Directorio de artículos
- ¿Qué es un contenedor?
- interfaz de contenedor
- implementación de contenedores
- Ciclo de vida del frijol
- Patrón de diseño de método de plantilla
- Postprocesador de frijol
- Postprocesador BeanFactory
- En cuanto al período de llamada del postprocesador (PostProcessor)
- Interfaz consciente e interfaz InitializingBean
- inicialización y destrucción
- Alcance
¿Qué es un contenedor?
Spring contiene y administra la configuración y el ciclo de vida de los objetos de la aplicación. En este sentido, es un contenedor para transportar objetos. Puede configurar cómo se crea cada uno de sus objetos Bean. Estos Beans pueden crear una instancia separada o generar una nueva instancia cada vez que se necesitan, y cómo se relacionan entre sí. Construir y usar.
Si un objeto Bean se entrega al contenedor Spring para su administración, entonces el objeto Bean debe desensamblarse de manera similar y almacenarse en la definición Bean. Esto es equivalente a una operación de desacoplamiento del objeto, que Spring puede administrar más fácilmente, como el manejo de dependencias circulares y otras operaciones.
Después de definir y almacenar un objeto Bean, Spring lo ensamblará de manera unificada. Este proceso incluye la inicialización del Bean, el llenado de propiedades, etc. Finalmente, podemos usar completamente un objeto instanciado de Bean.
interfaz de contenedor
En esta sección vamos a:
- ¿Sabes lo que puede hacer BeanFactory?
- ¿Qué funciones de extensión puede tener ApplicationContext?
- Desacoplamiento de eventos
Hay dos interfaces de contenedor bien conocidas en Spring, una es la interfaz BeanFactory y la otra es la interfaz ApplicationContext.
-
BeanFactory 接口, las funciones típicas son:- obtenerBean
-
ApplicationContext 接口, es una subinterfaz de BeanFactory. Extiende la funcionalidad de la interfaz BeanFactory, como:- globalización
- Obtenga un conjunto de recursos de recursos en modo comodín
- Integrar el entorno Environment (a través del cual se puede obtener información de configuración de varias fuentes)
- Publicación y monitorización de eventos para lograr el desacoplamiento entre componentes
Cuando solemos usar SpringBoot para ejecutar un proyecto, la clase de inicio es similar a esto:
public class HmDianPingApplication {
public static void main(String[] args) {
SpringApplication.run(HmDianPingApplication.class, args);
}
}
Usamos el método de ejecución para iniciar un programa SpringBoot, que tiene dos parámetros:
- Tipo de clase de inicio
- Los parámetros de la línea de comando pasados por el método principal
Este método de ejecución en realidad tiene un valor de retorno, que es nuestro contenedor Spring:
ConfigurableApplicationContext context = SpringApplication.run(A01.class, args);
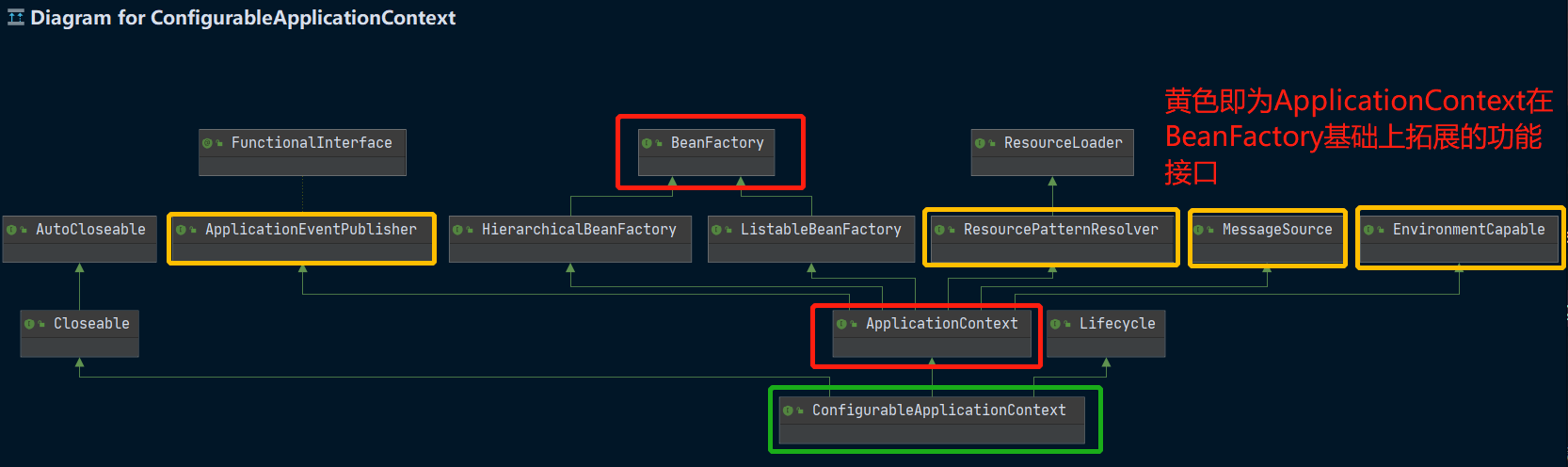
Entonces, ¿qué tiene que ver este ConfigurableApplicationContext con nuestras dos interfaces de contenedor? Podemos ver el diagrama de clases con Ctrl + Alt + u:
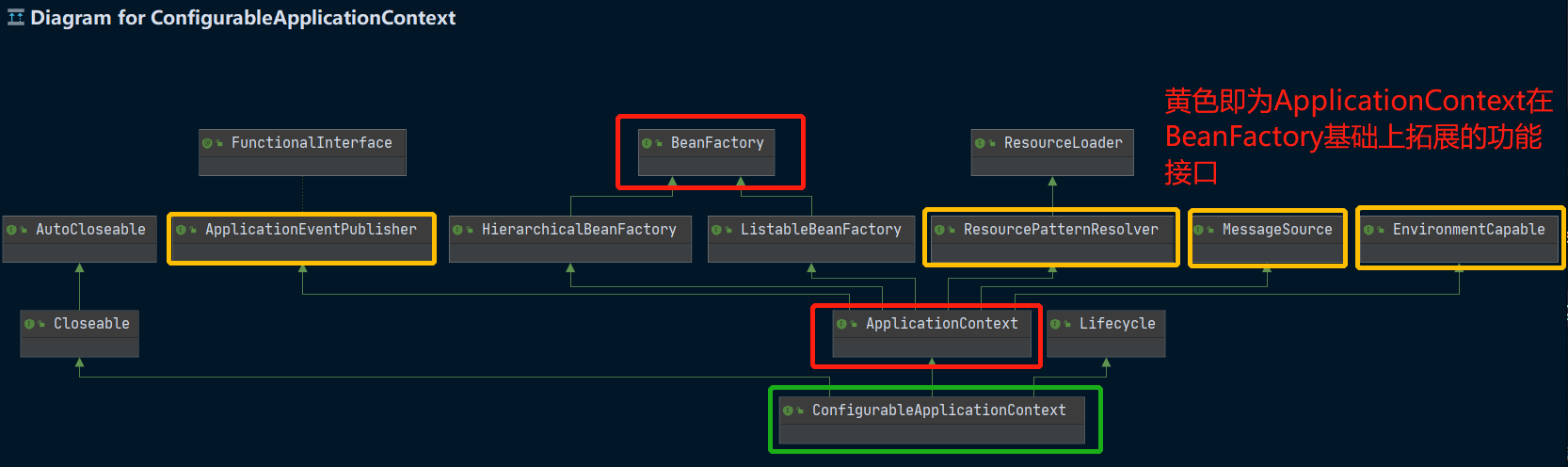
Podemos ver que ConfigurableApplicationContext realmente hereda de la interfaz ApplicationContext, y la interfaz ApplicationContext hereda de la interfaz BeanFactory.Es concebible que la interfaz ApplicationContext deba extender algunas funciones de la interfaz BeanFactory.
Este lugar respondemos una pregunta? ¿Qué es exactamente una BeanFactory?
- Es la interfaz principal de ApplicationContext.
- Es el contenedor central de Spring y las principales implementaciones de ApplicationContext [combinan] sus funciones
- Podemos ver el siguiente código, el método getBean es directamente el método en BeanFactory llamado:
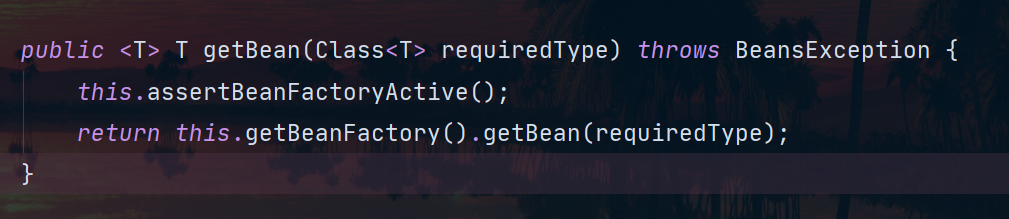
- BeanFactory es una variable miembro de ApplicationContext
- Podemos ver el siguiente código, el método getBean es directamente el método en BeanFactory llamado:
Luego resolvemos la segunda pregunta: ¿qué puede hacer BeanFactory?
Observamos directamente el método abstracto en esta interfaz y encontramos que es relativamente simple:
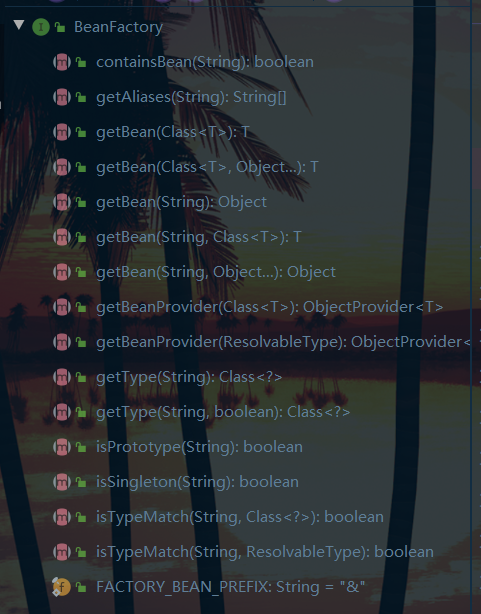
Parece que el método getBean es más útil. De hecho, no solo podemos mirar la interfaz sino también su implementación. La clase de implementación proporciona inversión de control, inyección de dependencia básica y varias funciones hasta el ciclo de vida del Bean.
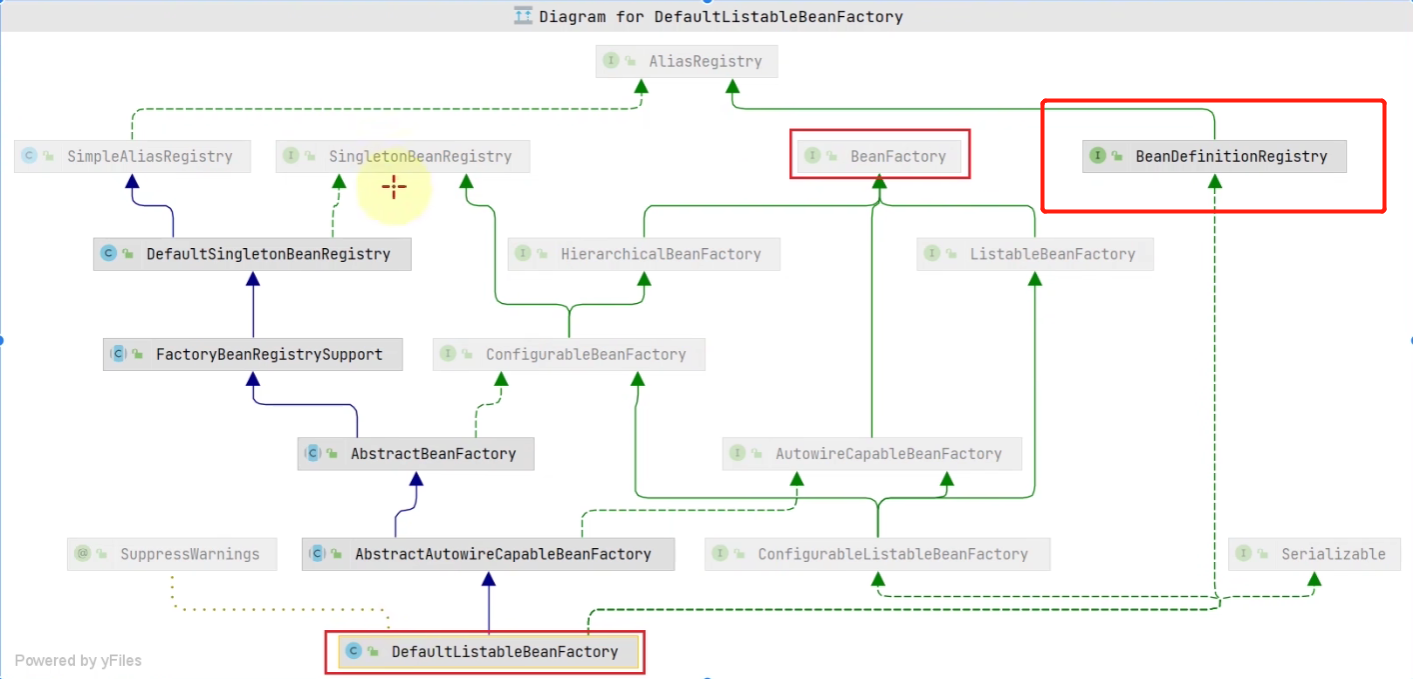
Y esta clase de implementación esDefaultListableBeanFactory
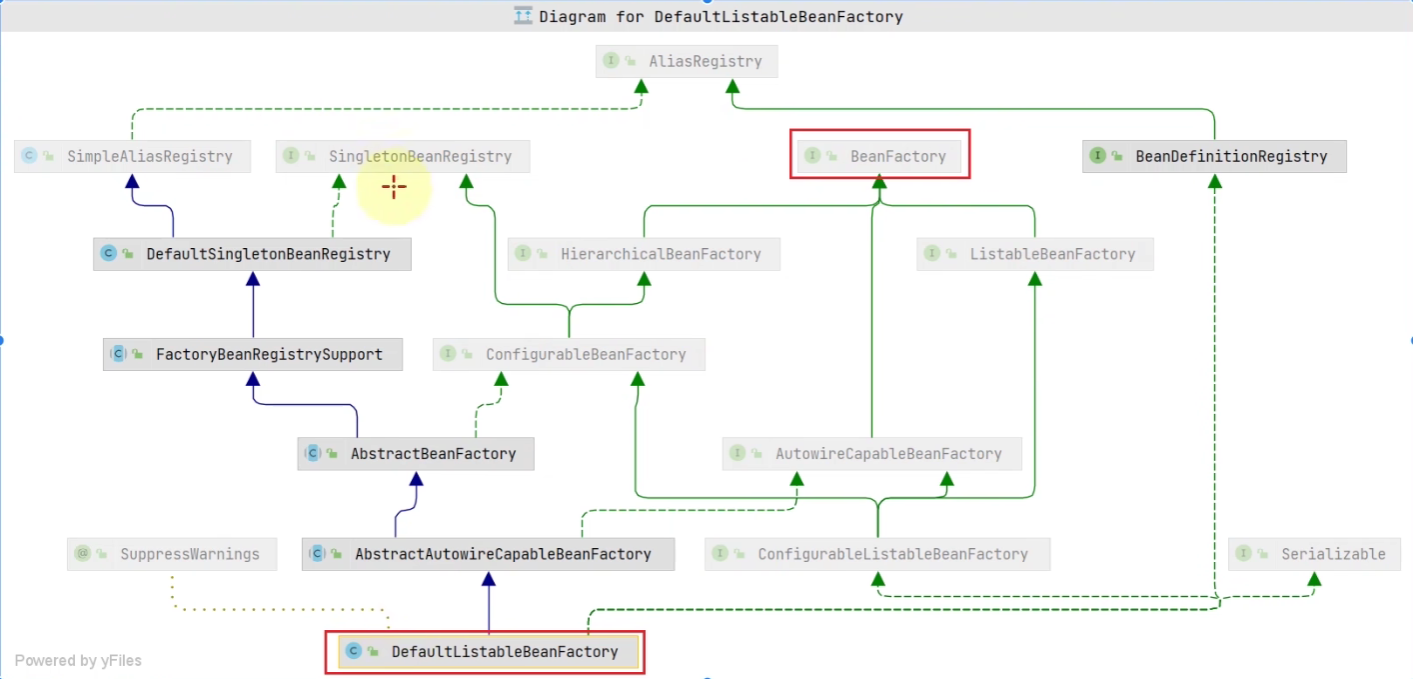
Podemos encontrar que BeanFactory es solo una pequeña parte de todas las interfaces que implementa.
