Revisión anterior
Continúe con el artículo anterior " Desgarrar el código fuente central de Spring a mano y comprender a fondo el proceso de Spring ". Debido a la relación lógica entre contextos, los amigos que no hayan leído el artículo anterior recomiendan enfáticamente leer el artículo anterior primero.
Un breve resumen del artículo anterior:
Primero escribimos una versión HelloWorld de Spring juntos. Debido a que el núcleo de Spring es la inversión de control, es decir, los objetos Bean se entregan a Spring para que los administre. Los desarrolladores solo necesitan obtenerlo cuando lo usan. Hay dos pasos en uso: el primer paso es crear un contenedor de contexto Spring a través de la configuración de anotaciones; el segundo paso es obtener los beans necesarios para su uso.
Si tiene sentido, primero construimos el marco requerido para estos dos pasos, por lo que tenemos el siguiente estante:
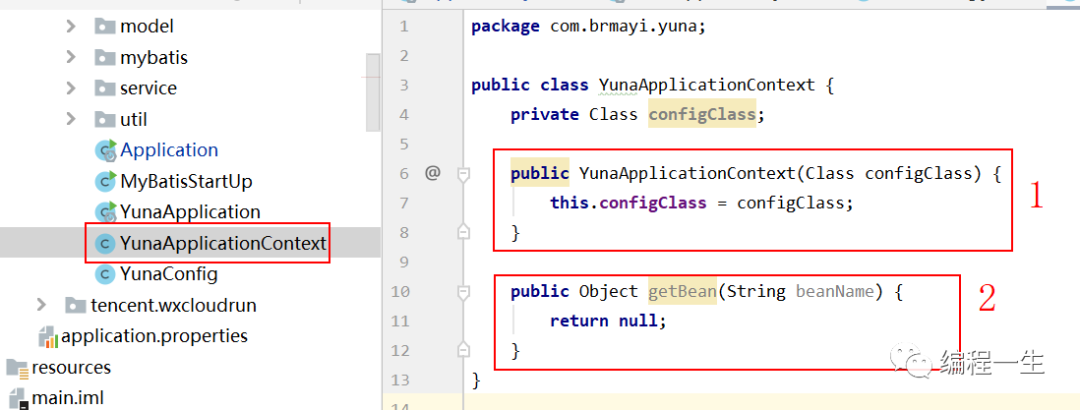
Luego, debemos llenar este estante con carne y sangre, para lograr el objetivo de usar Spring a través de anotaciones para la inyección de dependencia. Lo primero que hay que hacer es definir las anotaciones utilizadas:
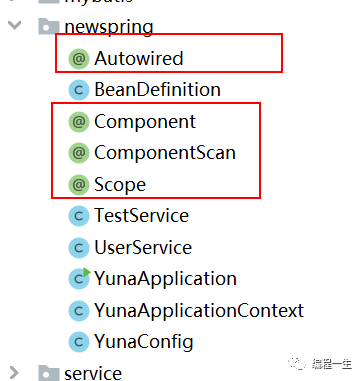
Implementar funciones de acuerdo con estas anotaciones y marcos definidos es algo que puede hacer un desarrollador experimentado. Para facilitar la integración del código final con el código fuente de Spring, ajusté ligeramente el nombre, el nombre es el mismo que en el código fuente de Spring y la función es la misma:
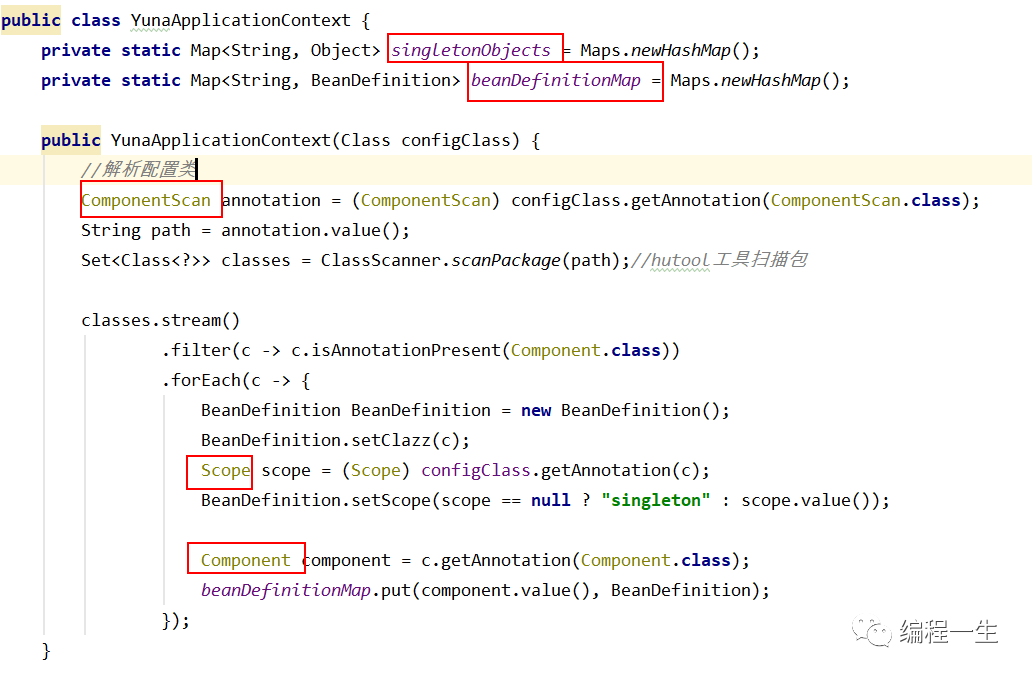
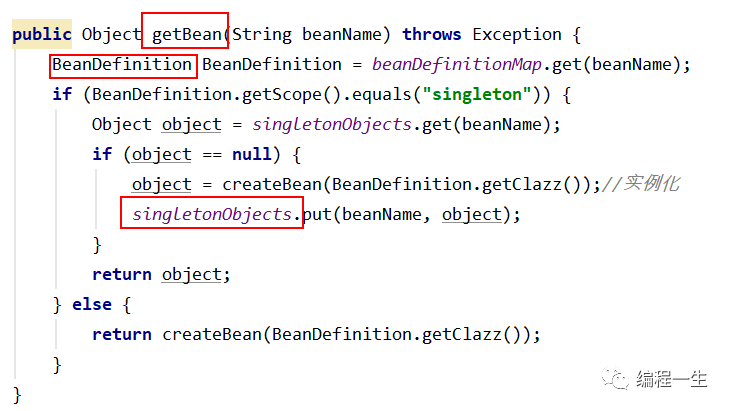
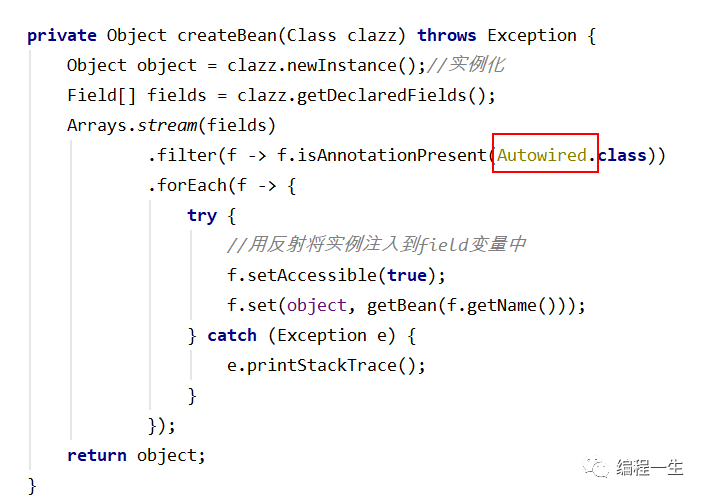
Los pasos clave para que Spring cree Beans se reflejan aquí:
1. Generar definición de Bean según clase
2. Instanciar según Bean
3. Complete las propiedades del Bean de la instancia (se instancian las propiedades autoconectadas)
4. Complete la creación del objeto Bean
De hecho, Spring también realiza una gran cantidad de procesamiento antes de instanciar el bean para generar el objeto bean, como la inicialización y la mejora del bean. Los posprocesadores AOP y Bean están estrechamente relacionados. Hoy nos centraremos en esta parte.
Todo el texto del código de este artículo se puede encontrar en https://github.com/xiexiaojing/yuna.
