Tabla de contenido
- 1. ¿Qué es Elasticsearch?
- 2. Instala Elasticsearch
-
- 2.1 Descargar el paquete de instalación
- 2.2 Descripción Ambiental
- 2.3 Crear usuario es
- 2.4 Crear ubicación de almacenamiento es
- 2.5 instalaciones
- 2.5 Modificar el archivo de configuración
- 2.6 Optimización del sistema
- 2.7 Instalar entorno jdk
- 2.8 Cambiar el usuario es para iniciar la base de datos
- 2.9 gestión systemctl
- 2.10 Acceso
- 3. kibana
- 4. Clúster de alta disponibilidad de Elasticsearch
- 5. Implementación de clústeres ES de alta disponibilidad
- 6. Configurar el clúster de monitoreo de kibana
1. ¿Qué es Elasticsearch?
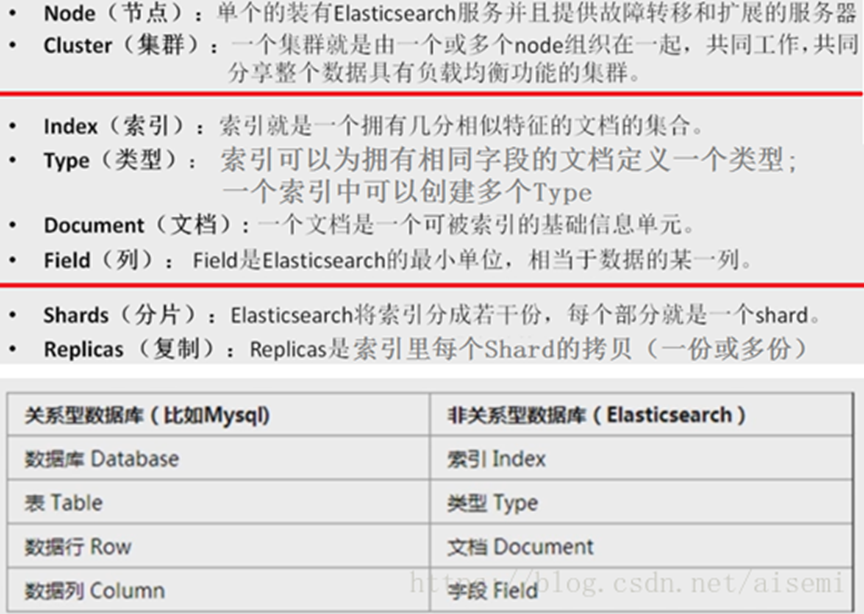
1.1 Concepto y características
-
Elasticsearch, como MongoDB/Redis/Memcache, es una base de datos no relacional. Es una plataforma de búsqueda casi en tiempo real. Solo hay un ligero retraso desde la indexación de este documento hasta que se pueda buscar en este documento. Posicionamiento de aplicaciones empresariales: una herramienta de búsqueda de texto completo escalable y de alta disponibilidad para el análisis de datos en tiempo real utilizando Restful API estándares
-
Escalable: admite un maestro y múltiples esclavos y es fácil de expandir. Siempre que el nombre del clúster sea consistente y esté en la misma red, puede unirse automáticamente al clúster actual; es un software de código abierto en sí mismo y también es compatible con muchos de código abierto. complementos de terceros.
-
Alta disponibilidad: almacenamiento distribuido entre múltiples nodos en un clúster. El índice admite fragmentos y replicación. Incluso si algunos nodos están inactivos, la recuperación de datos y el cambio maestro-esclavo se pueden realizar automáticamente.