Aviso:
DefaultListableBeanFactory en sí mismo no tiene la función de analizar automáticamente los archivos de configuración para el registro de Bean (generalmente existe la clase de implementación de ApplicationContext).
DefaultListableBeanFactory es una implementación básica de BeanFactory que puede:
- Registrar BeanDefinition
- Inyección de dependencia en BeanDefinition
- Administrar el ciclo de vida de Bean
- Ejecutar la devolución de llamada especificada cuando el contenedor se inicia y se apaga
- Delegados al BeanFactory principal, etc.
Sin embargo, no tiene la capacidad de analizar archivos de configuración por sí mismo. Si desea utilizar DefaultListableBeanFactory con el archivo de configuración, debemos analizar manualmente el archivo de configuración y luego registrar el BeanDefinition analizado en DefaultListableBeanFactory.
Podemos pensar en DefaultListableBeanFactory como una cocina, donde se puede lavar y cocinar, pero enviar platos a la cocina no pertenece al ámbito funcional de la cocina.
DefaultListableBeanFactory puede administrar todos los beans, entre los que estamos más familiarizados es que puede administrar objetos singleton, y esta función la realiza una de sus clases principales DefaultSingletonBeanRegistry, tiene una variable miembro singletonObjects para administrar todos los objetos singleton:
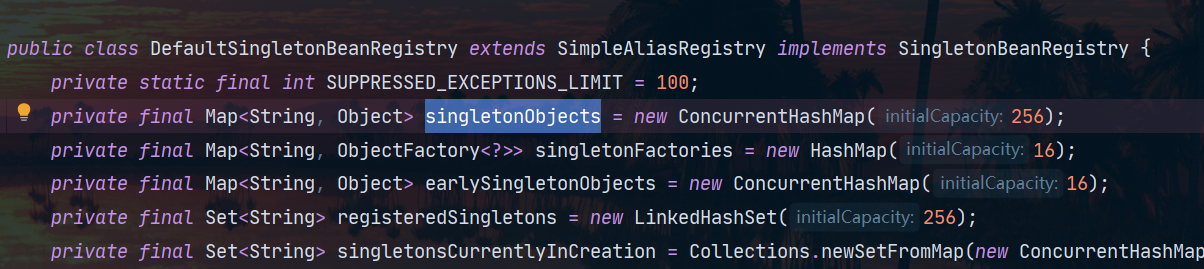
La clave es el nombre del bean y el valor es la instancia del objeto. Para entender este singletonObjects más claramente, usemos la reflexión para echarle un vistazo Aquí definimos nuestros propios dos beans y vamos a buscarlos:
Field singletonObjects = DefaultSingletonBeanRegistry.class.getDeclaredField("singletonObjects");
singletonObjects.setAccessible(true);
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
Map<String, Object> map = (Map<String, Object>) singletonObjects.get(beanFactory);
map.entrySet().stream().filter(e -> e.getKey().startsWith("component"))
.forEach(e -> {
System.out.println(e.getKey() + "=" + e.getValue());
});
Luego resolvemos la última pregunta: ¿ Qué tiene más de ApplicationContext que BeanFactory?
Podemos resolver este problema mediante una interfaz de herencia múltiple desde ApplicationContext:
-
MessageSource: un acceso a mensajes internacionalizados, su función principal es analizar los mensajes de acuerdo con la configuración regional para admitir la internacionalización.


En el futuro, la información de configuración regional se obtendrá del encabezado de solicitud del navegador.
-
ResourcePatternResolver: un solucionador de patrones de recursos, su función principal es resolver los recursos de acuerdo con la ubicación y el patrón especificados.
- Cargue los archivos de recursos según la ruta. Puede cargar archivos de recursos en la ruta de clases (classpath:), archivos de recursos en el sistema de archivos (archivo:), URL, etc.
- Se admite la coincidencia de rutas de estilo Ant y se pueden usar comodines como ? y * para hacer coincidir varios recursos.
- Los recursos pueden ser archivos de propiedades, archivos de configuración XML, imágenes, archivos de texto, etc.
- Si no se puede encontrar el recurso, no se informará ningún error y se devolverá un valor nulo.
-
Tomemos un ejemplo:


- classpath significa buscar desde la ruta de clases, si es un archivo, significa buscar desde el directorio del disco
- Si el archivo que busca está en el paquete jar, debe agregar un
*número para que pueda encontrarlo
-
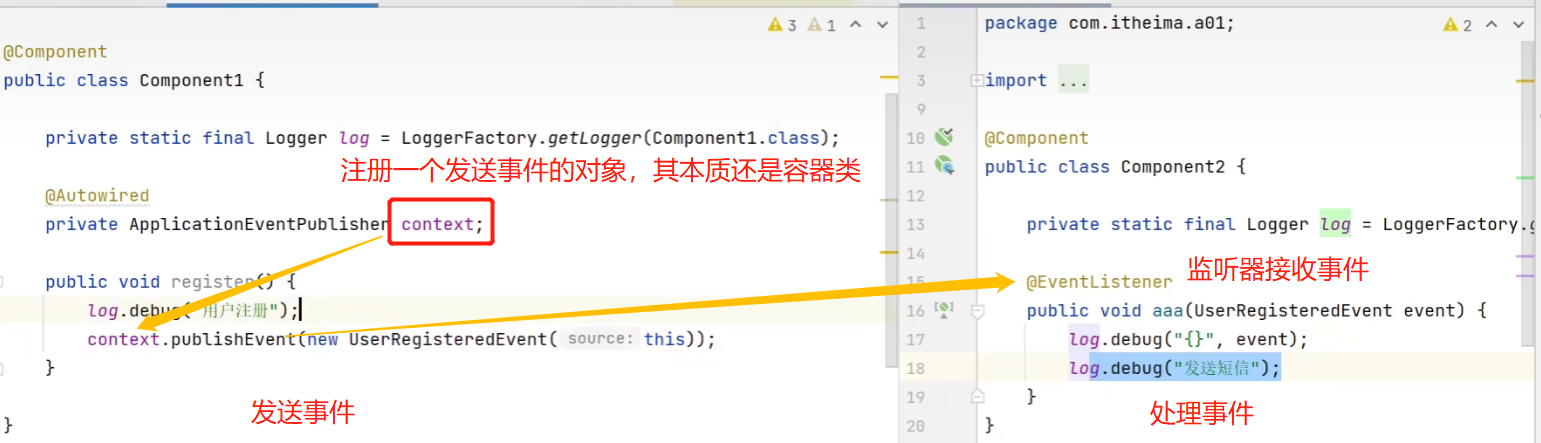
ApplicationEventPublisher: una interfaz de publicación de eventos cuya función principal es publicar eventos en aplicaciones Spring.
-
Remitente: heredar ApplicationEvent para definir un evento. Luego envíelo utilizando el método de publicación de eventos del contenedor. source representa el origen del evento del evento.


-
Receptor (oyente): Cualquier componente en Spring se puede usar como oyente, y qué evento se envía debe recibirse con el tipo de evento correspondiente:
-
El papel del evento: nos proporciona un método de desacoplamiento
-
-
EnvironmentCapable: Su función principal es permitir que los componentes accedan a Environment para leer información como variables de entorno, Profile(), archivos de configuración, etc.



Anteriormente dijimos que BeanFactory no tiene archivos de configuración de análisis automático para el registro de Bean, pero ApplicationContext sí, debido a este ResourcePatternResolver.
La función de ResourcePatternResolver es resolver recursos de recursos de acuerdo con el patrón de ubicación especificado. ApplicationContext usa ResourcePatternResolver para cargar los siguientes recursos:
El recurso devuelto por ResourcePatternResolver representa varias abstracciones de recursos, y ApplicationContext invoca al lector correspondiente de acuerdo con el tipo de recurso para el análisis y procesamiento de recursos..
Entonces, en resumen, ApplicationContext usa ResourcePatternResolver para la carga de recursos, lo que permite que ApplicationContext cargue recursos desde varias ubicaciones y de varias maneras, con una gran flexibilidad de configuración.
Finalmente hacemos un resumen:
-
¿Qué es exactamente BeanFactory?
- Es la interfaz principal de ApplicationContext.
- Es el contenedor principal de Spring. La implementación principal de ApplicationContext ha [combinado] sus funciones. [Combinado] significa que una variable miembro importante de ApplicationContext es BeanFactory
-
¿Qué puede hacer BeanFactory?
- En la superficie solo getBean
- De hecho, su clase de implementación proporciona varias funciones, como la inversión de control, la inyección de dependencia básica y el ciclo de vida del Bean.
- En el ejemplo, su variable miembro singletonObjects se ve a través de la reflexión, que contiene todos los beans singleton.
-
ApplicationContext es más que BeanFactory
- ApplicationContext combina y amplía la funcionalidad de BeanFactory
- Internacionalización y adquisición comodín de un conjunto de recursos Resource, integración del entorno Environment, lanzamiento y seguimiento de eventos
- Aprende una nueva forma de desacoplamiento entre códigos, desacoplamiento de eventos
Aviso
- Si jdk > 8, agregue --add-opens java.base/java.lang=ALL-UNNAMED cuando se ejecute, porque estas versiones de jdk no permiten la reflexión entre módulos de forma predeterminada
- La publicación de eventos también puede ser asíncrona, consulte @EnableAsync, uso de @Async
implementación de contenedores
En esta sección aprenderemos sobre:
- Características de la implementación de BeanFactory
- Implementación común y uso de ApplicationContext
- Contenedor integrado, DispatcherServlet registrado
Spring tiene una larga historia de desarrollo, por lo que todavía hay muchos materiales que explican sus implementaciones más antiguas. Por razones nostálgicas, todos se enumeran aquí para su referencia.
- DefaultListableBeanFactory es la implementación más importante de BeanFactory, implementa funciones como inversión de control e inyección de dependencia .
- ClassPathXmlApplicationContext, busque archivos de configuración XML desde classpath, cree un contenedor (antiguo)
- FileSystemXmlApplicationContext, busque el archivo de configuración XML desde la ruta del disco, cree un contenedor (antiguo)
- XmlWebApplicationContext, cuando se integra SSM tradicional, el contenedor se basa en el archivo de configuración XML (antiguo)
- AnnotationConfigWebApplicationContext, cuando se integra SSM tradicional, un contenedor basado en clases de configuración de Java (antiguo)
- AnnotationConfigApplicationContext, contenedor de entorno no web en Spring boot (nuevo)
- AnnotationConfigServletWebServerApplicationContext, contenedor de entorno web de servlet en Spring boot (nuevo)
- AnnotationConfigReactiveWebServerApplicationContext, contenedor de entorno web reactivo en Spring boot (nuevo)
Además, debe tenerse en cuenta que las siguientes clases con ApplicationContext son todas implementaciones de la interfaz ApplicationContext, pero son una combinación de las funciones de DefaultListableBeanFactory, no heredadas.
Implementación del contenedor BeanFactory
Aquí tomamos DefaultListableBeanFactory como ejemplo para crear un contenedor.
Cuando creamos por primera vez un objeto contenedor, no había beans en él, por lo que debemos agregarle algunas definiciones de beans, y luego el contenedor nos ayudará a crear beans de acuerdo con la definición, y finalmente podemos obtener el bean deseado a través del contenedor.。
La definición de bean incluye los siguientes aspectos:
- clase: La clase de implementación real del bean. Puede ser una clase ordinaria, una clase abstracta o una interfaz.
- nombre: El nombre del bean. Se utiliza para obtener objetos de frijol del contenedor.
- alcance: El alcance del bean. Incluyendo singleton, prototipo, solicitud, sesión, aplicación, etc.
- Argumentos del constructor: los valores de los parámetros del método de construcción del bean. Para la inyección de dependencia.
- propiedades: El valor de la propiedad del bean. Para la inyección de dependencia.
- autowire: El método de autowire del bean. Incluyendo no, byName, byType, constructor.
- lazy-init: inicialización diferida de beans.
- métodos de inicialización y destrucción: el método de inicialización y el método de destrucción del bean.
- depende de: Otros beans de los que depende el bean.
Ejemplo de una definición de frijol:
<bean id="helloBean" name="hello" class="com.example.HelloBean" scope="singleton">
<constructor-arg value="HelloSpring"/>
<property name="message" value="Hello World"/>
</bean>
Esta definición de bean contiene:
- id y nombre: helloBean y hola
- clase: com.ejemplo.HelloBean
- alcance: singleton
- constructor-arg: pasa el argumento "HelloSpring" al constructor
- property: establece el valor "Hello World" para la propiedad del mensaje
Cuando se inicia el contenedor, se creará una instancia de bean de acuerdo con la definición del bean, es decir, ejecutar:
HelloBean bean = new HelloBean("HelloSpring");
bean.setMessage("Hello World");
La instancia de bean creada se almacenará en el grupo de caché de singleton, la clave es el nombre del bean y luego el objeto bean se puede obtener del contenedor por su nombre.
Entonces, en resumen, la definición del bean determina las características del bean, diciéndole a Spring qué instanciar, cuáles son las dependencias, cuál es el alcance, cómo crear el bean, etc. De acuerdo con la definición del bean, Spring puede inicializar el bean e insertarlo en la aplicación.
