Equipo: AP0200023
Tabla de contenido
1. Optimización de exportación de modelos
1.1 Volcar el modelo original directamente y convertir
1.2 Preprocesamiento del modelo de exportación
1.2.1 Cambiar tamaño de exportación
1.2.2 Normalización de exportaciones
1.3 Post-procesamiento después de exportar el modelo
1.3.1 Cambiar tamaño de exportación y
1.3.3 Función de exportación a RGB
1. Determinar la línea de base
Resumen de resultados de semifinales
3. Resumen de los problemas encontrados
3. ERROR del código de razonamiento MLIR 【ya resuelto】
4. Algunas reflexiones y sugerencias
preliminares
1. Optimización de exportación de modelos
1.1 Volcar el modelo original directamente y convertir
Informe de error Problema de entrada del nodo Pad, modifique el código fuente para resolver el informe de error
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2], mode="constant",
value=0)1.2 Preprocesamiento del modelo de exportación
1.2.1 Cambiar tamaño de exportación
x = F.interpolate(x, (h // 2, w // 2), mode='bilinear')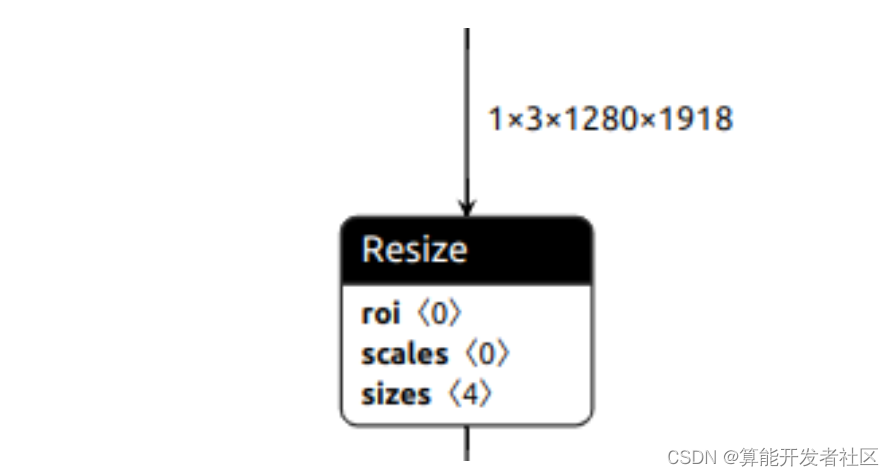
El Unet original cambia el tamaño con la entrada UINT8, pero esta operación no se puede exportar directamente a ONNX, por lo que probamos el cambio de tamaño FP32 y el cambio de tamaño normalizado FP32, así como el modo de cambio de tamaño bicúbico bilineal.
La cadena de herramientas no es compatible con bicubic. El resultado final de usar bilineal es muy diferente.
