procesamiento de datos por lotes y en tiempo real, y pueden hacer frente a diferentes requisitos de procesamiento de datos. Ambos están orientados a la toma de decisiones empresariales y al análisis de datos. ● Similitudes y diferencias: estructura de datos: los almacenes de datos adoptan estructuras de datos estandarizados, mientras que los lagos de datos admiten formatos de datos arbitrarios y modos de almacenamiento de datos no estandarizados. Fuente de datos: el almacén de datos extrae principalmente datos de diferentes fuentes de datos a través de ETL y luego los limpia, integra y procesa. El lago de datos almacena datos sin procesar sin procesar ni limpiar en un espacio de almacenamiento unificado y admite la lectura y consulta directas de todos los formatos de datos. Uso de datos: el almacén de datos se utiliza principalmente para la toma de decisiones empresariales y el análisis de informes, que es un método de análisis de datos relativamente tradicional. El lago de datos tiene una gama más amplia de aplicaciones y puede admitir varios campos, incluidos big data, aprendizaje automático e inteligencia artificial. Puntualidad de los datos: los datos del almacén de datos son principalmente registros de datos históricos, que se archivan y procesan en lotes, por lo que los datos reales solo se pueden obtener después de horas o días. El lago de datos admite más consultas y procesamiento de datos en tiempo real, y puede obtener y procesar datos en tiempo real. (4) Problema SCD:Los datos en algunas tablas de dimensiones no son estáticos, sino que cambian lentamente con el tiempo. Esta dimensión que cambia con el tiempo se denomina dimensión de cambio lento. El problema de tratar con cambios históricos en los datos de la tabla de dimensiones se denomina problema de dimensión de cambio lento. como problema SCD. Solución: mantenga el valor original, vuelva a escribir el valor del atributo, agregue una nueva fila de dimensiones, agregue una nueva columna de dimensiones, agregue una tabla de historial y use una tabla zip para guardar instantáneas históricas (recomendado).
- (1) ¿Cómo determinar el orden de prioridad de la gestión de la calidad de los datos? (2) Combinado con la situación real de la empresa, construya un sistema de gestión de calidad de datos en el orden de (1)
(1) La gestión de la calidad de los datos debe comenzar con los datos más importantes de la organización. Es decir, mayor calidad y más valor para la organización y los clientes. Los datos se pueden priorizar en función de factores como los requisitos reglamentarios, el valor financiero y el impacto inmediato para los clientes. (2) Según la situación real, el contenido de datos de la empresa y la clasificación de prioridad (omitido). El método para construir un sistema de gestión de la calidad de los datos: realizar la gestión de la calidad de los datos de acuerdo con el ciclo de vida de los datos. Planificación: Definir las características de los datos de alta calidad Diseñar y habilitar:Definir los controles del sistema y del proceso para evitar problemas con los datos y mantener la calidad de los datos Crear/adquirir:Medir o verificar los datos para garantizar que cumplan con los requisitos de calidad Almacenamiento/Mantenimiento:Con sistemas y procesos Probar los datos para garantizar que los datos puedan continuar cumpliendo con las expectativas Uso: Usar mecanismos de bucle de retroalimentación para mejorar continuamente la calidad de los datos Mejora: Tomar medidas sobre las oportunidades de mejora de la calidad de los datos Disposición: Identificar y mejorar correctamente los datos en función de los requisitos de calidad de los datos
- Combinado con la práctica de la empresa, cómo construir un sistema de gestión de metadatos para garantizar la calidad de los metadatos.
Los metadatos son datos. Como otros datos, también tiene un ciclo de vida y debemos gestionar su ciclo de vida. Planificación: defina los requisitos de los metadatos Diseño y habilitación: cree y gestione los metadatos como parte de las actividades de gestión de datos en curso. metadatos para obtener valor de los datos. Habilitar bucles de retroalimentación puede mejorar la calidad de los metadatos Mejora: mejorar los metadatos existentes con nuevos conocimientos para implementar nuevos metadatos Disposición del requisito: purgar o archivar metadatos obsoletos Pasos: seguir los pasos de gestión de calidad para administrar la calidad de los metadatos (1) Definir metadatos de alta calidad, (2) Definir estrategia de calidad de los metadatos, (3) definir el alcance de la evaluación inicial, (4) realizar la evaluación inicial de la calidad de los metadatos, (5) identificar y priorizar las mejoras, (6) definir los objetivos de mejora de la calidad de los metadatos, (7) desarrollar y desplegar operaciones de calidad de los metadatos, etc. . ● Actividades de metadatos: defina la estrategia de metadatos, comprenda los requisitos de metadatos, defina la arquitectura de metadatos, cree y mantenga metadatos, consulte informes y analice metadatos
- ¿Cuál es el contenido del súper esquema?
