
Antecedentes: en la actualidad, la versión de milvsu se ha iterado a 2.0 y ya puede admitir la ejecución directamente en el entorno de la ventana acoplable.

Tabla de contenido
1. La situación básica de Milvus
¿Qué es la base de datos de vectores Milvus?
Recuperación de similitud de vectores
¿Por qué elegir utilizar Milvus?
Herramienta de gestión visual para la biblioteca de vectores Milvus
Base de datos de vectores de operación Java
Dificultades encontradas en la manipulación de datos
1. La situación básica de Milvus
¿Qué es la base de datos de vectores Milvus?
Milvus fue de código abierto en 2019 y se dedica a almacenar, indexar y administrar vectores de incrustación masivos generados por el aprendizaje de redes neuronales profundas y otros modelos de aprendizaje automático.
La base de datos de vectores de Milvus está especialmente diseñada para consultas y recuperación de vectores, y puede indexar billones de datos de vectores. A diferencia de las bases de datos relacionales existentes que se utilizan principalmente para procesar datos estructurados, Milvus está diseñado para procesar vectores de incrustación convertidos a partir de varios datos no estructurados.
Con el desarrollo continuo de Internet, los datos no estructurados como correos electrónicos, documentos, datos de sensores IoT, fotos de redes sociales y estructuras moleculares de proteínas se han vuelto cada vez más comunes. Si desea usar una computadora para procesar estos datos, necesita usar tecnología de incrustación para convertir estos datos en vectores. Luego, Milvus almacena e indexa estos vectores. Milvus es capaz de analizar la correlación de dos vectores según la distancia entre ellos. Si dos vectores son muy similares, significa que los datos de origen representados por los vectores también son muy similares.
datos no estructurados
Los datos no estructurados se refieren a datos con estructura de datos irregular, sin modelo de datos predefinido unificado y datos que no son convenientes para ser representados por tablas lógicas bidimensionales de la base de datos. Los datos no estructurados incluyen imágenes, videos, audio, lenguaje natural, etc., que representan el 80 % de todos los datos. El procesamiento de datos no estructurados se puede llevar a cabo convirtiéndolos en datos vectoriales a través de varios modelos de inteligencia artificial (IA) o aprendizaje automático (ML).
Vector de características
Vector, también conocido como vector de incrustación, se refiere a un vector continuo transformado a partir de variables discretas (como imágenes, videos, audio, lenguaje natural, etc.) mediante tecnología de incrustación. En la representación matemática, un vector es una matriz de n dimensiones compuesta por números de coma flotante o datos binarios. A través de técnicas modernas de transformación de vectores, como varios modelos de inteligencia artificial (IA) o aprendizaje automático (ML), los datos no estructurados se pueden abstraer en vectores en un espacio vectorial de características n-dimensional. De esta forma, el algoritmo del vecino más cercano (ANN) se puede utilizar para calcular la similitud entre los datos no estructurados.
Recuperación de similitud de vectores
La recuperación de similitud se refiere a comparar el objeto de destino con los datos en la base de datos y recordar los resultados más similares. De manera similar, la recuperación de similitud de vectores devuelve los datos vectoriales más similares. El algoritmo del vecino más cercano aproximado (ANN) puede calcular la distancia entre vectores, mejorando así la velocidad de recuperación de similitud de vectores. Si dos vectores son muy similares, significa que los datos de origen que representan también son muy similares.
¿Por qué elegir utilizar Milvus?
- Alto rendimiento: tiene un alto rendimiento y puede realizar la recuperación de similitud de vectores en conjuntos de datos masivos.
- Alta disponibilidad y confiabilidad: Milvus admite la expansión en la nube y su capacidad de recuperación ante desastres puede garantizar una alta disponibilidad del servicio.
- Consulta híbrida: Milvus admite el filtrado de campos escalares durante la recuperación de similitud de vectores para lograr una consulta híbrida.
- Desarrollador amigable: ecosistema Milvus que admite múltiples idiomas y múltiples herramientas.
2. Descarga e instala Milvus
requisitos previos
Antes de instalar Milvus, verifique si su hardware y software cumplen con los requisitos.
