Desarrollo y optimización del despliegue del "sistema inteligente de corrección de fórmulas"
Resumen
Esta importante asignación construyó y realizó el desarrollo y la optimización de la implementación del "Sistema de corrección de fórmula inteligente". El "sistema de corrección de fórmula inteligente" es un sistema de corrección inteligente que integra la detección de objetivos yolo, el reconocimiento de paddleocr y cuatro algoritmos de juicio aritmético. El sistema puede corregir las páginas cargadas que contienen cuatro problemas aritméticos, incluida la identificación del área de cálculo y la evaluación de la corrección de los resultados del cálculo. La página frontal del sistema está construida por el marco vue3, y el back-end está construido por el marco matraz de python, y algunas funciones se han sincronizado con el subprograma WeChat. El sistema tiene las funciones de detección, identificación y corrección de fórmulas, así como un conjunto de mecanismos de retroalimentación y autoactualización. Después de mucho entrenamiento y optimización del sistema, la detección de objetivos yolo ha realizado la detección precisa de las coordenadas del área de la fórmula, y el reconocimiento de escritura a mano paddleocr también ha reconocido con precisión el contenido de la fórmula y juzgado si el resultado es correcto o correcto. no. El efecto de corrección general del sistema es bueno, pero todavía hay mucho margen de mejora.
-
Introducción al "Sistema inteligente de corrección de fórmulas"
-
1.1 Introducción
La corrección de las preguntas aritméticas de la escuela primaria es una tarea repetitiva, y el proceso es tedioso y fácil de corregir errores. Por lo tanto, es adecuado utilizar métodos de aprendizaje profundo para diseñar un sistema de corrección para la corrección inteligente, por lo que el "sistema de corrección aritmética inteligente" viene de esto El "Sistema inteligente de corrección de fórmulas" es principalmente para la corrección de tareas de cuatro operaciones aritméticas simples. Este sistema tiene las funciones de detección, identificación y corrección de fórmulas. El sistema tiene una página visual relativamente completa (como se muestra en las Figuras 1 y 2 a continuación), que puede ejecutarse en computadoras y teléfonos móviles.
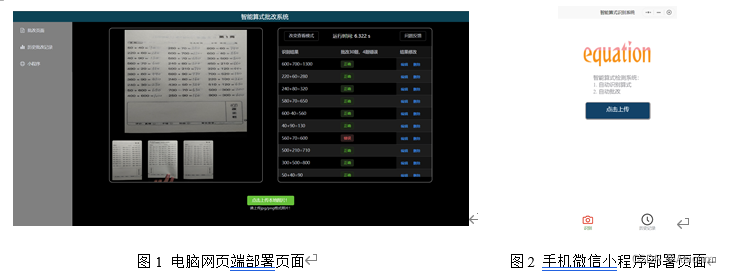
El principio del sistema es usar yolo para detectar la fórmula primero y luego pasar el fragmento de imagen detectado de la fórmula a paddleocr para el reconocimiento de la fórmula. Después de obtener el contenido de la fórmula, use el algoritmo de cuatro juicios aritméticos para juzgar el resultado del cálculo de la fórmula y, finalmente, envíe los datos del índice de la fórmula, los datos de contenido y los resultados del juicio a la página frontal creada por el marco vue3 para visualización. (el diagrama esquemático es como se muestra en la Figura 3 que se muestra). Además, el "sistema de corrección inteligente" también tiene retroalimentación de corrección de errores humanos, funciones de retroalimentación de problemas y funciones regulares de actualización automática del modelo. Para el modelo de reconocimiento, también lo hemos comprimido y optimizado para aumentar la velocidad de razonamiento.
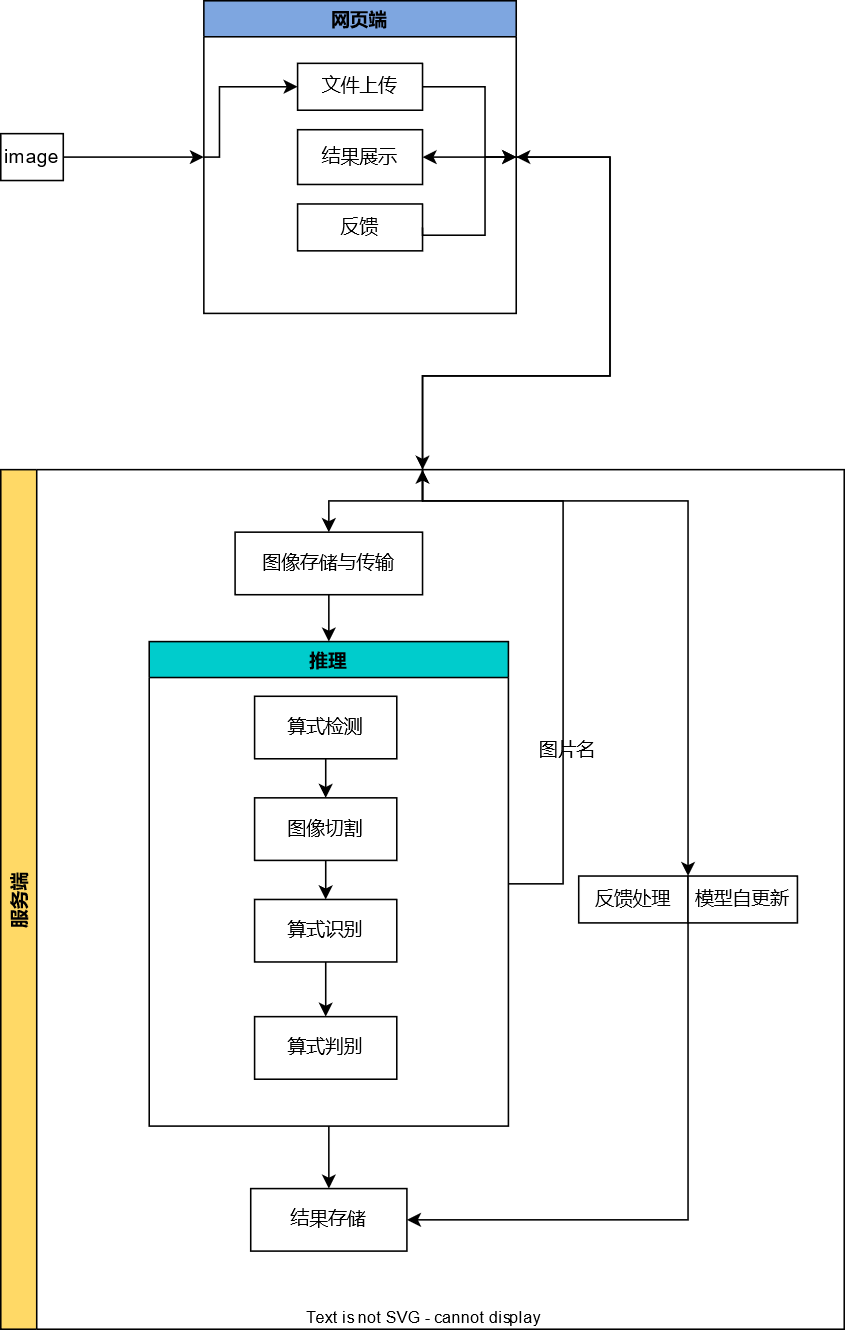
Figura 3 El diagrama de funciones general del "Sistema de corrección inteligente"
1.2 Trabajo relacionado
El desarrollo del "Sistema de corrección de algoritmo inteligente" se divide principalmente en cuatro pasos, a saber, recopilación y etiquetado de datos, entrenamiento de modelos, implementación de modelos y optimización de modelos.
Para la recopilación y el etiquetado de datos, primero completamos un conjunto de ejercicios de matemáticas de la escuela primaria (los resultados de los cálculos manuales no son 100% correctos), luego cargamos fotos del conjunto de ejercicios y usamos la plataforma CVAT para marcar la posición de la fórmula y agregar el contenido de la fórmula al atributo. Después de completar el etiquetado de datos, llevamos a cabo la conversión de formato de datos junto con los conjuntos de datos existentes y dividimos los conjuntos de datos de acuerdo con ciertos métodos.
Para el entrenamiento del modelo, se seleccionó el modelo correspondiente a yolo como modelo de detección de fórmulas, y el modelo en paddleocr como modelo de reconocimiento de fórmulas. Durante el proceso de entrenamiento, el modelo de detección de yolo tiene un buen efecto, pero el modelo de reconocimiento del algoritmo paddleocr tiene un fenómeno de sobreajuste.
Para la implementación del modelo, elegimos el marco vue y element plus para construir la página de inicio.La página de inicio es principalmente responsable de cargar imágenes, obtener resultados y dibujar estadísticas. En cuanto al marco de trabajo de back-end, elegimos el marco ligero de matraz de python, que es principalmente responsable de recibir imágenes, detectar algoritmos, cortar imágenes, identificar contenido y devolver contenido al front-end. Al mismo tiempo, el backend también se sincronizará con los resultados de modificación de los usuarios del frontend, registrará el contenido de los comentarios y tendrá una estrategia de actualización automática del modelo.
Para la optimización del modelo, primero cuantificamos el modelo de reconocimiento de paletas para hacer que el resultado del peso sea más pequeño y más fácil de almacenar y calcular. Además, también construimos un mecanismo de autoactualización del modelo, utilizando las imágenes cargadas y predichas por el usuario como conjunto de datos, cuando el número alcanza un cierto umbral, el programa iniciará el modo de entrenamiento para actualizar los resultados de peso que están más en línea con la realidad para el reemplazo.
-
Anotación de datos basada en CVAT
2.1 Etiquetado de datos
Antes del entrenamiento del modelo, es necesario recopilar un conjunto de datos adecuado y marcar el contenido necesario del conjunto de datos. El "Sistema de corrección de fórmula inteligente" utiliza la página de ejercicios en el libro de ejercicios de aritmética oral de la escuela primaria como el conjunto de datos, en el que el las respuestas se completan manualmente y las respuestas pueden ser correctas o incorrectas. Después de completarlo, toma una foto y guárdala.

