1. Optimización básica de HTTP
Hay dos factores principales que afectan una solicitud de red HTTP: ancho de banda y latencia.
Ancho de banda
Si todavía estamos en la etapa de acceso a Internet por marcado, el ancho de banda puede convertirse en un problema que afecta seriamente las solicitudes, pero ahora que la infraestructura de la red ha mejorado mucho el ancho de banda, ya no nos preocupamos de que el ancho de banda afecte la velocidad de la red, entonces solo hay retraso a la izquierda.
Demora
- Bloqueo del navegador (Bloqueo HOL): El navegador bloqueará la solicitud por algún motivo. El navegador solo puede tener 4 conexiones al mismo nombre de dominio al mismo tiempo (esto puede variar según el kernel del navegador), si se excede el número máximo de conexiones del navegador, las solicitudes posteriores se bloquearán.
- Búsqueda de DNS: el navegador necesita conocer la IP del servidor de destino para establecer una conexión. El sistema que resuelve los nombres de dominio a IP es el DNS. Por lo general, esto se puede lograr mediante el uso de resultados de caché de DNS para reducir este tiempo.
- Establecer una conexión (Conexión inicial): HTTP se basa en el protocolo TCP. El navegador solo puede aprovechar un mensaje de solicitud HTTP en el tercer protocolo de enlace como mínimo para lograr un establecimiento de conexión real. Sin embargo, estas conexiones no se pueden reutilizar, lo que provocará cada solicitud Ambos pasan por un apretón de manos de tres vías y un comienzo lento. El protocolo de enlace de tres vías tiene un impacto más evidente en escenarios de alta latencia, y el inicio lento tiene un mayor impacto en las solicitudes de archivos de gran tamaño.
2. Algunas diferencias entre HTTP1.0 y HTTP1.1
2.1 Código de estado de respuesta
HTTP/1.0 solo define 16 códigos de estado.
Se ha agregado recientemente una gran cantidad de códigos de estado a HTTP/1.1 y se han agregado 24 tipos de códigos de estado de respuesta de error.
Por ejemplo:
- 100 (Continuar)·············································· ················································· ··································
- 206 (Contenido parcial)·····Código identificador para solicitud de rango
- 409 (Conflicto)············································· ···································
- 410 (Desaparecido)············································· ················································· ···················.
2.2, procesamiento de caché
La tecnología de almacenamiento en caché ahorra una gran cantidad de ancho de banda de la red y reduce la demora en la recepción de información por parte de los usuarios al evitar interacciones frecuentes entre los usuarios y los servidores de origen.
2.2.1, HTTP/1.0
El mecanismo de almacenamiento en caché proporcionado por HTTP/1.0 es muy simple. El lado del servidor usa la etiqueta Expires para marcar (tiempo) un cuerpo de respuesta, y las solicitudes dentro del tiempo de marca de Expires obtendrán el caché del cuerpo de respuesta. En el cuerpo de la respuesta que el servidor devuelve al cliente por primera vez, hay una etiqueta Last-Modified, que marca la última modificación del recurso solicitado en el lado del servidor. En el encabezado de la solicitud, use la etiqueta If-Modified-Since, que marca un tiempo, lo que significa que el cliente le pregunta al servidor: "Después de este tiempo, ¿se ha modificado el recurso que quiero solicitar?" Por lo general, el valor de If -Modified-Since en el encabezado de la solicitud es el valor de Last-Modified en el cuerpo de la respuesta cuando se obtuvo el recurso por última vez.
Si el servidor recibe el encabezado de la solicitud y juzga que el recurso no ha sido modificado después del tiempo If-Modified-Since, devolverá un encabezado de respuesta 304 no modificado al cliente, indicando "el búfer está disponible, puede obtenerlo de ¡el navegador!".

