ссылка
《OpenCL в действии》
"Руководство по программированию OpenCL"
«Принцип гетерогенных параллельных вычислений OpenCl и практика оптимизации»
Использование образов OpenCL™ 2.0 для чтения и записи
Общее введение





объект изображения
В графических процессорах данные изображения хранятся в специальной глобальной памяти, называемой текстурной памятью.
В отличие от обычной глобальной памяти, память текстур кэшируется для быстрого доступа.
Объекты изображения служат механизмом хранения, который хост-приложения используют для передачи данных пикселей на устройство и с устройства.
Когда устройство получает данные изображения, сэмплеры сообщают ему, как считывать значения цвета.
На хосте объекты изображений представлены структурами cl_mem , а сэмплеры представлены структурами cl_sampler .
На устройстве объекты изображения представляют собой структуры image2d_t или image3d_t , а сэмплеры — это структуры sampler_t .
Все объекты памяти представлены типом данных cl_mem, и не существует отдельных
типов, позволяющих отличить объекты буфера от объектов изображения. Вместо этого, чтобы создать объект буфера,
вы можете вызвать clCreateBuffer или clCreateSubBuffer. Чтобы создать объект изображения, вы можете
вызвать clCreateImage2d или clCreateImage3d.

cl_mem clCreateImage2D(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
size_t image_width,
size_t image_height,
size_t image_row_pitch,
void* host_ptr,
cl_int* errcode_ret);
cl_mem clCreateImage3D(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
size_t image_width,
size_t image_height,
size_t image_depth,
size_t image_row_pitch,
size_t image_slice_pitch,
void* host_ptr,
cl_int* errcode_ret);
clReleaseMemObject(image).'clCreateImage2D': объявлен устаревшим".
>=1.2 версия становится clCreateImage
1D-изображение, буфер 1D-изображения, массив 1D-изображений, 2D-изображение, массив 2D-изображений и объект 3D-изображения могут быть созданы с помощью следующей функции.
cl_mem clCreateImage(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
const cl_image_desc* image_desc,
void* host_ptr,
cl_int* errcode_ret);
clReleaseMemObject(image).
typedef struct _cl_image_format {
cl_channel_order image_channel_order;
cl_channel_type image_channel_data_type;
} cl_image_format;
typedef struct cl_image_desc {
cl_mem_object_type image_type;
size_t image_width;
size_t image_height;
size_t image_depth;
