1. Descripción general del lenguaje de definición de datos
1.1 Métodos de desarrollo comunes
(1) CLI de Hive, CLI de Beeline
El cliente de línea de comandos que viene con Hive
Ventajas: no se requiere instalación adicional
Desventajas: el entorno para escribir SQL es duro, sin indicaciones efectivas, sin resaltado de sintaxis y una alta tasa de operaciones incorrectas
(2) Algunos editores de texto
como Sublime, Emacs y EditPlus
no admiten la conexión a los servicios de Hive como clientes, pero admiten el entorno de sintaxis SQL, luego desarrollan SQL en el editor y lo copian en la CLI de Hive para su ejecución; algunos admiten la instalación de complementos. ins como clientes Conexión directa al servicio Hive;
(3) Herramientas de visualización de Hive
IntelliJ IDEA, DataGrip, Dbeaver, SQuirrel SQL Client, etc.
Herramientas de interfaz gráfica que pueden conectarse a HiveServer2 a través de JDBC en plataformas Windows y MAC
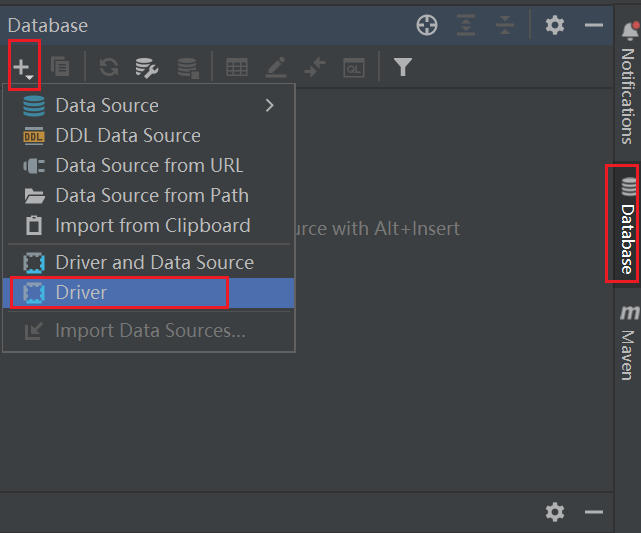
Herramienta de visualización de Hive IntelliJ IDEA
-
Configure la fuente de datos de Hive
En cualquier proyecto de IDEA, configure el controlador Hive Driver antes de seleccionar la configuración estándar de la base de datos
.

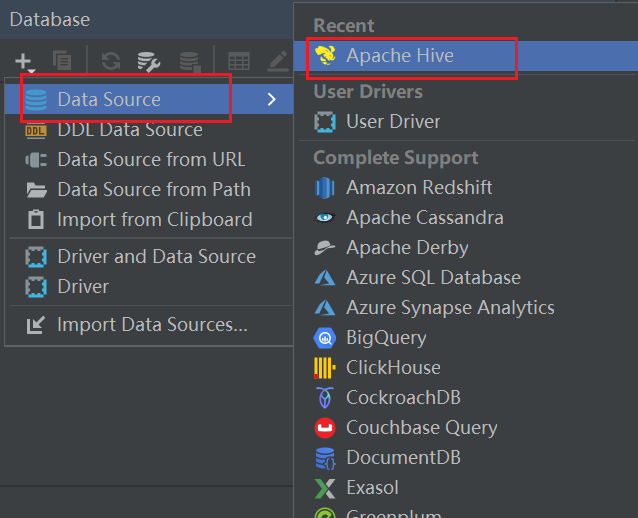
-
Configure la fuente de datos
Configure la fuente de datos de Hive y conéctese a la
fuente de datos de configuración HS2

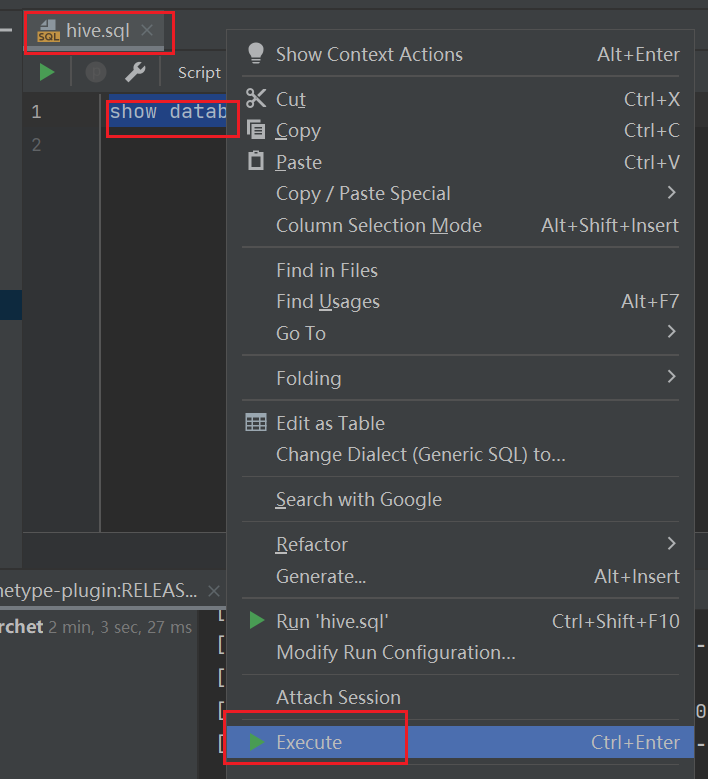
-
Hive usa visualmente para
escribir código, seleccione el código que se ejecutará y haga clic derecho para ejecutar
1.2 Descripción general de DDL
El papel de la sintaxis DDL en el lenguaje de definición de datos SQL es el lenguaje utilizado para crear, eliminar y modificar la estructura del objeto
dentro de la base de datos en el lenguaje SQL . La sintaxis central de DDL consta de CREATE, ALTER y DROP. DDL no involucra la operación de los datos internos de la tabla.