Si el servidor considera que el recurso ha sido modificado después del tiempo Si-Modificado-Desde, devolverá un cuerpo de respuesta 200 OK al cliente con un nuevo contenido de recurso, lo que significa "He modificado lo que desea y le daré usted una nueva. de".

2.2.2, HTTP/1.1
El mecanismo de almacenamiento en caché de HTTP/1.1 aumenta considerablemente la flexibilidad y la escalabilidad sobre la base de HTTP/1.0. El principio de funcionamiento básico sigue siendo el mismo que el de HTTP/1.0, pero se han agregado características más sutiles. Entre ellos, la característica más común en el encabezado de la solicitud es Cache-Control, consulte el documento web de MDN Cache-Control para obtener más información .
2.3 Método de conexión
HTTP/1.0 usa conexiones cortas de forma predeterminada , es decir, cada vez que el cliente y el servidor realizan una operación HTTP, se establece una conexión y la conexión finaliza cuando se completa la tarea. Cuando un HTML u otro tipo de página web a la que accede un navegador cliente contiene otros recursos web (como archivos JavaScript, archivos de imagen, archivos CSS, etc.), cada vez que se encuentra un recurso web de este tipo, el navegador recreará el A TCP conexión, esto dará como resultado una gran cantidad de "mensajes de protocolo de enlace" y "mensajes de onda" que ocupan el ancho de banda.
Para resolver el problema del desperdicio de recursos en HTTP/1.0, HTTP/1.1 está optimizado como el modo de conexión persistente predeterminado. El mensaje de solicitud que usa el modo de conexión larga notificará al servidor: "Le solicito una conexión y, después de que la conexión se haya establecido correctamente, no la cierre". Por lo tanto, la conexión TCP se mantendrá abierta para atender la posterior interacción de datos cliente-servidor. Es decir, en el caso de usar una conexión larga, cuando se abre una página web, la conexión TCP utilizada para transmitir datos HTTP entre el cliente y el servidor no se cerrará, y cuando el cliente acceda nuevamente al servidor, seguirá utilizando esta conexión establecida.
Si la conexión TCP se mantiene todo el tiempo, también es una pérdida de recursos, por lo que algunos software de servidor (como Apache) también admiten el tiempo de espera. La conexión TCP se cerrará si no llega ninguna nueva solicitud dentro del período de tiempo de espera.
Cabe señalar que HTTP/1.0 todavía ofrece una opción de conexión larga, que se agrega en el encabezado de la solicitud Connection: Keep-alive. De manera similar, en HTTP/1.1, si no desea utilizar la opción de conexión larga, también puede agregarla al encabezado de la solicitud Connection: close, lo que notificará al servidor: "No necesito una conexión larga y puede ser cerrado después de que la conexión sea exitosa".
La conexión larga y la conexión corta del protocolo HTTP son esencialmente la conexión larga y la conexión corta del protocolo TCP.
Para implementar una conexión persistente, tanto el cliente como el servidor deben admitir conexiones persistentes.
2.4, Procesamiento de encabezado de host
En HTTP1.0, se considera que cada servidor está vinculado a una dirección IP única, por lo tanto, la URL en el mensaje de solicitud no pasa el nombre de host (hostname). Pero con el desarrollo de la tecnología de host virtual, pueden existir múltiples hosts virtuales (servidores web multiubicados) en un servidor físico y comparten una dirección IP. Tanto los mensajes de solicitud HTTP1.1 como los mensajes de respuesta deben ser compatibles con el campo de encabezado de Host y, si no hay un campo de encabezado de Host en el mensaje de solicitud, se informará un error (400 Bad Request).
Supongamos que tenemos una URL de recurso http://example1.org/home.html, en el mensaje de solicitud HTTP/1.0, la solicitud será GET /home.html HTTP/1.0, es decir, no se agregará el nombre de host. Dicho mensaje se envía al servidor y el servidor no puede entender la URL real que el cliente desea solicitar.
