milagro
El tema de este libro, ChatGPT, es una maravilla.
Ha pasado casi medio año desde su lanzamiento en noviembre de 2022, y la atención y el impacto que ha atraído ChatGPT pueden haber superado casi todos los puntos calientes en la historia de la tecnología de la información.
Su número de usuarios alcanzó 1 millón en 2 días y 100 millones en 2 meses, rompiendo el récord anterior de TikTok. Y después del lanzamiento de la aplicación iOS en mayo de 2023, también encabezará la lista general de la App Store de Apple sin ningún suspenso.
Por primera vez en sus vidas, muchas personas han entrado en contacto con un sistema de diálogo tan inteligente que puede corregir errores. Escribir artículos, aunque muchas veces tendrá mucha confianza, "tonterías graves", e incluso las sumas y restas simples no son correctas, pero si le recuerda que está mal, o lo deja ir paso a paso, será realmente muy confiable, enumere los pasos para hacer las cosas de manera ordenada y luego obtenga la respuesta correcta. Para algunas tareas complicadas, estás esperando a verla bromear, pero te sorprende dándote respuestas razonables sin prisas.
Muchos expertos de la industria también son conquistados por él:
Gates, que inicialmente era pesimista e incluso votó en contra de la decisión de Microsoft de invertir en OpenAI en 2019, ahora compara ChatGPT con las PC, Internet, etc. Huang Renxun lo llamó el momento del iPhone, Sam Altman de OpenAI lo comparó con una imprenta y el CEO de Google, Sundar Pichai, dijo que era fuego y electricidad. La sugerencia de Alibaba Zhang Yong es: "Vale la pena rehacer todas las industrias, aplicaciones, software y servicios en función de las capacidades del modelo grande". Muchos expertos, representados por Musk, pidieron la suspensión del desarrollo de poderosos modelos de IA porque las capacidades innovadoras de ChatGPT pueden representar una amenaza para los seres humanos.
En la Conferencia de Zhiyuan de 2023 que acaba de concluir, Sam Altman dijo con confianza que es probable que AGI llegue dentro de diez años, y que se necesita la cooperación global para resolver varios problemas causados por ello. Los tres científicos que ganaron el Premio Turing por promover conjuntamente el aprendizaje profundo desde el borde hasta el centro del escenario tienen opiniones significativamente diferentes:
Yann LeCun dejó en claro que el modelo grande autorregresivo representado por GPT tiene fallas esenciales, y es necesario encontrar una nueva forma en torno al modelo mundial, por lo que no está preocupado por la amenaza de la IA.
Aunque Yoshua Bengio, quien apareció en el video de otro orador, no estaba de acuerdo con que la ruta GPT por sí sola pudiera conducir a AGI (es optimista sobre la combinación de razonamiento bayesiano y redes neuronales), admitió que existe un gran potencial en los modelos grandes y que no hay un techo obvio desde el primer principio, por lo que firmó una carta abierta pidiendo una moratoria en el desarrollo de la IA.
Geoffrey Hinton, quien pronunció el discurso final, obviamente estuvo de acuerdo con la opinión de su discípulo Ilya Sutskever de que el modelo grande puede aprender la representación comprimida del mundo real. Se dio cuenta de que con la retropropagación (en términos sencillos, significa un mecanismo incorporado de reconocimiento y corrección de errores) y una red neuronal artificial que se puede expandir fácilmente, la inteligencia pronto podría superar a la de los humanos. Por lo tanto, también se unió al equipo que pide el riesgo de la IA.