1.2.2 Normalización de exportaciones
x = x / 255.0 # 1.导出除法
x = x * (1.0 / 255.0) # 2.导出乘法
param = self.unet.inc.double_conv[0].weight / 255.0
self.unet.inc.double_conv[0].weight = torch.nn.Parameter(param,
requires_grad=False) # 3.首层卷积权重/ 255.0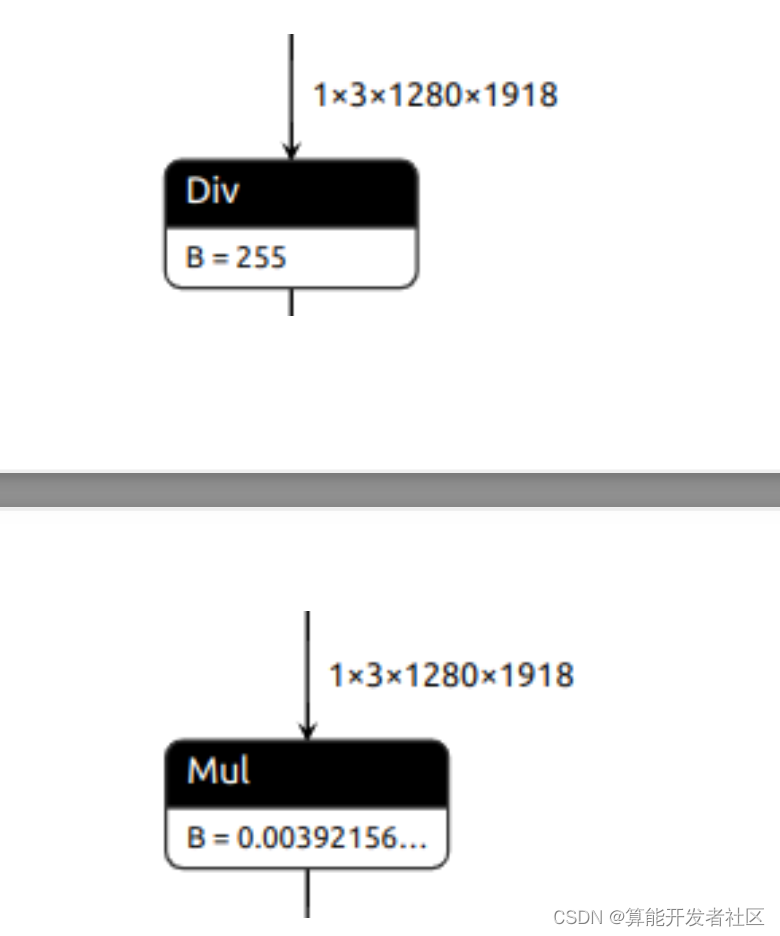
Las tres operaciones de normalización anteriores tienen poco impacto en el consumo total de tiempo El tercer método es el más rápido, FP32, pero puede haber problemas con la cuantificación INT8.
1.2.3 Exportar BGR2RGB
Después de la prueba, OpenCV + slicing es más rápido que PillowSkimage para leer imágenes, así que considere transferir BGR2RGB a ONNX y use el operador Gather para implementar.
param = param[:, [2, 1, 0], ...]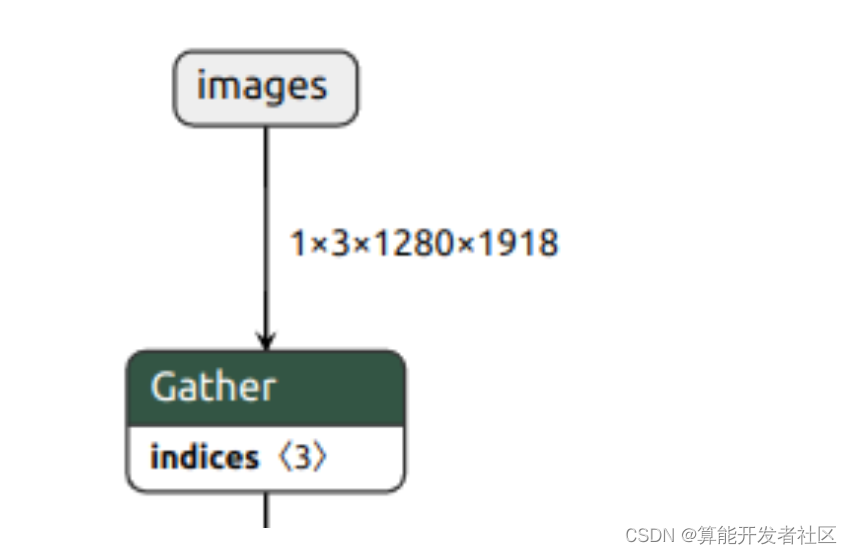
El uso de Gather generará copias adicionales y luego mejorará para invertir el orden de la primera capa de núcleos de convolución, que es la más rápida sin efectos negativos.
1.3 Post-procesamiento después de exportar el modelo
1.3.1 Cambiar tamaño de exportación y
El pretratamiento es similar.
1.3.2 Exportar ArgMaxout
out = out.argmax(-1)El error de conversión del modelo no es compatible con ArgMax y la implementación es la siguiente:
out = torch.lt(out[0, 0], out[0, 1]) # Gather + Less
out = self.conv(out) > 0 # Conv + Greater
Intente construir Conv para darse cuenta de la diferencia entre dos canales. Conv puede ejecutarse en INT8, que es más rápido.