Figura 4 Ejemplo de página para ejercicios de cálculo oral
Cargue el conjunto de imágenes de la página del ejercicio guardado en el CVAT del sitio web de anotación de conjuntos de datos compartidos para la anotación de datos.
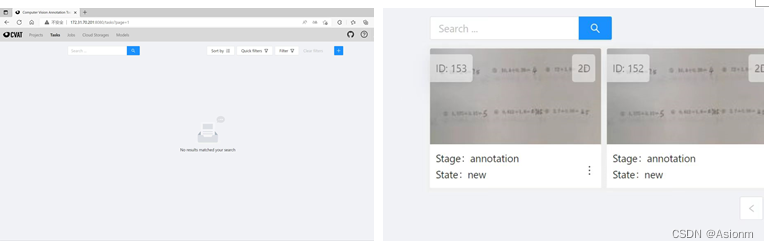
Figura 5 Cargue el conjunto de imágenes guardadas en CVAT
Use la herramienta de etiquetado basada en CVAT para etiquetar, use principalmente un rectángulo para enmarcar la fórmula, el formato es "ecuación", el contenido de la etiqueta es el resultado de la fórmula y el llenado manual, y exporte el resultado del etiquetado a formato xml como un conjunto de entrenamiento para el posterior entrenamiento del algoritmo de detección de objetivos yolo.
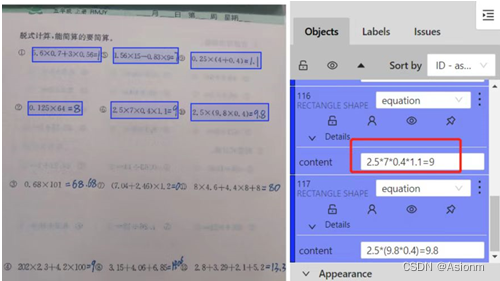
Figura 6 Ejemplo de etiquetado de datos
Para el conjunto de datos de entrenamiento de paddleocr, la imagen original generalmente se coloca en la misma carpeta que la imagen de entrenamiento, y se usa un archivo txt para registrar la ruta y la etiqueta de la imagen. El contenido del archivo txt es el siguiente:
" Información de anotación de imagen de nombre de archivo de imagen "
train_data/rec/train/word_001.jpg contenido de texto 1
train_data/rec/train/word_002.jpg contenido de texto 2
...
Y la ruta de la imagen y la etiqueta de texto deben estar separadas por " ", de lo contrario, se informará un error durante el entrenamiento. La estructura de la ruta del archivo del conjunto de entrenamiento final debe ser la siguiente:
|-tren_datos
|-rec
|- rec_gt_test.txt
|- tren
|- palabra_001.jpg
|- palabra_002.jpg
|- palabra_003.jpg
| ...
2.2 División de conjuntos de datos
El conjunto de datos de reconocimiento de texto paddleocr esta vez utiliza la combinación del conjunto de imágenes de cuatro páginas de ejercicios aritméticos existentes y el conjunto de ejercicios rellenados manualmente, corta la página de ejercicios en bloques que contienen solo la parte de cálculo y registra el contenido del cálculo de la imagen y la ruta de la imagen, y los conjuntos de datos se dividen aleatoriamente 7:3. Tome el conjunto de entrenamiento como ejemplo como se muestra en la figura:

Figura 7 conjunto de entrenamiento paddleocr como se muestra en la figura
-
Diseño de modelo basado en yolo y paddleocr
Detección de objetivos 3.1 yolo
La "corrección de fórmula inteligente" se divide principalmente en tres pasos, el primero de los cuales es ubicar la posición de la fórmula. Así que aquí usamos yolov5 para entrenar el conjunto de datos para lograr el propósito de detectar fórmulas.
3.1.1 Configuración antes del entrenamiento
La configuración antes del entrenamiento incluye principalmente tres contenidos, a saber, conversión de formato de conjunto de datos, archivo de configuración de conjunto de datos y configuración de estructura de red.
- Conversión de formato de conjunto de datos
Primero, se procesa el formato de los datos. Dado que algunos conjuntos de datos están en formato voc, los datos en este formato deben convertirse al formato yolo. Para el formato voc su archivo es de tipo xml, mientras que yolo está en formato txt. Por lo tanto, la conversión de formato es principalmente para extraer la información de coordenadas en el archivo xml en el archivo txt. Para ver el código, consulte conjuntos de datos/personalizado/ conversión de formato /voc2yolo.py en yolov5.zip , el código se menciona principalmente en
[El tutorial más completo] Formato VOC a formato YOLO data_voc a yolo_Blue fat fat ▸'s blog-CSDN blog . El formato de yolo convertido es el siguiente, en el que cada imagen corresponde a un archivo txt, y los valores de las coordenadas se almacenan principalmente en el archivo txt.

Figura 8 formato de etiqueta yolo
- Archivo de configuración del conjunto de datos
Después de transformar el conjunto de datos, edite el archivo de configuración del conjunto de datos. Este archivo se encuentra en yolov5-master/data/equation.yaml en el paquete comprimido yolov5.zip . Su contenido es principalmente para establecer la ruta del conjunto de datos y la categoría de clasificación. Su contenido se muestra en la siguiente figura.