Veamos un trozo de código:
public class TestBeanFactory {
public static void main(String[] args) {
//创建一个容器类
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
// bean 的定义(class, scope, 初始化, 销毁)
//这里构建一个bean的定义,指明了类型和Scope
//genericBeanDefinition就是用来指定类型的
AbstractBeanDefinition beanDefinition =
BeanDefinitionBuilder.genericBeanDefinition(Config.class).setScope("singleton").getBeanDefinition();
//根据定义进行注册,执行bean的名称,创建bean
beanFactory.registerBeanDefinition("config", beanDefinition);
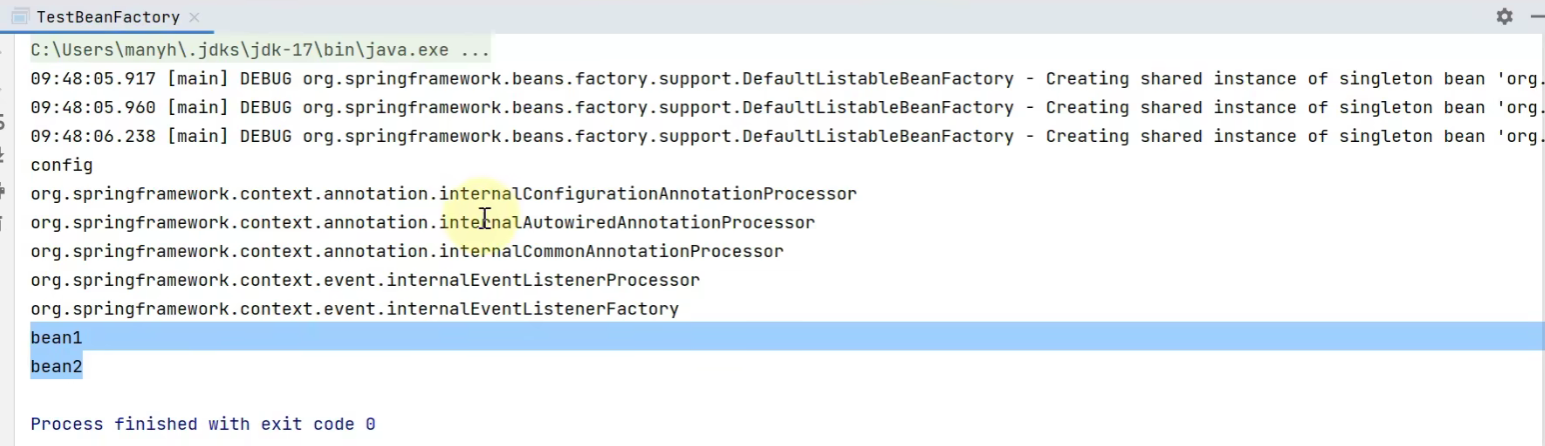
//打印一下现在容器中有的bean的定义
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
}
//这里不能使用非静态内部类,因为它需要外部类的实例才能实例化内部类
@Configuration
static class Config {
@Bean
public Bean1 bean1() {
return new Bean1();
}
@Bean
public Bean2 bean2() {
return new Bean2();
}
}
static class Bean1 {
private static final Logger log = LoggerFactory.getLogger(Bean1.class);
public Bean1() {
log.debug("构造 Bean1()");
}
@Autowired
private Bean2 bean2;
public Bean2 getBean2() {
return bean2;
}
}
static class Bean2 {
private static final Logger log = LoggerFactory.getLogger(Bean2.class);
public Bean2() {
log.debug("构造 Bean2()");
}
}
}
Consejos:
En el código anterior podemos ver el método registerBeanDefinition,Este método es para registrar un BeanDefinition en el BeanDefinitionRegistry, es decir, para incorporar una definición de bean en la gestión del contenedor Spring IoC..
BeanDefinitionRegistry es una interfaz en el contenedor de Spring, que define el método de registro y obtención de BeanDefinition, y puede ser utilizado como el gran ama de llaves de la definición de Bean en el contenedor. Su implementación típica es:
- DefaultListableBeanFactory: la implementación de BeanFactory más utilizada en Spring, que implementa la interfaz BeanDefinitionRegistry.
- AnnotationConfigApplicationContext: contexto de aplicación Spring anotado, que utiliza DefaultListableBeanFactory como delegado (modo decorador), por lo que también implementa la interfaz BeanDefinitionRegistry.
El método registerBeanDefinition es un método en la interfaz BeanDefinitionRegistry, y su definición es:
void registerBeanDefinition(String beanName, BeanDefinition >beanDefinition) throws BeanDefinitionStoreException;Recibe dos parámetros:
- beanName: nombre de frijol registrado
- beanDefinition: instancia de BeanDefinition utilizada para describir beans
Cuando se llama al método registerBeanDefinition, el contenedor Spring vinculará la instancia recibida de BeanDefinition con el beanName especificado y lo llevará a la administración. Esto significa que Spring administrará los procesos de creación, instanciación, configuración e inicialización del bean.
Por ejemplo, en AnnotationConfigApplicationContext, podemos registrar un BeanDefinition como este:public static void main(String[] args) { AnnotationConfigApplicationContext ctx = new >AnnotationConfigApplicationContext(); RootBeanDefinition beanDefinition = new >RootBeanDefinition(Person.class); ctx.registerBeanDefinition("person", beanDefinition); ctx.refresh(); Person person = ctx.getBean(Person.class); // ... }Aquí, creamos un RootBeanDefinition que describe el bean del tipo Person y luego llamamos al método registerBeanDefinition para registrarlo en ApplicationContext. Después de refresh(), el bean está disponible desde el contenedor.
Por lo tanto, el método registerBeanDefinition es una forma de registrar un nuevo bean en el contenedor Spring IoC y ponerlo bajo la administración del contenedor. Esta es una forma de agregar dinámicamente definiciones de bean al contenedor. Una vez que se registra la definición del bean, el contenedor puede realizar tareas de administración como la inicialización y la inyección de dependencia.
De acuerdo con los resultados, encontramos que solo existe la definición de config en el contenedor, pero de acuerdo con nuestro sentido común, config aquí es una clase de configuración Después de agregarle la anotación @Bean, nuestro contenedor también debe tener las definiciones de Bean1 y Bean2.
Es decir, la anotación @Configuration en Config, incluida la anotación @Bean, no se analizó. En otras palabras, nuestra DefaultListableBeanFactory no tiene la capacidad de analizar anotaciones y sus funciones no están completas.
Así que aquí presentamos una clase de herramienta relacionada con las anotaciones: AnnotationConfigUtils. Tiene un método estático registerAnnotationConfigProcessors (procesador de configuración de anotaciones de registro), que puede agregar algunos posprocesadores de uso común ( PostProcessor) a BeanFactory (por supuesto, no solo los posprocesadores de BeanFactory, sino también los posprocesadores de Bean, que se mencionarán más adelante). De hecho, es una expansión de nuestras funciones de contenedor.
Más detalladamente, la función del método AnnotationConfigUtils.registerAnnotationConfigProcessors esControladores de registros para manejar la configuración de anotaciones, estos procesadores se utilizarán para procesar anotaciones como @Configuration, @Import, @ComponentScan, etc.
Específicamente, este método registra los siguientes controladores:
-
ConfigurationClassPostProcessor: se utiliza para procesar anotaciones @Configuration, resolver clases anotadas por anotaciones @Configuration en uno o más objetos BeanDefinition y registrarlos en BeanFactory.
-
AutowiredAnnotationBeanPostProcessor: se utiliza para procesar @Autowired, @Value y otras anotaciones, e inyectar los campos o parámetros de método marcados por estas anotaciones en las instancias de Bean correspondientes.
-
CommonAnnotationBeanPostProcessor: se utiliza para procesar anotaciones JSR-250, como @Resource, @PostConstruct, etc.
-
PersistenceAnnotationBeanPostProcessor: se utiliza para procesar anotaciones JPA, como @PersistenceContext, @Transactional, etc.
Al registrar estos procesadores, Spring puede identificar y procesar automáticamente varias configuraciones de anotaciones, lo que facilita la realización de operaciones como la inyección de dependencia y el escaneo de componentes.
Después de agregar este método, ejecutamos cada procesador y recorremos el contenedor nuevamente:

En este momento, puede ver los dos beans que definimos en la clase de configuración.
Preste atención a este lugar:
la anotación @Configuration indica que esta clase se puede usar para configurar Spring BeanDefinition. Puede entenderse como:
- Una clase marcada con @Configuration es equivalente a un archivo de configuración XML
- El método anotado con @Bean en la clase @Configuration es equivalente a la definición <bean> en el archivo XML
Pero esta clase de configuración en sí misma no se agregará al contenedor Spring.
Pero la siguiente vez que llamamos al método getBean2 en Bean1, encontramos que obtenemos nulo:
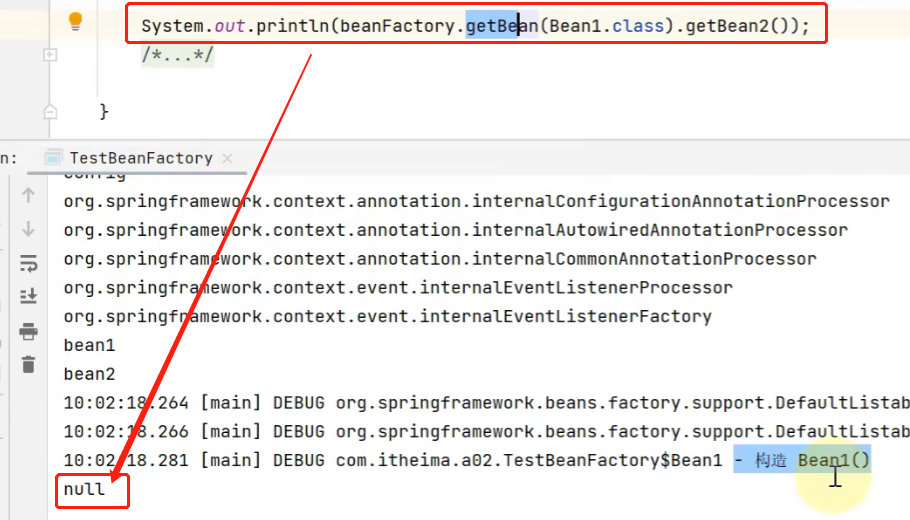
En otras palabras, nuestra anotación @Autowired no surtió efecto. Entonces, ¿cómo resolvemos este problema?
Aquí vamos a presentar un nuevo concepto llamado Bean的后处理器postprocesador BeanFactory, que agrega algunas definiciones de Bean. El posprocesador Bean proporciona extensiones para cada etapa del ciclo de vida del Bean, como @Autowired, @Resource...
Llamamos a estos procesadores (no es necesario registrarse, porque se han registrado antes), y podemos encontrar que la dependencia bean2 en bean1 se ha inyectado con éxito:

Se puede ver que después de obtener nuestro BeanFactoryPostProcessor, necesitamos ejecutar el método postProcessBeanFactory para que funcione, y el BeanPostProcessor se puede registrar directamente en el contenedor. Esto se debe a que no podemos ejecutar con precisión el método en el ciclo de vida del bean, así que ejecute el método en la interfaz BeanPostProcessor y deje que el contenedor lo haga. ( Explicaremos más adelante que Spring usa el patrón de diseño del método de plantilla y llama uniformemente a la interfaz BeanPostProcessor en el ciclo de vida )
Entonces podemos encontrar fácilmente que nuestro contenedor crea frijoles de manera retrasada, es decir, cuando se usan. Comienza por sí mismo y solo contiene algunas definiciones de frijol. Pero para algunos objetos singleton, esperamos crear estos objetos antes de getBean. En este momento, podemos llamar a un método llamado DefaultListableBeanFactory.preInstantiateSingletons(), que creará instancias previas de todos los objetos singleton.
Aquí hay un pequeño resumen:
Cosas que BeanFactory no hará
- No llamará activamente al posprocesador BeanFactory (hay un método de actualización en ApplicationContext que servirá)
- No agregará activamente posprocesadores Bean (hay un método de actualización en ApplicationContext que servirá)
- El singleton no se inicializará activamente (hay un método de actualización en ApplicationContext que lo hará)
- No analizará ${ } y #{ }
Se puede ver que BeanFactory es solo un contenedor básico y muchas de sus funciones no se han agregado al sistema de antemano. Y ApplicationContext ha hecho estos preparativos, que es más amigable para los desarrolladores.
Una cosa más a tener en cuenta: el posprocesador de beans tendrá una lógica de clasificación.
Finalmente, para resumir:
- beanFactory puede registrar un objeto de definición de bean a través de registerBeanDefinition
- Usualmente usamos clases de configuración, xml, escaneo de componentes, etc. para generar objetos de definición de bean y registrarlos en beanFactory
- La definición del bean describe el modelo para la creación de este bean: cuál es el alcance, se crea con un constructor o una fábrica, cuál es el método de inicialización y destrucción, etc.
- beanFactory necesita llamar manualmente al posprocesador beanFactory para mejorarlo
- Por ejemplo, al analizar @Bean, @ComponentScan y otras anotaciones para complementar algunas definiciones de beans
- beanFactory necesita agregar manualmente postprocesadores de beans para proporcionar mejoras al proceso de creación de beans posterior
- Por ejemplo, @Autowired, @Resource y otras anotaciones son analizadas por el posprocesador del bean
- El orden en el que se agrega el posprocesamiento de bean afectará los resultados del análisis; vea el ejemplo de agregar @Autowired y @Resource en el video al mismo tiempo
- beanFactory necesita llamar manualmente al método para inicializar el singleton
- beanFactory requiere configuración adicional para resolver ${} y #{}
Implementación del contenedor ApplicationContext
Tiene cuatro clases de implementación clásicas más:
// ⬇️较为经典的容器, 基于 classpath 下 xml 格式的配置文件来创建
private static void testClassPathXmlApplicationContext() {
}
// ⬇️⬇️较为经典的容器, 基于磁盘路径下 xml 格式的配置文件来创建
private static void testFileSystemXmlApplicationContext() {
}
// ⬇️较为经典的容器, 基于 java 配置类来创建
private static void testAnnotationConfigApplicationContext() {
}
// ⬇️较为经典的容器, 基于 java 配置类来创建, 用于 web 环境
private static void testAnnotationConfigServletWebServerApplicationContext() {
}
Echemos un vistazo a los dos primeros. Son similares y se basan en archivos de configuración xml. Uno es cargar la configuración desde la ruta del disco y el otro es cargar la configuración desde la ruta de clase. El uso es el siguiente:
// ⬇️较为经典的容器, 基于 classpath 下 xml 格式的配置文件来创建
private static void testClassPathXmlApplicationContext() {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("a02.xml");
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
// ⬇️基于磁盘路径下 xml 格式的配置文件来创建
private static void testFileSystemXmlApplicationContext() {
FileSystemXmlApplicationContext context =
new FileSystemXmlApplicationContext(
"src\\main\\resources\\a02.xml");
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
Archivo de configuración:
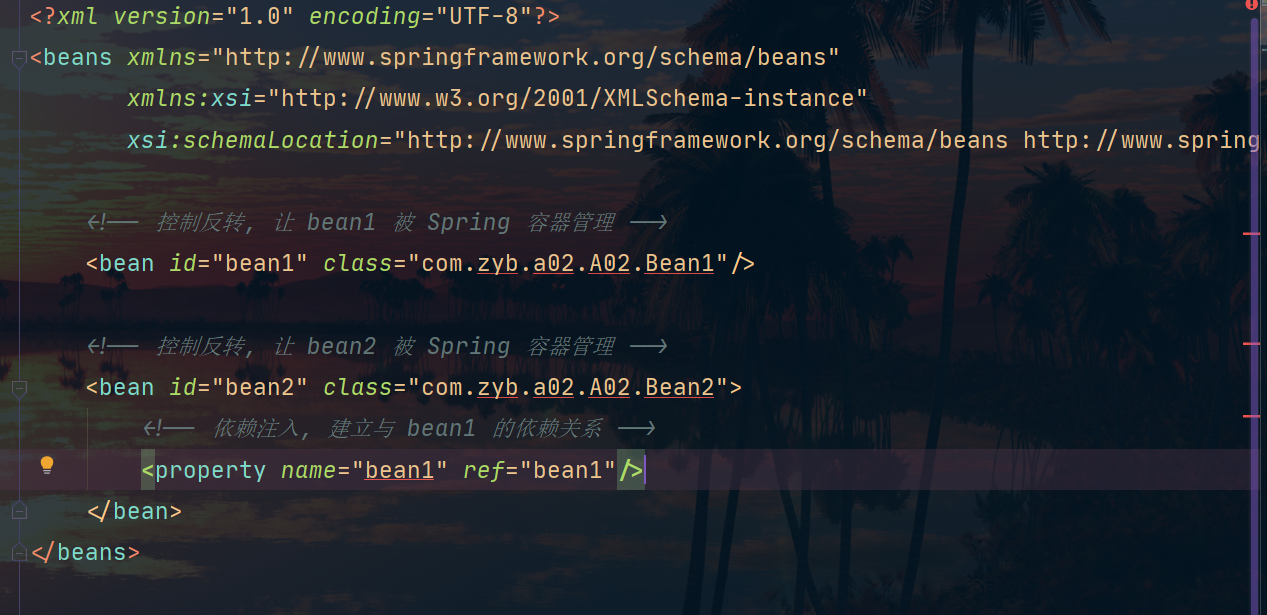
Entonces hablemos de sus principios. Aquí tomamos ClassPathXmlApplicationContext como ejemplo. Como dijimos antes, definitivamente necesita el soporte de BeanFactory (BeanFactory es responsable de la función de administración de beans). ¿Cómo ClassPathXmlApplicationContext implementa el análisis del archivo xml y lo agrega a BeanFactory?