El uso de la sintaxis DDL en Hive La
sintaxis de Hive SQL es similar a la de SQL estándar, y son básicamente lo mismo Basado
en el diseño y las características de uso de Hive, la sintaxis de creación (especialmente la creación de tablas) en HQL será la lo más importante para aprender y dominar la sintaxis de Hive DDL
Enfoque: árbol de sintaxis completo
HIVE DDL CREATE TABLE
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)[SORTED BY (col_name[ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value, ...)]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
1.3 Explicación detallada de los tipos de datos de Hive
El tipo de datos de Hive se refiere al tipo de campo de la columna en la tabla. Se
divide en dos categorías: tipo de datos nativos y tipo de datos complejos.
Tipo de datos nativos: tipo numérico, tipo de hora y fecha, tipo de cadena, tipo de datos misceláneos
. Complejo tipo de datos: matriz de matriz, mapeo de mapas, estructura de estructura, unión de unión
Precauciones
- En Hive SQL, el tipo de datos en letras y mayúsculas en inglés no está claro
- Además de los tipos de datos SQL, también se admiten los tipos de datos Java, como string string
- El uso de tipos de datos complejos generalmente debe usarse junto con la sintaxis de especificación del delimitador
- Si el tipo de datos definido no es coherente con el archivo, Hive intentará realizar la conversión implícitamente, pero no se garantiza el éxito.
La conversión del tipo de visualización utiliza la función CAST, como CAST('100' as INT), pero si la conversión falla, se devolverá un valor nulo.
1.4 Mecanismo de archivo de lectura y escritura de Hive
SerDe
- SerDe es la abreviatura de Serializer and Deserializer, que se utiliza para serialización y deserialización.
- El proceso de convertir objetos en bytecodes durante la serialización y el proceso de convertir bytecodes en objetos durante la deserialización
- Hive usa SerDe (incluido FileFormat) para leer y escribir filas de tablas. Cabe señalar que la parte "clave" se ignora al leer, y la clave siempre es una constante al escribir. Básicamente, los objetos de fila se almacenan en "valor".
Read:
HDFS files -> InputFileFormat -> <key,value> -> Deserializer -> Deserializer(反序列化) -> Row object
Write:
Row object -> Serializer(序列化) -> <key,value> -> OutputFileFormat -> HDFS files
Sintaxis relacionada con SerDe
FORMATO DE FILA Esta línea representa la sintaxis relacionada con la lectura y escritura de archivos y la serialización de SerDe. Tiene dos funciones:
1. Qué clase de SerDe usar para la serialización 2. Cómo especificar el separador
[ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value, ...)]
Elija uno de DELIMITED y SERDE. Si usa delimitado, puede usar la clase LazySimpleSerDe predeterminada para procesar datos; si el formato del archivo de datos es especial, puede usar ROW FORMAT SERDE serde_name para especificar otras clases de Serde para procesar datos, e incluso admitir Clases SerDe definidas por el usuario.
El delimitador LazySimpleSerDe especifica que
LazySimpleSerDe es la clase de serialización predeterminada de Hive y contiene 4 sintaxis de neutrones, que se usan para especificar los símbolos delimitadores entre campos, entre elementos de colección, entre kv de mapeo de mapas y líneas nuevas. Al construir una tabla, se puede usar de manera flexible de acuerdo con las características de los datos
ROW FORMAT DELIMITED
[FIELDS TERMINATED BY char] ——> 字段之间分隔符
[COLLECTION ITEMS TERMINATED BY char] ——> 集合元素之间分隔符
[MAP KEYS TERMINATED BY char] ——> Map映射kv之间分隔符
[LINES TERMINATED BY char] ——> 行数据之间分隔符
Delimitador predeterminado de Hive : el delimitador predeterminado es '\001', que utiliza un valor codificado en ASCII, que no se puede escribir con el teclado.
Ingrese continuamente ctrl+v/ctrl+a en el editor vim para ingresar '\001', que se mostrará ^A
en forma de miles de millones de SOH en algunos editores de texto
Especificar la ruta de almacenamiento
- Cuando Hive crea una tabla, puede usar la sintaxis de ubicación para cambiar la ruta de almacenamiento de datos en HDFS, lo que hace que sea más flexible cargar datos al crear una tabla.
- Sintaxis: LOCATION '<ubicación_hdfs>'
- Para los archivos de datos que se han generado, será conveniente utilizar la ubicación para especificar la ruta
[LOCATION hdfs_path]
2. Sintaxis básica de creación de tablas Hive SQL
2.1 Ejercicio de sintaxis de creación de tablas Hive
2.1.1 Uso de tipos de datos nativos
El nombre del archivo es archer.txt, que registra la información relevante del tirador King of Glory, incluida la vida, la defensa física, etc., donde el separador entre campos es un carácter de tabulación \t, que requiere que la tabla se mapee correctamente en Colmena.