El viaje de contraataque de la red neuronal artificial representada por ChatGPT también ha sido considerado como altibajos en toda la historia de la ciencia y la tecnología. Ha sido discriminado y atacado repetidamente en la comunidad de inteligencia artificial con muchos géneros. Más de un genio pionero terminó en tragedia:
En 1943, Walter Pitts y Warren McCulloh tenían solo 20 años cuando propusieron la representación matemática de las redes neuronales, él no terminó la escuela secundaria, luego se separó de la academia por su discordia con su tutor Wiener, murió prematuramente a la edad de 46 años debido al consumo excesivo de alcohol;
Frank Rosenblatt, quien realmente se dio cuenta de la red neuronal a través del perceptrón a la edad de 30 años en 1958, se ahogó en su 43 cumpleaños;
El principal defensor de la retropropagación, David Rumelhart, padecía una rara enfermedad incurable en su mejor momento a los 50. Comenzó a sufrir demencia en 1998 y murió en 2011 después de luchar contra la enfermedad durante más de diez años.
……
Algunas conferencias importantes y gigantes académicos como Minsky se han opuesto sin ceremonias o incluso han rechazado las redes neuronales, lo que obligó a Hinton y a otros a adoptar términos más neutrales u oscuros como "memoria asociativa", "procesamiento distribuido en paralelo", "red convolucional" y "aprendizaje profundo" para ganar un espacio vital para ellos.
El mismo Hinton comenzó en la década de 1970, manteniéndose en la dirección impopular durante décadas, desde el Reino Unido hasta los Estados Unidos, y finalmente estableció un punto de apoyo en Canadá, la antigua frontera académica, y trabajó duro para establecer una escuela con un pequeño número de élites a pesar de la falta de apoyo financiero.
Hasta 2012, cuando su estudiante de doctorado Ilya Sutskever y otros utilizaron nuevos métodos para volar hacia el cielo en la competencia de ImageNet, el aprendizaje profundo comenzó a convertirse en la ciencia prominente de la IA y se usó ampliamente en varias industrias.
En 2020, dirigió el equipo de OpenAI y abrió la era de los modelos grandes a través de GPT-3 con cientos de miles de millones de parámetros.
La propia experiencia de vida de ChatGPT también es muy dramática.
En 2015, Sam Altman, de 30 años, y Greg Brockman, de 28, se asociaron con Musk para convocar a Ilya Sutskever, de 30 años, y a otros talentos destacados de IA para cofundar OpenAI, con la esperanza de establecer una fuerza de investigación de IA de frontera neutral fuera de Google, Facebook y muchos otros gigantes, y establecer ambiciosamente la inteligencia artificial a nivel humano como su objetivo.
En ese momento, los medios básicamente informaron que Musk apoyaba el establecimiento de una organización de inteligencia artificial sin fines de lucro como título, y no muchas personas eran optimistas sobre OpenAI. Incluso un alma como Ilya Sutskever pasó por algunas luchas ideológicas antes de unirse.
En los últimos tres años, han realizado ataques multilínea en aprendizaje reforzado, robots, multiagentes, seguridad de IA, etc., y de hecho no han logrado resultados particularmente convincentes. Tanto es así que el patrocinador principal, Musk, no estaba satisfecho con el progreso y quería gestionar directamente, pero tras ser rechazado por el consejo, optó por irse por completo.
En marzo de 2019, Sam Altman comenzó a desempeñarse como director ejecutivo de OpenAI y, en unos pocos meses, completó el establecimiento de una empresa comercial y recibió una inversión de mil millones de dólares de Microsoft, haciendo los preparativos para el desarrollo posterior.
En términos de investigación científica, Alec Radford, quien se unió a OpenAI dos años después de graduarse de Olin College of Engineering en 2014, comenzó a trabajar duro. Como autor principal, bajo la dirección de Ilya Sutskever y otros, completó sucesivamente PPO (2017), GPT-1 (2018), GPT-2 (2019), Jukebox (2020), ImageGPT (2020), CLIP (2021), Whisper (20 22) y muchas otras obras pioneras. En particular, el trabajo de las neuronas emocionales en 2017 creó una arquitectura minimalista de "predecir el próximo personaje" combinada con una ruta técnica de modelos grandes, gran poder de cómputo y big data, que tuvo un impacto clave en el GPT posterior.
El desarrollo de GPT no ha sido fácil.