conv = nn.Conv2d(2, 1, kernel_size=1, stride=1, padding=0, bias=False)
conv.weight = nn.Parameter(
torch.tensor([-1, 1]).to(conv.weight).reshape(conv.weight.shape),
requires_grad=False)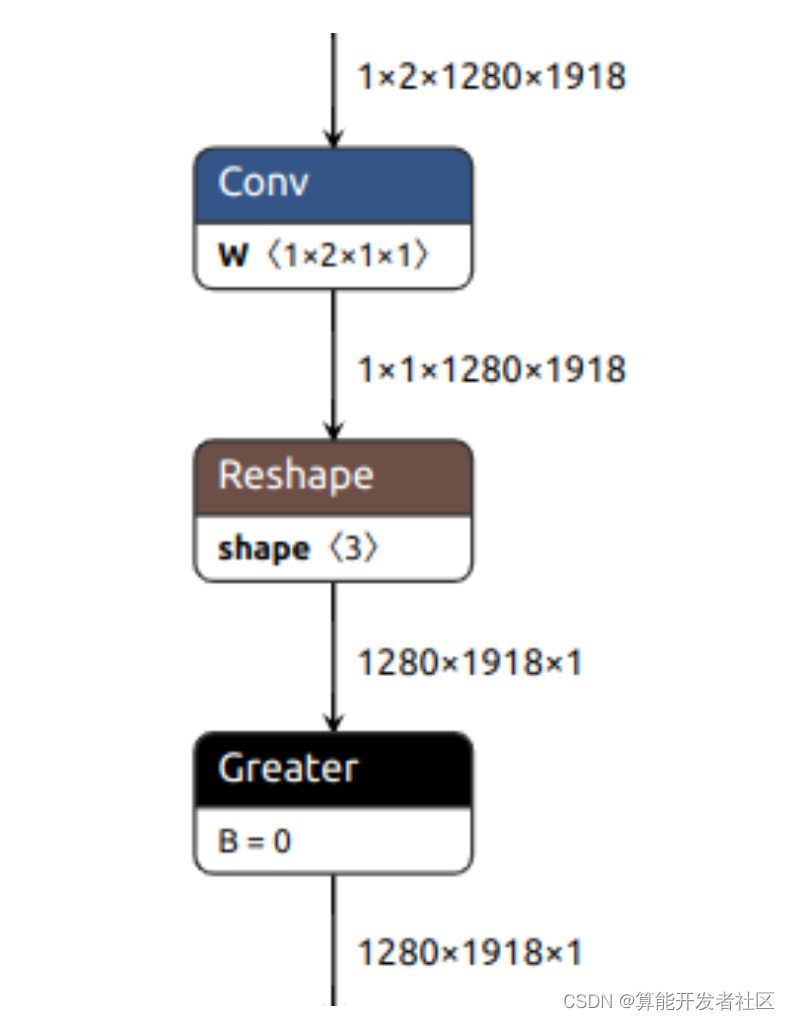
1.3.3 Función de exportación a RGB
out = out.to(torch.uint8) * 255
out = torch.cat([out, out, out], -1)revancha
1. Determinar la línea de base
En la descripción de la revancha, prevalecerá la velocidad de carrera del modelo, por lo que no se utilizará mucho trabajo en la ronda preliminar. Esto se convirtió en una optimización pura del modelo UNET.
Uso UNET-Scale1.0 para ingresar 1918x1280 para la conversión y cuantificación del modelo, y finalmente lo uso como línea base.Los resultados son los siguientes:
flops: 3604915801600, runtime: 204.196060ms, ComputationAbility: 17.654188T
195.027445 0.992235 204.196060 1.675526e+09 2023-02-04La puntuación DICE del modelo es alta y el resultado predicho por el modelo se utiliza como GT.
2. Modelo de optimización
1. Después de la observación, se encontró que las 16 veces de reducción de resolución en el modelo causaron que la entrada de 1918 no fuera divisible, lo que resultó en un relleno adicional, así que traté de ingresar 1920x1280 para probar la velocidad del modelo. Dado que la imagen de entrada es de 1918x1280, si se redimensiona directamente, causará distorsión. Elegimos rellenar 2 píxeles en la parte inferior, y el resultado es el siguiente:
0.992251 199.453278 1.675657e+09 2023-02-06Se puede ver que la puntuación DICE del modelo ha mejorado y la velocidad de detección se ha vuelto más rápida, con una puntuación final de 200.
2. Optimización de la desconvolución
Además, para resolver el problema del relleno adicional generado por la reducción de muestreo 16 veces, intente mover el relleno a ConvTranspose. Consulte la introducción de ONNXop para saber que se puede establecer la propiedad de relleno de salida _.