数据示例:
1 马可波罗 5584 200 362 remotely archer
show database;
-- 切换数据库
use testdb;
-- 建表
create table t_archer(
id int comment "ID",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最高物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
) comment "王者荣耀射手信息"
row format delimited
fields terminated by "\t";
-- 删除表
drop table t_archer;
2.1.2 Uso de tipos de datos complejos
El nombre de archivo hot_hero_skin_price.txt registra la información relevante del precio de la máscara del popular juego móvil Glory of Kings, y es necesario para crear una tabla en Hive y mapear correctamente este archivo.
数据示例:字段:id、name(英雄名称)、win_rate(胜率)、skin_price(皮肤及价格)
2,鲁班七号,54,木偶奇遇记:288-福禄兄弟:288-兄控梦想:0
3,铠,52,龙域领主:288-曙光守护者:1776
Análisis: los primeros tres campos son tipos de datos nativos y el último campo es un mapa de tipo complejo
-- 复杂数据类型建表
create table t_hot_hero_skin_price(
id int,
name string,
win_rate int,
skin_price map<string,int> -- 注意这个map复杂类型
) row format delimited
fields terminated by ',' -- 指定字段之间的分隔符
collection items terminated by '-' -- 指定元素集合之间的分隔符
map keys terminated by ':'; -- 指定map元素kv之间的分隔符
2.1.3 Uso del delimitador predeterminado
El nombre del archivo es team_ace_player.txt, que registra la información de los jugadores as más populares del equipo principal. Los campos están separados por \001, lo que requiere que la tabla se mapee correctamente en Hive.
数据示例:
1^A成都AG超会玩^A一诺
Análisis: todos los datos son tipos de datos nativos y el separador entre campos es \001, por lo que la declaración de formato de fila se puede omitir incluso si la tabla está construida
create table t_team_ace_player(
id int,
team_name string,
ace_player_name string
); -- 没有指定row format语句,此时采用的是默认的\001作为字段的分隔符
2.1.4 Especificar la ruta de almacenamiento de datos
El nombre del archivo es team_ace_player.txt, que registra la información de los jugadores as más populares del equipo principal. El campo usa \001 como delimitador. Es necesario cargar el archivo en cualquier ruta en HDFS. No se puede mover y copiado, y debe crearse en Hive. La asignación de tablas es correcta para el archivo
create table t_team_ace_player(
id int,
team_name string,
ace_player_name string
) location '/date'; -- 使用location关键字指定本张表在hdfs上的存储路径
2. Colmena adentro, mesa afuera
Tablas internas
Las tablas internas también se denominan tablas administradas que pertenecen y son administradas por Hive.
De manera predeterminada, todas las tablas creadas son tablas internas. Hive posee la estructura y los archivos de la tabla (Hive administra completamente el ciclo de vida de la tabla), y los datos y las tablas se eliminarán cuando se eliminen Metadatos
Puede usar DESCRIBE FORMATTED tablename para obtener la información de descripción de metadatos de la tabla, desde la cual puede ver el tipo de tabla
Tabla externa
Hive no posee ni administra los datos de la tabla externa, solo se administra el ciclo de vida de los metadatos de la tabla. Use la
palabra clave EXTERNAL para crear una tabla externa. Eliminar una
tabla externa solo eliminará los metadatos, pero no los datos
La tabla externa se especifica con la sintaxis de ubicación La ruta de datos es más segura
-- 创建外部表 需要关键字external
-- 外部表数据存储路径不指定 默认规则和内部表一致
-- 也可以使用location关键字指定HDFS任意路径
create external table student_ext(
num int,
name string,
sex string,
age int,
dept string
)row format delimited
fields terminated by ','
location '/stu';
Cómo elegir tablas internas y externas
Cuando necesite administrar y controlar por completo el ciclo de vida completo de la tabla a través de Hive, utilice la tabla interna
Cuando los datos sean difíciles de obtener y evite la eliminación accidental, utilice la tabla externa, porque incluso si se elimina la tabla, el archivo se conservará
El papel de la palabra clave de ubicación
- Al crear una tabla externa, puede usar la ubicación para especificar la ruta de la ubicación de almacenamiento. ¿Qué sucede si no la especifica?
- Si no se especifica la ubicación, la ruta predeterminada de la tabla externa también se encuentra en /usr/hive/warehouse, que está controlada por los parámetros predeterminados.
- Al crear una tabla interna, ¿se puede especificar la ubicación?
- Las tablas internas pueden usar la ubicación para especificar la ubicación
- ¿Significa que la ubicación de los datos de la tabla de Hive en HDFS no debe estar en /usr/hive/warehouse?
- No necesariamente, la ubicación de almacenamiento de los datos de la tabla en Hive, sin importar la tabla interna o la tabla externa, está en /usr/hive/warehouse de manera predeterminada. Por supuesto, puede usar la palabra clave de ubicación para especificar la ubicación de almacenamiento en cualquier lugar. ubicación en HDFS al crear la tabla.
3. Tabla de particiones
3.1 Antecedentes de generación de tablas de particiones
Actualmente hay 6 capítulos de archivos de datos estructurados, que registran respectivamente la información del héroe en las 6 posiciones en la gloria del rey. Ahora se requiere mapear y cargar los 6 archivos al mismo tiempo creando una tabla t_all_hero
Simplemente cree la tabla t_all_hero y luego copie las 6 tablas en la ruta especificada.