-
La unidad más pequeña de almacenamiento de datos es un documento, que es esencialmente un texto JSON:
1.2 Descripción general de los escenarios aplicables de ElasticSearch
-
Wikipedia, similar a la Enciclopedia de Baidu, búsqueda de texto completo, resaltado, recomendación de búsqueda
-
The Guardian (un sitio web de noticias extranjero), similar a Sohu News, registros de comportamiento del usuario (clics, navegación, favoritos, comentarios) + datos de redes sociales (vistas relacionadas con ciertas noticias), análisis de datos y entregados al autor de cada artículo de noticias , Hágale saber acerca de los comentarios públicos sobre sus artículos (bueno, malo, popular, basura, despreciado, adorado)
-
Desbordamiento de pila (foro de discusión de excepciones de programas extranjeros), problemas de TI, informes de errores de programas, envíelos, alguien discutirá y responderá con usted, búsqueda de texto completo, búsqueda de preguntas y respuestas relacionadas, si el programa informa un error, el mensaje de error se pegará en él Vaya, busque si hay una respuesta correspondiente
-
GitHub (administración de código fuente abierto), busque cientos de miles de millones de líneas de código
-
Sitio web de comercio electrónico, búsqueda de productos.
-
Nacional: búsqueda en el sitio (comercio electrónico, reclutamiento, portales, etc.), búsqueda en sistemas de TI (OA, CRM, ERP, etc.), análisis de datos (un escenario de uso popular para ES)
2. Instala Elasticsearch
2.1 Descargar el paquete de instalación
Dirección de descarga del sitio web oficial:
https://www.elastic.co/cn/downloads/past-releases
2.2 Descripción Ambiental
//系统版本
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
//关闭防火墙
[root@localhost ~]# systemctl stop firewalld && systemctl disable firewalld
[root@localhost ~]# sed -i '7s/enforcing/disabled/g' /etc/selinux/config
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
2.3 Crear usuario es
[root@localhost ~]# groupadd es
[root@localhost ~]# useradd -g es -s /bin/bash -md /home/es es
2.4 Crear ubicación de almacenamiento es
//存放在/var/es(根据实际需求)
[root@localhost ~]# mkdir /var/es && cd /var/es
[root@localhost es]# mkdir data && mkdir log
[root@localhost es]# chown -Rf es:es /var/es/
2.5 instalaciones
//创建文件夹,并将安装包上传到这里
[root@localhost ~]# mkdir /usr/local/es && cd /usr/local/es
//上传安装包
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf elasticsearch-6.8.20.tar.gz -C /usr/local/es/
[root@localhost src]# cd /usr/local/es/
[root@localhost es]# chown -Rf es:es /usr/local/es/elasticsearch-6.8.20/
2.5 Modificar el archivo de configuración
//编辑配置文件
[root@localhost es]# vim /usr/local/es/elasticsearch-6.8.20/config/elasticsearch.yml
//取消cluster.name前的#号注释,改成自己起的名字。(注意前面的数字代表行号)