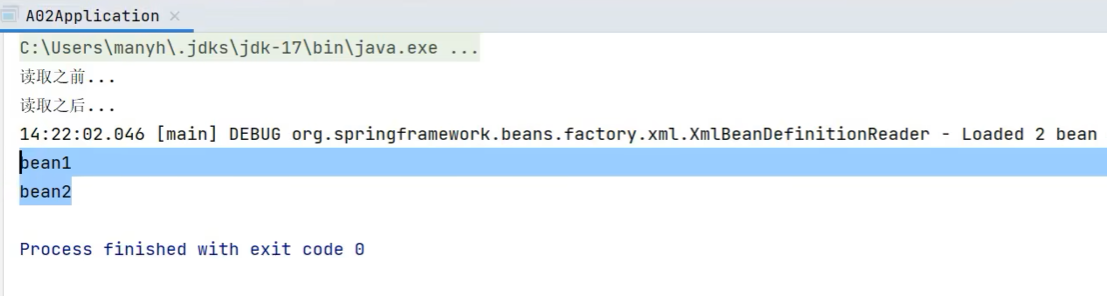
Utiliza XmlBeanDefinitionReader internamente, podemos usar el siguiente código para experimentar:
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
System.out.println("读取之前...");
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println("读取之后...");
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(new FileSystemResource("src\\main\\resources\\a02.xml"));
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
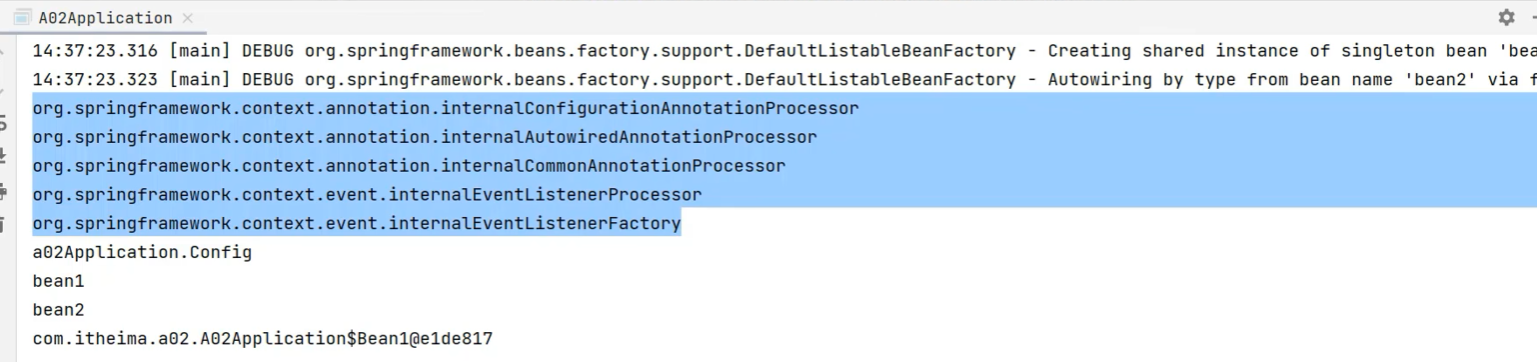
Entonces veamos la tercera implementación:
// ⬇️较为经典的容器, 基于 java 配置类来创建
private static void testAnnotationConfigApplicationContext() {
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(Config.class);
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
@Configuration
static class Config {
@Bean
public Bean1 bean1() {
return new Bean1();
}
@Bean
public Bean2 bean2(Bean1 bean1) {
Bean2 bean2 = new Bean2();
bean2.setBean1(bean1);
return bean2;
}
}
Después de ejecutarlo, encontramos que, en comparación con el xml anterior, hay varios beans más en el contenedor (el posprocesador que mencionamos anteriormente):
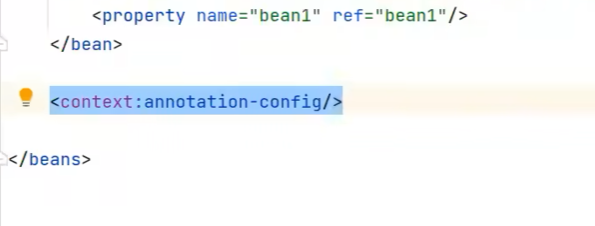
Y si usamos las dos clases de contenedor ApplicationContext anteriores basadas en archivos de configuración xml, debemos configurarlo manualmente:
Finalmente nos fijamos en la cuarta categoría:
// ⬇️较为经典的容器, 基于 java 配置类来创建, 用于 web 环境
private static void testAnnotationConfigServletWebServerApplicationContext() {
//这个地方一定要注意是AnnotationConfigServletWebServerApplicationContext,否则会出现容器不能持续运行的问题
AnnotationConfigServletWebServerApplicationContext context =
new AnnotationConfigServletWebServerApplicationContext(WebConfig.class);
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
}
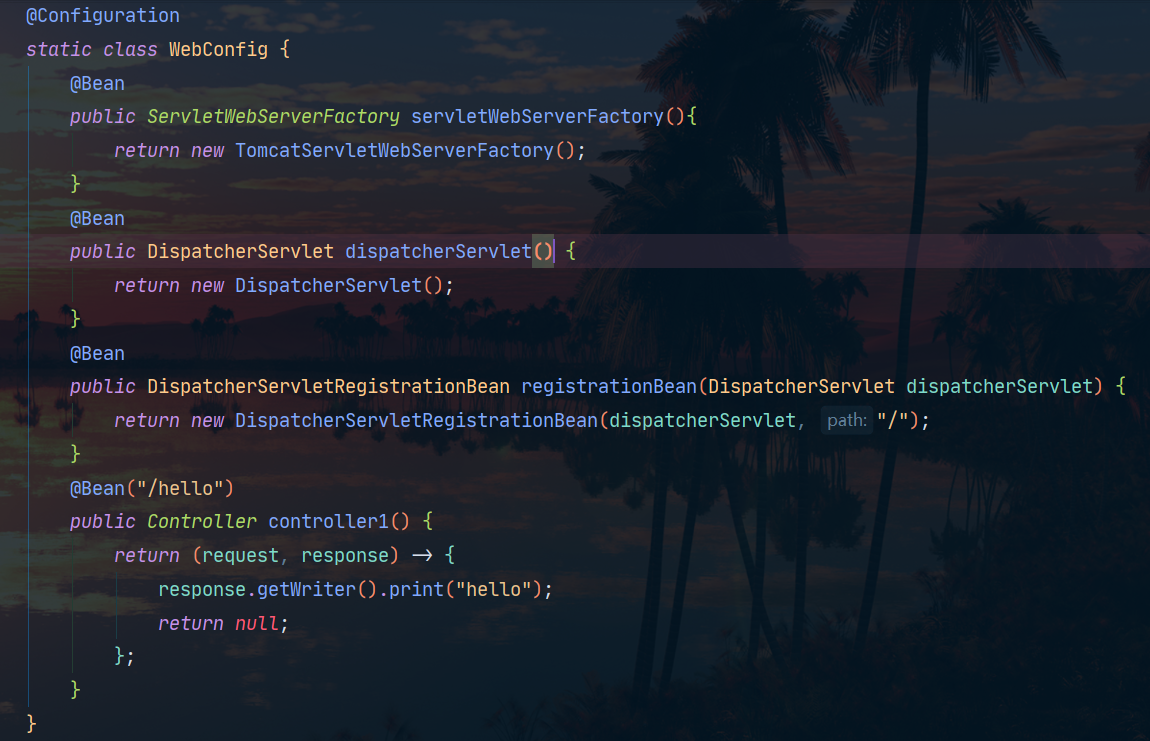
@Configuration
static class WebConfig {
@Bean
public ServletWebServerFactory servletWebServerFactory(){
return new TomcatServletWebServerFactory();
}
@Bean
public DispatcherServlet dispatcherServlet() {
return new DispatcherServlet();
}
@Bean
public DispatcherServletRegistrationBean registrationBean(DispatcherServlet dispatcherServlet) {
return new DispatcherServletRegistrationBean(dispatcherServlet, "/");
}
}
Para iniciar un proyecto web, debe haber tres beans en el contenedor:
- ServletWebServerFactory
- DispatcherServlet
- DispatcherServletRegistrationBean
Echemos un vistazo a ServletWebServerFactory primero :
ServletWebServerFactory es una interfaz de fábrica de servidor web Servlet para iniciar contenedores Servlet integrados en aplicaciones Spring.
En las aplicaciones Spring Boot, generalmente usamos contenedores de Servlet como Tomcat, Jetty o Undertow integrados, en lugar de empaquetarlos en archivos WAR e implementarlos en contenedores de Servlet independientes.
Las clases de implementación de la interfaz ServletWebServerFactory son estas fábricas de contenedores de Servlet integradas, que incluyen principalmente:
- TomcatServletWebServerFactory: fábrica de Tomcat integrada
- JettyServletWebServerFactory: Embedded Jetty factory
- UndertowServletWebServerFactory: fábrica de Undertow integrada
En las aplicaciones Spring Boot, generalmente no necesitamos configurar estas fábricas manualmente, porque Spring Boot seleccionará automáticamente una configuración de fábrica de acuerdo con las dependencias que agregue. Por ejemplo:
- Agregar spring-boot-starter-tomcat usará automáticamente TomcatServletWebServerFactory
- Agregar spring-boot-starter-jetty usará automáticamente JettyServletWebServerFactory
- Agregar spring-boot-starter-undertow usará automáticamente UndertowServletWebServerFactory
Sin embargo, si necesitamos personalizar la configuración del contenedor de Servlet incrustado, podemos agregar manualmente un bean ServletWebServerFactory. Por ejemplo:
@Bean
public ServletWebServerFactory servletContainer() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.setPort(9000);
factory.setSessionTimeout(10 * 60);
return factory;
}
Aquí hemos personalizado el servidor Tomcat, configuramos el puerto en 9000 y el tiempo de espera de la sesión en 10 minutos.
Otros usos de ServletWebServerFactory son:
- Agregue múltiples ServletWebServerFactories para iniciar múltiples instancias de contenedores de Servlet integrados.
- Elija diferentes ServletWebServerFactory según los diferentes entornos, por ejemplo, elija Undertow en el entorno de Windows.
- Para una configuración de contenedor de Servlet más profunda. ServletWebServerFactory solo expone algunas opciones de configuración, y la configuración profunda puede llamar directamente a la API del contenedor Servlet.
Entonces, en resumen, las funciones principales de ServletWebServerFactory son:
- Inicie un contenedor de Servlet incrustado (Tomcat, Jetty, Undertow) en una aplicación Spring Boot
- La configuración del contenedor de servlet se puede personalizar para anular la configuración predeterminada
- Inicie varias instancias de contenedor de Servlet
- Elija diferentes contenedores de Servlet según el entorno
En cuanto a DispatcherServlet, todo el mundo debería estar familiarizado con él, intercepta solicitudes de red, generalmente lo llamamos el pre-controlador, que es equivalente a la entrada del programa Springweb.
Ahora hay un contenedor web incrustado y DispatcherServlet, pero los dos aún no se han conectado. Necesitamos registrar DispatcherServlet en el contenedor web.
Y DispatcherServletRegistrationBean es un bean de registro de Servlet, que se utiliza para registrar DispatcherServlet con el contenedor de Servlet.
Con estos tres beans, podemos iniciar un proyecto web, pero aún no podemos hacer nada, por lo que agregamos otro controlador Controlador: Nota aquí: si el nombre
del bean /comienza con el acuerdo, significa la ruta de intercepción.
Ciclo de vida del frijol
Un bean gestionado por Spring, las principales fases del ciclo de vida son
- Crear: Cree objetos de instancia de bean de acuerdo con el constructor o el método de fábrica del bean.
- Inyección de dependencia: según @Autowired, @Value o algún otro medio, complete los valores y establezca relaciones para las variables miembro del bean
- Inicialización: llamar a varias interfaces Aware, llamar a varios métodos de inicialización de objetos
- Destrucción: cuando se cierra el contenedor, se destruirán todos los objetos singleton (es decir, se llamará a sus métodos de destrucción)
- El objeto prototipo también se puede destruir, pero el contenedor debe llamarlo activamente.