Ahora se requiere consultar el número de tiradores cuando role_main está posicionado principalmente y la vida máxima de hp_max es superior a 6000. La declaración sql es la siguiente
select count(*) from t_all_hero where role_main="archer" and hp_max>6000;
Problemas existentes:
- Detrás de la instrucción where, se requiere un escaneo completo de la tabla para filtrar los resultados. Para hive, se debe escanear cada archivo. Si hay muchos archivos de datos, la eficiencia del escaneo es muy lenta y no es necesario
- En este requisito, solo escanee el archivo archer.txt
- Hay diferencias en la eficiencia entre los escaneos de archivos específicos y los escaneos de tablas completas.
Concepto de tabla de particiones
Cuando la tabla de Hive corresponde a una gran cantidad de datos y una gran cantidad de archivos, para evitar escanear los datos en toda la tabla durante la consulta, Hive admite la partición de la tabla de acuerdo con campos específicos. identificado por fecha, región, tipo, etc. campo de significado
-- 注意分区表创建语法规则
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
role_main string,
role_assist string
) partitioned by (role string) -- 分区字段
row format delimited
fields terminated by "\t";
Nota: El campo de partición no puede ser un campo existente en la tabla , porque el campo de partición finalmente se mostrará en la estructura de la tabla en forma de campo virtual.
3.2 Carga de datos de la tabla de particiones: partición estática
Partición estática
La denominada partición estática significa que el usuario especifica manualmente el valor del atributo de la partición al cargar los datos.
La sintaxis es la siguiente
load data [local] inpath 'filepath' into table tablename partition(分区字段='分区值'...);
El parámetro Local se utiliza para especificar si los datos que se cargarán se encuentran en el sistema de archivos local o en el sistema de archivos HDFS.
-- 静态加载分区表数据
load data local inpath '/root/hivedata/archer.txt' into table t_all_hero_part partition(role='sheshou');
load data local inpath '/root/hivedata/assassin.txt' into table t_all_hero_part partition(role='cike');
...
Naturaleza
- El concepto de partición proporciona una forma de separar los datos de la tabla de Hive en varios archivos/directorios.
- Diferentes particiones corresponden a diferentes carpetas, y los datos de la misma partición se almacenan en la misma carpeta
- Al consultar y filtrar, solo necesita encontrar la carpeta correspondiente de acuerdo con el valor de la partición y escanear los archivos en esta partición debajo de la carpeta para evitar el escaneo completo de datos de la tabla.
- Esta forma de especificar consultas de partición se denomina poda de partición.
3.3 Tablas de particiones múltiples
A partir de la sintaxis relevante sobre las particiones en la declaración de creación de tablas, se puede encontrar que Hive admite varios campos de partición:
PARTICIONADO POR (tipo_datos_partición1, tipo_datos_partición2,...)
En particiones múltiples, hay una relación progresiva entre particiones, que puede entenderse como el anterior Continuar particionando sobre la base de una partición
Desde la perspectiva de HDFS, es continuar dividiendo subcarpetas debajo de la carpeta.
-- 单分区表,按身份分区
create table t_user_province (id int, name string, age int) partitiond by (province string);
-- 双分区表,按省份和市分区
-- 分区字段之间时一种递进的关系,因此要注意分区字段的顺序
create table t_user_province_city (id int, name string, age int) partitiond by (province string, city string);
-- 双分区表的数据加载 静态分区加载数据
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city partition(province='zhejiang', city='hangzhou');
...
-- 双分区表的使用,使用分区进行过滤 减少全表扫描 提高效率
select * from t_user_province_city where province='zhejiang' and city='hangzhou';
3.4 Carga de datos de la tabla de particiones: partición dinámica
Partición dinámica
Partición dinámica significa que el valor del campo de la partición se deduce automáticamente en función del resultado de la consulta (posición del parámetro).
Sintaxis básica: insertar+seleccionar
Para habilitar la partición dinámica de colmena, se deben configurar dos parámetros en la pintura de colmena:
# 是否启用动态分区功能
set hive.exec.dynamic.partition=true;
# 指定动态分区模式,分别为nonstrict非严格模式和strict严格模式
# strict严格模式要求至少由一个分区为静态分区
set hive.exec.dynamic.partition.mode=nonstrict;
-- 从一张已有的表中执行动态分区插入
insert into table t_all_hero_part_dynamic partition(role) -- 注意:分区值并没有手动写死指定
select tmp.*, tmp.role_main from t_all_hero tmp;
4. Mesa de cubo
Concepto
Una tabla de cubos también se denomina tabla de cubos, que es un tipo de tabla diseñada para la optimización de consultas. El
archivo de datos correspondiente a la tabla de cubos se descompondrá en varias partes en la capa inferior.
Al agrupar, debe especificar qué campo dividir los datos en varios depósitos.