Figura 9 Contenido del archivo de configuración del conjunto de datos
- Configuración de estructura de red
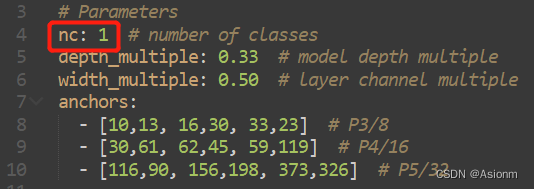
Para la red utilizada para el entrenamiento, elegimos el modelo de red yolov5s Para el modelo original, sus categorías de salida son 80, por lo que aquí debemos cambiar 80 a 1. La dirección modificada es yolov5-master/models/yolov5s.yaml en yolov5.zip . El contenido modificado es el siguiente y el valor de nc se cambia a 1.
|
|
| Figura 10 configuración de la estructura de la red yolo |
3.1.2 Formación modelo
Después de completar la configuración previa al entrenamiento, el siguiente paso es entrenar el modelo. Al principio del entrenamiento del modelo utilizamos nuestro propio ordenador, al no haber tarjeta gráfica el efecto era relativamente pobre, posteriormente compramos un servidor GPU en Tencent Cloud, por lo que migramos los pesos obtenidos del entrenamiento anterior en nuestra propia computadora al servidor GPU para entrenamiento.
El entrenamiento en el servidor GPU primero necesita comprimir la carpeta yolov5 y transferirla al servidor y luego descomprimirla. Después de la descompresión, ingrese el comando cd yolov5/yolov5-master para ingresar a la carpeta, y luego ingrese el comando pip install -r require.txt para instalar el paquete correspondiente.La instalación de pytorch debe consultar el sitio web oficial para instalar la gpu correspondiente versión. Una vez completada la instalación, ingrese el siguiente comando para entrenar. El comando pasa parámetros a train.py, especifica el archivo de configuración del conjunto de datos, el archivo de red del modelo, la ruta del modelo pre-entrenado, el tamaño de procesamiento de la imagen, y el número de épocas.
![]()
La captura de pantalla durante el entrenamiento se muestra a continuación,
|
|
| Figura 11 captura de pantalla del entrenamiento de yolo |

3.1.3 Resultados del entrenamiento
Cuando se completó la ronda 336, dado que no había margen de mejora, el sistema inició la capacitación y guardó los resultados, como se muestra en la captura de pantalla a continuación. El archivo de resultados exp18 se puede encontrar en yolov5-master/runs/train/exp18 en el paquete comprimido yolov5.zip .
|
|
| Figura 12 Captura de pantalla después de completar el entrenamiento de yolo |

Conecte los resultados del entrenamiento en el servidor gpu a las 10 rondas de resultados del entrenamiento local para dibujar la siguiente figura,
|
|
| Figura 13 gráfico de resultados de entrenamiento de yolo |
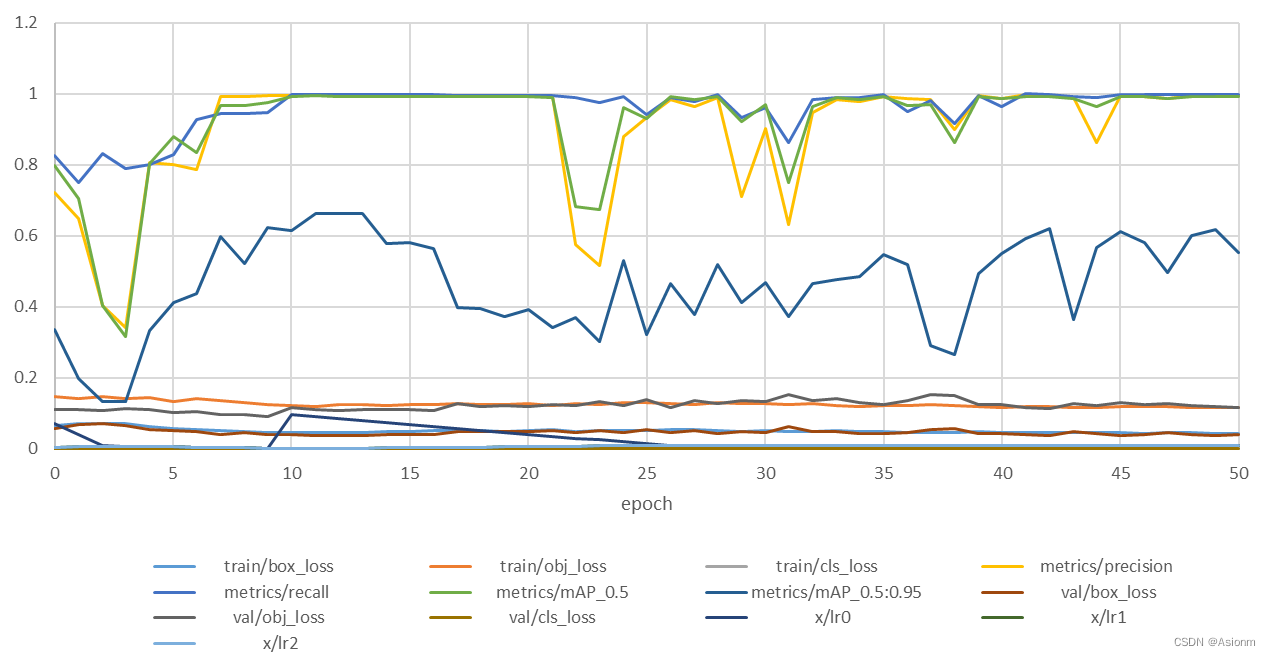
El eje horizontal son las rondas de entrenamiento. Dado que los resultados de las rondas posteriores son básicamente los mismos, las primeras 50 rondas se interceptan aquí, y el eje vertical es el valor de cada indicador. Se puede ver que el valor de map50, el valor de precisión, la tasa de recuperación y otros indicadores mostraron una cierta tendencia a la baja al principio, pero esto fue de corta duración.El valor de este último indicador subió rápidamente a cerca de 0, y luego se estabilizó en 0.9, y estuvo entre 20 y 35. Hay grandes fluctuaciones entre rondas y luego estabilidad regional. En cuanto al índice de pérdida de valor, básicamente tiende a una tendencia a la baja, con algunas fluctuaciones en el medio pero básicamente estable.
Del análisis del gráfico anterior, se puede ver que el modelo de detección de objetivos de yolo básicamente puede manejar bien los problemas de detección del conjunto de datos actual, y su tasa de precisión se mantiene básicamente por encima de 0.9.
3.1.4 Insuficiencia del Modelo y Dirección de Mejora
Aunque el modelo yolo entrenado esta vez puede detectar de manera efectiva las fórmulas en el conjunto de datos, en pruebas posteriores se encontró que no puede manejar de manera efectiva otras páginas de fórmulas que son diferentes del estilo del conjunto de datos, como se muestra en la Figura 9 a continuación. Hay demasiadas palabras en el conjunto de datos original, pero la nueva página de fórmula tiene palabras similares a la forma de la fórmula, por lo que es probable que aparezca la situación que se muestra en la siguiente figura, lo que también muestra que la aplicabilidad general de este modelo es no es bueno. Además, también reconocerá algunos entornos especiales, como la fórmula de cálculo del reverso escrita con demasiada fuerza para que algunas partes se muestren y estén cara a cara.
|
|
|
| Figura 14 Mapa de errores de reconocimiento del modelo |
|