Vamos a verificarlo con código:
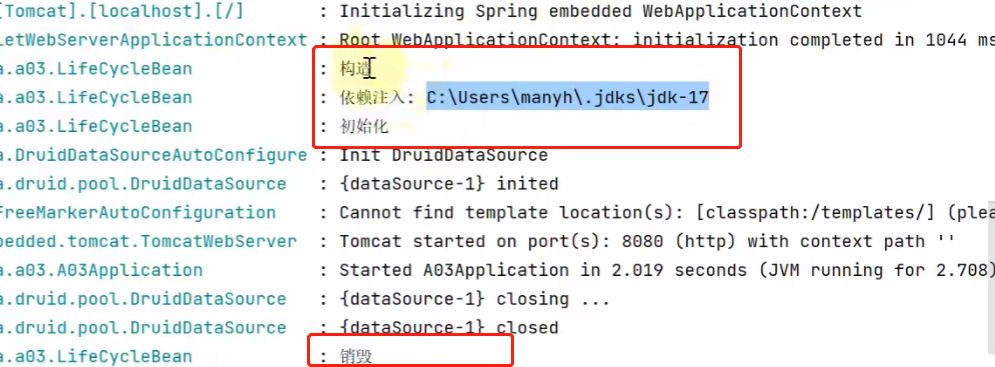
@Component
public class LifeCycleBean {
private static final Logger log = LoggerFactory.getLogger(LifeCycleBean.class);
public LifeCycleBean() {
log.debug("构造");
}
@Autowired
public void autowire(@Value("${JAVA_HOME}") String home) {
log.debug("依赖注入: {}", home);
}
@PostConstruct
public void init() {
log.debug("初始化");
}
@PreDestroy
public void destroy() {
log.debug("销毁");
}
}
Clase de prueba:
@SpringBootApplication
public class A03 {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(A03.class, args);
context.close();
}
}
resultado de la operación:
Aún debe recordar el posprocesador Bean que mencionamos anteriormente. Está estrechamente relacionado con el ciclo de vida de nuestro bean. Puede proporcionar una expansión funcional para cada etapa del ciclo de vida del bean. Veamos una parte del código a continuación:
@Component
public class MyBeanPostProcessor implements InstantiationAwareBeanPostProcessor, DestructionAwareBeanPostProcessor {
private static final Logger log = LoggerFactory.getLogger(MyBeanPostProcessor.class);
@Override
public void postProcessBeforeDestruction(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 销毁之前执行, 如 @PreDestroy");
}
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 实例化之前执行, 这里返回的对象会替换掉原本的 bean");
return null;
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean")) {
log.debug("<<<<<< 实例化之后执行, 这里如果返回 false 会跳过依赖注入阶段");
// return false;
}
return true;
}
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 依赖注入阶段执行, 如 @Autowired、@Value、@Resource");
return pvs;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 初始化之前执行, 这里返回的对象会替换掉原本的 bean, 如 @PostConstruct、@ConfigurationProperties");
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 初始化之后执行, 这里返回的对象会替换掉原本的 bean, 如代理增强");
return bean;
}
}
Vamos a ejecutarlo:


Mejoras antes y después de la creación
- postProcessBeforeInstanciación
- Si el objeto devuelto aquí no es nulo, se reemplazará el bean original y solo se seguirá el proceso postProcessAfterInitialization
- postProcessAfterInstanciation
- Aquí, si se devuelve falso, se omitirá la fase de inyección de dependencia
Mejoras antes de la inyección de dependencia
- postProcessProperties
- 如 @Autowired、@Value、@Resource
Mejoras antes y después de la inicialización
- postProcessBeforeInitialization
- El objeto devuelto aquí reemplazará el bean original
- 如 @PostConstruct, @ConfigurationProperties
- postProcessAfterInitialization
- El objeto devuelto aquí reemplazará el bean original
- como la mejora del agente
mejoras antes de la destrucción
- postProcesoAntesDestrucción
- como @PreDestroy
Patrón de diseño de método de plantilla
El patrón de método de plantilla define un esqueleto de algoritmo y retrasa la implementación de algunos pasos a las subclases, de modo que las subclases puedan redefinir algunos pasos específicos del algoritmo sin cambiar la estructura del algoritmo, para realizar la extensión y el empaquetado del algoritmo.
En el método de plantilla, el método de combinación de métodos dinámicos y estáticos se utiliza para realizar la escalabilidad del método:
- Acción: partes inciertas, abstraídas en subclases o interfaces y devueltas
- Estático: esqueleto de algoritmo fijo
En términos simples, significa que el proceso grande se ha solucionado y se proporcionan extensiones antes y después de algunos puntos clave a través de devoluciones de llamada de interfaz (postprocesadores de beans)
Veamos un ejemplo:
Ahora simulamos un contenedor BeanFactory:
// 模板方法 Template Method Pattern
static class MyBeanFactory {
public Object getBean() {
Object bean = new Object();
System.out.println("构造 " + bean);
System.out.println("依赖注入 " + bean); // @Autowired, @Resource
System.out.println("初始化 " + bean);
return bean;
}
}
Cuando diseñamos el código por primera vez, no consideramos la escalabilidad posterior. Agregaremos nuevas funciones más adelante, por lo que solo podemos seguir acumulando código en él. Al final, este método se volverá enorme y engorroso.
Aquí podemos usar el patrón de diseño del método de plantilla para modificar el código anterior:
Por ejemplo, si queremos agregar algo de lógica después de la inyección de dependencia, podemos abstraer la lógica después de la inyección de dependencia en una interfaz y luego llamarlos uno por uno después de la inyección de dependencia.
public class TestMethodTemplate {
public static void main(String[] args) {
MyBeanFactory beanFactory = new MyBeanFactory();
beanFactory.addBeanPostProcessor(bean -> System.out.println("解析 @Autowired"));
beanFactory.addBeanPostProcessor(bean -> System.out.println("解析 @Resource"));
beanFactory.getBean();
}
// 模板方法 Template Method Pattern
static class MyBeanFactory {
public Object getBean() {
Object bean = new Object();
System.out.println("构造 " + bean);
System.out.println("依赖注入 " + bean); // @Autowired, @Resource
for (BeanPostProcessor processor : processors) {
processor.inject(bean);
}
System.out.println("初始化 " + bean);
return bean;
}
private List<BeanPostProcessor> processors = new ArrayList<>();
public void addBeanPostProcessor(BeanPostProcessor processor) {
processors.add(processor);
}
}
static interface BeanPostProcessor {
public void inject(Object bean); // 对依赖注入阶段的扩展
}
}
Postprocesador de frijol
- El análisis de anotaciones como @Autowired pertenece a las funciones extendidas de la fase del ciclo de vida del bean (inyección de dependencia, inicialización), y estas funciones extendidas las completa el posprocesador del bean.
- Lo que mejora cada posprocesador
- AutowiredAnnotationBeanPostProcessor analiza @Autowired y @Value
- CommonAnnotationBeanPostProcessor 解析 @Resource、@PostConstruct、@PreDestroy
- ConfigurationPropertiesBindingPostProcessor 解析 @ConfigurationProperties
- Además, ContextAnnotationAutowireCandidateResolver es responsable de obtener el valor de @Value, analizar @Qualifier, generics, @Lazy, etc. (esta anotación es más complicada y se explicará en detalle más adelante) ( este no es un posprocesador de Bean )
Luego, hablemos en detalle sobre el principio de funcionamiento del postprocesador de Bean AutowiredAnnotationBeanPostProcessor .
Para comprender este método, lo usamos solo y escribimos el siguiente código de prueba:
// AutowiredAnnotationBeanPostProcessor 运行分析
public class DigInAutowired {
public static void main(String[] args) throws Throwable {
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
beanFactory.registerSingleton("bean2", new Bean2()); // 创建过程,依赖注入,初始化
beanFactory.registerSingleton("bean3", new Bean3());
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver()); // @Value
AutowiredAnnotationBeanPostProcessor processor = new AutowiredAnnotationBeanPostProcessor();
processor.setBeanFactory(beanFactory); //依赖注入部分跟Bean有关,需要得到BeanFactory的支持
Bean1 bean1 = new Bean1();
System.out.println(bean1);
processor.postProcessProperties(null, bean1, "bean1"); // 执行依赖注入 @Autowired @Value
System.out.println(bean1);
}
}
Aquí necesitamos tres dependencias en bean1:
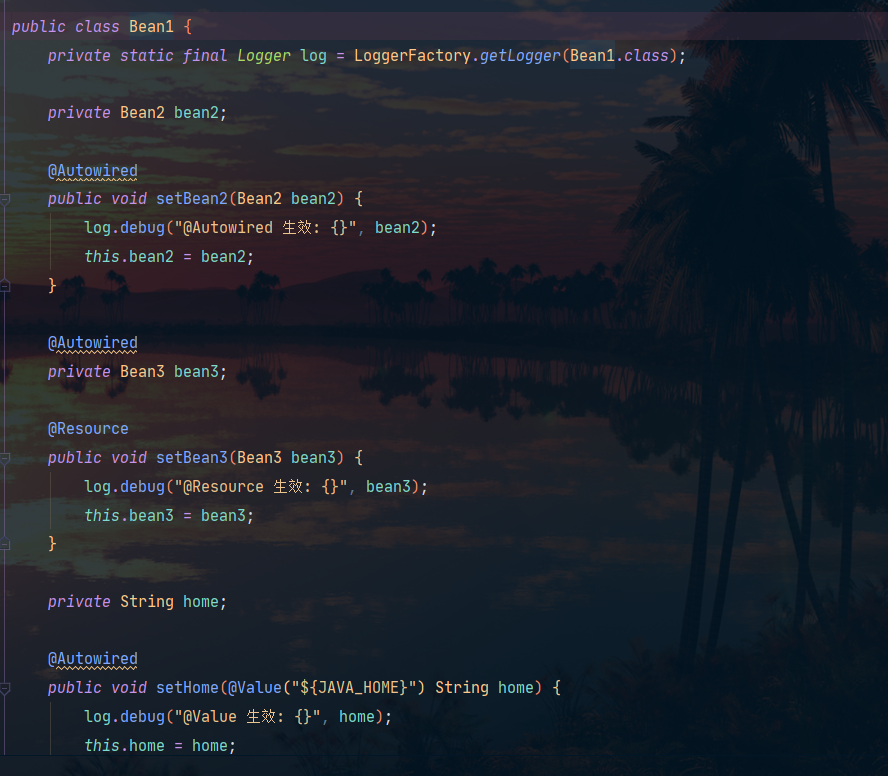
Errata de imagen: No hay anotación @Autowired en Bean3 en este momento
En Spring, la anotación @Autowired se marca en el método para indicar que el método necesita inyectar beans dependientes automáticamente. Al llamar a este método, Spring encontrará automáticamente un bean cuyo nombre coincida con el tipo de parámetro del contexto y lo inyectará en el método .
resultado de la operación:

El ${} aquí no ha sido analizado, podemos agregar una oración:
beanFactory.addEmbeddedValueResolver(new StandardEnvironment()::resolvePlaceholders); // ${} 的解析器
Después de llamar al método postProcessProperties en AutowiredAnnotationBeanPostProcessor, nuestra dependencia se inyecta con éxito, lo que indica que este método ha funcionado. A continuación, veamos cómo se ejecuta:
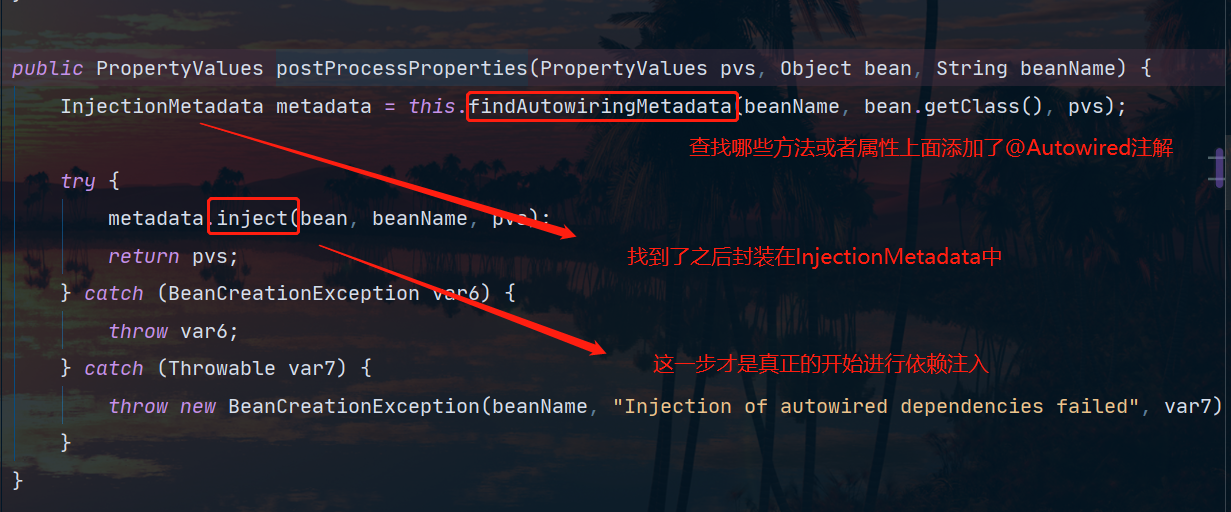
Podemos echar un vistazo al punto de ruptura, este InjectionMetadata:
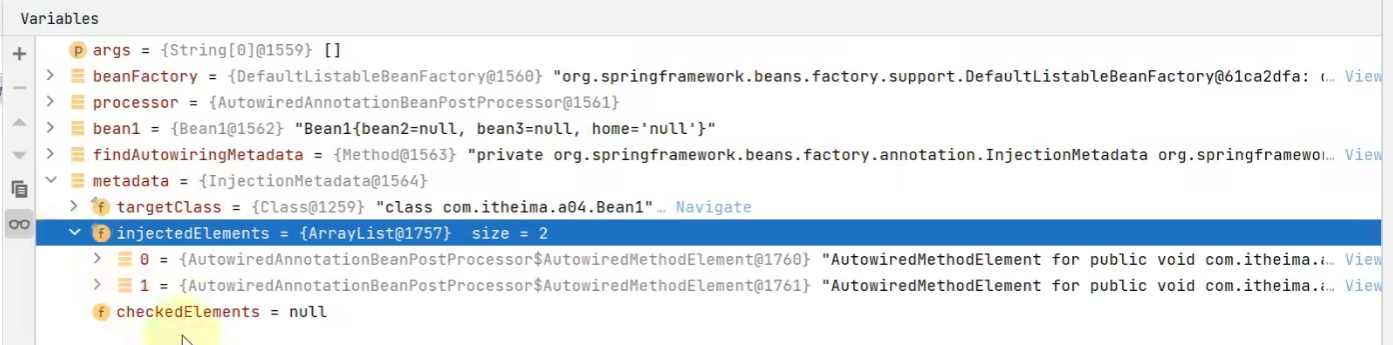

Corresponde exactamente a nuestros dos métodos:
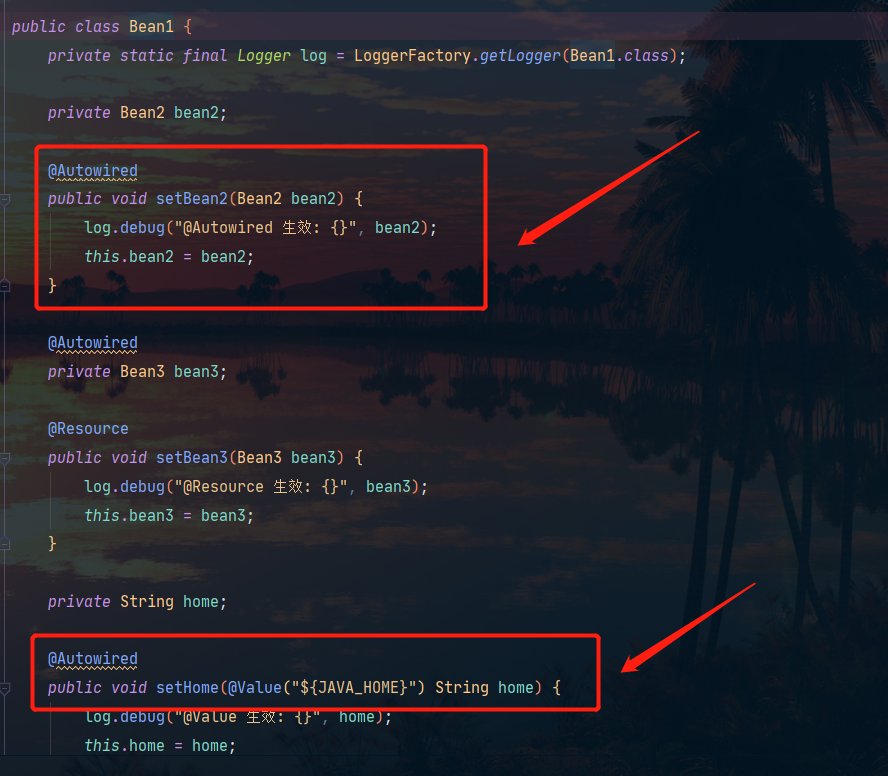
Errata de imagen: No hay anotación @Autowired en Bean3 en este momento
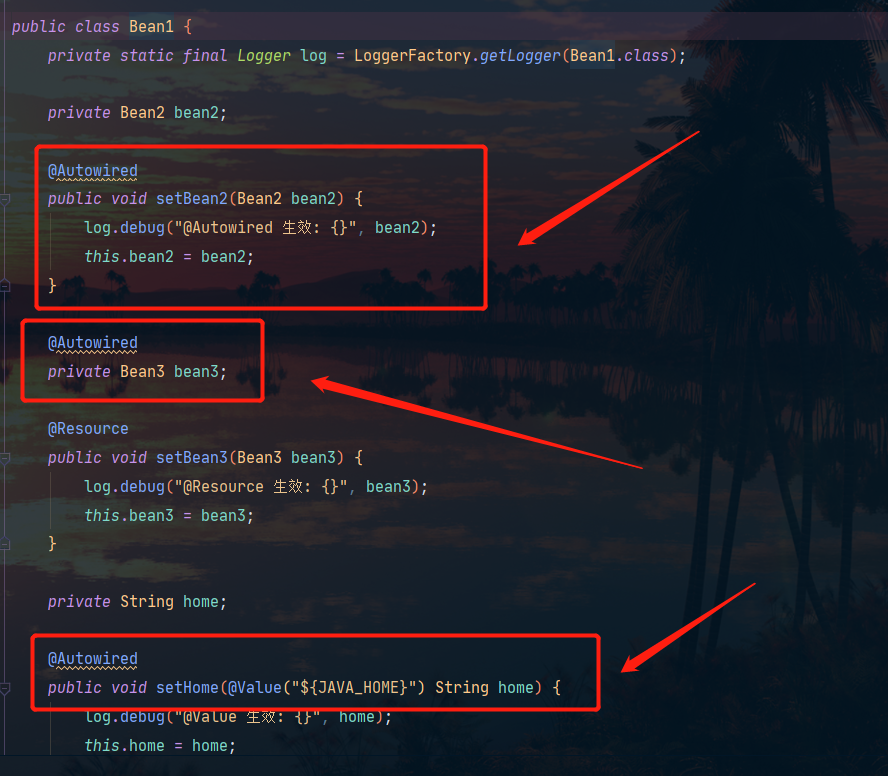
En el método de inyección, la lógica es envolver los parámetros o atributos del método con DependencyDescriptor, y luego podemos usar el método beanFactory.doResolveDependency para buscar.El proceso es el siguiente:
//@Autowired作用于Bean3
Field bean3 = Bean1.class.getDeclaredField("bean3");
DependencyDescriptor dd1 = new DependencyDescriptor(bean3, false);
Object o = beanFactory.doResolveDependency(dd1, null, null, null);
System.out.println(o);
//@Autowired作用于setBean2方法
Method setBean2 = Bean1.class.getDeclaredMethod("setBean2", Bean2.class);
DependencyDescriptor dd2 =
new DependencyDescriptor(new MethodParameter(setBean2, 0), true);