17 cluster.name: my-application
//node.name取消#号
23 node.name: node-1
//设置path.data,取消#号,改为如下的
33 path.data: /var/es/data
//设置path.logs,取消#号,改为如下的
37 path.logs: /var/es/log
//network.host取消#号,改为0.0.0.0(允许所有ip访问)
55 network.host: 0.0.0.0
//取消http.port#
59 http.port: 9200
//在文件的最后添加以下配置
89 bootstrap.memory_lock: false
90 bootstrap.system_call_filter: false
2.6 Optimización del sistema
//修改文件1
[root@localhost es]# vi /etc/security/limits.conf
末尾添加
62 es soft nofile 65536
63 es hard nofile 65536
64 es soft nproc 4096
65 es hard nproc 4096
//修改文件2
[root@localhost es]# vim /etc/sysctl.conf
末尾添加
11 vm.max_map_count = 655360
[root@localhost es]# sysctl -p
vm.max_map_count = 655360
2.7 Instalar entorno jdk
//上传jdk安装包
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/
//添加环境变量
[root@localhost src]# vim /etc/profile
末尾添加
78 #JAVA_HOME
79 export JAVA_HOME=/usr/local/java
80 #JRE_HOME
81 export JRE_HOME=/usr/local/java/jre
82 #CALSSPATH
83 export CLASSPATH=$CLASSPATH:${JAVA_HOME}/lib:${JRE_HOME}/lib
84 #PATH
85 export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin
//重命名
[root@localhost ~]# mv /usr/local/jdk1.8.0_131/ /usr/local/java
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
2.8 Cambiar el usuario es para iniciar la base de datos
[root@localhost ~]# su es
[es@localhost root]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
2.9 gestión systemctl
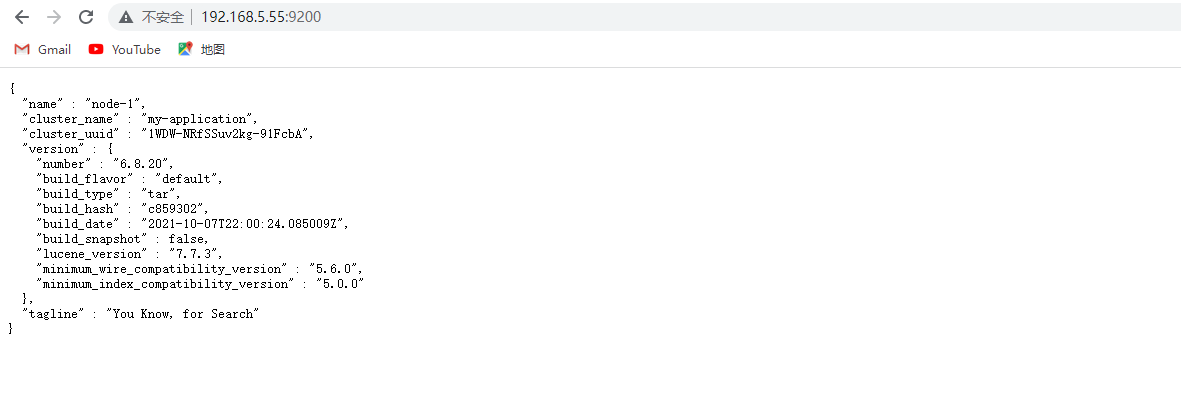
2.10 Acceso
Use un navegador para acceder a ip:9200 (puerto 9200 del dispositivo instalado), y vea las siguientes instrucciones para que la instalación sea exitosa:
3. kibana
3.1 introducción a kibana
Kibanaes una plataforma de análisis y visualización de código abierto diseñada para usarse Elasticsearchcon y con. Puede kibanabuscar y ver Elasticsearchlos datos almacenados en él. KibanaLa forma de interactuar Elasticsearches una variedad de gráficos, tablas, mapas, etc., para mostrar datos de manera intuitiva, a fin de lograr el propósito de análisis y visualización de datos avanzados.
Elasticsearch, Logstashy Kibanaestas tres tecnologías son lo que a menudo llamamos la pila de tecnología ELK. Se puede decir que la combinación de estas tres tecnologías es un diseño muy inteligente en el campo de los grandes datos. Una idea muy típica de MVC, capa de persistencia del modelo, capa de visualización y capa de control. Logstash actúa como la capa de control y es responsable de recopilar y filtrar datos. ElasticsearchDesempeña el papel de capa de persistencia de datos y es responsable de almacenar datos. El tema de nuestro capítulo Kibanadesempeña el papel de la capa de vista, tiene varias dimensiones de consulta y análisis y utiliza una interfaz gráfica para mostrar los datos almacenados en Elasticsearch.
