【Prefacio】
Sabemos que solo los datos binarios se almacenan en la computadora, independientemente del texto, las imágenes, el audio, el video, etc., cuando los guardamos en la computadora, se convertirán en binarios. Cuando lo abrimos para verlo, los datos binarios se convierten en información que podemos entender. Cómo convertir datos binarios en la computadora en texto e imágenes que podamos entender implica reglas de codificación, es decir, la relación de mapeo entre datos binarios e información que podemos entender. Lo que estamos discutiendo aquí son las reglas de codificación de texto, incluidas ANSI, ASCII, UTF-8, Unicode, etc.
【ASCII】
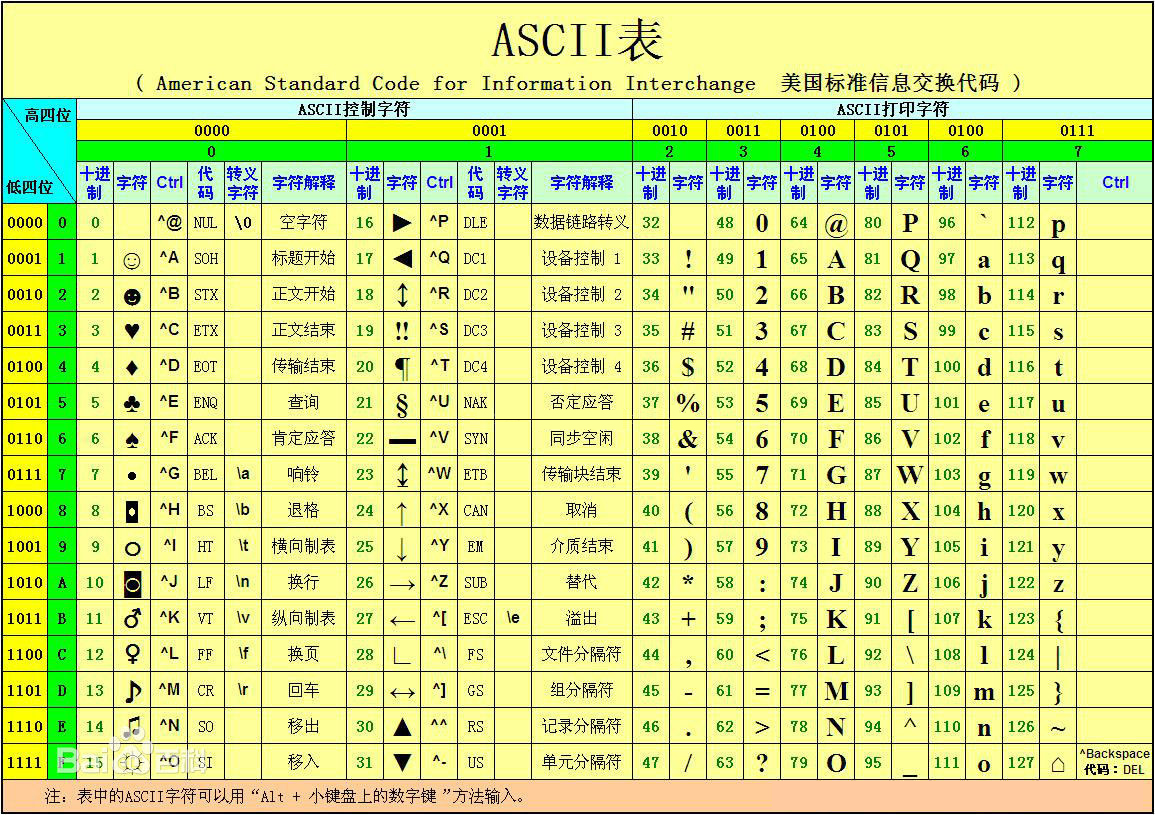
ASCII es lo primero con lo que entrará en contacto al programar. Su nombre completo es Código estándar estadounidense para el intercambio de información, que se denomina "Código estándar estadounidense para el intercambio de información". La tecnología informática moderna surgió de los países de habla inglesa. El contenido inicial del texto solo incluía 26 caracteres en inglés, 10 números y algunos caracteres de uso común en la industria. El conjunto de 128 caracteres es el conjunto de caracteres ASCII. 128 necesita 7 bits para distinguir en binario. Pero la computadora requiere al menos un byte, es decir, 8 bits. Por lo tanto, el bit más alto de ASCII es 0, que no se utiliza. En código ASCII, una letra en inglés ocupa un byte de espacio.
