Introducción
Para que la computadora admita más idiomas, generalmente se usan 2 bytes en el rango de 0x80 ~ 0xFFFF para representar 1 carácter. Por ejemplo: carácter chino "中" En el sistema operativo chino codificado por ANSI, los dos bytes [0xD6,0xD0] se utilizan para el almacenamiento.
Diferentes países y regiones han formulado diferentes estándares, lo que resulta en sus propios estándares de codificación, como GB2312, GBK, GB18030, Big5 y Shift_JIS. Estos métodos de codificación extendidos de varios caracteres chinos que utilizan varios bytes para representar un carácter se denominan codificación ANSI. En el sistema operativo Windows en chino simplificado, el código ANSI significa código GBK; en el sistema operativo Windows en chino tradicional, el código ANSI significa Big5; en el sistema operativo Windows japonés, el código ANSI significa código Shift_JIS.
Los diferentes códigos ANSI son incompatibles entre sí. Cuando la información se intercambia internacionalmente, es imposible almacenar textos en dos idiomas en el mismo texto codificado ANSI.
La codificación ANSI utiliza un byte para caracteres en inglés y dos o cuatro bytes para chinos.
la diferencia
Primero haz un pequeño experimento:
En una carpeta, guarde un texto txt (el texto contiene la oración "El clima de hoy es muy bueno") como archivos txt ansi, unicode y utf-8. Luego, haga clic derecho en la carpeta y seleccione "Buscar (E) ...".

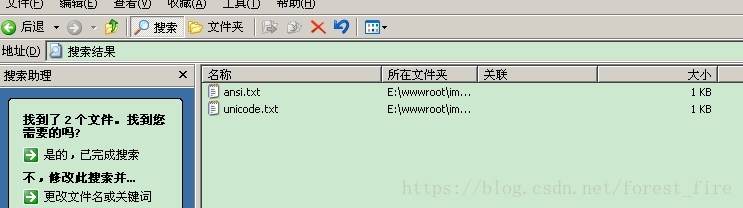
Al buscar la palabra "clima", puede buscar archivos txt codificados en ansi y unicode, pero no archivos codificados en utf-8.
la razón
1. El sistema operativo chino utiliza la codificación ansi de forma predeterminada, y el archivo txt generado utiliza la codificación ansi de forma predeterminada, por lo que se puede buscar.
2. Unicode es un código universal internacional, por lo que se puede buscar.
3. La codificación utf-8 es una especie de codificación "alternativa" y "puente" cuando la codificación Unicode se transmite entre redes (principalmente páginas web). utf-8 puede guardar datos al transferir entre redes. Por lo tanto, el texto txt no se puede buscar usando el sistema operativo.
Según los deseos del fundador de utf-8:
Finalizar (unicode) -transmisión (utf-8) -end (unicode)
Sin embargo, más tarde, muchos desarrolladores web utilizan directamente la codificación utf-8 al desarrollar páginas web.
Fin (utf-8) -transmisión (utf-8) -end (utf-8)
Por lo tanto, la codificación que se ve en el navegador es: unicode (utf-8). El hecho de que unicode (utf-8) se enumere uno al lado del otro en el navegador, muchos internautas (e incluso muchos programadores) creen erróneamente que unicode = utf-8. De hecho, de acuerdo con la intención original del fundador de utf-8, es incorrecto utilizar la codificación utf-8 al desarrollar páginas web, y los primeros navegadores no admiten el análisis de la codificación utf-8. Sin embargo, el poder de todos es inmenso, y Microsoft tiene que "seguir las llamas" y admitir el análisis de la codificación utf-8 en el navegador.
El problema es: la codificación utf-8 afecta a los desarrolladores de sitios web, en otras palabras, los desarrolladores de sitios web "expandieron" el uso de la codificación utf-8. Sin embargo, los desarrolladores de sitios web todavía no pueden influir en los desarrolladores de varios documentos. Por lo tanto, los documentos de Word y algunos documentos de uso internacional todavía utilizan codificación Unicode en lugar de codificación utf-8.
Por ejemplo, el código Unicode de "Yan" es 4E25 y el código UTF-8 es E4B8A5. Los dos son diferentes.
Aunque las codificaciones de los archivos (txt y xml) generados en los sistemas operativos chino y japonés son todas ansi, en el sistema chino simplificado, el código ansi representa el código GB2312, y en el sistema operativo japonés, el código ansi representa el código JIS. Diferentes códigos ANSI son incompatibles entre sí.Cuando la información se intercambia internacionalmente, no es posible almacenar textos pertenecientes a dos idiomas en el mismo párrafo de texto codificado ANSI.
En conclusión
Es una práctica auténtica utilizar la codificación Unicode para documentos internacionales (txt y xml), tanto los sistemas operativos como los navegadores pueden "entender" la codificación Unicode. El navegador "comprende la presión" para "comprender" la codificación utf-8. Sin embargo, el sistema operativo a veces solo reconoce la codificación Unicode.
La diferencia entre Unicode y Unicode big endian: ¿come primero la cabeza pequeña o la cabeza grande cuando come huevos? La diferencia entre Unicode y Unicode big endian es la diferencia entre el extremo pequeño primero y el extremo grande primero en la codificación. "Seguir la tendencia" con Unicode está bien