Instalar con Docker Compose Instalar con Kubernetes
Requisitos de hardware
| hardware | Requerir | Configuración recomendada | ilustrar |
|---|---|---|---|
| UPC | Intel CPU Sandy Bridge o superior |
|
La versión actual de Milvus no es compatible con las CPU AMD y Apple M1. |
| conjunto de instrucciones de la CPU |
|
|
La búsqueda de similitud de vectores y la creación de índices en Milvus requieren soporte de CPU para el conjunto ampliado de datos múltiples de instrucción única (SIMD). Asegúrese de que la CPU admita al menos una de las extensiones SIMD enumeradas. Consulte CPU con AVX para obtener más información . |
| RAM |
|
|
El tamaño de la RAM depende de la cantidad de datos. |
| disco duro | SSD SATA 3.0 o superior | SSD SATA 3.0 o superior | El tamaño del disco duro depende de la cantidad de datos. |
Requisitos de Software
| Sistema operativo | software | ilustrar |
|---|---|---|
| macOS 10.14 o superior | Escritorio acoplable | Una máquina virtual Docker (VM) se ejecuta con al menos 2 CPU virtuales (vCPU) y 8 GB de memoria inicial. De lo contrario, la instalación puede fallar. Consulte Instalar Docker Desktop en Mac para obtener más información . |
| distribución de linux |
|
Consulte Instalar Docker Engine e Instalar Docker Compose para obtener más información . |
| Windows con WSL 2 habilitado | Escritorio acoplable | Le recomendamos que almacene el código fuente y otros enlaces de datos en contenedores de Linux en el sistema de archivos de Linux en lugar del sistema de archivos de Windows. Consulte Instalar Docker Desktop en Windows con backend WSL 2 para obtener más información . |
| software | Versión |
|---|---|
| etc. | 3.5.0 |
| E/S mínima | LANZAMIENTO.2020-11-06T23-17-07Z |
| púlsar | 2.8.2 |
Este artículo presenta principalmente la instalación y descarga del cliente de escritorio Docker y los problemas relacionados encontrados
Actualmente, la versión de escritorio de docker se ha actualizado a 4.90, pero se recomienda no usar la última versión, la versión de escritorio de docker 4.4.4 utilizada en esta máquina.
Lista histórica de descargas de la versión de Docker Desktop【Notas de la versión de Docker Desktop | Documentación de Docker】
Después de la descarga, simplemente inicie la ventana acoplable directamente. Puede aparecer un mensaje de error que indica que la interfaz no se pudo iniciar. Puede actualizar WSL 2 de acuerdo con el mensaje emergente
Actualizar WSL [ Pasos de instalación manual para versiones anteriores de WSL | Microsoft Docs ]
Recuerde reiniciar la computadora después de la actualización y luego vuelva a iniciar la ventana acoplable. Después de que aparezca la interfaz de inicio exitosa, significa que el entorno de la ventana acoplable se ha implementado y puede comenzar la descarga e instalación de Milvus.
Descargar e instalar Milvus
La versión independiente y la versión distribuida se pueden instalar de acuerdo con los requisitos del proyecto 【Instalar la versión independiente de Milvus: documentación de Milvus】.