Inicialización de frijoles
Spring tiene tres formas de inicializar beans, el principio es el mismo, son:
1. Implementar la interfaz InitializingBean
2. Usa la anotación @PostConstruct
3. O especifique el método de inicio
<bean
id="testInitializingBean"
class="com.TestInitializingBean"
init-method="testInit">
</bean>Cuando existen al mismo tiempo, hay una secuencia:
Orden de ejecución:
Constructor >
@PostConstruct >
InicializandoBean >
método de inicio
Dado que se implementó una gran cantidad de métodos de anotación en la sección anterior, los principios de los tres métodos de inicialización son similares.Este artículo romperá el código del método InitializingBean a mano:
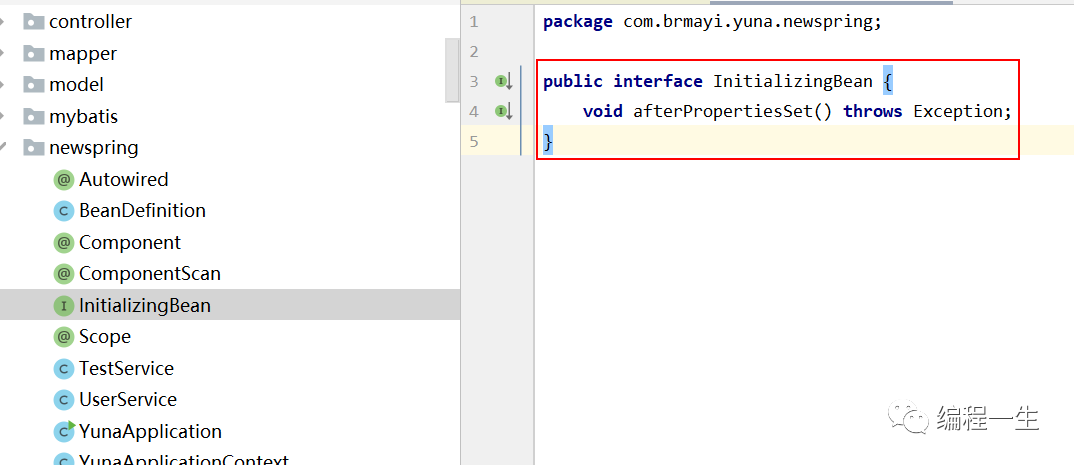
Primero defina una interfaz InitializingBean y copie la definición de la interfaz directamente desde el código fuente de spring-beans:
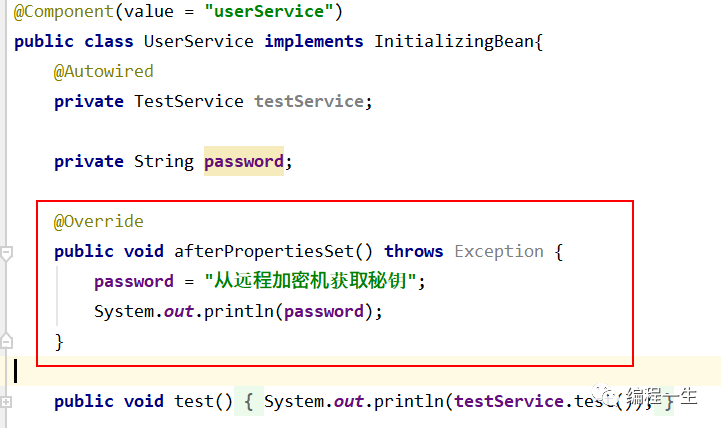
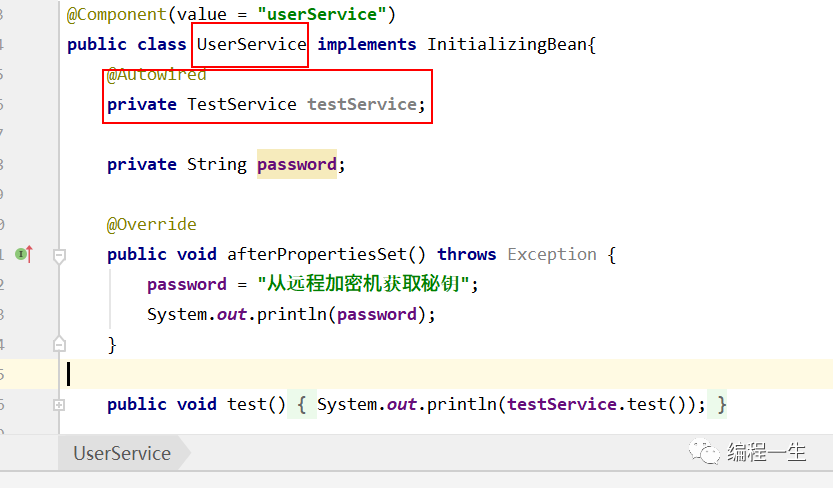
Luego busque un escenario de uso, como obtener el valor del control remoto después de que se crea una instancia del bean:
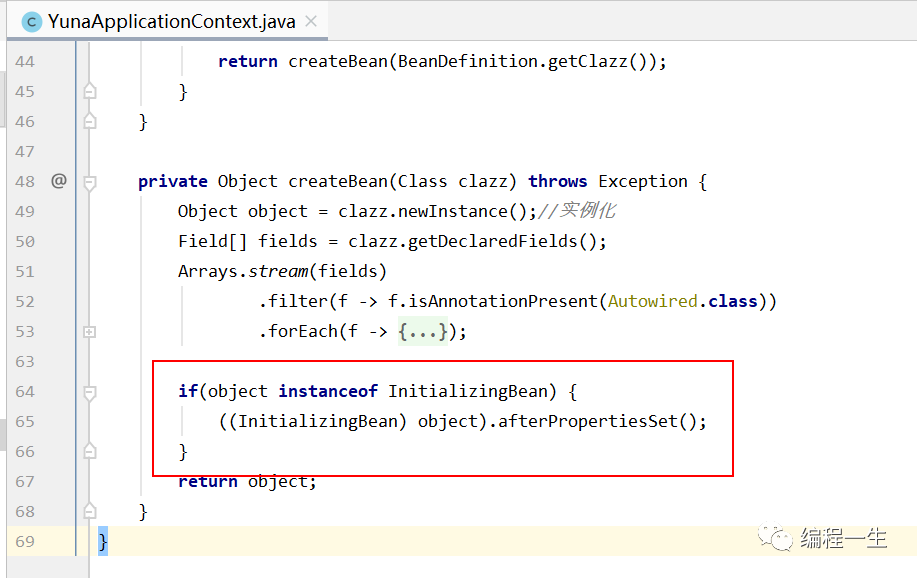
La implementación también es muy simple.Después de crear el Bean, agregue un juicio + llamada:
Echa un vistazo al efecto:
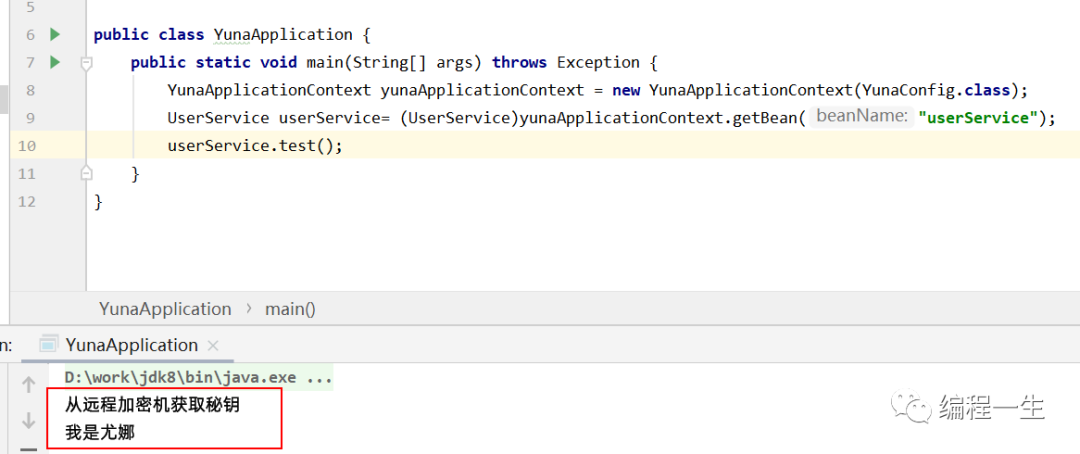
Lo anterior es la implementación del proceso de inicialización de Spring.
Postprocesador de frijol
Hay dos posprocesadores en Spring, BeanFactoryPostProcessor y BeanPostProcessor. El primero se denomina posprocesador de fábrica de frijoles y el segundo se denomina posprocesador de frijoles. Ahora todos estamos hablando de Bean, pero no hemos hablado de BeanFactory, así que no lo presentaré demasiado aquí.