【ANSI】
Con el desarrollo de las computadoras en otros países, cada país también necesita tener su propio juego de caracteres. Al crear un juego de caracteres para su propio idioma nacional, debe ser compatible con el juego de caracteres ASCII existente.
Algunos países tienen muy pocos caracteres de idioma, menos de 128, como el latín, y usan directamente el bit más alto que no se usa en el código ASCII.
Pero para los caracteres chinos, hay más de 6000 caracteres chinos de uso común, además de caracteres gráficos relacionados con el chino, etc., que requieren dos bytes para su representación.
El número máximo de caracteres que se pueden almacenar en dos bytes es de 2 a la 16, es decir, 65536 caracteres, que es suficiente para otros idiomas. De manera similar, se requieren dos bytes para coreano y japonés.
Los caracteres del conjunto de caracteres ASCII todavía se representan con un byte, y los caracteres en otros idiomas se representan con dos bytes. Por ejemplo, en la representación del chino GB2312, si el bit más alto de un byte es 0, significa que ese byte está codificado en ASCII, y si el bit más alto es 1, significa que es el primer byte de un byte doble. código, y el siguiente Los bytes se codifican en fragmentos. Este es el juego de caracteres ANSI, que es una extensión del juego de caracteres ASCII.
En el sistema operativo chino, la regla de codificación del conjunto de caracteres ANSI es GB2312; en el sistema operativo japonés, la regla de codificación es JIS.
GB2312 solo recopiló caracteres chinos de uso común y no hubo caracteres raros. Más tarde, GBK y GB18030 recopilaron más caracteres.
【Unicode】
El problema con el conjunto de caracteres Ansi es que si un texto está codificado en GBK, el chino no se puede mostrar correctamente en el sistema operativo japonés y lo que verá serán caracteres ilegibles. Por lo tanto, se necesita un juego de caracteres que contenga todos los caracteres de todos los países, y este juego de caracteres es el juego de caracteres Unicode.
Actualmente incluye más de 100.000 caracteres y sigue aumentando. En este momento, es suficiente usar 3 bytes para establecer la relación de mapeo, pero no hay un tipo digital de 24 bits en la computadora, por lo que todavía es necesario usar 4 bytes para representar.
Todos los caracteres en Unicode están representados por 4 bytes y la codificación UTF-32 está representada por solo 4 bytes.
La codificación UTF-16 es una codificación de longitud variable, los primeros 65536 caracteres están representados por dos bytes y los demás caracteres están representados por cuatro bytes. Al juzgar si los primeros dígitos de un byte son "11011" para distinguir si un carácter está representado por dos o cuatro bytes.
Para las letras en inglés, el byte original se cambió a 4 bytes de codificación UTF-32 y 2 bytes de codificación UTF-16. Todavía hay una pérdida de espacio. El uso de la codificación UTF-8 puede ahorrar espacio de manera efectiva. , que también es una codificación de longitud variable.
Si el primer bit de un byte leído es 0, significa que este byte tiene un carácter correspondiente; si el primer bit de un byte leído es 1, entonces juzgue el siguiente bit, y el resultado del juicio a su vez es 110, entonces significa que este byte tiene un carácter correspondiente con el byte analizado. Por analogía, los primeros dígitos del primer byte son 1110, lo que significa que 3 bytes corresponden a un carácter, y 11110 significa que 4 bytes corresponden a un carácter, como se muestra en la siguiente figura.

【otro】
En términos generales, UTF-8 es el más utilizado. En C#, el texto está codificado en UTF-16 de forma predeterminada y un carácter corresponde a dos bytes. (El caso de que un carácter corresponda a cuatro bytes rara vez se encuentra en los idiomas chino e inglés). En C++, el valor predeterminado es la codificación ANSI.
Pase una cadena de C++ a C#. Si la cadena está toda en inglés, puede pasarla directamente a C#, ya que UTF-16 es compatible con la codificación en inglés en ANSI. Si la cadena contiene chino, no se puede reconocer correctamente en el lado de C#. Es necesario convertir primero la cadena en una secuencia de bytes (es decir, una matriz de bytes), luego convertir la secuencia de bytes ANSI en una secuencia de bytes Unicode y luego convertir la secuencia de bytes Unicode en un código UTF-16 o UTF-8. cadena.
Tenga en cuenta que el archivo de código también es un archivo de texto, y también habrá problemas con el formato de codificación. En VS, seleccione Archivo -> Opciones avanzadas de guardado para modificar el formato de codificación del archivo de código.
【referencia】
La diferencia entre el código ASCII y el código ANSI_ansi ascii_Mottled years blog-CSDN blog