Метод Requests-get использует
Возьмем в качестве примера сайт https://books.toscrape.com/:
открыть веб-страницу
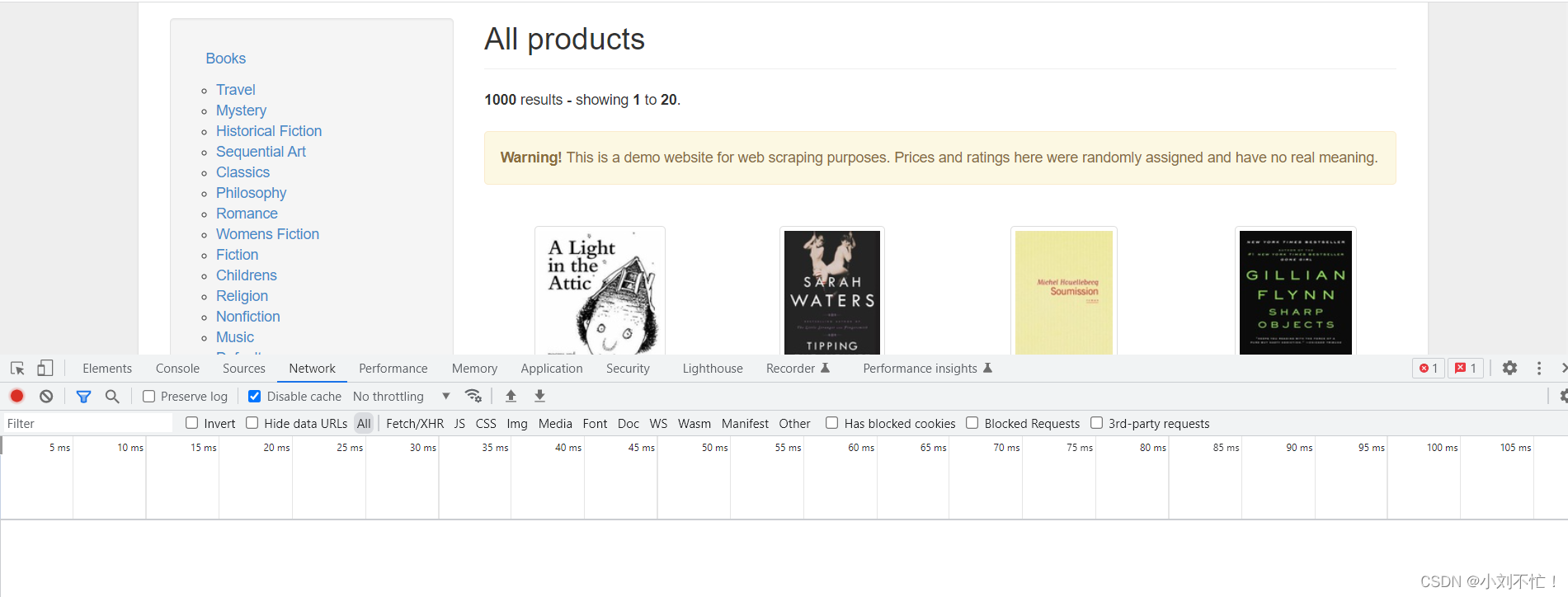
Сначала откройте веб-страницу, затем щелкните правой кнопкой мыши, чтобы проверить, и найдите столбец сети. В это время вы обнаружите, что нижняя часть пуста и ничего нет: просто обновите ее. После обновления: щелкните первый, чтобы
просмотреть

:

вы можете видеть, что метод запроса является методом «GET», запрошенный URL-адрес также можно увидеть.
В нижней части страницы вы можете найти более одной страницы, щелкните на следующей странице и продолжайте проверять страницу:


теперь используйте тот же формат, введите «https://books.toscrape.com/catalogue/page-1». .html" для просмотра, возврат на домашнюю страницу. Как правило, первая страница является домашней, поэтому /catalogue/page-2.html не будет добавлен к следующему пути, и вы можете найти его, просмотрев еще несколько страниц.