Se puede ver claramente en la Figura 1 a continuación que después de la publicación del documento GPT-1, la arquitectura de solo decodificador intencionalmente más simple de OpenAI (hablando con precisión, un codificador-decodificador con autorregresivo) no recibió mucha atención. El BERT de Google (arquitectura solo de codificador, hablando con precisión, un codificador no decodificador autorregresivo) se llevó el protagonismo unos meses después. Ha habido una serie de trabajos muy influyentes como xxBERT.
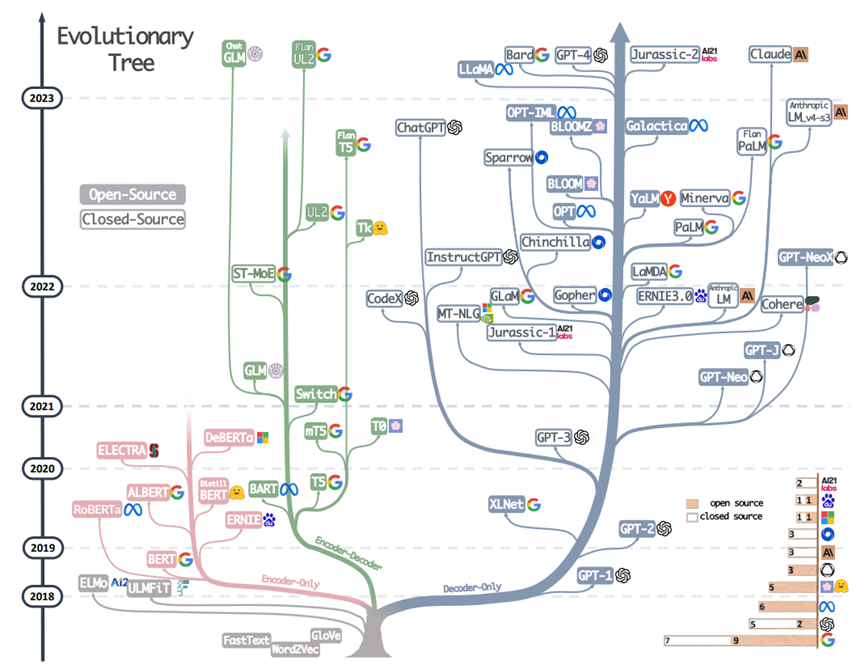
Figura 1 Árbol evolutivo de modelo grande, del artículo "Harnessing the Power of LLMs in Practice" de Amazon Yang Jingfeng et al. en abril de 2023
Incluso hoy en día, este último ha acumulado más de 68.000 referencias, que sigue siendo un orden de magnitud superior a las menos de 6.000 de GPT-1. Las rutas técnicas de los dos documentos son diferentes. Ya sea en la academia o en la industria, casi todos eligieron el campo BERT en ese momento.
GPT-2, lanzado en febrero de 2019, aumentó la escala máxima de parámetros a 1500 millones. Al mismo tiempo, al utilizar datos a mayor escala, de mayor calidad y más diversos, el modelo comenzó a mostrar sólidas capacidades generales.
En ese momento, no fue la investigación en sí lo que hizo que GPT-2 acaparara los titulares de la comunidad técnica (hasta el día de hoy, el número de citas en los artículos aún ronda los 6000, que es mucho menor que el de BERT), sino que OpenAI solo abrió el modelo de código abierto de 345 millones de parámetros por razones de seguridad, lo que causó un gran revuelo. La impresión de la comunidad sobre si OpenAI no es Open comienza aquí.
Antes y después de esto, OpenAI también realizó una investigación sobre el impacto de la escala en las capacidades del modelo de lenguaje, y propuso la "Ley de Escalamiento" (Scaling Law), que determinó la dirección principal de toda la organización: modelos grandes. Por ello, se cortaron otras direcciones como el aprendizaje por refuerzo y la robótica. Lo que es encomiable es que la mayoría del personal central de I+D optó por quedarse, cambiar su dirección de investigación, renunciar a su ego y concentrarse en hacer grandes cosas. Muchas personas recurrieron al trabajo de ingeniería y datos, o reposicionaron su dirección de investigación en torno a modelos grandes (por ejemplo, el aprendizaje por refuerzo desempeñó un papel importante en GPT 3.5 y su evolución posterior). Esta flexibilidad organizativa también es un factor importante para el éxito de OpenAI.
