1. Categoría de investigación: mejora y restauración de imágenes
----图像增强:基于图像增强的去雾算法出发点是尽量去除图像噪声,提高图像对比度,从而恢复出无雾清晰图像
----方法:直方图均衡化(HLE)、自适应直方图均衡化(AHE)、限制对比度自适应直方图均衡化(CLAHE)、Retinex算 法、小波变换、同态滤波。
----图像复原:基于大气退化模型,进行响应的去雾处理
----方法:暗通道去雾算法、基于导向滤波的暗通道去雾算法、Fattal的单幅图像去雾算法(Single image dehazing)、Tan的单一图像去雾算法(Visibility in bad weather from a single image)、Tarel的快速图像恢复算法(Fast visibility restoration from a single color or gray level image)、贝叶斯去雾算法(Single image defogging by multiscale depth fusion)
2. CNN
-----大气退化模型 : 利用神经网络对模型中的参数进行估计
-----利用输入的有雾图像,直接输出得到去雾后的图像(**端到端**)通过学习有雾图像到无雾图像之间的映射关系来恢复无雾图像
3. 何凯明:Eliminación de la neblina de una sola imagen mediante el canal oscuro previo
----**暗通道**:对于非天空区域,暗通道的值等于取一个局部窗口中每个像素点三个通道中最小值组成的集合的最小值
(**也就是按照像素点,每个像素点都有RGB三个通道,取三个通道中的最小值,构成暗通道图**)
对于有雾的图像来说其暗通道值不是趋于0
(https://img-blog.csdnimg.cn/f1cbbda9986444aabc28d84ea6411abc.png)
En la fórmula anterior, [fórmula] representa cada canal de la imagen en color, Ω(x) representa una ventana centrada en el píxel X y el tamaño del ventana se puede determinar de acuerdo con la situación real La situación se ajusta adecuadamente.
4. Encuentra la luz atmosférica A:



Debido a la existencia de luz atmosférica, la imagen del canal oscuro original tiene brillo, por lo que la luz atmosférica A es el lugar brillante en el canal oscuro (tanto si hay niebla como si no)



https://www.bilibili.com/video/BV1CX4y1P7Sk?spm_id_from=333.999.0.0
5. Genere una fórmula de imagen borrosa:

--------I(X) tiene niebla, J(x) no tiene imagen de niebla, A es la luz atmosférica global, t(x) es la transmitancia
6.GCANet
Descripción general:
una red de agregación de contexto cerrada de extremo a extremo para recuperar directamente la imagen final sin neblina. En esta red, adoptamos la técnica de dilatación suave de última generación para ayudar a eliminar los artefactos de cuadrícula causados por circunvoluciones dilatadas ampliamente utilizadas con parámetros adicionales insignificantes, y utilizamos subredes cerradas para fusionar características de diferentes niveles.
La convolución dilatada se usa ampliamente para agregar información contextual sin sacrificar la resolución espacial para mejorar su efectividad; también se adopta para ayudar a obtener resultados de restauración más precisos al cubrir más píxeles adyacentes. Suavizar las circunvoluciones dilatadas puede reducir en gran medida este artefacto de cuadrícula .
Se propone una subred de puertas para determinar la importancia de los diferentes niveles, que se fusionan según sus correspondientes pesos de importancia. (fusión entre diferentes niveles)
Resumen:
1. Una nueva red de agregación de contexto cerrada de extremo a extremo GCANet para desempañar imágenes, que utiliza convoluciones dilatadas suaves para evitar artefactos de malla y aplica subredes cerradas para fusionar características en diferentes niveles 2. Proporciona estudios de ablación completos
para verificar la importancia y necesidad de cada componente.
3. Aplique aún más nuestra GCANet propuesta a la tarea de drenaje de imágenes .
Trabajo relacionado:
Tradicional: las imágenes previas están hechas a mano en el tipo anterior
Ahora: se aprenden automáticamente
GCANet está diseñado para realizar una regresión directa del residuo entre la imagen borrosa y la imagen limpia de destino. La estructura de la red es muy ligera y el efecto es bueno.
Estructura detallada del marco:
En esta sección, presentamos la arquitectura de la red de agregación de contexto cerrado propuesta, GCANet. Como se muestra en la Figura 1, dada una imagen de entrada borrosa, primero la codificamos en un mapa de características a través de la parte del codificador y luego las mejoramos agregando más información contextual y fusionando características en diferentes niveles sin reducir la resolución. Específicamente, se utilizan circunvoluciones dilatadas suaves y redes de puertas adicionales. Los mapas de características mejoradas finalmente se decodificarán de nuevo al espacio de la imagen original para obtener el residuo de neblina objetivo. Al agregarlo en la imagen con niebla de entrada, obtendremos la imagen final sin niebla.
**Convolución de Atrous:** para abordar la inferencia de contexto multiescala necesaria y la información de resolución espacial que falta durante la reducción de resolución.
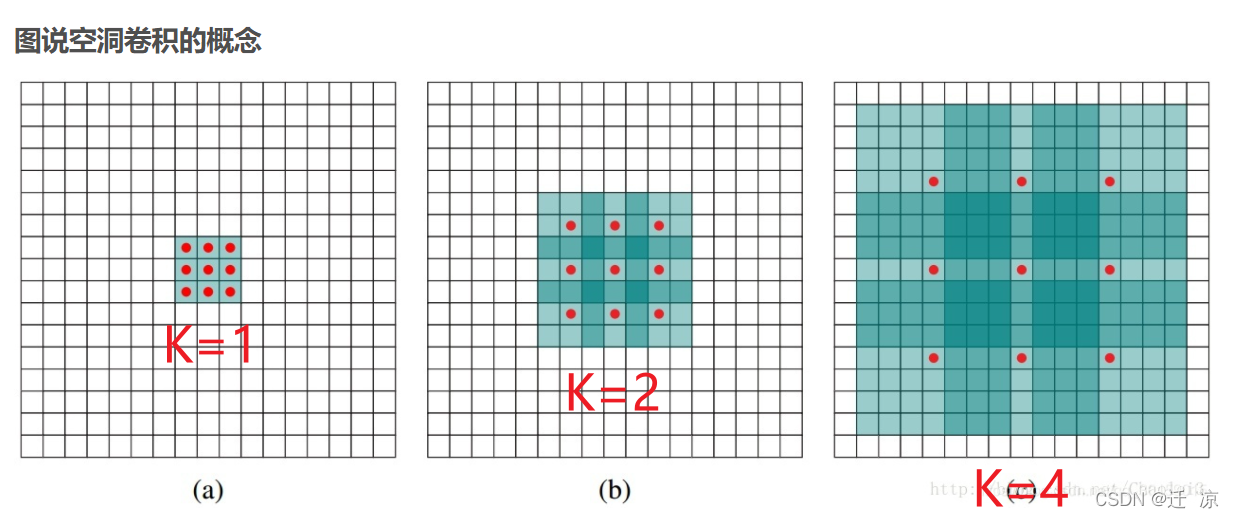
La convolución atrosa produce artefactos de rejilla:

Convolución dilatada suave:
** if self.only_residual: # 去雾
y = self.deconv1(y) # output: (out_c, im_h, im_w)
else: # 去雨
y = F.relu(self.deconv1(y))
return y
**
