¡Desplegar a bordo! Esta palabra debe ser la máxima prioridad de todas las principales empresas de conducción autónoma en 2023. ¡A través de la optimización de la implementación del modelo, el modelo de punto flotante que entrenamos puede ejecutarse en el hardware del automóvil más rápido y mantener un alto rendimiento! Los amigos que recién comienzan a meterse en el pozo definitivamente pensarán en el procesamiento paralelo y ¿qué es CUDA? ¿Cómo se implementa CNN? ¿Qué debo hacer si Transformer toma demasiado tiempo? ¿Qué debo hacer si el NMS es demasiado lento? ¿Cómo hacer la optimización de posprocesamiento? ¿Cómo implementar el modelo BEV en el vehículo? ¡Se trata de las preguntas, se trata de los detalles!
Dado que hay muchos módulos de percepción involucrados en la conducción autónoma, como clasificación, segmentación, detección 2D/3D, líneas de carril, puntos clave, seguimiento, etc., pero al final debe pasar por la implementación y optimización del modelo antes de que realmente pueda ser implementado. Por lo tanto, el despliegue y la optimización de modelos es una de las direcciones más desafiantes en el campo de la conducción autónoma o visión por computadora, ¡y también es la dirección que mejor refleja las capacidades de ingeniería! Además, a medida que el país apoya vigorosamente el desarrollo de la industria de vehículos de nueva energía, en los últimos dos años han aparecido empresas emergentes relacionadas con CV/conducción autónoma/conducción inteligente en grupos.
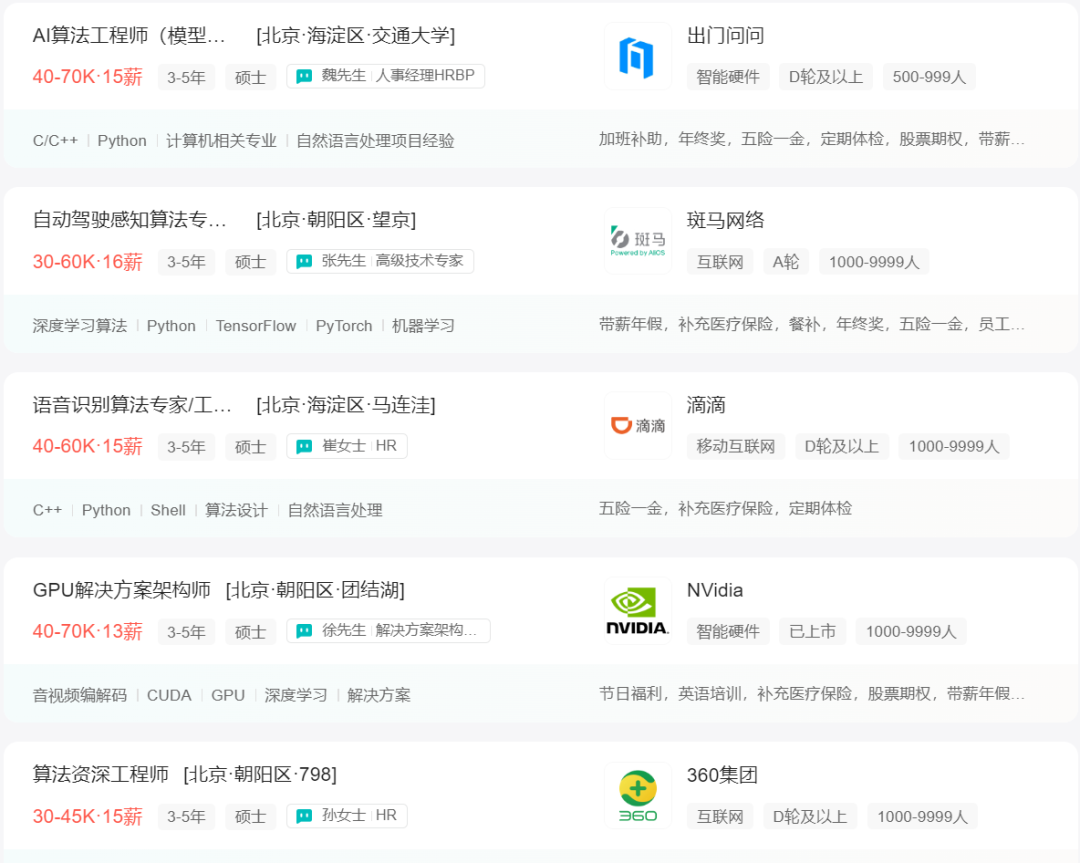
La economía se recuperará en 2023, y las principales empresas también aumentarán su contratación para puestos relevantes. Acabo de ver un sitio web de contratación, y el salario mensual promedio de puestos relacionados ha llegado a 40,000, y el salario anual es de 600,000. ¡Hay muchos puestos de alto nivel con un salario anual de un millón!
