Tema del ensayo:
Reconocimiento de acento basado en representación de aprendizaje autosupervisado con memoria de acento persistente
Lista de autores:
Li Rui, Xie Zhiwei, Xu Haihua, Peng Yizhou, Liu Hexin, Huang Hao, Chng Eng Siong
Antecedentes de la investigación
El reconocimiento de acento (AR) es una tarea importante y desafiante. Porque el acento no solo contiene las características del habla del hablante, sino también información regional, que puede ser crucial para el reconocimiento del hablante [1] y el reconocimiento del habla [2]. Sin embargo, los datos de etiquetado de acento a gran escala son difíciles de obtener, por lo que es una tarea de bajos recursos. Por lo tanto, para obtener un sistema AR ideal, es necesario hacer un uso completo de la eficiencia del modelado de datos y modelos.
El esquema de este artículo.
Este documento tiene como objetivo mejorar el rendimiento de AR desde dos perspectivas. En primer lugar, para aliviar el problema de la insuficiencia de datos, utilizamos la representación de aprendizaje autosupervisado (SSLR) extraída del modelo preentrenado WavLM [3] para construir el modelo AR. Con la ayuda de SSLR, logra un aumento significativo del rendimiento en comparación con las firmas acústicas tradicionales. En segundo lugar, proponemos una memoria de acento persistente (PAM) como conocimiento contextual para sesgar el modelo AR. Las incorporaciones de acento extraídas de todos los datos de entrenamiento por el codificador del modelo AR se agrupan para formar un libro de códigos de acento, PAM. Además, proponemos múltiples mecanismos de atención para estudiar el uso óptimo de PAM. Observamos que el mejor rendimiento se logra seleccionando las incrustaciones de acento más relevantes.
1. Para aliviar el problema de la insuficiencia de datos, utilizamos representaciones de aprendizaje autosupervisadas (SSLR) extraídas de modelos previamente entrenados para construir modelos AR.

Figura 1 Modelo de red troncal multitarea
Tabla 1 La precisión de los SSLR extraídos con WavLM en el conjunto de prueba

