IMRAM: Iteratives Matching mit rekurrentem Aufmerksamkeitsgedächtnis für modalübergreifenden Bild-Text-Abruf
IMRAM: Recurrent Attentional Memory-Based Iterative Matching for Cross-Modal Image-Text Retrieval [Eingereicht am 8. März 2020]
Überblick
Existierende Methoden nutzen den Aufmerksamkeitsmechanismus, um die Korrespondenz zwischen Sehen und Sprache auf feinkörnige Weise zu untersuchen. Die meisten von ihnen betrachten jedoch alle Semantiken gleichermaßen und richten sie dadurch unabhängig von ihrer Komplexität einheitlich aus. Tatsächlich ist die Semantik vielfältig (d. h. beinhaltet verschiedene Arten von semantischen Konzepten), und Menschen folgen normalerweise einer zugrunde liegenden Struktur, um sie zu einer verständlichen Sprache zu kombinieren. Existierende Methoden tun sich schwer damit, solche komplexen Korrespondenzen optimal zu erfassen.
Um diesen Mangel zu beheben, schlägt dieses Papier eine Iterative Matching with Recurrent Attentional Memory (IMRAM)-Methode vor , die auf Recurrent Attentional Memory Networks basiert und die feinkörnige Korrespondenz zwischen Bildern und Texten auf progressive Weise mit zwei Merkmalen untersucht: (1) an iteratives Matching-Schema mit einer modalübergreifenden Aufmerksamkeitseinheit, um Segmente aus verschiedenen Modalitäten auszurichten, und (2) einer Speicherdestillationseinheit, um das Alignment-Wissen von frühen Schritten zu nachfolgenden Schritten zu verfeinern. Wir erreichen SOTA auf drei Benchmark-Datensätzen, Flickr8K, Flickr30K und MS COCO, und einem neuen Datensatz (d. h. KW AI-AD) für echte kommerzielle Werbeszenarien.
Das iterative Matching-Schema kann den modalübergreifenden Aufmerksamkeitskern allmählich aktualisieren und Hinweise sammeln, um die passende Semantik zu lokalisieren, während die Speicherdestillationseinheit potenzielle Korrespondenzen verfeinern kann, indem sie die Interaktivität modalübergreifender Informationen verbessert. Mit diesen beiden Eigenschaften können unterschiedliche Arten von Semantik in unterschiedlichen Matching-Schritten gut verteilt und erfasst werden.