Esta máquina se instala como una versión independiente
https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml1. Abra el enlace anterior en su navegador y descargue milvus-standalone-docker-compose.yml
2. Una vez completada la descarga, cámbiele el nombre a docker-compose.yml
3. Cree una nueva carpeta para almacenar la configuración, por ejemplo: MilvusFolder, coloque el archivo yml en esta carpeta
4. En la ventana negra cmd debajo de la ruta actual del archivo yml, ejecute el siguiente comando para descargar la biblioteca de vectores
docker-compose up -d5. Una vez completada la descarga, abra la ventana acoplable nuevamente y podrá ver que hay 3 contenedores Docker ejecutándose (2 para servicios básicos y 1 para servicios Milvus), respectivamente:
sudo docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -listen-peer-urls=htt ... Up (healthy) 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp,:::19530->19530/tcp
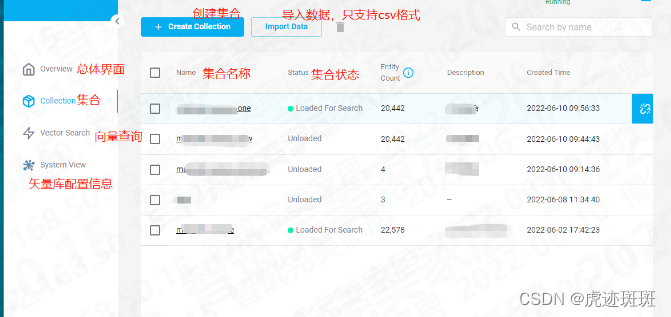
Herramienta de gestión visual para la biblioteca de vectores Milvus
La herramienta de visualización presentada en este artículo es attu, nota [Attu solo es compatible con Milvus 2.x]
Esta máquina se instala descargando el paquete de instalación (Ventana) [ Instalación de Attu - Documentación de Milvus ]
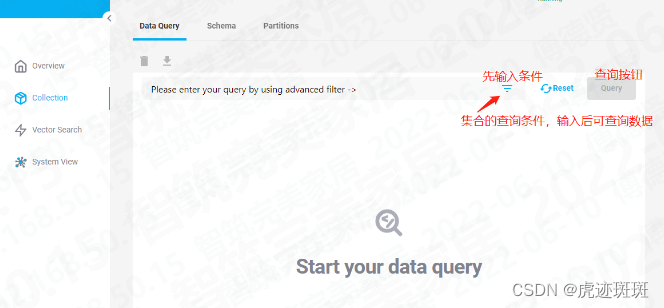
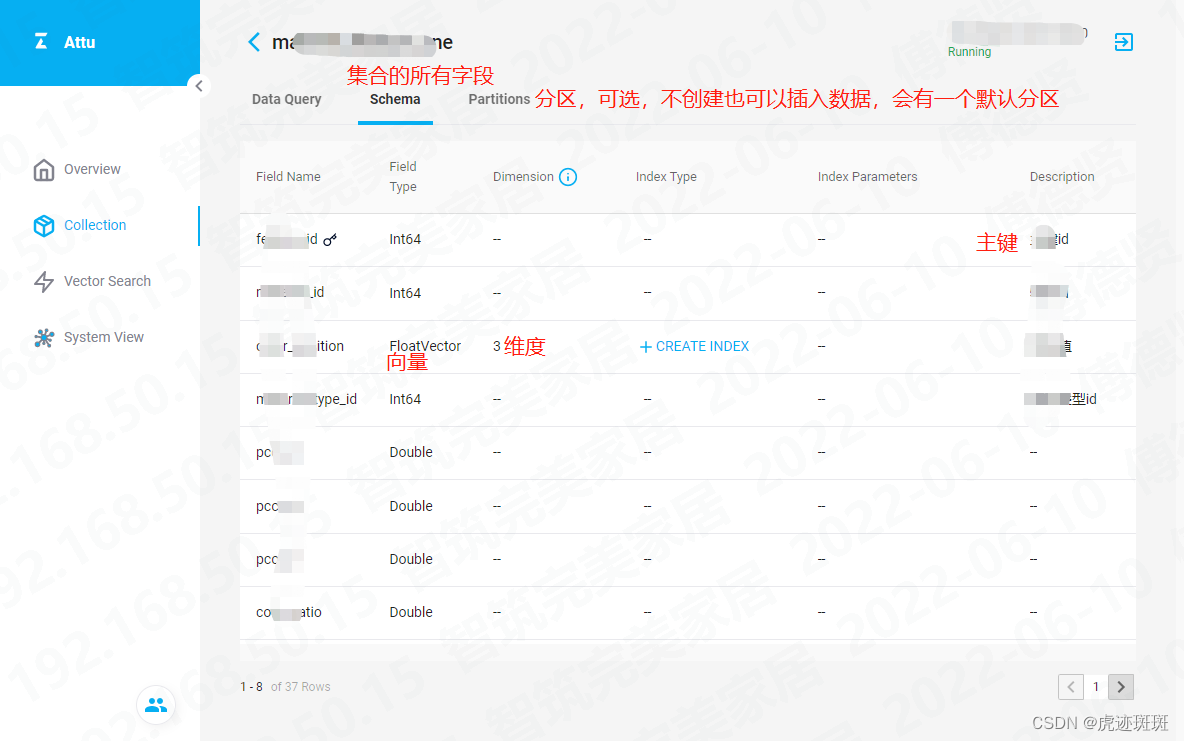
El siguiente es el diagrama después de la instalación:
Base de datos de vectores de operación Java
control de versiones
- versión milvus-sdk-java
2.0.0 - Versión SpringBoot
2.3.0.RELEASE
manipulación de datos
1. importación pom.xml
<dependencia>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.0.0</version>
</dependency>
2. KiteServiceClient
Si necesita interactuar con milvus, debe llamar a MilvusServiceClient. Mi enfoque aquí es definirlo como un Bean, donde debe usarse para la inyección de dependencia.