Primero, usamos los SSLR extraídos por WavLM en lugar de la característica acústica tradicional Fbank para entrenar el modelo. De los sistemas 1–5 en la Tabla 1, se puede ver que el uso de WavLM para extraer SSLR puede mejorar significativamente el rendimiento de AR en comparación con los sistemas entrenados desde cero usando Fbank de características acústicas tradicionales. En segundo lugar, el modelo entrenado con SSLR extraídos en codificadores intermedios superiores funciona mejor que los SSLR en codificadores de capa inferior, y los mejores resultados se obtienen en la capa 20. Finalmente, de acuerdo con las precisiones en la Tabla 1 sobre diferentes acentos, encontraremos que los SSLR extraídos por diferentes codificadores de capa brindan información efectiva diferente para diferentes acentos. Entonces tendremos una pregunta, ¿cómo combinar la información efectiva proporcionada por diferentes capas de SSLR para diferentes acentos, a fin de mejorar la precisión de todos los acentos?
2. Proponemos una memoria de acento persistente (PAM) como conocimiento contextual para sesgar los modelos AR.
Específicamente, PAM es un libro de códigos que contiene 256 incrustaciones, que se agrupan a partir de la salida de los datos del conjunto de entrenamiento del codificador del modelo AR entrenado con WavLM SSLR. El conjunto de entrenamiento contiene acentos 8. Agregamos las incrustaciones de audio correspondientes a cada acento en 32 incrustaciones utilizando k-means, y finalmente obtenemos 256 incrustaciones, que se denominan PAM. Entre ellos, "persistencia" significa que estas 256 incrustaciones no se actualizarán durante el entrenamiento.
3. Para explotar la información del contexto del acento, experimentamos con varios mecanismos de atención.
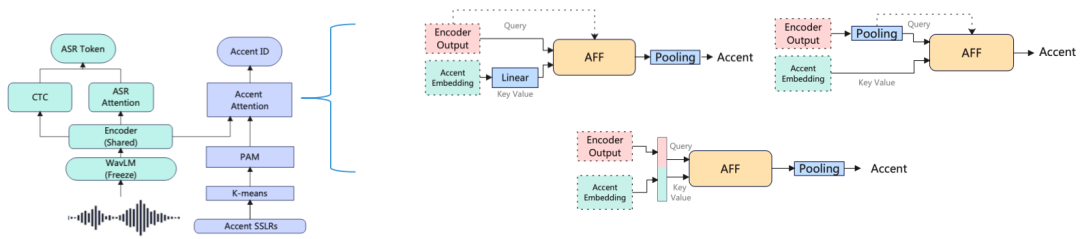
Figura 2 Diferentes mecanismos de atención
(1) Fusión de atención cruzada a nivel de marco: la salida del codificador se usa como consulta, PAM se usa como clave y valor, y el mecanismo de atención actúa en el nivel de marco.
(2) Fusión de atención cruzada a nivel de discurso: La salida del codificador está en el nivel de discurso por agrupación, ya que PAM también está en el nivel de discurso. Esto se da cuenta de que todos los componentes de la atención, como la consulta, la clave y el valor, están en el mismo nivel de expresión, lo que hace que la atención tenga una semántica clara.
(3) Empalme de fusión de autoatención PAM: empalme de la salida del codificador y PAM en la dimensión de tiempo, y realización de operaciones de autoatención en toda la secuencia. La motivación es mejorar el rendimiento de AR haciendo que el codificador sesgue la salida del codificador por el contexto de acento.
4. Para hacer un mejor uso de la información de contexto de acento, proponemos el método de selección de memoria de acento persistente N-mejor.
Cuando usamos diferentes mecanismos de atención, su limitación es que se consideran todas las incrustaciones en PAM, lo que conducirá a una excesiva redundancia, porque pensamos que el modelo solo necesita considerar incrustar información igual o similar al acento actual durante el entrenamiento. Así que proponemos el método de selección de memoria de acento persistente N-mejor. N denota el número de incrustaciones seleccionadas del PAM en función de la puntuación de similitud entre las incrustaciones en el PAM y la salida del codificador. La arquitectura del método se muestra en la Figura 3.
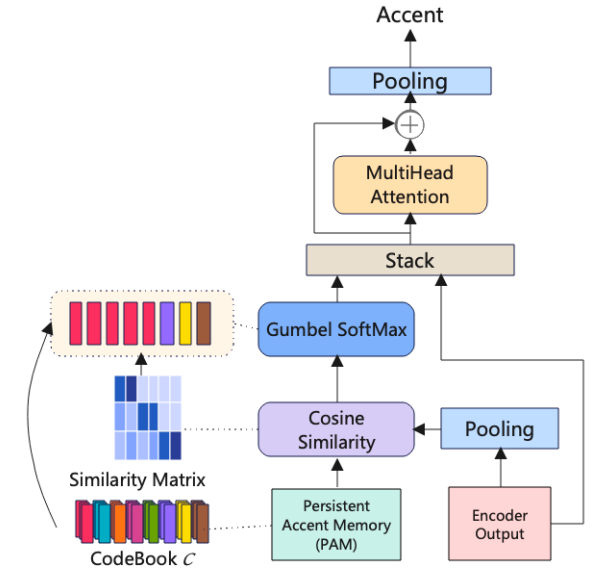
Figura 3 N-mejor método de selección de memoria de acento persistente
Resultados experimentales
Los resultados experimentales de todos los métodos basados en la atención se muestran en la Tabla 2. Para verificar la efectividad y la generalidad de nuestro método propuesto, "Oracle" representa que PAM se construye a partir de la incrustación extraída del modelo de reconocimiento de acento de mejor rendimiento correspondiente a cada acento, y los otros dos se basan en el resultado de la última capa y el resultado de la suma ponderada general, indicados como "capa-24" y "capas: 1-24" respectivamente. Encontramos que todos los métodos mejoran con respecto a la línea de base, y el método de selección N-mejor logra el mejor rendimiento.
Tabla 2 Precisión en el equipo de prueba usando PAM
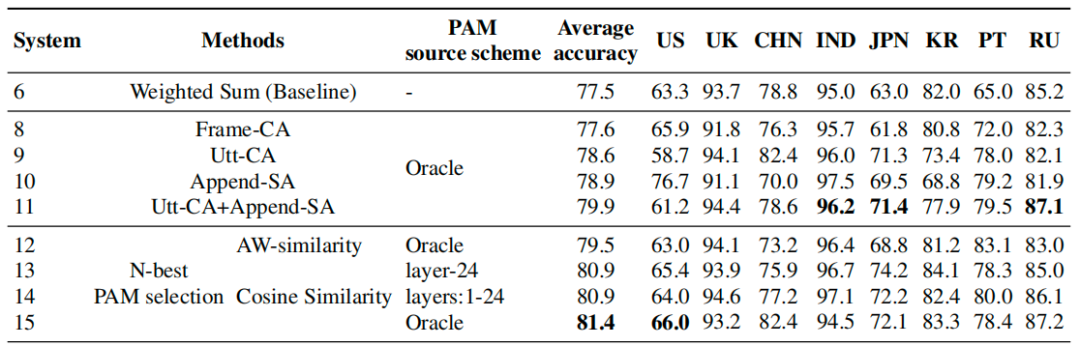
Tabla 3 El papel de N en el método de selección N-best PAM

Además, investigamos el efecto de diferentes N en el método de selección N-mejor, como se muestra en la Tabla 3. Cuando N es igual a 64, el modelo muestra la mayor precisión. Sin embargo, un N más grande no conduce necesariamente a un mayor rendimiento, sino que también conduce a una mayor complejidad computacional.
en conclusión
En este trabajo, incorporamos representaciones de aprendizaje autosupervisado (SSLR) en nuestro método de memoria de acento persistente (PAM) propuesto para mejorar AR. Usamos SSLR extraídos de un modelo WavLM previamente entrenado para abordar el problema de insuficiencia de datos en la tarea de reconocimiento de acento. El uso de SSLR muestra ganancias de rendimiento significativas en comparación con las funciones acústicas tradicionales, lo que demuestra la eficacia de los SSLR en el reconocimiento de acento. Además, proponemos un enfoque PAM con un mecanismo de atención diferente para mejorar el reconocimiento del acento. Demostramos la efectividad de nuestro método propuesto en conjuntos de datos de referencia de acento público, y el sistema de mejor rendimiento que selecciona las N mejores incrustaciones relevantes de la memoria de acento persistente logra mejoras adicionales en el reconocimiento de acento.
referencias
[1] S. Shon, H. Tang y J. Glass, "Incrustaciones de altavoces a nivel de fotograma para el reconocimiento de altavoces independientes del texto y el análisis del modelo de extremo a extremo", en Proc. SLT 2018. IEEE, 2018, págs. 1007–1013.
[2] X. Gong, Y. Lu, Z. Zhou e Y. Qian, "Adaptación rápida en capas para el reconocimiento de voz multiacento de extremo a extremo", en Proc. INTERSPEECH 2021, 2021, págs. 1274–1278.
[3] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao et al., "Wavlm: entrenamiento previo autosupervisado a gran escala para procesamiento de voz de pila completa", IEEE Journal of Selected Topics in Signal Processing, vol. 16, núm. 6, págs. 1505–1518, 2022.