1. Penetración de caché
1.1 Descripción del problema
Cuando el caché de redis se introduce en el sistema, después de que llega una solicitud, primero se consultará desde el caché de redis, y si hay un caché, se devolverá directamente. Si no hay caché, se consultará en la base de datos. Algunas claves corresponden a más datos que no existen en la base de datos. Cada vez que no se puede obtener una solicitud de esta clave desde el caché, la solicitud se presionará en la base de datos, lo que puede abrumar a la base de datos.
Por ejemplo, usar una identificación de usuario inexistente para obtener información del usuario, sin importar si hay un caché o una base de datos, si los piratas informáticos usan una gran cantidad de ataques de este tipo, la base de datos puede verse abrumada.
1.2 Soluciones
1.2.1 Caché para valores nulos
Si los datos devueltos por una consulta están vacíos (ya sea que la base de datos exista o no), aún almacenamos en caché el resultado (nulo) y establecemos un tiempo de caducidad corto para él, hasta cinco minutos.
1.2.2 Establecer la lista accesible (lista blanca)
Use el tipo de mapas de bits en redis para definir una lista accesible. La identificación de la lista se usa como el desplazamiento de los mapas de bits. Cada vez que el texto de muestra se compara con la identificación en el mapa de bits, si la identificación a la que se accede no está en los mapas de bits, se ser interceptado y no se permite el acceso.
1.2.3, usando el filtro Bloom
Bloom Filter (Bloom Filter) fue propuesto por Bloom en 1970. En realidad, es un vector binario muy largo (mapa de bits) y una serie de funciones de asignación aleatorias (funciones hash).
El filtro Bloom se puede utilizar para detectar si un elemento está en una colección. Sus ventajas son que su eficiencia de espacio y alcance de consulta superan con creces a los algoritmos generales. La desventaja es que tiene una cierta tasa de identificación errónea y dificultad en la eliminación.
Haga un hash de todos los datos posibles en mapas de bits lo suficientemente grandes, y los datos que no deben existir serán interceptados por estos mapas de bits, evitando así la presión de consulta en el sistema de almacenamiento subyacente.
1.2.4, Monitoreo en tiempo real
Cuando se descubre que la tasa de aciertos de redis comienza a disminuir rápidamente, es necesario verificar los objetos de acceso y los datos accedidos, cooperar con el personal de operación y mantenimiento y establecer una lista negra para restringir el servicio que se le brinda (por ejemplo : lista negra de IP)
2. Desglose de caché
2.1 Descripción del problema
Una tecla de acceso rápido en redis (una clave con un alto volumen de acceso) caduca. En este momento, llega una gran cantidad de solicitudes al mismo tiempo, y se descubre que no hay coincidencias en el caché. Todas estas solicitudes se encuentran en la db, lo que hace que la presión sobre la base de datos aumente instantáneamente, lo que puede romper la base de datos. Esta condición se denomina avería de caché.
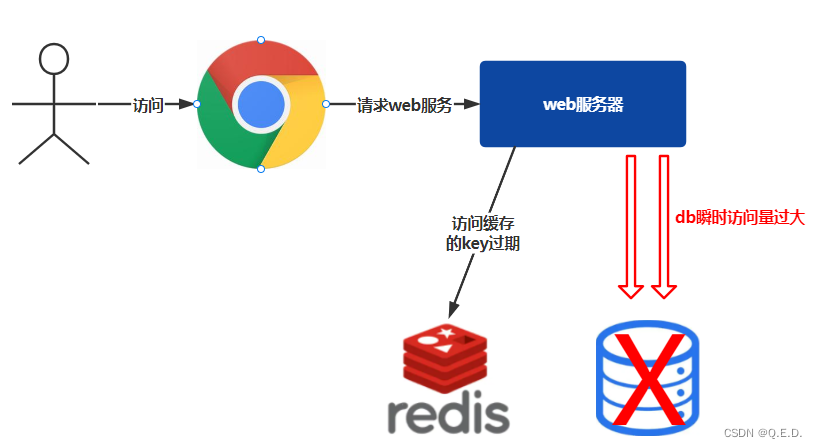
Fenómeno de avería de caché
- Aumento instantáneo de la presión de acceso a la base de datos
- No hay una gran cantidad de vencimientos de claves en redis
- redis funcionando normalmente
2.2 Soluciones
Es posible que se acceda a la clave con alta simultaneidad en algún momento, y es un dato muy "caliente". En este momento, se debe considerar un problema: el problema de la caché que se "descompone". Las soluciones comunes son las siguientes sigue
2.2.1 Preestablecer datos populares y ajustar el tiempo de caducidad a su debido tiempo
Antes del pico de redis, almacene algunos datos populares en redis por adelantado, monitoree estos datos populares en el caché y ajuste el tiempo de vencimiento en tiempo real.