@Configuration
public class MilvusConfig {
@Value("${milvus.host}")
private String host; //milvus所在服务器地址
@Value("${milvus.port}")
private Integer port; //milvus端口
@Bean
public MilvusServiceClient milvusServiceClient() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(host)
.withPort(port)
.build();
return new MilvusServiceClient(connectParam);
}
}
3. Clases de uso común
3.1 ¡Primero recuerde crear una clase constante (utilizada para almacenar los parámetros necesarios para esta colección)! ! !
public class PushMaterielsConfig{
/**
* 集合名称(库名)
*/
public static final String COLLECTION_NAME = "materiel_feature_one";
/**
* 分片数量
*/
public static final Integer SHARDS_NUM = 8;
/**
* 分区数量
*/
public static final Integer PARTITION_NUM = 16;
/**
* 分区前缀
*/
public static final String PARTITION_PREFIX = "shards_";
/**
* 特征值长度
*/
public static final Integer FEATURE_DIM = 256;
/**
* 字段
*/
public static class Field {
/**
* 主键id
*/
public static final String ARCHIVE_ID = "feature_id";
/**
* 物料id
*/
public static final String ORG_ID = "materiel_id";
/**
* 特征值
*/
public static final String COLOR_POSITION= "color_position";
}
}
3.2 creatCollection (crear colección)
//创建集合
public boolean creatCollection(String collectionName){
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
FieldType featureId = FieldType.newBuilder()
.withName(PushMaterielsConfig.Field.FEATURE_ID)
.withDescription("主键id")
.withDataType(DataType.Int64)
.withPrimaryKey(true)
.withAutoID(false)
.build();
FieldType materielId = FieldType.newBuilder()
.withName(PushMaterielsConfig.Field.MATERIEL_ID)
.withDescription("物料id")
.withDataType(DataType.Int64)
.build();
FieldType colorPosition = FieldType.newBuilder()
.withName(PushMaterielsConfig.Field.COLOR_POSITION)
.withDescription("特征值")
.withDataType(DataType.FloatVector)
.withDimension(PushMaterielsConfig.FEATURE_DIM)
.build();
FieldType materielTypeId = FieldType.newBuilder()
.withName(PushMaterielsConfig.Field.MATERIEL_TYPE_ID)
.withDescription("物料类型id")
.withDataType(DataType.Int64)
.build();
CreateCollectionParam createCollectionReq = CreateCollectionParam.newBuilder()
.withCollectionName(collectionName)
.withDescription("特征集合")
//.withShardsNum(PushMaterielsConfig.SHARDS_NUM)
.addFieldType(featureId)
.addFieldType(materielId)
.addFieldType(colorPosition)
.addFieldType(materielTypeId)
.addFieldType(disorder)
.build();
R<RpcStatus> response = milvusClient.createCollection(createCollectionReq);
LOGGER.info(PushMaterielsConfig.COLLECTION_NAME+"是否成功创建集合——>>"+response.getStatus());
return PushMaterielsConfig.TURE.equals(response.getStatus()) ? true : false;
}
3.3 isExitCollection (juzgando si la colección ya existe)
//判断集合是否已经存在
public boolean isExitCollection(String collectionName){
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<Boolean> response = milvusClient.hasCollection(
HasCollectionParam.newBuilder()
.withCollectionName(collectionName)
.build());
return PushMaterielsConfig.TURE.equals(response.getStatus()) ? true : false;
}3.4 createPartition (crear partición) [opcional, si no se crea, se seleccionará la partición predeterminada para el almacenamiento de datos]
//创建分区
public void createPartition(String collectionName, String partitionName){
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.createPartition(CreatePartitionParam.newBuilder()
.withCollectionName(collectionName) //集合名称
.withPartitionName(partitionName) //分区名称
.build());
}
/**