Con la aparición de GPT-3 en 2020, algunas personas perspicaces en el pequeño círculo de NLP comenzaron a darse cuenta del gran potencial de la ruta técnica de OpenAI. En China, el Instituto de Investigación de Inteligencia Artificial Zhiyuan de Beijing ha lanzado modelos como GLM y CPM en conjunto con la Universidad de Tsinghua y otras universidades, y está promoviendo activamente el concepto de modelos grandes en los círculos académicos nacionales. Como se puede ver en la Figura 1, después de 2021, la ruta GPT ha tomado la delantera por completo, mientras que el árbol evolutivo de las "especies" de BERT casi se ha detenido.
A fines de 2020, los hermanos y hermanas de Dario y Daniela Amodei, dos vicepresidentes de OpenAI, llevaron a varios colegas del GPT-3 y del equipo de seguridad a irse y fundaron Anthropic. La posición de Dario Amodei en OpenAI es extraordinaria, es otro creador de la hoja de ruta tecnológica además de Ilya Sutskever, y también es el director general de los proyectos GPT-2 y GPT-3 y la dirección de seguridad. Y con él, hay muchos núcleos de GPT-3 y documentos de ley de escala.
Un año más tarde, Anthropic publicó el artículo "A General Language Assistant as a Laboratory for Alignment" y comenzó a estudiar los problemas de alineación con los asistentes de chat. Desde entonces, se ha convertido gradualmente en Claude, un producto de chat inteligente.
En junio de 2022, se publicó el documento "Habilidades emergentes de modelos de lenguaje grande". El primer trabajo fue de Jason Wei, un investigador de Google que se graduó de Dartmouth College durante solo dos años como estudiante universitario (también fue a OpenAI en febrero de este año durante la ola de saltos de trabajo de élite de Google). En este trabajo se estudia la habilidad emergente de los modelos grandes, este tipo de habilidad no existe en los modelos pequeños, y solo aparecerá cuando la escala del modelo se expanda a un cierto nivel. Es decir, "el cambio cuantitativo conducirá al cambio cualitativo" que conocemos.
A mediados de noviembre, los empleados de OpenAI que habían estado desarrollando GPT-4 recibieron instrucciones de la gerencia para suspender todo el trabajo y lanzar una herramienta de chat con todas sus fuerzas debido a la competencia. Dos semanas después, nació ChatGPT. Lo que sucedió después de eso ha quedado registrado en la historia.
La industria especula que la gerencia de OpenAI debería haber aprendido sobre el progreso de Anthropic Claude, se dio cuenta del enorme potencial de este producto y decidió actuar primero. Esto demuestra el juicio súper estratégico del personal central. Ya sabes, incluso los principales desarrolladores de ChatGPT no saben por qué el producto está tan de moda después de su lanzamiento ("Mis padres finalmente saben lo que estoy haciendo"), y no se sintieron nada bien cuando lo probaron.
En marzo de 2023, después de medio año de "evaluación, pruebas contradictorias y mejoras iterativas de modelos y mitigaciones a nivel de sistema", se lanzó GPT-4.
El estudio de Microsoft Research de su versión interna (capaz de superar la versión en línea disponible públicamente) concluye: "En todas estas tareas, GPT-4 se desempeña sorprendentemente cerca del rendimiento humano... Dada la amplitud y profundidad de GPT-4, creemos que puede considerarse razonablemente como una versión temprana (pero aún incompleta) de los sistemas de inteligencia artificial general (AGI)".