Para esta situación, nuestra siguiente dirección de mejora es aumentar los conjuntos de datos de diferentes categorías y diferentes entornos para mejorar la capacidad de generalización del modelo y, al mismo tiempo, mejoraremos el modelo a través del aumento de datos.
3.2 Reconocimiento del algoritmo paddleocr
3.2.1 Conexión local a recursos de GPU Tencent Cloud
El entrenamiento de reconocimiento de texto de Paddleocr requiere una gran cantidad de conjuntos de datos para el entrenamiento de convergencia, y los portátiles de los miembros del equipo solo tienen una CPU sin una GPU independiente, por lo que la eficiencia del entrenamiento es muy lenta y el efecto es pobre. conecte la computadora a los recursos de GPU en Tencent Cloud para el entrenamiento. Ingrese al sitio web oficial de Tencent Cloud, elija comprar un servidor en la nube adecuado y seleccione una configuración de servidor adecuada. Aquí elegimos el modelo de GPU GN8 adecuado para el entrenamiento de aprendizaje profundo, que incluye memoria de 56G, 6 núcleos y configuración de memoria de 200G.
Figura 15 Servidor GPU utilizado
Después de registrar una cuenta en el sitio web oficial de Tencent Cloud para comprar recursos de GPU, reinstale el sistema como un sistema Ubuntu para facilitar las operaciones de conexión y codificación. Abra el pycharm local, conecte el terminal en ejecución al terminal Ubuntu en el servidor en la nube de Tencent conectándose a la IP de la red pública e ingrese el nombre de usuario y la contraseña para usar los recursos de la GPU del servidor en la nube localmente.
|
|
|
| Figura 16 Conexión a los recursos del terminal Tencent Cloud |
|
3.2.2 Instalar entorno PaddlePaddle
Esta capacitación utiliza como base el sistema maduro de reconocimiento paddleocr de Baidu Feijiang, descarga el marco paddleocr de GitHub (enlazado en la referencia) y lo carga y sincroniza con el sistema Ubuntu en la nube.

Figura 17 El paddleocr descargado
Instale el entorno de paddlepaddle y los paquetes de dependencia correspondientes antes del entrenamiento:
|
|
|
| Figura 18 Instalación de entorno y biblioteca dependiente |
|
3.2.3 Empezar a entrenar
- Descarga y preparación del modelo de entrenamiento
Descargue el modelo de entrenamiento de reconocimiento de texto oficial de paddleocr en gitee, aquí está el modelo de entrenamiento superligero chino e inglés

Figura 19 descarga del modelo de entrenamiento de reconocimiento de texto paddleocr
Seleccione el archivo yml adecuado, cambie la ruta de importación del conjunto de entrenamiento y los datos del conjunto de verificación a la ruta del conjunto de datos previamente dividido y ajuste la cantidad de rondas de entrenamiento, el tamaño del lote y la tasa de aprendizaje.

Figura 20 Archivo yml seleccionado
- modificación del diccionario
Debido a que en el proceso de reconocimiento de fórmulas, el contenido que se reconocerá son solo números y símbolos de operación, por lo que el archivo de diccionario original debe modificarse para que el contenido de la salida del reconocimiento sea solo números y operadores. Aquí debe prestar atención a la particularidad del signo de división, que debe ser el símbolo "÷"
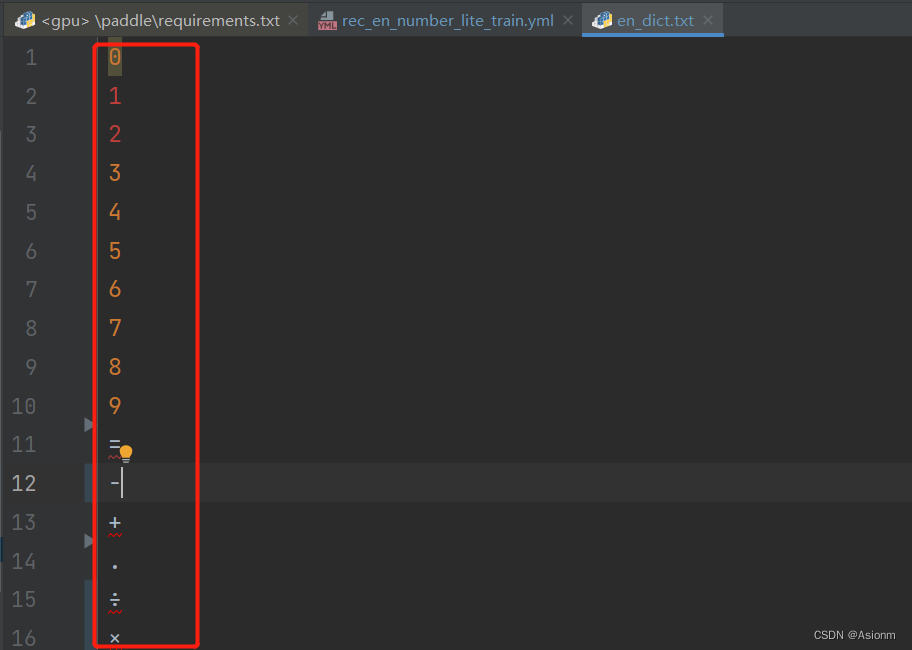
Figura 21 archivo de diccionario
- entrenamiento de fondo
Para iniciar el código de entrenamiento, debe llamar al archivo yml seleccionado y al archivo train.py en la terminal, especificar el modelo de entrenamiento descargado y guardar el mejor archivo de parámetros de peso después del entrenamiento.
# Entrenamiento de GPU
#Training icdar15 El registro de entrenamiento de datos en inglés se guardará automáticamente como train.log en "{ save_model_dir }"
python tools/train.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy
Debido a la conexión de red inestable, es fácil desconectarse durante el proceso de capacitación y hacer que la capacitación falle. Por lo tanto, la capacitación en segundo plano de nohup se utiliza para garantizar la estabilidad y la continuidad de la capacitación. Primero escriba el archivo train.sh, ingrese el código de comando de entrenamiento en el archivo, luego otorgue el permiso de ejecución al archivo sh e importe el resultado de salida en el archivo nohup.out,