size_t image_array_size;
size_t image_row_pitch;
size_t image_slice_pitch;
cl_uint num_mip_levels;
cl_uint num_samples;
#ifdef __GNUC__
__extension__ /* Prevents warnings about anonymous union in -pedantic builds */
#endif
union {
cl_mem buffer;
cl_mem mem_object;
};
} cl_image_desc;image_channel_order与image_channel_data_type:
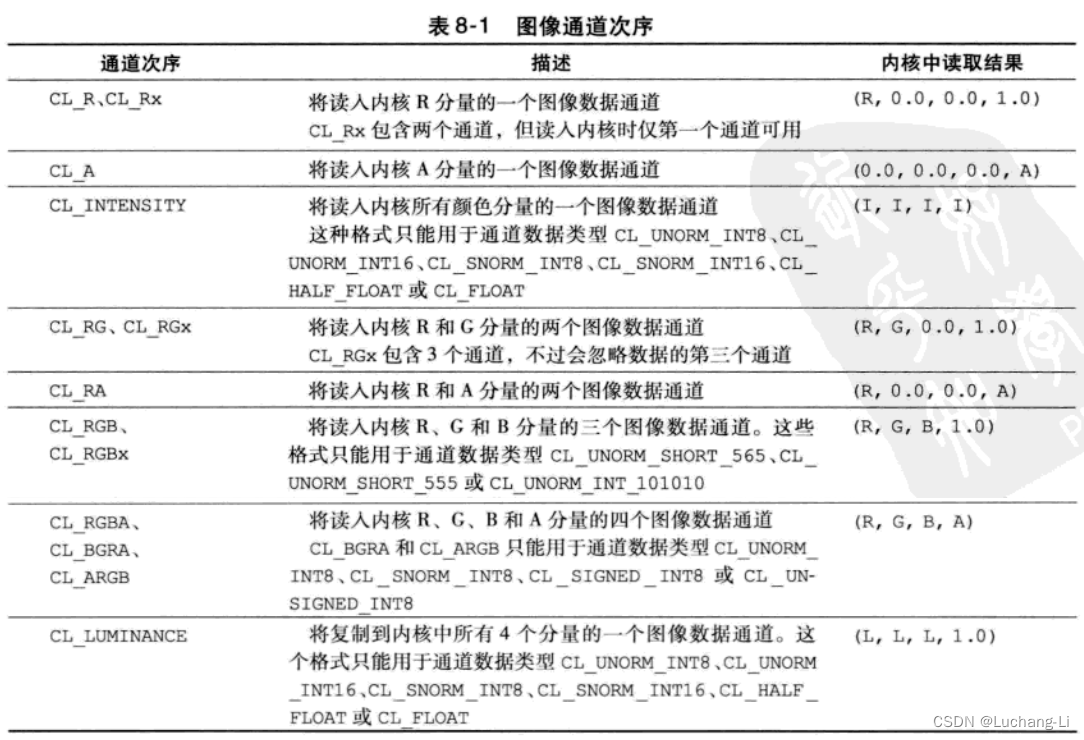

Поддержка формата изображения запроса


Например, следующий код инициализирует структуру cl_image_format,
пиксели которой отформатированы в соответствии с 24-битным форматом RGB:
cl_image_format rgb_format;
rgb_format.image_channel_order = CL_RGB;
rgb_format.image_channel_data_type = CL_UNSIGNED_INT8;Последние аргументы в clCreateImage2D и clCreateImage3D относятся к размерам объекта изображения и количеству байтов на измерение, также называемому шагом . Каждое измерение указано в пикселях , а на рисунке 3.2 представлены размеры объекта трехмерного изображения. Отдельные двумерные компоненты называются срезами.
В большинстве изображений количество байтов в строке можно определить, умножив количество байтов на пиксель на количество пикселей в строке . Но это не сработает, если строки содержат конечные биты или строки должны быть выровнены по границам памяти. По этой причине и clCreateImage2D, и clCreateImage3D принимают аргумент row_pitch, который определяет, сколько байтов содержится в каждой строке.Точно так же clCreateImage3D принимает аргумент slice_pitch, который определяет количество байтов в каждом двумерном изображении или срезе.
Если для row_pitch установлено значение 0, OpenCL будет считать, что его значение равно ширине * (размеру пикселя). Если для slice_pitch установлено значение 0, его значение будет установлено как row_pitch * высота.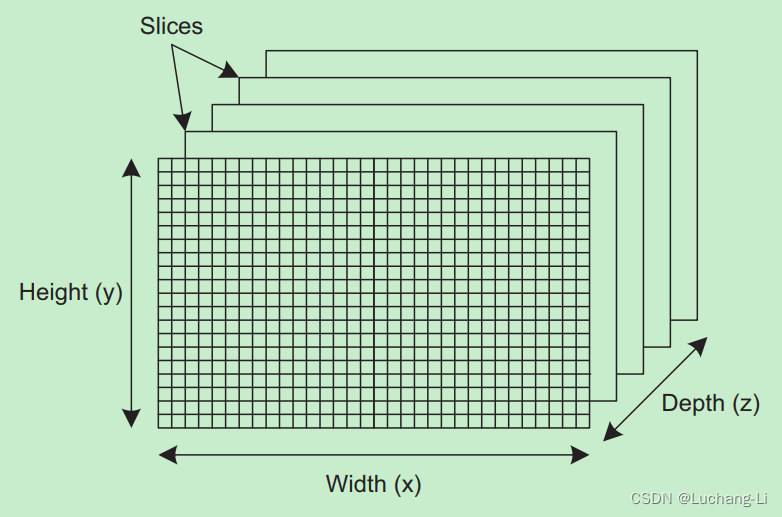
копировать данные между объектами памяти
clEnqueueReadBuffer // Reads data from a buffer object to host memory
clEnqueueWriteBuffer // Writes data from host memory to a buffer object
clEnqueueReadImage // Reads data from an image object to host memory
clEnqueueWriteImage // Writes data from host memory to an image object
void* clEnqueueMapBuffer // Maps a region of a buffer object to host memory
void* clEnqueueMapImage // Maps a rectangular region of an image object to host memory
int clEnqueueUnmapMemObject // Unmaps an existing memory object from host memory