Methode
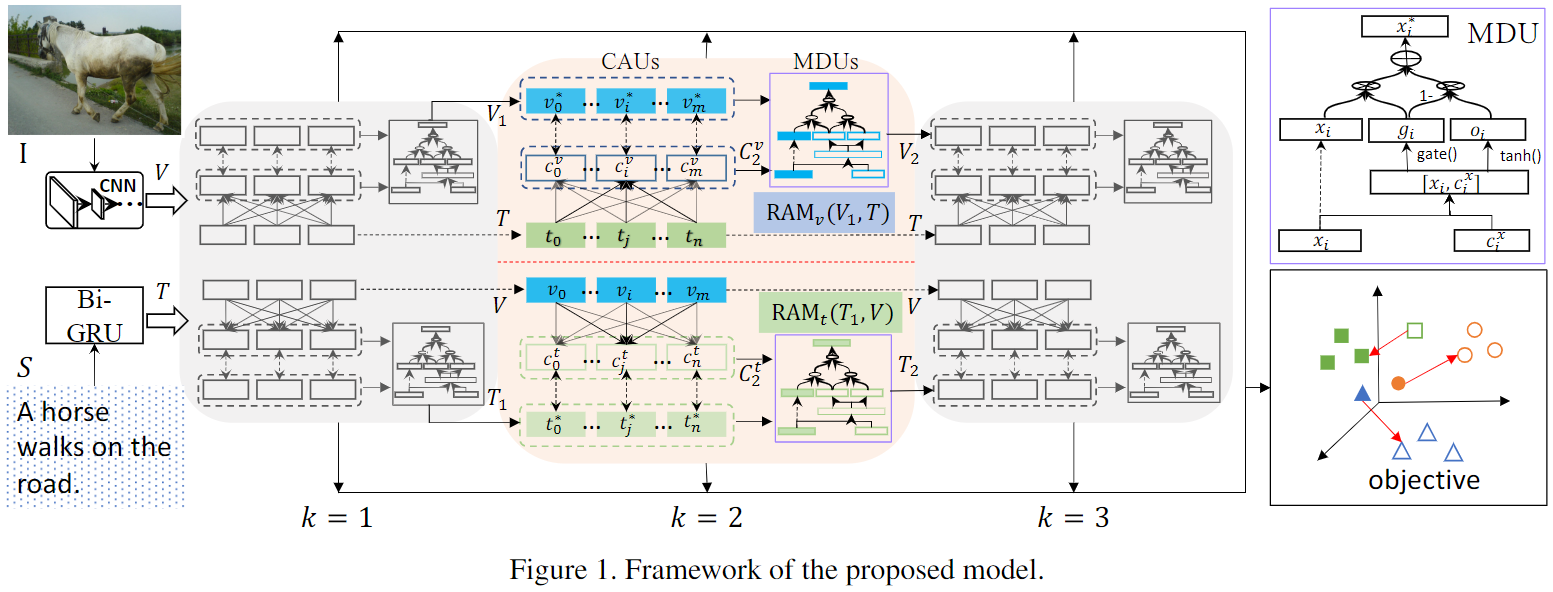
Modalübergreifende Merkmalsdarstellung
Bilddarstellung : Dieser Artikel verwendet ein vortrainiertes tiefes CNN, wie z. B. Faster R-CNN. Insbesondere erkennt ein CNN bei einem gegebenen Bild I Bildregionen und extrahiert einen Merkmalsvektor fi für jede Bildregion ri. Wir transformieren fi weiter in einen d-dimensionalen Vektor vi durch lineare Projektion, wie unten gezeigt,

wobei Wv und bv die zu lernenden Parameter sind.
Der Einfachheit halber bezeichnen wir ein Bild als V = {vi|i = 1, …, m, vi ∈ Rd}, wobei m die Anzahl der erkannten Regionen in I ist.
Textdarstellung : Grundsätzlich kann Text auf Satzebene oder Wortebene dargestellt werden. Um eine feinkörnige Verbindung zwischen Vision und Sprache zu erreichen, extrahieren wir Merkmale des Textes auf Wortebene, was mit einem bidirektionalen GRU als Encoder erfolgen kann.
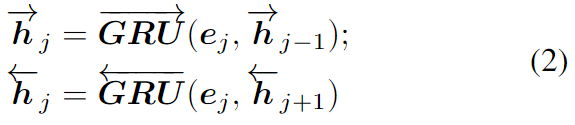
RAM: Rekurrentes Aufmerksamkeitsgedächtnis
Das wiederkehrende Aufmerksamkeitsgedächtnis zielt darauf ab, Fragmente im Einbettungsraum auszurichten, indem das Wissen über frühere Fragmentausrichtungen wiederholt verfeinert wird. Es kann als ein Block angesehen werden, der zwei Sätze von Merkmalspunkten absorbiert, nämlich V und T, und die Ähnlichkeit zwischen diesen zwei Sätzen von Merkmalspunkten über eine modalübergreifende Aufmerksamkeitseinheit schätzt. Die Aufmerksamkeitsergebnisse werden mithilfe einer Speicherdestillationseinheit verfeinert, um mehr Wissen für den nächsten Schritt der Ausrichtung bereitzustellen.
Crossmodale Aufmerksamkeitseinheit (CAU). Ziel ist es , Kontextinformationen in Y für jedes Merkmal xi in X zusammenzufassen. Um dies zu erreichen, berechnen wir zuerst die Ähnlichkeit zwischen jedem Paar ( xi , y j