Por lo tanto, HTTP/1.1 agregó el campo Host al encabezado de la solicitud. El encabezado del mensaje agregado al campo Host será:
GET /home.html HTTP/1.1
Host: example1.orgDe esta forma, el lado del servidor puede determinar la URL real que el cliente desea solicitar.
2.5 Optimización del ancho de banda
2.5.1 Solicitud de rango
HTTP/1.1 introdujo un mecanismo de solicitud de rango para evitar desperdiciar ancho de banda. Cuando el cliente desea solicitar una parte de un archivo, o necesita continuar descargando un archivo que se descargó pero finalizó, HTTP/1.1 puede agregar un encabezado a la solicitud para solicitar (y solo solicitar datos de bytes) la parte de datos Range. El lado del servidor puede ignorar Rangeel encabezado o devolver varias Rangerespuestas.
Si una respuesta contiene datos parciales, tendrá 206 (Partial Content)un código de estado. La importancia de este código de estado es evitar que la memoria caché del proxy HTTP/1.0 considere erróneamente la respuesta como una respuesta de datos completa, tratándola así como una memoria caché de respuesta para una solicitud.
En las respuestas de rango, Content-Rangelas banderas de encabezado indican el desplazamiento del bloque de datos y la longitud del bloque de datos.
2.5.2, código de estado 100
Los códigos de estado se agregaron recientemente en HTTP/1.1 100. El escenario de uso de este código de estado es que hay algunas solicitudes de archivos grandes y es posible que el servidor no esté dispuesto a responder a dichas solicitudes. En este momento, el código de estado se puede usar como una indicación de si 100la solicitud se responderá normalmente. . El proceso es el siguiente:


Sin embargo, en HTTP/1.0, no hay 100 (Continue)código de estado.Para activar este mecanismo, Expectse puede enviar un encabezado, que contiene un 100-continuevalor de .
2.5.3 Compresión
Los datos en muchos formatos se comprimen previamente durante la transmisión. La compresión de datos puede optimizar en gran medida la utilización del ancho de banda. Sin embargo, HTTP/1.0 no proporciona muchas opciones para la compresión de datos, no admite la selección de detalles de compresión y no puede distinguir entre compresión de extremo a extremo (end-to-end) o salto por salto (hop-by). -salto) compresión.
HTTP/1.1 hace una distinción entre codificaciones de contenido y codificaciones de transferencia. La codificación de contenido siempre es de extremo a extremo y la codificación de transferencia siempre es salto por salto.
HTTP/1.0 incluye el encabezado de codificación de contenido, que codifica el mensaje de principio a fin.
HTTP/1.1 agrega el encabezado Transfer-Encoding, que puede realizar la codificación de transferencia salto por salto en los mensajes.
HTTP/1.1 también agregó el encabezado Accept-Encoding, que el cliente usa para indicar qué codificación de contenido puede manejar.
2.6 Resumen
-
Método de conexión : HTTP 1.0 es una conexión corta, HTTP 1.1 admite una conexión larga.
-
Códigos de respuesta de estado : HTTP/1.1 ha agregado una gran cantidad de códigos de estado, incluidos 24 códigos de estado nuevos para respuestas de error.
Por ejemplo100 (Continue)... Solicitudes de calentamiento antes de solicitar grandes recursos206 (Partial Content)... Identificadores para solicitudes de rango409 (Conflict)... ····························· ···················410 (Gone). -
Procesamiento de caché : en HTTP1.0, If-Modified-Since y Expires en el encabezado se utilizan principalmente como criterios para el juicio de caché.HTTP1.1 introduce más estrategias de control de caché, como la etiqueta de entidad, If-Unmodified-Since, If- Match, If-None-Match y más encabezados de caché opcionales para controlar la estrategia de caché.