El papel del postprocesador parece ser la carpintería. Primero se hace el contorno de la talla general de madera, y el siguiente paso es afinarlo y colorearlo, es decir, reprocesarlo. Spring-AOP se implementa a través de postprocesadores.
¿Cuál es el tiempo de ejecución del posprocesador Bean? Después de leer la definición de la interfaz, lo entenderá. Del mismo modo, copiemos la interfaz del posprocesador Spring directamente:
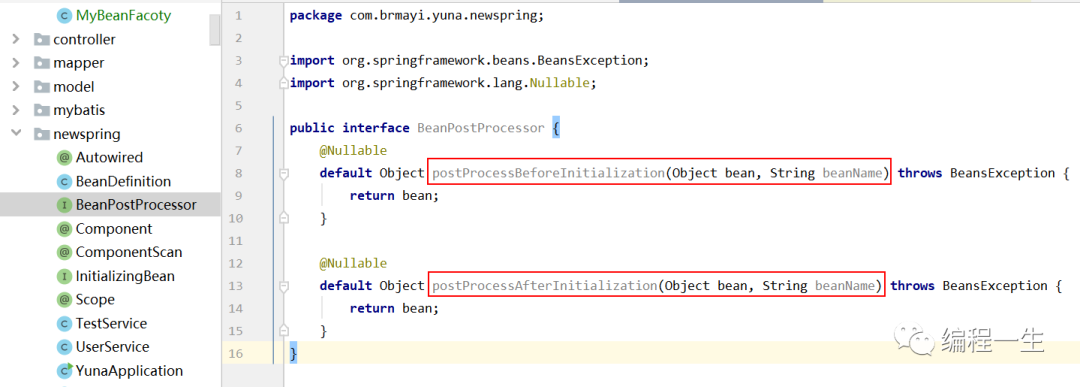
Hay dos métodos aquí, un método se llama:
Antes de la inicialización, procesamiento posterior
Un método se llama:
Después de la inicialización, posprocesamiento
Vamos a implementarlo de acuerdo con la definición del método:
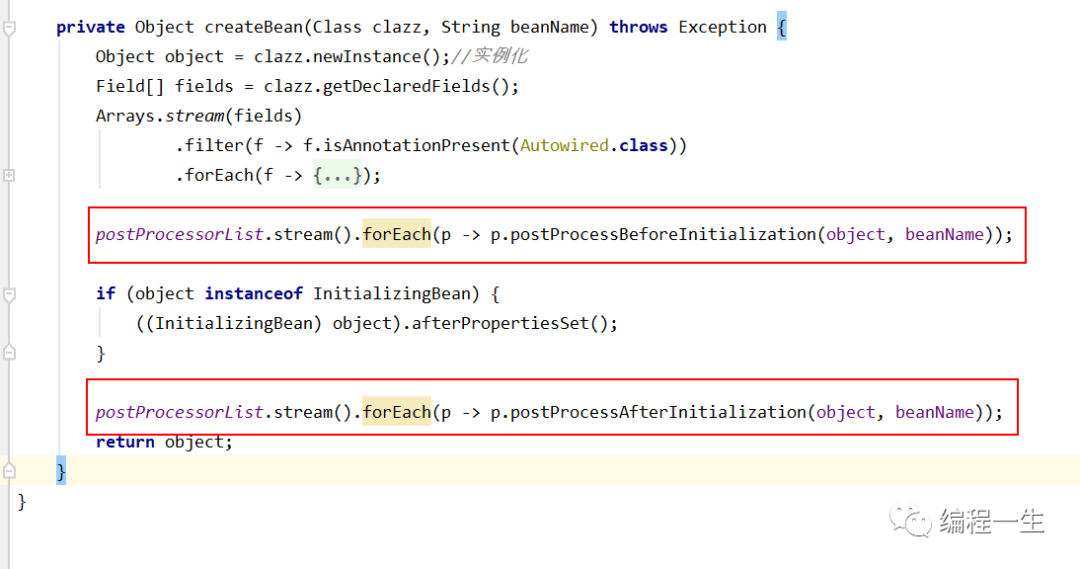
Tenga en cuenta que hay una lista de posprocesadores que acabo de definir, porque Spring tiene más de un posprocesador para proporcionar suficiente escalabilidad:

Entonces, ¿cuándo puso Spring el posprocesador en esta lista? Se coloca durante el escaneo, para un ejemplo específico de posprocesador:
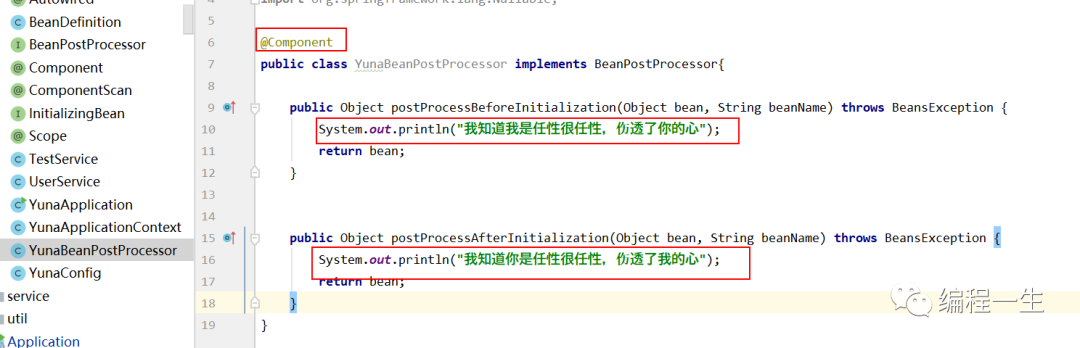
Porque para ser escaneado, debe ser un Componente. A menudo uso las dos letras impresas, así que permítanme explicar la fuente: en " Comprender el proceso de comunicación subyacente del lado de producción de MQ: comprender el canal ", puse la canción original de la canción. Me encantaba escucharlo cuando estaba en la universidad, pero ya no se siente bien cuando lo escucho de nuevo. Probablemente se enteró de que en los últimos diez años de matrimonio, su esposo obtuvo un amor voluntario, pero él es el que es tan tolerante e infeliz. Jajaja, es broma, la gente común como nosotros, las personas que están juntas al final son mutuamente tolerantes y exitosas.
Relájese un poco, vuelva al punto, escanee el postprocesador:
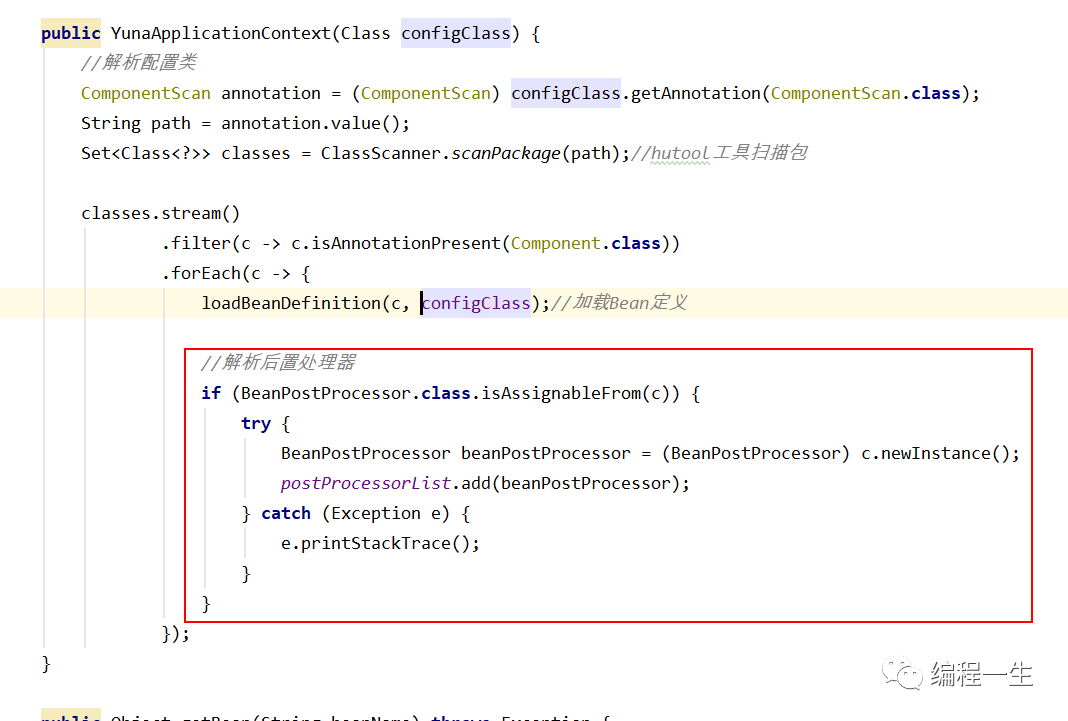
Debido a que el posprocesador está estrictamente definido, los beans no se pueden vincular internamente y no es necesario realizar la inicialización, por lo que se pueden instanciar directamente.