Object o1 = beanFactory.doResolveDependency(dd2, null, null, null);
System.out.println(o1);
//@Autowired作用于setHome方法
Method setHome = Bean1.class.getDeclaredMethod("setHome", String.class);
DependencyDescriptor dd3 = new DependencyDescriptor(new MethodParameter(setHome, 0), true);
Object o2 = beanFactory.doResolveDependency(dd3, null, null, null);
System.out.println(o2);
Correspondientes a las tres partes de la siguiente figura:
Finalmente, resumamos el principio de funcionamiento del postprocesador de Bean AutowiredAnnotationBeanPostProcessor:
- AutowiredAnnotationBeanPostProcessor.findAutowiringMetadata se utiliza para obtener la variable miembro y la información de parámetros de método de un bean con @Value @Autowired, expresado como InjectionMetadata
- InjectionMetadata puede completar la inyección de dependencia
- De acuerdo con las variables miembro dentro de InjectionMetadata, los parámetros del método se encapsulan como tipo DependencyDescriptor
- Con DependencyDescriptor, puede usar el método beanFactory.doResolveDependency para la búsqueda basada en tipos
Postprocesador BeanFactory
El código experimental es el siguiente, que es similar a la idea anterior (variables de control):
El contenedor de inicialización aquí tendrá dos operaciones:
- Ejecutará el posprocesador de BeanFactory
- Crear cada frijol singleton
Se puede concluir:
- ConfigurationClassPostProcessor puede resolver
- @ComponentScan
- @Frijol
- @Importar
- @ImportResource
- MapperScannerConfigurer puede resolver
- Interfaz del mapeador
- El análisis de @ComponentScan, @Bean, @Mapper y otras anotaciones pertenece a la función extendida del contenedor central (es decir, BeanFactory)
- Estas funciones extendidas se completan con diferentes postprocesadores de BeanFactory, de hecho, es principalmente para complementar algunas definiciones de beans.
A continuación, usamos la simulación para descubrir cómo ConfigurationClassPostProcessor analiza la anotación @ComponentScan.
//在初始化容器的时候会回调这个BeanFactory后处理器
public class ComponentScanPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override // context.refresh
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
}
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//在指定的类、方法、字段或者构造器上查找指定类型的注解。如果找到,则返回该注解,否则返回 null。
ComponentScan componentScan = AnnotationUtils.findAnnotation(Config.class, ComponentScan.class);
if (componentScan != null) {
for (String p : componentScan.basePackages()) {
//System.out.println(p);
//将包名转化为路径名方便后面资源的查找
// com.zyb.a05.component -> classpath*:com/zyb/a05/component/**/*.class
String path = "classpath*:" + p.replace(".", "/") + "/**/*.class";
//System.out.println(path);
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
Resource[] resources = new PathMatchingResourcePatternResolver().getResources(path);
//一个工具类:根据类上的注解生成 bean 的名称
AnnotationBeanNameGenerator generator = new AnnotationBeanNameGenerator();
for (Resource resource : resources) {
// System.out.println(resource);
MetadataReader reader = factory.getMetadataReader(resource);
// System.out.println("类名:" + reader.getClassMetadata().getClassName());
AnnotationMetadata annotationMetadata = reader.getAnnotationMetadata();
// System.out.println("是否加了 @Component:" + annotationMetadata.hasAnnotation(Component.class.getName()));
// System.out.println("是否加了 @Component 派生:" + annotationMetadata.hasMetaAnnotation(Component.class.getName()));
if (annotationMetadata.hasAnnotation(Component.class.getName())
|| annotationMetadata.hasMetaAnnotation(Component.class.getName())) {
//创建一个Bean的定义
AbstractBeanDefinition bd = BeanDefinitionBuilder
.genericBeanDefinition(reader.getClassMetadata().getClassName())
.getBeanDefinition();
//根据类上的注解生成 bean 的名称
String name = generator.generateBeanName(bd, beanFactory);
//根据定义注册Bean
beanFactory.registerBeanDefinition(name, bd);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
El BeanDefinitionRegistryPostProcessor implementado por esta clase aquí también es un posprocesador BeanFactory:
Cuando se inicializa el contenedor Spring, detectará y llamará automáticamente a todos los BeanDefinitionRegistryPostProcessor registrados, procesará la definición de Bean y luego lo instanciará..
Este posprocesador nos permite modificar la definición del bean después de cargar la definición del bean Spring y antes de que se cree una instancia del bean.
La interfaz BeanDefinitionRegistryPostProcessor define dos métodos:
- postProcessBeanDefinitionRegistry(): se llama después de cargar la definición del bean y antes de la instanciación. La definición del bean se puede modificar.
- postProcessBeanFactory(): se llama después de cargar la definición del bean y antes de la instanciación. BeanFactory se puede obtener aquí, pero la instancia de bean no se puede obtener en este momento.

La lógica básica es:
- Obtenga el paquete escaneado a través de la anotación ComponentScan
- Obtenga todos los archivos de clase en el paquete
- Determinar qué archivos de clase tienen anotaciones de componentes o sus anotaciones derivadas
- Registrar las clases que cumplan con los requisitos
punto importante:
-
En cuanto a los símbolos en las rutas:
*Representa de 0 a varios caracteres, por ejemplo:*.txtrepresenta todos los archivos txt**Representa 0 para varias carpetas, por ejemplo:/app1/**,/app2/**representa cualquier carpeta de capa en la carpeta app1 y cualquier carpeta de capa en app2
-
En Spring, podemos usar MetadataReader para leer la información de la clase, como el nombre de la clase, la interfaz, la anotación, etc. Sin embargo, la sobrecarga de obtener el objeto MetadataReader es relativamente grande y la carga de información de clase desde la ruta de clase cada vez afectará el rendimiento.
-
CachingMetadataReaderFactory existe para resolver este problema. Mantiene internamente una caché de instancias de MetadataReader, que pueden reutilizar las instancias de MetadataReader creadas sin recargar completamente la información de la clase cada vez.
en conclusión:
- Clase de herramienta de Spring CachingMetadataReaderFactory para manipular metadatos
- Obtener la información de anotación de anotación directa o indirecta a través de metadatos de anotación (AnnotationMetadata)
- Obtenga el nombre de la clase a través de los metadatos de la clase (ClassMetadata), y AnnotationBeanNameGenerator genera el nombre del bean
- El análisis de metadatos se basa en la tecnología ASM
ASM es un marco de manipulación de bytecode de Java. Nos permite modificar bytecode en forma binaria, o generar clases dinámicamente.
ASM se puede utilizar para:
- Generación dinámica de clases: el código de bytes de una clase se genera en tiempo de ejecución de acuerdo con ciertas reglas.
- Modificar la clase: agregar campos o métodos a la clase en tiempo de ejecución, modificar el cuerpo del método en la clase, etc.
- Analizar clases: obtenga información detallada sobre las clases en tiempo de ejecución, como relaciones de herencia de clases, métodos y campos en clases, etc.
- Convertir clases: convierta archivos de clase de un formato a otro en tiempo de ejecución, como convertir archivos de clase Java a archivos dex, etc.
El principio de funcionamiento de ASM es: analiza el código de bytes del archivo de clase y lo convierte en un elemento ASM de nivel superior (llamado Nodo) para representar, como MethodNode, FieldNode, etc. Podemos generar nuevas clases agregando o modificando estos Nodos, o modificar las clases existentes.
A continuación, prestemos atención a una cosa más:
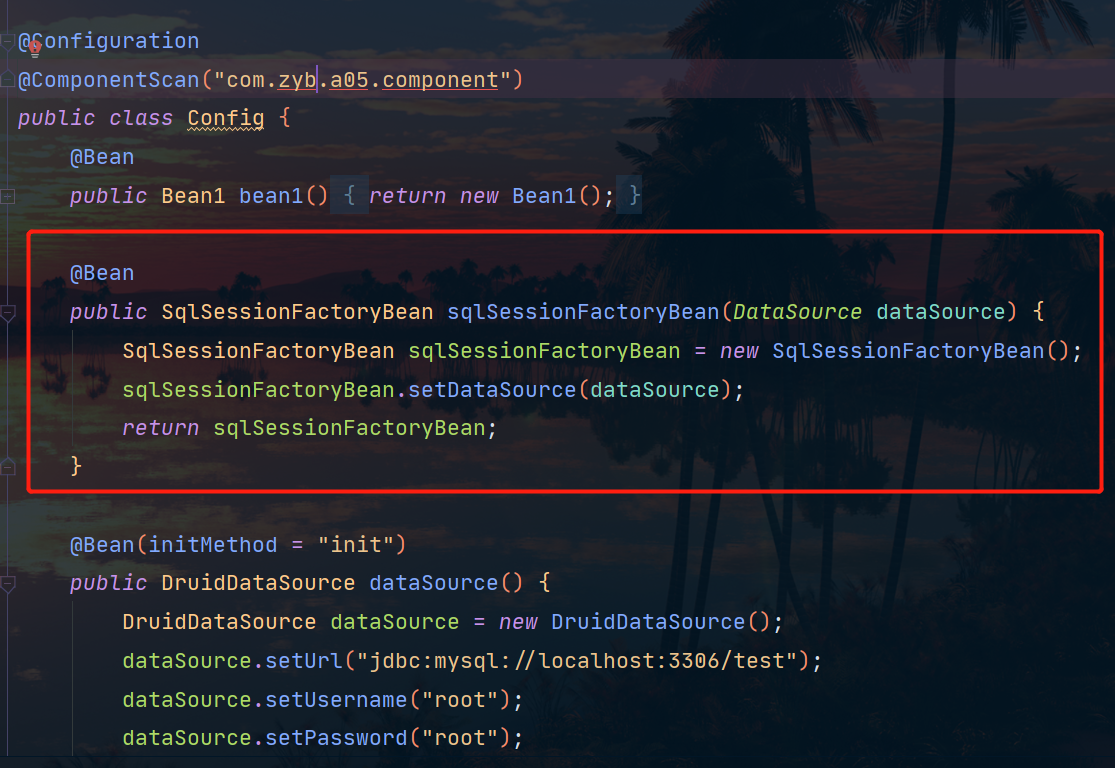
En este código de clase de configuración, podemos ver dos formas de definir beans:
- Clase de configuración + @Bean
- Clase de configuración + Bean de fábrica (la parte del cuadro rojo en la figura)
Estamos muy familiarizados con el primer tipo, entonces, ¿cuál es el bean de fábrica en el segundo tipo?
Tomemos este SqlSessionFactoryBean como ejemplo:
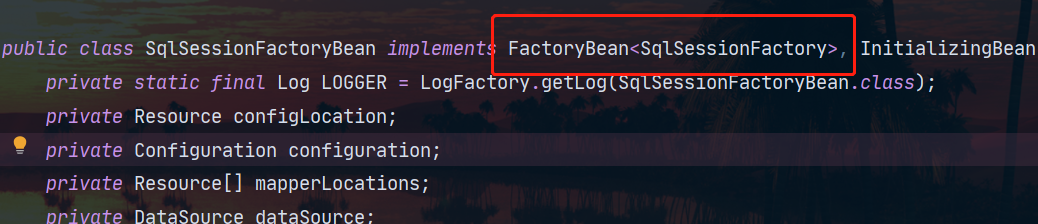
Entonces, ¿qué es este FactoryBean?
En Spring, la interfaz FactoryBean es la interfaz de un bean de fábrica . Los beans que implementen esta interfaz se tratarán como beans de fábrica en el contenedor Spring. Cuando un bean depende del bean de fábrica, se llama al método getObject() para obtener la instancia del bean. Le permite realizar alguna lógica personalizada durante la creación de instancias de Bean.
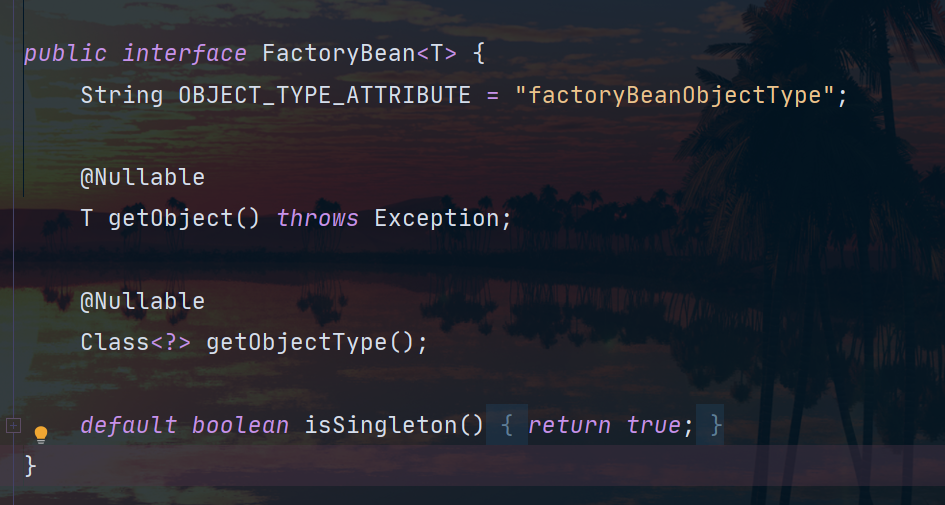
Los frijoles de fábrica generalmente siguen el siguiente patrón:
- Implementar la interfaz org.springframework.beans.factory.FactoryBean
- Devuelve la instancia de Bean que se generará de fábrica en el método getObject()
- Devuelve el tipo de Bean a generar, especificado en el método getObjectType()
- Especifique si el Bean generado es un singleton en el método isSingleton()
Los beans de fábrica se pueden combinar bien con las clases de configuración @Configuration para definir beans.