-
Optimización de ancho de banda y uso de conexiones de red : en HTTP1.0, hay algunos fenómenos de desperdicio de ancho de banda.Por ejemplo, el cliente solo necesita una parte de un objeto, pero el servidor envía el objeto completo y no admite la función de reanudación. HTTP1.1 introduce el campo de encabezado de rango en el encabezado de solicitud, lo que permite solicitar solo una parte determinada del recurso, es decir, el código de retorno es 206 (Contenido parcial), lo cual es conveniente para que los desarrolladores elijan libremente aprovechar al máximo el ancho de banda y las conexiones.
-
Procesamiento del encabezado del host : HTTP/1.1 agrega
Hostcampos al encabezado de la solicitud.
3. SPDY: Optimización de HTTP1.x
En 2012, Google propuso la solución SPDY como un trueno, que optimizó el retraso de solicitud de HTTP1.X y resolvió la seguridad de HTTP1.X, de la siguiente manera:
3.1 Reducir la latencia
Para resolver el problema de la alta latencia de HTTP, SPDY adopta elegantemente la multiplexación. La multiplexación resuelve el problema del bloqueo HOL al compartir una conexión tcp con múltiples flujos de solicitudes, reduce la latencia y mejora la utilización del ancho de banda.
3.2, prioridad de solicitud (priorización de solicitudes)
Un nuevo problema provocado por la multiplexación es que las solicitudes de clave pueden bloquearse sobre la base de compartir la conexión. SPDY permite establecer la prioridad para cada solicitud, de modo que las solicitudes importantes se respondan primero. Por ejemplo, cuando un navegador carga la página de inicio, primero se debe mostrar el contenido html de la página de inicio y luego se cargan varios archivos de recursos estáticos, archivos de script, etc., para que los usuarios puedan ver el contenido de la página web por primera vez.
3.3, compresión de encabezado
Como se mencionó anteriormente, los encabezados de HTTP1.x suelen ser redundantes. La elección de un algoritmo de compresión adecuado puede reducir el tamaño y la cantidad de paquetes.
3.4 Transmisión del protocolo de cifrado basado en HTTPS
La fiabilidad de la transmisión de datos se mejora considerablemente.
3.5, empuje del servidor (empuje del servidor)
Una página web que utiliza SPDY. Por ejemplo, mi página web tiene una solicitud de sytle.css. Cuando el cliente recibe los datos de sytle.css, el servidor enviará el archivo sytle.js al cliente. Cuando el cliente intente obtenerlo de nuevo, sytle .js se puede obtener directamente del caché, sin necesidad de enviar una solicitud. Diagrama de composición SPDY:

SPDY se encuentra bajo HTTP y por encima de TCP y SSL, por lo que puede ser fácilmente compatible con la versión anterior del protocolo HTTP (que encapsula el contenido de HTTP1.x en un nuevo formato de marco) y puede usar las funciones SSL existentes en el Mismo tiempo.
4. HTTP2.0: una versión mejorada de SPDY
Se puede decir que HTTP2.0 es una versión mejorada de SPDY (de hecho, se diseñó originalmente en base a SPDY), pero aún existen diferencias entre HTTP2.0 y SPDY, como se indica a continuación:
La diferencia entre HTTP2.0 y SPDY:
- HTTP2.0 admite la transmisión HTTP de texto sin formato, mientras que SPDY impone el uso de HTTPS
- El algoritmo de compresión del encabezado del mensaje HTTP2.0 usa HPACK en lugar de DEFLATE que usa SPDY
5. Nuevas características de HTTP2.0 en comparación con HTTP1.X
- El nuevo formato binario (Binary Format) , el análisis de HTTP1.x se basa en texto. El análisis de formato basado en el protocolo de texto tiene fallas naturales. La representación del texto es diversa y debe haber muchos escenarios por consideraciones de robustez. El binario es diferente y solo se reconoce la combinación de 0 y 1. Con base en esta consideración, el análisis del protocolo HTTP2.0 decidió utilizar el formato binario, que es conveniente y robusto de implementar.