Figura 22 Código de comando de ejecución en segundo plano
Posteriormente, el proceso de entrenamiento en tiempo real y los resultados del entrenamiento se pueden observar en el archivo nohup.out generado.
Figura 23 Contenido de salida de nohup.out
3.2.3 Predicción y exportación del modelo
Una vez que se entrena el modelo, es necesario probarlo y predecirlo. Seleccione aleatoriamente una imagen de cuatro ejercicios aritméticos para la detección, se puede ver que el efecto de reconocimiento del modelo es bueno.
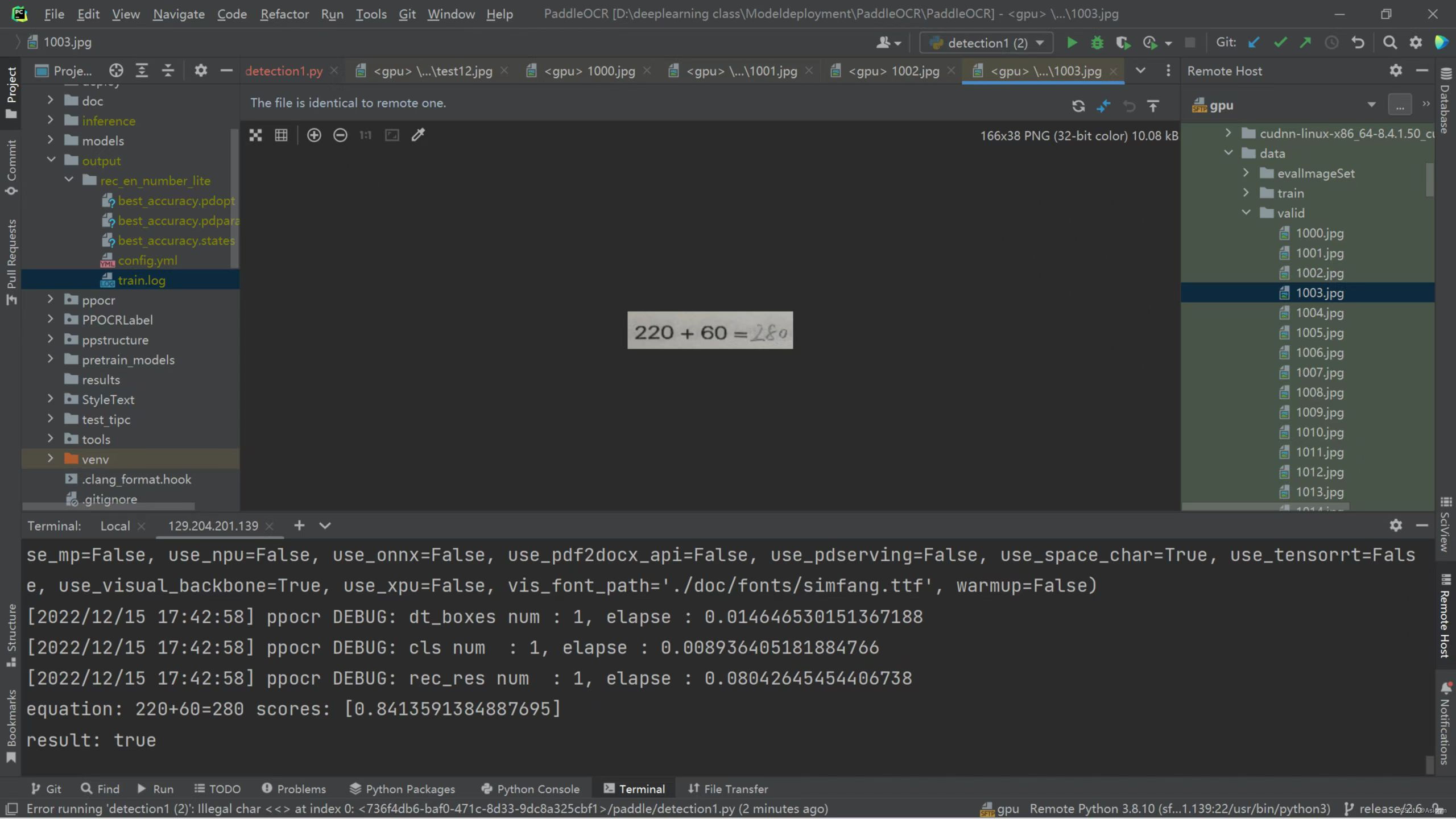
Figura 24 Resultados de detección del modelo de entrenamiento
Para exportar el modelo de entrenamiento entrenado a un modelo de inferencia disponible más tarde, el comando es el siguiente:
# Establecer el archivo de configuración yml del algoritmo de entrenamiento después de -c
# -o parámetros opcionales de configuración
# El parámetro Global.pretrained_model establece la dirección del modelo de entrenamiento que se convertirá, sin agregar el sufijo de archivo .pdmodel , .pdopt o .pdparams .
# El parámetro Global.save_inference_dir establece la dirección donde se guardará el modelo convertido.
python tools/export_model.py -c configs/rec/multi_language/rec_en_number_lite_train.yml -o Global.pretrained_model=output/rec_en_number_lite//best_accuracy Global.save_inference_dir=inference/equation_rec/
El modelo de inferencia exportado está en la carpeta de inferencia.
3.2.4 Algoritmo de discriminación e interfaz de reconocimiento de cuatro operaciones aritméticas
Después de exportar el modelo, para conectar el front-end y la detección de objetivos de yolo, es necesario reconocer el contenido de texto de la fórmula de cálculo del bloque de detección proporcionado por yolo, y analizar si el resultado del cálculo del cálculo es correcto. Parte del código del algoritmo se muestra en la figura y el código completo está en el archivo de detecciónq1.py en el archivo paddleocr. El principio general es extraer los resultados de números, operadores y "=" del contenido de texto reconocido, y luego colocar y operar de acuerdo con el orden de operación de acuerdo con el contenido reconocido, y comparar los resultados de la operación con los resultados del reconocimiento de texto para juzgar si está bien o mal.
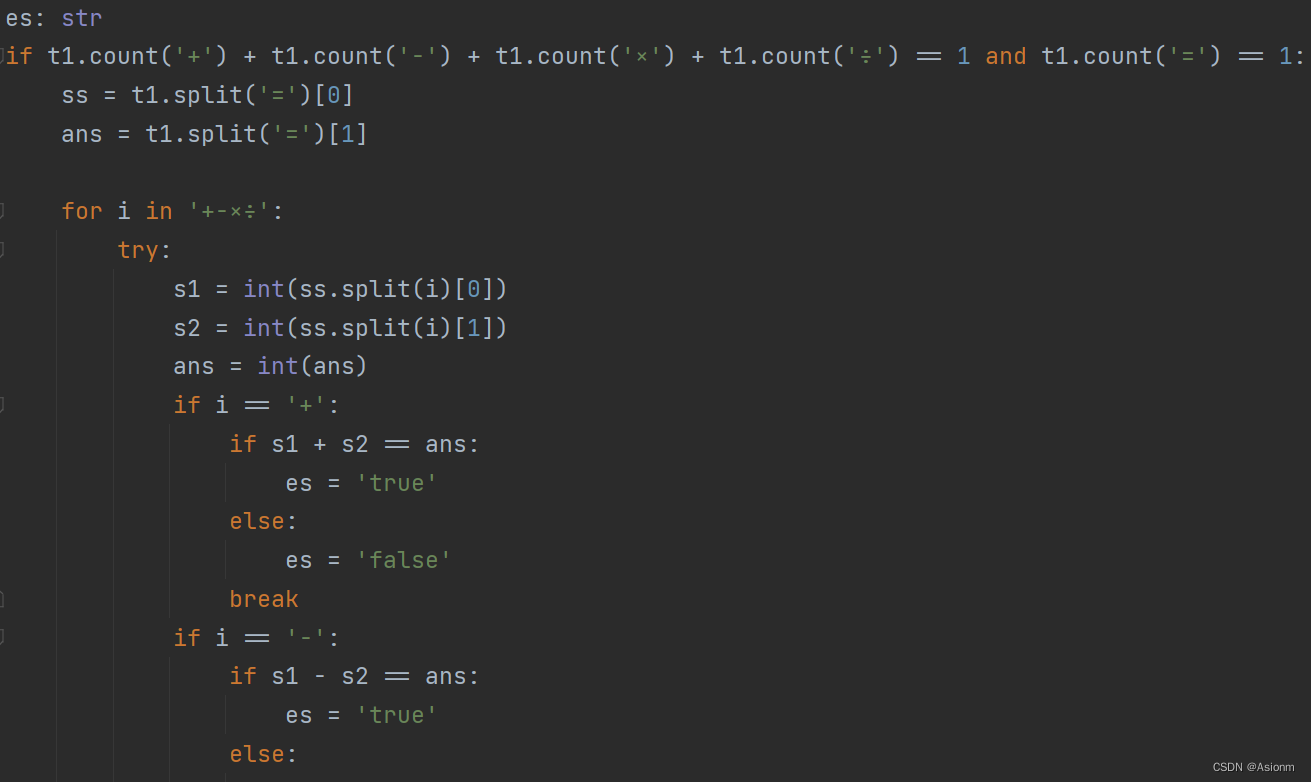
Figura 25 Algoritmo de discriminación para resultados de cuatro operaciones aritméticas
-
Despliegue de modelo basado en Flasc , Vue y Applet de WeChat
Para el despliegue del modelo, hemos implementado el despliegue en la página web de la computadora y el teléfono móvil. La página en la página web de la computadora está escrita usando el framework vue, mientras que el teléfono móvil usa un pequeño programa que usa uniapp basado en vue. Ya sea una computadora o un teléfono móvil, el servidor back-end se basa en el marco del matraz. El proceso de implementación se describirá en detalle a continuación.
backend del matraz 4.1
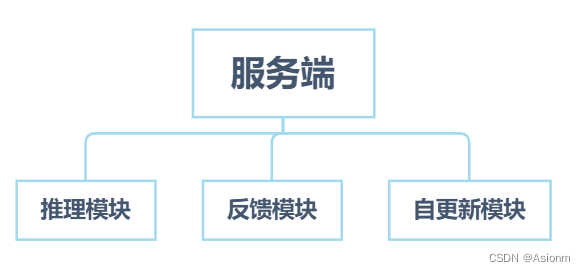
La función principal del backend de Flask es organizar los resultados del razonamiento del modelo y la información de rendimiento en formato json y enviarlos al front-end, y también almacenar información. El backend se divide principalmente en módulo de razonamiento, módulo de retroalimentación y módulo de actualización automática. A continuación, presentaré las funciones y los procesos de ejecución de cada módulo uno por uno.
|
|
| Figura 26 Organigrama del servidor |
- módulo de razonamiento
El módulo de razonamiento es la parte central del servidor y se puede subdividir en tres partes: detección de algoritmos, reconocimiento de algoritmos y corrección de algoritmos. Entre ellos, la detección aritmética se realiza mediante yolo, que se ha descrito en detalle anteriormente. Después de que se detecte cada fórmula, se obtendrá su valor de coordenadas, y el programa usará estos valores para cortar la imagen y transferirla a paddleocr uno por uno para el reconocimiento de la fórmula. La fórmula reconocida será enviada al área de corrección de fórmulas para su corrección, y finalmente se obtendrá el valor de Verdadero o Falso. La parte de procesamiento de imágenes del programa se realiza a través de opencv. Habrá registros de tiempo durante todo el proceso de ejecución de la inferencia para contar el rendimiento de la inferencia y pasar esta información de tiempo al front-end.
- módulo de retroalimentación
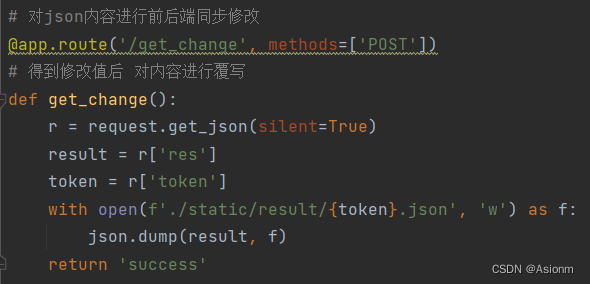
El módulo de retroalimentación desempeña principalmente las funciones de edición de resultados y retroalimentación de funciones. El módulo de comentarios estará vinculado al front-end. Cuando el usuario edite o elimine una fórmula, el front-end enviará los resultados de la edición al back-end, y el back-end actualizará el archivo json del back-end en tiempo real basado en estos resultados El contenido del código se muestra en la Figura 11 a continuación.
|
|
| Figura 27 Código de backend de edición de resultados |
Los comentarios funcionales se ingresarán en el archivo de información de comentarios actual de acuerdo con el contenido enviado por el usuario desde el front-end. Este archivo tendrá el nombre de la fecha en formato txt, y su contenido de muestra se muestra en la Figura 12 a continuación.
|
|
| Figura 28 Documento de texto de fondo de comentarios sobre problemas |