Por ejemplo, podemos definir un método de posprocesador de fábrica en la clase de configuración y usar la anotación @Bean para registrar el posprocesador de fábrica:
@Configuration
public class AppConfig {
@Bean
public MyFactoryBean myFactoryBean() {
return new MyFactoryBean();
}
}
Luego, el posprocesador de fábrica MyFactoryBean puede definir el bean en el método getObject():
public class MyFactoryBean implements FactoryBean<Example> {
@Override
public Example getObject() throws Exception {
return new Example();
}
}
De esta forma, Spring:
- Crea una instancia de la clase de configuración AppConfig
- Llame al método myFactoryBean() y registre la instancia de MyFactoryBean devuelta como un bean
- Para obtener la instancia de bean final de MyFactoryBean, la instancia de Ejemplo devuelta al llamar al método getObject() también se registrará como un bean
Entonces, al final se registrarán dos beans:
- myFactoryBean: instancia de MyFactoryBean
- ejemplo: instancia de ejemplo
Y el bean de ejemplo es generado por el posprocesador de fábrica myFactoryBean.
Los clientes pueden inyectar ejemplos como frijoles normales:
public class Client {
@Autowired
private Example example;
}
De esta forma, definimos beans de forma flexible a través de clases de configuración y beans de fábrica. La clase de configuración define el bean de fábrica, que a su vez define el bean final.
Este método combina la flexibilidad de los beans de fábrica con la comodidad que brinda @Configuration, y es un modo muy práctico para definir beans en Spring.
A continuación, todavía usamos código para simular este proceso de análisis:
public class AtBeanPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
}
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//首先建立一个元数据读取工厂,方便后面的元数据读取
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
//对指定路径上的类资源进行元数据读取
MetadataReader reader = factory.getMetadataReader(new ClassPathResource("com/itheima/a05/Config.class"));
//得到所有带有@Bean注解的方法
Set<MethodMetadata> methods = reader.getAnnotationMetadata().getAnnotatedMethods(Bean.class.getName());
for (MethodMetadata method : methods) {
System.out.println(method);
//创建BeanDefinitionBuilder
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
//提供工厂方法的名字,同时指定工厂对象
builder.setFactoryMethodOnBean(method.getMethodName(), "config");
//因为 工厂方法有参数我们这里要设置自动装配的模式
builder.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_CONSTRUCTOR);
//得到bean定义
AbstractBeanDefinition bd = builder.getBeanDefinition();
//通过BeanFactory进行bean的注册
beanFactory.registerBeanDefinition(method.getMethodName(), bd);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Aviso:
- Debido a que el método de fábrica tiene parámetros, debemos configurar el modo de ensamblaje automático aquí
- Para los parámetros del método de fábrica y el método de constructor, si desea utilizar el ensamblaje automático, todos son
AbstractBeanDefinition.AUTOWIRE_CONSTRUCTORtipos - Podemos imaginar la clase de configuración como una fábrica, y el método marcado con @Bean en la clase de configuración actúa como un método de fábrica.
Finalmente, simulemos y analicemos la interfaz de Mapper:
En primer lugar, debemos entender cómo Spring administra la interfaz de Mapper.
Spring generará automáticamente clases de implementación de proxy basadas en la interfaz de Mapper, que es cómo Spring administra la interfaz de Mapper.
Los pasos específicos son:
- Registre la interfaz de Mapper en la configuración de Spring, generalmente usando la anotación @MapperScan para escanear todas las interfaces de Mapper en el paquete:
@MapperScan("com.example.mapper") @Configuration public class AppConfig { } - Spring generará el objeto proxy correspondiente de acuerdo con la interfaz Mapper, y el objeto proxy implementará el método de la interfaz Mapper.
- Cuando se llama al método de la interfaz Mapper, se ejecuta realmente el método del objeto proxy. El objeto proxy obtendrá SqlSession de SqlSessionFactory y llamará a SqlSession para realizar operaciones de base de datos.
- Spring crea SqlSession usando SqlSessionFactory. SqlSessionFactory se obtiene según DataSource y Mapper XML o configuración de anotaciones.
Entonces, todo el proceso es:
- Registre la interfaz de Mapper (usualmente usando @MapperScan)
- Spring genera un objeto proxy para la interfaz Mapper
- El programa llama al método de la interfaz Mapper, que en realidad llama al método del objeto proxy
- El objeto proxy realiza operaciones de base de datos a través de SqlSession
- SqlSession se obtiene de SqlSessionFactory y SqlSessionFactory se configura desde DataSource
Después de leer el proceso anterior, podemos tener fácilmente una pregunta: ¿De dónde proviene el objeto proxy de este Mapeador ?
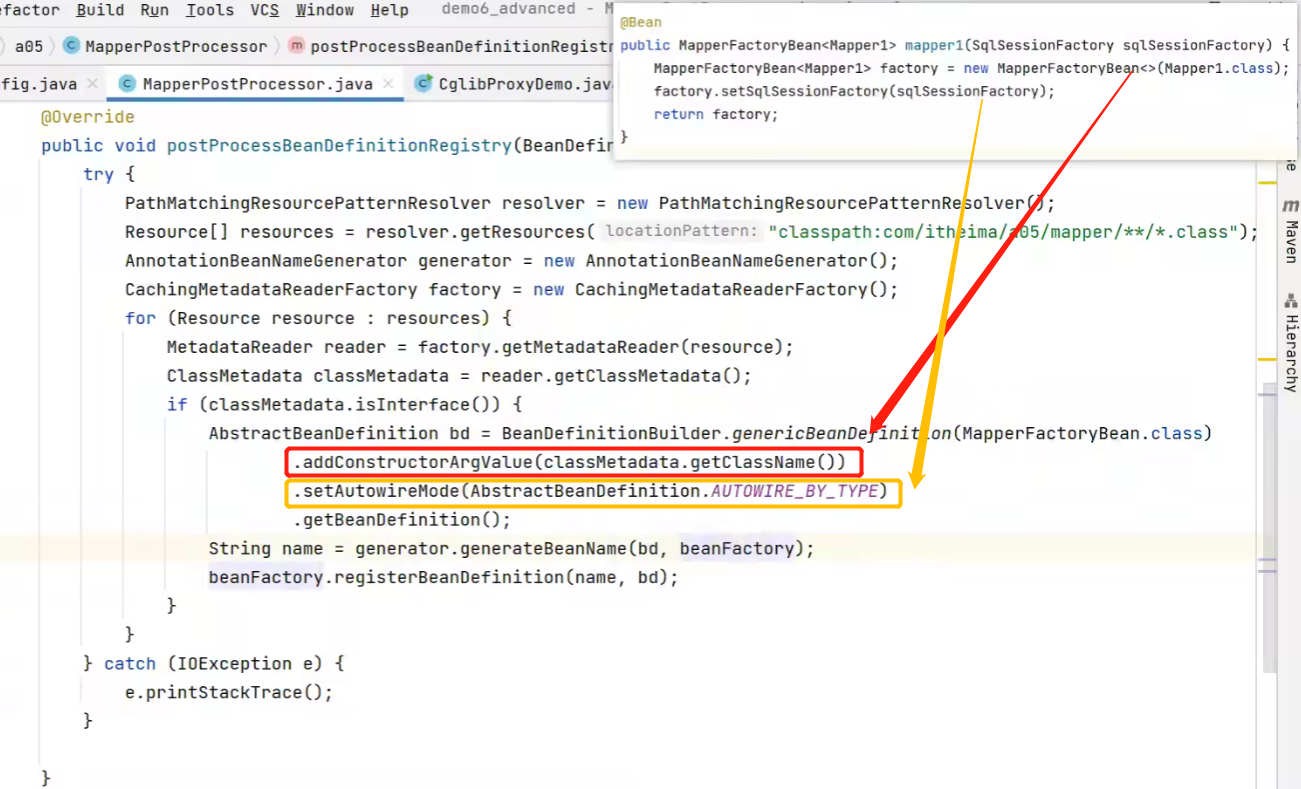
Aquí vamos a introducir otro componente importante:MapperFactoryBean
MapperFactoryBean es un bean de fábrica que se utiliza para generar objetos proxy de interfaz Mapper. En otras palabras, Spring gestiona la interfaz de Mapper a través de MapperFactoryBean.
Cuando registramos un bean de interfaz Mapper en la configuración de Spring, Spring usará MapperFactoryBean para generar este bean。
Todo el proceso es:
- Defina el bean de interfaz Mapper en la configuración de Spring y especifique la clase como MapperFactoryBean:
<bean id="userMapper" class="org.mybatis.spring.mapper.MapperFactoryBean"> <property name="mapperInterface" value="com.example.mapper.UserMapper" /> </bean> - Spring creará una instancia de MapperFactoryBean e inyectará la propiedad mapperInterface especificada.
- Spring llamará al método getObject() de MapperFactoryBean para obtener la instancia del bean.
- En el método getObject(), MapperFactoryBean construirá el objeto proxy de la interfaz Mapper y lo devolverá.
- El objeto proxy devuelto se registrará como un bean cuyo id es userMapper, y este bean es la implementación de proxy de la interfaz UserMapper.
- Entonces podemos inyectar UserMapper como inyectar beans ordinarios, y lo que en realidad obtenemos es un objeto proxy.
Por lo tanto, MapperFactoryBean desempeña un papel que debería tener un bean de fábrica: generar una instancia de bean de acuerdo con ciertas propiedades. Aquí, genera el bean de objeto proxy de la interfaz Mapper de acuerdo con la propiedad mapperInterface.
Se puede ver que uno de los pasos clave para que Spring administre la interfaz de Mapper es usar MapperFactoryBean para generar objetos proxy. El MapperFactoryBean es un bean de fábrica proporcionado por el módulo MyBatis-Spring para este propósito.
A continuación, comenzamos a escribir el código de simulación, el efecto es el siguiente:
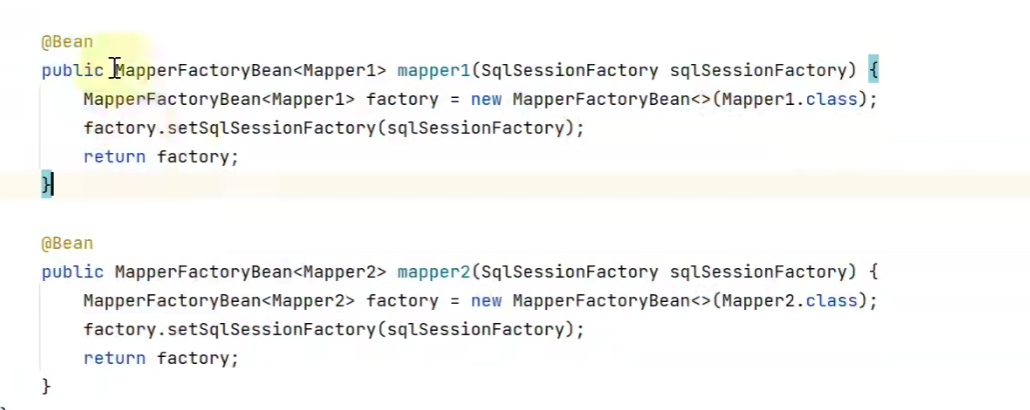
public class MapperPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//创建一个路径匹配资源解析器
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
//获取该路径下的所有class文件
Resource[] resources = resolver.getResources("classpath:com/zyb/a05/mapper/**/*.class");
//创建一个注解beanname生成器,方便后面bean的命名
AnnotationBeanNameGenerator generator = new AnnotationBeanNameGenerator();
//创建MetadataReader的工厂,为MetadataReader的使用做准备
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
for (Resource resource : resources) {
//拿到MetadataReader
MetadataReader reader = factory.getMetadataReader(resource);
//获得类的元数据
ClassMetadata classMetadata = reader.getClassMetadata();
//判断当前类是不是接口
if (classMetadata.isInterface()) {
//开始生成对应MapperFactoryBean的定义
AbstractBeanDefinition bd = BeanDefinitionBuilder.genericBeanDefinition(MapperFactoryBean.class) //指定Bean的类型
.addConstructorArgValue(classMetadata.getClassName())
.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE)
.getBeanDefinition();
//这里的定义仅仅只是为了生成名字,所以我们后面没有向容器里进行注册
AbstractBeanDefinition bd2 = BeanDefinitionBuilder.genericBeanDefinition(classMetadata.getClassName()).getBeanDefinition();
String name = generator.generateBeanName(bd2, beanFactory);
//使用bd的定义、bd2的name进行注册
beanFactory.registerBeanDefinition(name, bd);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}
En cuanto al período de llamada del postprocesador (PostProcessor)
El método postProcessBeanFactory() de BeanFactoryPostProcessor se llamará en los siguientes momentos:
- Todas las BeanDefinitions se cargan, pero antes de que se creen instancias de los beans.
- Es decir, modificará la definición del bean cuando se inicialice el contenedor para prepararse para la siguiente inicialización de la instancia del bean.
El momento de su llamada está en la fase de inicialización del contenedor Spring, y el proceso general es el siguiente:
- Carga de recursos Spring, lectura de xml/anotaciones, etc. y análisis para generar BeanDefinition.
- Llame al método postProcessBeanDefinitionRegistry() del BeanDefinitionRegistryPostProcessor. BeanDefinitions se puede agregar/eliminar aquí.
- Llame al método postProcessBeanFactory() de BeanFactoryPostProcessor. Aquí se pueden modificar las propiedades de BeanDefinition, etc.
- fase de creación de instancias de bean: cree una instancia de bean de acuerdo con BeanDefinition.
- Llame al método postProcessBeforeInitialization() del BeanPostProcessor.
- Llame a métodos de devolución de llamada de inicialización como @PostConstruct o init-method.
- Llame al método postProcessAfterInitialization() del BeanPostProcessor.
- Todo el contenedor Spring está cargado.
Asegúrese de tener un orden general en mente. Cuando se inicializa el contenedor Spring, primero analiza la definición del bean, registra el bean en el contenedor de acuerdo con la definición y entra en el ciclo de vida del bean después de registrar el bean: creación --> inyección de dependencia --> inicialización --> disponible --> destrucción
entonces,El momento de llamar a BeanFactoryPostProcessor se especifica en el paso 3, después de que se carguen todas las definiciones de Bean, pero antes de que se creen instancias de beans.. Podemos usar este tiempo para modificar BeanDefinition en lotes.