0.742231 199.346721 1.675677e+09 2023-02-063. Cuando anuncié los resultados de la primera ronda, descubrí que otros equipos obtuvieron puntajes muy altos. El puntaje DICE del modelo fue de 98 a 99, y el puntaje de razonamiento fue de alrededor de 30 a 40. El puntaje final fue mucho más alto que el mío, así que También opté por reducir la resolución.
Use Scale1.0 y 640x959640x960 para obtener los siguientes resultados:
0.776212 42.033154 1.675665e+09 2023-02-06
0.777545 39.177540 1.675695e+09 2023-02-06El puntaje de velocidad es muy bueno, pero el puntaje DICE es muy bajo, se sospecha que es causado por el modelo Scale1.0, y luego use el modelo Scale0.5 para continuar la prueba.
0.990611 41.376142 1.676272e+09 2023-02-13
0.990987 39.177540 1.676293e+09 2023-02-13Tanto la puntuación de velocidad como la puntuación de precisión han subido, alcanzando los 360 puntos.
4. Continúe reduciendo el tamaño de entrada
Para asegurar que la relación de ancho y alto de entrada sea 3:2 e intentar satisfacer el múltiplo de 16, probé las siguientes combinaciones

Los experimentos han encontrado que cuando el tamaño es de alrededor de 560x368, el modelo aún puede mantener la precisión, y cuando el tamaño es más pequeño, la precisión cae más.
5. Procesamiento mejorado antes y después de la segmentación
La lista se actualizó en los últimos días de la competencia, y luego se siguió reduciendo el tamaño de entrada para competir por la lista, finalmente se fijó en 304x208, lo que satisface el múltiplo de 16 y la relación de aspecto de 3: 2.
Después de la evaluación local, se encontró que la pérdida de precisión era muy grave, y luego se comenzó a optimizar el procesamiento previo y posterior.
(1) Pretratamiento
Debido al pequeño tamaño de la imagen, los resultados del método Redimensionar son diferentes.

Los resultados obtenidos al usar INTER_CUBICINTER_LINEARINTER_NEAREST son similares a la imagen de la izquierda, y el área de ruido es más grande.Usar INTER_AREA es como la imagen de la derecha, y el ruido es pequeño.
(2) Posprocesamiento
Dado que la red tiene un puntaje alto para la predicción de ruido durante el procesamiento posterior, habrá cierta confusión después de usar ArgMax, por lo que uso una operación similar a SoftMax para establecer los resultados de predicción que están cerca del valor de detección y dentro de un cierto rango como el fondo El código es el siguiente:
bg, qg = out[..., 0], out[..., 1]
diff = bg - qg
flag = diff < 0
mi = np.abs(out).min(axis=2)
new_flag = diff[flag] / mi[flag] < -thres
diff[flag] = -new_flag.astype(np.float32)(3) Eliminar campos Unicom redundantes
Después de filtrar la diferencia dentro de un cierto rango, se puede reducir la detección de ruido. Después de varios conjuntos de experimentos, finalmente se confirma que thres es 2.2. Además, hay áreas redundantes en los resultados pronosticados, como se muestra en la figura:

Las regiones redundantes se pueden evitar filtrando regiones que no sean la región de dominio conectado más grande.
def remove_no_connected_gray(gray):
num_labels, labels, stats, centroids =
cv2.connectedComponentsWithStats(gray, connectivity=8)
quyuId, pixNums = np.unique(labels, return_counts=True)
mask_background = quyuId != 0
quyuId, pixNums = quyuId[mask_background], pixNums[mask_background]
if quyuId.shape[0] == 1:
return np.ones_like(gray)
else:
maxId = quyuId[pixNums.argmax()]
mask = (labels == maxId).astype(np.uint8)
return mask(4) Para la predicción de que el borde no es liso, como se muestra en la figura:

El uso de la apertura morfológica y el filtrado gaussiano puede suavizar los bordes y eliminar las protuberancias:
out = cv2.medianBlur(opening, 9)Experimentó con varios tamaños de kernel de filtro, 3/6/9/11/13 encontró que cuanto más grande es el kernel, mayor es la precisión y finalmente eligió 9 para lograr una mejor puntuación.