Reglas
Las reglas de almacenamiento en depósitos son las siguientes: los datos con el mismo número de depósito se asignarán al mismo depósito
Bucket number=hash_function(bucketing_column) mod num_buckets
分桶编号 =哈希方法 (分桶字段) 取模 分桶个数
hash_function depende del tipo de bucketing_column:
- Si es de tipo int, hash_function(int) == int;
- Si es otro tipo de datos, como bigint, cadena o complejo, la función hash es complicada, será un cierto número derivado de este tipo, como el valor del código hash
gramática
-- 分桶表建表语句
CREATE [EXTERNAL] TABLE [db_name.]table_name
[(col_name data_type,...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;
CLUSTERED BY (col_name) significa según qué campo;
INTO N BUCKETS significa dividido en varios cubos
Nota: El campo para agrupar debe ser un campo existente en la tabla
Creación de la tabla de cubos
Estados Unidos existentes 2021-1-28, la información acumulada de casos de la nueva situación epidémica en cada condado, incluidos los casos confirmados y las muertes.
数据示例:包含字段count_date(统计日期),county(县),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)
2021-01-28,Jefferson,Alabama,01073,65992,1101
...
Los datos se dividen en 5 cubos según el estado, y la declaración de creación de la tabla es la siguiente:
CREATE TABLE itheima.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
) CLUSTERED BY(state) INTO 5 BUCKETS;
Al crear una tabla de depósito, también puede especificar las reglas de clasificación de datos en el depósito:
-- 根据state州分为5桶,每个桶内根据cases确诊病例数倒序排序
CREATE TABLE itheima.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
) CLUSTERED BY(state)
sorted by (cases desc) INTO 5 BUCKETS;
Carga de datos de la tabla de cubos
-- step1:开启分桶的功能 从Hive2.0开始不再需要设置
set hive.enforce.bucketing=true;
-- step2:把数据加载到普通hive表
drop table if exists t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
) row format delimited fields terminated by ",";
-- 将源数据上传到HDFS,t_usa_covid19表对应的路径下
hadoop fs -put 源数据 目标路径
-- step3:使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket select * from t_usa_covid19;
beneficio
- Reduzca los escaneos de tablas completos al realizar consultas basadas en campos agrupados
-- 基于分桶字段state查询来自于New York州的数据
-- 不再需要进行全表扫描过滤
-- 根据分桶的规则hash_function(New York) mod 5 计算出分桶编号
-- 查询指定分桶里面的数据
select * from t_usa_covid19_bucket where state="New York";
-
Cuando JOIN, puede mejorar la eficiencia de los programas MR y reducir la cantidad de productos cartesianos, y
realizar operaciones de almacenamiento en la tabla de acuerdo con los campos de la combinación. -
Muestreo eficiente de datos de tablas agrupadas
Cuando la cantidad de datos es particularmente grande y es difícil procesar todos los datos, el muestreo es particularmente importante. El muestreo puede estimar e inferir las características de la población a partir de los datos muestreados.
5. Tabla de transacciones
limitación
- Todavía no se admiten BEGIN, COMMIT y ROLLBACK. Todas las operaciones lingüísticas se envían automáticamente
- Solo admite el formato de archivo ORC (ALMACENADO COMO ORC)
- Las transacciones están desactivadas de forma predeterminada. Necesidad de configurar parámetros para habilitar el uso
- La tabla debe ser una tabla de cubo para usar la función de transacción
- El parámetro de la tabla transaccional debe ser verdadero
- Las tablas externas no pueden ser tablas ACID, no se permite leer/escribir en tablas ACID desde sesiones que no sean ACID
Cree y use la tabla de transacciones de Hive
Cree una tabla con la función de transacción en Hive e intente agregar, eliminar y modificar
-- Hive 事务表
-- step1,创建普通的表
drop table if exists student;
create table student(
num int,
name string,
sex string,
age int,
dept string
) row format delimited
fields terminated by ',';
-- step2:加载数据到普通表中
load data local inpath '/root/hivedata/student.txt' into table student;
select * from student;
-- Hive中事务表的创建使用
-- 1.开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; -- Hive是否支持并发
set hive.enforce.bucketing = true; -- 从Hive2.0开始就不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; -- 动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true; -- 是否在Metastore实例上运行启动线程和清理线程
set hive.compactor.worker.threads = 1; -- 在此metastore实例上运行多个压缩程序工作线程
-- 2.创建Hive事务表
create table trans_student(
id int,
name string,
age int
) clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
--注意:事务表创建几个要素:开启参数、分桶、存储格式orc、表属性
-- 3.针对事务表进行insert update delete操作
insert into trans_student values(1,"allen",18);
6. Ver
concepto
- Una vista en Hive es una tabla virtual que solo guarda la definición y no almacena los datos.
- Las vistas generadas generalmente se crean a partir de consultas de tablas físicas reales, y también se pueden crear nuevas vistas a partir de vistas existentes.
- El esquema de la vista se congela cuando se crea la vista y deja de ser válido si las tablas subyacentes se descartan o modifican.
- Las vistas se utilizan para simplificar las operaciones, no almacenar registros en búfer y no mejorar el rendimiento de las consultas.