3.2 instalar kibana
Dirección de descarga del sitio web oficial:
https://www.elastic.co/cn/downloads/past-releases#kibana
3.3 Subir paquete de instalación
//使用rz命令或者xftp上传
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels kibana-6.8.20-linux-x86_64.tar.gz
3.4 Descomprimir el archivo
[root@localhost src]# tar xf kibana-6.8.20-linux-x86_64.tar.gz -C /usr/local/
3.5 Modificar el archivo de configuración
//下列的序号为行号
[root@localhost src]# vim /usr/local/kibana-6.8.20-linux-x86_64/config/kibana.yml
7 server.host: "192.168.5.55" //ES服务器主机地址
28 elasticsearch.hosts: ["http://192.168.5.55:9200"] //ES服务器地址
3.6 inicio
[root@localhost src]# cd /usr/local/kibana-6.8.20-linux-x86_64/
[root@localhost kibana-6.8.20-linux-x86_64]# ./bin/kibana &
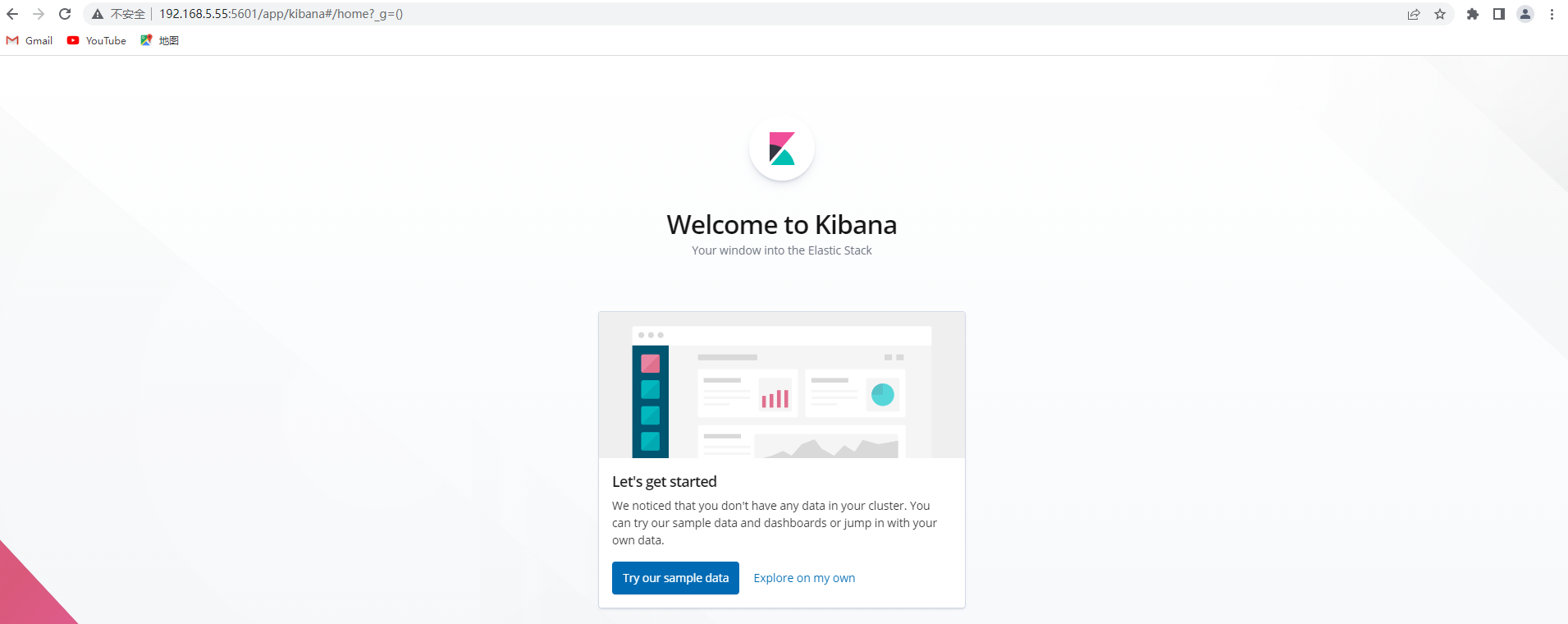
3.7 Acceso al navegador
http://192.168.5.55:5601/app/kibana
4. Clúster de alta disponibilidad de Elasticsearch
4.1 Cómo resuelve ES la alta concurrencia
ES es un marco de búsqueda de texto completo distribuido que oculta mecanismos de procesamiento complejos, como el mecanismo de fragmentación de contenido principal, el descubrimiento de clústeres y el enrutamiento de solicitudes de carga de fragmentación.
4.2 Sustantivos de conceptos básicos ES
Grupo
Representa un clúster. Hay varios nodos en el clúster, y uno de ellos es el nodo maestro. Este nodo maestro se puede elegir a través de elecciones. Los nodos maestro-esclavo están para el interior del clúster. Uno de los conceptos de es es la descentralización. Literalmente, significa que no hay un nodo central. Esto es para el exterior del clúster, porque mirando el clúster de es desde el exterior, es lógicamente un todo. Su comunicación con cualquier nodo y el todo La comunicación del clúster ES es equivalente.