clEnqueueCopyBuffer // Copies data from a source buffer object to a destination buffer object
clEnqueueCopyImage // Copies data from a source image object to a destination image object
clEnqueueCopyBufferToImage // Copies data from a source buffer object to a destination image object
clEnqueueCopyImageToBuffer // Copies data from a source image object to a destination buffer object
Сэмплер Сэмплер


Сэмплеры могут быть созданы хост-приложением или внутри ядра. Хост-приложения создают объекты cl_sampler, вызывая clCreateSampler, сигнатура которого выглядит следующим образом:
cl_sampler clCreateSampler(cl_context context, cl_bool normalized_coords,
cl_addressing_mode addressing_mode, cl_filter_mode filter_mode, cl_int *errcode_ret)Численные операции, а не обработка изображений должны использовать
cl_sampler clCreateSampler(context, /*normalized_coords*/ false,
/*addressing_mode*/ CL_ADDRESS_CLAMP, /*filter_mode*/ CL_FILTER_NEAREST, &errcode)
clReleaseSampler()Установите параметр образа ядра
clSetKernelArg(image_knl, 0, sizeof(cl_mem), &image);
clSetKernelArg(kernel, 0, sizeof(cl_sampler), &ex_sampler);
Создайте пример сэмплера в ядре устройства:
__constant sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE | CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST;
Работа ядра CL с изображениями
В OpenCL 1.2 и более ранних версиях изображения квалифицировались с помощью квалификаторов «__read_only» и __write_only. В OpenCL 2.0 изображения можно квалифицировать с помощью квалификатора «__read_write» и копировать вывод во входной буфер. Это уменьшает количество необходимых ресурсов.
OpenCL предоставляет ряд функций обработки изображений, которые можно запускать внутри ядра, и они делятся на три категории:
■ Функции чтения — возвращают значения цвета по заданной координате
■ Функции записи — устанавливают значения цвета по заданной координате
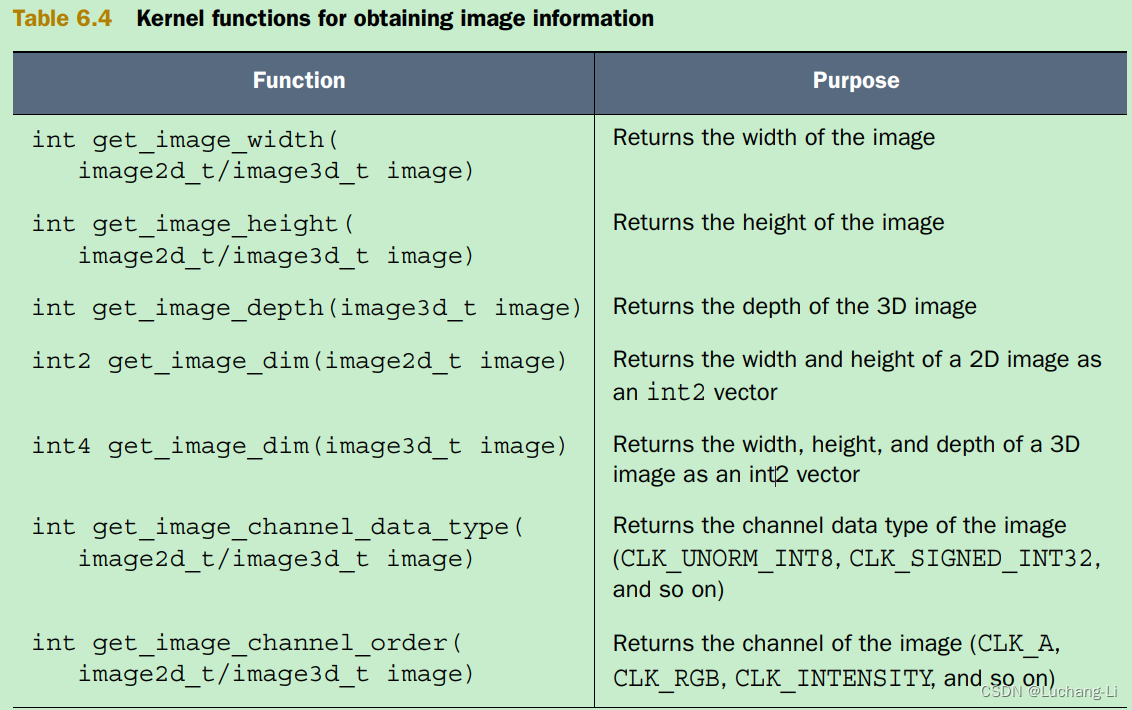
■ Информационные функции — предоставляют данные об объекте изображения, например, о его размерах и свойствах пикселей
half4 read_imageh(image2d_t image, sampler_t sampler, int2 coord);
half4 read_imageh(image2d_t image, sampler_t sampler, float2 coord);
void write_imageh(image2d_t image, int2 coord, half4 color);Для форм, принимающих image3d_t, используйте координату (coord.x, coord.y, coord.z) для поиска элемента в объекте 3D-изображения, заданном параметром image. coord.w игнорируется.