¿Aprender es difícil?
Durante este período de tiempo, muchos amigos han consultado sobre la implementación de modelos. De hecho, también estamos muy interesados en la implementación de modelos. La calidad de los materiales de aprendizaje relacionados con la implementación de modelos en el mercado es desigual. Pisó más pozos:
La comprensión del procesamiento paralelo de GPU no es lo suficientemente completa y no sé cómo iniciar la programación CUDA...
Tratando de entender el principio, pero no sé en qué escena debe usarse;
El efecto esperado de aceleración y optimización en la medición real está lejos del resultado esperado, y todavía es imposible averiguar qué salió mal.
En el proceso de autoaprendizaje, se encontrará con varios problemas. El transformador ONNX no se puede transferir a TRT, las versiones de CUDA y TRT no coinciden, varias fallas en los segmentos, tiene problemas con el código fuente abierto y no puede encontrar una solución. Los amigos todos tienen un profundo entendimiento;
... ...
Después de analizar los puntos débiles de todos en el proceso de aprendizaje, Heart of Autopilot y el Dr. Han Jun de la Universidad de Waseda produjeron conjuntamente el curso "Aceleración CUDA e implementación de TensorRT". Si desea aprender la implementación de modelos, o sufre una caída grave del modelo que implementa, no sabe cómo optimizar, lo que requiere mucho tiempo y carece de experiencia práctica en proyectos, entonces debe estudiar este curso. el contenido presenta en detalle el procesamiento paralelo, la implementación real de GPU, CUDA y TensorRT.
El curso comienza con el procesamiento paralelo más básico y la arquitectura GPU, y luego con la introducción de CUDA y cuDNN, escribiendo su primer programa CUDA, y luego con la introducción básica del uso de TensorRT y API. Transformador), implementación del detector de la serie YOLO y una explicación detallada de la implementación del modelo pesado BEVFusion. Después del curso, también está planeado agregar el proceso de creación del complemento TensorRT, explicar el analizador de TensorRT, TVM y otros compiladores en detalle, ¡e implementar en el dispositivo Edge! Lleno de productos secos, realmente ayuda a los estudiantes con base cero a aprender de manera eficiente y rápida a dominar cada punto del conocimiento.El esquema del curso es el siguiente:

caracteristicas del curso
Cobertura completa de la dirección de CV
¡Ataque directamente los problemas de implementación del modelo, como la clasificación de imágenes, el transformador, la detección de objetos y la percepción de BEV, teniendo en cuenta los campos de la visión por computadora y la conducción autónoma!
Combinando la teoría con la práctica
Combinación de combate real y teoría del proyecto, y el código de combate real después de la clase del curso de combate real, que se puede dominar rápidamente después de aprender y practicar.
Un total de 5 grandes proyectos de combate.
El curso incluye un servicio completo de [docente enseñando] + [docente asistente respondiendo preguntas] para garantizar que cada pequeño compañero pueda aprender felizmente el conocimiento.