Используйте код для получения содержимого страницы
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
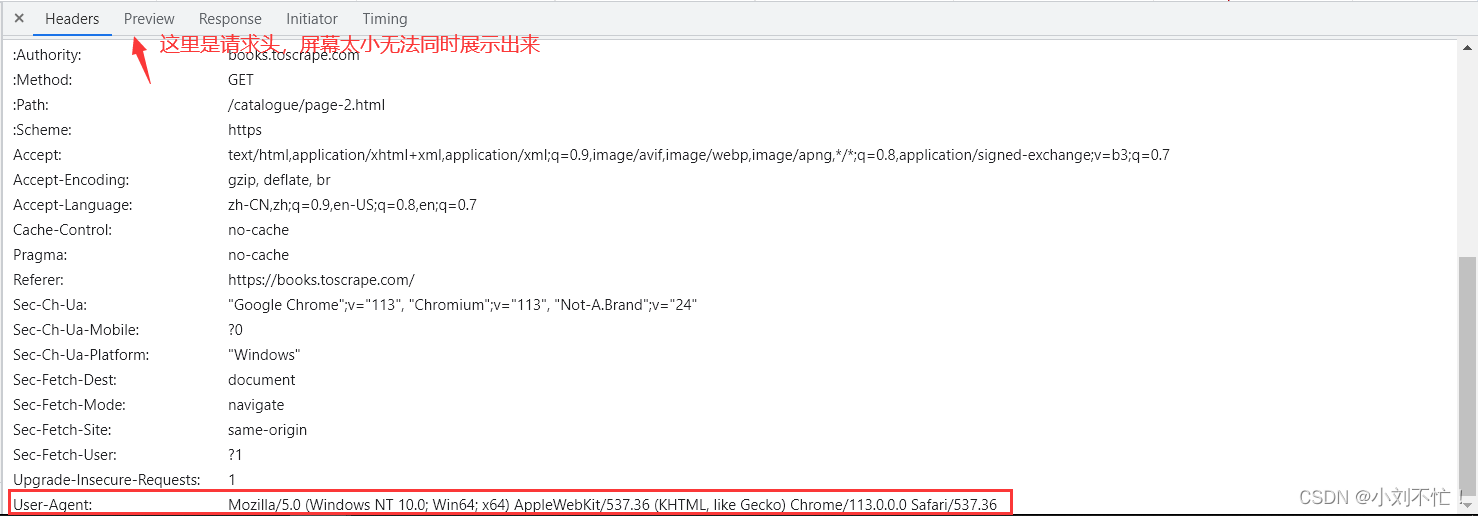
Во-первых, добавьте заголовок сканера, потому что многие страницы имеют ограничения на сканирование для сканеров, и после добавления заголовка он может имитировать обычные запросы браузера с более высокими шансами на успех. Эта часть находится в разделе заголовка запроса страницы, к которой нужно получить доступ:
url = "https://books.toscrape.com/catalogue/page-1.html"
В этом разделе объявляется URL для посещения.
responce = requests.get(url,headers=headers).text
Разберите эту часть:
request.get(url, headers=headers): с соответствующим заголовком запроса получите доступ к указанному выше URL-адресу в режиме GET.
request.get(url,headers=headers).text: Вернуть вышеуказанное содержимое в виде текста.
response = request.get(url, headers=headers).text: вернуть содержимое в переменную response.
Посмотреть Результаты

После запуска отображается содержимое соответствующей страницы. Но формат немного беспорядочный, и его можно настроить с помощью некоторых методов.
Изменение формата страницы
В это время будет представлена библиотека BeautifulSoup. BeautifulSoup — это библиотека Python для извлечения данных из документов HTML и XML. Он обеспечивает простой и гибкий способ анализа и просмотра этих документов, упрощая извлечение конкретной информации.
soup = BeautifulSoup(responce,"html.parser")
Смысл этого шага заключается в том, чтобы использовать BeautifulSoup для разбора полученного содержимого веб-страницы (текста ответа), чтобы данные в ней можно было легко извлечь и манипулировать ими. Без этого шага функцию BeautifulSoup нельзя использовать для анализа содержимого веб-страницы. Без синтаксического анализа вы просто получите простой текстовый ответ, что затруднит прямое извлечение конкретных данных, которые вам нужны. Вам придется вручную обрабатывать содержимое ответа, чтобы найти и извлечь необходимую информацию, что очень утомительно и чревато ошибками.
Теперь печать (суп) обнаружит, что формат страницы намного проще.
Объяснение грамматики:
ответ: Это обязательный параметр, указывающий содержимое документа, подлежащего анализу. В этом примере ответ — это содержимое веб-страницы, полученное путем отправки HTTP-запроса, то есть текст ответа, возвращаемый сервером. Это переменная типа string, которая содержит содержимое HTML-документа.
«html.parser»: это второй параметр, указывающий используемый парсер. В этом случае используется встроенный в Python анализатор HTML, который называется «html.parser». Этот синтаксический анализатор является неотъемлемой частью библиотеки BeautifulSoup и может преобразовывать HTML-документы в деревья синтаксического анализа для дальнейшей обработки и извлечения.