Para dar un ejemplo simple:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
for (String beanName : beanFactory.getBeanDefinitionNames()) {
BeanDefinition definition = beanFactory.getBeanDefinition(beanName);
if (definition.getScope().equals(BeanDefinition.SCOPE_PROTOTYPE)) {
definition.setScope(BeanDefinition.SCOPE_SINGLETON);
}
}
}
}
Este posprocesador modificará todos los beans con ámbito de prototipo para que tengan un ámbito único. Su tiempo de llamada es justo después de que se cargan todas las BeanDefinitions y antes de que se cree una instancia del bean. Entonces puede modificar frijoles por lotes.
Además, el tiempo de llamada de BeanDefinitionRegistryPostProcessor es anterior a BeanFactoryPostProcessor, lo que permite agregar o eliminar BeanDefinition. Por lo tanto, si estas dos interfaces se implementan al mismo tiempo, debe tenerse en cuenta que el BeanDefinition definido en postProcessBeanDefinitionRegistry() está disponible en postProcessBeanFactory().
en conclusión:
- Se llama a BeanFactoryPostProcessor después de cargar BeanDefinition antes de crear una instancia del bean.
- Puede modificar las propiedades de BeanDefinition en lotes para prepararse para la posterior creación de instancias de beans.
- Su tiempo de llamada se encuentra en una etapa del proceso de inicialización del contenedor Spring, después de BeanDefinitionRegistryPostProcessor y antes de la instanciación del bean.
- Comprender el momento de su invocación nos ayudará a hacer un mejor uso de BeanFactoryPostProcessor para personalizar la definición del bean.
- Al implementar BeanFactoryPostProcessor y BeanDefinitionRegistryPostProcessor al mismo tiempo, es necesario prestar atención al orden de llamada de los dos y su impacto.
BeanFactoryPostProcessor nos proporciona un poderoso punto de extensión que nos permite personalizar y modificar BeanDefinition cuando se inicia el contenedor.
Interfaz consciente e interfaz InitializingBean
En primer lugar, necesitamos saber para qué sirve la interfaz de Aware.
La interfaz Aware es una interfaz en el marco Spring,Le permite a Bean percibir su propio entorno, como el contenedor Spring, el contexto de la aplicación, etc.. El marco Spring proporciona múltiples interfaces Aware que permiten a Beans percibir diferentes entornos.
Específicamente, cuando un Bean implementa una interfaz Aware, el contenedor Spring llamará automáticamente al método de interfaz correspondiente al Bean y pasará la información del entorno correspondiente al método como un parámetro. De esta forma, el Bean puede obtener información sobre su entorno y procesarla en consecuencia .
Es decir: al implementar estas interfaces Aware, podemos obtener algunos objetos en el contenedor Spring cuando se inicializa el bean y luego realizar más operaciones en el bean. en una palabraLa interfaz de Aware proporciona un método de inyección [incorporado]
Las siguientes son varias interfaces de Aware comúnmente utilizadas:
-
BeanNameAware: Esta interfaz permite que el Bean perciba su propio nombre en el contenedor Spring. -
ApplicationContextAware: Esta interfaz permite que el Bean perciba el contexto de la aplicación en la que se encuentra. -
BeanFactoryAware: Esta interfaz permite que el Bean perciba la fábrica de Bean en la que se encuentra.
Por ejemplo, el siguiente código muestra un bean que implementa la interfaz ApplicationContextAware:
public class MyBean implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public void doSomething() {
// 使用ApplicationContext进行相应的处理
}
}
En este ejemplo, MyBean implementa la interfaz ApplicationContextAware y reescribe el método setApplicationContext. En este método, guardamos la instancia de ApplicationContext entrante para usarla en el procesamiento posterior.
Cabe señalar que la interfaz Aware es solo un mecanismo de percepción y no cambia el comportamiento del Bean. Por lo tanto, si un Bean implementa la interfaz Aware, pero no procesa la información del entorno correspondiente, entonces la interfaz no tiene ningún efecto práctico.
Entonces echemos un vistazo a la interfaz InitializingBean, ¿qué es esto?
InitializingBean es una interfaz y tiene un método:
void afterPropertiesSet() throws Exception;
Los beans que implementan esta interfaz llamarán al método afterPropertiesSet() después de que el contenedor haya establecido todas las propiedades necesarias y antes de la inicialización.。
Al igual que la interfaz Aware, podemos entenderla como:
La interfaz InitializingBean proporciona un método de inicialización [incorporado]
Esto nos da la oportunidad de realizar una inicialización personalizada en el bean antes de que se inicialice . Por ejemplo, en el método afterPropertiesSet(), podemos:
- Verifique si las propiedades requeridas están todas establecidas
- Hacer el procesamiento final en ciertos atributos
- llamar al método de inicialización, etc.
Un ejemplo sencillo:
public class MyBean implements InitializingBean {
private String message;
public void setMessage(String message) {
this.message = message;
}
@Override
public void afterPropertiesSet() {
System.out.println(message);
}
}
Luego defina este bean en la configuración de Spring:
<bean id="myBean" class="com.example.MyBean">
<property name="message" value="Init done!" />
</bean>
Cuando el contenedor Spring inicializa este bean, ocurre el siguiente proceso:
- Establezca las propiedades necesarias a través del método setter, y la propiedad del mensaje se establece en "¡Iniciar listo!"
- Llame al método afterPropertiesSet() para imprimir el valor de la propiedad del mensaje
- inicialización de bean completa
Por lo tanto, el método afterPropertiesSet() proporciona una devolución de llamada, lo que nos permite agregar una lógica personalizada antes de la inicialización del bean. Este también es un propósito similar a la interfaz Aware, pero de una manera ligeramente diferente:
- Las devoluciones de llamada de la interfaz consciente ocurren después de la inyección de dependencia
- Mientras que la devolución de llamada de InitializingBean ocurre después de la inyección de dependencia, pero antes de la inicialización.
- El tiempo de devolución de llamada de la interfaz Aware y la interfaz InitializingBean es posterior a la creación de una instancia del Bean, por lo que ambos pueden obtener la instancia del Bean y realizar las operaciones correspondientes. Sin embargo, el tiempo de devolución de llamada de la interfaz Aware es anterior a la inyección de dependencia, por lo que no puede obtener otras instancias de Bean. El tiempo de devolución de llamada de la interfaz InitializingBean es después de la inyección de dependencia, por lo que puede obtener otras instancias de Bean y realizar el trabajo de inicialización correspondiente.
Sobre la interfaz Aware y la interfaz InitializingBean, también decimos :
- La inyección y la inicialización integradas no se ven afectadas por las funciones de extensión y siempre se ejecutarán
- Sin embargo, la función extendida puede no ser válida debido a ciertas circunstancias.
- Por lo tanto, las clases dentro del marco Spring a menudo usan inyección e inicialización integradas.
Estas pocas oraciones pueden no ser fáciles de entender, demos un ejemplo:
Algunas funciones se pueden realizar con @Autowired, ¿por qué usar la interfaz Aware?
hablando en general:
- El análisis de @Autowired necesita usar el postprocesador de bean, que pertenece a la función de extensión
- La interfaz Aware es una función integrada, sin ninguna extensión, Spring puede reconocer que,
en algunos casos, la función extendida fallará, pero la función integrada no fallará
Veamos un trozo de código:
@Configuration
public class MyConfig1 {
private static final Logger log = LoggerFactory.getLogger(MyConfig1.class);
@Autowired
public void setApplicationContext(ApplicationContext applicationContext) {
log.debug("注入 ApplicationContext");
}
@PostConstruct
public void init() {
log.debug("初始化");
}
@Bean // beanFactory 后处理器
public BeanFactoryPostProcessor processor1() {
return beanFactory -> {
log.debug("执行 processor1");
};
}
}
Clase de prueba:
/*
Aware 接口及 InitializingBean 接口
*/
public class A06 {
private static final Logger log = LoggerFactory.getLogger(A06.class);
public static void main(String[] args) {
GenericApplicationContext context = new GenericApplicationContext();
context.registerBean("myConfig1", MyConfig1.class);
context.registerBean(AutowiredAnnotationBeanPostProcessor.class);
context.registerBean(CommonAnnotationBeanPostProcessor.class);
context.registerBean(ConfigurationClassPostProcessor.class);
/*
Java 配置类在添加了 bean 工厂后处理器后,
你会发现用传统接口方式的注入和初始化仍然成功, 而 @Autowired 和 @PostConstruct 的注入和初始化失败
*/
context.refresh(); // 1. beanFactory 后处理器, 2. 添加 bean 后处理器, 3. 初始化单例
context.close();
}
}
Después de ejecutar el método refresh(), las siguientes operaciones se ejecutarán aproximadamente en secuencia en el contenedor (hay muchas acciones que no se enumeran):
- Postprocesador beanFactory
- Añadir bean post-procesador
- Inicializar el singleton
Resultado:

se puede ver que las anotaciones @PostConstruct y @Autowired no son válidas. ¿Por qué?
Si desea comprender completamente esto, debe averiguar el tiempo de devolución de llamada del posprocesador, la interfaz Aware y la interfaz InitializingBean. ! !
El caso en el que la clase de configuración de Java no contiene BeanFactoryPostProcessor
El caso donde la clase de configuración de Java contiene BeanFactoryPostProcessor
Por lo tanto, para crear el BeanFactoryPostProcessor, debe crear la clase de configuración de Java con anticipación (cómo ejecutar el método para obtener el Bean si no lo crea), y el BeanPostProcessor no está listo en este momento, lo que hace que las anotaciones como @Autowired fallen.
NOTA
Solución alternativa:
- Reemplace la inyección e inicialización de dependencias extendidas con la inyección e inicialización de dependencias integradas
- Use métodos de fábrica estáticos en lugar de métodos de fábrica de instancias para evitar que se creen objetos de fábrica por adelantado.
Si necesita usar anotaciones @Autowired y @PostConstruct en BeanFactoryPostProcessor, puede considerar usar la interfaz ApplicationContextAware y la interfaz InitializingBean para implementar la inyección e inicialización de dependencias. Específicamente, puede implementar la interfaz ApplicationContextAware para obtener una instancia de ApplicationContext y luego usar esta instancia para la inyección de dependencia; al mismo tiempo, puede implementar la interfaz InitializingBean para implementar la lógica de inicialización de Bean.
Por ejemplo:
@Configuration
public class MyConfig1 implements ApplicationContextAware, InitializingBean {
private static final Logger log = LoggerFactory.getLogger(MyConfig1.class);
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
log.debug("注入 ApplicationContext");
}
@Override
public void afterPropertiesSet() {
log.debug("初始化");
}
@Bean
public BeanFactoryPostProcessor processor1() {
return beanFactory -> {
log.debug("执行 processor1");
};
}
}
En este ejemplo, la interfaz ApplicationContextAware y la interfaz InitializingBean se implementan para la inserción e inicialización de dependencias, respectivamente. De esta forma, cuando se ejecuta el BeanFactoryPostProcessor, se puede realizar la inyección de dependencias a través de la instancia de ApplicationContext; al mismo tiempo, luego de instanciado el Bean, se puede inicializar a través del método de implementación de la interfaz InitializingBean.
inicialización y destrucción
Spring proporciona una variedad de métodos de inicialización. Además de @PostConstruct y @Bean(initMethod), también puede implementar la interfaz InitializingBean para la inicialización. Si el mismo bean declara tres métodos de inicialización usando los métodos anteriores, su orden de ejecución es
- Método de inicialización anotado por @PostConstruct
- Método de inicialización de la interfaz InitializingBean
- El método de inicialización especificado por @Bean(initMethod)
Similar a la inicialización, Spring también proporciona una variedad de métodos de destrucción, el orden de ejecución es
- @PreDestroy 标注的销毁方法
- DisposableBean 接口的销毁方法
- @Bean(destroyMethod) 指定的销毁方法
示例代码:
@SpringBootApplication
public class A07_1 {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(A07_1.class, args);
context.close();
}
@Bean(initMethod = "init3")
public Bean1 bean1() {
return new Bean1();
}
@Bean(destroyMethod = "destroy3")
public Bean2 bean2() {
return new Bean2();
}
}
public class Bean1 implements InitializingBean {
private static final Logger log = LoggerFactory.getLogger(Bean1.class);
@PostConstruct
public void init1() {
log.debug("初始化1");
}
@Override
public void afterPropertiesSet() throws Exception {
log.debug("初始化2");
}
public void init3() {
log.debug("初始化3");
}
}
public class Bean2 implements DisposableBean {
private static final Logger log = LoggerFactory.getLogger(Bean2.class);
@PreDestroy
public void destroy1() {
log.debug("销毁1");
}
@Override
public void destroy() throws Exception {
log.debug("销毁2");
}
public void destroy3() {
log.debug("销毁3");
}
}
Scope
在当前版本的 Spring 和 Spring Boot 程序中,支持五种 Scope
- singleton,容器启动时创建(未设置延迟),容器关闭时销毁(单例与容器同生共死)
- prototype,每次使用时创建,不会自动销毁,需要调用 DefaultListableBeanFactory.destroyBean(bean) 销毁(也就是说多例的销毁不归容器管理)
- request,每次请求用到此 bean 时创建,请求结束时销毁
- session,每个会话用到此 bean 时创建,会话结束时销毁
- application,web 容器用到此 bean 时创建,容器停止时销毁
有些文章提到有 globalSession 这一 Scope,也是陈旧的说法,目前 Spring 中已废弃
但要注意,如果在 singleton 注入其它 scope 都会有问题,解决方法有
- @Lazy
- @Scope(proxyMode = ScopedProxyMode.TARGET_CLASS)
- ObjectFactory
- ApplicationContext.getBean
解决方法虽然不同,但理念上殊途同归: 都是推迟其它 scope bean 的获取
我们举一个例子:
以单例注入多例为例
有一个单例对象 E
@Component
public class E {
private static final Logger log = LoggerFactory.getLogger(E.class);
private F f;
public E() {
log.info("E()");
}
@Autowired
public void setF(F f) {
this.f = f;
log.info("setF(F f) {}", f.getClass());
}
public F getF() {
return f;
}
}
要注入的对象 F 期望是多例
@Component
@Scope("prototype")
public class F {
private static final Logger log = LoggerFactory.getLogger(F.class);
public F() {
log.info("F()");
}
}
测试
E e = context.getBean(E.class);
F f1 = e.getF();
F f2 = e.getF();
System.out.println(f1);
System.out.println(f2);
输出
com.zyb.demo.cycle.F@6622fc65
com.zyb.demo.cycle.F@6622fc65
发现它们是同一个对象,而不是期望的多例对象
对于单例对象来讲,依赖注入仅发生了一次,后续再没有用到多例的 F,因此 E 用的始终是第一次依赖注入的 F
解决
- 仍然使用 @Lazy 生成代理
- Aunque el objeto proxy sigue siendo el mismo, cuando cualquier método del objeto proxy se usa cada vez , el proxy crea un nuevo objeto f
@Component
public class E {
@Autowired
@Lazy
public void setF(F f) {
this.f = f;
log.info("setF(F f) {}", f.getClass());
}
// ...
}
Aviso
- @Lazy también se puede agregar a las variables miembro, pero el propósito de agregarlo al método set es observar la salida, y agregarlo a las variables miembro no funcionará
- El propósito de agregar @Autowired al método set es similar
producción
E: setF(F f) class com.zyb.demo.cycle.F$$EnhancerBySpringCGLIB$$8b54f2bc
F: F()
com.zyb.demo.cycle.F@3a6f2de3
F: F()
com.zyb.demo.cycle.F@56303b57
Desde el registro de salida, podemos ver que cuando se llama al método setF, el tipo del objeto f es el tipo de proxy