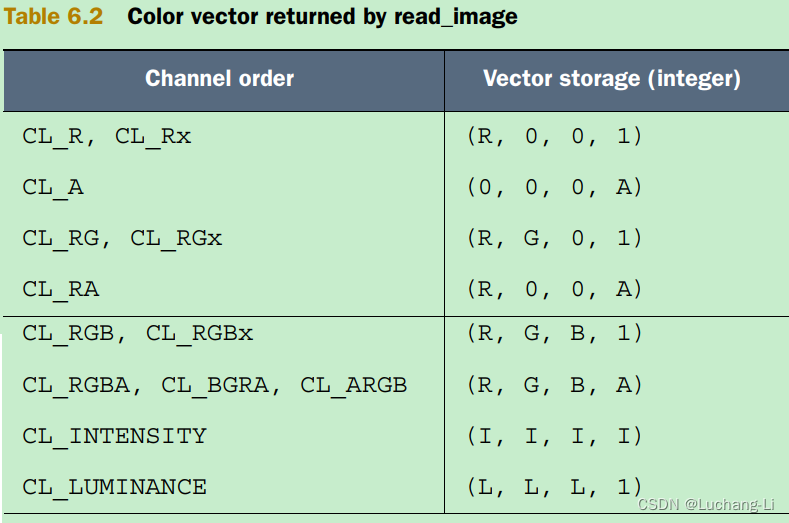
read_imagef возвращает значения с плавающей запятой для объектов изображения, созданных с image_channel_data_type установленным значением CL_HALF_FLOAT или CL_FLOAT.
Вызовы read_imagef , которые принимают целочисленные координаты, должны использовать сэмплер с установленным режимом фильтрации CLK_FILTER_NEAREST, нормализованными координатами, установленными на CLK_NORMALIZED_COORDS_FALSE , и режимом адресации, установленным на CLK_ADDRESS_CLAMP_TO_EDGE, CLK_ADDRESS_CLAMP или CLK_ADDRESS_NONE; в противном случае возвращаемые значения не определены.

Ядро размытия по Гауссу в OpenCL 2.0
__kernel void GaussianBlurDualPass(__read_only image2d_t inputImage, __read_write image2d_t tempRW,
__write_only image2d_t outputImage, __constant float* mask, int maskSize) {
int2 currentPosition = (int2)(get_global_id(0), get_global_id(1));
float4 currentPixel = (float4)(0, 0, 0, 0);
float4 calculatedPixel = (float4)(0, 0, 0, 0);
currentPixel = read_imagef(inputImage, currentPosition);
for (int maskIndex = -maskSize; maskIndex < maskSize + 1; ++maskIndex) {
currentPixel = read_imagef(inputImage, currentPosition + (int2)(maskIndex, 0));
calculatedPixel += currentPixel * mask[maskSize + maskIndex];
}
write_imagef(tempRW, currentPosition, calculatedPixel);
barrier(CLK_GLOBAL_MEM_FENCE);
for (int maskIndex = -maskSize; maskIndex < maskSize + 1; ++maskIndex) {
currentPixel = read_imagef(tempRW, currentPosition + (int2)(0, maskIndex));
calculatedPixel += currentPixel * mask[maskSize + maskIndex];
}
write_imagef(outputImage, currentPosition, calculatedPixel);
}
разработка оператора глубокого обучения изображений opencl
Разница между использованием opencl изображений и буферов для численных вычислений и разработкой операторов глубокого обучения:
Буфер соответствует линейной памяти в общепринятом понимании, а метод разработки очень близок к методу разработки NV GPU CUDA, что упрощает разработку оператора. Изображение заведомо сложнее и имеет много ограничений.Например, есть только 1D, 2D и 3D изображения, потому что разные операторы имеют разные размерности и методы индексации, и даже один и тот же оператор имеет разные размерности и методы индексации.Это требует от нас для разделения Используйте другое изображение для обработки, даже не для обработки изображения. Кроме того, изображение должно обрабатывать четыре компонента одновременно, что также усложняет обработку измерений оператором.