-- Hive View 视图相关语法
-- hive中有一张真实的基础表t_usa_covid19
select * from t_usa_covid19;
-- 1.创建视图
create view v_usa_covid19 as select count_date, county, state, deaths from t_usa_covid19 limit 5;
-- 能否从已有的视图中创建视图 可以的
create view v_usa_covid19_from_view as select * from v_usa_covid19 limit 2;
-- 2.显示当前已有的视图
show tables;
show views; -- hive v2.2.0之后支持
-- 3.视图的查询使用
select * from v_usa_covid19;
-- 注意:视图不支持插入数据
-- 4.查看视图定义
show create table v_usa_covid19;
-- 5.删除视图
drop view v_usa_covid19_from_view;
-- 6.更改视图属性
alter view v_usa_covid19 set TBLPROPERTIES ('comment' = 'This is a view');
-- 7.更改视图定义
alter view v_usa_covid19 as select county, deaths from t_usa_covid19 limit 2;
Beneficios de las vistas
- Proporcione datos de columna específicos en la tabla real a los usuarios para proteger la privacidad de los datos
-- 通过视图来限制数据访问可以用来保护信息不被随意查询
create table userinfo(firstname string, lastname string, ssn string, password string);
create view safer_user_info as select firstname,lastname from userinfo;
-- 可以通过where子句限制数据访问,比如,提供一个员工表视图,只暴露来自特定部门的员工信息
create table employee(firstname string, lastname string, ssn string, password string, department string);
create view techops_employee as select firstname, lastname, ssn from userinfo where department='java';
- Reduzca la complejidad de las consultas y optimice las declaraciones de consulta
-- 使用视图优化嵌套查询
from(
select * from people join cart
on(cart.people_id = people.id) where firstname = 'join'
) a select a.lastname where a.id = 3;
-- 把嵌套子查询变成一个视图
create view shorter_join as
select * from people join cart
on(cart.people_id = people.id) where firstname = 'join';
-- 基于视图查询
select lastname from shorter_join where id = 3;
7. Nueva función de Hive3.0: vista materializada
concepto
- Una vista materializada es un objeto de base de datos que incluye resultados de consultas, que se puede usar para calcular previamente y guardar los resultados de operaciones que consumen mucho tiempo, como uniones de tablas o agregaciones. Al ejecutar la consulta, se pueden evitar estas operaciones que consumen mucho tiempo y los resultados se pueden obtener rápidamente
- El propósito de usar vistas materializadas es mejorar el rendimiento de las consultas a través del cálculo previo, lo que por supuesto requiere una cierta cantidad de espacio de almacenamiento.
- Hive3.0 comenzó a intentar introducir vistas materializadas y proporcionar un mecanismo automático de reescritura de consultas para vistas materializadas (implementado en base a Apache Calcite)
- La vista materializada de Hive también proporciona un mecanismo de selección de almacenamiento de vista materializada, que puede almacenarse localmente en Hive o almacenarse en otros sistemas a través de controladores de almacenamiento definidos por el usuario.
- El propósito de Hive al introducir vistas materializadas es optimizar la eficiencia del acceso a las consultas de datos, lo que equivale a optimizar el acceso a los datos desde la perspectiva del preprocesamiento de datos.
- Hive eliminó el soporte de sintaxis de índice de 3.0 y recomienda usar vistas materializadas y formatos de archivo de almacenamiento en columnas para acelerar las consultas
La diferencia entre vista materializada y vista.
- Las vistas son virtuales y existen lógicamente, solo las definiciones no almacenan datos
- Las vistas materializadas son reales, se almacenan físicamente y almacenan y calculan datos en ellas
- El propósito de la vista es simplificar y reducir la complejidad de la consulta, mientras que el propósito de la vista materializada es mejorar el rendimiento de la consulta.
gramática
-- 物化视图的创建语法
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name
[DISABLE REWRITE]
[COMMENT materialized_view_comment]
[PARTITIONED ON (col_name, ...)]
[CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)]
[
[ROW FORMATE row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES(property_name=property_value, ...)]
AS SELECT ...;
(1) Después de que se crea la vista materializada, los datos de ejecución del desenredado seleccionado se aterrizarán automáticamente. "Automático" significa que durante la ejecución de la consulta, ningún usuario podrá ver la vista materializada, y la vista materializada no estar disponible después de que se complete la ejecución; (2) De forma
predeterminada En algunos casos, la vista materializada creada se puede usar para reescribir la consulta del optimizador de consultas.Durante la creación de la vista materializada, se puede deshabilitar configurando el parámetro DISABLE PEWRITE. (3
) El SerDe y el formato de almacenamiento predeterminados son hive. materializedview.serde, hive.materializedview.fileformat;
(4) La vista materializada admite el almacenamiento de datos en sistemas externos (como druid), y la sintaxis es la siguiente:
CREATE MATERIALIZED VIEW druid_wiki_mv
STORED AS 'org.apache.hadoop.hive.druid.DruidStorageHandler'
AS
SELECT __time,page.user,c_added,c_removed
FROM src;
(5) Actualmente se admiten las operaciones de colocación y visualización de vistas materializadas, y se agregarán otras operaciones en el futuro.
-- Drops a materialized view
DROP MATERIALIZED VIEW [db_name.]materialized_view_name;
-- Shows materialized views (with optional filters)
SHOW MATERIALIZED VIEW [IN database_name];
-- Shows information about a specific materialized view
DESCRIBE [EXTENDED | FORMATTED] [db_name.]materialized_view_name;
(6) Cuando la fuente de datos cambia (nuevos datos insertados, datos modificados modificados), la vista materializada también debe actualizarse para mantener la consistencia de los datos. Actualmente, el usuario debe activar activamente la reconstrucción de reconstrucción.
