보간 알고리즘과 피팅 알고리즘의 차이점:
보간 알고리즘 : 얻어진 다항식 f(x)는 모든 샘플 포인트를 통과해야 함
피팅 알고리즘 : 얻어진 다항식은 반드시 모든 샘플 포인트를 통과하는 것은 아니지만 오차가 충분히 작을 경우
피팅 알고리즘은 최소 제곱법을 사용함 , 먼저 최소 제곱법 (Qingfeng 씨와 자신의 이해에 의해 설명됨)을 설명 하겠습니다
. 최소 제곱법 : 일부 샘플 포인트를 (Xi, Yi)로 설정합니다. 여기서 i=1,2,3,...n 피팅 곡선을 y=kx+b로 합니다. 오차를 충분히 작게 만들려면 샘플 포인트와 피팅 곡선을 가장 가깝게 만들기 위해 k와 b의 특정 값이 있는지 확인하기만 하면 됩니다.

위 그림은 1. 먼저 말씀드리 자면
** 왜 최소값을 취하는지, **이것도 피팅알고리즘의 정의를 기반으로 하기 때문에 샘플의 모든 포인트를 통과할 수는 없지만, 가장 작은 오차를 보장하기 위해 샘플과 피팅 곡선이 가장 가깝습니다. 기하학적 측면에서 수학에 관해서는 y=kx+b에서 실제 y와 계산된 y^의 차이가 가장 작습니다.
2 이런 이유로 일반적으로 두 번째 정의를 많이 사용하는데 첫 번째 정의는 절대값을 가지고 있어 도출이 쉽지 않고 계산이 복잡하고 두 번째 정의는 비교적 단순하고 응용에 적합하기 때문에
3. 제곱 , 세제곱, 네 번째를 사용할 수 있습니까?
첫째, 세제곱은 양수와 음수로 나눌 수 있으며 y 값의 차이에 영향을 미칩니다.합과 덧셈이 영향을 미칩니다.네번째 거듭제곱 이론도 가능하지만 개별 점의 편차가 너무 커서 피팅 곡선에 너무 많은 영향을 미치고 유도하기가 쉽지 않기 때문에 일반적으로 이차 거듭제곱을 사용합니다.위 공식을 변경하여 다음을 얻습니다
. 공식:
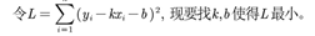
(L은 기계 학습에서 손실 함수라고 하며, 회귀에서는 종종 잔차 제곱합이라고 합니다.) 다음
그림은 k와 b를 최소화하기 위한 k와 b의 유도를 보여줍니다.

관련된 모델링 코드는 다음과 같습니다.
k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))
b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))
점 곱셈에 주의하십시오 .R의 제곱 과 관련된 몇 가지 코드를 설명하겠습니다
(적합도는 결정 계수라고도 함) .

y_hat = k*x+b; % y的拟合值 mean为取平均值作用
SSR = sum((y_hat-mean(y)).^2) % 回归平方和
SSE = sum((y_hat-y).^2) % 误差平方和
SST = sum((y-mean(y)).^2) % 总体平方和
SST-SSE-SSR % 5.6843e-14 = 5.6843*10^-14 matlab浮点数计算的一个误差
R_2 = SSR / SST
여기서 선형성에 대한 두 가지 해석이 있습니다: 매개변수에 대한 선형 과 변수에
대한 선형 사고 : y=a+bx^2는 선형 함수입니까?
답: 매개변수에 대해 선형이면 선형이고 변수에 대해 선형이면 선형입니다.
피팅 알고리즘에서 언급한 선형성은 매개변수에 대해 선형적이며 여기서 특별한 주의를 기울여야 합니다. (
Ab , a^2는 선형이 아니며 지수 함수는 괜찮습니다.)
지금까지 피팅 알고리즘에 사용되는 몇 가지 개념과 요구 사항에 대해 간단하게 이해하였으며, 다음 글에서는 계속해서 피팅 알고리즘에 대해 이야기하고 작은 주제를 실제로 운용해 보도록 하겠습니다.