Кроме того, часто говорят, что производительность образа на arm gpu хуже, чем у буфера, поэтому образ имеет плохую совместимость с разными устройствами.
Лучшим решением является использование буфера в качестве модели основной памяти, а затем использование образа для ускорения определенных операций на графическом процессоре Qualcomm Adreno, таких как умножение матриц и свертка. Для arm mali gpu буферная память используется единообразно.
Используйте image2d для двух случаев сложения матриц [1024,1024]:
#include <iostream>
#include <memory>
#include <string>
#include <vector>
#include "mem_helper.h"
#define CL_HPP_TARGET_OPENCL_VERSION 300
#include <CL/opencl.hpp>
using DTYPE = half;
std::string kernel_source{R"(
#pragma OPENCL EXTENSION cl_khr_fp16 : enable
__constant sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE | CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST;
kernel void vecAdd(read_only image2d_t img_a, read_only image2d_t img_b, __write_only image2d_t img_c,
const unsigned int n) {
int gid_x = get_global_id(0);
int gid_y = get_global_id(1);
int2 coord = (int2)(gid_x, gid_y);
half4 data_a = read_imageh(img_a, sampler, coord);
half4 data_b = read_imageh(img_b, sampler, coord);
half4 data_c = data_a + data_b;
write_imageh(img_c, coord, data_c);
}
)"};
int main() {
std::vector<cl::Platform> platforms;
cl::Platform::get(&platforms);
std::cout << "get platform num:" << platforms.size() << std::endl;
cl::Platform plat;
for (auto& p : platforms) {
std::string platver = p.getInfo<CL_PLATFORM_VERSION>();
if (platver.find("OpenCL 2.") != std::string::npos || platver.find("OpenCL 3.") != std::string::npos) {
// Note: an OpenCL 3.x platform may not support all required features!
plat = p;
}
}
if (plat() == 0) {
std::cout << "No OpenCL 2.0 or newer platform found.\n";
return -1;
}
std::cout << "platform name:" << plat.getInfo<CL_PLATFORM_NAME>() << std::endl;
cl::Platform newP = cl::Platform::setDefault(plat);
if (newP != plat) {
std::cout << "Error setting default platform.\n";
return -1;
}
// get default device (CPUs, GPUs) of the default platform
std::vector<cl::Device> all_devices;
newP.getDevices(CL_DEVICE_TYPE_GPU, &all_devices); // CL_DEVICE_TYPE_ALL
std::cout << "get all_devices num:" << all_devices.size() << std::endl;
if (all_devices.size() == 0) {
std::cout << " No devices found. Check OpenCL installation!\n";
exit(1);
}
// cl::Device default_device = cl::Device::getDefault();
cl::Device default_device = all_devices[0];
std::cout << "device name: " << default_device.getInfo<CL_DEVICE_NAME>() << std::endl;
std::cout << "device CL_DEVICE_LOCAL_MEM_SIZE: " << default_device.getInfo<CL_DEVICE_LOCAL_MEM_SIZE>() << std::endl;
cl::Context context({default_device});
int queue_properties = 0;
queue_properties |= CL_QUEUE_PROFILING_ENABLE;
cl::CommandQueue queue(context, default_device, queue_properties);
const int height = 1024;
const int width = 1024;
const int width_d4 = width / 4;
int img_size = height * width_d4;
vector<int> shape1 = {height, width};
vector<int> shape2 = {height, width};
vector<int> shape3 = {height, width};
MemoryHelper<DTYPE> h_a(shape1);
MemoryHelper<DTYPE> h_b(shape1);
MemoryHelper<DTYPE> h_c(shape3);
h_a.StepInit(0.001f);
h_b.StepInit(0.002f);
memset(h_c.Mem(), 0, h_c.bytes);
cl_int error;
cl_image_format image_format;
image_format.image_channel_order = CL_RGBA;
image_format.image_channel_data_type = CL_HALF_FLOAT;
cl_image_desc image_desc = {0};
image_desc.image_type = CL_MEM_OBJECT_IMAGE2D;
image_desc.image_width = width;
image_desc.image_height = height;
image_desc.image_row_pitch = 0;
cl_mem img_a =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
cl_mem img_b =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
cl_mem img_c =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
if (error != CL_SUCCESS) {