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
Reescritura de consultas basada en vistas materializadas
- Una vez que se crea la vista materializada, se puede usar para acelerar las consultas relacionadas, es decir, si el usuario envía una consulta, si la consulta puede alcanzar la vista materializada existente después de volver a escribir, el resultado se devolverá directamente a través de la consulta de la vista materializada. datos para lograr la aceleración de consultas
- El parámetro global puede controlar si reescribir la consulta para usar la vista materializada, el valor predeterminado es verdadero: hive.materializedview.rewrite=true;
- Los usuarios pueden controlar selectivamente el mecanismo de reescritura de consulta de vista materializada especificado, la sintaxis es la siguiente
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name ENABLE|DISABLE REWRITE;
Caso: Reescritura de consulta basada en vistas materializadas
-- 1.新建一张事务表 student_trans
set hive.support.concurrency = true; -- Hive是否支持并发
set hive.enforce.bucketing = true; -- 从Hive2.0开始就不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; -- 动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动线程和清理线程
set hive.compactor.worker.threads= 1 -- 在此metastore实例上运行多少个压缩程序工作线程
drop table if exists student_trans;
CREATE TABLE student_trans(
sno int,
sname string,
sdept string
) clustered by (sno) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
-- 2.导入数据到student_trans中
insert overwrite table student_trans
select num,name,dept
from student;
select *
from student_trans;
-- 3.对student_trans建立聚合物化视图
CREATE MATERIALIZED VIEW student_trans_agg
AS SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
-- 注意:这里当执行CREATE MATERIALIZED VIEW,会启动一个MR对物化视图进行构建
-- 可以发现当下数据库中有一个物化视图
show tables;
show materialized views;
-- 4.对于原始表student_trans拆线呢
-- 由于会命中物化视图,重写query查询物化视图,查询速度会加快(没有启动MR,只是普通的table scan)
SELECT sdept,count(*) as sdept_cnt from student_trans group by sdept;
-- 5.查询执行计划可以发现 查询被自动重写为 TableScan alias
-- 转化成了物化视图的查询 提高了查询效率
explain SELECT sdept,count(*) as sdept_cnt from student_trans group by sdept;
-- 验证禁用物化视图自动重写
ALTER MATERIALIZED VIEW student_trans_agg DISABLE REWRITE;
-- 删除物化视图
drop materialized view student_trans_agg;
8. Operación DDL de Hive Database|Schema (base de datos)
Resumen general
- En Hive, el concepto de DATABASE es similar a RDBMS, llamado base de datos, DATABASE y SCHEMA son intercambiables y se pueden usar
- La base de datos predeterminada se llama predeterminada y los datos almacenados se encuentran en /user/hive/warehouse
- La ubicación de almacenamiento de la base de datos creada por el usuario es /user/hive/warehouse/database_name.db
create database
se usa para crear una nueva base de datos
COMENTARIO: la declaración de descripción de comentario de la base de datos
UBICACIÓN: especifica la ubicación de almacenamiento de la base de datos en HDFS, el valor predeterminado /user/hive/warehouse/dbname.db
WITH DBPROPERTIES: se usa para especificar la propiedad configuración de algunas bases de datos
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name = property_value, ...)];
describe la base de datos
muestra información como el nombre de la base de datos en Hive, el comentario (si está configurado) y su ubicación en el sistema de archivos. La
palabra clave EXTENDIDA se usa para mostrar más información. La palabra clave describe se puede abreviar como desc
语法:
DESCRIBE DATABASE|SCHEMA [EXTENDED] db_name;
usar base de datos
Seleccione una base de datos específica
para cambiar qué base de datos se usa para la sesión actual
descartar base de datos
El
comportamiento predeterminado es RESTRINGIR, lo que significa que la base de datos solo se elimina si está vacía.
Para soltar una base de datos con tablas (no vacías), podemos usar CASCADE
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
alterar la base de datos
cambia los metadatos asociados con una base de datos en Hive
-- 更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name = property_value, ...);
-- 更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER USER user;
-- 更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
-- 创建数据库
create database if not exists test
comment "this is test db"
with dbproperties('createdBy'='Allen');
-- 描述数据库信息
describe database test;
describe database extended test;
desc database extended test;
-- 切换数据库
use default;
use test;
-- 删除数据库
-- 注意:CASCADE关键字谨慎使用
drop database test;
9. Hive Table (tabla) Operación DDL
Resumen general
- Se puede decir que las operaciones DDL para tablas en Hive son las operaciones principales en DDL, incluida la creación de tablas, la modificación de tablas, la eliminación de tablas y la descripción de la información de metadatos de la tabla.
- Entre ellos, la declaración de creación de tablas es el núcleo del núcleo, consulte la declaración de creación de tablas Hive DDL para obtener más información.
- Se puede decir que si la definición de la tabla es exitosa afecta directamente el mapeo exitoso de los datos y luego afecta si Sun Li puede usar Hive para llevar a cabo el análisis de datos.
- Dado que Hive carga los datos de asignación muy rápidamente después de crear la tabla, si hay un problema con la tabla en la práctica, se puede eliminar y reconstruir directamente sin modificaciones.
describe table
muestra la información de metadatos de la tabla en Hive
Si se especifica la palabra clave EXTENDIDA, mostrará todos los metadatos de la tabla en forma serializada Thrift
Si se especifica la palabra clave FORMATTED, mostrará los metadatos en formato de tabla
drop table
elimina los metadatos y los datos de la tabla.
Si la papelera está configurada y no se especifica PURGE, los datos correspondientes a la tabla se moverán a la papelera HDFS y los metadatos se eliminarán por completo.