- Multiplexación (MultiPlexing) , es decir, conexión compartida, es decir, cada solicitud se utiliza como un mecanismo de conexión compartida. Una solicitud corresponde a una identificación, por lo que puede haber múltiples solicitudes en una conexión, y las solicitudes de cada conexión se pueden mezclar aleatoriamente, y el receptor puede atribuir la solicitud a diferentes solicitudes de servidor según la identificación de la solicitud.
- La compresión de encabezado , como se mencionó anteriormente, tiene mucha información en el encabezado de HTTP1.x mencionado anteriormente, y debe enviarse repetidamente cada vez. HTTP2.0 usa un codificador para reducir el tamaño del encabezado que debe transmitirse , y cada parte en la comunicación almacena en caché una copia. La tabla de campos de encabezado no solo evita la transmisión de encabezados repetidos, sino que también reduce el tamaño que debe transmitirse.
- Server push (inserción del servidor) , como SPDY, HTTP2.0 también tiene una función de inserción del servidor.
6. Actualización y transformación de HTTP2.0
- Como se mencionó anteriormente, HTTP 2.0 en realidad no admite HTTPS, pero ahora los navegadores convencionales como Chrome y Firefox aún solo admiten el protocolo HTTP 2.0 basado en la implementación de TLS, por lo que es mejor actualizar a HTTPS primero si desea actualizar a HTTP 2.0 .
- Después de que su sitio web se haya actualizado a HTTPS, es mucho más fácil actualizar a HTTP2.0. Si usa NGINX, solo necesita habilitar el protocolo correspondiente en el archivo de configuración. Puede consultar el documento técnico de NGINX, Guía oficial de NGINX a Configuración de HTTP2.0 .
- Si usa HTTP2.0, ¿qué debe hacer con el HTTP1.x original? De hecho, no hay que preocuparse por este problema. HTTP2.0 es totalmente compatible con la semántica de HTTP1.x. Para los navegadores que no soporte HTTP2.0, NGINX automáticamente será compatible con versiones anteriores.
7. Notas
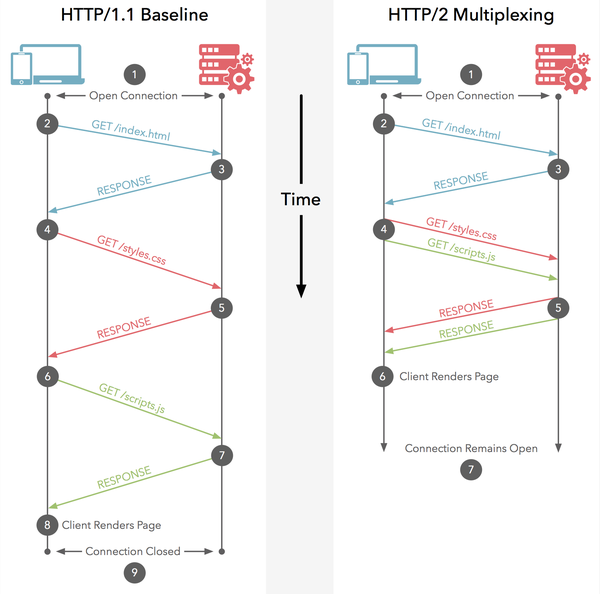
7.1 ¿Cuál es la diferencia entre la multiplexación de HTTP2.0 y la multiplexación de conexiones largas en HTTP1.X?
- HTTP/1.* Una solicitud-respuesta, establecer una conexión, cerrar cuando se agote, cada solicitud debe establecer una conexión;
- La solución a HTTP/1.1 Pipeling es que varias solicitudes se ponen en cola y se serializan para el procesamiento de un solo subproceso, y las solicitudes posteriores esperan el regreso de las solicitudes anteriores para obtener una oportunidad de ejecución. Una vez que se agota el tiempo de espera de una solicitud, las solicitudes posteriores solo se pueden bloquear, y no hay manera Es decir, la gente suele decir que el final de la línea está bloqueado;
-
Se pueden ejecutar múltiples solicitudes HTTP/2 en paralelo en una conexión al mismo tiempo. Una determinada tarea de solicitud lleva mucho tiempo y no afectará la ejecución normal de otras conexiones;
Específicamente como se muestra en la figura:
7.2 ¿ Qué es exactamente el push del servidor?