printf("clCreateImage failed\n");
}
array<size_t, 3> region;
array<size_t, 3> origin;
origin[0] = 0;
origin[1] = 0;
origin[2] = 0;
region[0] = width_d4;
region[1] = height;
region[2] = 1;
error |=
clEnqueueWriteImage(queue.get(), img_a, CL_TRUE, origin.data(), region.data(), 0, 0, h_a.Mem(), 0, NULL, NULL);
error |=
clEnqueueWriteImage(queue.get(), img_b, CL_TRUE, origin.data(), region.data(), 0, 0, h_b.Mem(), 0, NULL, NULL);
error |=
clEnqueueWriteImage(queue.get(), img_c, CL_TRUE, origin.data(), region.data(), 0, 0, h_c.Mem(), 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("clEnqueueWriteImage failed\n");
}
std::vector<std::string> programStrings;
programStrings.push_back(kernel_source);
cl::Program program(context, programStrings);
if (program.build({default_device}, "-cl-std=CL3.0") != CL_SUCCESS) {
std::cout << "Error building: " << program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device) << std::endl;
exit(1);
}
cl::Kernel cl_kernel(program, "vecAdd");
int arg_pos = 0;
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_a);
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_b);
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_c);
error |= cl_kernel.setArg(arg_pos++, sizeof(int), &width_d4);
if (error != CL_SUCCESS) {
printf("setArg failed\n");
}
int local_size_x = std::min(width_d4, 32);
int local_size_y = std::min(height, 16);
cl::NDRange global_size(width_d4, height);
cl::NDRange local_size(local_size_x, local_size_y);
int warmup_num = 50;
int eval_num = 50;
for (int i = 0; i < warmup_num; i++) {
queue.enqueueNDRangeKernel(cl_kernel, cl::NullRange, global_size, local_size, NULL, NULL);
}
queue.finish();
float total_time = 0.0f;
for (int i = 0; i < eval_num; i++) {
cl::Event event;
cl_int err = queue.enqueueNDRangeKernel(cl_kernel, cl::NullRange, global_size, local_size, NULL, &event);
if (err != CL_SUCCESS) {
printf("enqueueNDRangeKernel failed\n");
}
event.wait();
cl_ulong start_time, end_time; // time in ns
cl_int err1 = event.getProfilingInfo(CL_PROFILING_COMMAND_START, &start_time);
cl_int err2 = event.getProfilingInfo(CL_PROFILING_COMMAND_END, &end_time);
float exec_time = (end_time - start_time) / 1000.0f;
total_time += exec_time;
}
queue.finish();
printf("mean exec time: %f us ----------\n", total_time / eval_num);
error |=
clEnqueueReadImage(queue.get(), img_c, CL_TRUE, origin.data(), region.data(), 0, 0, h_c.Mem(), 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("clEnqueueWriteImage failed\n");
}
h_a.PrintElems(1, 256);
h_c.PrintElems(1, 256);
clReleaseMemObject(img_a);
clReleaseMemObject(img_b);
clReleaseMemObject(img_c);
return 0;
}
По сравнению с версией векторного добавления на основе буфера, версия image2d процессора Qualcomm 888 на 10% медленнее, чем версия с буфером, что показывает, что не все приложения Qualcomm GPU быстрее, чем изображение, чем буфер. Разница между vecadd и обработкой изображений здесь может заключаться в том, что один поток считывает данные только одного пикселя, а преимущество кеша изображения не отражается.
В сцене, где каждому потоку необходимо прочитать данные из нескольких соседних позиций при умножении на матрицу ядра свертки, изображение может быть лучше, чем буфер. На самом деле это действительно так, автор реализовал матричное умножение тайлов нитей 8x1x1x4 на основе буфера и изображения, вариант с изображением на 10%-15% быстрее, чем вариант с буфером.
image1d_buffer_t
Одномерное изображение, созданное из буферного объекта. Для получения дополнительной информации см. отдельные функции изображения.
void write_imagef (изображение image1d_buffer_t, int coord, float4 color);
float4 read_imagef(read_write image1d_buffer_t image, int coord);
Image1DBuffer(
const Context& context,
cl_mem_flags flags,
ImageFormat format,
size_type width,
const Buffer &buffer,
cl_int* err = NULL)