Cuando EXTERNAL Si se elimina la tabla, los datos de la tabla no se eliminarán del sistema de archivos, solo se eliminarán los metadatos.Si se
especifica PURGE, los datos de la tabla se eliminarán directamente, saltándose la papelera de HDFS. Por lo tanto, si DROP falla, los datos de la tabla no se pueden recuperar
DROP TABLE [IF EXISTS] table_name [PURGE];
truncar tabla
elimina todas las filas de la tabla.
Puede entenderse simplemente como borrar todos los datos de la tabla pero conservando la estructura de metadatos de la tabla.
Si la papelera está habilitada en HDFS, los datos se arrojarán a la papelera, de lo contrario será borrado
TRUNCATE [TABLE] table_name;
alterar la tabla
-- 1.更改表名
ALTER TABLE table_name RENAME TO new_table_name;
-- 2.更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ...);
-- 更改表注释
ALTER TABLE student SET TBLPROPERTIES ('comment' = "new comment for student table");
-- 3.更改SerDE属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ...)];
ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim'=',');
-- 移出SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ...);
-- 4.更改表的文件存储格式 该操作仅更改表元数据,校友数据的人格转换都必须在Hive之外进行
-- 5.更改表的存储位置路径
ALTER TABLE table_name SET LOCATION "new location";
-- 6.更改列名称/类型/位置/注释
CREATE TABLE test_change (a int, b int, c int);
ALTER TABLE test_change CHANGE a a1 INT;
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
ALTER TABLE test_change CHANGE c c1 INT FIRST;
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
-- 7.添加/替换列
-- 使用 ADD COLUMNS,可以将新列添加到现有列的末尾但在分区列之前
-- REPLACE COLUMNS,将删除所有现有列,并添加新的列集
ALTER table_name ADD|REPLACE COLUMNS (col_name data_type,...);
10. Agregar partición (partición) Operación DDL
- ADD PARTITION cambia los metadatos de la tabla, pero no carga los datos. Si no hay datos en la ubicación de la partición, la consulta no arrojará resultados
- Por lo tanto, es necesario asegurarse de que los datos ya existan en la ruta de ubicación de partición agregada o importar los datos de partición después de agregar estiércol.
-- 1.增加分区
ALTER TABLE table_name ADD PARTITION (df='20170101') location '/user/hadoop/warehouse/table_name/dt=20170101'
-- 一次添加一个分区
ALTER TABLE table_name ADD PARTITION (dt='2008-08-08',county='us') location '/path/to/us/part080808' PARTITION (df='2008-08-09', country='us') location '/path/to/us/part080809';
-- 一次添加多个分区
renombrar partición
-- 2.重命名分区
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
ALTER TABLE table_name PARTITION (dt='2008-08-09') RENAME TO PARTITION (dt='20080809')
eliminar partición
elimina la partición de la tabla, y los datos y metadatos de la partición se eliminarán
-- 3.删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us');
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us') PURGE; -- 直接删除数据 不进垃圾桶
alterar la partición
-- 5.修改分区
-- 更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET FILEFORMAT file_format;
-- 更改分区位置
ALTER TABLE table_name PARTITION (df='2008-08-09') SET LOCATION "new location";
Partición MSCK
MSCK es la abreviatura de verificación de metastore, lo que significa operación de verificación de metadatos, que se puede usar para la reparación de metadatos
- El comportamiento predeterminado de MSCK es AGREGAR PARTICIONES, que agrega todas las particiones que existen en HDFS pero que no existen en el metastore al metastore.
- La opción DROP PARTITIONS eliminará la información de la partición del metastore que se eliminó de HDFS
- La opción SYNC PARTITIONS es equivalente a llamar ADD y DROP PARTITIONS
- Si hay una gran cantidad de particiones sin seguimiento, puede ejecutar MSCK PEPAIR TABLE en lotes para evitar OOME (errores de falta de memoria)
-- 分区修复
MSCK [PEPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
11. Sintaxis de demostración de colmena
-- 1.显示所有数据库 SCHEMAS和DATABASES的用法 功能一样
show database;
show schemas;
-- 2.显示当前数据库所有表/视图/物化视图/分区/索引
show tables;
SHOW TABLES [IN database_name]; -- 指定某个数据库
-- 3.显示当前数据库下所有视图
show views;
show views 'test_*';
show views from test1;
SHOW VIEWS [IN/FROM database_name];
-- 4.显示当前数据库下所有物化视图
SHOW MATERIALIZED VIEW [IN/FROM database_name];
-- 5.显示分区信息,分区按字母顺序列出,不是分区表执行该语句会报错
show partitions table_name;
-- 6.显示表/分区的扩展信息
SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name;
show table extended like student;
-- 7.显示表的属性信息
SHOW TBLPROPERTIES table_name;
show tblproperties student;
-- 8.显示表、视图的创建语句
SHOW CREATE TABLE ([db_name.]table_name|view_name)
show create table student;
-- 9.显示表的所有列,包括分区列
SHOW COLUMNS (FORM|IN) table_name [(FROM|IN) db_name];
show columns in student;
-- 10.显示当前支持的所有自定义和内置的函数
show functions;
-- 11.Describe desc
-- 查询表信息
desc extended table_name;
-- 查看表信息(格式化美观)
desc formatted table_name;
-- 查看数据库相关信息
describe database database_name;