2.2.2 Uso de candados
Cuando los datos no están disponibles en la caché, en lugar de consultar en la base de datos inmediatamente, es para obtener un bloqueo distribuido (como setnx en redis), obtener el bloqueo y cargar los datos en la base de datos; el hilo que no obtiene el candado duerme Vuelva a intentar el método completo de obtención de datos después de un período de tiempo.
3. Avalancha de caché
3.1 Descripción del problema
Los datos correspondientes a la clave existen, pero una gran cantidad de claves caducan en un período de tiempo muy corto. En este momento, si llega una gran cantidad de solicitudes simultáneas y no hay datos en el caché, una gran cantidad de solicitudes caerá a la base de datos para cargar datos, y la base de datos se aplastará, lo que provocará que el servicio se bloquee.
La diferencia entre la avalancha de caché y la falla de caché es que la primera es la caducidad centralizada de una gran cantidad de claves, mientras que la segunda es la caducidad de una determinada tecla de acceso rápido.
3.2 Soluciones
El impacto del efecto de avalancha en el sistema subyacente cuando el caché no es válido es muy terrible. Las soluciones comunes son las siguientes
3.2.1 Construyendo un caché multinivel
caché nginx + caché redis + otros cachés (ehcache, etc.)
3.2.2 Uso de bloqueos o colas
Use bloqueos o colas para asegurarse de que no haya una gran cantidad de subprocesos leyendo y escribiendo en la base de datos al mismo tiempo, para evitar que una gran cantidad de solicitudes simultáneas caigan en el sistema de almacenamiento subyacente cuando falla, lo cual no es adecuado. para situaciones de alta concurrencia.
3.2.3 Supervise la caducidad de la memoria caché y actualícela por adelantado
Supervise el caché, publique que el caché está a punto de caducar y actualice el caché con anticipación.
3.2.4 Distribuir el tiempo de invalidación de caché
Por ejemplo, podemos agregar un valor aleatorio basado en el tiempo de caducidad original, como 1-5 minutos aleatorios, de modo que la tasa de repetición del tiempo de caducidad de la memoria caché se reduzca y sea difícil desencadenar eventos de falla colectivos.
4. Bloqueo distribuido
4.1 Descripción del problema
Con las necesidades del desarrollo comercial, después de que el sistema de implementación original de una sola máquina se convierta en un sistema de clúster distribuido, dado que el sistema distribuido es multiproceso, multiproceso y distribuido en diferentes máquinas, esto hará que el control de concurrencia se bloquee en el situación original de implementación independiente La estrategia falla y la API de Java pura no puede proporcionar la capacidad de bloqueos distribuidos Para resolver este problema, se necesita un mecanismo de exclusión mutua entre JVM para controlar el acceso a los recursos compartidos Este es el problema que distribuyó las cerraduras necesitan resolver.
4.2 Implementación generalizada de bloqueos distribuidos
- Realizar bloqueo distribuido basado en base de datos
- Basado en caché (redis, etc.)
- Basado en el cuidador del zoológico
Cada solución de bloqueo distribuido tiene sus propias ventajas y desventajas
- Rendimiento: redis es el más alto
- Confiabilidad: el cuidador del zoológico es el más alto
Aquí implementamos bloqueos distribuidos basados en redis.
4.3 Solución: use redis para implementar bloqueos distribuidos
Debe usar el siguiente comando para implementar bloqueos distribuidos
set key value NX PX 有效期(毫秒)
Este comando significa: cuando la clave no existe, establezca su valor en valor y establezca su período de validez al mismo tiempo
ejemplo
set sku:1:info "ok" NX PX 10000Indica que cuando sku:1:info no existe, el valor de configuración es correcto y el período de validez es de 10 000 milisegundos.
4.3.1 El proceso de bloqueo
El proceso es como se muestra en la figura a continuación. Ejecute el comando establecer el valor de la clave NX PX período de validez (milisegundos), regrese ok para indicar que la ejecución fue exitosa y el bloqueo se adquirió con éxito. Cuando varios clientes ejecutan este comando al mismo tiempo, redis puede garantizar que solo uno pueda ejecutarse con éxito.

4.3.2 ¿Por qué se debe establecer el tiempo de caducidad?
Después de que el cliente adquiere el bloqueo, debido a problemas del sistema, como el tiempo de inactividad del sistema, el bloqueo no se puede liberar y otros clientes no pueden usar el bloqueo. Por lo tanto, es necesario especificar una vida útil para el bloqueo.