Desde entonces, las empresas nacionales y extranjeras y las instituciones de investigación científica han seguido, y casi todas las semanas se lanzan uno o más modelos nuevos, pero OpenAI sigue siendo el mejor en términos de capacidades integrales, y el único que puede competir con él es Anthropic.
Mucha gente se preguntará, ¿por qué China no produjo ChatGPT? De hecho, la pregunta (indicación) correcta debería ser: ¿Por qué solo OpenAI en el mundo puede hacer ChatGPT? ¿Cuál es la razón de su éxito? Pensar en esto sigue siendo relevante hoy.
ChatGPT, qué milagro.
hombre impar
El autor de este libro, Stephen Wolfram, es un hombre extraño.

Aunque no es una celebridad tecnológica tan conocida como Musk, sí es muy conocido en el pequeño círculo de geeks tecnológicos, y se le llama "la persona viva más inteligente".
Uno de los fundadores de Google, Sergey Brin, se sintió atraído por la empresa de Wolfram para realizar una pasantía durante sus años universitarios. Wang Xiaochuan, el fundador de Sogou y Baichuan Intelligent, también es un famoso admirador acérrimo de él, "con reverencia y fanatismo... siguiendo y siguiendo durante muchos años".
Wolfram era conocido como un niño prodigio cuando era niño. Porque desdeñan leer los "libros estúpidos" recomendados por la escuela, y no son buenos en aritmética, y no quieren hacer las preguntas que ya han sido respondidas.Al principio, los maestros pensaron que el niño no era bueno.
Como resultado, a la edad de 13 años, escribí varios libros de física, uno de los cuales se titulaba "Física de partículas subatómicas".
A la edad de 15 años, publicó un artículo serio sobre física de alta energía "¿Electrones hadrónicos?" en el Australian Journal of Physics, proponiendo una nueva forma de acoplamiento electrón-hadrón de alta energía. Este artículo también tiene 5 citas.

Wolfram pasó algunos años en universidades famosas como Eton College y la Universidad de Oxford en el Reino Unido, y no tomó muchas clases. Odiaba los problemas que habían sido resueltos por otros, por lo que se escapó antes de graduarse. Finalmente, a la edad de 20 años, obtuvo directamente un doctorado.
Luego se quedó y se convirtió en profesor en Caltech.
En 1981, Wolfram ganó el primer premio MacArthur Genius y fue el ganador más joven. El mismo grupo son todos maestros de varias disciplinas, incluido el ganador del Premio Nobel de 1992, Walcott.
Rápidamente perdió interés en la física pura. En 1983, se transfirió al Instituto de Estudios Avanzados de Princeton y comenzó a estudiar los autómatas celulares, con la esperanza de encontrar más leyes subyacentes de los fenómenos naturales y sociales.
Esta transformación ha tenido un gran impacto. Se convirtió en uno de los fundadores de la disciplina de los sistemas complejos, y algunos consideran que produjo un trabajo digno del Premio Nobel. Cuando tenía 20 años, participó en los primeros trabajos del Instituto Santa Fe con varios ganadores del Premio Nobel Gell-Mann y Philip Anderson (fue él quien publicó el artículo "Más es diferente" en 1972 y propuso el concepto de emergencia), y fundó el centro de investigación de sistemas complejos en la UIUC. También fundó la revista académica Complex Systems.
Para hacer más convenientes los experimentos informáticos relacionados con los autómatas celulares, desarrolló el software matemático Mathematica (el nombre se lo dio su amigo Jobs), y luego fundó la compañía de software Wolfram Research, convirtiéndose en un exitoso empresario.
El poder del software de Mathematica se puede sentir intuitivamente a partir de la gramática clara y altamente abstracta al interpretar ChatGPT más adelante en este libro. Para ser honesto, esto me hizo querer estudiar seriamente este software y las tecnologías relacionadas.
En 1991, Wolfram volvió al estado de investigación y comenzó a esconderse por la noche, sumergiéndose en experimentos y escribiendo durante diez años todas las noches, y publicó una obra maestra de más de 1000 páginas, A New Kind of Science.