- módulo de actualización automática
El módulo de autoactualización se utiliza principalmente para crear automáticamente conjuntos de datos para el entrenamiento de actualización automática. Construyo este módulo a través del método de una clase llamada update, y su organigrama es el siguiente.
|
|
| Figura 29 Organigrama de clases autoactualizable |

El módulo de inicialización se usa principalmente para agregar una lista de nombres de archivos protegidos y crear una carpeta para guardar. La función de obtener datos json se usa para obtener todos los datos en la carpeta json en la carpeta. La función de juzgar completo se usa para juzgar si el número de imágenes en la carpeta ha alcanzado el número que se puede usar para construir un conjunto de datos, y si está lleno, ejecute el programa. La función del programa en ejecución es la parte central de la clase. Su función es escribir todos los archivos json obtenidos en el archivo label.txt, cortar la imagen y eliminar el archivo original. El módulo de actualización automática solo se puede utilizar para crear el conjunto de datos de entrenamiento y no proporciona una interfaz para el entrenamiento automático, ya que puede requerir una revisión manual de la exactitud del conjunto de datos.
Descripción del código fuente de back-end: el código fuente de back-end se almacena en el paquete de ecuación back -end .zip , entre los cuales server.py es el programa que se utiliza principalmente para ejecutarse, siempre que se utilice el comando python server.py . entrada para ejecutar el servidor. Run.py es el archivo utilizado para la inferencia. Detection.py es un archivo para el reconocimiento de algoritmos y update.py es un archivo para la actualización automática. La carpeta estática se usa principalmente para almacenar imágenes enviadas y archivos de resultados, y la carpeta de comentarios almacena archivos de información de comentarios. El resto de los archivos son los archivos que vienen con incrustación de yolov5 y paddleocr.
4.2 Diseño frontal de Vue