(5) Operación morfológica para eliminar otros ruidos
Después del filtrado y otras operaciones, la imagen aún tiene problemas como bordes prominentes, agujeros dentro del mapa de segmentación y bordes anormales.Finalmente, se utilizan operaciones morfológicas para mejorarla. La erosión se usa para eliminar las protuberancias de los bordes y la dilatación se usa para llenar los agujeros de la imagen.

kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (k, k))
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (k, k))
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, 1)De manera similar, el núcleo de filtro (círculo cruzado ovalado), el tamaño del núcleo de filtro 3/6/9/11/13, etc. se confirman a través de múltiples conjuntos de experimentos.
Muchos hiperparámetros, como los umbrales y el tamaño y la forma del núcleo del filtro, son las soluciones óptimas determinadas por el experimento local y la puntuación de dados de cálculo de GT obtenida por BaseLine. El resultado final del último commit es el siguiente:
391.288683 0.952803 3.991613 1.677598e+09 2023-02-28Resumen de resultados de semifinales
Después de varias presentaciones, se puede analizar que la diferencia en el puntaje DICE del modelo es pequeña, todo entre 95-99 puntos, y la fluctuación no supera los 5 puntos, pero la entrada de diferentes tamaños en el puntaje de tiempo puede traer 1-200 Por lo tanto, la brecha solo está disponible en el capítulo de contexto de la dimensión de entrada. Dado que el procesamiento frontal y posterior no toma tiempo, finalmente elegí el tamaño de entrada de 304x208 y mejoré el módulo de procesamiento posterior para lograr el modelo más rápido en esta competencia y el cuarto lugar en la puntuación total.
3. Resumen de los problemas encontrados
1. ONNX a MLIR
1.1 Después de registrar el preprocesamiento en ONNX, debe cambiar --mean0,0,0--scale1,1,1-pixel-formatbgr1.2 Resize / ArgMax en ONNX no es compatible con MLIR, reemplace otros operadores en 1.3ONNX The Pad carece de parámetros e informa de un error. El PyTorch modelo 1.4 modificado no es compatible con el formato de datos UINT8. Esta parte genera imágenes y las coloca en la CPU.
2. MLIR a bmodelo
2.1 Al compilar el modelo de cuantificación simétrica: si la configuración de tolerancia es demasiado alta, la compilación fallará y la puntuación se reducirá a 0,80. 2.3 Al compilar el modelo, el tamaño grande lleva mucho tiempo y el razonamiento también lleva mucho tiempo.Finalmente, elija un tamaño pequeño.
3. ERROR del código de razonamiento MLIR 【ya resuelto】
Hubo un problema con el código de razonamiento MLIR proporcionado en la etapa inicial de la competencia, lo que provocó que no se enviara una presentación. Posteriormente, el código oficial modificado y actualizado fue normal.
4. Algunas reflexiones y sugerencias
1. Se espera que la herramienta model_transform implemente los OP de preprocesamiento de datos comunes admitidos por TPU. Si la normalización y la conversión de canal se usan como OP separados, entonces no hay necesidad de escribir implementaciones de CPU.
2. Espero que model_transform pueda proporcionar el nombre del OP y otra información cuando encuentre un informe de error, para ubicar el problema convenientemente y el informe de error pueda ser más detallado.
3. Espero que las herramientas run_calibration y model_deploy puedan aprovechar al máximo la CPU multinúcleo. Al usar las herramientas anteriores, la utilización de la CPU es alta en algunas etapas, y solo se usa un núcleo en algunas etapas. Supongo que esta parte se debe al código de Python restringido por GIL. , puede intentar mejorar Pybind11.
4. Se espera que el modelo compilado pueda revertir la fusión y pasar a generar un tpuop onnx para visualizar la estructura del modelo.
5. Se espera que la CPU pueda hacer un uso completo de multinúcleo al simular el razonamiento de TPU. El razonamiento de imágenes a gran escala consume demasiado tiempo y tarda algunas horas en comenzar.
6. Se espera que el archivo de perfil obtenido al probar bmodel pueda visualizar los resultados a través de páginas web u otros formularios, actualmente el análisis solo se puede ver línea por línea.
7. Espero que en la revancha futura, puedas personalizar muchos trucos como la primera ronda. La revancha es demasiado monótona y no muy útil.