El punto de vista principal en el libro es: todo está calculado, y varios fenómenos complejos en el universo, incluidos los producidos por humanos o de naturaleza espontánea, pueden simularse mediante cálculos simples con algunas reglas.
La declaración de la reseña del libro en Amazon puede entenderse mejor: "Galileo una vez afirmó que la naturaleza está escrita en el lenguaje de las matemáticas, pero Wolfram cree que la naturaleza está escrita en lenguajes de programación (y lenguajes de programación muy simples)".
Además, estos fenómenos o sistemas, como el trabajo del cerebro humano y la evolución del sistema meteorológico, son equivalentes en términos de cálculo y tienen la misma complejidad, lo que se denomina "principio de equivalencia computacional".
El libro es muy popular, porque el lenguaje es muy popular, y hay casi mil dibujos, pero también hay muchas críticas del círculo académico, especialmente de los viejos colegas físicos. Las teorías concentradas principalmente en el libro no son originales (el trabajo de Turing sobre la complejidad computacional, el juego de la vida de Conway, etc. son similares) y carecen de rigor matemático, por lo que muchas conclusiones son difíciles de superar (por ejemplo, la selección natural no es la causa raíz de la complejidad biológica, Scott Aaronson, autor del libro de Turing "Curso abierto de computación cuántica", también señaló que el método de Wolfram no puede explicar los resultados centrales de la prueba de Bell en la computación cuántica).
Wolfram respondió a las críticas lanzando el motor informático de conocimiento Wolfram|Alpha, considerado por muchos como la primera tecnología de inteligencia artificial realmente práctica. Combinando conocimiento y algoritmos, permite a los usuarios emitir comandos en lenguaje natural y el sistema devuelve respuestas directamente. Los usuarios de todo el mundo pueden usar este poderoso sistema a través de la web, Siri, Alexa, incluido el complemento ChatGPT.
Si tomamos la red neuronal representada por ChatGPT para observar la teoría de Wolfram, encontraremos una relación coincidente: la arquitectura autorregresiva subyacente de GPT, en comparación con muchos modelos de aprendizaje automático, puede clasificarse como "computación con reglas simples", y su capacidad emerge a través de la acumulación de cambios cuantitativos.
Wolfram a menudo brinda soporte técnico para las películas de ciencia ficción de Hollywood y utiliza el lenguaje de programación Mathematica y Wolfram para generar algunos efectos realistas. Los más famosos incluyen el efecto de lente gravitacional del agujero negro en "Interstellar" y el lenguaje alienígena mágico que puede trascender el tiempo y el espacio en "Arrival".


Eventualmente dejó la academia ese año, vinculado a una disputa con sus colegas de Princeton. El maestro Feynman escribió para persuadirlo: "No entenderás los pensamientos de la gente común, son solo tontos para ti".
Hice lo mío y viví una vida maravillosa.
Stephen Wolfram es increíble.
libro extraño
Cosas extrañas + gente extraña, este libro es, por supuesto, un libro extraño.
Es un milagro en sí mismo que un maestro como Stephen Wolfram pueda escribir un libro popular sobre un tema de gran interés para una amplia gama de lectores.
Pasó de la física pura a los sistemas complejos hace 40 años porque quería resolver los primeros principios de fenómenos como la inteligencia humana, y ha acumulado mucho. Debido a sus amplios contactos, se ha comunicado con figuras clave como Geffrey Hinton, Ilya Sutskever y Dario Amodei, y tiene información de primera mano, lo que garantiza la precisión de la tecnología. No es de extrañar que el CEO de OpenAI lo llamara "la mejor explicación del principio de ChatGPT" después de la publicación de este libro.
Todo el libro está dividido en dos partes y el espacio es muy pequeño, pero se mencionan los puntos más importantes sobre ChatGPT y la explicación es popular y completa.