El diseño frontal aquí se refiere al diseño de la página web de la computadora, que se utiliza principalmente para la visualización. Puede proporcionar las funciones de cargar imágenes, recibir, mostrar, editar resultados de razonamiento y comentarios de preguntas. Además, hay algunas páginas de índice sin desarrollar, como las páginas de registro de corrección. A continuación se presentarán principalmente los módulos de funciones de visualización y retroalimentación.
- Visualización de resultados
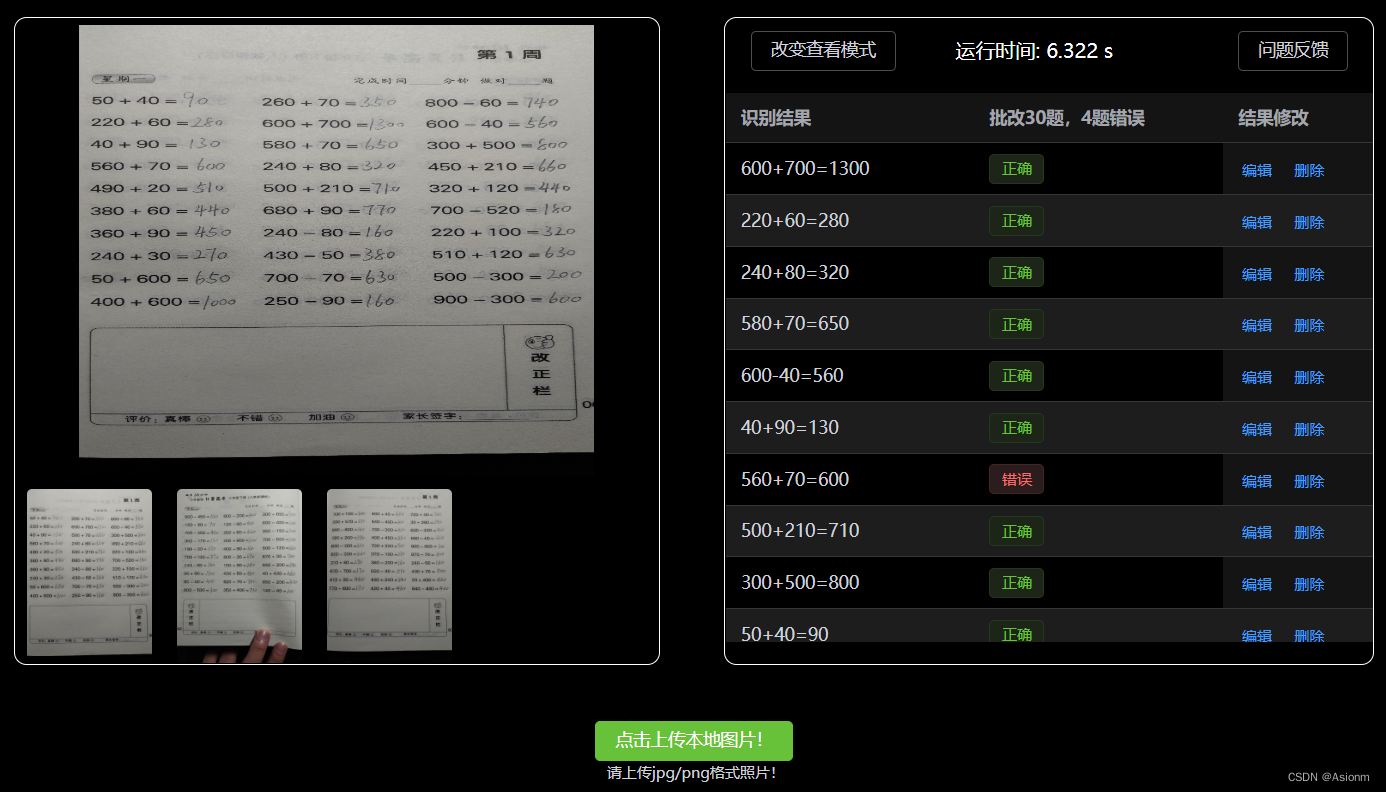
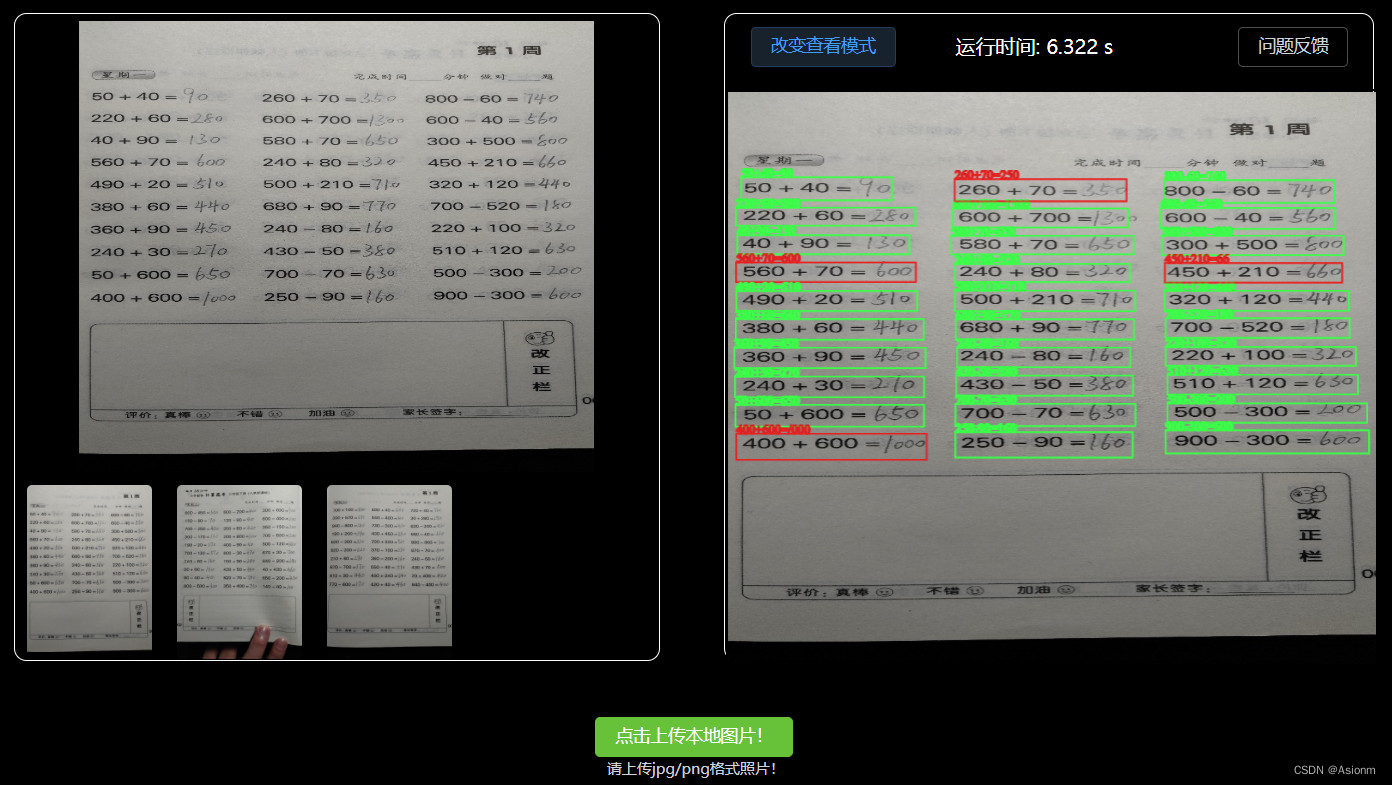
Hay dos modelos de visualización para la visualización de resultados en la computadora web, uno es el modo de texto sin formato y el otro es el formato enmarcado (como se muestra en las Figuras 13 y 14 a continuación).
|
|
|
| Figura 30 Formato de visualización de resultados de texto sin formato |
Figura 31 Formato de visualización de resultados enmarcados |
结果展示页面以及下面的功能反馈页面均集中于一个组件中进行编写,组件的名称为UpdatePart.vue中。展示区的原理是通过axios接收后端传回来包含算式坐标、内容、正确信息、运行效率的信息,然后将这些信息进行渲染统计。其中渲染的页面主要通过element plus和canvas的第三方库fabric.js进行。电脑网页端不仅仅是单张的识别,可以进行多张的切换,且一打开页面时就可以看到三张demo照片。
- 功能反馈
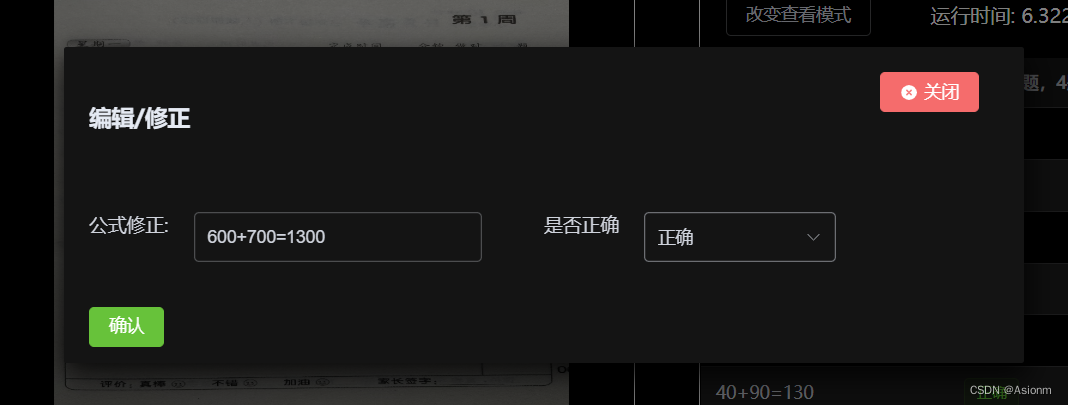
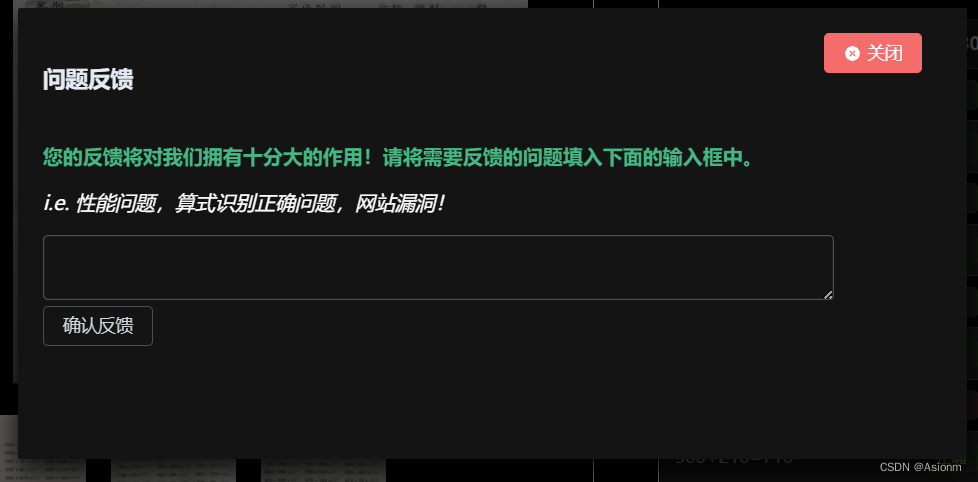
此处的功能反馈包括了算式编辑、删除、功能反馈这几方面,算式编辑删除的页面如下图图15所示,功能反馈如图16所示。
|
|
| 图32 算式编辑页面 |
|
|
| 图33 问题反馈页面 |
每当编辑按钮为确认时,编辑结果状态就会为True然后当切换图片或关闭页面时,前端就会将编辑的信息发送给后端以实现同步。而对于问题反馈,其原理仅仅只是个文本发送的功能。
源码文件说明:若要运行前端程序,需要先用npm i安装相应的以来包。电脑web端的代码在equation.zip处,其中主要的代码存储于src/views处,其包括了主要的几个页面,如索引页面、上传展示页面、未开发的历史页面、小程序页面。而主要的代码是通过组件的形式传到上传展示页面的,此文件位于src/components/Uploader.vue。除此之外src/api主要用于封装axios用于网络传输,src/router文件夹主要存储路由信息,src/main.js是整体的一些配置如引入全局包等等。
4.3 微信小程序设计
微信小程序使用的是uniapp,而其代码基本与电脑端的类似仅仅只是进行了一定的适应性修改。微信小程序的功能相对于电脑网页端的而言只保留了单张推理展示的功能,并未提供编辑结果、功能反馈等的功能。同时由于后端服务器只是为临时性服务器所以并未申请域名于ssl证书所以开真实使用上并不能连接到后端因此目前小程序只存在外观展示。而在开发中小程序的功能已经得以实现,具体的展示视频可见于小程序展示.mp4。具体代码可见于小程序.zip压缩包中,由于功能基本于电脑网页端的一致,因此不再展开描述。
-
模型压缩与自更新策略
5.1 模型优化讨论
对于我们模型中存在的问题,我们已在第三章模型设计中进行了论述。为了解决这些问题,我们将实现一系列的优化方法。为了应对模型的泛化能力不足的问题,我们将从添加各种环境下的数据以构成更庞大的数据集进行训练得到泛化能力更强的模型。而对于推理速度慢的问题,我们将从模型压缩方面考虑,将模型进行量化。将32位浮点数转换为8位置整型数以提升cpu的运行能力,同时也减少模型的体积减缓存储压力。下面将从上面提到的两方面进行详细论述实行。
5.2 模型自更新策略
更大的数据集用于训练,在此处我们通过模型的自更新策略进行。自更新原理已在第四章服务端中的自更新模块进行了论述,因此此处不再进行论述。对于此策略,我们主要通过大批量用户提供的经过一定修改的数据构成新的训练数据集,然后调用paddleocr的训练接口进行进一步的训练,在训练完后经过机器验证或人工验证无误后,将此权重代替旧的。因此模型的泛化能力将会得到提供,此策略主要依靠于用户的使用量,若用户多使用次数也多那么生成的数据集也越大越丰富,相应更新出来的模型泛化能力也会越强。下图为自动构建的数据集截图。主要代码可见于equation后端.zip中的update.py文件。
|
|
| 图34 自动生成数据集截图 |