Combate práctico 1: programación CUDA, optimización del cálculo matricial, optimización del preprocesamiento y posprocesamiento, y reparto de trampas;
Combate 2: Introducción al uso de la API TensorRT C++ y análisis de rendimiento del modelo Nsight;
Combate 3: Implementación y optimización de Clasificadores: implementación de CNN, implementación y optimización de Transformadores;
Combate 4: Despliegue y optimización de YOLO v8: despliegue de detección/segmentación, optimización de procesamiento previo/posterior, análisis de cuello de botella del modelo y estrategia de optimización;
Combate 5: implementación y optimización del proyecto de código abierto BEVFusion: explicación detallada del marco BEVFusion, implementación NVIDIA-AI-IOT y análisis de BEVFusion.
Los códigos de material didáctico están fácilmente disponibles
¡Para una explicación detallada, no solo la teoría, sino también el código y la práctica deben explicarse a fondo! A través de un conjunto completo de explicaciones en video, lo ayudará a construir el marco básico del modelo en su mente y comprender a fondo cada punto de conocimiento, mejorando así la eficiencia y la velocidad de escritura de código.


instructores
Han Jun, graduado de la Universidad de Waseda con un doctorado, actualmente es investigador y profesor en la Universidad de Waseda, y está afiliado al departamento de investigación y desarrollo de aprendizaje profundo de una empresa líder en conducción autónoma en Japón. Durante su período de doctorado, se centró en la optimización de compiladores, el procesamiento paralelo, la programación lógica y la verificación matemática. Actualmente involucrado en la implementación de alto rendimiento de aprendizaje profundo, desarrollo de hardware de transformadores, capacitación multitarea, aprendizaje activo, Apollo, Autoware y otros campos
Después de aprender el curso
Tener una comprensión profunda de la implementación del modelo TensorRT y haber mejorado mucho la implementación y la optimización del modelo;
Domine la implementación del modelo y la optimización de la clasificación, detección y percepción de BEV, y comprenda profundamente los puntos débiles y las dificultades de la optimización de la implementación;
Después de completar este curso, puede alcanzar el nivel de ingeniero de implementación de modelos durante aproximadamente un año;
¡Conozca a muchos profesionales de la industria y socios de estudio!
adecuado para la multitud
Pregrado/Máster/Doctorado en la dirección de investigación de visión artificial y percepción de conducción autónoma;
Ingenieros de algoritmos relacionados con la percepción 2D/3D de CV y conducción autónoma;
Ingenieros de algoritmos que necesitan aceleración CUDA;
Pequeños socios que tienen necesidades de implementación y optimización de modelos;
Lo básico requerido para este curso.
Tener una cierta base de python, pyTorch, Makefile, docker, estar familiarizado con C/C++, estar familiarizado con algunos algoritmos básicos comúnmente utilizados en el aprendizaje profundo;
Tener una cierta comprensión de la aplicación y las soluciones básicas de GPU, CUDA, detección de objetos, segmentación, Transformador y percepción de BEV;
Una cierta base de álgebra lineal y teoría de matrices;
La computadora necesita tener su propia GPU, que se puede implementar a través de CUDA (la configuración de enseñanza del maestro es RTX3080 10G, Jeston AGX Xavier);
Tiempo de clase y estilo de aprendizaje.
El viaje de aprendizaje comenzará oficialmente el 15 de julio de 2023. Después de dos meses, se darán conferencias en video fuera de línea. ¡El profesor responde preguntas en el grupo de aprendizaje de WeChat y resuelve problemas como algoritmos, códigos y configuración del entorno en el curso uno por uno!
consulta de curso
¡Descuento de clase! ¡Escanea el código QR para estudiar el curso juntos!

¡Escanee el código para agregar cursos de consultoría asistente!
(WeChat: AIDriver004)