Другими необязательными парсерами являются «lxml» и «html5lib». Все они являются сторонними библиотеками с разными функциями и производительностью. Выбор правильного парсера зависит от ваших потребностей и среды.
Подводя итог, можно сказать, что два параметра в BeautifulSoup(response, "html.parser") соответственно представляют содержимое анализируемого документа и тип используемого синтаксического анализатора.
заголовок сканирования
Использование сканера определенно означает сканирование содержимого, а затем сканирования названия книги.
Идея примерно разделена на несколько шагов: URL-адрес соответствующей страницы, настройка заголовка запроса, просмотр содержимого страницы и настройка параметров кода.
URL и заголовки запросов настроены. Далее проверяем содержимое страницы. Каковы характеристики места, где вы проверяете название книги? Вы можете обнаружить, что снаружи есть h3, а внутри
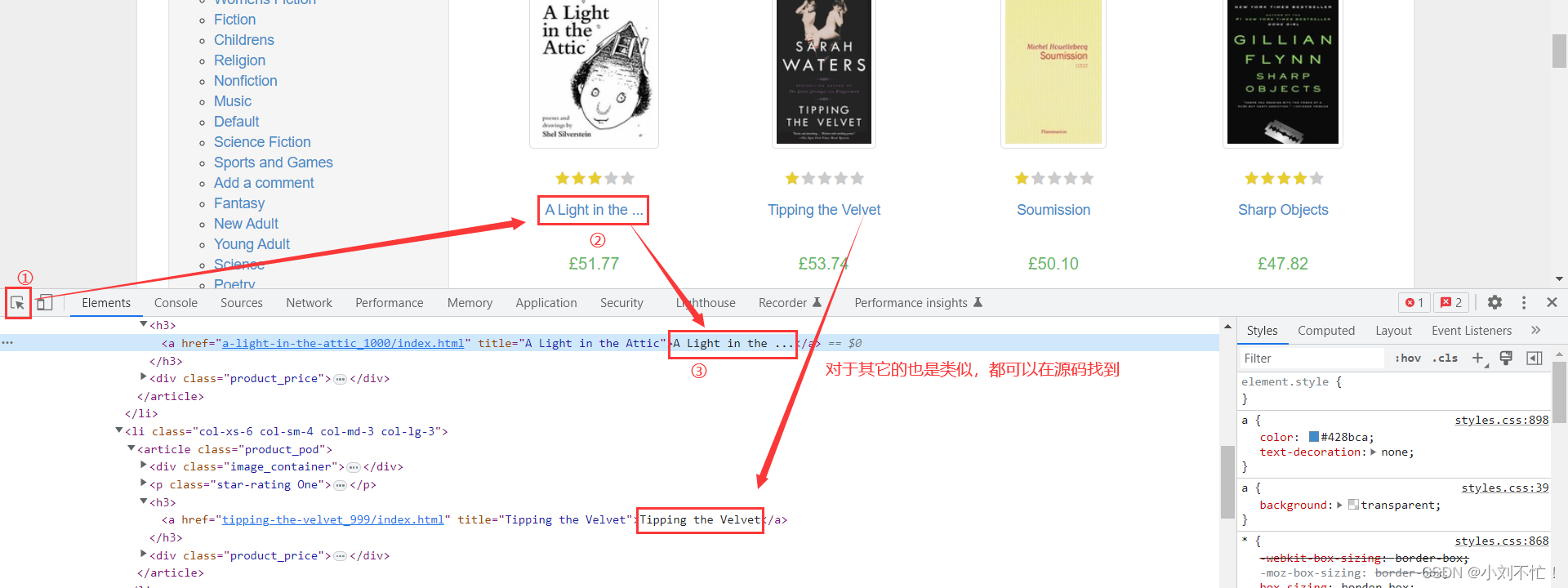
окружено теги а. Далее, посмотрите на код:
soup = BeautifulSoup(responce,"html.parser")
all_title = soup.findAll("h3")
Искать все содержимое в супе, искать содержимое, содержащееся в теге «h3», и проверять вывод:

можно обнаружить, что содержимое в теге «h3» действительно выводится, но содержимое в нем не то, что мы все хотим.Далее нам нужно отфильтровать, см. код:
all_title = soup.findAll("h3")
for i in all_title:
title = i.find("a")
print(title)
Теперь просмотрите содержимое в каждом теге «h3», а затем найдите содержимое в теге «a» и просмотрите вывод:
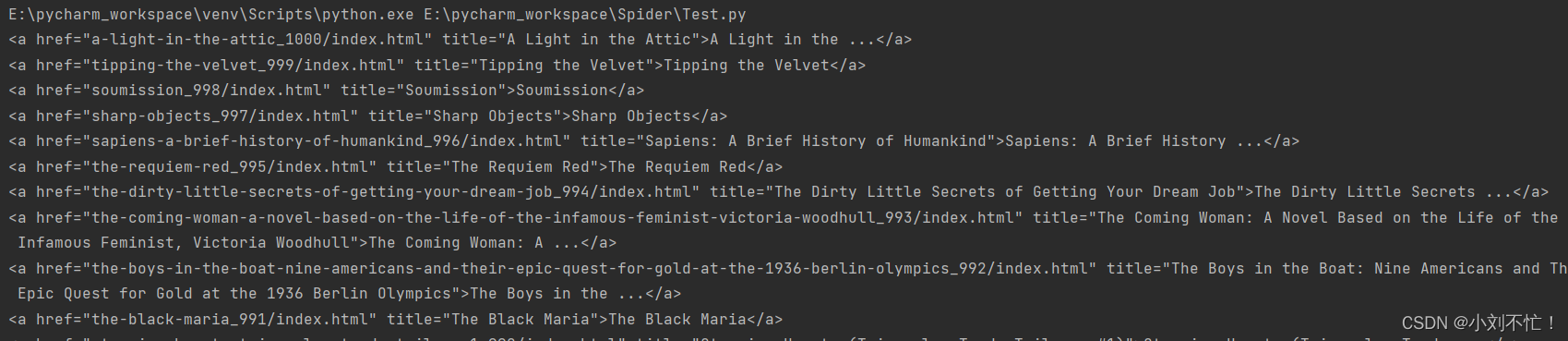
для содержимого в теге «a» нам не нужны теги в html, только html В тексте, так что продолжайте добавлять параметры, смотрите код:
all_title = soup.findAll("h3")
for i in all_title:
title = i.find("a")
print(title.string)
Здесь окончательная печать ограничена, и выводится строковый тип названия, то есть пока текстовый тип включен, проверьте вывод: можно обнаружить, что

выводится только название книги, и это эффект именно то, что мы хотим.
Полный код с комментариями
код
from bs4 import BeautifulSoup
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}#请求头改成自己的
url = "https://books.toscrape.com/catalogue/page-1.html"
responce = requests.get(url,headers=headers).text