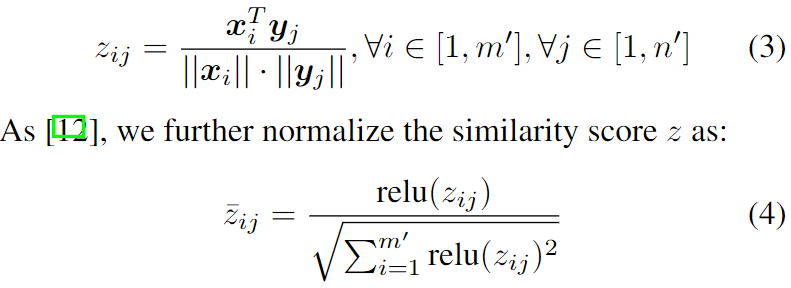
) unter Verwendung der Kosinusfunktion: wobei relu(x) = max(0, x) Memory Distillation Unit (MDU). Um das Alignment-Wissen für das nächste Alignment zu verbessern, verwenden wir eine Speicherdestillationseinheit, um das Abfragemerkmal X zu aktualisieren, indem wir es dynamisch mit dem entsprechenden X-geerdeten Alignment-Merkmal Cx aggregieren
Experiment
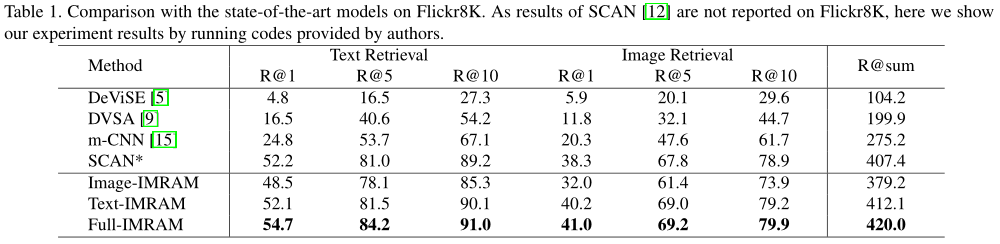
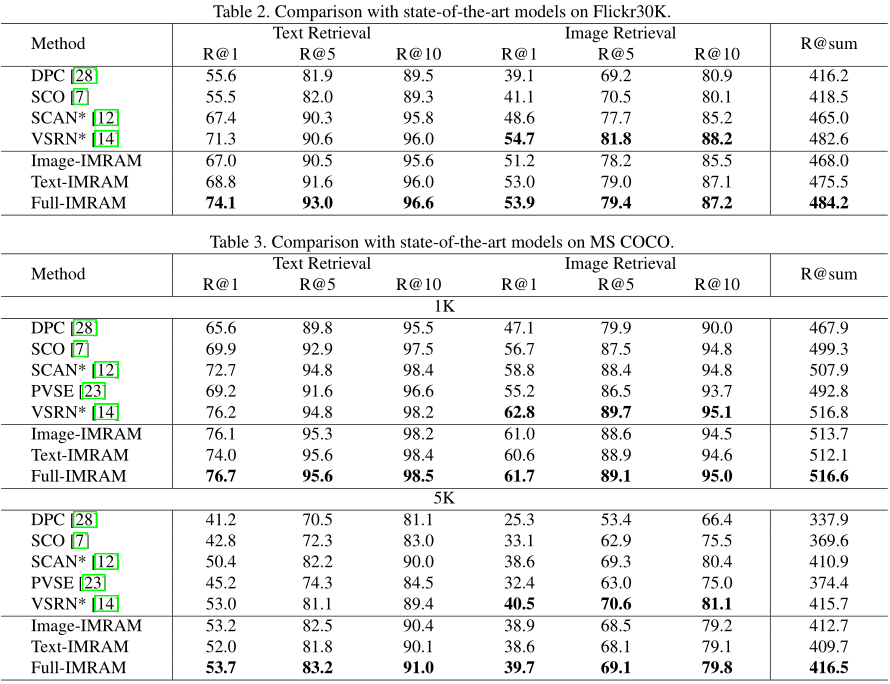
Experimentelle Ergebnisse zeigen, dass dieses Verfahren eine gute Wirkung bei der modalübergreifenden Bildtextabfrage hat. Es kann nicht nur in den kleinen Datensätzen Flickr8K und Flickr30K konstant eine State-of-the-Art-Performance erreichen, sondern zeigt auch seine Robustheit gut im großen Datensatz MS COCO.
abschließend
In diesem Artikel schlagen wir eine iterative Matching-Methode basierend auf dem Recurrent Attention Memory Network (IMRAM) für den modalübergreifenden Bild-Text-Abruf vor, um die Komplexität der Semantik zu bewältigen. IMRAM kann die Korrespondenz zwischen Bildern und Texten auf progressive Weise mit zwei Merkmalen untersuchen: (1) ein iteratives Zuordnungsschema mit einer modalübergreifenden Aufmerksamkeitseinheit, um Segmente aus verschiedenen Modalitäten auszurichten; (2) eine Gedächtnisdestillationseinheit, aus der das Wissen verfeinert wird frühe Schritte zu späteren Schritten. Wir validieren unser Modell an drei Benchmarks (d. h. Flickr8K, Flickr30K und MS COCO) und einem neuen Datensatz (d. h. KW AI-AD) für reale kommerzielle Werbeszenarien. Experimentelle Ergebnisse an allen Datensätzen zeigen, dass unser IMRAM Vergleichsmethoden durchweg übertrifft und eine State-of-the-Art-Leistung erreicht.
Empfohlene Lektüre:
CVPR2020 Cross-Modal Retrieval-IMRAM
IMRAM: Iterative Matching and Recursive Attention Mechanism for Cross-Modal Image-Text Retrieval