* 先定义了分区总数PARTITION_NUM, 然后循环建立分区,在查询或者插入的时候根据里面的某个值进行取模,分到对应的分区里面去
* PARTITION_NUM=10
* */
public void test(){
for (int i = 0; i < 10; i++) {
createPartition(PushMaterielsConfig.COLLECTION_NAME, PushMaterielsConfig.PARTITION_PREFIX + i);
}
}3.5 createIndex (crear índice)
/**
* 创建索引
*/
public R<RpcStatus> createIndex(String collectionName, String fieldName) {
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.createIndex(CreateIndexParam.newBuilder()
.withCollectionName(collectionName)
.withFieldName(fieldName)
.withIndexType(IndexType.IVF_FLAT)
.withMetricType(MetricType.IP)
//nlist 建议值为 4 × sqrt(n),其中 n 指 segment 最多包含的 entity 条数。
.withExtraParam("{\"nlist\":16384}")
.withSyncMode(Boolean.FALSE)
.build());
LOGGER.info("createIndex-------------------->{}", response.toString());
R<GetIndexBuildProgressResponse> idnexResp = milvusClient.getIndexBuildProgress(
GetIndexBuildProgressParam.newBuilder()
.withCollectionName(collectionName)
.build());
LOGGER.info("getIndexBuildProgress---------------------------->{}", idnexResp.toString());
return response;
}3.6 insertPrepare (inserción de datos)
//数据插入
public String insertPrepare(String collectionName) {
//特征入Milvus前的数据处理
List<Long> featureIdList = new ArrayList();
List<Long> materielIdList = new ArrayList();
List<List<Float>> colorPostation = new ArrayList<>();
List<Long> materielTypeIdList = new ArrayList();
=====================================业务代码====================================
//查询特征数据,拿到需要插入的数据
List<FeatureColor> listColor = featureColorDao.list(new QueryWrapper<FeatureColor>().eq("is_included",PushMaterielsConfig.TURE));
if (WebplusUtil.isEmpty(listColor))return "No featureColor data found";
listColor.forEach(item->{
Long materielId = item.getMaterielId();
List<FeatureShape> shapeList = featureShapeDao.list(new QueryWrapper<FeatureShape>().eq("materiel_id",
materielId).eq("is_included", PushMaterielsConfig.TURE));
List<FeatureTexture> textureList = featureTextureDao.list(new QueryWrapper<FeatureTexture>().eq("materiel_id",
materielId).eq("is_included", PushMaterielsConfig.TURE));
//三缺一则跳过,不存入
if(WebplusUtil.isAnyEmpty(shapeList,textureList))return;
//过滤
FeatureShape materielshape = shapeList.size()> 1 ? shapeList.stream().sorted(Comparator.comparing(a ->
a.getUpdateDatetime())).collect(Collectors.toList()).get(0) : shapeList.get(0);
FeatureTexture materielTexture = textureList.size()> 1 ? textureList.stream().sorted(Comparator.comparing(a ->
a.getUpdateDatetime())).collect(Collectors.toList()).get(0) : textureList.get(0);
=====================================以上为业务代码====================================
featureIdList.add(item.getId());
materielIdList.add(item.getMaterielId());
materielTypeIdList.add(item.getMaterielTypeId());
List<Float> colorXYZ = new ArrayList<Float>();
colorXYZ.add(item.getColorX().floatValue());
colorXYZ.add(item.getColorY().floatValue());
colorXYZ.add(item.getColorZ().floatValue());
colorPostation.add(colorXYZ);
});
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field(PushMaterielsConfig.Field.FEATURE_ID, DataType.Int64, featureIdList));
fields.add(new InsertParam.Field(PushMaterielsConfig.Field.MATERIEL_ID, DataType.Int64, materielIdList));
fields.add(new InsertParam.Field(PushMaterielsConfig.Field.COLOR_POSITION, DataType.FloatVector, colorPostation));
fields.add(new InsertParam.Field(PushMaterielsConfig.Field.MATERIEL_TYPE_ID, DataType.Int64, materielTypeIdList));