Fragmentos
Representa la fragmentación del índice. Es puede dividir un índice completo en múltiples fragmentos. La ventaja de esto es que un índice grande se puede dividir en múltiples partes y distribuir a diferentes nodos. constituyen una búsqueda distribuida. El número de fragmentos solo se puede especificar antes de crear el índice y no se puede cambiar después de crear el índice.
réplicas
Representa copia de índice. Es puede establecer múltiples copias de índice. La primera función de la copia es mejorar la tolerancia a fallas del sistema. Cuando un nodo o un fragmento se daña o se pierde, se puede recuperar de la copia. El segundo es mejorar la eficiencia de las consultas de es, y es automáticamente equilibrará la carga de las solicitudes de búsqueda.
Recuperación
Representa la recuperación de datos o la redistribución de datos. ES redistribuirá los fragmentos de índice de acuerdo con la carga de la máquina cuando un nodo se una o salga, y la recuperación de datos también se realizará cuando se reinicie el nodo que cuelga.
4.3 ¿Por qué ES implementa clústeres?
Un índice en un clúster de ES puede constar de varios fragmentos y cada fragmento puede tener varias copias. Al dividir un solo índice en múltiples fragmentos, podemos manejar índices grandes que no se pueden ejecutar en un solo servidor. En pocas palabras, el tamaño del índice es demasiado grande, lo que genera problemas de eficiencia. El motivo de que no se ejecute puede ser la memoria o el almacenamiento. Dado que cada fragmento puede tener múltiples réplicas, al distribuir las réplicas a múltiples servidores, se puede mejorar la capacidad de carga de consultas.
Análisis del principio básico del clúster ES:
-
Cada índice se divide en varios fragmentos para su almacenamiento. De forma predeterminada, se asignan 5 fragmentos para crear un índice.
Cada fragmento se distribuirá e implementará en múltiples nodos diferentes, y el fragmento se convertirá en fragmentos primarios.
Nota: Una vez definidos los fragmentos primarios del índice, no se pueden modificar más adelante. -
Para lograr una alta disponibilidad de datos altamente disponibles, el fragmento principal puede tener fragmentos de réplicas de fragmentos de copia de seguridad correspondientes, y los fragmentos de fragmentos de réplica son responsables de la tolerancia a fallas y el equilibrio de carga de las solicitudes.
Nota: Para lograr una alta disponibilidad, cada fragmento principal tendrá su propio fragmento de respaldo correspondiente. El fragmento de respaldo correspondiente al fragmento principal no se puede almacenar en el mismo servidor (un solo ES no tiene un fragmento de respaldo). Los fragmentos primarios se pueden almacenar en el mismo nodo que otros fragmentos de réplicas.
Al almacenar datos en el servidor de fragmentos primario, se sincronizará con el servidor de fragmentos en espera en tiempo real:
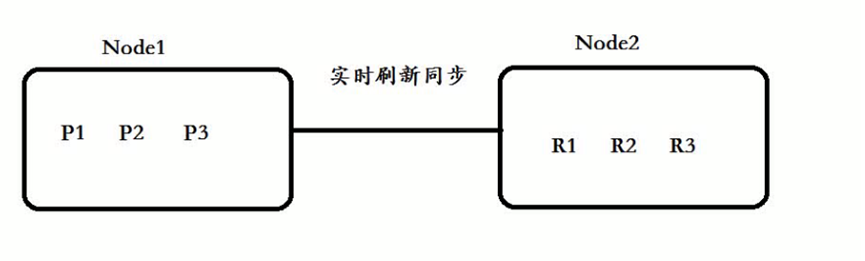
pero al consultar, se consultará todo (principal y en espera).