1、Malla de datos及Tejido de datos
Ambos son para resolver el problema del acceso y análisis de datos a través de plataformas y pilas de tecnología, de modo que los datos permanezcan en el lugar original en lugar de concentrarse en una plataforma o campo. La estructura de datos se centra en la tecnología, mientras que la malla de datos se centra en los cambios en la metodología y la colaboración organizativa.
Referencia de contenido más detallada:
¡Comprenda la diferencia entre Data Fabric y Data Mesh en 10 minutos! - Saber casi (zhihu.com)
2. Componentes de big data de código abierto (Atlas apareció en esta pregunta de opción múltiple)
Los componentes tecnológicos comunes son los siguientes:
● plataforma del sistema (Hadoop, CDH, HDP)
● Plataforma en la nube (AWS, GCP, Microsoft Azure)
● Gestión de supervisión (CM, Hue, Ambari, Dr.Elephant, Ganglia, Zabbix, Eagle, Prometheus)
● Sistema de archivos (HDFS, GPFS, Ceph, GlusterFS, Swift , BeeGFS, Alluxio, JindoFS)
● Programación de recursos (K8S, YARN, Mesos, independiente)
● marco de coordinación (ZooKeeper , Etcd, Consul)
● Almacenamiento de datos (HBase, Cassandra, ScyllaDB , MongoDB, Accumulo, Redis , Ignite, Geode, CouchDB, Kudu)
● Almacenamiento en filas y columnas (Parquet, ORC, Arrow, CarbonData, Avro)
● Lago de datos (IceBerg, Hudi, DeltaLake)
● Procesamiento de datos (MaxCompute, Hive, MapReduce, Spark, Flink, Storm, Tez, Samza, Apex, Beam, Heron)
● OLAP (Hologres, StarRocks, GreenPlum, Trino/Presto, Kylin, Impala, Druid, ElasticSearch, HAWQ, Lucene, Solr, Phoenix)
● Recopilación de datos (Flume, Filebeat, Logstash, Chukwa)
● Intercambio de datos (Sqoop , Kettle, DataX , NiFi)
● Sistema de mensajes (Pulsar, Kafka, RocketMQ, ActiveMQ, RabbitMQ)
● Programación de tareas (Azkaban, Oozie, Airflow, Contab, DolphinScheduler)
● Seguridad de datos (Ranger, Sentry, Atlas)
● Linaje de datos (OpenLineage, Egeria, Márquez, DataHub)
● Aprendizaje automático (Pai, Mahout, MADlib, Spark ML, TensorFlow, Keras, MxNet)
- Otros puntos de conocimiento que se pasan por alto fácilmente en la selección de temas
1. ¿Cuáles son las fases primera y segunda de la gestión de datos? Fase 1: Integración e interoperabilidad de datos, almacenamiento y operación de datos, seguridad de datos, modelado y diseño de datos Fase 2: arquitectura de datos, gobierno de datos, metadatos Fase 3: Gobierno de datos, datos Almacenamiento e inteligencia comercial, datos de referencia y datos maestros, gestión de documentos y contenido Fase 4: análisis de Big Data, minería de datos 2, pasos de la arquitectura de datos: definir el alcance, comprender los requisitos, diseñar, implementar3. Qué son los datos no estructurados: documentos de procesamiento de texto, correos electrónicos, redes sociales, salas de chat, archivos planos, hojas de cálculo, archivos xml, información transaccional, informes, gráficos, imágenes digitales, microfilm, video y audio. También hay una gran cantidad de datos no estructurados en documentos en papel.