soup = BeautifulSoup(responce,"html.parser")
all_title = soup.findAll("h3")
for i in all_title:
title = i.find("a")
print(title.string)
примечание
-
from bs4 import BeautifulSoup: Импортировать библиотеку BeautifulSoup, это для использования функций парсинга и извлечения. -
import requests: импортировать библиотеку запросов, которая используется для отправки HTTP-запросов для получения содержимого веб-страницы. -
headers = {...}: определяет переменную типа словаряheaders, которая содержит информацию заголовка запроса. Поле User-Agent задается в информации заголовка запроса для имитации отправки запроса браузером. -
url = "https://books.toscrape.com/catalogue/page-1.html": определяет URL-адрес целевой веб-страницы для сканирования. -
response = requests.get(url, headers=headers).text: отправить HTTP-запрос GET на указанный URL-адрес и получить объект ответа..textВернуть содержимое ответа в виде текста. Присвоить полученный текст ответаresponseпеременной. -
soup = BeautifulSoup(response, "html.parser"): Используйте библиотеку BeautifulSoup для анализа полученного текста ответа и создания объекта BeautifulSoup. Передайте параметрыresponseкак содержимое документа для анализа и тип парсера "html.parser". -
all_title = soup.findAll("h3"): ИспользуйтеfindAllметод объекта BeautifulSoup, чтобы найти все<h3>теги и сохранить результат в переменнойall_title.findAllВозвращает список всех соответствующих тегов. -
for i in all_title::all_titleИтерация по каждому элементу в списке. -
title = i.find("a")<h3>: Используйтеfindэтот метод, чтобы найти первую метку среди меток текущей итерации<a>и сохранить результат в переменнойtitle. -
print(title.string): Печататьtitleтекстовое содержимое этикетки, то есть название книги. Используйте.stringдля получения текста внутри тега.
Функция этого кода — сканировать информацию о названии книги с указанной веб-страницы и распечатывать ее. Он использует библиотеку запросов для отправки HTTP-запросов для получения содержимого веб-страницы, а затем использует библиотеку BeautifulSoup для анализа веб-страницы и извлечения необходимой информации. Наконец, название каждой книги распечатывается через цикл.
Переверните страницу, чтобы запросить все
Поместите это в следующую статью для подробного ознакомления.