El principal puede almacenar los secundarios:
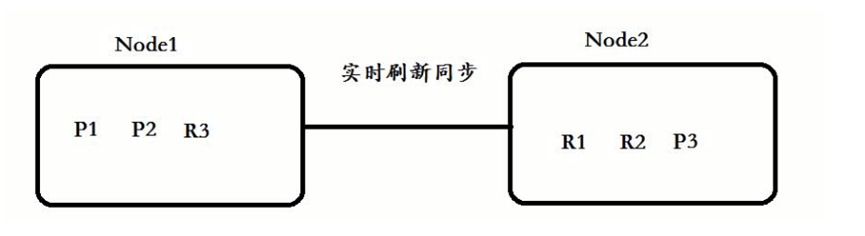
Nodo1: ¡P1+P2+R3 constituye un dato completo! almacenamiento distribuido
¡Los datos centrales almacenados en el núcleo de ES son un índice!
Si ES implementa un clúster, el archivo de índice de un solo nodo de servidor se distribuirá y almacenará en varias máquinas físicas diferentes utilizando tecnología de fragmentación.
La fragmentación consiste en dividir los datos en varios nodos para su almacenamiento.
En la tecnología de fragmentación ES, se divide en fragmentación primaria (primaria) y fragmentación secundaria (réplicas). Esto se hace para la tolerancia a fallas.
5. Implementación de clústeres ES de alta disponibilidad
5.1 Descripción ambiental
系统环境:
[es@localhost root]$ cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
Anfitrión:
| dirección IP | nodo | versión de la base de datos | herramienta de visualización |
|---|---|---|---|
| 192.168.5.55 | nodo1 (maestro) | elasticsearch-6.8.20 | Kibana-6.8.20 |
| 192.168.5.56 | nodo2 | elasticsearch-6.8.20 | |
| 192.168.5.100 | nodo3 | elasticsearch-6.8.20 |
5.2 Proceso de instalación
Se deben preparar tres hosts y se ha instalado la base de datos ES. Consulte la segunda sección del catálogo para conocer el proceso de instalación.
Nota: cierre el firewall.
5.3 Modificar el archivo de configuración
修改192.168.5.55配置文件
[root@localhost config]# pwd
/usr/local/es/elasticsearch-6.8.20/config
[root@localhost config]# vim elasticsearch.yml
注:前面的序号为行号,标记多少行
前面省略……
17 cluster.name: myes //集群名称,保证三台集群名字相同
23 node.name: node-1 //当前节点名称,集群内节点名字不能相同
33 path.data: /var/es/data //数据存放目录
37 path.logs: /var/es/log //日志存放目录
55 network.host: 0.0.0.0 //主机
59 http.port: 9200 //端口号
68 discovery.zen.ping.unicast.hosts: ["192.168.5.55", "192.168.5.56","192.168.5.100"] //多个服务集群ip