La inserción del lado del servidor puede enviar los recursos requeridos por el cliente al cliente junto con el index.html, eliminando la necesidad de que el cliente solicite repetidamente. Solo porque no hay operaciones como iniciar una solicitud o establecer una conexión, la velocidad de los recursos estáticos se puede mejorar en gran medida al enviarlos a través del servidor. detalles de la siguiente manera:
7.2.1 Proceso de solicitud de clientes ordinarios
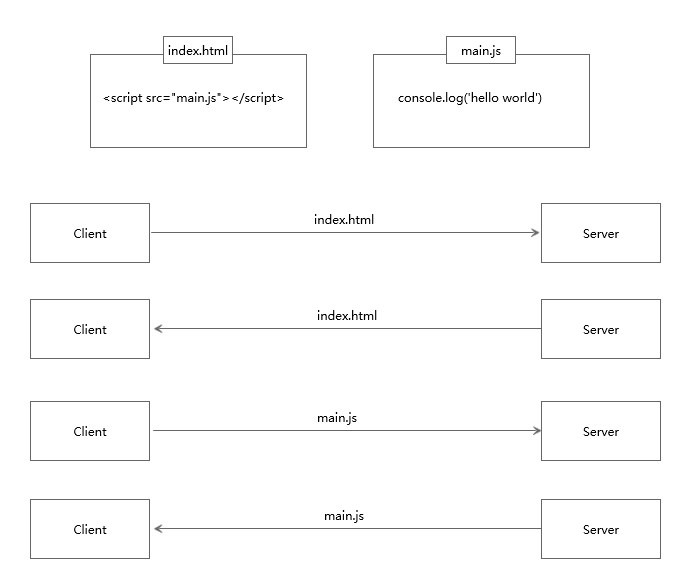
7.2.2 El proceso de inserción del servidor

7.3 ¿ Por qué es necesaria la compresión de cabecera?
Suponga que una página tiene 100 recursos para cargar (esta cantidad es bastante conservadora para la Web de hoy), y cada solicitud tiene un encabezado de mensaje de 1 kb (esto tampoco es poco común, debido a cosas como cookies y referencias), necesita consumir en menos 100kb más para obtener estos encabezados de mensajes. HTTP 2.0 puede mantener un diccionario y actualizar encabezados HTTP en pequeños incrementos, lo que reduce en gran medida el tráfico generado por la transmisión de encabezados. Referencia específica: Introducción a la tecnología de compresión de encabezados HTTP/2
7.4 ¿Qué tan buena es la multiplexación HTTP2.0?
La clave para la optimización del rendimiento de HTTP no es un gran ancho de banda, sino una baja latencia. Una conexión TCP se "sintoniza" a sí misma con el tiempo, limitando inicialmente la velocidad máxima de la conexión y aumentando la velocidad con el tiempo si los datos se transmiten con éxito. Este ajuste se denomina inicio lento de TCP. Por esta razón, las conexiones HTTP, que ya son a ráfagas y de corta duración, se vuelven muy ineficientes.
HTTP/2 permite un uso más eficiente de las conexiones TCP al permitir que todos los flujos de datos compartan la misma conexión, por lo que el ancho de banda alto también puede mejorar realmente el rendimiento de HTTP.
8, referencia
¿Cuáles son las principales mejoras de HTTP/2.0 en comparación con 1.0?
Investigación en profundidad: ¿Cuál es el rendimiento real de HTTP2?
Introducción a la tecnología de compresión de encabezados HTTP/2