Inicié el "Campamento de aprendizaje de ChatGPT" en la comunidad de Turing. Tuve muchos intercambios con estudiantes de varios niveles técnicos y antecedentes profesionales. Descubrí que es muy importante comprender el modelo grande y establecer correctamente algunos conceptos básicos. Sin estos pilares, incluso si es un ingeniero de algoritmos senior, su cognición puede estar muy sesgada.
Por ejemplo, uno de los conceptos centrales de la ruta técnica de GPT es usar la arquitectura de generación autorregresiva más simple para resolver problemas de aprendizaje no supervisados, es decir, usar los datos originales sin etiquetado humano y luego aprender el mapeo de los datos al mundo a partir de ellos. Entre ellos, la arquitectura generativa autorregresiva es el muy popular "solo agrega una palabra a la vez" en el libro. Es importante señalar aquí que el propósito de elegir esta arquitectura no es hacer tareas de generación, sino comprender o aprender, y darse cuenta de las capacidades generales del modelo. En los años anteriores e incluso posteriores a 2020, muchos profesionales de la industria dieron por sentado que GPT era para generar tareas y optaron por ignorarlo. Como todos saben, el título del documento GPT-1 es "Mejorar la comprensión del lenguaje a través del preentrenamiento generativo".
Para poner otro ejemplo, para los lectores que no tienen muchos antecedentes técnicos o de aprendizaje automático, la dificultad inmediata que pueden encontrar al comprender los últimos desarrollos en inteligencia artificial es que no pueden comprender los viejos conceptos básicos de "modelo" y "parámetros (pesos en redes neuronales)", y estos conceptos no son tan fáciles de explicar con claridad. En este libro, el gran autor lo explicó con ejemplos intuitivos (funciones y perillas) muy cuidadosamente. (Consulte la sección "Qué es un modelo")
Las diversas secciones sobre redes neuronales son ricas en imágenes y textos, creo que será muy útil para todo tipo de lectores tener una comprensión más profunda de la naturaleza de las redes neuronales y su proceso de entrenamiento, así como conceptos como funciones de pérdida y descenso de gradiente.
El autor no ignoró la naturaleza ideológica en la explicación, por ejemplo, los siguientes párrafos son una buena introducción al significado del aprendizaje profundo:
El gran avance en el "aprendizaje profundo" alrededor de 2012 estuvo relacionado con el descubrimiento de que podría ser más fácil minimizar (al menos aproximadamente) cuando hay muchos pesos involucrados que cuando hay relativamente pocos pesos involucrados.
En otras palabras, puede parecer contrario a la intuición que los problemas complejos a veces son más fáciles de resolver con redes neuronales que con los simples. La razón general es que cuando hay muchas "variables de peso", hay "muchas direcciones diferentes" en el espacio de alta dimensión que nos pueden llevar al mínimo; y cuando hay menos variables, es fácil caer en el "lago de montaña" del mínimo local y no puede encontrar la "dirección de salida".
Este párrafo deja en claro el valor del aprendizaje de extremo a extremo:
En los primeros días de las redes neuronales, la gente tendía a pensar que "las redes neuronales deberían hacer lo menos posible". Por ejemplo, cuando se convierte el habla en texto, se cree que primero se debe analizar el audio del discurso, desglosarlo en fonemas, etc. Pero resulta que (al menos para "tareas similares a las humanas") el mejor enfoque suele ser tratar de entrenar una red neuronal para "resolver el problema de principio a fin", permitiéndole "descubrir" las funciones intermedias necesarias, codificaciones, etc. por su cuenta.
Dominar el por qué de estos conceptos es beneficioso para comprender los antecedentes de GPT.
El concepto de incrustación es crucial para los investigadores de algoritmos que participan en el desarrollo de modelos a gran escala, los programadores que se basan en el desarrollo de aplicaciones de modelos a gran escala y los lectores comunes que desean comprender GPT en profundidad. También es la "idea central de ChatGPT", pero es relativamente abstracto y no particularmente fácil de entender. La sección "El concepto de 'incrustación'" en este libro es la mejor explicación que he visto de este concepto. A través de los tres métodos de diagrama, código e interpretación de texto, creo que todos pueden entenderlo. Por supuesto, hay muchas imágenes en color en la sección "Espacio de significado y leyes del movimiento semántico" en el siguiente texto, que pueden profundizar más en este concepto.