72 discovery.zen.minimum_master_nodes: 1 //最少主节点数量
89 bootstrap.memory_lock: false //添加以下两行,开放网络权限
90 bootstrap.system_call_filter: false
剩下的两台利用scp命令远程覆盖配置文件
注意:记得修改节点名称,集群内节点名字不能相同
[root@localhost ~]# cd /usr/local/es/elasticsearch-6.8.20/config/
[root@localhostconfig]# scp elasticsearch.yml [email protected]:/usr/local/es/
elasticsearch-6.8.20/config/
5.4 Iniciar la base de datos es
三台依次启动
[root@localhost config]# su es
[es@localhost config]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
5.5 Prueba de conglomerados
Acceda a la siguiente dirección a través de un navegador para ver el estado de inicio del clúster
192.168.5.55:9200/_cat/health?v

//查看集群信息
[root@localhost config]# curl 192.168.5.55:9200/_cat/nodes
192.168.5.56 14 96 1 0.05 0.15 0.13 mdi - node-2
192.168.5.100 14 90 0 0.00 0.06 0.06 mdi - node-3
192.168.5.55 23 97 2 0.00 0.04 0.05 mdi * node-1 带*号表示主节点
//检查分片是否正常
[root@localhost ~]# curl 192.168.5.55:9200/_cat/shards
.kibana_task_manager 0 p STARTED 2 6.8kb 192.168.5.55 node-1
.kibana_task_manager 0 r STARTED 2 6.8kb 192.168.5.56 node-2
.kibana_1 0 p STARTED 4 19.8kb 192.168.5.56 node-2
.kibana_1 0 r STARTED 4 19.8kb 192.168.5.100 node-3
.monitoring-kibana-6-2023.05.15 0 p STARTED 2194 747.9kb 192.168.5.55 node-1
.monitoring-kibana-6-2023.05.15 0 r STARTED 2194 680.4kb 192.168.5.100 node-3
.monitoring-kibana-6-2023.05.12 0 p STARTED 1180 420kb 192.168.5.56 node-2
.monitoring-kibana-6-2023.05.12 0 r STARTED 1180 420kb 192.168.5.100 node-3
.monitoring-es-6-2023.05.15 0 p STARTED 28065 14mb 192.168.5.55 node-1
.monitoring-es-6-2023.05.15 0 r STARTED 28065 14mb 192.168.5.56 node-2
.monitoring-es-6-2023.05.12 0 p STARTED 11490 5.6mb 192.168.5.55 node-1
.monitoring-es-6-2023.05.12 0 r STARTED 11490 5.6mb 192.168.5.100 node-3
P 表示primar shard 主分片,前面的数字表示分片数量
R 表示 replica shard 副本分片
5.6 Verificar la conmutación por error del clúster ES