resultado de la operación:
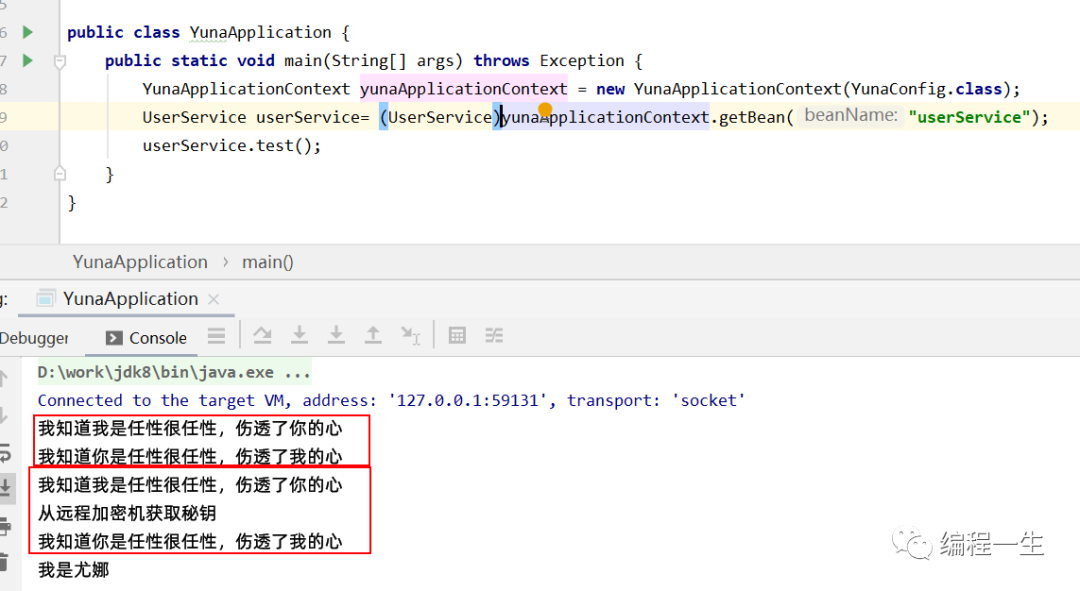
Aquí, los dos métodos del posprocesador se ejecutan dos veces cada uno porque se crean dos beans:
Por supuesto, podemos especificar las condiciones efectivas del posprocesador, pero no todos los beans.
Aquí hay una breve introducción de AOP, y no la venderé. AOP se implementa a través de un llamado
AnnotationAwareAspectJAutoProxyCreator
implementada por el post-procesador. Muchas implementaciones vienen a juzgar qué Beans pueden representar.
Resumir
Resumamos los pasos clave para crear frijoles en primavera:
1. Generar definición de Bean según clase
2. Instanciar según Bean
3. Complete la propiedad Bean de la instancia
4. Inicializar Bean
5. Postprocesamiento de frijoles
6. Complete la creación del objeto Bean
Si reorganizo el código y lo nombro de la misma manera que el código de Spring, encontrará que está muy cerca del código fuente de Spring en muchos lugares. Creo que comprender el código fuente de Spring es útil.
Bueno, después de leer este artículo, le sugiero que lea mi artículo : " Tres métodos y aplicaciones clásicas de la entrega de objetos a la administración de Spring " para ver si tiene una comprensión más profunda de Spring.
programación para toda la vida
Debido a que la plataforma de la cuenta oficial ha cambiado las reglas de publicación, si no quiere perderse el contenido, recuerde hacer clic en "ver" después de leerlo y agregar una "estrella", para que cada vez que se publique un nuevo artículo, se aparecerá en su lista de suscripción por primera vez.
Metodología PDCA , revisa si te pierdes la actualización: Actualizaré el artículo todos los miércoles alrededor de las 8:00 p. m. Si no lo recibes, recuerda abrir la cuenta oficial de [Programming Lifetime] para encontrarlo (*^▽^* ).