5.3 paddleocr识别模型模型压缩
复杂的模型有利于提高模型的性能,但也导致模型中存在一定冗余,模型量化将全精度缩减到定点数减少这种冗余,达到减少模型计算复杂度,提高模型推理性能的目的。使用量化后的模型在移动端等部署时更具备速度优势。而 PaddleSlim 集成了模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等多种业界常用且领先的模型压缩功能。
- 安装paddleslim
使用pip 下载2.3.2版本
pip3 install paddleslim==2.3.2

图35 paddleslim安装
- 量化训练
将训练好的模型进行量化训练,量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,以PPOCRv3检测模型为例,训练指令如下:
python deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model='ch_PP-OCRv3_rec_distill_train/best_accuracy' Global.save_model_dir=./output/quant_model_distill/
- 导出模型
在得到量化训练保存的模型后,我们可以将其导出为inference_model,用于预测部署:
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_rec_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
5.4 后期优化讨论
目前的模型仍拥有很大的优化提升空间,目前模型的推理速度仍可以进一步提升。后期我们将通过知识蒸馏的方法尝试使用更小地模型尝试更进一步加快推理速度。除此之外,目前算式识别的内容仅仅只是四则运算内容,而后期若要提高其实用性,那么就不仅仅只是四则运算,还希望能够识别如微积分运算、对数运算、复合运算等更复杂的公式判别和结果判断,所以下一步我们也将引入latex格式公式以求进一步优化模型。
结论
本文中识别模型部分主要架构为yolo目标检测和paddleocr文本识别,而在训练过程中遇到了非常多的问题,包括数据集格式、训练集和数据集导入路径问题,以及在训练后检测效果差的问题。对于paddleocr,由于训练集模板数量仍不足够,且训练的时间成本高,发生了训练过拟合、检测结果出现中英文等等问题,逐个原因排查后,训练后的模型的检测效果和不同场景、不同纸张与不同字迹的识别准确度仍有很大的进步空间,初步分析为有选用的paddleocr中的训练模型CRNN网络结构仍有待针对性的调整、数据集的选用、数据预处理的合理性以及是否考虑数据增广等等因素。整体智能批改习题的核心识别部分有待进一步的改进和完善。