4.3.3 ¿Qué debo hacer si el período de validez es demasiado corto?
Por ejemplo, el período de validez se establece en 10 segundos, pero 10 segundos no son suficientes para el lado comercial. En este caso, el cliente necesita implementar la función de extensión de vida, que puede resolver este problema.
4.3.4 Resolver el problema de borrado accidental de bloqueos
Hay un caso de borrado accidental del bloqueo: el llamado borrado accidental consiste en eliminar el bloqueo en poder de otros.
Por ejemplo, cuando el subproceso A adquiere el bloqueo, el período de validez establecido es de 10 segundos, pero al ejecutar negocios, el programa A de repente se atasca durante más de 10 segundos. En este momento, el bloqueo puede ser adquirido por otros subprocesos, como el subproceso B. , y luego A se recupera de la congelación y continúa ejecutando el negocio. Después de ejecutar el negocio, ejecuta la operación de liberación del bloqueo. En este momento, A ejecutará el comando del. En este momento, el bloqueo se elimina accidentalmente, y el resultado es que el bloqueo mantenido por B se libera, y luego otros subprocesos adquirirán el bloqueo nuevamente, lo cual es muy grave.
¿Cómo resolverlo?
Antes de adquirir el bloqueo, genere una identificación única global e ingrese esta identificación en el valor correspondiente a la clave. Antes de liberar el bloqueo, tome la identificación de redis y compárela con la local para ver si es su propia identificación. Si Sí, luego ejecute del para liberar el bloqueo.
4.3.5 Todavía existe la posibilidad de borrado accidental (problema de operación atómica)
Como se mencionó anteriormente, antes de eliminar, primero se leerá la identificación de redis y luego se comparará con la identificación local, si son consistentes, se ejecutará la eliminación. El pseudocódigo es el siguiente
step1:判断 redis.get("key").id==本地id 是否相当,如果是则执行step2
step2:del key;
En este momento, si el propietario de la tarjeta del sistema se ejecuta cuando se ejecuta el paso 2, por ejemplo, el propietario de la tarjeta espera 10 segundos y luego lo vuelve a recibir. Durante este período, el bloqueo puede ser adquirido por otros subprocesos y un error accidental. la operación de eliminación se produce en este momento.
La causa raíz de este problema es: los dos pasos de juzgar y eliminar no son causados por operaciones atómicas para redis, ¿cómo resolverlo?
Necesito usar el script Lua para resolver.
4.3.6, la solución definitiva: Lua script para liberar el candado
Escriba una operación redis compleja o de varios pasos como una secuencia de comandos y envíela a redis para que la ejecute al mismo tiempo, lo que reduce la cantidad de conexiones repetidas a redis y mejora el rendimiento.
Los scripts de Lua son similares a las transacciones de redis, tienen cierta atomicidad, otros comandos no los pondrán en cola y pueden completar algunas operaciones de transacción de redis.
Pero preste atención a la función de script LUA de redis, que solo se puede usar en redis2.6 o superior.
el código se muestra a continuación:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @className LockTest
* @date 2022/6/21
**/
@RestController
public class LockTest {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@RequestMapping(value = "/lock", produces = MediaType.TEXT_PLAIN_VALUE)
public String lock() {
String lockKey = "k1";
String uuid = UUID.randomUUID().toString();
// 1.获取锁,有效期10秒
if (this.redisTemplate.opsForValue().setIfAbsent(lockKey, uuid, 10, TimeUnit.SECONDS)) {
// 2.执行业务
// todo 业务
//3.使用Lua脚本释放锁(可防止误删)
String script = "if redis.call('get',KEYS[1])==ARGV[1] then returnredis.call('del', KEYS[1]) else return 0 end ";
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
redisScript.setResultType(Long.class);
Long result = redisTemplate.execute(redisScript, Arrays.asList(lockKey), uuid);
System.out.println(result);
return "获取锁成功!";
} else {
return "加锁失败!";
}
}
}4.3.7 Resumen de bloqueos distribuidos
Para garantizar que los bloqueos distribuidos estén disponibles, debemos asegurarnos de que la implementación de bloqueos distribuidos cumpla las siguientes cuatro condiciones al mismo tiempo
- Exclusión mutua, solo un cliente puede mantener el bloqueo en cualquier momento
- Se produce un interbloqueo inequívoco, incluso si un cliente falla mientras mantiene el bloqueo y no lo libera, también puede garantizar que otros clientes puedan bloquear más tarde
- El remitente debe enviarse para desbloquear. El mismo cliente debe usarse para bloquear y desbloquear. El cliente no puede desbloquear los bloqueos de otras personas.
- El bloqueo y desbloqueo debe ser atómico