return insert(collectionName,fields);
}
public String insert(String collectionName, List<InsertParam.Field> fields ){
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
//插入
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(collectionName)
//.withPartitionName(partitionName)
.withFields(fields)
.build();
R<MutationResult> insert = milvusClient.insert(insertParam);
LOGGER.info("插入:{}", insert);
return insert.getStatus().equals(PushMaterielsConfig.TURE) ? "InsertRequest successfully! Total number of " +
"inserts:{"+insert.getData().getInsertCnt()+"} entities" : "InsertRequest failed!";
}3.7 loadCollection (cargue la colección, antes de insertar datos, si la colección no está cargada en la memoria, primero debe cargar la colección y la partición, la carga de la partición es opcional (si es la partición predeterminada, no puede cargar la partición))
/**
* 加载集合
* */
public boolean loadCollection(String collectionName) {
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.loadCollection(LoadCollectionParam.newBuilder()
//集合名称
.withCollectionName(collectionName)
.build());
LOGGER.info("loadCollection------------->{}", response);
return response.getStatus().equals(PushMaterielsConfig.TURE) ? true : false;
}
/**
* 加载分区
* */
public void loadPartitions(String collectionName, String partitionsName) {
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.loadPartitions(
LoadPartitionsParam
.newBuilder()
//集合名称
.withCollectionName(collectionName)
//需要加载的分区名称
.withPartitionNames(Arrays.asList(partitionsName))
.build()
);
LOGGER.info("loadCollection------------->{}", response);
}3.8 releaseCollection (liberar colección de la memoria)
/**
* 从内存中释放集合
* */
public void releaseCollection(String collectionName) {
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.releaseCollection(ReleaseCollectionParam.newBuilder()
.withCollectionName(collectionName)
.build());
LOGGER.info("releaseCollection------------->{}", response);
}
/**
* 释放分区
* */
public void releasePartition(String collectionName, String partitionsName) {
MilvusServiceClient milvusClient = milvusConfig.milvusServiceClient();
R<RpcStatus> response = milvusClient.releasePartitions(ReleasePartitionsParam.newBuilder()
.withCollectionName(collectionName)
.addPartitionName(partitionsName)
.build());
LOGGER.info("releasePartition------------->{}", response);
}Dificultades encontradas en la manipulación de datos
1. Recuerde: como herramienta de visualización, attu se puede utilizar para consultas y eliminaciones simples, así como para operaciones de creación de colecciones y particiones, pero para operaciones complejas, se recomienda implementar código.
2. Después de insertar datos en la biblioteca de vectores, los datos insertados no se consultarán inmediatamente (para insertar más de 10,000 piezas de datos a la vez, siempre que la retroalimentación de estado de insertf sea 0, significa que la inserción es exitosa. Generalmente, debe esperar media hora antes de poder eliminar el tipo de situación)
3. La biblioteca de vectores no eliminará los datos de forma permanente, y el número total de entidades solo aumentará y no disminuirá. Sin embargo, siempre que la retroalimentación del estado eliminado de los datos eliminados sea 0, significa que la eliminación se realizó correctamente. Al realizar consultas a través de condiciones, los datos eliminados deben estar libres de consultas.
4. El tipo Int64 solo se puede almacenar en Long