注意实心星号的是主节点,我们尝试将 192.168.5.55 节点服务关闭,验证,主节点是否进行重新选举,并再次启动 192.168.5.55,看看是否变成候选节点:
[root@localhost ~]# ps -ef | grep /usr/local/es/ela
[root@localhost ~]# kill -9 3184
[es@localhost config]$ curl 192.168.5.56:9200/_cat/nodes
192.168.5.56 21 96 1 0.03 0.02 0.05 mdi - node-2
192.168.5.100 24 95 1 0.30 0.10 0.07 mdi * node-3
发现 192.168.5.100变成了主节点,然后启动 192.168.5.55,验证其是否变成了候选节点
[root@localhost ~]# curl 192.168.5.55:9200/_cat/nodes
192.168.5.100 27 94 2 0.08 0.08 0.07 mdi * node-3
192.168.5.55 26 96 1 0.97 0.25 0.12 mdi - node-1
192.168.5.56 22 96 1 0.03 0.03 0.05 mdi - node-2
6. Configurar el clúster de monitoreo de kibana
6.1 Modificar el archivo de configuración
Consulte la tercera parte del directorio para el proceso de instalación.
修改配置kibana配置文件
[root@localhost ~]# vim /usr/local/kibana-6.8.20-linux-x86_64/config/kibana.yml
7 server.host: "0.0.0.0" //服务器主机地址
//集群ip端口号
28 elasticsearch.hosts: ["http://192.168.5.55:9200","http://192.168.5.56:9200",
"http://192.168.5.100:9200"]
[root@localhost ~]# cd /usr/local/kibana-6.8.20-linux-x86_64/bin/
[root@localhost bin]# ./bin/kibana &
6.2 Acceso
Supervisó con éxito todo el clúster
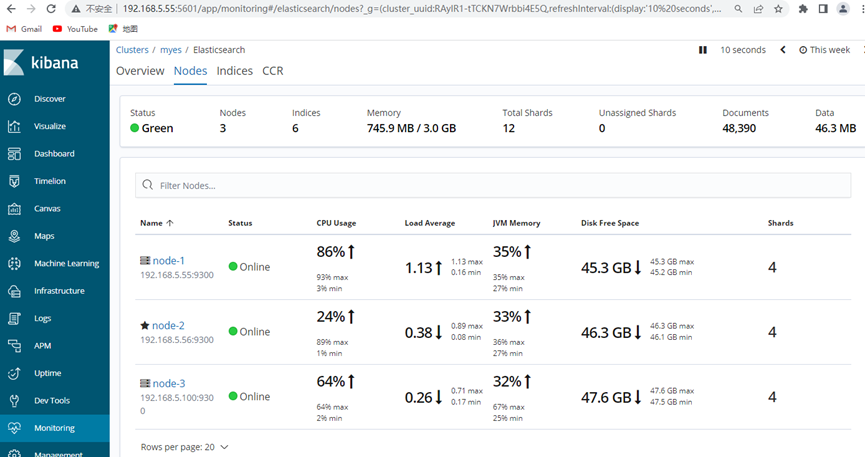
6.3 Verificar fragmentación
Cuando los tres nodos son normales, lo siguiente muestra 16 fragmentos
Nodo1: 5
Nodo2: 6
Nodo3: 5
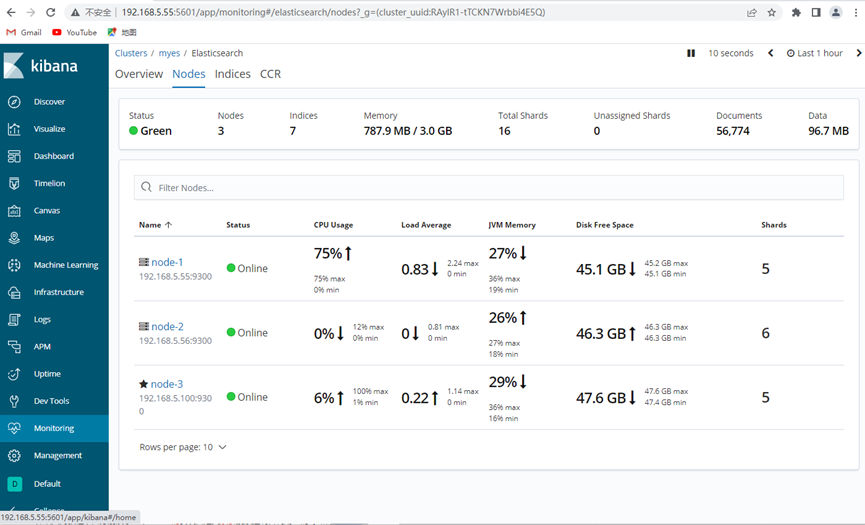
fallas simuladas:
Ahora apague el nodo nodo1, normalmente los cinco fragmentos del nodo nodo1 se redistribuirán al resto Los dos nodos a continuación traen el total a 16 fragmentos
[root@localhost kibana-6.8.20-linux-x86_64]# netstat –tunlp
[root@localhost kibana-6.8.20-linux-x86_64]# kill -9 2036
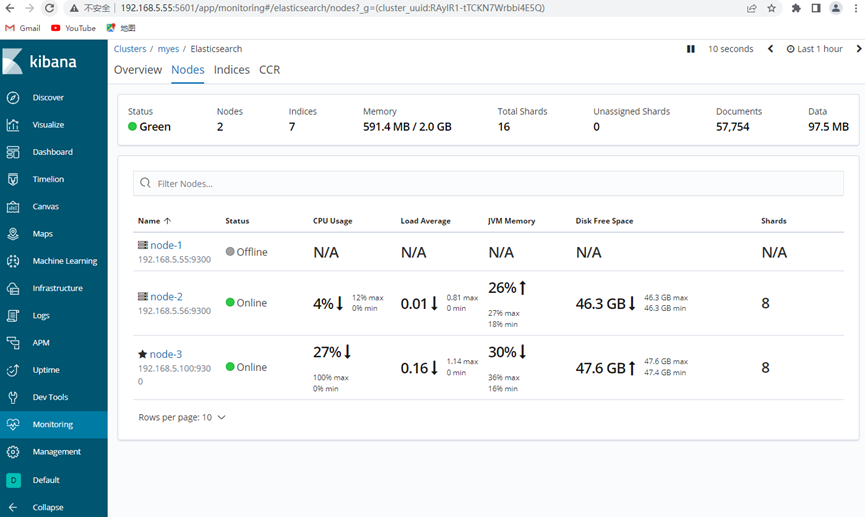
La verificación es exitosa, y puede ver que el nodo 1 está colgado, y a los dos nodos restantes se les asignan 8 fragmentos a cada uno