Al final de esta sección, también se presentan tokens de palabras comunes (token) y se dan varios ejemplos intuitivos en inglés.
La siguiente introducción al principio de funcionamiento y al proceso de capacitación de ChatGPT también es popular y rigurosa. La tecnología más complicada de Transformer está muy detallada, y también se informa verazmente que la teoría actual no ha descubierto por qué esto es efectivo.
La primera parte termina al final, combinando la teoría de irreductibilidad computacional del autor, elevando la comprensión de ChatGPT a un nivel superior, que es similar a la idea general de GPT que Illya Sutskever enfatizó en múltiples entrevistas es obtener la representación comprimida del modelo mundial a través de la generación.
En mi opinión, este pasaje es muy estimulante:
¿Qué se necesita para producir un "lenguaje humano significativo"? En el pasado, podríamos haber pensado que el cerebro humano era esencial. Pero ahora sabemos que la red neuronal de ChatGPT también puede hacer un muy buen trabajo. …Sospecho firmemente que el éxito de ChatGPT insinúa un hecho "científico" importante: que el lenguaje humano significativo es en realidad más estructurado y más simple de lo que sabemos, y puede terminar siendo posible describir cómo organizar dicho lenguaje con reglas bastante simples.
El lenguaje es una herramienta para el pensamiento serio, la toma de decisiones y la comunicación. En comparación con la percepción y la acción, debería ser la tarea más difícil de la inteligencia desde la perspectiva de la secuencia de adquisición y la dificultad de los niños. Pero es probable que ChatGPT haya descifrado la contraseña, como dijo Wolfram "". Esto indica que en el futuro, podemos mejorar mucho más el nivel general de inteligencia a través del lenguaje informático u otras representaciones.
Más allá de esto, el progreso de la inteligencia artificial puede tener efectos similares en varias disciplinas: temas que antes se consideraban difíciles en realidad no lo son tanto desde otra perspectiva. Junto con la bendición de un asistente inteligente de propósito general como GPT, "algunas tareas han cambiado de básicamente imposibles a básicamente factibles", y finalmente el nivel tecnológico de toda la humanidad ha alcanzado una nueva altura.
La segunda parte de este libro es una introducción a la comparación y combinación de los sistemas ChatGPT y Wolfram|Alpha, con muchos ejemplos. Si la inteligencia general de GPT se parece más a los seres humanos, la mayoría de los seres humanos no son buenos en el cálculo y el pensamiento precisos por naturaleza.La combinación de modelos de propósito general y modelos de propósito especial en el futuro también debería ser una dirección prometedora.
Es un poco lamentable que este libro solo se centre en la parte previa al entrenamiento de ChatGPT, pero no cubra los siguientes pasos de ajuste que también son importantes: ajuste fino supervisado (SFT), modelado de recompensas y aprendizaje reforzado. Un mejor material de aprendizaje en este sentido es el discurso "Estado de GPT" dado por Andrej Karpathy, miembro fundador de OpenAI y exlíder de IA de Tesla, en la conferencia Microsoft Build en mayo de 2023.

He proporcionado un video de este discurso e imágenes de texto refinado en chino en el "Campamento de aprendizaje ChatGPT" de la comunidad de Turing. También habrá una clase de lectura guiada de este libro en el futuro. Bienvenidos a todos a unirse.
El Sr. Liu Jiang y el Sr. Wan Weigang compartirán el contenido relacionado con el libro "Esto es ChatGPT" el 25 de julio. ¡Bienvenido a hacer una cita a continuación!
Haga clic para leer el texto original y unirse al campamento de aprendizaje de ChatGPT.